






大模型中的位置编码Rope + Llama3 源码示例 详解
今天由于idea的需要接触到了position embedding的细节知识,顺便做了一个梳理
首先,提供一些链接去学习rope的基础知识
位置编码基础:https://zhuanlan.zhihu.com/p/454482273
苏神原文:https://arxiv.org/abs/2104.09864
Rope知乎上的博客:https://zhuanlan.zhihu.com/p/642884818
https://zhuanlan.zhihu.com/p/647109286
了解原理后,我们直接看公式
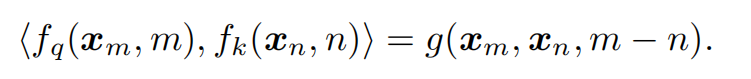
我们的目标是找到functions
f
q
(
.
)
f_q(.)
fq(.)和
f
k
(
.
)
f_k(.)
fk(.),使其满足这个等式
这个等式是什么意思呢?
x
m
x_m
xm表示第m个token的feature,
f
q
(
x
m
,
m
)
f_q(x_m, m)
fq(xm,m)表示融合m位置编码后的
x
m
x_m
xm
x
n
x_n
xn表示第n个token的feature,
f
k
(
x
n
,
n
)
f_k(x_n, n)
fk(xn,n)表示融合m位置编码后的
x
n
x_n
xn
<
f
q
(
x
m
,
m
)
,
f
