







0.前言
本系列以同济大学的检索增强生成(RAG)综述[1],ACL2023 检索增强语言模型(RALM) Tutorial[2]作为参考材料,讲解RAG的前世今身,包含概述,评估方法,检索器,生成器,增强方法,多模态RAG等内容。
本篇为检索篇,介绍RAG检索器概述和三种检索器优化方法。
1.检索器概述
检索的目的是给定一个查询和一个文档集合,检索器需要对文档进行相关性排序,返回在特定需求下与查询最相关的文档列表。根据[2],文本检索中主要包含稀疏检索和稠密检索两大类。此外还有后交互检索[6],即使用跨注意力编码器直接得到两个文档的相似度,由于这种检索方式效率较低,一般用于重排,本文不单独探讨这种技术。
1.1 稀疏检索
稀疏检索不需要训练,直接通过词语重叠计算相似度,如下图。
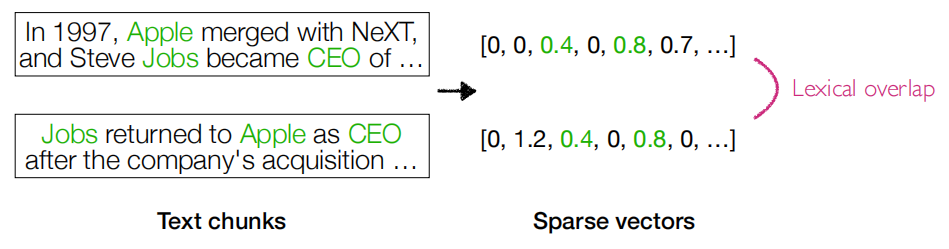
稀疏检索用于检索一般分为如下步骤:
- 对所有的文档进行分词,确定词表
- 计算每个文档词表中每个词的词频
- 利用合适算法结合词频信息将文档转换为向量
- 计算向量相似度从而进行排序检索
接下来简要介绍两个最常见算法:
- TF-IDF(term frequency–inverse document frequency)[3]
- 词频(TF)是一个给定词语在某个文档中出现频率,度量词语在某个文件中的重要性。词频是对词数的标准化,防止偏向长文档(因为长文档中可能出现更多次某个词语,即使该词语并不重要)。
- 假设文档 d j d_j dj中有K个词语, n k , j n_{k,j} nk,j是词语 t k t_k tk在文档 d j d_j dj中出现次数,则对于词语 t i t_i ti,其词频计算公式为 t f i , j = n i , j ∑ k = 1 K n k , j tf_{i,j}=\frac {n_{i,j}} {\sum_{k=1}^Kn_{k,j}} tfi,j=∑k=1Knk,jni,j。
- 逆向文档频率(IDF)是一个词语普遍重要性的度量。
- 假设一共有D个文档, d f i df_i dfi表示含有词语 t i t_i ti的文档数量,即文档频率,则对于词语 t i t_i ti,其逆向文档频率计算公式为 i d f i = log 2 ( D / d f i ) idf_i=\log_2(D/df_i) idfi=log2(D/dfi)
- 最终某个文档 d j d_j dj中词语 t i t_i ti的TF-IDF分数为 t d i d f i , j = t f i , j × i d f i tdidf_{i,j}=tf_{i,j}\times idf_i tdidfi,j=tfi,j×idfi
- 词表中每个词的TF-IDF分数拼成一个列表,组成了这个文档的向量
- TF-IDF倾向于过滤常见的词语,保留重要的词语。
- BM25(Okapi BM25)[4]
- BM25在TF-IDF基础上进行改进,主要面向信息检索。
- 假设一个查询Q含有n个词语 q 1 , q 2 , . . . , q n q_1,q_2,...,q_n q1,q2,...,qn,对于文档 d j d_j dj, f ( q i , d j ) f(q_i,d_j) f(qi,dj)表示 q i q_i qi在 d j d_j dj中出现次数, ∣ d j ∣ |d_j| ∣dj∣表示文档长度, a v g d l avgdl avgdl表示文档集合中文档的平均长度, k 1 , b k_1,b k1,b为超参数,BM25分数计算公式为: s c o r e ( d j , Q ) = ∑ i = 1 n I D F ( q i ) ⋅ f ( q i , d j ) ⋅ ( k 1 + 1 ) f ( q i , d j ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ d j ∣ a v g d l ) score(d_j,Q)=\sum_{i=1}^nIDF(q_i)\cdot\frac {f(q_i,d_j)\cdot (k_1+1)} {f(q_i,d_j)+k_1\cdot(1-b+b\cdot\frac {|d_j|} {avgdl})} score(dj,Q)=∑i=1nIDF(qi)⋅f(qi,dj)+k1⋅(1−b+b⋅avgdl∣dj∣)f(qi,dj)⋅(k1+1)
