










前言:从2021年10月接触到医学报告生成(Medical Report Generation,MRG)任务以来,感触颇深。本期分享一下之前读过的几篇2023年的文章,希望能够对这个了领域的初学者有帮助。
(2023TMM) Semi-supervised Medical Report Generation via Graph-guided Hybrid Feature Consistency
研究动机/存在问题:
-
报告生成数据集标注成本高并且受到隐私保护协议的制约,导致规模不够
-
局部病理变化的内在关系往往被忽略
贡献:
首次在医学报告生成领域引入了知识蒸馏,并提出了 Relation-Aware Mean Teacher (RAMT) 解决数据不足问题
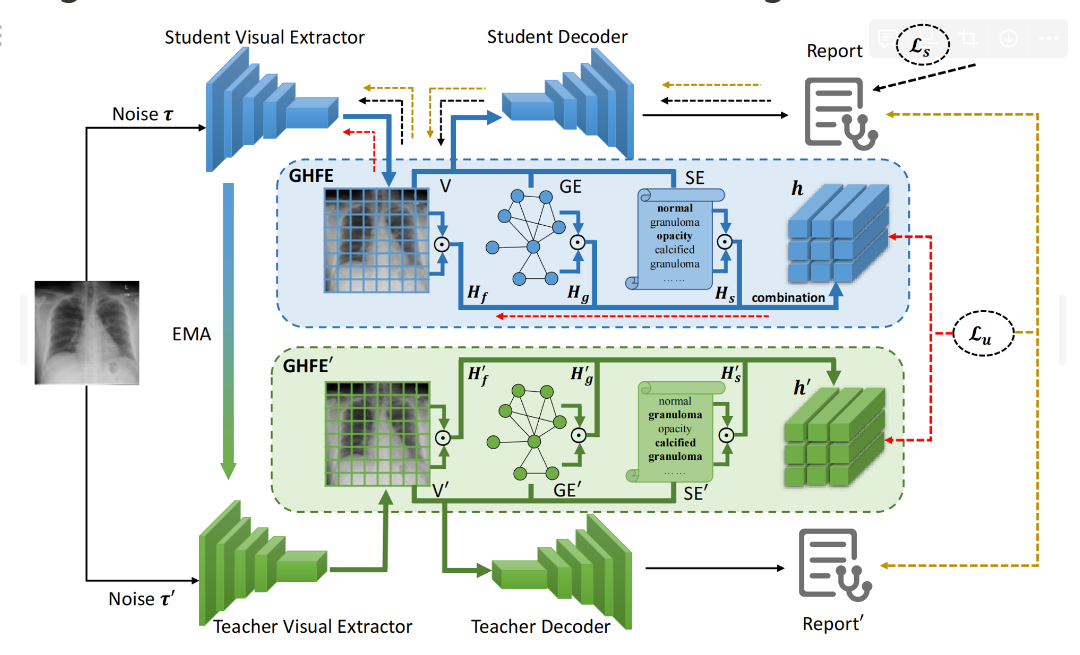
GE使用疾病知识图将病理变化之间的关系编码到特征嵌入中。SE学习一个单词字典,从这里可以检索到每个病理变化的语义嵌入,从而实现细粒度的疾病描述。
在两个常用的公共基准医疗报告数据集上进行了广泛的实验,结果证明了方法的有效性。
方法核心:
主要看学生和教师网络是如何交互的,这里有两个无监督损失
报告一致性损失:使用两个网络提取加噪声的图片并分别生成告,采用KL散度计算报告的一致性
中间一致性表示:得到教师和学生网络的向量化的中间表示,并采用L2范式拟合
疑问:
什么是内在关系,什么是局部变化,是指同一症状的样本与样本之间图像像素的差异吗
带着疑问继续阅读
在引言部分,说明白了研究问题,引入了报告生成工作后,两个问题分两段。
第一个问题好理解,作者通过和image caption数据集规模对比的方式印证这个问题
