






模型选择研究
为了完成我们的烟草相关法律文书方面的内容,我们小组首先进行了模型比较选择,我们通过查阅相关资料以及其他有关大模型的有关知识,初步预选了基础Bert(后期均称为Bert)、GPT系列(以3为例子),ELmo,RoBERTa,ALBERT几个市面常见的模型。我们初步敲定了采用Bert来进行我们的LLM模型学习与部署。我们分析了Bert模型本身的优势,以及在NLP方面处理烟草法律文书的优势、并且横向比较了和其他几个模型的优势。
BERT模型的优势
-
双向性:BERT的最大特点是它的双向性。传统的语言模型一般是单向的,只能从左到右或者从右到左进行词的预测。而BERT则是同时考虑了上下文的前后关系,这使得它对文本的理解更加深入和准确。
-
预训练和微调:BERT通过在大量文本数据上进行预训练,然后在具体任务上进行微调。这种方法使得BERT可以在各种NLP任务上表现出色,如问答系统、文本分类、命名实体识别等。
-
Transformer架构:BERT基于Transformer架构,使用自注意力机制,能够捕捉句子中任意两个词之间的依赖关系,无论它们相距多远。相比传统的RNN和LSTM,Transformer可以并行处理整个句子,极大提高了训练效率。
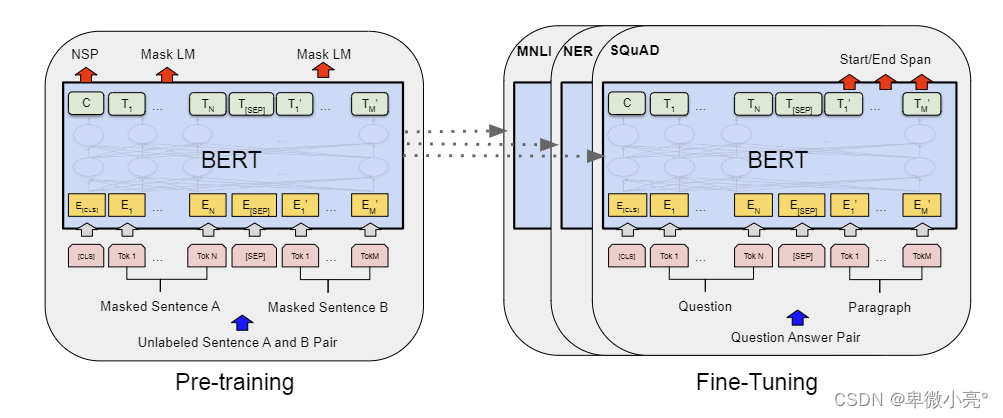
BERT 预训练和微调
预训练阶段:
-
掩码语言模型(MLM):随机掩盖输入文本中的一些词,并要求模型预测这些被掩盖的词。例如,句子"the cat sat on the mat"可能会被处理成"the [MASK] sat on the mat",模型需要根据上下文预测"[MASK]"处的词是"cat"。
-
下一句预测(Next Sentence Prediction, NSP):给定两个句子A和B,模型需要判断B是否是A的下一句。这有助于模型理解句子之间的关系。
微调阶段:
-
在预训练完成后,BERT可以通过在特定任务的数据集上进行微调,快速适应各种NLP任务,如文本分类、命名实体识别、问答系统等。
在NLP方面处理烟草相关法律文书BERT的优势
-
精确的语义理解:烟草相关的法律文书通常包含复杂的法律术语和长句子。BERT的双向性使得它能够更好地理解这些复杂的句子结构和上下文,从而提高文本分析的准确性。
-
处理长文本的能力:法律文书往往篇幅较长,BERT的Transformer架构可以有效处理和理解长文本中的依赖关系,提取出有用的信息。
-
预训练模型的泛化能力:BERT在大规模通用语料上进行预训练,具有很好的泛化能力。通过在法律领域的特定数据集上进行微调,BERT能够快速适应和处理烟草相关的法律文书,提高处理效率。
-
多任务处理:BERT可以被微调用于多种NLP任务,如文本分类、命名实体识别、关系抽取等。这些任务在处理法律文书时非常重要,例如识别法律条款、分类法律文书类型、抽取关键信息等。
