







算法&&八股文&&其他
前言:转眼间面经整理计划已经来到第十弹了,前面一直都是在简单的“搬运”而没有深究,接下来一段时间就是“内化于心”的时候了🤔,因此本计划会暂停更新一个月,感谢大家一直以来对本计划的关注与支持,祝大家都能斩获满意的offer🔥
----愿我们在互相看不见的日子里熠熠生辉✨----
一、算法篇
- 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
分析:hard(lc132)
动态规划:设 f [ i ] f[i] f[i] 表示字符串的前缀 s [ 0.. i ] s[0..i] s[0..i] 的最少分割次数,可以写出状态转移方程 :
f [ i ] = min 0 ≤ j < i f [ j ] + 1 f[i] = \min_{\mathclap{0\le j\lt i}} {f[j]}+1 f[i]=0≤j<iminf[j]+1其中 s [ j + 1.. i ] \ s[j+1..i] s[j+1..i]是一个回文串。即我们枚举最后一个回文串的起始位置 j + 1 j+1 j+1,保证 s [ j + 1.. i ] s[j+1..i] s[j+1..i] 是一个回文串,那么 f [ i ] f[i] f[i] 就可以从 f [ j ] f[j] f[j] 转移而来,附加 1 次额外的分割次数。并考虑到当 s [ 0.. i ] s[0..i] s[0..i] 本身就是一个回文串,此时不需要进行任何分割,即 f [ i ] = 0 f[i] = 0 f[i]=0
预处理:将字符串 s 的每个子串是否为回文串预先计算出来,方法如下:设 g ( i , j ) g(i,j) g(i,j) 表示 s [ i . . j ] s[i..j] s[i..j] 是否为回文串,那么有状态转移方程:
g ( i , j ) = { True , i ≥ j g ( i + 1 , j − 1 ) ∧ ( s [ i ] = s [ j ] ) , otherwise g(i, j) = \begin{cases} \texttt{True}, & \quad i \geq j \\ g(i+1,j-1) \wedge (s[i]=s[j]), & \quad \text{otherwise} \end{cases} g(i,j)={True,g(i+1,j−1)∧(s[i]=s[j]),i≥jotherwise
其中 ∧ \wedge ∧ 表示逻辑与运算,即 s [ i . . j ] s[i..j] s[i..j] 为回文串,当且仅当其为空串( i > j i>j i>j),其长度为 1( i = j i=j i=j),或者首尾字符相同且 s [ i + 1.. j − 1 ] s[i+1..j−1] s[i+1..j−1] 为回文串。
class Solution:
def minCut(self, s: str) -> int:
n = len(s)
g = [[True] * n for _ in range(n)]
for i in range(n - 1, -1, -1):
for j in range(i + 1, n):
g[i][j] = (s[i] == s[j]) and g[i + 1][j - 1]
f = [float("inf")] * n
for i in range(n):
if g[0][i]:
f[i] = 0
else:
for j in range(i):
if g[j + 1][i]:
f[i] = min(f[i], f[j] + 1)
return f[n - 1]
- 给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度
分析:middle(lc525)
前缀和 + 哈希表:由于「0 和 1 的数量相同」等价于「1 的数量减去 0 的数量等于 0」,我们可以将数组中的 0 视作 −1,则原问题转换成 求最长的连续子数组,其元素和为 0,记转换后的数组为 n e w N u m s newNums newNums,为了快速计算 newNums \textit{newNums} newNums 的子数组的元素和,需要首先计算 newNums \textit{newNums} newNums 的前缀和。用 prefixSums [ i ] \textit{prefixSums}[i] prefixSums[i] 表示 newNums \textit{newNums} newNums 从下标 0 到下标 i i i 的前缀和,则 newNums \textit{newNums} newNums 从下标 j + 1 j+1 j+1 到下标 k k k(其中 j + 1 ≤ k j+1\le k j+1≤k)的子数组的元素和为 prefixSums [ k ] − prefixSums [ j ] \textit{prefixSums}[k]-\textit{prefixSums}[j] prefixSums[k]−prefixSums[j],该子数组的长度为 k − j k−j k−j。