第二个问题主要是指疾病的产生/变化,不是独立进行的,而是互相带有一定隐式关系的,这种关系有助于为报告生成提供一种暗示,但在先前缺乏考虑,导致这些局部的变化与报告中的对应描述具有较弱的一致性。
研究方法
采用了一个半监督学习的知识蒸馏框架,用于呼应问题1
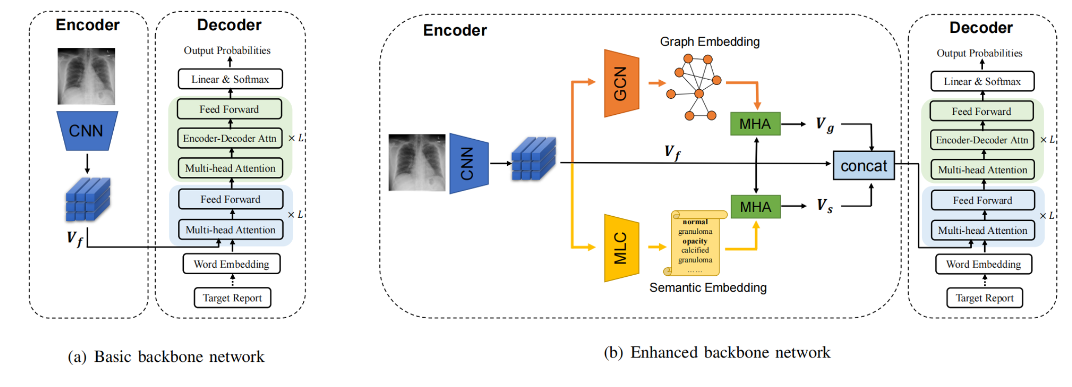
在教师网络和学生网络应用一个GHFE框架,用于呼应问题2
这个GHFE框架包含两个重要的部分,一个用于提取图特征,一个用于提取语义特征,其都是基于当前的视觉特征出发的,两者分别用于表达病理改变之间的关系、编码病理改变的特征。
最后,将图特征、语义特征以及视觉特征相合并组成的混合特征输入解码器中,生成报告
实验设计
关于实验,将模型设计了多种
设定,分别是采用25%的成对数据训练、采用25%的成对数据与75%的不成对数据进行训练、采用100%的成对数据进行训练,并将模型与诸多全监督模型进行对比,发现半监督方案能够与以往全监督的模型达到大致持平的效果,证明了学习到了病理变化的内在特征。
消融实验根据混合特征的成分进行设计,具体的分析见文章,其中许多的表达可以学习,比如将报告与attmap建立联系的说法。
定性实验给出了报告生成示例和attmap,分析了attmap的特点,值得借鉴,这些结果表明GHFE模块确实增强了RAMT对学习特定图像区域之间的图像-文本映射的鲁棒性。
敏感性试验围绕β的取值设计,可以借鉴其呈现的形式——表格+折线,并学习阈值的选取模式与原因分析。
总的来说,通篇逻辑闭环不错,方法有创新,实验部分回扣主题比较好,分析得也很深入,尤其是对病理关系的分析,涉及了报告、图谱、attmap三者的对应关系,容易受认可。
(2023arxiv) Towards Medical Artificial General Intelligence via Knowledge-Enhanced Multimodal Pretraining
