









密集文本检索的无监督语料库感知语言模型预训练
ACL2022 论文链接
摘要
最近的研究证明了使用微调语言模型(LM)进行密集检索的有效性。然而,密集检索器很难训练,通常需要经过精心设计的微调管道才能充分发挥其潜力。在本文中,我们识别并解决了密集检索器的两个潜在问题:i)对训练数据噪声的脆弱性,ii)需要大批量来鲁棒地学习嵌入空间。我们使用最近提出的冷凝器预训练架构,该架构通过LM预训练学习将信息浓缩到密集向量中。在此基础上,我们提出了coCon冷凝器,它增加了一个无监督的语料库级对比损失,以预热文章嵌入空间。在MS-MARCO、Natural Question和Trivia QA数据集上进行的实验表明,CoConductor消除了对诸如增强、合成或过滤等重数据工程的需求,也消除了对大批量训练的需求。它显示出与RocketQA相当的性能,RocketQA是一个先进的、经过大量工程设计的系统,使用简单的小批量微调。
引言
基于预训练语言模型的进步(LM;Devlin等人(2019);Liu等人。
(2019)),稠密检索已成为文本检索的有效范式(Lee等人,2019;Chang等人,2020;Karpukhin等,2020;Qu等人,2021;Gao等人,2021a;Zhang等人,2022)。然而,最近的研究发现,微调密集检索器以实现其容量需要精心设计的微调技术。早期的工作包括迭代负挖掘(Xiong等人,2021)和多向量表示(Luan等人,2020)。最近的RocketQA系统(Qu等人,2021)通过设计优化微调管道,显著提高了密集型检索器的性能,其中优化的包括i)去噪硬负片,纠正标签错误,以及ii)大批量训练。虽然这非常有效,但整个管道的计算量非常大,对于那些没有大量硬件资源的人来说是不可行的,比如学术界的人。在本文中,我们问,我们是否可以利用RocketQA的见解来执行语言模型预训练,而不是直接使用管道,以便可以在任何目标查询集上轻松地微调预训练的模型。
具体来说,我们问RocketQA中的优化训练解决了什么问题。我们假设,典型的LMs对错误标记很敏感,这可能会导致模型权重的有害更新。去噪可以有效地去除坏样本及其更新。另一方面,对于大多数LMs,CLS向量要么通过简单任务训练(Devlin等人,2019),要么根本没有明确训练(Liu等人,2019年)。这些向量远不能形成段落的嵌入空间(Lee等人,2019)。RocketQA中的大批量训练有助于LM稳定地学习以形成完整的嵌入空间。为此,我们希望对LM进行预训练,使其具有局部抗噪声性,并具有良好结构的全局嵌入空间。为了抗噪声,我们借用了冷凝器预训练架构(Gao和Callan,2021),该架构对CLS向量进行主动预训练。