当 prefixSums [ k ] − prefixSums [ j ] = 0 \textit{prefixSums}[k]-\textit{prefixSums}[j]=0 prefixSums[k]−prefixSums[j]=0 时,即得到 newNums \textit{newNums} newNums 的一个长度为 k − j k−j k−j 的子数组元素和为 0 0 0,对应 nums \textit{nums} nums 的一个长度为 k − j k−j k−j 的子数组中有相同数量的 0 0 0 和 1 1 1。
实现方面,不需要创建数组 newNums \textit{newNums} newNums 和 prefixSums \textit{prefixSums} prefixSums,只需要维护一个变量 counter \textit{counter} counter 存储 newNums \textit{newNums} newNums 的前缀和即可。具体做法是,遍历数组 nums \textit{nums} nums,当遇到元素 1 1 1 时将 counter \textit{counter} counter 的值加 1 1 1,当遇到元素 0 0 0 时将 counter \textit{counter} counter 的值减 1 1 1,遍历过程中使用哈希表存储每个前缀和第一次出现的下标。
规定空的前缀的结束下标为 − 1 −1 −1,由于空的前缀的元素和为 0 0 0,因此在遍历之前,首先在哈希表中存入键值对 ( 0 , − 1 ) (0,−1) (0,−1)
由于哈希表存储的是 counter \textit{counter} counter 的每个取值第一次出现的下标,因此当遇到重复的前缀和时,根据当前下标和哈希表中存储的下标计算得到的子数组长度是以当前下标结尾的子数组中满足有相同数量的 0 0 0 和 1 1 1 的最长子数组的长度。遍历结束时,即可得到 nums \textit{nums} nums 中的有相同数量的 0 0 0 和 1 1 1 的最长子数组的长度。
class Solution {
public:
int findMaxLength(vector<int>& nums) {
int maxLength = 0;
unordered_map<int, int> mp;
int counter = 0;
mp[counter] = -1;
int n = nums.size();
for (int i = 0; i < n; i++) {
int num = nums[i];
if (num == 1) {
counter++;
} else {
counter--;
}
if (mp.count(counter)) {
int prevIndex = mp[counter];
maxLength = max(maxLength, i - prevIndex);
} else {
mp[counter] = i;
}
}
return maxLength;
}
};
3.给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
分析:middle(lc19)
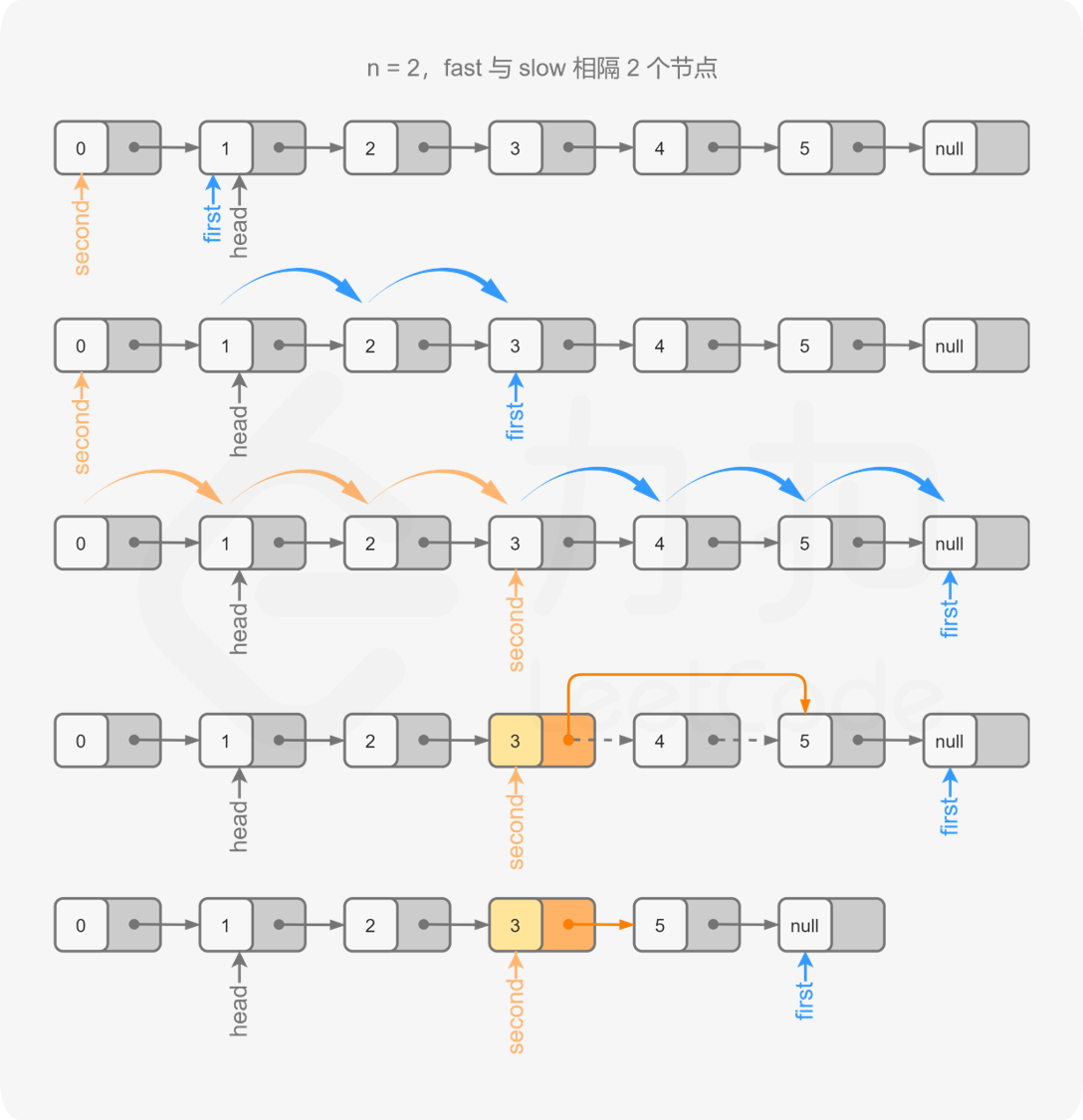
双指针:由于我们需要找到倒数第 n n n 个节点,因此我们可以使用两个指针 first \textit{first} first 和 second \textit{second} second 同时对链表进行遍历,并且 first \textit{first} first 比 second \textit{second} second 超前 n n n 个节点。当 first \textit{first} first 遍历到链表的末尾时, second \textit{second} second 就恰好处于倒数第 n n n 个节点。
具体地,初始时 first \textit{first} first 和 second \textit{second} second 均指向头节点。我们首先使用 first \textit{first} first 对链表进行遍历,遍历的次数为 n n n。此时, first \textit{first} first 和 second \textit{second} second 之间间隔了 n − 1 n−1 n−1 个节点,即 first \textit{first} first 比 second \textit{second} second 超前了 n n n 个节点。
在这之后,我们同时使用 first \textit{first} first 和 second \textit{second} second 对链表进行遍历。当 first \textit{first} first 遍历到链表的末尾(即 first \textit{first} first 为空指针)时, second \textit{second} second 恰好指向倒数第 n n n 个节点。
而如果我们能够得到的是倒数第 n n n 个节点的前驱节点而不是倒数第 n n n 个节点的话,删除操作会更加方便。因此我们可以考虑在初始时将 second \textit{second} second 指向哑节点,其余的操作步骤不变。这样一来,当 first \textit{first} first 遍历到链表的末尾时, second \textit{second} second 的下一个节点就是我们需要删除的节点。 如图所示:
class Solution:
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
dummy = ListNode(0, head)
first = head
second = dummy
for i in range(n):
first = first.next
while first:
first = first.next
second = second.next
second.next = second.next.next
return dummy.next
- 给定一个字符串s,找到至多包含k个不同字符得最长子串的长度
分析:middle(lc340)
滑动窗口+hash表:遍历字符串将其加入到hash表中, 若不同字符多于k个, 就从左边开始删字符. 直到hash表不同字符长度等于k.此时字符串的长度就是当前字符和左边界的距离
class Solution:
def lengthOfLongestSubstringKDistinct(self,s,k):
from collections import defaultdict
#使用python中的collections.defaultdict
#字典中存储的整型的值默认为0
hash = defaultdict(int)
max_num = 0 #用于存放最大值
start = 0 #滑动窗口的左端
#从字符串左开始遍历
for i in range(len(s)):
#遍历到一个字符,使得字典中对应得字符加1
hash[s[i]] += 1
while len(hash)>k:
hash[s[start]] -= 1
if hash[s[start]] == 0:
del hash[s[start]]
start += 1
max_num = max(max_num,i-start+1)
return max_num
- 快速求幂xn
分析:快速幂
位运算
def quickPower(x, n):
ans = 1
while n:
if n&1:ans *= x
x *= x
n >>= 1
return ans
- 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致
分析:简单(lc26)
双指针:当数组 nums \textit{nums} nums 的长度大于 0 0 0 时,数组中至少包含一个元素,在删除重复元素之后也至少剩下一个元素,因此 nums [ 0 ] \textit{nums}[0] nums[0] 保持原状即可,从下标 1 1 1 开始删除重复元素。
定义两个指针 fast \textit{fast} fast 和 slow \textit{slow} slow 分别为快指针和慢指针,快指针表示遍历数组到达的下标位置,慢指针表示下一个不同元素要填入的下标位置,初始时两个指针都指向下标 1 1 1。
假设数组 nums \textit{nums} nums 的长度为 n n n。将快指针 fast \textit{fast} fast 依次遍历从 1 1 1 到 n − 1 n−1 n−1 的每个位置,对于每个位置,如果 nums [ fast ] ≠ nums [ fast − 1 ] \textit{nums}[\textit{fast}] \ne \textit{nums}[\textit{fast}-1] nums[fast]=nums[fast−1],说明 nums [ fast ] \textit{nums}[\textit{fast}] nums[fast] 和之前的元素都不同,因此将 nums [ fast ] \textit{nums}[\textit{fast}] nums[fast] 的值复制到 nums [ slow ] \textit{nums}[\textit{slow}] nums[slow],然后将 slow \textit{slow} slow 的值加 1 1 1,即指向下一个位置。
遍历结束之后,从 nums [ 0 ] \textit{nums}[0] nums[0] 到 nums [ slow − 1 ] \textit{nums}[\textit{slow}-1] nums[slow−1] 的每个元素都不相同且包含原数组中的每个不同的元素,因此新的长度即为 slow \textit{slow} slow,返回 slow \textit{slow} slow 即可。
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
if not nums:
return 0
n = len(nums)
fast = slow = 1
while fast < n:
if nums[fast] != nums[fast - 1]:
if and fast-slow > 0:
nums[slow] = nums[fast]
slow += 1
fast += 1
return slow
- 以字符串的形式读入两个数字,编写一个函数计算它们的乘积,以字符串形式返回。
分析:middle(lc43)
模拟: 维护一个单调递增的栈,当栈非空并且栈顶数 令 m m m 和 n n n 分别表示 num 1 \textit{num}_1 num1 和 num 2 \textit{num}_2 num2 的长度,并且它们均不为 0,则 num 1 \textit{num}_1 num1 和 num 2 \textit{num}_2 num2 的乘积的长度为 m + n − 1 m+n−1 m+n−1 或 m + n m+n m+n。简单证明如下:
- 如果 num 1 \textit{num}_1 num1 和 num 2 \textit{num}_2 num2 都取最小值,则 num 1 = 1 0 m − 1 \textit{num}_1=10^{m-1} num1=10m−1, num2 = 1 0 n − 1 \textit{num2}=10^{n-1} num2=10n−1, num 1 × num 2 = 1 0 m + n − 2 \textit{num}_1 \times \textit{num}_2=10^{m+n-2} num1×num2=10m+n−2 ,乘积的长度为 m+n−1;
- 如果 num 1 \textit{num}_1 num1 和 num 2 \textit{num}_2 num2 都取最大值,则 num 1 = 1 0 m − 1 \textit{num}_1=10^m-1 num1=10m−1, num 2 = 1 0 n − 1 \textit{num}_2=10^n-1 num2=10n−1, num 1 × num 2 = 1 0 m + n − 1 0 m − 1 0 n + 1 \textit{num}_1 \times \textit{num}_2=10^{m+n}-10^m-10^n+1 num1×num2=10m+n−10m−10n+1,乘积显然小于 1 0 m + n 10^{m+n} 10m+n 且大于 1 0 m + n − 1 10^{m+n-1} 10m+n−1,因此乘积的长度为 m+n。
由于 num 1 \textit{num}_1 num1 和 num 2 \textit{num}_2 num2 的乘积的最大长度为 m + n m+n m+n,因此创建长度为 m + n m+n m+n 的数组 ansArr \textit{ansArr} ansArr 用于存储乘积。对于任意 0 ≤ i < m 0 \le i < m 0≤i<m 和 0 ≤ j < n 0 \le j < n 0≤j<n, num 1 [ i ] × num 2 [ j ] \textit{num}_1[i] \times \textit{num}_2[j] num1[i]×num2[j] 的结果位于 ansArr [ i + j + 1 ] \textit{ansArr}[i+j+1] ansArr[i+j+1],如果 ansArr [ i + j + 1 ] ≥ 10 \textit{ansArr}[i+j+1] \ge 10 ansArr[i+j+1]≥10,则将进位部分加到 ansArr [ i + j ] \textit{ansArr}[i+j] ansArr[i+j]。
最后,将数组 ansArr \textit{ansArr} ansArr 转成字符串,如果最高位是 0 则舍弃最高位。
class Solution {
public:
string multiply(string num1, string num2) {
if (num1 == "0" || num2 == "0") {
return "0";
}
int m = num1.size(), n = num2.size();
auto ansArr = vector<int>(m + n);
for (int i = m - 1; i >= 0; i--) {
int x = num1.at(i) - '0';
for (int j = n - 1; j >= 0; j--) {
int y = num2.at(j) - '0';
ansArr[i + j + 1] += x * y;
}
}
for (int i = m + n - 1; i > 0; i--) {
ansArr[i - 1] += ansArr[i] / 10;
ansArr[i] %= 10;
}
int index = ansArr[0] == 0 ? 1 : 0;
string ans;
while (index < m + n) {
ans.push_back(ansArr[index]);
index++;
}
for (auto &c: ans) {
c += '0';
}
return ans;
}
};
- 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
分析:middle(lc133)
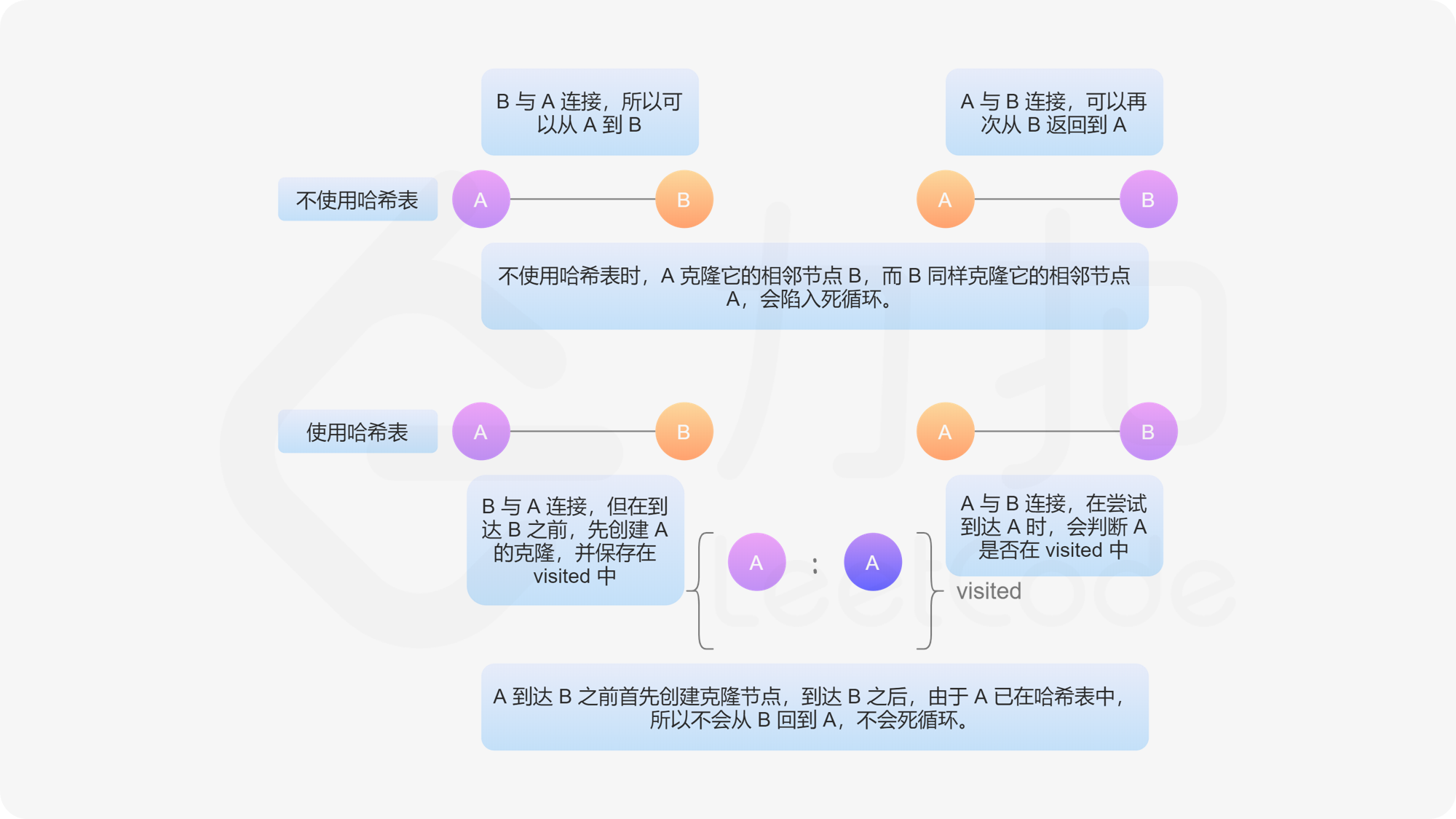
深度优先搜索:为了深拷贝出整张图,我们需要知道整张图的结构以及对应节点的值。因此我们需要从给定的节点出发,进行「图的遍历」,并在遍历的过程中完成图的深拷贝。为了防止多次遍历同一个节点,陷入死循环,我们需要用一种数据结构记录已经被克隆过的节点。
- 使用一个哈希表存储所有已被访问和克隆的节点。哈希表中的 key 是原始图中的节点,value 是克隆图中的对应节点。
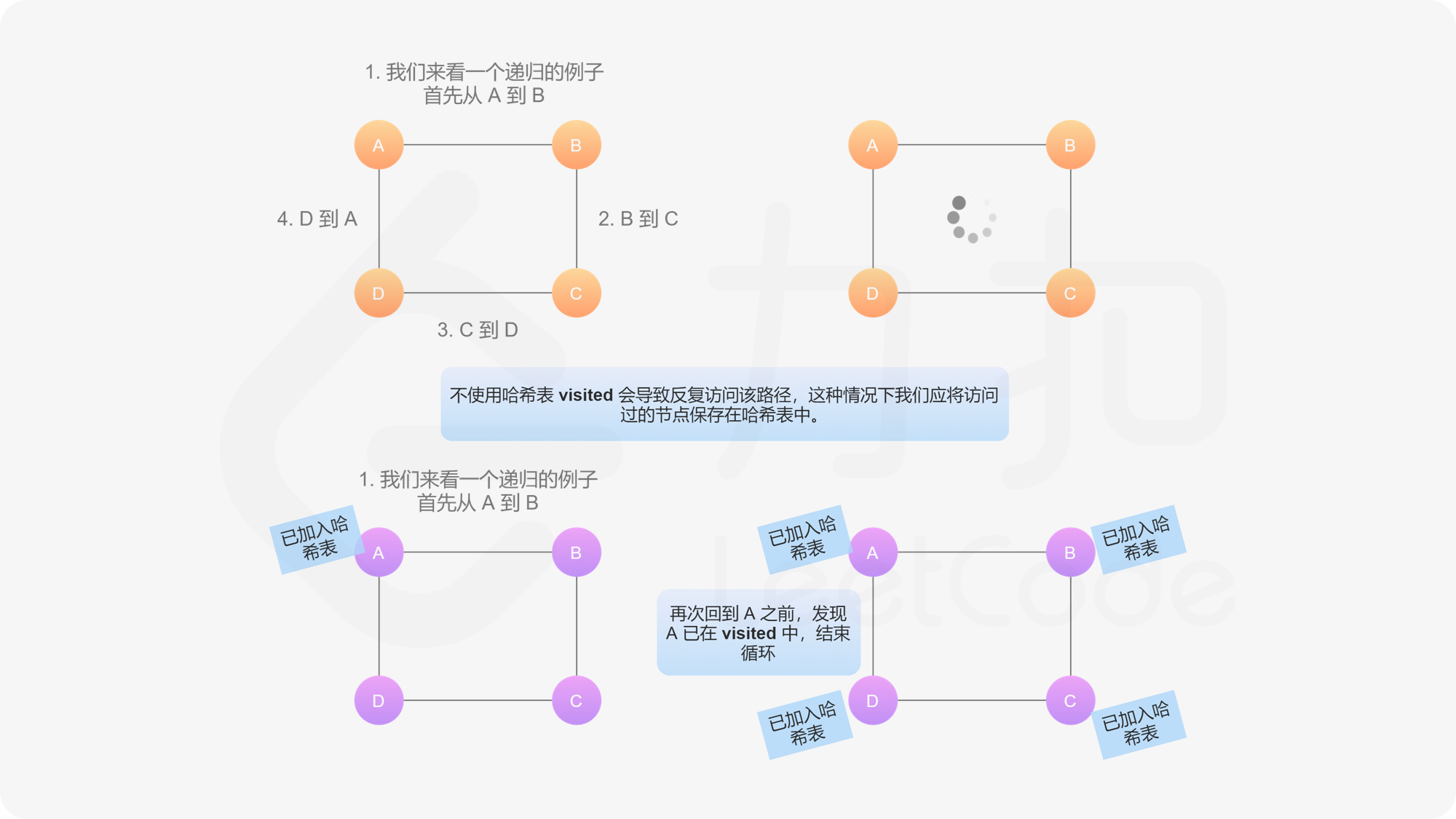
- 从给定节点开始遍历图。如果某个节点已经被访问过,则返回其克隆图中的对应节点。如下图,我们给定无向边边 A - B,表示 A 能连接到 B,且 B 能连接到 A。如果不对访问过的节点做标记,则会陷入死循环中。
