






深入了解HashMap底层原理
HashMap的常用方法
| 方法和描述 | 修饰符和返回值类型 |
|---|---|
clear() 从Map集合中删除所有的映射。 | void |
containsKey(Object key) 如果此映射包含指定键的映射,则返回 true | boolean |
containsValue(Object value) 如果此地图将一个或多个键映射到指定值,则返回 true | boolean |
get(Object key) 返回到指定键所映射的值,或 null如果此映射包含该键的映射。 | V |
isEmpty() 如果此地图不包含键值映射,则返回 true 。 (判断是否为空) | boolean |
put(K key, V value) 将指定的值与此映射中的指定键相关联。 | V |
remove(Object key) 从该地图中删除指定键的映射(如果存在)。 | boolean |
replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。 | V |
replace(K key, V oldValue, V newValue) 仅当当前映射到指定的值时,才能替换指定键的条目。 | boolean |
size() 返回此地图中键值映射的数量。 | int |
values() 返回此地图中包含的值的Collection视图。 | Collection |
要了解的数据结构
在数据结构中常见的三种结构:数组、链表、哈希结构(散列表)、这里总结各自特点和它们的优缺点
1、数组
数组:采用一段连续的存储单元来存储数据。
数组的查找图解:

数组的插入和删除图解:
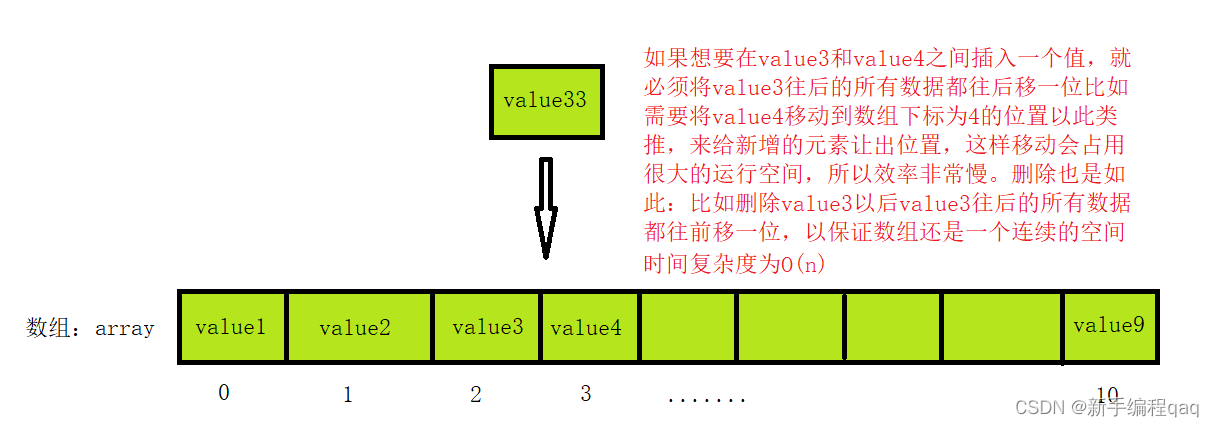
优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快),时间复杂度为O(1)。
缺点:插入、删除效率低,并且大小固定不易动态扩展时间复杂度为O(n)。
2、链表
链表:是一种物理存储单元上非连续,非顺序的存储结构
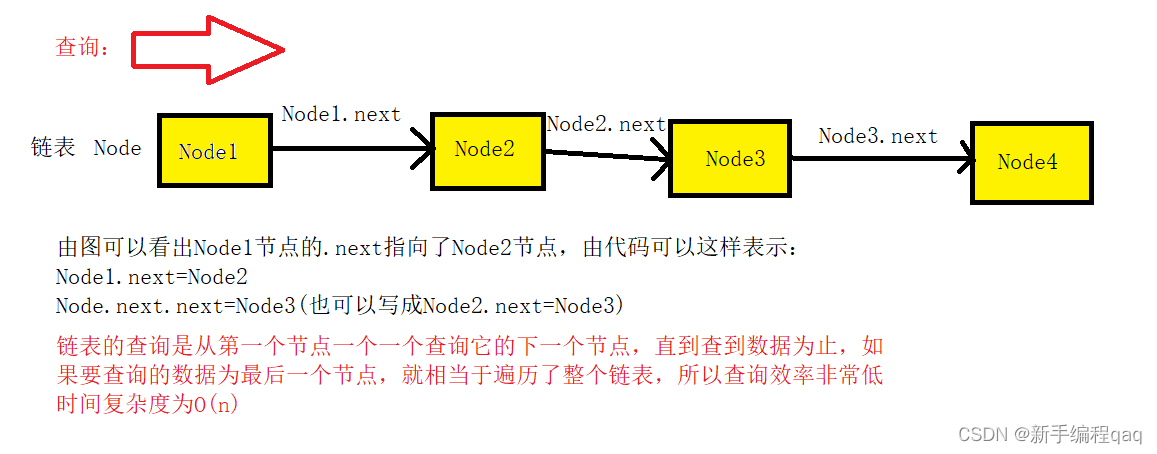
链表的查询图解:
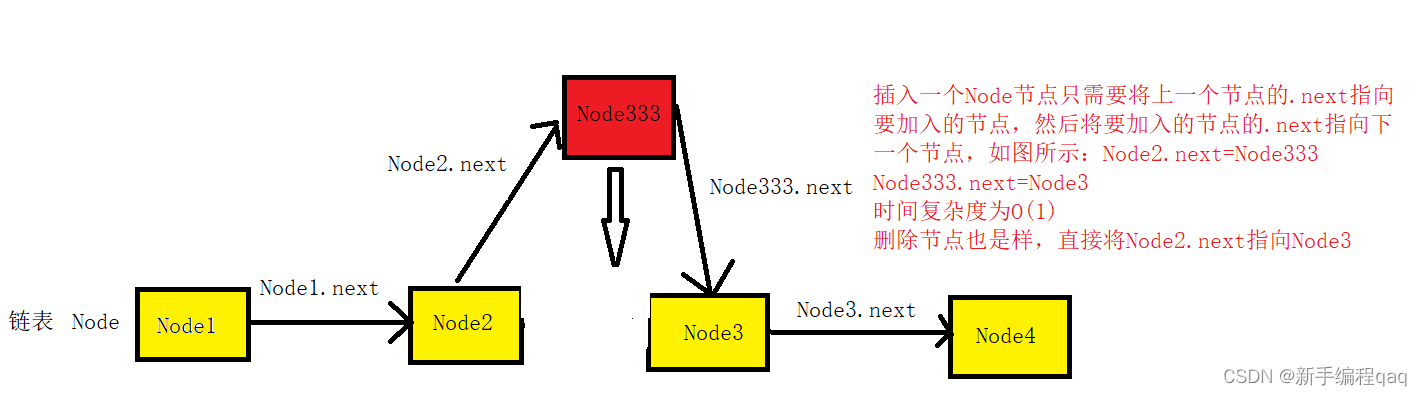
链表的插入和删除图解
3、哈希结构(散列表)
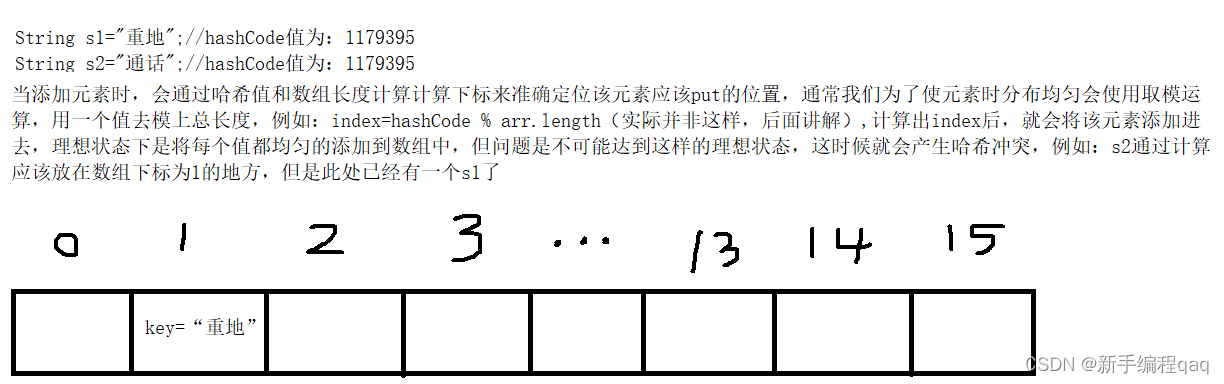
什么是哈希值:
- 根据Object.hashCode()可以获得对象的哈希值,
- 它是一个十进制的整数,由系统随机给出;
- 是对象的地址值,但这是一个逻辑地址,是模拟出来的;不是数据实际存储的物理地址;
什么是哈希表(散列表)结构
哈希表可以简单理解为存储Key-Value(键值对)映射的集合比如说HashMap底层就是由哈希表构成,我们可以通过Key快速找到对应的Value。
- jdk1.7中HashMap的底层数据结构是由数组+链表
- jdk1.8中HashMap的底层数据结构是由数组+链表+红黑树