- I D F ( q i ) = ln ( N − d f q i + 0.5 d f q i + 0.5 + 1 ) IDF(q_i)=\ln(\frac {N-df_{q_i}+0.5} {df_{q_i}+0.5}+1) IDF(qi)=ln(dfqi+0.5N−dfqi+0.5+1),N表示文档数量, d f q i df_{q_i} dfqi表示含有 q i q_i qi的文档数量
1.2 稠密检索
稠密检索需要训练,一般来说使用单编码器或双编码器架构,将查询和文档分别编码为相同维度向量,并计算相似度。有代表性的工作比如DPR[5],SimCSE[9],Contriever[6]。下图演示了DPR的推理过程:
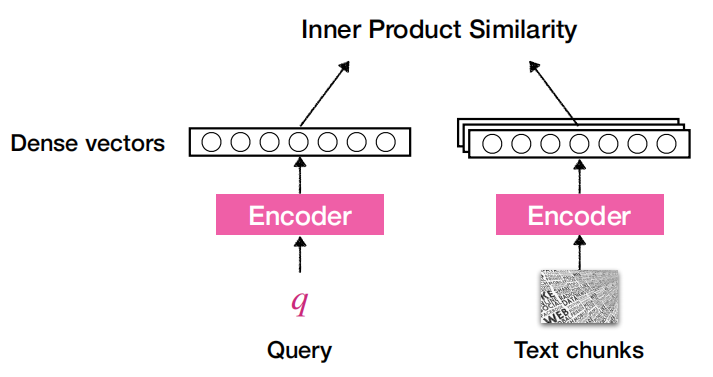
DPR采用有监督的批内对比学习的方法把查询与相关文档拉近,和不相关文档推远,如下图所示(注意,对比学习中每个相似度计算后应当除以温度参数 ,图中可以认为是 时的情况):

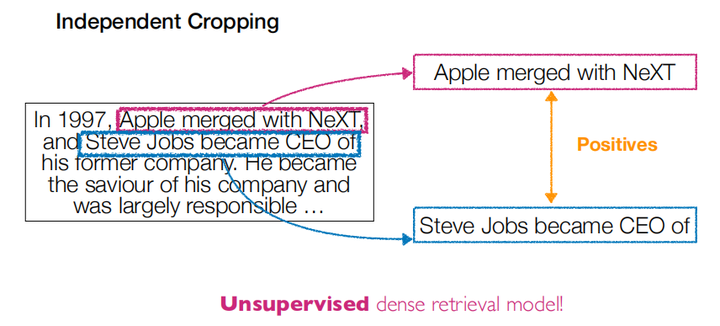
此外也可以通过无监督训练,Contriever[6]从文档中随机选取两段没有重叠的词语序列组成两个子文档,这两个子文档互相作为正例。而一个文档的子文档和其他文档的子文档互相构成了负例对,如下图所示:
1.3 检索评估
1.3.1 英文基准
- BEIR(Benchmarking-IR)[7]:包含18个检索数据集,9个任务以及不同领域。大部分不包含训练集,评估时直接进行零样本检索。开源地址:https://github.com/UKPLab/beir
- MTEB(Massive Text Embedding Benchmark)[16]:扩展了BEIR数据集,集成了56个数据集,可以对所有重要的文本编码功能进行评估,如检索、排序、聚类等。开源地址:https://github.com/embeddings-benchmark/mteb
- MS MARCO(Machine Reading Comprehension Dataset)[8]:大规模的机器阅读理解数据集,可以使用这个基准中的段落排序任务评估检索。开源地址:https://microsoft.github.io/msmarco/
- STS(semantic textual similarity)任务:STS2012-2016[13],STS-Benchmark[14],SICK-Relatedness [15],GitHub Issues Similarity Dataset[10]。此任务要求给出一对句子, 使用1~5的评分评价两者在语义上的相似程度,一般用来评估编码的质量。
1.3.2 中文基准
- C-MTEB[12]:作为MTEB的扩充,C-MTEB收集了包含6种任务类型的35个公共数据集。由于C-MTEB的规模和多样性,中文编码的所有主要功能都可以被可靠地评估,使其成为评估中文编码通用性的最合适的基准。开源地址:https://huggingface.co/C-MTEB
- MTEB-zh:选取了常用的若干中文数据集,使用MTEB的方式进行评测。开源地址:https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh
2.增强语义表示
语义表示空间对于检索至关重要,需要通过优化文本分块和微调编码模型来提升语义表示效果。
2.1 文本分块优化