- 如果当前访问的节点不在哈希表中,则创建它的克隆节点并存储在哈希表中。注意:在进入递归之前,必须先创建克隆节点并保存在哈希表中。如果不保证这种顺序,可能会在递归中再次遇到同一个节点,再次遍历该节点时,陷入死循环。
- 递归调用每个节点的邻接点。每个节点递归调用的次数等于邻接点的数量,每一次调用返回其对应邻接点的克隆节点,最终返回这些克隆邻接点的列表,将其放入对应克隆节点的邻接表中。这样就可以克隆给定的节点和其邻接点。
广度优先搜索:
- 使用一个哈希表 visited 存储所有已被访问和克隆的节点。哈希表中的 key 是原始图中的节点,value 是克隆图中的对应节点。
- 将题目给定的节点添加到队列。克隆该节点并存储到哈希表中。
- 每次从队列首部取出一个节点,遍历该节点的所有邻接点。如果某个邻接点已被访问,则该邻接点一定在 visited 中,那么从 visited 获得该邻接点,否则创建一个新的节点存储在 visited 中,并将邻接点添加到队列。将克隆的邻接点添加到克隆图对应节点的邻接表中。重复上述操作直到队列为空,则整个图遍历结束。
//深度优先搜索
class Solution_dfs {
public:
unordered_map<Node*, Node*> visited;
Node* cloneGraph(Node* node) {
if (node == nullptr) {
return node;
}
// 如果该节点已经被访问过了,则直接从哈希表中取出对应的克隆节点返回
if (visited.find(node) != visited.end()) {
return visited[node];
}
// 克隆节点,注意到为了深拷贝我们不会克隆它的邻居的列表
Node* cloneNode = new Node(node->val);
// 哈希表存储
visited[node] = cloneNode;
// 遍历该节点的邻居并更新克隆节点的邻居列表
for (auto& neighbor: node->neighbors) {
cloneNode->neighbors.emplace_back(cloneGraph(neighbor));
}
return cloneNode;
}
};
// 广度优先搜索
class Solution_bfs {
public Node cloneGraph(Node node) {
if (node == null) {
return node;
}
HashMap<Node, Node> visited = new HashMap();
// 将题目给定的节点添加到队列
LinkedList<Node> queue = new LinkedList<Node> ();
queue.add(node);
// 克隆第一个节点并存储到哈希表中
visited.put(node, new Node(node.val, new ArrayList()));
while (!queue.isEmpty()) {
// 取出队列的头节点
Node n = queue.remove();
// 遍历该节点的邻居
for (Node neighbor: n.neighbors) {
if (!visited.containsKey(neighbor)) {
// 如果没有被访问过,就克隆并存储在哈希表中
visited.put(neighbor, new Node(neighbor.val, new ArrayList()));
// 将邻居节点加入队列中
queue.add(neighbor);
}
// 更新当前节点的邻居列表
visited.get(n).neighbors.add(visited.get(neighbor));
}
}
return visited.get(node);
}
}
- 请写一个整数计算器,支持加减乘三种运算和括号。
分析:middle(nc137,lc224)
递归+栈:用栈保存各部分的值,整个表达式的值即为各部分的和
遍历表达式,使用 sign 变量记录运算符,初始化为 ‘+’;使用 number 变量记录字符串中的数字部分的数字值是多少
- 遇到空格时跳过
- 遇到数字时继续遍历求这个完整的数字的值,保存到 number 中
- 遇到左括号时递归求这个括号里面的表达式的值
- 先遍历找到对应的右括号,因为可能里面还嵌有多对括号,使用一个变量 counterPartition 统计括号对数直到变量为 0
- 遇到运算符时或者到表达式末尾时,就去计算上一个运算符并把计算结果 push 进栈,然后保存新的运算符到 sign
- 如果是 + ,不要计算,append 进去
- 如果是 - ,append 进去负的当前数
- 如果是 ×、÷ ,pop 出一个运算数和当前数作计算
- 最后把栈中的结果求和即可
双栈:对于「任何表达式」而言,我们都使用两个栈 nums 和 ops:
- nums : 存放所有的数字
- ops :存放所有的数字以外的操作
细节: 由于第一个数可能是负数,为了减少边界判断。一个小技巧是先往 nums 添加一个 0 为防止 () 内出现的首个字符为运算符,将所有的空格去掉,并将 (- 替换为 (0-,(+ 替换为 (0+(当然也可以不进行这样的预处理,将这个处理逻辑放到循环里去做)
然后从前往后做,对遍历到的字符做分情况讨论:
- 空格 : 跳过
- ( : 直接加入 ops 中,等待与之匹配的 )
- ) : 使用现有的 nums 和 ops 进行计算,直到遇到左边最近的一个左括号为止,计算结果放到 nums
- 数字 : 从当前位置开始继续往后取,将整一个连续数字整体取出,加入 nums
- + - * : 需要将操作放入 ops 中。在放入之前先把栈内可以算的都算掉(只有「栈内运算符」比「当前运算符」优先级高/同等,才进行运算),使用现有的 nums 和 ops 进行计算,直到没有操作或者遇到左括号,计算结果放到 nums
#
# 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
# 返回表达式的值
# @param s string字符串 待计算的表达式
# @return int整型
#递归+栈
class Solution:
def solve(self , s ):
partStack = [] #idea:用列表保存各部分的值,整个表达式的值即为各部分的和
sign = '+' #使用sign记录运算符
number = 0
i = 0
while i < len(s):
if s[i] in '0123456789':
number = number * 10 + ord(s[i]) - ord('0') #number记录字符串中的数字部分
if s[i] == '(': #遇到左括号时递归求这个括号里面的表达式的值
counterPartition = 1
j = i
while counterPartition > 0:
j += 1
if s[j] == '(':
counterPartition += 1
if s[j] == ')':
counterPartition -= 1 #先遍历找到对应的右括号,counterPartition统计括号对数直到变量为0
S = Solution()
number = S.solve(s[i+1:j]) #利用递归来化解括号带来的优先级问题
i = j #更新当前扫描到字符的索引
if (s[i] in '+-*') or (i == len(s) - 1): #遇到运算符时或者到表达式末尾时,就去计算上一个运算符并把计算结果push进栈
if sign == '+': #如果是当前sign为+,直接将当前number push 进去
partStack.append(number)
if sign == '-': #如果是-,push 进去-number
partStack.append(-number)
if sign == '*': #如果是 ×、÷ ,pop 出一个运算数和当前数作计算
partStack.append(partStack.pop() * number)
sign = s[i] #然后保存新的运算符到sign
number = 0 #并将number置零,即完成一个部分的计算
i += 1
return sum(partStack)
# write code here
//双栈
class Solution {
public:
void replace(string& s){
int pos = s.find(" ");
while (pos != -1) {
s.replace(pos, 1, "");
pos = s.find(" ");
}
}
int calculate(string s) {
// 存放所有的数字
stack<int> nums;
// 为了防止第一个数为负数,先往 nums 加个 0
nums.push(0);
// 将所有的空格去掉
replace(s);
// 存放所有的操作,包括 +/-
stack<char> ops;
int n = s.size();
for(int i = 0; i < n; i++) {
char c = s[i];
if(c == '(')
ops.push(c);
else if(c == ')') {
// 计算到最近一个左括号为止
while(!ops.empty()) {
char op = ops.top();
if(op != '(')
calc(nums, ops);
else {
ops.pop();
break;
}
}
}
else {
if(isdigit(c)) {
int cur_num = 0;
int j = i;
// 将从 i 位置开始后面的连续数字整体取出,加入 nums
while(j <n && isdigit(s[j]))
cur_num = cur_num*10 + (s[j++] - '0');
// 注意上面的计算一定要有括号,否则有可能会溢出
nums.push(cur_num);
i = j-1;
}
else {
if (i > 0 && (s[i - 1] == '(' || s[i - 1] == '+' || s[i - 1] == '-')) {
nums.push(0);
}
// 有一个新操作要入栈时,先把栈内可以算的都算了
while(!ops.empty() && ops.top() != '(')
calc(nums, ops);
ops.push(c);
}
}
}
while(!ops.empty())
calc(nums, ops);
return nums.top();
}
