







前言
本来只是想学习 React-Router v6 ,没有想到,带出了这么多东西。前后端路由有什么区别?SPA与MPA的是什么?在了解到前端路之后又发现单页面于应用与多页面应用的不同之处,以及 .nextjs 数据抓取选择CSR、SSR、SSG、ISP不同形式也是有区别的。
lesson1-前端路由介绍
- 路由来源
路由这个概念最早出现在后端,在服务端中路由描述的是 URL 与处理函数之间的映射关系。对于服务器来说,当接收到客户端发来的HTTP请求,就会根据所请求的相应URL,来找到相应的映射函数,然后执行该函数,并将函数的返回值发送给客户端。(该过程又称之为后端路由或 服务端路由)
大致流程如图所示:
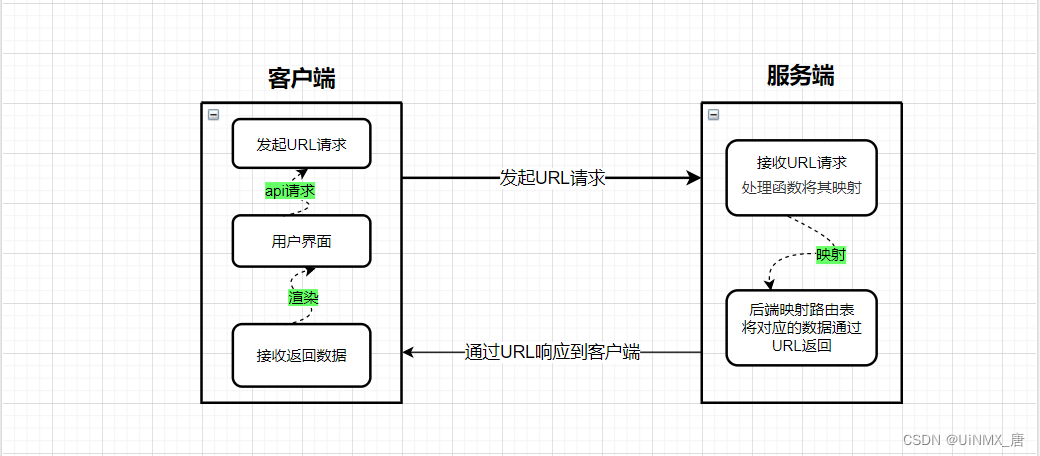
早期前端路由主要呈现的是多页面应用(MPA)的形式,每个HTML界面通过自己独有的URL,向服务端发起请求。这导致用户每发起一次不同的请求,服务器就要解析不同的URL,切换资源加载慢影响用户体验。
而随着前后端的分离,AJAX的出现带来了无刷新加载的优势。现在的前端路由不同于传统路由,它不在需要服务器解析,而是通过 Hash 函数或者 History API 来实现。在前端开发中,我们可以使用路由设置访问路径,并根据路径与组件的映射关系切换不同的组件,而这个过程都是在同一个页面中实现的,不涉及HTML页面之间的跳转,这也就是我们常说的单页应用(SPA)。
