








@R星校长
MapReduce 实战2 案例-2
课程内容
PageRank
TF-IDF
itemCF
PageRank
概念
PageRank 是 Google 提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。是 Google 创始人拉里·佩奇和谢尔盖·布林于1997年创造的 PageRank 实现了将链接价值概念作为排名因素。
GOOGLE PageRank 并不是唯一的链接相关的排名算法,而是最为广泛使用的一种。其他算法还有:
1、 Hilltop 算法
2、 ExpertRank
3、 HITS
4、 TrustRank
思考超链接在互联网中的作用
入链 ====投票
PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票。
入链数量
如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
入链质量
指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面 A,则页面 A 越重要。
案例分析 pagerank PR 值
站在 A 的角度:
需要将自己的 PR 值分给 B,D
站在 B 的角度:
收到来自 A,C,D 的 PR 值
迭代计算使 PR 值收敛于稳定值
假设初始值设定为 1。
算法实现
初始值
Google 的每个页面设置相同的 PR 值
pagerank 算法给每个页面的 PR 初始值为 1。
迭代计算(收敛)
Google 不断的重复计算每个页面的 PageRank 。那么经过不断的重复计算,这些页面的 PR 值会趋向于稳定,也就是收敛的状态。
在具体企业应用中怎么样确定收敛标准?
1、 每个页面的PR值和上一次计算的PR相等
2、 设定一个差值指标(0.0001)。当所有页面和上一次计算的PR|差值|的平均值小于标准时,则收敛。

PRa - PRa’ = |Δ|
3、 设定一个百分比(99%),当99%的页面和上一次计算的PR相等。
算法修正
站在互联网的角度:
只出,不入:PR会为0
只入,不出:PR会很高
直接访问网页
修正 PageRank 计算公式
增加阻尼系数
在简单公式的基础上增加了阻尼系数(damping factor)d,一般取值 d=0.85。