动机:
设计针对医疗数据的强泛化模型是一项困难的任务,大多数现有的方法倾向于开发针对特殊任务的模型。
贡献:
面向医学人工通用智能,本文提出了一种新的范式,称为Medical-knOwledge-enhanced mulTimOdal pretRaining (MOTOR),即一种新的知识增强医学多模式预训练范式,其能够理解和生成医学内容,从而推进了现有的工作。
核心方法:
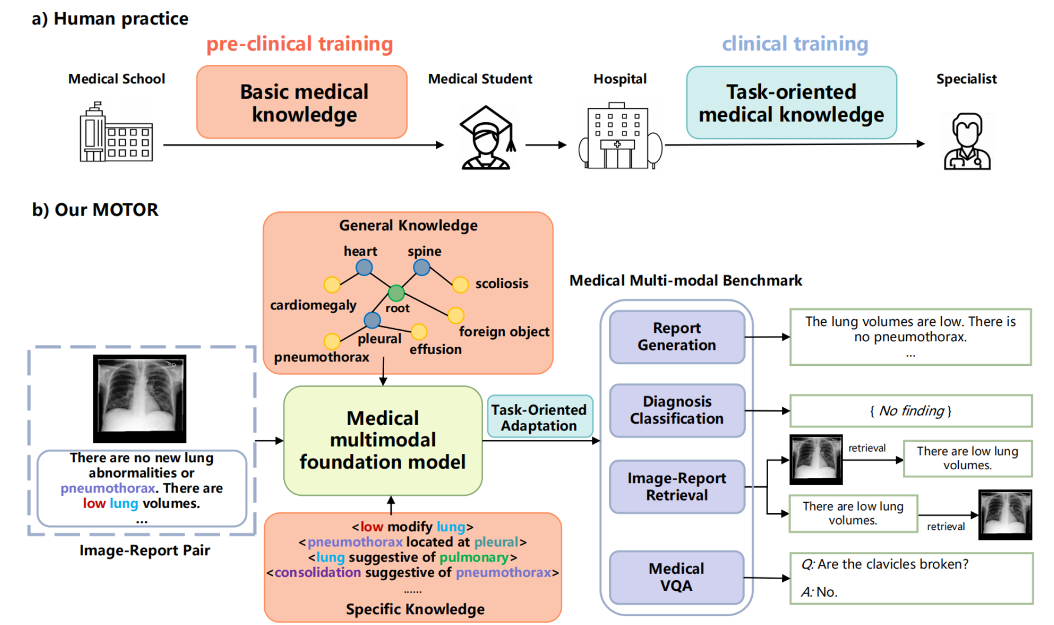
提出了一种通用模型,解决医学报告生成、医学图像分类、医学问答等任务。其核心思想是,首先预训练一个基础模型来学习通用的医学知识,其次学习针对于每个任务的特定知识。该模型使用了两种互补的医学知识——全局知识(Zhang等人的固定图谱)和细节知识(针对于样本的三元组),设计了特定的方法提取这些知识并建立全局与细节知识的对应关系(器官与病灶的对齐),之后将知识嵌入视觉特征并学习视觉-文本特征的映射,从而增强模型对医学病理的表征。

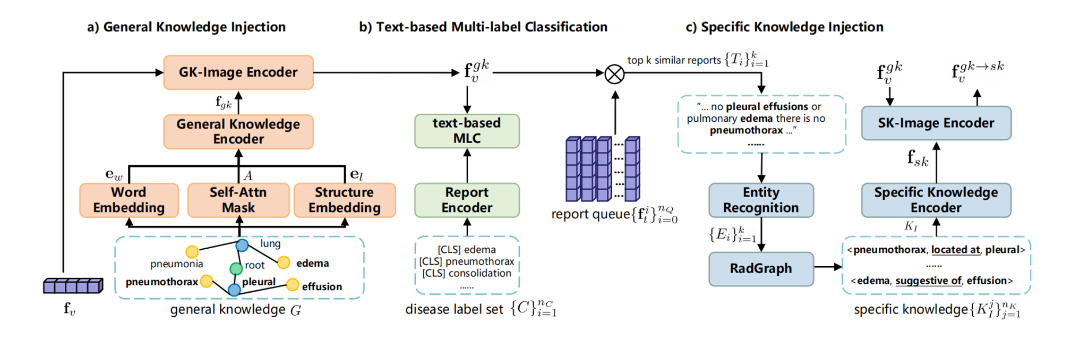
总体框架图,预训练模仿医学学生的通用知识学习过程,微调模仿专家对专业医学知识的学习。
知识融合过程分成了三个部分,全局知识并入、基于文本的分类、细节知识并入。
进行了充分的实验,比如可视化了模型关注的重点病理词汇与病理区域(器官与病灶),可视化了视觉与文本模态中病理特征的分布(证明模态表征一致性的学习能力)。
(2023CVPR) KiUT: Knowledge-injected U-Transformer for Radiology Report Generation