AJAX工作大致流程如图所示:
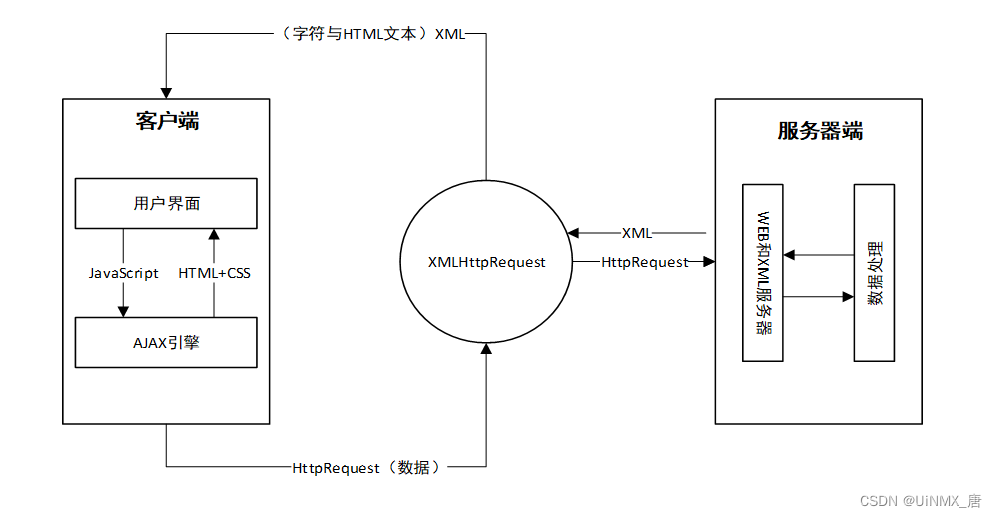
- 前后端路由的明显区别
前端路由:不向后台发送请求,不刷新页面,前后端分离( 无刷新加载 )
后端路由:向服务器发送请求,会刷新页面,前后端不能分离( 需要刷新加载 )
lesson2-简述SPA与MPA
- 单页面应用与多页面应用模板对比图
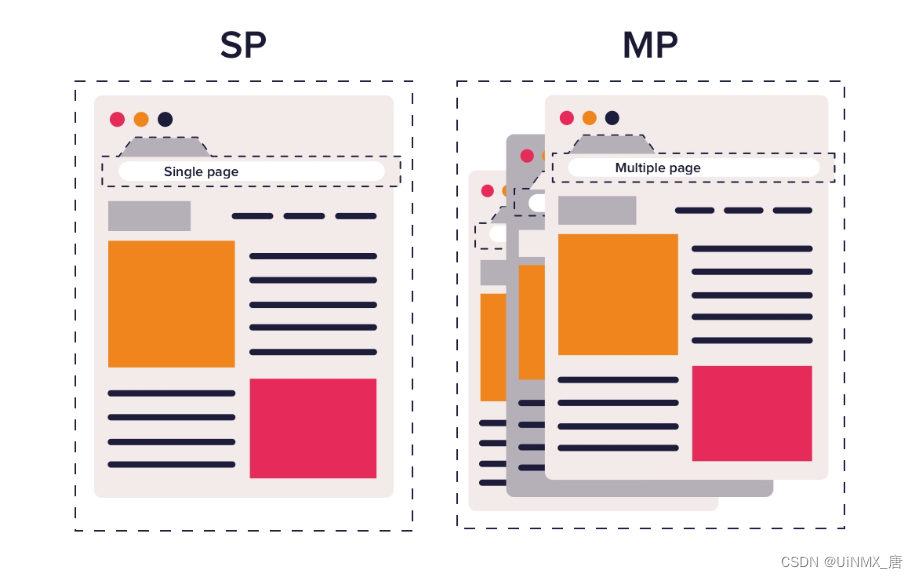
SPA 是什么?
SPA全称(single-page application),翻译过来就是单页应用。
单页应用(SPA):它是一种特殊的web应用。将所有的活动局限于一个Web页面中,仅在该Web页面初始化时加载相应的HTML、JavaScript和CSS。 一旦页面加载完成,SPA不会因为用户的操作而进行页面的重新加载或跳转。取而代之的是利用JavaScript动态的变换HTML的内容, 从而实现UI与用户的交互。(该过程就类似我们常说的客户端渲染,又称 CSR )
大致CSR 流程图
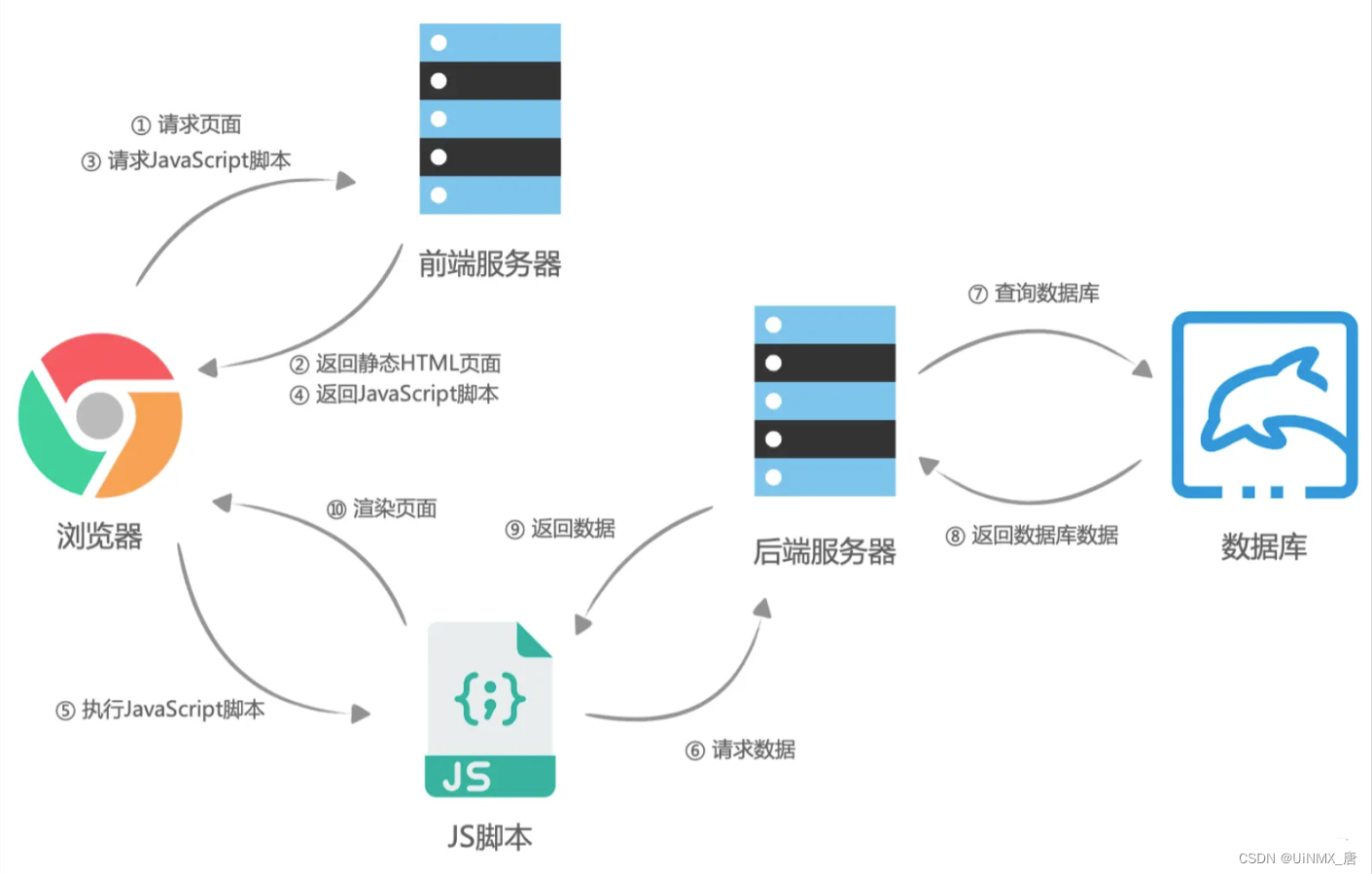