此时就有了第二种数据结构——链表,冲突的元素就会以链表的形式放在此索引的位置
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WEkOEZPJ-1660051210427)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20220809204839110.png)]](https://img-blog.csdnimg.cn/8b24e9914c604a91ab30099c4c3264e2.png)
但是,当链表的长度越来越长超过8个的时候就会出现第三种数据结构——红黑树
因为链表的查询效率非常低时间复杂度为O(n),而红黑树的时间复杂度为O(logn),查询的效率远远高于链表。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A2NeLLHL-1660051210427)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20220809205843927.png)]](https://img-blog.csdnimg.cn/5bb9647b2abf4e05bfb6f4e0fcc321db.png)
-
红黑树是一棵接近于平衡的二叉树,其查询时间复杂度为O(logn),远远比链表的查询效率高。
-
但如果链表长度不到一定的阈值,直接使用红黑树代替链表也是不行的,因为红黑树的自身维护的代价也是比较高的,每插入一个元素都可能打破红黑树的平衡性,这就需要每时每刻对红黑树再平衡(左旋、右旋、重新着色)
HashMap解析
简介
HashMap 是基于哈希表的 Map 接口是实现的。它的值(key)和键(value)允许为null。是无序的,也不能保证顺序一直不变。
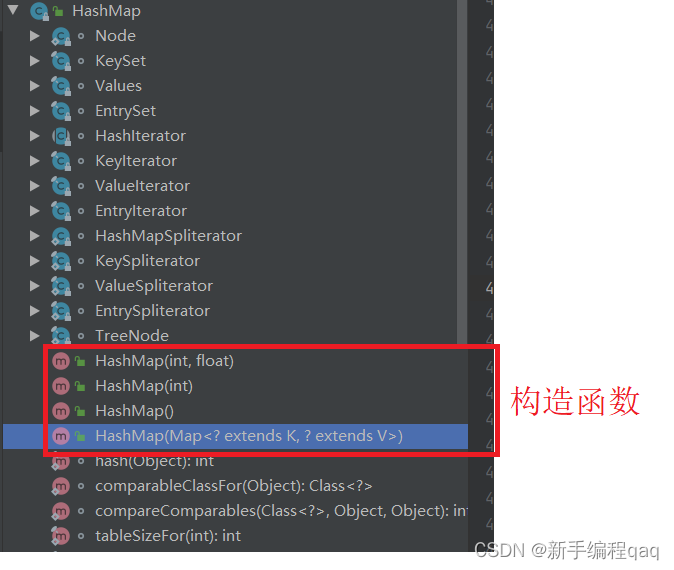
从源码可以看出HashMap有四个构造器,通过构造器可以看出HashMap有两个默认参数nitialCapacity (初始容量)和loadFactor(加载因子)当用户没有给定值的时候初始容量的值为16,加载因子为0.75,其中初始容量是HashMap刚初始化时的容量,加载因子是对HashMap空间和时间效率的一个平衡,当达到这个值的时候HashMap就会触发扩容。
为什么要这个加载因子
加载因子是对HashMap空间和时间效率的一个平衡, 因为如果跟ArrayList一样等到放不下再进行扩容的时候,某一个Hash的Key所对应的Value链表可能已经很长了,所以使用HashMap使用空间加载载因子的方式进行扩容了,可以避免hash重复,从而提升查询的效率。
分析HashMap的put(K key,V value)方法源码
//实现Map.put和相关方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//tab 哈希数组,p 该哈希桶的首节点,n hashMap的长度,i 计算出的数组下标