完整 PageRank 计算公式
d:阻尼系数 0.85
M(i):指向i的页面集合 ?
L(j):页面的出链数 1/2
PR(pj):j页面的PR值
n:所有页面数
数据
A B D
B C
C A B
D B C
解题思路
分组:所有指向第 i 个页面的页面的 PR 值之和。
将所有指向第 i 个页面的页面分为一组,reduce 中迭代计算。
A B D
B C
C A B
D B C
PR 初始值是 1
<偏移量, A B D>
A->B
A->D
B 1/2
D 1/2
A B D
C 1
B C
A 1/2
B 1/2
C A B
B 1/2
C 1/2
D B C
分组:
A 1/2
A B D
B 1/2
B 1/2
B 1/2
B C
C 1
C 1/2
C A B
D 1/2
D B C
Reduce 接收到数据,先将原 pr 值进行累加:
A 1/2
A B D
B 3/2
B C
C 3/2
C A B
D 1/2
D B C
然后套公式:
A 0.15/4 + 0.85 *1/2
A B D
B 0.15/4 + 0.85 *3/2
B C
C 0.15/4 + 0.85 *3/2
C A B
D 0.15/4 + 0.85 *1/2
D B C
计算结果:
A 0.4625
A B D
B 1.3125
B C
C 1.3125
C A B
D 0.4625
D B C
Reduce 输出该如何设计?既要有计算后新的PR值,又要有投票关系:
key value
A 0.4625\tB\tD
B 1.3125\tC
C 1.3125\tA\tB
D 0.4625\tB\tC
{“0.4625”,“B”,“D”}=value.toString().split("\t");
输出后,还要计算当前页的 PR 差:(long)(|newPR-oldPR|*10000),将来计算的时候在除以 10000 即可。何时停止 MR 计算,当所有页本次与上次运算 PR 差值的平均值小于 0.0001。所以还要想办法将所有 reduce 技术的 “ PR差 ” 求和。
第一轮运算:
PR(A)1=(1-0.85)/4 + 0.85*(1/2)=0.0375+0.425=0.4625
PR(B)1=(1-0.85)/4 + 0.85*(1/2+1/2+1/2)=0.0375+1.275=1.3125
PR(C)1=(1-0.85)/4 + 0.85*(1+1/2)=1.3125
PR(D)1=(1-0.85)/4 + 0.85*(1/2)=0.4625
不判断
第二轮运算:
PR(A)2=(1-0.85)/4 + 0.85*(1.3125/2)=
PR(B)2=(1-0.85)/4 + 0.85*(0.4625/2+1.3125/2+0.4625/2)=
PR(C)2=(1-0.85)/4 + 0.85*(1.3125+0.4625/2)=
PR(D)2=(1-0.85)/4 + 0.85*(0.4625/2)=
判断(从第二轮开始都判断):
(|PR(A)2-PR(A)1 |*10000+|PR(B)2-PR(B)1 |*10000+|PR(C)2-PR(C)1 |*10000+|PR(D)2-PR(D)1 |*10000)/4<0.0001
成立则break;
不成立执行第三轮运算和判断
思路总结
**MR原语不被破坏
PR 计算是一个迭代的过程,首先考虑一次计算
思考:
页面包含超链接
每次迭代将 pr 值除以链接数后得到的值传递给所链接的页面
so:每次迭代都要包含页面链接关系和该页面的 pr 值
mr:相同的 key 为一组的特征
map:
1,读懂数据:第一次附加初始 pr 值
2,映射 k : v
1,传递页面链接关系,key 为该页面,value 为页面链接关系
2,计算链接的 pr 值,key 为所链接的页面,value 为 pr 值
reduce:
*,按页面分组
1,两类value分别处理
2,最终合并为一条数据输出:key为页面&新的pr值,value为链接关系
开发步骤
数据准备
[root@node1 ~]# hdfs dfs -mkdir -p /data/pagerank/input
[root@node1 ~]# vim pagerank.txt
[root@node1 ~]# hdfs dfs -put pagerank.txt /data/pagerank/input
[root@node1 ~]# hdfs dfs -ls /usr/local/pagerank
Found 1 items
-rw-r--r-- 2 root supergroup 22 2020-02-12 18:21 /usr/local/pagerank/pagerank.txt
PRMapper
package com.bjsxt.mr.pagerank;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PRMapper extends Mapper<Text, Text, Text, Text> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
// 指示第几次运行
int index = context.getConfiguration().getInt("runCount", 0);
System.err.println("index = " + index);
//KeyValueTextInputFormat使用\t对行进行分割,第一个\t前面是key,后面是value
//第一次运行:key:A value:B\tD
//非次运行:key:A value:0.4625\tB\tD
String line = value.toString();
String[] pages = line.split("\t");
//被key投票的页面数量,后续被用于均分key的PR值
int pageNum = 0;
//用于确定pages[]数组遍历从0(第一次运行)开始还是从1(非第一次运行)开始
int i = 0;
//当前Key的PR值,第一次默认为1.0
double prValue = 1.0;
//
String newValue = line;
if (index == 0) {
// B D
pageNum = pages.length;
// 为了防止第一次计算的时候,没有pr值,添加默认pr值
newValue = "1\t" + newValue;
} else {
// pages: {"0.4625","B","D"}
prValue = Double.parseDouble(pages[0]);
pageNum = pages.length - 1;
i = 1;//后续遍历时排除掉0.465
}
// B D
for (;i < pages.length; i++) {
// <B, 1/2>
// <D, 1/2>
context.write(new Text(pages[i]), new Text(prValue / pageNum + ""));
}
// <A, pr B D>
context.write(key, new Text(newValue));
System.err.println("Mapper输出键值对:" + key.toString() + "::" + newValue);