相对于MPA而言SPA的优缺点是什么?
SPA.优点:
- 不涉及html页面跳转,内容改变不需要重新加载页面,可减小服务器压力。
- 只涉及组件之间的切换,因此跳转顺畅,用户体验好。
- 组件开发更便捷,页面效果更好更炫酷(比如组件切换时的转场动画)。
SPA.缺点:
- 单页资源庞大,导致首屏(首页)加载过慢。【面试题-如何解决首屏加载过慢】
- 不利于搜索引擎优化(SEO)
- 页面复杂度提高,防护数据端点要求更高。更容易受到黑客攻击,因为它们运行在JavaScript上,而JavaScript不执行代码编译,因此更容易受到恶意软件的攻击。
MPA是什么?
MPA全称(mutiple-page application),翻译过来就是多页面应用。
多页面应用(MPA):每个页面都是相对独立的,它们都拥有各自独立的URL,当我们访问一个页面时,需要重新加载公共资源文件(HTML、Javascript、CSS)。
即当MPA对您的输入作出反应或必须显示一些新内容时,它会从服务器请求一个新的HTML页面。在接收到标记之后,浏览器将呈现新页面,并重新加载它。(该过程类似我们常说的服务端渲染,又称 SSR)
大致SSR流程图
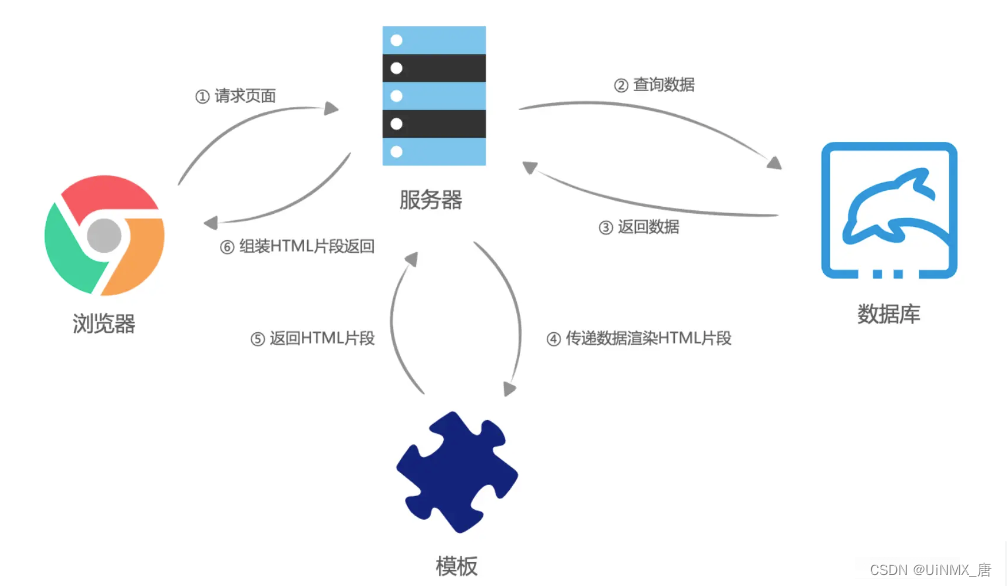
相对于SPA而言MPA的优缺点是什么?
