









训练密集通道检索器所需要的问题
arxiv 2022 论文链接
摘要
我们介绍了ART,这是一种新的语料库级自动编码方法,用于训练不需要任何标记训练数据的密集检索模型。密集检索是开放领域任务(如open QA)的核心挑战,其中最先进的方法通常需要具有自定义硬负采样和正样本去噪的大型监督数据集。相反,ART只需要访问未配对的输入和输出(例如问题和潜在答案文件)。它使用一种新的文档检索自动编码方案,其中(1)使用输入问题来检索一组证据文档,(2)然后使用文档来计算重构原始问题的概率。基于问题重构的检索训练可以实现文档和问题编码器的有效无监督学习,之后可以将其整合到完整的开放式QA系统中,而无需进一步微调。广泛的实验表明,ART在多个QA检索基准上获得了最先进的结果,只需从预训练的语言模型中进行一般初始化,就不需要标记数据和任务特定损失。
引言
密集文档检索方法(Karpukhin等人,2020年;Xiong等人,2021),使用BERT等编码器进行初始化(Devlin等人,2019年),并使用监督对比损失进行训练(Oord等人,2018年),已经超过了以前流行的基于关键字的方法(如BM25)的性能(Robertson和Zaragoza,2009年)。此类检索器是开放领域任务模型的核心组件,如开放QA,其中最先进的方法通常需要具有自定义功能的大型监督数据集硬负采样和正样本的去噪。在本文中,我们介绍了第一种基于新的语料库级自动编码方法的无监督方法,该方法可以在没有标记的训练数据或任务特定损失的情况下匹配或超过强监督性能水平。
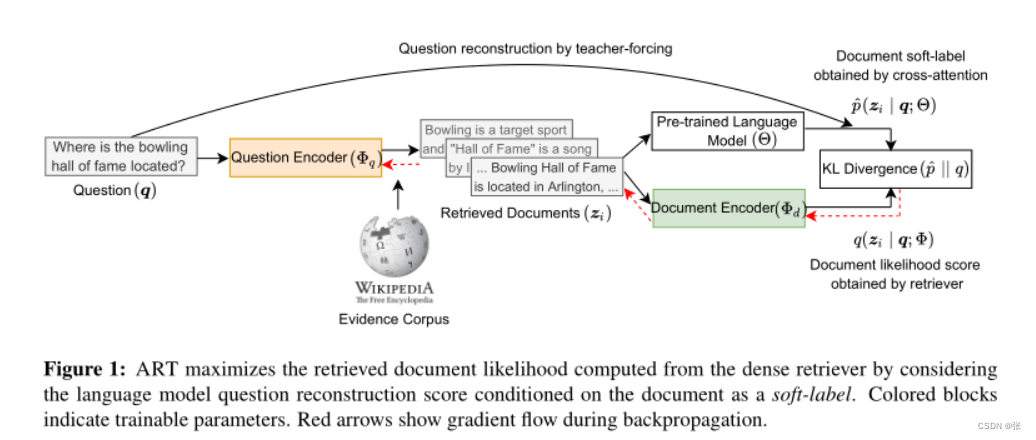
我们提出了ART:基于自动编码的检索器训练,它只假设访问未配对的问题和文档集。给定一个输入问题,ART首先检索一小组可能的证据文件。然后,它通过关注这些文档来重构原始问题(请参见图1中的概述)。ART中的关键思想是将检索到的文档视为原始问题的有噪声表示,并将问题重建概率视为一种去噪方法,为每个文档获得正确结果的可能性提供软标签。
为了引导强模型的训练,重要的是要有一个强大的初始检索模型,并且能够在以(检索的)文档为条件时计算问题重建概率的可靠初始估计。尽管BERT风格模型的文档表示被认为是合理的检索基线,但如何进行零射击问题生成还不太清楚。我们使用生成的预训练语言模型(PLM),并以文档作为输入提示它,以使用教师强制生成问题标记。由于不需要对问题生成PLM进行微调,只需要检索模型,ART可以使用大型PLM,并获得哪些文档可能是最高质量的准确软标签估计。
检索器被训练以惩罚文档可能性与其软标签得分的差异。例如,如果问题是“保龄球名人堂在哪里?”如图1所示,那么训练过程将提高文档“保龄球名人堂位于阿灵顿”的检索率,因为它是相关的,并将导致更高的问题重建可能性,而文档“名人堂是……的歌曲”的可能性将受到惩罚,因为它不相关。以这种方式,训练过程鼓励正确的检索结果,反之亦然,从而导致文档检索的迭代改进。
在五个基准QA数据集上的综合实验证明了我们提出的训练方法的有用性。通过简单地使用训练集中的问题,ART在前20名中的平均绝对值为5分,在前100名中的绝对值为4分,优于DPR等模型。我们还使用NaturalQuestions(NQ)数据集中包含的所有问题进行了训练(Kwiatkowski等人,2019),并发现即使混合了可回答和无法回答的问题,ART也在非分布数据集上实现了强大的零镜头泛化。我们的分析进一步表明,ART具有很高的样本效率,在NQOpen数据集上仅用100个问题和1000个问题就超过了BM25和DPR,并且扩展到更大的检索器模型始终可以提高性能。
方法
问题定义
我们专注于开放域检索,在给定问题q的情况下,任务是从大量证据文档集合D={d1,…,dm}中选择一小组匹配文档(即20或100)。我们的目标是以零射击的方式训练寻回器,即不使用问答对,从而检索相关文档来回答问题。我们提出的方法包括两个核心建模组件(§2.2、§2.3)和一种新的训练方法(§2.4)。
双编码检索器
