







KMP模式匹配算法
4.KMP模式匹配算法改进
后来有人发现,KMP还是有缺陷的。比如,如果我们的主串S=“aaaabcde”,子串T=“aaaaax”,其next数组值分别为012345,在开始时,当i=5、j=5时,我们发现“b”与“a”不相等,如图5-7-6的①,因此j=next[5]=4,如图中的②,此时“b”与第4位置的“a”依然不等,j=next[4]=3,如图中的③,后依次是④⑤,直到j=next[1]=0时,根据算法,此时i++、j++,得到i=6、j=1,如图中的⑥。
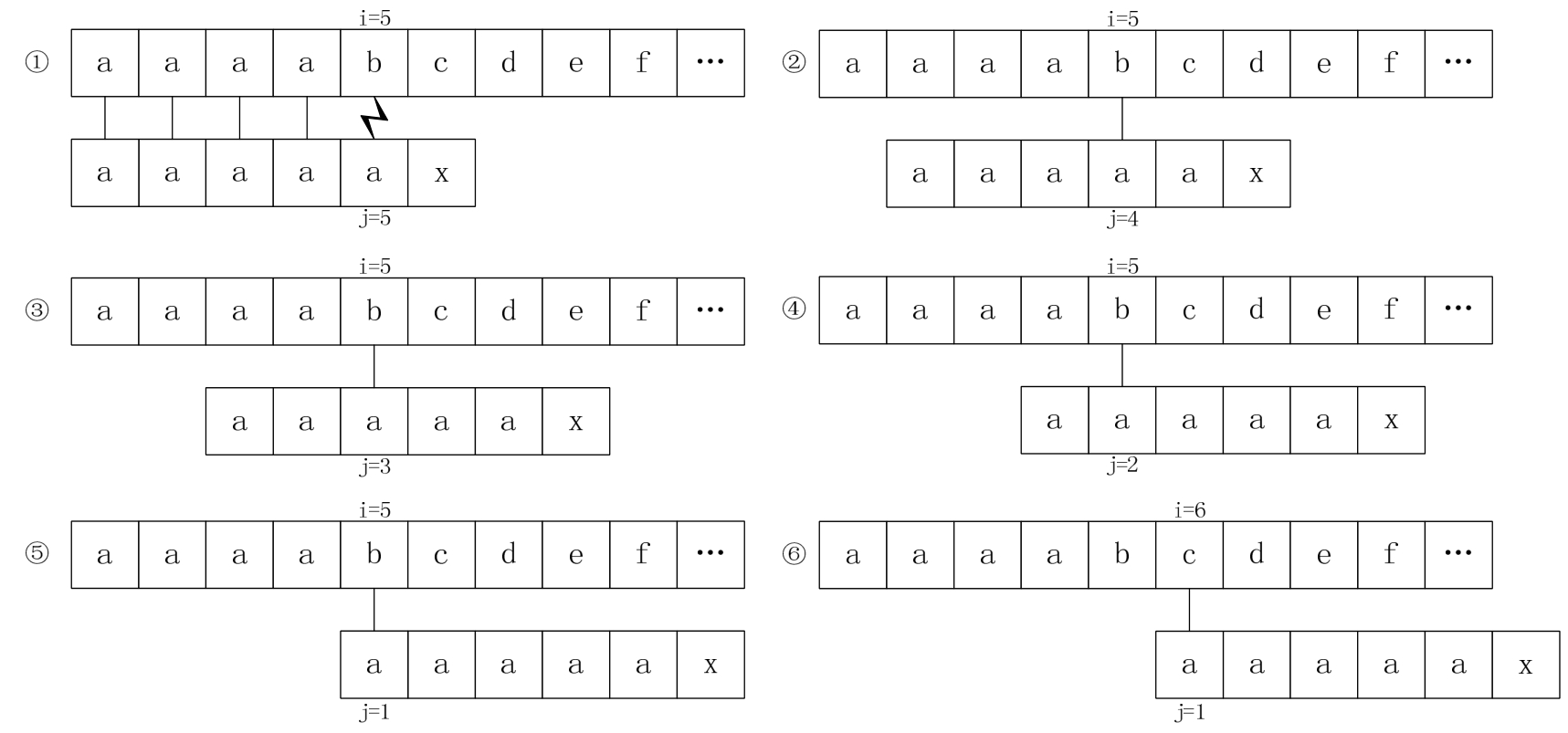 我们发现,当中的②③④⑤步骤,其实是多余的判断。由于T串的第二、三、四、五位置的字符都与首位的“a”相等,那么可以用首位next[1]的值去取代与它相等的字符后续next[j]的值,这是个很好的办法。因此我们对求next函数进行了改良。
我们发现,当中的②③④⑤步骤,其实是多余的判断。由于T串的第二、三、四、五位置的字符都与首位的“a”相等,那么可以用首位next[1]的值去取代与它相等的字符后续next[j]的值,这是个很好的办法。因此我们对求next函数进行了改良。
假设取代的数组为nextval,增加了加粗部分,代码如下:

实际匹配算法,只需要将“get_next(T, next);”改为“get_nextval(T,next);”即可,这里不再重复。
5.nextval数组值推导
改良后,我们之前的例子nextval值就与next值不完全相同了。比如:
1.T=“ababaaaba”(如表5-7-5所示)
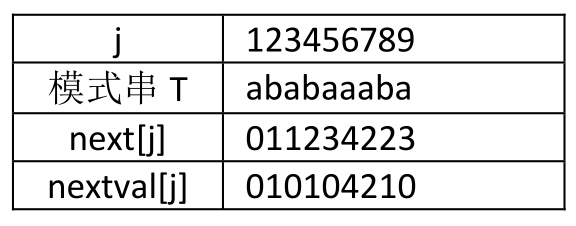
先算出next数组的值分别为001234223,然后再分别判断。
1)当j=1时,nextval[1]=0;
2)当j=2时,因第二位字符“b”的next值是1,而第一位就是“a”,它们不相等,所以nextval[2]=next[2]=1,维持原值。
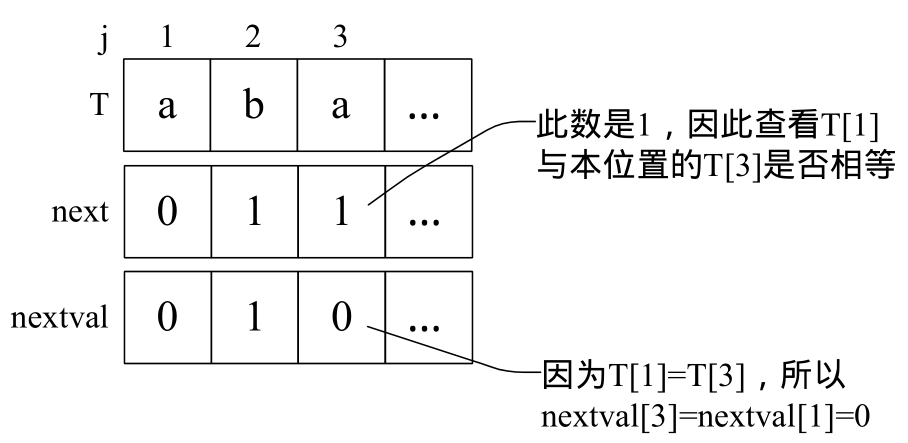
3)当j=3时,因为第三位字符“a”的next值为1,所以与第一位的“a”比较得知它们相等,所以nextval[3]=nextval[1]=0;如图5-7-7所示。
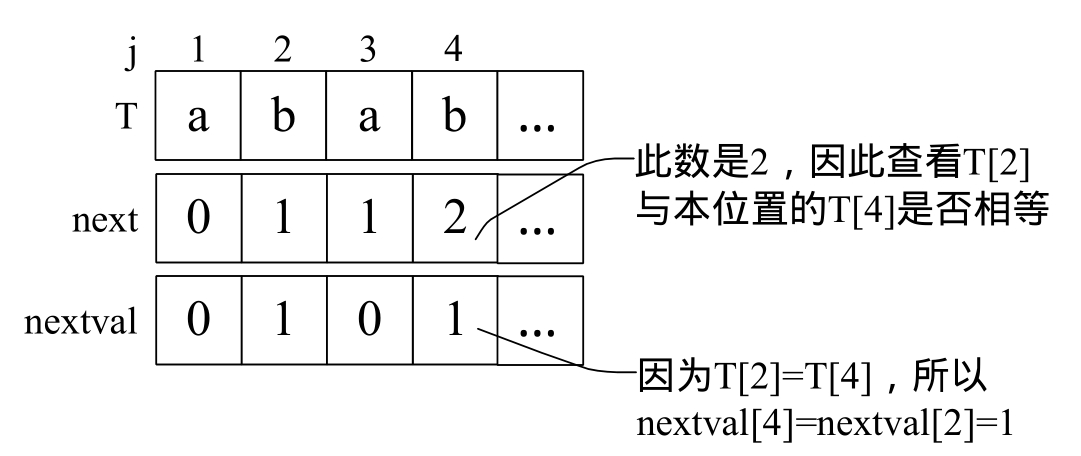
4)当j=4时,第四位的字符“b”next值为2,所以与第二位的“b”相比较得到结果是相等,因此nextval[4]=nextval[2]=1;如图5-7-8所示。
5)当j=5时,next值为3,第五个字符“a”与第三个字符“a”相等,因此nextval[5]=nextval[3]=0;
6)当j=6时,next值为4,第六个字符“a”与第四个字符“b”不相等,因此nextval[6]=4;
7)当j=7时,next值为2,第七个字符“a”与第二个字符“b”不相等,因此nextval[7]=2;
8)当j=8时,next值为2,第八个字符“b”与第二个字符“b”相等,因此nextval[8]=nextval[2]=1;
9)当j=9时,next值为3,第九个字符“a”与第三个字符“a”相等,因此nextval[9]=nextval[3]=1。
2. T=“aaaaaaaab”(如表5-7-6)

先算出next数组的值分别为012345678,然后再分别判断。
1)当j=1时,nextval[1]=0;
2)当j=2时,next值为1,第二个字符与第一个字符相等,所以nextval[2]=nextval[1]=0;
3)同样的道理,其后都为0……;
4)当j=9时,next值为8,第九个字符“b”与第八个字符“a”不相等,所以nextval[9]=8。
总结改进过的KMP算法,它是在计算出next值的同时,如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next的值。
总结回顾
这一章节我们重点讲了“串”这样的数据结构,串(string)是由零个或多个字符组成的有限序列,又名叫字符串。本质上,它是一种线性表的扩展,但相对于线性表关注一个个元素来说,我们对串这种结构更多的是关注它子串的应用问题,如查找、替换等操作。现在的高级语言都有针对串的函数可以调用。我们在使用这些函数的时候,同时也应该要理解它当中的原理,以便于在碰到复杂的问题时,可以更加灵活的使用,比如KMP模式匹配算法的学习,就是更有效地去理解index函数当中的实现细节。多用心一点,说不定有一天,可以有以你的名字命名的算法流传于后世。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