Node<K,V>[] tab; Node<K,V> p; int n, i;
//获取长度并进行扩容,使用的是懒加载,table一开始是没有加载的,等put后才开始加载
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/**如果计算出的该哈希桶的位置没有值,则把新插入的key-value放到此处,此处就算没有插入成功,也就是发生哈希冲突时也会把哈希桶的首节点赋予p**/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//发生哈希冲突的几种情况
else {
// e 临时节点的作用, k 存放该当前节点的key
Node<K,V> e; K k;
//第一种,插入的key-value的hash值,key都与当前节点的相等,e = p,则表示为首节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//第二种,hash值不等于首节点,判断该p是否属于红黑树的节点
else if (p instanceof TreeNode)
/**为红黑树的节点,则在红黑树中进行添加,如果该节点已经存在,则返回该节点(不为null),该值很重要,用来判断put操作是否成功,如果添加成功返回null**/
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//第三种,hash值不等于首节点,不为红黑树的节点,则为链表的节点
else {
//遍历该链表
for (int binCount = 0; ; ++binCount) {
//如果找到尾部,则表明添加的key-value没有重复,在尾部进行添加
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断是否要转换为红黑树结构
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//如果链表中有重复的key,e则为当前重复的节点,结束循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//有重复的key,则用待插入值进行覆盖,返回旧值。
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//到了此步骤,则表明待插入的key-value是没有key的重复,因为插入成功e节点的值为null
//修改次数+1
++modCount;
//实际长度+1,判断是否大于临界值,大于则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
//添加成功
return null;
}
流程图:
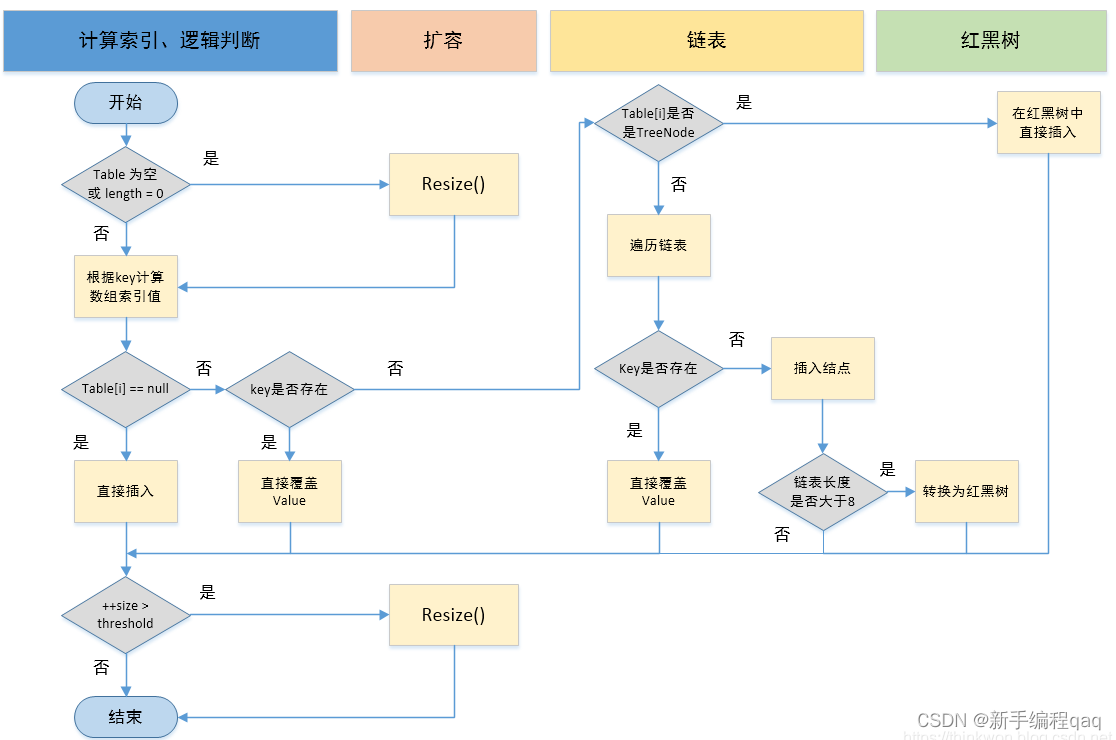
HashMap的扩容机制
-
空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
-
