







- 王树森老师《深度强化学习基础》学习笔记
一、前提知识:
深度学习基础
- 搭神经网络、求导…
概率论
-
随机变量(Random Variable):
- 一个未知变量,值只取决于一个随机事件的结果(Eg:抛硬币的结果)。
- 用 X X X 表示随机变量, x x x表示观测值 (单纯的数,没有随机性)。
-
概率密度函数(Probability Density Function, PDF):
- 随机变量在某个确定的取值点附近的可能性。
- Eg:高斯分布

- 性质:积分(连续)或者加和(离散)值为1。

-
期望(Expectation):

-
随机抽样(Random Sampling)
专业术语
-
State(状态)和 Action(动作),动作的主体为 Agent(智能体)。
-
Policy(策略)
- 根据观测到的state(状态)做出policy(决策),控制Agent(智能体)运动。
- 数学表述:

- 强化学习主要就是学习这个 policy函数。
-
Reward(奖励)
- 对Agent做出的Action的评价。
- 强化学习的目标:获得的Reward尽可能的高。
-
state transition(状态转移)
- 做出Action导致进入新的State。
- 状态转移可以是随机的(通常),随机性来自环境。
- 数学表述:
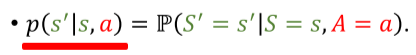
-
智能体与环境的交互


强化学习中的两个随机性
-
Actions有随机性。
- 智能体的动作(Actions)是根据policy函数 随机抽样 得来的。

- 智能体的动作(Actions)是根据policy函数 随机抽样 得来的。
-
状态转移有随机性。
- Agent做出动作后,环境生成的下一个状态S‘具有随机性。
- 环境用状态转移函数p算出概率,然后用概率 随机抽样 来得到下一个状态S’。

如何用AI打游戏
- 根据状态 S t S_t St, 选择动作 a t π ( ⋅ ∣ s t ) a_t~\pi(\cdot|s_t) at π(⋅∣st)执行.
- 环境给一个新的状态 s t + 1 s_{t+1} st+1和反馈 r t r_t rt.
- 循环…
- 通过Reward不断修正policy

奖励和回报(Rewards and Returns)
-
Return (cumulative future reward)是 未来所有奖励的总和 , 数学定义(由于普遍未来的奖励没有现在的奖励值钱,所以普遍使用 Discounted Return.):

-
Returns中的随机性
Return U t U_t Ut的随机性来源是未来所有的动作和状态.

价值函数(Value Functions)
动作价值函数
-
U t U_t Ut是个***随机变量***,在 t t t时刻其并不能确定,依赖于未来所有的动作( A t , A t + 1 , A t + 2 , . . . A_t, A_{t+1}, A_{t+2}, ... At,At+1,At+2,...)和状态( S t , S t + 1 , S t + 2 , . . . S_t, S_{t+1}, S_{t+2}, ... St,St+1,St+2,...).
-
对随机变量 U t U_t Ut求期望, 得到一个数, 记作 Q π Q_{\pi} Qπ, 动作价值函数. 只与当前的状态 s t s_t st和动作 a t a_t at有关, 因为未来的状态和动作都被积分积掉了, 而 s t s_t st和 a t a_t at是观测到的值而不是随机变量. Q π Q_{\pi} Qπ还与policy函数有关(积分时会用到).
-
Q π Q_{\pi} Qπ意义: Q π Q_{\pi} Qπ告诉我们如果用policy函数 π \pi π 在 s t s_t st 状态下做动作 a t a_t at 是好还是坏
-
最优动作价值函数 Q ∗ Q^* Q∗: 与 π \pi π无关, 找的是能使 Q π Q_{\pi} Qπ 最大的 π \pi π.

-
Q ∗ ( s t , a t ) Q^*(s_t, a_t) Q∗(st,at)意义: 对动作 a a a 做评价, 假如有了 Q ∗ ( s t , a t ) Q^*(s_t, a_t) Q∗(st,at), Agent就可以根据对动作的评价做决策.
状态价值函数
-
是 Q π 的 期 望 , 把 动 作 Q_{\pi}的期望, 把动作 Qπ的期望,把动作A 作 为 随 机 变 量 . 关 于 作为随机变量. 关于 作为随机变量.关于A 求 期 望 把 求期望把 求期望把A 消 掉 . , 所 以 消掉., 所以 消掉.,所以V_\pi 只 与 只与 只与\pi 和 和 和s$有关.
-
作用: 告诉我们当前的局势好不好.


-
总结: 两中 Value Functions

如何用AI打游戏
-
学习 π \pi π函数(策略学习)或者 Q ∗ Q^* Q∗函数(价值学习)。
-
策略学习

-
价值学习

-
-
强化学习最常用标准库:OpenAI Gym
- 控制问题
- 小游戏
- 连续控制问题















 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









