







本文精华在于最后一部分,前面特别是②这一部分感觉在胡言乱语,不建议除了我之外的人观看
1.为何不用线性回归模型
参考文献:文献1
该文献讲的十分通俗易懂,简单来说就是因变量为分类变量时,使用线性模型会违反五个回归假定中的两个。以及,结合吴恩达教授的网课来理解,如果我们用线性模型来强行预测分类的话,确实也可以把回归的直线看作决策边界,但是我们做的是预测,不是百分百准确的,因此更希望给出一个概率,如判断该肿瘤属于良性的可能性是90%。然而这样的概率在线性模型中是无法给出的,或者说给出的可能是低于0或高于1的错误值

(可见原文,稍微复习一下数学期望的相应公式就能推导出,我亲手推导过发现确实如此)
2.为何要用logistic模型
其他参考文献:
文献2
文献3(何谓logit)
文献4(部分原理+spss实现)
①满足上述假定
在文献4中提到,通过logit转换实现了对线性回归的要求

②对数函数的性质更符合分类问题的讨论
敏感性问题
该原因主要是通过文献2来阐述,文献3是对文献2中一些概念的介绍。
文献2首先提出了一个“敏感度”的原因,这个原因我没听懂,不知道为什么分类问题需要【随着自变量的变化,因变量产生更为巨大的变化,因此需要用对数函数】
我悟了,其实他想表达的意思是,因为在分类问题中(假设是二分的话),两个选项代表的意义是天差地别的,例如男女/喜欢讨厌/推荐不推荐等等,而如果是普通的线性回归,y的变动仅代表了数值的变化,也就是说更多的是“量变”,而逻辑回归则代表的是“质变”,因此我们更想用一个能够反映出“自变量的微小变动能带来因变量的巨大变化”、“敏感性较强”的函数来应用于分类问题上,那么我们很自然地想到指数函数,以及指数函数的反函数——对数函数,其在0~1之间的部分也是增长极快的。

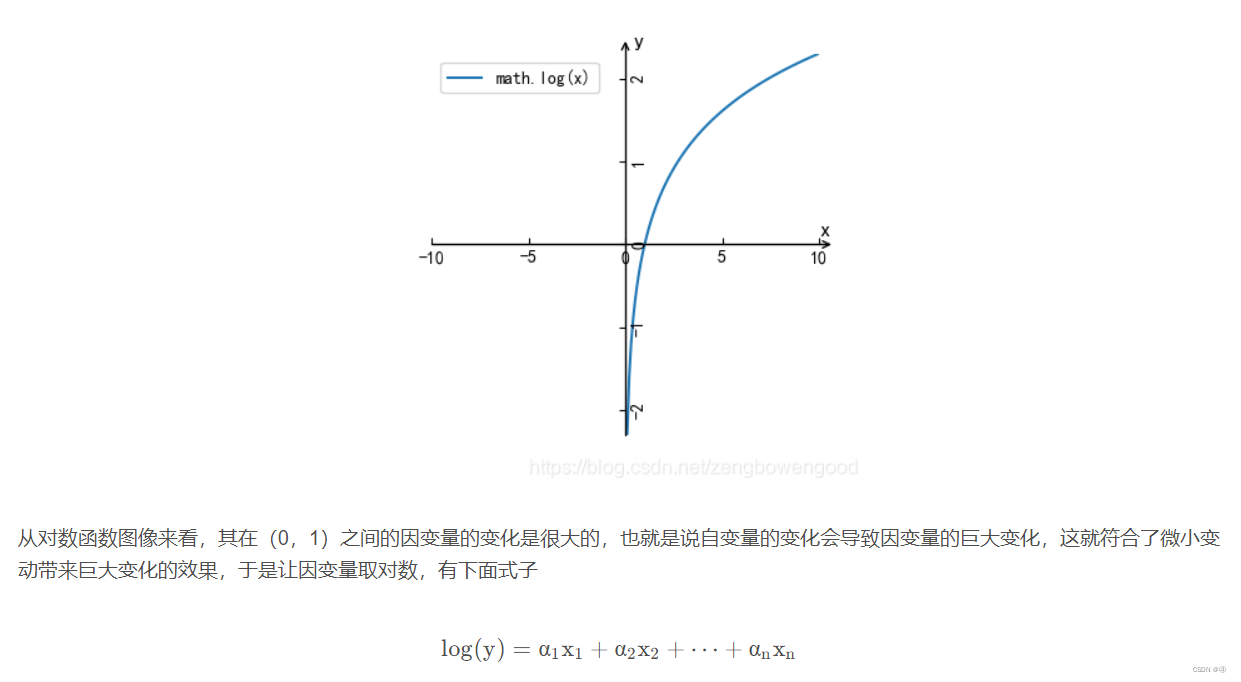
对称性问题(按照文献2的思路)
那么为何要引入odd(几率、优势比)呢?


我觉得作者的意思是,目前的式子左边的log(y)的值域是在负无穷到正无穷之间,而在概率中更好地表达的方法是,必然不发生表示为0,必然发生表示为1或者正无穷。而引入了几率之后,其值域就在0到正无穷了,更符合我们的习惯。
↑错误的,仅仅是几率的定义域在0到正无穷,而对几率取对数,也就是
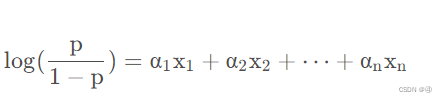
log(p/1-p)的值域在负无穷到正无穷之间。这篇文章好像有那么点问题,虽然可能是我理解不透彻,但是先别看了,直接看文献3吧
也就是说文献二的解释存在两个思路,一方面是解决敏感性问题,这个我可以理解,第二个方面是对称性问题,我目前还是无法理解。
③抛开以上两点(文献2),从文献3出发

用odd来代替概率的原因在于,假如我们等式左边是概率p的话,p的取值在0-1,而等式右边的取值是负无穷到正无穷,这样的等式就出问题了;而如果用和概率密切联系的几率,取其对数来作为因变量的话,就能很好地解决这个问题,并且意义还不会发生变化。
以上这段话是加上了自己的理解的,也就是说一开始用线性回归中的y作为因变量肯定不合适,会违背回归假定,以及出现吴恩达教授所说的一些问题,例如出现极端值的话很容易影响直线的变动(卧槽这么一说我突然更能够理解所谓“敏感性”问题了,因为S型的曲线会比直线更具有“抗干扰性”。不过这个抗干扰性和文献2中所说的敏感性是同一个东西吗?好像不对);如果用概率p的话也不行,因为等式直接不成立了,左右两边的定义域不同;那么最后选用了几率的对数,完美地解决了上述的问题

注意一下,此处的最后一个式子和吴恩达给出的式子是一样的:
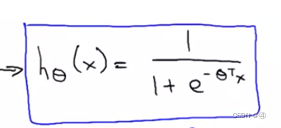
仅需把吴恩达的式子右边上下同乘以eαx即可。















 5147
5147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









