









一、机器翻译及相关技术;
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。( 例:i am chinese=我是中国人,长度变化:3—>5)
数据预处理: 将数据集清洗、转化为神经网络的输入minbatch
分词: 字符串—>单词组成的列表
建立词典: 单词组成的列表—>单词id组成的列表
载入数据集:
Encoder-Decoder: 解决“i am chinese=我是中国人”问题
encoder:输入到隐藏状态
decoder:隐藏状态到输出
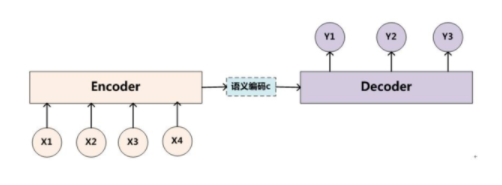
Sequence to Sequence模型:
用来解决输入输出长度都不明确的问题

Beam Search

二、注意力机制与Seq2seq模型;
注意力机制框架
Attention 是一种通用的带权池化方法,输入由两部分构成:询问(query)和键值对(key-value pairs) k i ∈ R d k k_{i}\in R^{d_{k}} ki∈Rdk , v i ∈ R d v v_{i}\in R^{d_{v}} vi∈Rdv . Query q ∈ R d q q\in R^{d_{q}} q∈Rdq, attention layer得到输出与value的维度一致 o ∈ R d v o\in R^{d_{v}} o∈Rdv . 对于一个query来说,attention layer 会与每一个key计算注意力分数并进行权重的归一化,输出的向量则是value的加权求和,而每个key计算的权重与value一一对应。
为了计算输出,首先假设有一个函数 用于计算query和key的相似性,然后可以计算所有的 attention scores
a
1
,
⋅
⋅
⋅
⋅
⋅
,
a
n
a_{1},·····,a_{n}
a1,⋅⋅⋅⋅⋅,an by
a
i
=
α
(
q
,
k
i
)
a_{i}=\alpha(q,k_{i})
ai=α(q,ki)
使用 softmax函数 获得注意力权重:
b
1
,
⋅
⋅
⋅
⋅
⋅
,
b
n
=
s
o
f
t
m
a
x
(
a
1
,
⋅
⋅
⋅
⋅
⋅
,
a
n
)
b_{1},·····,b_{n}=softmax(a_{1},·····,a_{n})
b1,⋅⋅⋅⋅⋅,bn=softmax(a1,⋅⋅⋅⋅⋅,an)
最终的输出就是value的加权求和:
o
=
∑
i
=
1
n
b
i
v
i
o=\sum_{i=1}^{n}b_iv_i
o=i=1∑nbivi

不同的attetion layer的区别在于score函数的选择。
Softmax屏蔽

点击注意力

多层感知机注意力
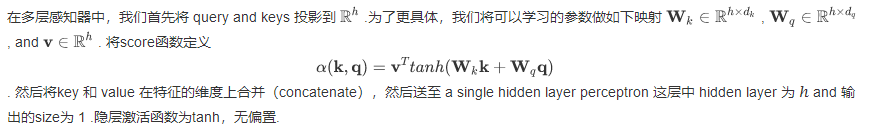
引入注意力机制的Seq2seq模型
将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的t时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合. Attetion model的输出当作成上下文信息context vector,并与解码器
D
t
D_t
Dt输入拼接起来一起送到解码器:

解码器
添加一个MLP注意层(MLPAttention),它的隐藏大小与解码器中的LSTM层相同。然后通过从编码器传递三个参数来初始化解码器的状态:
a、the encoder outputs of all timesteps:encoder输出的各个状态,被用于attetion layer的memory部分,有相同的key和values
b、the hidden state of the encoder’s final timestep:编码器最后一个时间步的隐藏状态,被用于初始化decoder 的hidden state
c、the encoder valid length: 编码器的有效长度,借此,注意层不会考虑编码器输出中的填充标记(Paddings)
在解码的每个时间步,使用解码器的最后一个RNN层的输出作为注意层的query。然后,将注意力模型的输出与输入嵌入向量连接起来,输入到RNN层。虽然RNN层隐藏状态也包含来自解码器的历史信息,但是attention model的输出显式地选择了enc_valid_len以内的编码器输出,这样attention机制就会尽可能排除其他不相关的信息。
三、Transformer
与的seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
1、Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
2、Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
3、Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。

多头注意力层
自注意力(self-attention)结构:自注意力模型是一个正规的注意力模型,序列的每一个元素对应的key,value,query是完全一致的,下图自注意力输出了一个与输入长度相同的表征序列,与循环神经网络相比,自注意力对每个元素输出的计算是并行的

多头注意力层包含 h 个并行的自注意力层,每一个这种层被成为一个head。对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这 h 个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。

基于位置的前馈网络
Transformer 模块另一个非常重要的部分就是基于位置的前馈网络(FFN),它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以称他为position-wise,这等效于一个1x1的卷积。
与多头注意力层相似,FFN层同样只会对最后一维的大小进行改变;除此之外,对于两个完全相同的输入,FFN层的输出也将相等。
Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。
这里 Layer Norm 与Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。
位置编码
Transformer模型引入位置编码去保持输入序列元素的位置。

编码器
编码器包含一个多头注意力层,一个position-wise FFN,和两个 Add and Norm层。对于attention模型以及FFN模型,输出维度都是与embedding维度一致的,这也是由于残差连接天生的特性导致的,因为要将前一层的输出与原始输入相加并归一化。
解码器
Transformer 模型的解码器与编码器结构类似,除了之前介绍的几个模块之外,编码器部分有另一个子模块。该模块也是多头注意力层,接受编码器的输出作为key和value,decoder的状态作为query。与编码器部分相类似,解码器同样是使用了add and norm机制,用残差和层归一化将各个子层的输出相连。
仔细来讲,在第t个时间步,当前输入
x
t
x_t
xt 是query,那么self attention接受了第t步以及前t-1步的所有输入
x
1
,
…
,
x
t
−
1
x_1,…,x_{t−1}
x1,…,xt−1 。在训练时,由于第t位置的输入可以观测到全部的序列,这与预测阶段的情形项矛盾,所以我们要通过将第t个时间步所对应的可观测长度设置为t,以消除不需要看到的未来的信息。

对于Transformer解码器来说,构造方式与编码器一样,除了最后一层添加一个dense layer以获得输出的置信度分数。














 1802
1802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