MPA.优点:
- 单独页面对数据端点保护更好。
- 更易于搜索引擎优化(SEO)。
MPA缺点:
- 需要页面跳转,服务器资源消耗大。
- 用户体验要求高,维护难度高。
- 依赖URL请求,页面请求反应速度慢。
总体来说:不难发现其实spa与mpa之间的优缺点都是互补的,你的缺点就是我的优点。
SPA与MPA的主要区别是什么?
疑问:SPA 这么好是不是MPA就没有使用了呢?如果有那么什么情况下会使用到 MAP ?
其实从以下几个方面不难看出它们之间的区别,以及选择什么合适。
- 速度
速度是这里的一个重要因素——人们的注意力持续时间越来越短,为什么我们对SPA的加载速度越来越没有耐心? 因为它只加载一次大部分的应用资源。每当用户请求新数据时,页面不会完全重新加载。MPA速度较慢,因为每当用户想要访问新数据或移动到网站的不同部分时,浏览器必须从头重新加载整个页面。一个网站的最佳加载时间是0.4秒。如果你的网站或应用程序过于注重图片,那么选择SPA是一个更安全的选择。 - 耦合性
SPA是强解耦的,这意味着前端和后端是分离的。单页应用程序使用服务器端开发人员开发的apl来读取和显示数据。在MPA中,前端和后端更加相互依赖。所有的代码通常都包含在一个项目中。 - 用户体验
良好的用户体验不再是一种选择,而是一种需求。SPA对移动设备更友好,这一点值得记住,因为很多流量来自移动设备。甚至谷歌也开始将移动体验置于桌面体验之上。在SPA开发中应用的框架使您能够开发移动应用程序。另一方面,MPA支持更好的信息体系结构。您可以根据需要创建任意多的页面,并且可以在一个页面上包含任意多的信息,而不受任何限制。导航是清晰的,所以用户可以很容易地找到他们在网站上的路,这对他们的体验有积极的影响。 - 安全性
这可能对你来说并不奇怪,但网站越大,在多页面应用程序中需要付出的努力就越多。如果你想要一个MPA,那么你必须保护每一个网页。在SPA中,要保持页面安全,您所要做的就是更快地保护数据端点,但不一定更安全。SPA更容易受到黑客攻击,因为它们运行在JavaScript上,而JavaScript不执行代码编译,因此更容易受到恶意软件的攻击。 - 开发过程
SPA的最大优势之一是可重用的后端代码。如果您认为可重用代码等于更少的工作,那么您是对的。你可以将你在网页应用中使用的代码应用到你的原生移动应用中。这是一个重要的信息,因为应用程序和网站经常在移动设备上使用——这并不奇怪,因为我们大多数人都在不停地奔跑。由于前端和后端划分清晰,可以同时开发这两个部分,加快了整个开发过程。MPA的开发时间较长,因为在大多数情况下,必须从一开始就对服务器端进行编码。