非常interesting的work
动机:
医学报告生成领域需要医学知识的注入。然而,由于异构的上下文嵌入空间,直接采用该知识会带来不一致性。而过于复杂的知识可能会分散视觉编码器的注意力,并转移表示。
贡献:
提出了一种新的模型,遵循具有u型连接的编码解码器架构,它充分利用了不同层次的视觉信息,而不是只有一个来自视觉模态的单一输入。
提出的模型通过构建症状图,注入临床知识,将其与视觉和上下文信息相结合,并在解码阶段生成最终单词时提取临床知识。
开发了区域关系编码器,以恢复图像区域之间的外在关系和内在关系,以提取异常区域特征,这在医学领域至关重要。
核心方法:
提出了一种知识注入的u型Transformer(KiUT)来学习多层次的视觉表示,并自适应地提取具有上下文和临床知识的信息,用于单词预测。
与之前在视觉特征中注入知识的方法不同,本文在最后的解码阶段引入外部知识来增强特征提取。此外,在专业医生的指导下,构建了一个包含临床实体,即症状及其关系的图表。这些实体与训练语料库具有均匀的嵌入空间,该信号可以平滑地注入视觉和上下文信息。之后,进一步在解码器之上设计了注入知识蒸馏器,从视觉、语境和临床知识中提取有价值的知识。
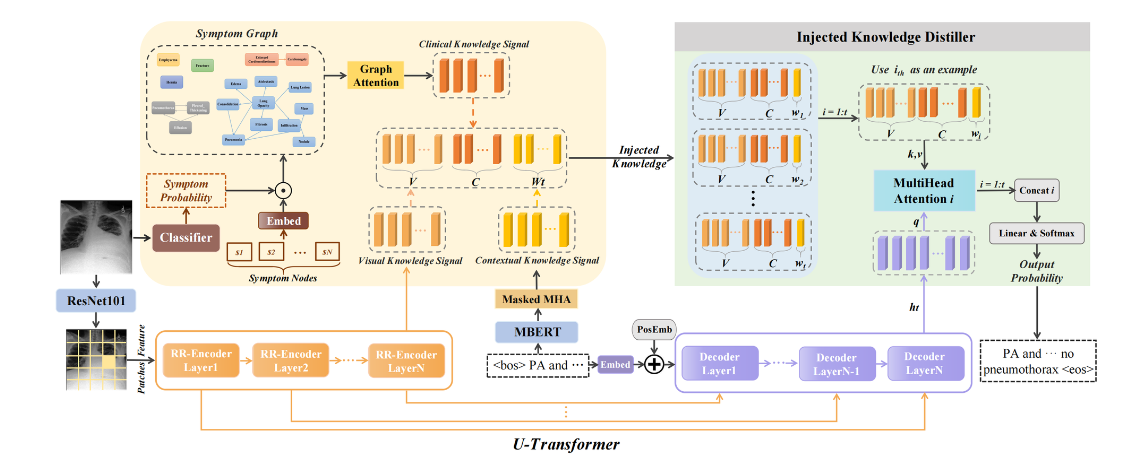 总体结构如上,“U连接”和“在解码端融合知识”的设计比较有意思
总体结构如上,“U连接”和“在解码端融合知识”的设计比较有意思
此外,图谱的构建和使用也具有一定的创新
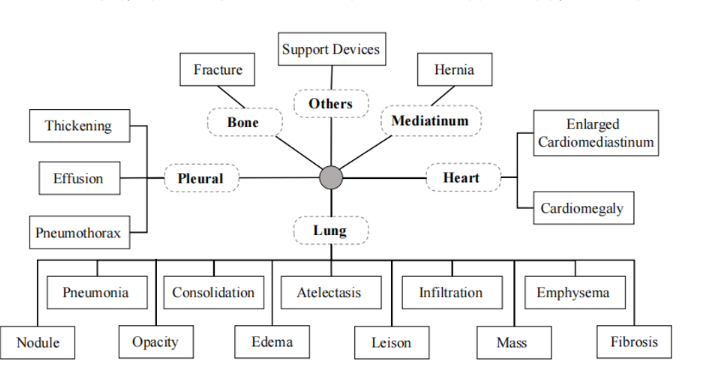
此处图谱采用word embedding初始化,文本特征使用MBERT提取。对于样本而言,给出图像,对其进行病理分类,根据每类病理的概率值调整图谱的内容,并对报告生成作出提示。