void calc(stack<int> &nums, stack<char> &ops) {
if(nums.size() < 2 || ops.empty())
return;
int b = nums.top(); nums.pop();
int a = nums.top(); nums.pop();
char op = ops.top(); ops.pop();
nums.push(op == '+' ? a+b : a-b);
}
};
- 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
分析:middle(lc15)
双指针:
- 特判,对于数组长度 n n n,如果数组为 n u l l null null 或者数组长度小于 3 3 3,返回 [ ] [~] [ ]。
- 对数组进行排序
- 遍历排序后数组:
- 若 n u m s [ i ] > 0 nums[i]>0 nums[i]>0:因为已经排序好,所以后面不可能有三个数加和等于 0 0 0,直接返回结果
- 对于重复元素:跳过,避免出现重复解
- 令左指针 L = i + 1 L=i+1 L=i+1,右指针 R = n − 1 R=n-1 R=n−1,当 L < R L< R L<R 时,执行循环:
- 当 n u m s [ i ] + n u m s [ L ] + n u m s [ R ] = 0 nums[i]+nums[L]+nums[R]=0 nums[i]+nums[L]+nums[R]=0,执行循环,判断左界和右界是否和下一位置重复,去除重复解。并同时将 L , R L,R L,R 移到下一位置,寻找新的解
- 若和大于 0 0 0,说明 n u m s [ R ] nums[R] nums[R] 太大, R R R 左移
- 若和小于 0 0 0,说明 n u m s [ L ] nums[L] nums[L] 太小, L L L 右移
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
nums.sort()
ans = list()
# 枚举 a
for first in range(n):
# 需要和上一次枚举的数不相同
if first > 0 and nums[first] == nums[first - 1]:
continue
# c 对应的指针初始指向数组的最右端
third = n - 1
target = -nums[first]
# 枚举 b
for second in range(first + 1, n):
# 需要和上一次枚举的数不相同
if second > first + 1 and nums[second] == nums[second - 1]:
continue
# 需要保证 b 的指针在 c 的指针的左侧
while second < third and nums[second] + nums[third] > target:
third -= 1
# 如果指针重合,随着 b 后续的增加
# 就不会有满足 a+b+c=0 并且 b<c 的 c 了,可以退出循环
if second == third:
break
if nums[second] + nums[third] == target:
ans.append([nums[first], nums[second], nums[third]])
return ans
- 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
分析:middle(lc213)
动态规划:假设数组 nums \textit{nums} nums 的长度为 n n n。如果不偷窃最后一间房屋,则偷窃房屋的下标范围是 [ 0 , n − 2 ] [0, n-2] [0,n−2];如果不偷窃第一间房屋,则偷窃房屋的下标范围是 [ 1 , n − 1 ] [1, n-1] [1,n−1],对于两段下标范围分别计算可以偷窃到的最高总金额,其中的最大值即为在 n n n 间房屋中可以偷窃到的最高总金额。
假设偷窃房屋的下标范围是 [ start , end ] [\textit{start},\textit{end}] [start,end],用 dp [ i ] \textit{dp}[i] dp[i] 表示在下标范围 [ start , i ] [\textit{start},i] [start,i] 内可以偷窃到的最高总金额,那么就有如下的状态转移方程:
d p [ i ] = m a x ( d p [ i − 2 ] + n u m s [ i ] , d p [ i − 1 ] ) dp[i]=max(dp[i−2]+nums[i],dp[i−1]) dp[i]=max(dp[i−2]+nums[i],dp[i−1])
边界条件为:
{ dp [ start ] = nums [ start ] 只 有 一 间 房 屋 , 则 偷 窃 该 房 屋 dp [ start + 1 ] = max ( nums [ start ] , nums [ start + 1 ] ) 只 有 两 间 房 屋 , 偷 窃 其 中 金 额 较 高 的 房 屋 \begin{cases} \textit{dp}[\textit{start}] = \textit{nums}[\textit{start}] & 只有一间房屋,则偷窃该房屋 \\ \textit{dp}[\textit{start}+1] = \max(\textit{nums}[\textit{start}], \textit{nums}[\textit{start}+1]) & 只有两间房屋,偷窃其中金额较高的房屋 \end{cases} {dp[start]=nums[start]dp[start+1]=max(nums[start],nums[start+1])只有一间房屋,则偷窃该房屋只有两间房屋,偷窃其中金额较高的房屋
计算得到 dp [ end ] \textit{dp}[\textit{end}] dp[end] 即为下标范围 [ start , end ] [\textit{start},\textit{end}] [start,end] 内可以偷窃到的最高总金额。
分别取 ( start , end ) = ( 0 , n − 2 ) (\textit{start},\textit{end})=(0,n-2) (start,end)=(0,n−2) 和 ( start , end ) = ( 1 , n − 1 ) (\textit{start},\textit{end})=(1,n-1) (start,end)=(1,n−1) 进行计算,取两个 dp [ end ] \textit{dp}[\textit{end}] dp[end] 中的最大值,即可得到最终结果。
class Solution {
public:
int robRange(vector<int>& nums, int start, int end) {
int first = nums[start], second = max(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++) {
int temp = second;
second = max(first + nums[i], second);
first = temp;
}
return second;
}
int rob(vector<int>& nums) {
int length = nums.size();
if (length == 1) {
return nums[0];
} else if (length == 2) {
return max(nums[0], nums[1]);
}
return max(robRange(nums, 0, length - 2), robRange(nums, 1, length - 1));
}
};
二、八股文
1.lr特征为什么要离散化 (1, 2, 3)
2. 神经网络如何评估特征有效性和重要性(1)
3. 编译分为哪些步骤,宏定义是在哪个阶段处理的(1, 2, 3)
4. c++ vector 的底层是什么(1, 2, 3)
5. GAUC,AUC和F1适用场景(1, 2, 3, 4)
三、其他
待解决 (欢迎评论区或私信解答)
-
给出一个有序数组A和一个常数C,求所有长度为C的子序列中的最大的间距D。
一个数组的间距的定义:所有相邻两个元素中,后一个元素减去前一个元素的差值的最小值. 比如[1,4,6,9]的间距是2.
例子:A:[1,3,6,10], C:3。最大间距D应该是4,对应的一个子序列可以是[1,6,10]。 -
给定一个数字矩阵和一个数字target,比如5。从数字1开始(矩阵中可能有多个1),每次可以向上下左右选择一个方向移动一次,可以移动的条件是下个数字必须是上个数字+1,比如1必须找上下左右为2的点,2必须找上下左右为3的点,以此类推。求到达target一共有几个路径。
-
给定一个只包含0和1的字符串,判断其中有无连续的1。若有,则输出比该串大的无连续1的最小值串。若无,则不做操作
例:给定 ‘11011’ ,则输出 ‘100000’ ;给定 ‘10011’ ,则输出 ‘10100’
(参考:感觉有点像字符串匹配,只要第一次匹配到’011’模式串就改成’100’,然后后面全部置0,仅供参考) -
给定两个字符串 target 和 block,对bolck进行子串选取,选取出的子串可对target进行重构。问最少需要选取多少block子串进行重构。(子串须保持相对顺序,但不要求连续)
例:(1)target = ‘aaa’ ,block = ‘ab’ ,输出为3。即分别选取block子串中的 ‘a’、 ‘a’、 ‘a’;(2)target = ‘abcd’ ,block = ‘bcad’ ,输出为2。即分别选取子串 ‘a’、‘bcd’
(参考:双指针 i,j 分别遍历target和block,j会回溯。时间复杂度是len(target)*len(block)) -
给定一个由二元组组成的列表,分别代表分数和类别,给定一个k,要求按分数从大到小输出,同时满足类别不能连续k个相同。
输入:[(1,1),(2,2),(3,3),(4,3)],k = 2
输出:[(4,3),(2,2),(3,3),(1,1)]
解释:原始数组排序后必须满足类别不能连续k个一样的条件,因此 [(4,3),(3,3),(2,2),(1,1)] -> (4,3),(2,2),(3,3),(1,1)]














 2856
2856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









