







⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/❗️❗️❗️知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
概述
UNSW-NB15数据集是一个用于网络入侵检测系统(NIDS)研究的大型数据集。以下是关于UNSW-NB15数据集的详细信息:
1、数据集来源:UNSW-NB15由澳大利亚新南威尔士大学(UNSW)发布,旨在提供一个全面的网络活动数据集,用于测试和评估网络入侵检测系统。
2、数据集内容:该数据集包含2,540,044条记录,分为正常和异常(攻击)网络活动。这些记录由IXIA流量生成器使用三台虚拟服务器收集,其中两台服务器配置为分发正常网络流量,第三台服务器配置为生成异常网络流量。
3、特征数量:数据集包含49个特征,包括基于包和基于流的特征。基于包的特征从包头和负载中提取,而基于流的特征使用从源到目的地的包序列生成。
4、攻击类型:攻击被分为多个类别,包括DoS、Fuzzers、Analysis、Backdoors、Exploits、Generic、Reconnaissance、Shellcode和Worms。
5、数据集分布:正常记录占数据集的87%,而所有9个攻击类别的记录仅占13%。特别是Worms攻击类别的记录仅占数据集的0.0008%。
6、数据集格式:数据集以CSV文件格式提供,包括四个文件,每个文件包含攻击和正常记录。此外,还提供了PCAP文件、BRO文件、Argus文件和报告。
7、数据集分割:数据集已经被分割为训练集和测试集,分别包含175,341条和82,332条记录。
8、数据集特点:UNSW-NB15数据集相比于其他基准数据集如DARPA98、KDD Cup 99和NSL-KDD等,结构更复杂,因此可以更可靠地评估现有的网络入侵检测系统。
9、数据集使用:在使用UNSW-NB15数据集进行学术研究时,需要引用相关的研究论文。
10、数据集问题:UNSW-NB15数据集存在类别不平衡和类别重叠的问题,这些问题在模型开发前需要得到解决。
11、可视化分析:研究中使用了PCA、t-SNE和K-means等技术对数据集进行了可视化分析,以揭示数据集的内在问题。
12、数据集预处理:在进行可视化分析之前,实施了包括去除冗余特征、归一化特征和特征缩放在内的预处理步骤。
数据集下载
数据集下载:可以从UNSW官方网站下载UNSW-NB15数据集。
https://research.unsw.edu.au/projects/unsw-nb15-dataset
数据格式及描述
关于UNSW-NB15数据集的数据格式及描述
1、数据集内容:UNSW-NB15数据集包含了九种不同的攻击类型,包括DoS、蠕虫(worms)、后门(Backdoors)、模糊测试(Fuzzers)等。数据集包含了原始网络数据包。
2、记录数量:训练集包含175,341条记录,测试集包含82,332条记录,这些记录涵盖了攻击和正常网络活动的不同类型。
3、数据格式:数据集以CSV文件格式提供,共有四个CSV文件,分别是UNSW-NB15_1.csv, UNSW-NB15_2.csv, UNSW-NB15_3.csv, 和 UNSW-NB15_4.csv。此外,还提供了PCAP文件、BRO文件、Argus文件和报告。
4、特征数量:数据集包含49个特征,这些特征包括基于包的特征和基于流的特征,以及由特定算法生成的其他特征。
5、攻击类型:攻击记录被进一步分类为九个家族,根据攻击的性质进行分类,例如Fuzzers、Analysis、Backdoors、DoS、Exploits、Generic、Reconnaissance、Shellcode和Worms。
6、数据集分布:数据集中的主要类别为正常和攻击记录。正常记录指的是自然交易数据,而攻击记录则根据攻击类型进一步细分。
7、数据集特点:UNSW-NB15数据集是为了生成真实现代正常活动和合成当代攻击行为的混合体而创建的,它包含了大量的特征和记录,适合用于复杂的网络入侵检测研究
预处理
步骤
UNSW-NB15数据集的预处理是使用该数据集进行网络入侵检测研究前的一个重要步骤。
1、数据清洗:检查数据集中的缺失值和异常值。根据,UNSW-NB15数据集在发布时已经进行了清洗,但研究者可能需要根据分析目标进行进一步的清洗。
2、格式转换:数据集以CSV格式提供,如果需要使用其他工具或软件进行分析,可能需要将数据转换为相应的格式,如ARFF格式用于Weka工具。
3、特征编码:对分类特征(如攻击类型)进行One-Hot编码或标签编码,以便于机器学习模型可以正确处理。
4、特征缩放:由于不同的特征可能具有不同的量级,进行特征缩放(如标准化或归一化)以保证模型训练的稳定性和效率。
5、数据划分:将数据集分为训练集和测试集。UNSW-NB15数据集已经预先划分了训练集和测试集,训练集包含175,341条记录,测试集包含82,332条记录。
6、数据探索:在预处理之前,通常需要对数据集进行探索,了解其分布、统计特性和潜在的问题。
7、数据集分割:根据,研究者可能会根据实验目标对数据集进行进一步的分割。
8、数据集理解:理解数据集中每个特征的含义及其对模型可能的影响
9、数据集特征:数据集共有49个特征,每种攻击的数量以及训练集和测试集的分布需要在预处理阶段进行分析。
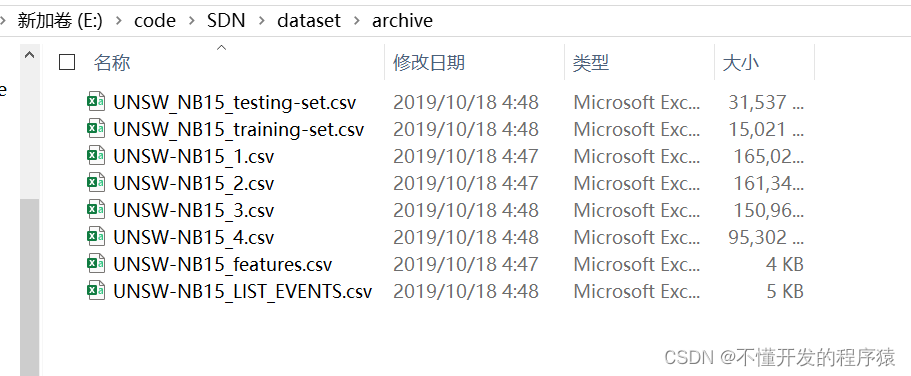
原始数据集
预处理后的数据集
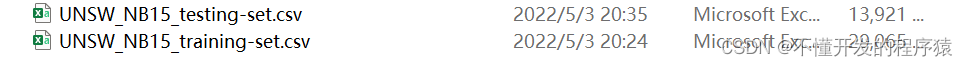
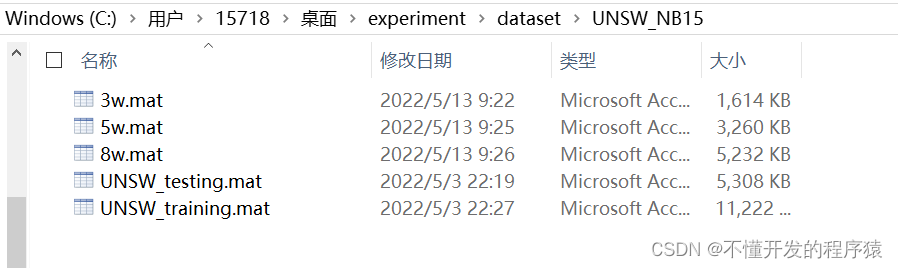
预处理结果
总结
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我


















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