选择合适的文本分块策略,需要考虑内容的性质、编码模型及其最佳块大小、用户查询的预期长度和复杂度,以及特定应用程序对检索结果的利用情况。比如对于sentence-transformer选用单句话最佳,而对于OpenAI的 text-embedding-ada-002,尽量选取256-512token长度的文本块。对于问答任务和语义检索任务来说最佳文本分块策略也不一样。一般来说对于每一个特定的场景,都存在相应的最优分块策略,没有通用的最优解。
本文介绍常见的几种策略:
- 滑动窗口:用一个固定长度的上下文窗口输入语言模型进行生成,不断根据当前窗口内的上下文多次检索相应的内容。
- 递归分块(small2big):检索小的文本块,每个小的文本块对应于一个大文本块,将大文本块输入语言模型。
- 摘要编码:检索文档的摘要对检索结果进行精排。
- 元数据过滤:使用文档的元数据来过滤无关文档。
- 图索引:将实体和关系转换为节点和边,用于解决多跳问题。
2.2 微调编码模型
一般来说需要使用预训练的编码模型将文本块转换为向量。下面介绍常见的几个模型:
-
AngIE[10]:提出了复数空间角度优化,与之前的批内对比学习,余弦目标结合,缓解了一般的余弦相似度优化中的梯度消失问题。模型架构为BERT-base。
-
Voyage[11]:面向特定领域和特定公司创建编码模型。
-
BGE[12]
- 模型架构为BERT,分为small,base,large等若干尺寸。
- 训练分为三步。第一步是预训练,在Wudao语料[17]上利用类似MAE的方式进行文本重建,即将没被遮挡的文本编码输入一个轻量解码器还原遮挡的文本。第二步是通用微调,在C-MTP[12]的无标注文本对数据集上进行对比学习。第三步是特定任务微调,在C-MTP[12]的有标注文本对数据集上进行指令编码微调,针对不同任务指令得到不同的编码。
- 开源工具:https://github.com/FlagOpen/FlagEmbedding
-
M3E[13]:
- 在2200万中文句子对上进行了批内对比学习训练。
- 开源工具:https://github.com/wangyuxinwhy/uniem
选择好了合适的编码模型,根据不同的领域和下游任务有时需要进行相应的微调。
- 领域知识微调:需要构造特定领域的编码微调数据集,包含文档集合,查询-文档对。LlamaIndex[18]开发了一系列类和函数来简化微调过程。
- 下游任务微调:有的方法利用LLM的能力来微调编码模型,Promptagator[19]利用LLM作为少样本查询生成器,并基于生成的数据创建特定于任务的检索器;LLM-Embedder[20]使用LLM对许多下游任务生成奖励信号,检索器使用数据集中的硬标签和LLM产生的软标签进行监督微调,这种方式让下游任务微调更高效。
3.对齐查询和文档
用户查询有时不够精确或缺少信息,需要对用户查询进行重写或查询向量进行转换以适配特定需求。
3.1 查询重写
用户查询有时缺少语义信息或不够精确,因此需要重写。
- Qurey2Doc[21]和ITER-RETGEN[22]提示LLM为查询创建伪文档。
- HyDE[23]提示LLM为查询生成包含核心要素的假设文档。
- RRR[24]提出了重写-检索-阅读过程,利用LLM作为重写模块的强化学习激励信号或直接用于重写模块,使得重写器能够修改和完善检索查询。
- STEP-BACKPROMPTING[25]让语言模型发现用户查询背后的定理来完善查询。多查询方法用LLM生成多个查询来检索相关文档,可以被用于复杂问题的子问题拆解。
3.2 编码转换
- LlamaIndex[18]开发了查询编码适配器模块,微调适配器将查询编码转换为对特定任务更好的编码。
- SANTA[26]使用两种预训练策略(利用内在关系对齐结构化文本和非结构化文本;遮蔽实体预测)将查询与结构化文本对齐,解决了结构化文本与非结构化文本的异质问题。
4.对齐检索器和LLM
仅优化检索器有时不一定可以提升最终效果,因为检索结果可能和LLM的需求不一致,因此需要研究如何将检索器和LLM的偏好对齐。
4.1 微调检索器
许多方法使用来自LLM的反馈信号来优化检索模型。
