







百度搜索每个关键字最多显示76页,每页最多显示10条数据。(截至2022/11/23)
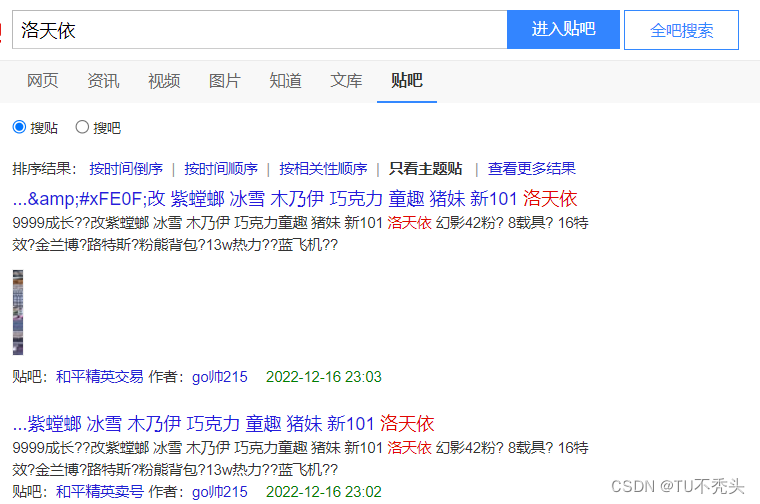
一、爬虫需求
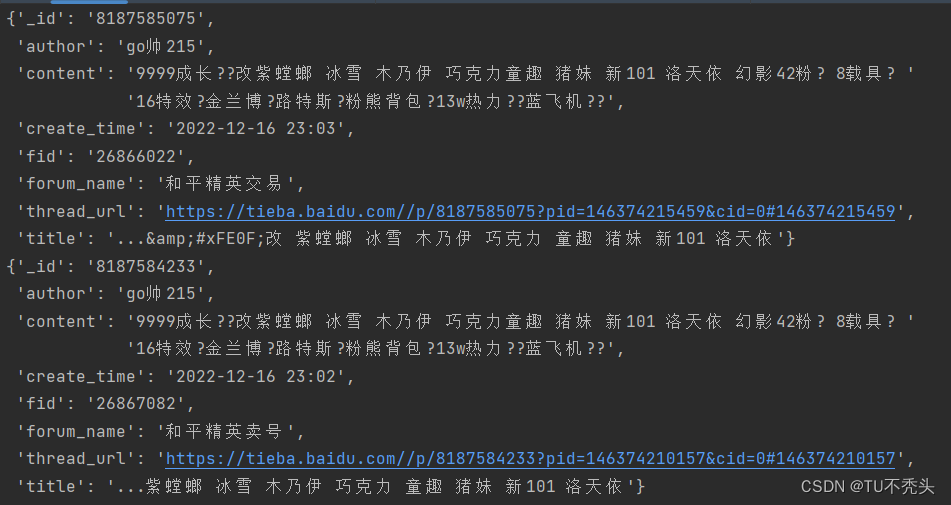
_id = scrapy.Field() # _id:data_tid也是thread_id,该帖的tid号
fid = scrapy.Field() # 贴吧的id,方便后续获取json包
title = scrapy.Field() # 帖名,问题名
thread_url = scrapy.Field() # 该帖的URL
content = scrapy.Field() # 内容(实际为楼层页的第一层内容,可考虑不要)
forum_name = scrapy.Field() # 所属贴吧名
author = scrapy.Field() # 帖主即作者
create_time = scrapy.Field() # 发帖时间
二、字段分析
1、搜索关键词的编码为gbk编码,如果直接字段组合连接,获得的是utf-8的编码,因此需要进行转换。
req_url = 'https://tieba.baidu.com/f/search/res?isnew=1&kw=&qw=' + quote(keyword.encode('utf-8').decode('utf-8').encode('gbk')) + '&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=' + str(page)
> https://tieba.baidu.com/f/search/res?isnew=1&kw=&qw=%C2%E5%CC%EC%D2%C0&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=1
# 该方式无法正确获取到数据
req_url = 'https://tieba.baidu.com/f/search/res?isnew=1&kw=&qw=' + str(keyword) + '&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=' + str(page)
> https://tieba.baidu.com/f/search/res?isnew=1&kw=&qw=%E6%B4%9B%E5%A4%A9%E4%BE%9D&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=1
三、代码实现
def start_requests(self):
keyword = '洛天依'
# 一个关键字搜索最多显示76页,用range循环结束元素需要加1
for page in range(1,77):
req_url = 'https://tieba.baidu.com/f/search/res?isnew=1&kw=&qw=' + quote(keyword.encode('utf-8').decode('utf-8').encode('gbk')) \
+ '&rn=10&un=&only_thread=1&sm=1&sd=&ed=&pn=' + str(page)
yield Request(url=req_url,headers=UA_header)
def parse(self, response: HtmlResponse, **kwargs):
response_data = etree.HTML(response.text)
post_lists = response_data.xpath('//div[@class="s_post_list"]/div')
TiebaPost = TiebaKeysearchItem()
if post_lists == []:
print('没有获取到内容')
else:
for post in post_lists:
TiebaPost['_id'] = post.xpath('./span/a/@data-tid')[0]
TiebaPost['fid'] = post.xpath('./span/a/@data-fid')[0]
# 只获取文本
TiebaPost['title'] = post.xpath('./span/a')[0].xpath('string(.)').strip()
TiebaPost['thread_url'] = 'https://tieba.baidu.com/' + post.xpath('./span/a/@href')[0]
TiebaPost['content'] = post.xpath('./div[1]')[0].xpath('string(.)').strip()
TiebaPost['forum_name'] = post.xpath('./a[1]/font/text()')[0]
try:
TiebaPost['author'] = post.xpath('./a[2]/font/text()')[0]
except:
TiebaPost['author'] = ''
TiebaPost['create_time'] = post.xpath('./font/text()')[0]
print(TiebaPost)
如果有其他的问题欢迎讨论~

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