对JavaScript的依赖
SPA与JavaScript息息相关。越来越多的搜索引擎开始支持JavaScript,但结果却不尽相同。支持的级别很大程度上取决于所使用的JS框架。如果应用运行在禁用JavaScript的浏览器上,它可能会导致应用功能问题,这可能会导致更高的反弹率和更低的转化率。对JavaScript的依赖也导致了SEO优化和安全问题。可以在不依赖任何JavaScript的情况下构建MPAs。 - 综上:
无论是SPA还是MPA ,它们在架构上没有一个是完美的——都有各自的优点和缺点。SPA在速度和代码可重用性方面胜出,这可以用于开发您的移动应用程序,但它在SEO优化方面有不足。使用MPA将帮助可以提高搜索引擎优化(SEO),并且具有更强的可伸缩性,但比SPA慢得多。SPA更好地用于社交网络应用程序、SaaS平台——任何SEO排名不易被破坏者的地方。MPA最适合用于电子商务应用程序、企业目录和市场。如果您是一家提供各种产品的大公司,那么MPA是您的最佳选择。
lesson3-关于CSR、SSR、SSG、ISP
在了解到SPA与MPA后,发现其与渲染模式是息息相关于的。
- CSR 全称(Client-Side Rendering) 客户端渲染
- SSR 全称(Server-Side Rendering) 服务器端渲染
- SSG 全称(Static Site Generator )静态站点生成器
- ISR 全称(Incremental Static Regeneration) 增量静态再生
1.CSR 全称(Client-Side Rendering) 客户端渲染:在每次渲染之后获取数据
页面的渲染其实就是浏览器将HTML文本转化为页面帧的过程。而如今我们大部分WEB应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,也就是说,求在执行 JavaScript 脚本的时候,HTML页面已经开始解析并且构建DOM树了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面动态渲染。这个过程就叫客户端渲染。
CSR大致流程如图
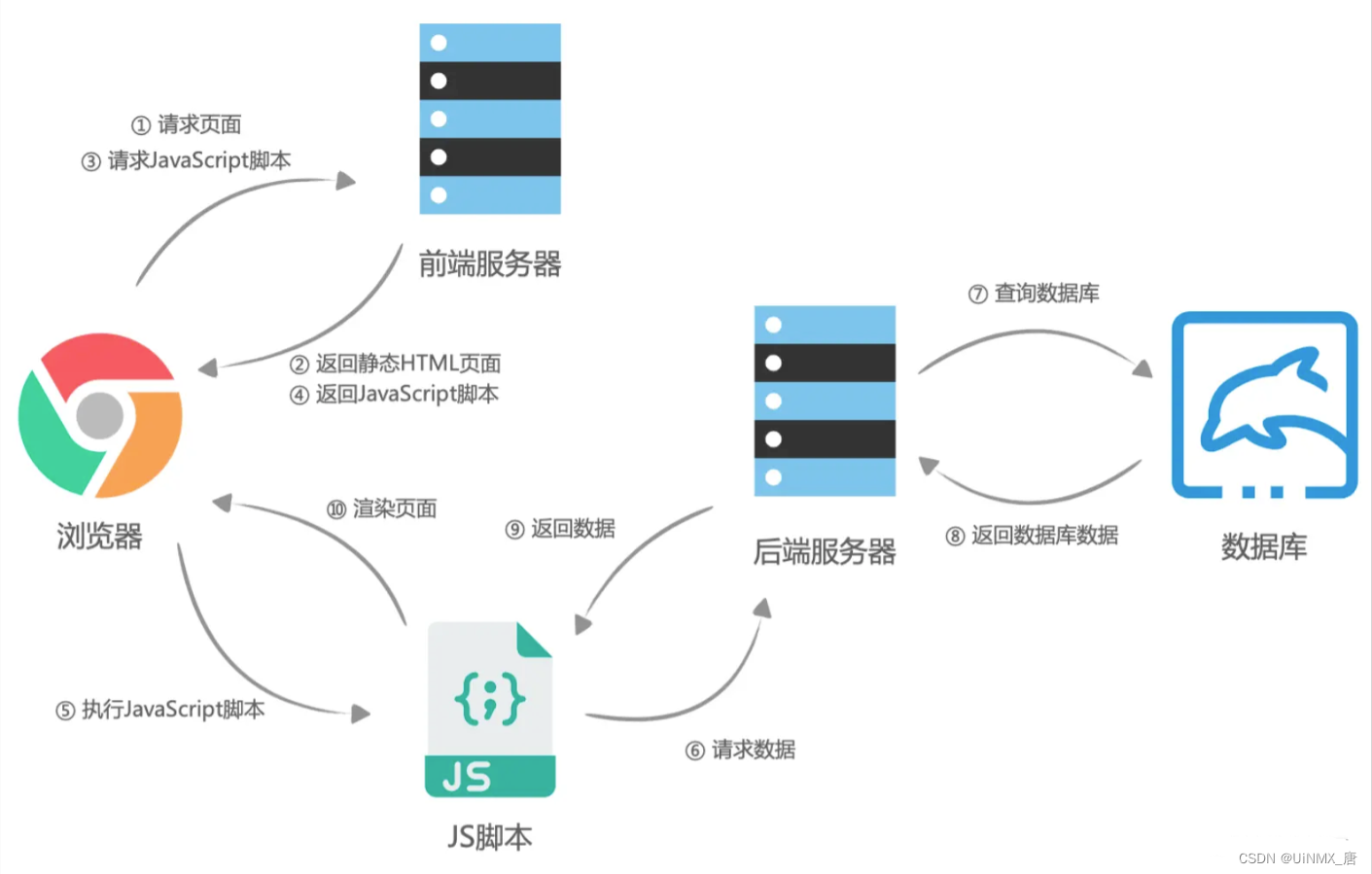
SSR 全称(Server-Side Rendering) 服务器端渲染:在每次渲染之前获取数据