- AAR[27]使用FiD跨注意力分数来判断LLM的偏好文档,并使用难负例挖掘和传统的交叉熵损失,对检索器进行优化,这篇工作还发现LLM更喜欢易读的而不是信息丰富的文本。
- REPLUG[28]使用一个检索器和一个冻结的LLM来计算不同文档的概率分布(每个文档拼接进上下文后输入LLM,得到的正确答案token概率作为这个文档的概率),并用KL散度对检索器进行监督训练,不需要跨注意力机制。
- UPRISE[29]也使用冻结的LLM和一个可微调的提示词检索器,检索器用LLM返回的信号来优化。
- Atlas[30]提出了四种方法来微调编码模型:注意力蒸馏(利用LLM跨注意力分数),EMDR2(使用EM算法,将检索结果作为隐变量),复杂度蒸馏(使用生成token的复杂度作为监督信号),LOOP(利用文档删除对于LLM预测结果的影响设计损失函数)。
4.2 适配器
- PRCA[31]通过自回归策略来训练适配器,优化检索器输出的向量。
- [32]通过查询token过滤的方法来删去一些用户查询中信息含量低的token。
- RECOMP[33]使用文本摘要技术来压缩文档。
- PKG[34]将检索模块直接替换为一个白盒语言模型(比如llama),将知识注入白盒语言模型的方式,并通过白盒语言模型的输出作为增强知识给黑盒LLM提供输入。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!
5.引用
[1]Gao Y, Xiong Y, Gao X, et al. Retrieval-augmented generation for large language models: A survey[J]. arXiv preprint arXiv:2312.10997, 2023.
[2]Asai A, Min S, Zhong Z, et al. Retrieval-based language models and applications[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts). 2023: 41-46.
[3]Ramos J. Using tf-idf to determine word relevance in document queries[C]//Proceedings of the first instructional conference on machine learning. 2003, 242(1): 29-48.
[4]Robertson S, Zaragoza H. The probabilistic relevance framework: BM25 and beyond[J]. Foundations and Trends® in Information Retrieval, 2009, 3(4): 333-389.
[5]Karpukhin V, Oguz B, Min S, et al. Dense Passage Retrieval for Open-Domain Question Answering[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 6769-6781.
[6]Izacard G, Caron M, Hosseini L, et al. Unsupervised Dense Information Retrieval with Contrastive Learning[J]. Transactions on Machine Learning Research, 2022.
[7]Thakur N, Reimers N, Rücklé A, et al. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models[C]//Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). 2021.
