








@R星校长

内存的访问效率是硬盘的10万倍

Zoo 动物园 Keeper 管理者 因为 hadoop 大象 pig 小猪 都是他们开发的,再有一些这样的起名的软件,我们就成动物园了 ,所以我们这款产品就叫动物园管理员吧
如你有几千台服务器的集群,你就需要用 ZooKeeper 监控,看那台服务器宕机了
ElasticSearch 学起来很快,因为它是站在巨人 Lucene 的肩膀上

因为实时计算 Spark 的底层代码是用 Scala 写的,所以 Scala 也需要学习,配合 Spark 做实时计算

Scala


CDH 可视化安装,解决兼容问题,它提前给你兼容的对应关系,如Hadoop和hive的兼容版本,都有推荐

实时计算 最近几年比较火

Flink 也是做实时运算,是分布式的流数据引擎
我推荐这个,国内字节跳动和阿里都是主要用的 Flink ,想多了解一些东西可以去看看阿里技术 这个公众号

Kylin 麒麟能在亚秒内查询巨大的 Hive 表

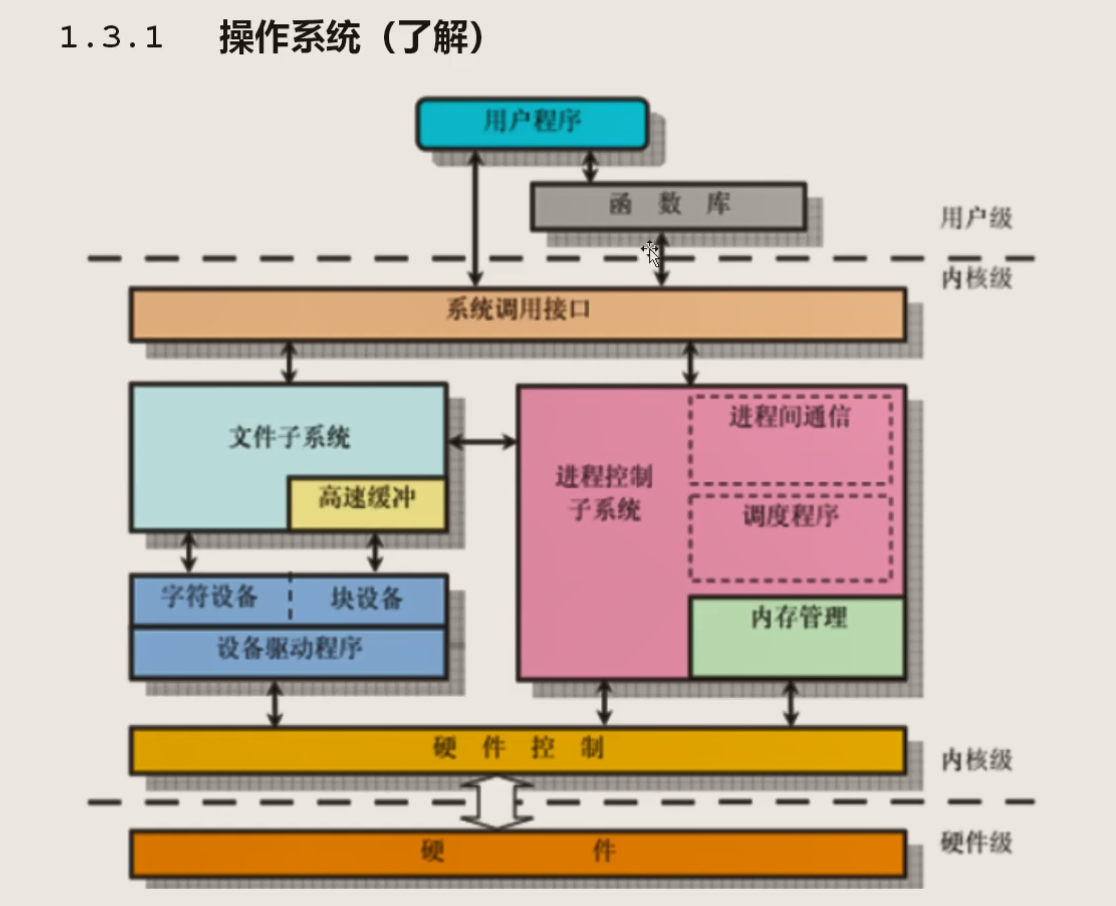
安装在电脑上的叫应用程序,那什
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









