






项目github地址:https://github.com/xsfmGenius/Ner_Bert_CoNLL-2003
数据集下载地址:https://www.clips.uantwerpen.be/conll2003/ner/
数据集介绍
数据格式
每个词占一行,以空行分割句子,数据样例如下:
| 词 | 词性 | 语法块 | 实体标签 |
|---|---|---|---|
| SOCCER | NN | B-NP | O |
| - | : | O | O |
| JAPAN | NNP | B-NP | B-LOC |
| GET | VB | B-VP | O |
| … | … | … | … |
在Ner任务中,我们只需要关注词和实体标签,即第一列和最后一列,不需要用到词性和语法块。
标注方法
BIO标注法,B-begin,代表实体的开头;I-inside,代表实体的中间或结尾;O-outside,代表不属于实体。
实体分为四类:人名(PER)、地名(LOC)、组织名(ORG)、其他实体名(MISC)。
共组成九种实体标签:
| 实体标签 | 含义 |
|---|---|
| O | 非实体 |
| B-PER | 人名开头 |
| I-PER | 人名中间或结尾 |
| B-LOC | 地名开头 |
| I-LOC | 地名中间或结尾 |
| B-ORG | 组织名开头 |
| I-ORG | 组织名中间或结尾 |
| B-MISC | 其他实体开头 |
| I-MISC | 人名中间或结尾 |
数据预处理
原始数据存储在txt文件中,需要按行读取数据。如果不是空行提取词和标签加入的一个列表中;是空行说明这句话结束了,将进行提取的列表加入到全部数据的列表中。
# 读取数据
def readFile(name):
data = []
label = []
dataSentence = []
labelSentence = []
with open(name, 'r') as file:
lines = file.readlines()
for line in lines:
if not line.strip():
data.append(dataSentence)
label.append(labelSentence)
dataSentence = []
labelSentence = []
else:
content = line.strip().split()
dataSentence.append(content[0].lower())
labelSentence.append(content[-1])
return data, label
trainData, trainLabel = readFile('train.txt')
devData, devLabel = readFile('dev.txt')
testData, testLabel = readFile('test.txt')
效果如下:


label2index
将八个标签转化为序号。遍历标签,如果该标签没有对应的index则新增字典项,否则跳过。返回label2index和index2label。
def label2index(label):
label2index = {}
for sentence in label:
for i in sentence:
if i not in label2index:
label2index[i] = len(label2index)
return label2index,list(label2index)
效果如下:


构建数据集
使用’bert-base-uncased’预训练Bert模型,生成Dataset和DataLoader。
继承Dataset类并改写函数,指定maxlength,若该句长度大于maxlength则裁剪,若小于则补充。
tokernizer.encode根据传入的tokenizer将词映射为index,truncation=True,加入首尾标记,因此最大长度+2;return_tensors="pt"返回张量便于后续计算;add_special_tokens=True,padding="max_length"对于长度不够maxlength的句子进行padding。
label根据data构造进行对齐,补充收尾标记及padding。
class Dataset(Dataset):
def __init__(self, data, label, labelIndex, tokenizer, maxlength):
self.data = data
self.label = label
self.labelIndex = labelIndex
self.tokernizer = tokenizer
self.maxlength = maxlength
def __getitem__(self, item):
thisdata = self.data[item]
thislabel = self.label[item][:self.maxlength]
thisdataIndex = self.tokernizer.encode(thisdata, add_special_tokens=True, max_length=self.maxlength + 2,
padding="max_length", truncation=True, return_tensors="pt")
thislabelIndex = [self.labelIndex['O']] + [self.labelIndex[i] for i in thislabel] + [self.labelIndex['O']] * (
maxlength + 1 - len(thislabel))
thislabelIndex = torch.tensor(thislabelIndex)
# print(thisdataIndex.shape)
# print(thislabelIndex.shape)
return thisdataIndex[-1], thislabelIndex,len(thislabel)
def __len__(self):
return self.data.__len__()
if hasattr(torch.cuda, 'empty_cache'):#清缓存
torch.cuda.empty_cache()
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
trainDataset = Dataset(trainData, trainLabel, labelIndex, tokenizer, maxlength)
trainDataloader = DataLoader(trainDataset, batch_size=batchsize, shuffle=False)
devDataset = Dataset(devData, devLabel, labelIndex, tokenizer, maxlength)
devDataloader = DataLoader(devDataset, batch_size=batchsize, shuffle=False)
建模
继承并改写nn.Module类,模型由Bert预训练模型和一个全连接层组成,Bert输出维度为768。根据是否传入label判断是训练还是验证,训练返回loss,验证返回预测值。
# 建模
class BertModel(nn.Module):
def __init__(self, classnum, criterion):
super().__init__()
self.bert = BertForPreTraining.from_pretrained('bert-base-uncased').bert
self.classifier = nn.Linear(768, classnum)
self.criterion = criterion
def forward(self, batchdata, batchlabel=None):
bertOut=self.bert(batchdata)
bertOut0,bertOut1=bertOut[0],bertOut[1]#字符级别bertOut[0].size()=torch.Size([batchsize, maxlength, 768]),篇章级别bertOut[1].size()=torch.Size([batchsize,768])
pre=self.classifier(bertOut0)
if batchlabel is not None:
loss=self.criterion(pre.reshape(-1,pre.shape[-1]),batchlabel.reshape(-1))
return loss
else:
return torch.argmax(pre,dim=-1)
criterion = nn.CrossEntropyLoss()
model = BertModel(len(labelIndex), criterion).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
训练验证
正常的训练验证流程,训练时声明训练,反向传播,更新权重,累计损失并在该次训练结束后计算平均损失。
验证时声明验证,不进行参数更新,将返回的预测结果和实际的标签去除padding部分,并转换回原本的标签,计算accuracy和f1。
for e in range(epoch):
#训练
time.sleep(0.1)
print(f'epoch:{e+1}')
epochPlt.append(e+1)
epochloss=0
model.train()
for batchdata, batchlabel,batchlen in tqdm(trainDataloader,total =len(trainDataloader),leave = False,desc="train"):
batchdata=batchdata.to(device)
batchlabel = batchlabel.to(device)
loss=model.forward(batchdata, batchlabel)
epochloss+=loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
epochloss/=len(trainDataloader)
trainLossPlt.append(float(epochloss))
print(f'loss:{epochloss:.5f}')
# print(batchdata.shape)
# print(batchlabel.shape)
#验证
time.sleep(0.1)
epochbatchlabel=[]
epochpre=[]
model.eval()
for batchdata, batchlabel,batchlen in tqdm(devDataloader,total =len(devDataloader),leave = False,desc="dev"):
batchdata=batchdata.to(device)
batchlabel = batchlabel.to(device)
pre=model.forward(batchdata)
pre=pre.cpu().numpy().tolist()
batchlabel = batchlabel.cpu().numpy().tolist()
for b,p,l in zip(batchlabel,pre,batchlen):
b=b[1:l+1]
p=p[1:l+1]
b=[indexLabel[i] for i in b]
p=[indexLabel[i] for i in p]
epochbatchlabel.append(b)
epochpre.append(p)
# print(pre)
acc=accuracy_score(epochbatchlabel,epochpre)
f1=f1_score(epochbatchlabel,epochpre)
devAccPlt.append(acc)
devF1Plt.append(f1)
print(f'acc:{acc:.4f}')
print(f'f1:{f1:.4f}')
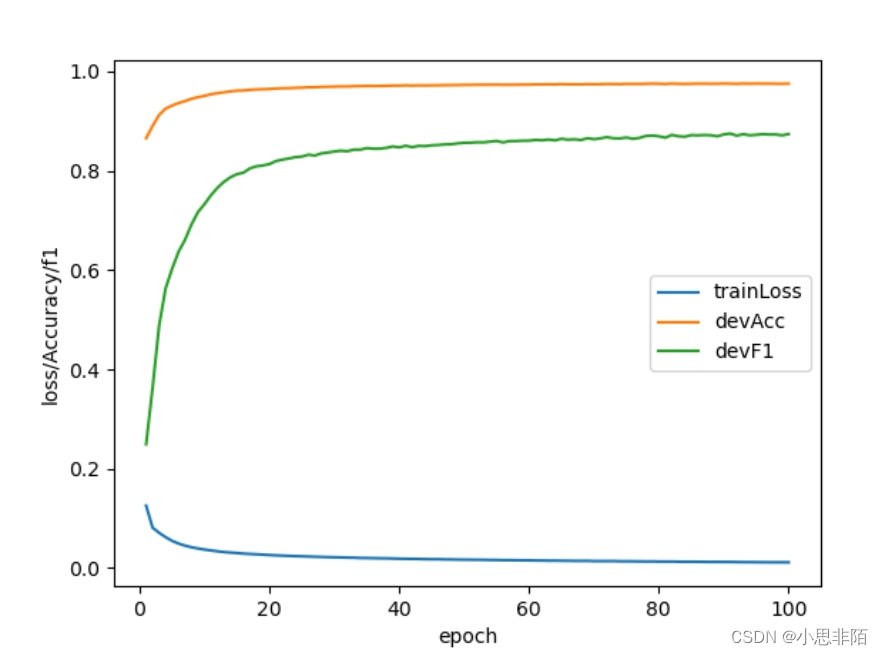
画图
#绘图
# print(epochPlt, trainLossPlt,devAccPlt,devF1Plt)
plt.plot(epochPlt, trainLossPlt)
plt.plot(epochPlt, devAccPlt)
plt.plot(epochPlt, devF1Plt)
plt.ylabel('loss/Accuracy/f1')
plt.xlabel('epoch')
plt.legend(['trainLoss', 'devAcc', 'devF1'], loc='best')
plt.show()
参数设置
| 参数 | 说明 | 值 |
|---|---|---|
| batchsize | 批次大小 | 64 |
| epoch | 训练次数 | 100 |
| maxlength | 句子固定长度 | 75 |
| lr | 学习率 | 0.01 |
| weight_decay | 权重衰减 | 0.00001 |
| crition | 损失函数 | CrossEntropyLoss |
| optimizer | 优化器 | SGD |
实验结果
f1基本稳定在0.87左右,优化空间比较大,后续可以考虑加入LSTM和crf进一步提升效果。















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