有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让 阈值=容量*负载因子。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
-
如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
-
首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
后让 阈值=容量*负载因子。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!) -
如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
手写HashMap源码
public class MyHashMap<K,V> {
private Entry[] entrys=new Entry[100];//简单版的,所以在这里就初始化容量(其实不能这样)
class Entry<K,V>{
K k;
V v;
int hash;
Entry<K,V> next;
public Entry(K k, V v, Entry<K, V> next, int hash) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
}
public void put(K k,V v){
int hash=k.hashCode();//获取key的HashCode值
int index = hash % entrys.length;//用HashCode值与整个数组的长度取模
Entry oldEntry = entrys[index];//将当前索引的值赋值给oldEntry
if (oldEntry == null) {//判断当前索引的值是否为空
entrys[index]=new Entry(k,v,null,hash);//如果当前索引的值为空说明此处没有值,就将当前的值填入当前索引
}else {
entrys[index]=new Entry(k,v,oldEntry,hash);//如果不为空就说明当前索引有值,将此索引位置变为链表结构,就用oldEntry.next指向当前放入的值
}
}
public V get(K k){
int index=k.hashCode()%entrys.length;
for (Entry entry = entrys[index];entry!=null;entry=entry.next){
if (entry.hash==k.hashCode()&&(entry.k==k||entry.k.equals(k))){
return (V) entry.v;
}
}
return null;
}
}
















 4005
4005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