服务端渲染就是在浏览器请求页面URL时,服务端直接将我们需要的HTML文本组装好,并返回给浏览器,这个HTML文本被浏览器解析之后,不需要经过JavaScript脚本的执行,可直接构建出完整的DOM树并展示页面中。这个服务端组装的过程,叫做服务端渲染。
而从服务器端请求URL获取数据的过程,是在页面加载之前完成的,该过程将首先运行特殊函数映射相关数据,并返回给客户端。在返回前存在一定(映射)延迟。
SSR大致流程图
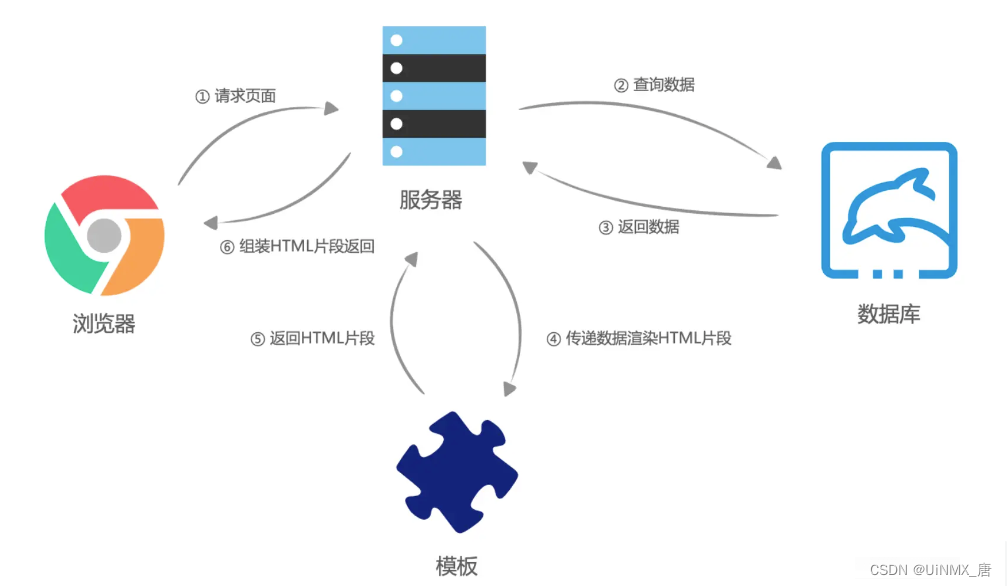
SSG 全称(Static Site Generator )静态站点生成器:在构建时获取一次数据
解析是在构建时执行的,当发出请求时,html 将静态存储,直接发送回客户端。
ISR 全称(Incremental Static Regeneration) 增量静态再生:
数据在构建时获取一次,在一定冷却时间后再次获取,并在第二次访问时提供。
增量静态再生是SSG和SSR的组合,它是静态服务的,但在特定的时间和条件下,页面将重新构建并再次从API获取数据
参考&学习
- 介绍参考:https://www.mybj123.com/13984.html
- 流程图参考:https://juejin.cn/post/7023932512363610120
- SEO优化参考:https://theodorusclarence.com/blog/nextjs-fetch-usecase
- 详细案例说明参考:https://theodorusclarence.com/blog/nextjs-fetch-method
lesson4-如何实现前端路由(SPA)
在了解SPA后不难发现其实它的原理是通过以下两种模式来实现的
- Hash 模式
- History API 模式
关于 Hash
早起的前端路由实现就是基于location.hash来实现的,location.hash就是路由#后面的内容,其原理就是通过hashchange监听#后面的内容的变化来进行页面更新。hash模式是利用浏览器不会对#后面的路径对服务端发起请求。
Hash 主要特性:
- 改变hash值,浏览器不会重新加载页面
- 当刷新页面时,hash不会传给服务器
根据它的特性可以用原始的JS来实现Hash路由
实现思路:运用hash特性,通过触发 hashchange 事件实现界面(UI),更新到 #/后面对应的内容
原生JS实现Hash路由方法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>原生JS实现的前端路由</title>
</head>
<body>
<ul>