}
}
PRReducer
package com.bjsxt.mr.pagerank;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PRReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//计算key被投票PR值的和
//C 1
//C 1/2
//C 1\tA\tB
//定义变量,用于记录旧的投票关系,比如:1\tA\tB
String oldValue = null;
//计算PR值得和 1+1/2
double prSum = 0;
//遍历迭代器
for (Text value : values) {
String str = value.toString();
String[] strs = str.split("\t");
if (strs.length == 1) {
// 1
// 1/2
prSum += Double.parseDouble(strs[0]);
} else if (strs.length > 1) {
// 1\tA\tB
oldValue = str;
}
}
// 获取旧的PR值:1\tA\tB->1
double oldPr = Double.parseDouble(oldValue.substring(0, oldValue.indexOf("\t")));
//newPr=0.15/4 + 0.85 *3/2= 1.3125
double newPr = 0.15/4 + 0.85 * prSum;
// 更新pr值之后
// 1.3125\tA\tB
String newValue = newPr + oldValue.substring(oldValue.indexOf("\t"));
// <C,1.3125\tA\tB>
context.write(key, new Text(newValue));
// 输出每次计算的pr值差值
System.err.println(Math.abs(newPr - oldPr) * 10000);
// 本次PR值-上次PR值 取绝对值,在所有reduce之间累加这个值
context.getCounter(MainClass.MyCounter.MY_COUNTER).increment((long) (Math.abs(newPr - oldPr) * 10000));
}
}
package com.bjsxt.mr.pagerank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MainClass {
enum MyCounter {
MY_COUNTER
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
//用于存储中间数据,mapreduce运行完要删掉
configuration.set("mapreduce.cluster.local.dir", "E:\\usr\\local\\mapreduce.cluster.local.dir");
int index = 0;
double myvalue = 0.0001;
while (true) {
configuration.setInt("runCount", index);
// configuration的设置一定设置完之后再实例化Job对象
Job job = Job.getInstance(configuration);
// job中获取不到这里设置的参数
// configuration.setInt("runCount", index);
//将当前是第几次计算放到计数器中
System.err.println(configuration.getInt("runCount", 0));
job.setJobName("pageRank");
job.setJarByClass(MainClass.class);
// 该inputformat使用\t对行进行分割,\t前面是key,后面是value
// 如果没有\t,则整行是key,value是空的
// 如果有多个\t,则第一个\t之前的是key,后面的是value
job.setInputFormatClass(KeyValueTextInputFormat.class);
if (index != 0) {
// 如果不是第一次计算,则以上次计算结果作为本次输入
FileInputFormat.addInputPath(job, new Path("/mr/pagerank/output" + (index - 1)));
} else {
// 如果是第一次计算,则直接读取原始文件
FileInputFormat.addInputPath(job, new Path("/usr/local/pagerank.txt"));
}
// 输出设置
FileOutputFormat.setOutputPath(job, new Path("/mr/pagerank/output" + index));
job.setMapperClass(PRMapper.class);
job.setReducerClass(PRReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.waitForCompletion(true);
long sum = job.getCounters().findCounter(MyCounter.MY_COUNTER).getValue();
System.err.println("sum = " + sum);
if (sum * 1.0 / (10000 * 4) < myvalue) {
break;
}
index++;
}
}
}
TF-IDF
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。
TF-IDF 是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF 加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
除了 TF-IDF 以外,因特网上的搜寻引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序:PageRank。
词频
词频 (term frequency, TF) 指的是某一个给定的词语在一份给定的文件中出现的次数。
Java A:10 200
B:20 20000
这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
公式中: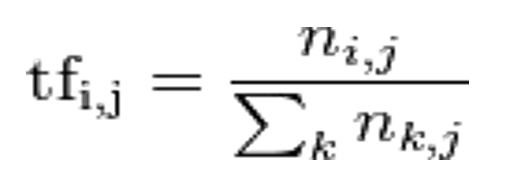
ni,j 是该词在文件 dj 中的出现次数,而分母则是在文件 dj 中所有字词的出现次数之和。
该单词出现的次数/该文档总词数=词频
逆向文档频率
逆向文档频率 ( inverse document frequency, IDF ) 是一个词语普遍重要性的度量。某一特定词语的 IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。