它产生了一种信息丰富的CLS表示,可以鲁棒地压缩输入序列。然后,我们引入了一个简单的语料库级对比学习目标:给定要从中检索的目标文档语料库,在每个训练步骤中,从一批文档中抽取文本跨度对样本,并对模型进行训练,以使来自同一文档的两个跨度的CLS嵌入接近,而来自不同文档的跨度相距较远。结合这两种方法,我们提出了coConductor预训练,它无监督地学习用于密集检索的语料库感知预训练模型。
本文框架
虽然冷凝器可以在不同的语料库集合上进行训练,以生成通用模型,但它无法解决嵌入空间问题:虽然嵌入CLS中的信息可以由头部非线性解释,但这些向量之间的内积仍然缺乏语义。因此,它们没有形成有效的嵌入空间。为此,我们用对比损失来增加冷凝器MLM损失。与先前在人工查询通道对上进行预训练的工作不同,在本文中,我们建议使用在目标搜索语料库上定义的对比损失,以查询不可知的方式简单地预训练通道嵌入空间。具体地,给定n个文档的随机列表[d1,d2,…,dn],我们从每个文档中随机抽取一对跨度[s11,s12,…,sn1,sn2]。然后,这些跨度形成了一个co冷凝器的训练批次。给定跨度sij对应的后期CLS表示hij,其语料库感知对比损失在批次中定义如下。
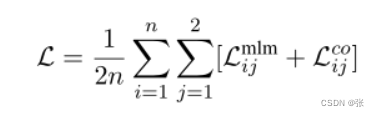
预训练
RocketQA管道使用监督和大批量培训来学习嵌入空间。我们还希望运行大批量无监督预训练,以构建方程6中对比损失的有效随机梯度估计。为了提醒我们的读者,这一大批量预训练只针对目标搜索语料库进行一次。我们将展示这允许对任务查询集进行有效的小批量微调。
然而,由于对比损失的逐批依赖性,它需要将大批量装入GPU(加速器)内存。虽然这可以通过互连的GPU节点或TPU吊舱(可以有数千GB的内存)天真地实现,但学术界和小型组织通常仅限于具有2845个四个商用GPU的机器。为了打破记忆限制并执行有效的对比学习,我们调整了梯度缓存技术(Gao等人,2021b)。我们在这里为那些希望进行coConductor预培训但资源有限的人描述了该程序。表示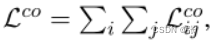 将第一个公式写成
将第一个公式写成
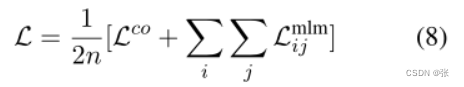
梯度缓存的精神是将表示梯度和编码器梯度计算解耦。在计算模型权重更新之前,我们首先为整个批次运行一个额外的主干。这提供了[h11,h12,……,hn1,hn2]的数值,我们从中计算:
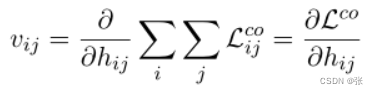
相对于CLS矢量的对比损失梯度。我们将所有这些向量存储在梯度缓存中,C=[v11,v12,…,vn1,vn2]。使用vij表示模型参数Θ,我们可以写出对比损失的导数,如下所示。