综上所述,BERT模型在处理烟草相关的法律文书方面具有显著优势,能够提供精确的语义理解、高效处理长文本、良好的泛化能力以及支持多任务处理。
BERT相对于其他大语言模型(如GPT-3、ELMo等)有其独特的优势,具体如下:
BERT的独特优势
-
双向编码:
-
BERT:采用双向Transformer架构,能够同时从左右两个方向理解上下文。这种双向性使得BERT在理解句子的语义时更加全面和准确。
-
其他模型(如GPT系列):主要是单向的(例如GPT-3是从左到右生成文本),这在某些情况下可能限制了对上下文的理解。
-
-
预训练和微调:
-
BERT:预训练阶段通过掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)任务进行训练,然后在具体任务上进行微调。这种方法使得BERT可以快速适应各种NLP任务。
-
其他模型:有些模型没有专门设计的预训练任务(如GPT-3使用自回归语言模型),可能在某些任务上的适应性不如BERT。
-
-
任务泛化能力:
-
BERT:预训练任务设计(MLM和NSP)使得它在多种下游任务上表现出色,包括问答系统、文本分类、命名实体识别等。
-
其他模型:如ELMo虽然也能在多个任务上表现良好,但其架构和预训练方法不如BERT全面。
-
-
训练效率:
-
BERT:在预训练阶段利用了大规模的计算资源和数据,但在具体任务上微调时相对高效,适合于实际应用。
-
其他模型:如GPT-3,虽然具有非常强的生成能力,但其参数规模巨大(1750亿参数),导致训练和推理的计算成本极高。
-
BERT与其他模型的比较
-
与GPT系列(如GPT-3):
-
BERT:双向编码,适合理解和处理复杂的文本任务。
-
GPT-3:主要用于文本生成和对话系统,生成能力强,但在需要理解上下文的任务上可能不如BERT。
-
-
与ELMo:
-
BERT:基于Transformer架构,能够捕捉更长距离的依赖关系。
-
ELMo:基于双向LSTM,虽然能够处理双向信息,但在处理长文本和全局依赖关系上不如BERT。
-
-
与RoBERTa、ALBERT等BERT变种:
-
BERT:原始模型具有较好的性能,但一些变种(如RoBERTa、ALBERT)通过改进预训练过程和架构,进一步提高了性能和效率。
-
这些变种:在具体任务上可能表现优于原始BERT,但其基本思想和架构仍然基于BERT。
-
总结
BERT在语言理解、预训练方法、任务适应性和训练效率方面具有显著优势,使其在多种NLP任务上表现出色。尽管其他大语言模型在某些特定任务上有其优势,但BERT的双向编码和预训练策略使其在理解复杂文本和多任务处理方面具备独特的优势。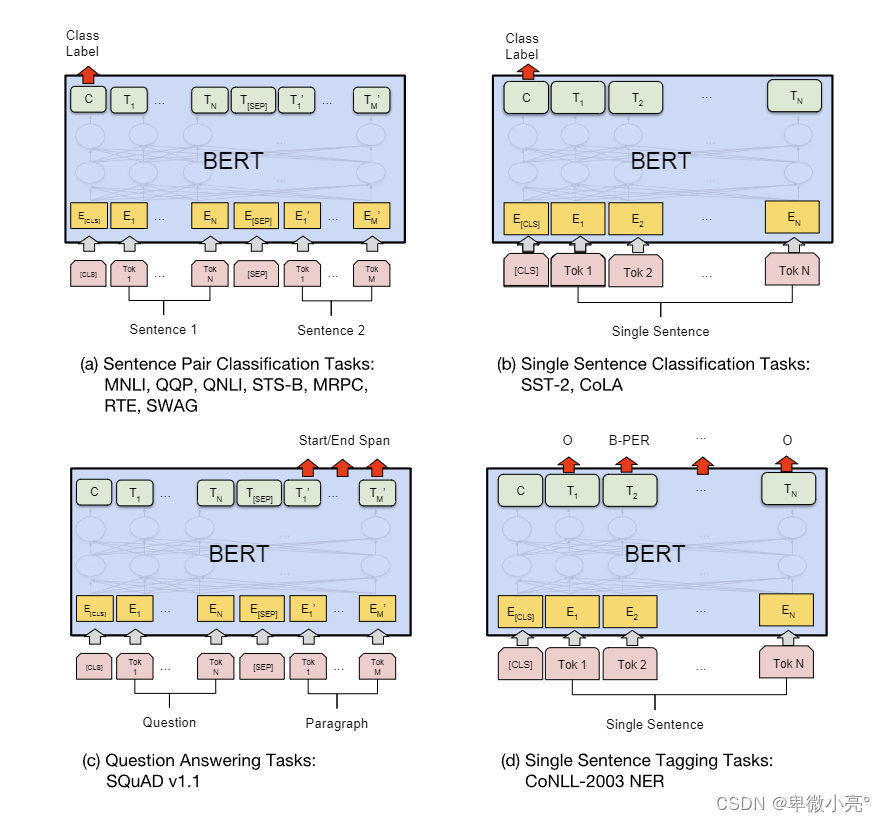















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









