







接上一篇: GoogLeNet网络讲解
网络结构
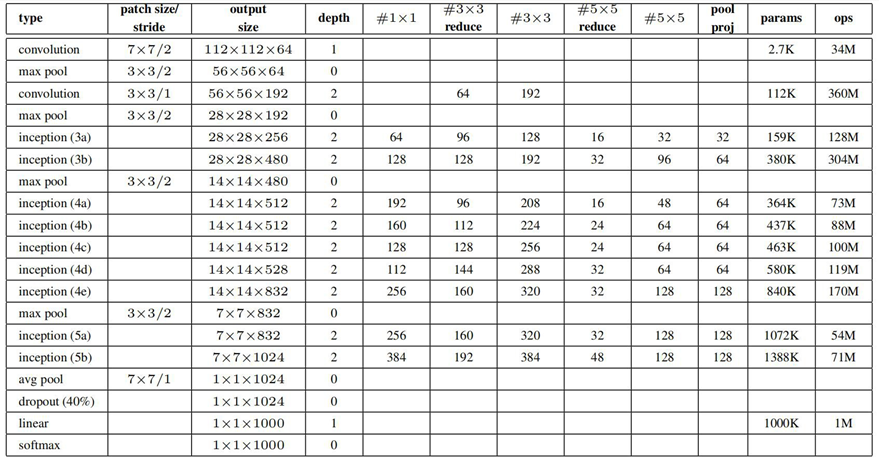
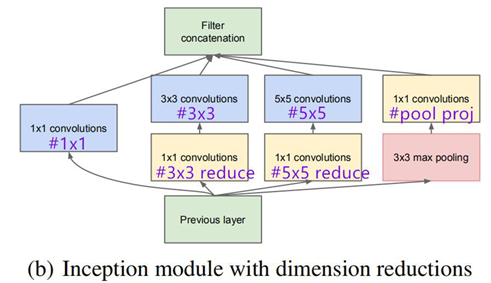
表格中#1*1代表下图中卷积核为1*1的个数,以此类推
model.py
每个inception网络结构相同,只是参数不同。因此把inception当成一个层结构,同时把两个辅助分类器当做一个层结构
当我们实例化一个模型model后,可以通过model.train()和model.eval()来控制模型状态,在model.train()模式下self.trainning=True,在model.eval()模式下self.trainning=False
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): # aux_logits是否使用辅助分类器
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
# 为了将特征矩阵的高和宽缩减为原来的一半,padding=3,(224-7+2*3)/2+1=112.5向下取整得112
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) # 如果经过最大池化下采样层后特征矩阵的大小为小数时,ceil_mode=True向上取整,=False向下取整
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits: # 辅助分类器
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化下采样层,输出特征矩阵的高和宽为1*1
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes) # 输入的展平后结点个数是1024,输出的节点个数=num_classes
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module): # inception结构模板
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
# 第一个参数为输入特征矩阵的深度,之后的六个参数分别对应表格中#1*1、#3*3reduce......
super(Inception, self).__init__()
# 第一个分支
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
# 第二个分支
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
# 第三个分支
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1), # stride=1, padding=1保证输出大小等于输入大小
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
# 首先分别得到四个分支的输出
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 将输出放入列表
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) # torch.cat将输出的四个分支进行合并,由于是在深度channel方向上合并,因此第二个参数为1,代表第一维的channel(第0维是batch)
class InceptionAux(nn.Module): # 辅助分类器模板
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) # 平均池化下采样层
# 采用之前已经定义好的BasicConv2d模板。辅助分类器采用的是128个卷积核
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024) # 输入128*4*4=2048,输出节点个数=1024
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1) # 展平处理
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module): # 把卷积层和ReLu激活函数抽象出一个模板
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torchvision
import json
import matplotlib.pyplot as plt
import os
import torch.optim as optim
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images fot validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
# net = torchvision.models.googlenet(num_classes=5)
# model_dict = net.state_dict()
# pretrain_model = torch.load("googlenet.pth")
# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",
# "aux2.fc2.weight", "aux2.fc2.bias",
# "fc.weight", "fc.bias"]
# pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}
# model_dict.update(pretrain_dict)
# net.load_state_dict(model_dict)
# num_classes=5类别个数,aux_logits=True使用辅助分类器
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
best_acc = 0.0
save_path = './googleNet.pth'
for epoch in range(30):
# train
net.train() # 训练模式时,self.trainning=True,train.py返回三个参数,需要两个辅助分类器
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device)) # 主输出、辅助分类器输出*2
loss0 = loss_function(logits, labels.to(device)) # 主分类器和真实标签的损失
loss1 = loss_function(aux_logits1, labels.to(device)) # 辅助分类器1和真实标签的损失
loss2 = loss_function(aux_logits2, labels.to(device)) # 辅助分类器2和真实标签的损失
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward() # 损失反向传播
optimizer.step() # 优化器更新
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
# validate
net.eval() # 验证时不需要两个辅助分类器
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
if __name__ == '__main__':
main()
predict.py
import torch
from model import GoogLeNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("../tulip.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model,预测时不需要两个辅助分类器
model = GoogLeNet(num_classes=5, aux_logits=False)
# load model weights
model_weight_path = "./googleNet.pth"
# 由于已经保存的模型包含了两个辅助分类器的模型参数,strict=True表示精准匹配当前模型和所需要载入的权重模型,因此此处为False(不需要两个辅助主分类器的模型参数)
missing_keys, unexpected_keys = model.load_state_dict(torch.load(model_weight_path), strict=False)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)])
plt.show()















 2247
2247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