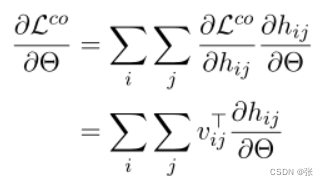
然后我们可以写出方程8的梯度。
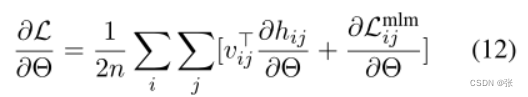
由于vij已经在缓存C中,所以每个求和项现在只涉及跨度sij及其激活,这意味着我们可以在小的子批次上以累加的方式计算整个批次的梯度。换句话说,整个批处理不再需要同时驻留在GPU上。
微调
在预训练结束时,我们丢弃冷凝器头部,只保留主干层。因此,该模型简化为其主干,或有效地简化为变压器编码器。我们使用主干权重来初始化查询编码器fq和通道编码器fp。每个都输出最后一层CLS。回想一下,他们已经在预训中热身了。(查询q,段落p)对相似性被定义为内积。
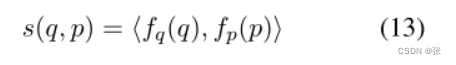
查询和通道编码器根据目标任务的训练集进行监督微调。我们使用监督对比损失进行训练,并计算查询q,正文档d+相对于一组负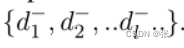
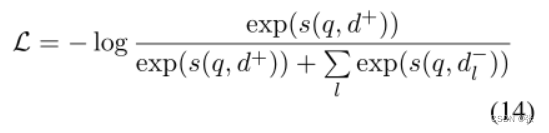
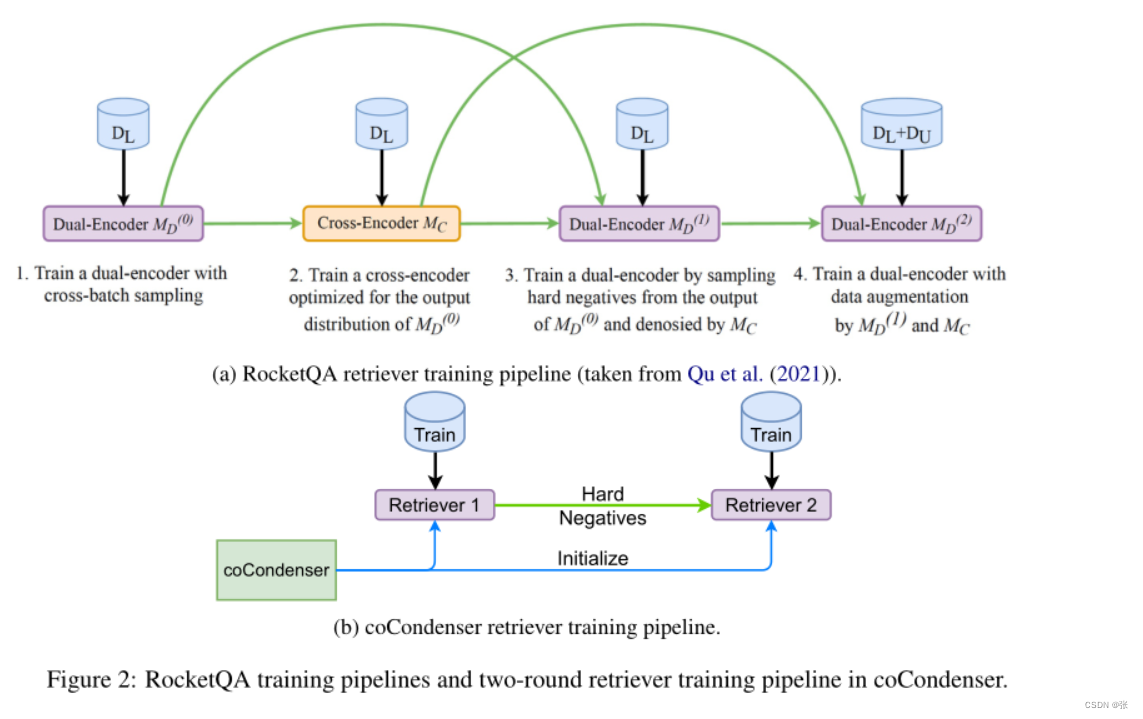
我们按照DPR(Karpukhin等人,2020)工具包中的描述进行了两阶段培训。如图2b所示,在第一阶段,用BM25底片训练寻回犬。第一阶段检索器随后用于挖掘硬负片,以补充负片池。第二阶段检索器使用第一轮生成的负池进行训练。这与图2a所示的RocketQA多级管道形成对比。
总结
本文介绍了一种无监督的语料库感知语言模型预训练方法coConductor。我们证明,适当的预训练不仅可以建立语言理解能力,而且可以建立语料库水平的表达能力。利用冷凝器结构和语料库感知对比损失,coCon冷凝器获得了密集检索的两个重要属性:抗噪声性和结构化嵌入空间。这种语料库感知预训练需要对搜索语料库进行一次,并且是查询不可知的。学习的模型可以在各种类型的最终任务查询之间共享。
实验表明,co冷凝器可以大幅降低微调强密度检索器的成本。我们还发现,co冷凝器的性能接近或类似于几倍大的半监督预训练模型。
重要的是,coConductor为密集检索提供了一种不受干扰的方式来预训练非常有效的LM。特别是,它有效地消除了设计和测试预训练以及微调技术的工作量。使用我们的模型,从业者可以使用有限的资源来训练具有最先进性能的密集检索系统。未来的工作还可以研究整合额外的预训练和/或微调方法,以进一步提高性能。















 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









