







⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计8655字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
根据问答文本预测问题所属编程语言
根据问答文本预测问题所属编程语言
实验描述:
StackOverflow是一个与程序相关的IT技术问答网站,用户在网站上提出问题,然后等待其他人的解答。由于是程序相关,因此问题被划归到各类编程语言版块下,本实验重点是通过tensorflow中的text_dataset_from_directory读取数据,并使用TextVectorization将语句进行词向量化,然后传递给神经网络模型,得到问题所属的编程语言标签。
实验环境
- Oracle Linux 7.4
- TensorFlow 2
- Python 3
实验目的
- 掌握如何使用text_dataset_from_directory读取数据
- 掌握如何使用TextVectorization将语句进行词向量化
- 掌握如何使用神经网络模型的建模、编译和训练
知识点
- text_dataset_from_directory读取数据,对数据文件夹存放形式有要求
- TextVectorization词向量化有多种输出方式,如binary、int等
- 文本需向量化后,转化为高维向量才能作为神经网络模型的输入
实验分析

任务实施过程
一、打开Jupyter,并新建python工程
1.桌面空白处右键,点击Konsole打开一个终端
切换至/experiment/jupyter目录
cd experiment/jupyter
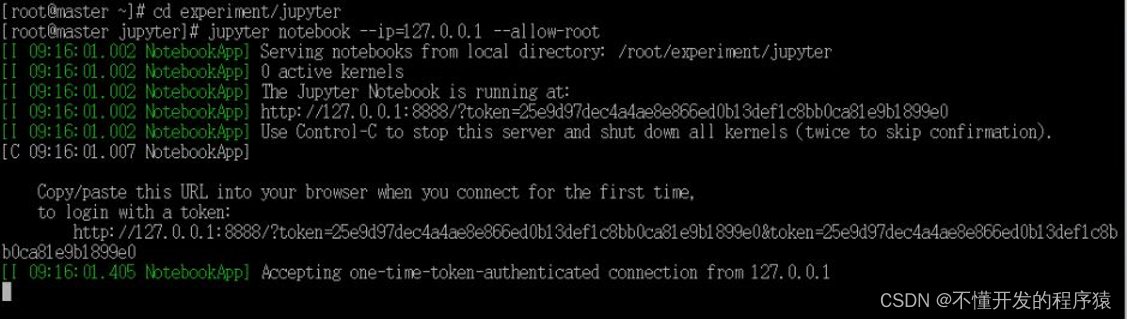
2.启动Jupyter,root用户下运行需加’–allow-root’
jupyter notebook --ip=127.0.0.1 --allow-root
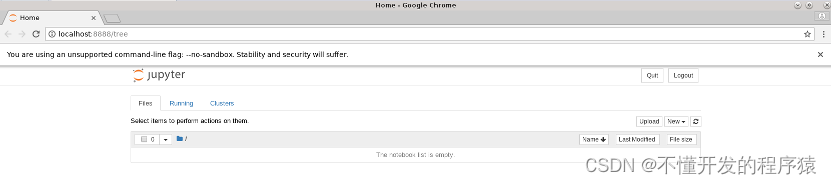
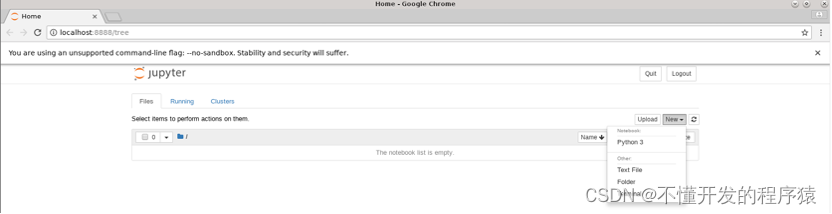
3.依次点击右上角的 New,Python 3新建python工程
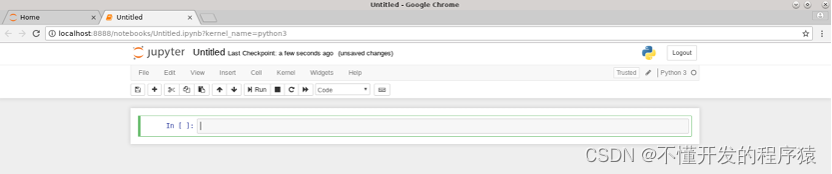
4.点击Untitled,在弹出框中修改标题名,点击Rename确认
二、加载工具,查看、处理数据
- 加载工具,查看数据文件结构,初步了解数据内容
# 加载试验所需用到的功能
import collections
import pathlib
import re
import string
import tensorflow as tf
from tensorflow.keras import layers,losses,preprocessing,utils
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
# 定义数据路径
data_path = '/root/experiment/datas/nlp/'
dataset_dir = pathlib.Path(data_path+'stackoverflow')
# 查看路径下的文件及文件夹
list(dataset_dir.iterdir())
# 查看训练集的文件及文件夹
train_dir = dataset_dir/'train'
list(train_dir.iterdir())
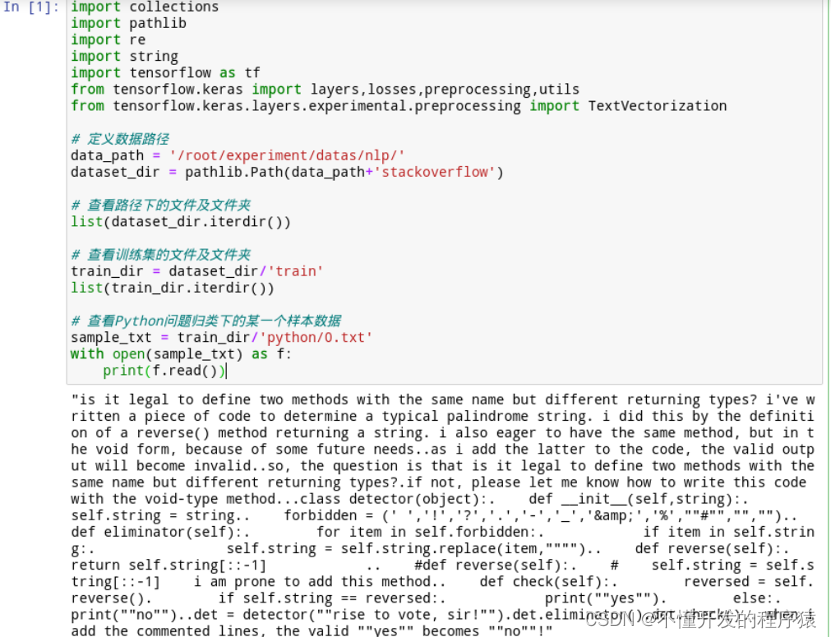
# 查看Python问题归类下的某一个样本数据
sample_txt = train_dir/'python/0.txt'
with open(sample_txt) as f:
print(f.read())
- 读取训练集、验证集、测试集,并查看数据和标签
batch_size = 32
seed = 42
# 使用text_dataset_from_directory方式读取数据
raw_train_ds = preprocessing.text_dataset_from_directory(
train_dir,
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
# 从读取的数据集中提取一个batch的数据,并使用for循环查看batch的前三项
for text_batch, label_batch in raw_train_ds.take(1):
for 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