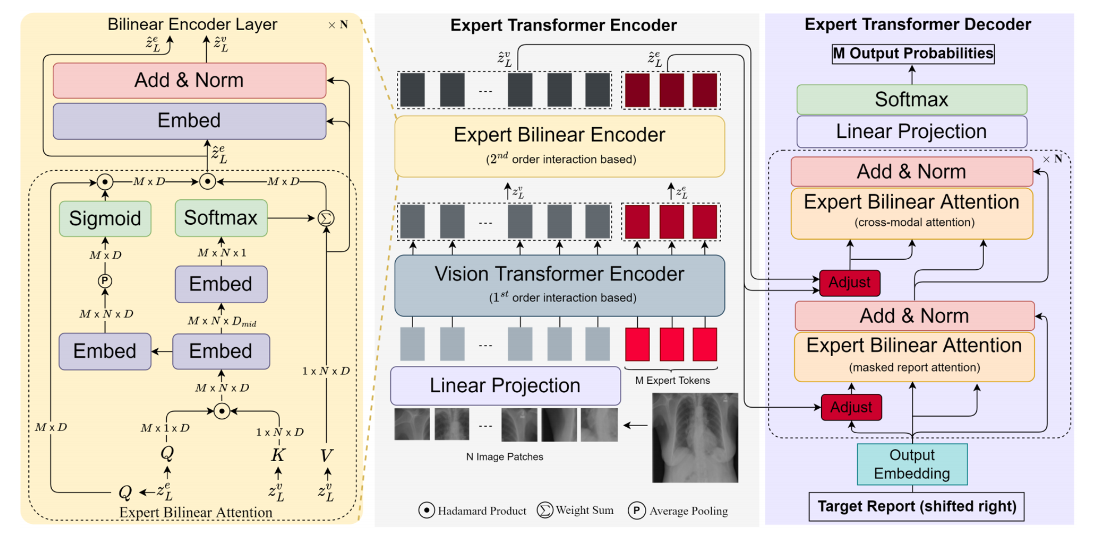
(2023CVPR)METransformer Radiology Report Generation by Transformer with Multiple Learnable Expert Tokens
动机:
在临床情况下,多专家会诊可以显著地有利于诊断,特别是对复杂的病例。这激励我们探索一种“多专家联合诊断”机制,以升级现有文献中常见的“单一专家”框架。
贡献:
首先,提出了一个新的METransformer框架,通过引入可学习的专家标记,来生成放射学报告,并有助于学习线性和非线性注意的互补表示。
其次,模型具有集成方法的优势。由于精心设计的网络结构和端到端训练方式,模型可以获得比普通集成方法更好的效果,同时大大降低了训练参数,提高了训练效率。
第三,方法在IU-Xray和MIMIC-CXR上显示出了良好的性能。
方法:
提出了一种用基于变压器的骨干来模拟多专家会诊。该方法的关键设计是在Transformer编码器和解码器中同时引入多个可学习的“专家”token。在编码器中,每个专家令牌都与视觉令牌和其他专家令牌进行交互,以学习参加不同的图像区域以进行图像表示。这些专家标记被鼓励通过一个正交损失来捕获互补信息,从而最小化它们的重叠。在解码器中,每个参与的专家标记引导输入词和视觉标记之间的交叉注意,从而影响生成的报告。进一步设计了一种基于指标的专家投票策略,以生成最终报告。该模型具有集成学习的优点,并支持专家之间的复杂交互。
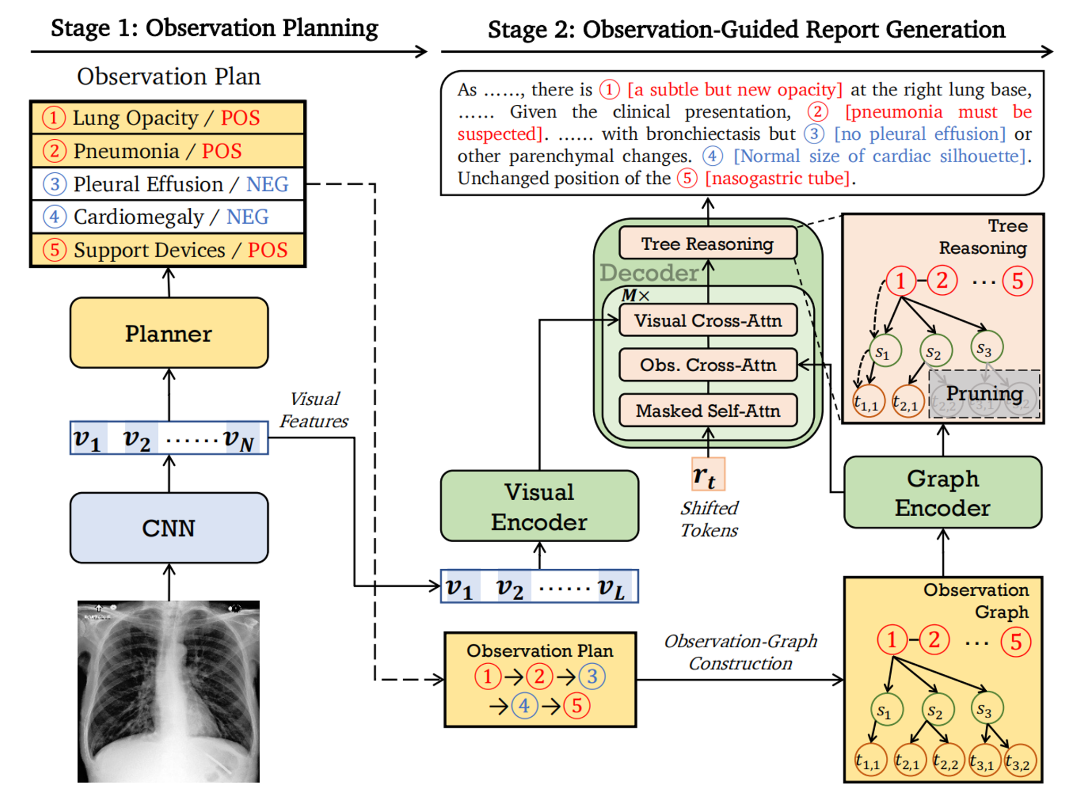
(2023ACL)ORGAN Observation-Guided Radiology Report Generation via Tree Reasoning