[8]Bajaj P, Campos D, Craswell N, et al. Ms marco: A human generated machine reading comprehension dataset[J]. arXiv preprint arXiv:1611.09268, 2016.
[9]Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 6894-6910.
[10]Li X, Li J. Angle-optimized text embeddings[J]. arXiv preprint arXiv:2309.12871, 2023.
[11]VoyageAI. Voyage’s embedding models.https://docs.voyageai.com/embeddings/, 2023.
[12]Xiao S, Liu Z, Zhang P, et al. C-pack: Packaged resources to advance general chinese embedding[J]. arXiv preprint arXiv:2309.07597, 2023.
[13]Agirre E, Banea C, Cer D, et al. SemEval-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation[C]//Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). 2016: 497-511.
[14]Cer D, Diab M, Agirre E, et al. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation[J]. arXiv preprint arXiv:1708.00055, 2017.
[15]Marelli M, Bentivogli L, Baroni M, et al. Semeval-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment[C]//Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014). 2014: 1-8.
[16]Muennighoff N, Tazi N, Magne L, et al. MTEB: Massive Text Embedding Benchmark[C]//Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023: 2006-2029.
[17]Yuan S, Zhao H, Du Z, et al. Wudaocorpora: A super large-scale chinese corpora for pre-training language models[J]. AI Open, 2021, 2: 65-68.
[18]Jerry Liu. Building production-ready rag applications. https://www.ai.engineer/summit/schedule/building-production-ready-rag-applications, 2023.
[19]Dai Z, Zhao V Y, Ma J, et al. Promptagator: Few-shot Dense Retrieval From 8 Examples[C]//The Eleventh International Conference on Learning Representations. 2022.
[20]Zhang P, Xiao S, Liu Z, et al. Retrieve anything to augment large language models[J]. arXiv preprint arXiv:2310.07554, 2023.
[21]Wang L, Yang N, Wei F. Query2doc: Query Expansion with Large Language Models[J]. arXiv preprint arXiv:2303.07678, 2023.
[22]Shao Z, Gong Y, Shen Y, et al. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy[J]. arXiv preprint arXiv:2305.15294, 2023.
[23]Gao L, Ma X, Lin J, et al. Precise zero-shot dense retrieval without relevance labels[J]. arXiv preprint arXiv:2212.10496, 2022.
[24]Ma X, Gong Y, He P, et al. Query Rewriting for Retrieval-Augmented Large Language Models[J]. arXiv preprint arXiv:2305.14283, 2023.
[25]Zheng H S, Mishra S, Chen X, et al. Take a step back: evoking reasoning via abstraction in large language models[J]. arXiv preprint arXiv:2310.06117, 2023.
[26]Li X, Liu Z, Xiong C, et al. Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data[J]. arXiv preprint arXiv:2305.19912, 2023.
[27]Yu Z, Xiong C, Yu S, et al. Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In[J]. arXiv preprint arXiv:2305.17331, 2023.
[28]Shi W, Min S, Yasunaga M, et al. Replug: Retrieval-augmented black-box language models[J]. arXiv preprint arXiv:2301.12652, 2023.
[29]Cheng D, Huang S, Bi J, et al. UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation[J]. arXiv preprint arXiv:2303.08518, 2023.
[30]Izacard G, Lewis P, Lomeli M, et al. Few-shot learning with retrieval augmented language models[J]. arXiv preprint arXiv:2208.03299, 2022.
[31]Yang H, Li Z, Zhang Y, et al. PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023: 5364-5375.
[32]Berchansky M, Izsak P, Caciularu A, et al. Optimizing Retrieval-augmented Reader Models via Token Elimination[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023: 1506-1524.
[33]Recomp: Improving retrieval-augmented lms with compression and selective augmentation[J]. arXiv preprint arXiv:2310.04408, 2023.
[34]Luo Z, Xu C, Zhao P, et al. Augmented Large Language Models with Parametric Knowledge Guiding[J]. arXiv preprint arXiv:2305.04757, 2023.















 7877
7877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