<li><a href="#/home">首页</a></li>
<li><a href="#/user">用户中心</a></li>
<li><a href="#/login">登录</a></li>
</ul>
<div id="view"></div>
</body>
<script>
let view = null
// 1.当初始的 HTML 文档被完全加载和解析完成之后,**DOMContentLoaded **事件被触发
window.addEventListener('DOMContentLoaded',onload)
// 3.监听hash变化
window.addEventListener('hashchange',onHashChange)
// 2.初次赋值
function onload(){
view = document.getElementById('view')
onHashChange()
}
function onHashChange(){
switch (location.hash){
case '#/home':
view.innerHTML = '首页'
break;
case '#/user':
view.innerHTML = '用户中心'
break;
case '#/login':
view.innerHTML = '登录'
break;
}
}
</script>
</html>
关于 history API
history 提供了 pushState 和 replaceState 两个方法,这两个方法改变 URL 的 path 部分不会引起页面刷新。 history 提供类似 hashchange 事件的 popstate 事件,但 popstate 事件有些不同:
- 通过浏览器前进后退改变 URL 时会触发 popstate 事件
- 通过pushState/replaceState或a标签改变 URL 不会触发 popstate 事件。
那应该怎样才能触发popstate事件呢?
- 方式一:可以拦截 pushState/replaceState的调用和a标签的点击事件来检测 URL 变化。
- 触发方法思路参考如下图:
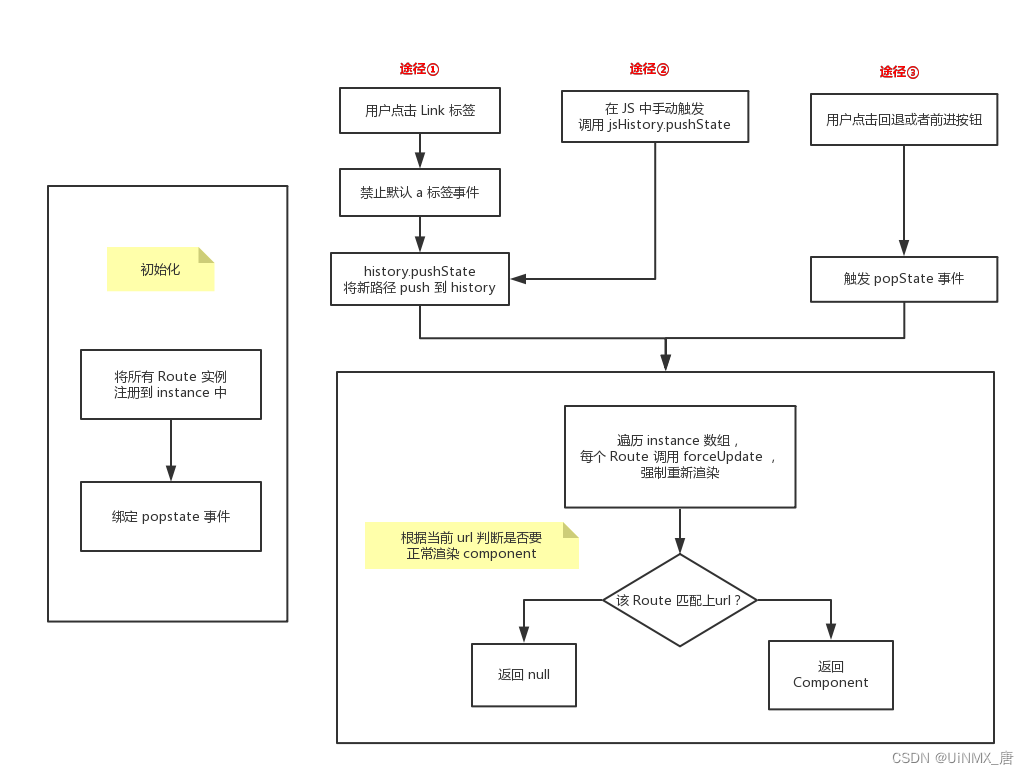
原生 history APi 实现案例
<p id="example">
<a href="/name" title="name">name</a>
<a href="/age" title="age">age</a>?