动机:
MRG的一个重大挑战是如何正确地保持图像和冗长的报告之间的一致性。以往的研究探索了通过planning-based方法来解决这个问题,该方法仅基于high-level plans生成报告。然而,这些计划通常只包含主要观察结果(如肺混浊),缺乏许多必要的信息,如观察特征和初步的临床诊断。
贡献:
提出了Observation-guided radiology Report GenerAtioN framework (ORGAN),它可以保持x线片和生成的自由文本报告之间的临床一致性。
基于训练语料库构建了一个包含观测值、n-gram和token的三级观测图。然后,对图进行树状推理,以动态地选择与观察相关的信息。
核心方法:
在本文中,提出了Observation-guided radiology Report GenerAtioN framework (ORGAN)。首先生成一个观测计划,然后将计划和射线片同时用于生成报告,其中采用观测图和树推理机制,通过捕获每个观测的多种格式来精确地丰富计划信息。
方法包含两个阶段:
在第一阶段,根据给定的图像制定观察计划,其中包括来自x光片的主要发现及其状态(即阳性、阴性和不确定)。
在第二阶段,将图像和观测计划都输入Transformer来生成报告。本文设计了一种树推理机制,精确地丰富简洁的观测计划。具体来说,构建了一个三级观测图,以高级观测为第一级,以观测感知的n-gram为第二级,以特定token为第三层。这些观测感知的n-gram捕获了对观测的不同常见描述,并作为观测提到的组成部分。然后,使用树推理机制,通过动态聚合图中的节点来捕获观察感知信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