对于检索器,我们使用双编码器模型(Bromley等人,1994),该模型由两个编码器组成,其中
•一个编码器计算问题嵌入fq(q;Φq):X → Rd,并且
•另一个编码器计算文档嵌入fd(d;Φd):X → Rd。
这里,X=Vn表示文本序列的通用集合,V表示由离散标记组成的词汇表,Rd表示(潜在)嵌入空间。我们假设问题和文档嵌入都位于同一潜在空间中。然后将问题文档对(q,d)的检索分数定义为它们各自嵌入之间的内积
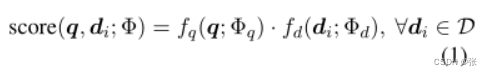
其中Φ=[Φq,Φd]表示检索器参数。我们选择具有最大内积分数的前K个文档,并将它们表示为Z={z1,…,zK}。
我们使用变压器网络(V aswani等人,2017)和BERT标记化(Devlin等人,2019)对两个编码器进行建模。为了获得问题或文档嵌入,我们通过转换器进行前向传递,并选择对应于[CLS]令牌的最后一层隐藏状态。作为输入文档表示,我们使用由[SEP]标记分隔的文档标题和文本。
零射击交叉注意力记分器
我们通过使用预先训练的语言模型(PLM)来获得问题-(检索的)文档对(q,z)的相关性得分的估计。为了以零镜头的方式实现这一点,我们使用大型生成PLM来计算以问题p(z|q)为条件的文档的可能性得分。
数量p(z|q)可以通过以文档和教师强制为条件的问题令牌的自回归生成来更好地近似(Sachan等人,2022)。更正式地说,这可以写成
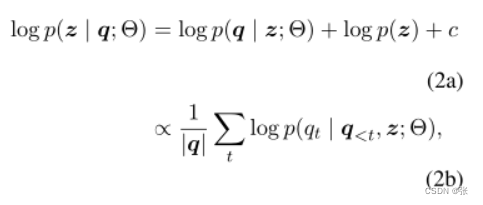
其中Θ表示PLM的参数,c是独立于文档z的常数,|q|表示问题令牌的数量。这里,等式2a来自贝叶斯的简单应用规则p(z|q),并假设公式2b中的文件优先于p(z)对于所有z是一致的∈ Z。
我们假设使用公式2b计算相关性得分将是准确的,因为它需要执行涉及所有问题和文档标记的深度交叉关注。在大型PLM中,交叉注意力步骤是高度表达的,结合教师强制,需要模型解释问题中的每一个标记,从而获得更好的估计。
作为输入文档表示,我们连接文档标题及其文本。为了提示PLM生成问题,我们遵循(Sachan等人,2022),并在文档文本中添加了一条简单的自然语言指令“请根据这篇文章写一个问题”。
ART作为自动编码器
由于我们的编码器将问题q作为输入,并且PLM在计算相关性分数时对同一问题进行评分(或重构),因此我们可以将我们的训练算法视为自动编码器,将检索到的文档作为潜在变量。
在生成过程中,我们从观察变量D(证据文件的收集)开始,这是我们潜在变量的支持集。给定输入q,我们生成索引i并检索文档zi。此索引生成和检索过程由我们的双编码器架构建模。给定zi,我们使用PLM将其解码回问题。
回想一下,我们的解码器(PLM)被冻结,其参数没有更新。然而,来自解码器输出的信号用于训练双编码器的参数,使得重建问题q的对数似然最大化。在实践中,这改进了双编码器为给定问题选择最佳文档,因为最大化目标的唯一方法是在给定输入q的情况下选择最相关的zi。
总结
我们引入了ART,这是一种只使用问题训练密集通道检索器的新方法。ART不需要问题文档对或硬负样本示例进行训练,但仍能取得最先进的结果。使ART工作的关键是优化检索器,以选择相关文档,从而在这些文档上,使用大型预训练语言模型计算的问题生成可能性迭代地提高。尽管需要更少的监督,但ART在多个QA数据集上进行评估时显著优于DPR,并且在分发外问题上也有更好的概括。ART为未来的工作提出了几个方向。将这种方法应用于低资源检索,包括多语言检索(Clark等人,2020年)和跨语言问答(Asai等人,2021)。我们的训练框架还可以扩展到训练跨模态检索器,例如使用文本查询进行图像或代码搜索(Li等人,2022;Neelakantan等人,2022)。最后,另一个值得探索的方向是用这种方法训练多向量检索器。














 1648
1648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