</p>
<div class="main" id="main"></div>
<script>
;(function(){
var examplebox = document.getElementById('example')
var mainbox = document.getElementById('main')
examplebox.addEventListener('click', function(e){
e.preventDefault()
var elm = e.target
var uri = elm.href
var tlt = elm.title
history.pushState({path:uri,title:tlt}, null, uri)
mainbox.innerHTML = 'current page is '+tlt
})
window.addEventListener('popstate',function(e){
var state = e.state
mainbox.innerHTML = 'current page is ' + state.title
})
})()
</script>
在React 与 Vue 中的History模式
Vue中的History 模式
核心思想:通过改变URL来触发pushState事件,达到同步页面UI的目的
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>Vue中的History 模式的实现</h1>
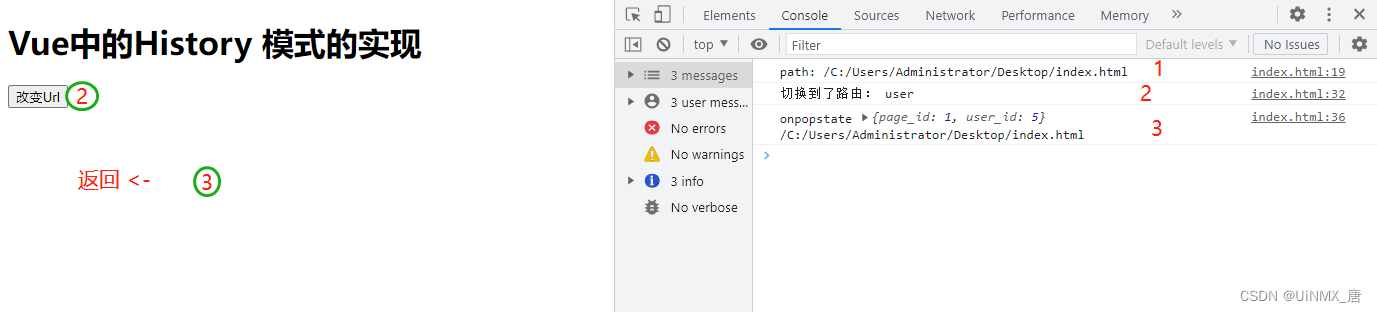
<button id="myBtn">改变Url</button>
<script>
const myBtn = document.getElementById('myBtn')
window.addEventListener('DOMContentLoaded', () => {
console.log('path:', location.pathname);
})
myBtn.addEventListener('click', () => {
const state = {
'page_id': 1,
'user_id': 5
}
const title = 'gotoser'
const url = 'index.html' //切换到的另一个 HTML文件
history.pushState(state, title, url)
console.log('切换到了路由:', 'user');
})
window.onpopstate = (e) => {
console.log('onpopstate', e.state, location.pathname);
}
</script>
</body>
</html>
- 在点击按钮改变URL 之后触发 pushState 事件
- 当执行返回与前进时触发 **onpopstate ** 事件
最终效果如图:
React-Router中的History模式
在react-router-dom中直接引入 HashRouter 即可
import { HashRouter as Router,Routes,Route,Link } from 'react-router
import HomePage from './pages/HomePage/index';
import UserPage from "./pages/UserPage/index"
import LoginPage from "./pages/LoginPage/index"
function App() {
return (
<div className="App">
<Router>
<Link to="/">首页</Link>
<Link to="/user">用户中心</Link>
<Link to="/login">登录</Link>
</Router>
</div>
);
}
React-router 原生写法待完善…
BrowserRouter 与 HashRouter 对比
-
HashRouter 是不需要服务端渲染的,靠浏览器的 # 来区分 path 就可以,而BrowserRouter 需要服务器端对不同的URL返回不同的HTML。需要后端配置
-
BrowserRouter 使用 HTML5 History API 其中包含 pushState、replaceState 、popstate 等事件,让页面UI同步与之URL。
-
HashRouter 不支持 location.key 与 location.state 动态路由跳转需要通过 ?传递参数。
-
HashRouter在web浏览器中使用,当URL由于某种原因不应该(或不能)发送到服务器时。这可能发生在某些共享托管场景中,您无法完全控制服务器。在这些情况下,HashRouter
可以将当前位置存储在当前URL的散列’部分,因此它永远不会被发送到服务器。所以事件开发环境中不推荐使用。
参考&学习
SPA实现原理参考:https://github.com/youngwind/blog/issues/109
结语:
本文内容主要是学习笔记总结,内容来源于网络
















 4165
4165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