TF-IDF:
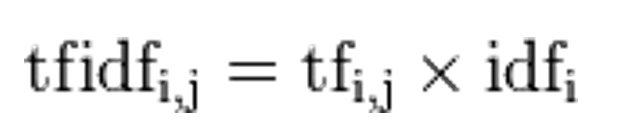
某一特定文件内的高词语频率(tf),以及该词语在整个文件集合中的高逆向文档频率(idf),可以产生出高权重的 TF-IDF。因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。
TFIDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
分析


∑表示A文档中一共多少单词 √
D表示文档总数, √
花括号表示包含AX单词的文档数 <单词,文档数>
实现
MR-1
第一次:词频统计 + 文本总数统计
map:
词频:key:字词_文本 id,value:1
文本总数:key:count,value:1
partition:4个 reduce
0~2号 reduce 并行计算词频
3号 reduce 计算文本总数
reduce:
0~2:字词_文本 id sum
3:count:sum
MR-2
字词集合统计:逆向文件频率
map:
key:字词,value:1
reduce:
字词 sum
MR-3
取 1,2 次结果最终计算出字词的 TF-IDF
map:
输入数据为第一步的 tf
setup:
加载:a,DF;b,文本总数
计算TF-IDF
key:文本,value:字词 + TF-IDF
reduce:
按文本(key)生成该文本的字词 + TF-IDF 值列表
itemCF
概述
电子商务网站是个性化推荐系统重要地应用的领域之一。亚马逊就是个性化推荐系统的积极应用者和推广者,亚马逊的推荐系统深入到网站的各类商品,为亚马逊带来了至少 30% 的销售额。
不光是电商类,推荐系统无处不在。
QQ,人人网的好友推荐;新浪微博的你可能感觉兴趣的人;优酷,土豆的电影推荐;豆瓣的图书推荐;大众点评的餐饮推荐;世纪佳缘的相亲推荐;天际网的职业推荐等。
最近两年比较火的今日头条、抖音、快手等,无一例外的都使用推荐系统。
思考
购买成功后:购买了该商品的其他用户购买了以下商品
根据用户的实时行为
搜索成功后:您可能感兴趣的以下商品
根据用户的主观意识
主页或广告:您可能感兴趣的以下商品
根据用户的特征向量
推荐系统
协同过滤(Collaborative Filtering)算法
UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
ItemCF
基于 item 的协同过滤,通过用户对不同 item 的评分来评测 item 之间的相似性,基于 item 之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
同现矩阵和用户评分向量
Co-occurrence Matrix (同现矩阵) 和 User Preference Vector (用户评分向量) 相乘得到的这个 Recommended Vector (推荐向量)
基于全量数据的统计,产生同现矩阵
体现商品间的关联性
每件商品都有自己对其他全部商品的关联性(每件商品的特征)
用户评分向量体现的是用户对一些商品的评分
任一商品需要:
用户评分向量乘以基于该商品的其他商品关联值
求和得出针对该商品的推荐向量
排序取 TopN 即可

思路解析
通过历史 订单交易记录
计算得出每一件商品相对其他商品同时出现在同一订单的次数
so:每件商品都有自己相对全部商品的同现列表
用户会对部分商品有过加入购物车,购买等实际操作,经过计算会得到用户对这部分商品的评分向量列表 查看(点击),收藏,加入购物车,付款
使用用户评分向量列表中的分值:
依次乘以每一件商品同现列表中该分值的代表物品的同现值
求和便是该物品的推荐向量
计算步骤
去除重复数据
计算用户评分向量
计算同现矩阵
计算乘积
计算求和
计算取 TopN
原始数据
MapReduce(k : v , 原语)
i161,u2625,click,2014/9/18 15:03
i161,u2626,click,2014/9/23 22:40
i161,u2627,click,2014/9/25 19:09
i161,u2628,click,2014/9/28 21:35
用户评分向量(所有用户对所有商品的评分)
同现矩阵
乘积计算
求和计算
去除重复数据
计算用户评分向量
key:用户
value:商品:评分 列表
计算同现矩阵
将每个用户的平分向量列表中的商品,两两组合输出(笛卡儿积),sum 次数
key:商品A:商品B
key:商品B:商品A
value:1
计算乘积
按商品分组
同现矩阵:A 商品同现列表
评分矩阵:所有用户对 A 商品的评分
乘机逻辑:不同同现商品下,A 商品的乘机
but:计算商品 A 对于用户甲的推荐向量需要满足:
商品 A 同现商品各自的评分乘机,再求和
map@key:商品
map@val:
reduce@key:用户+同现
reduce@val:map@key+乘机
计算求和
计算取 TopN
同现:
101:101 3
101:102 2
101:103 5
102:101 3
102:102 2
102:103 5
用户评分:
101:12
102:6















 6105
6105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