k
(
x
n
,
n
)
>
<f_q(x_m, m), f_k(x_n, n)>
<fq(xm,m),fk(xn,n)>表示inner product,内积
g表示一种方法,输入是
x
m
x_m
xm,
x
n
x_n
xn,以及相对位置
m
−
n
m - n
m−n
我们直接看作者给出的solution(详细推导见上面博客链接)
这是一个2D的情形,就是token embedding只有2维时:
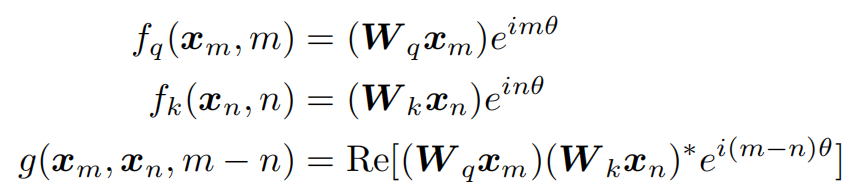
下面是具体的展开
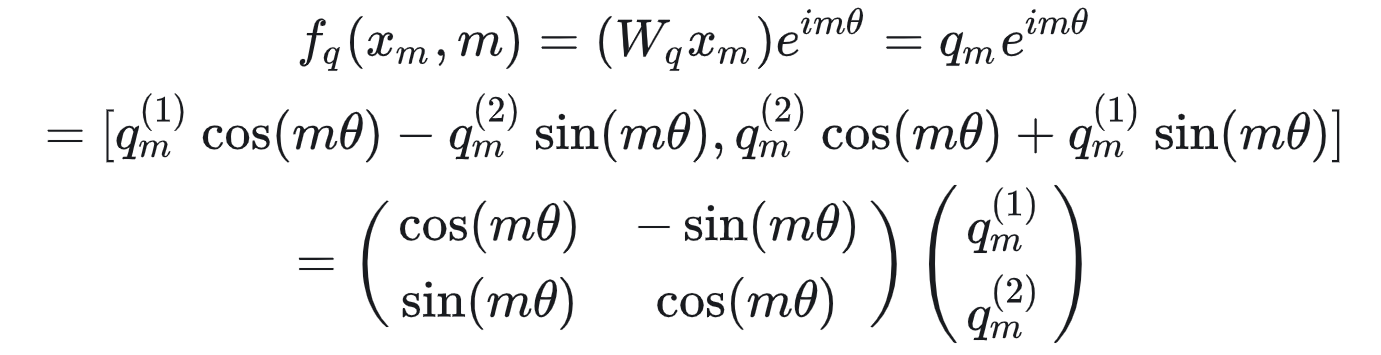 我们可以看到,其实只需要在
q
q
q前面乘上一个旋转角矩阵,就可以完成这个目标
我们可以看到,其实只需要在
q
q
q前面乘上一个旋转角矩阵,就可以完成这个目标
那么上升到多维的场景,可以表示为这样:
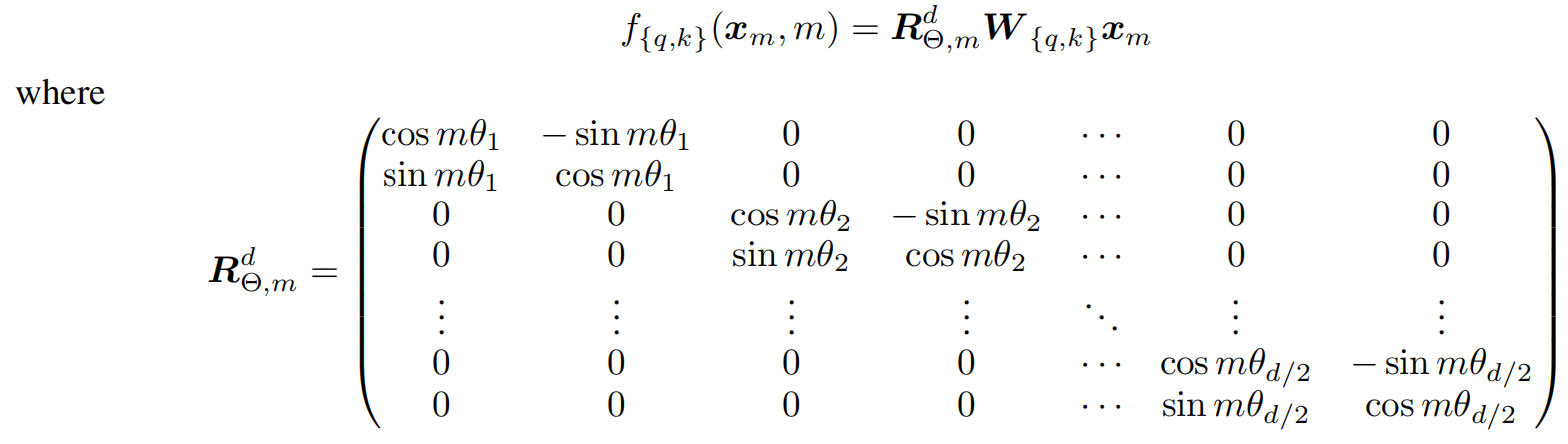
由于
R
R
R太过稀疏,为了提高计算效率,作者给出了等价计算方法(该方法被广泛用在LLM中):
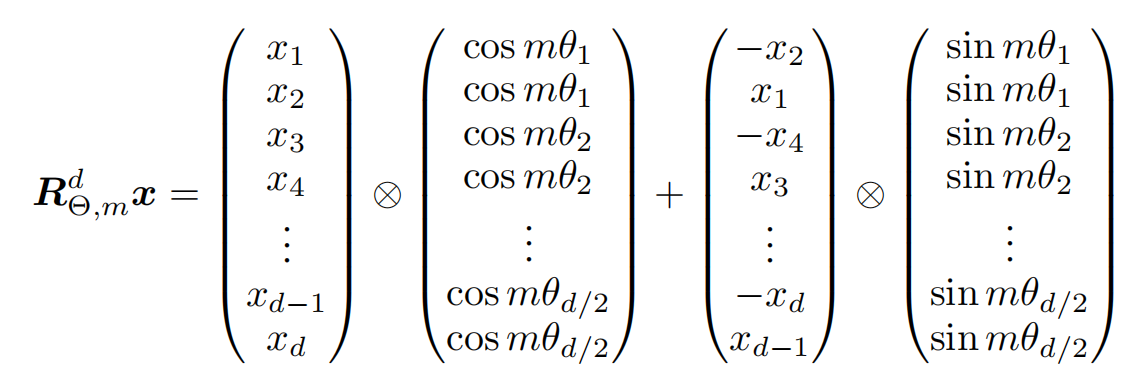
所以这就是我们需要计算的公式,至于其中具体的性质、意义及推导,前面提供的链接中已经讲得非常明白了,这里不再阐述
在注意力机制中,我们仅对
q
q
q和
k
k
k套用这个公式计算位置编码
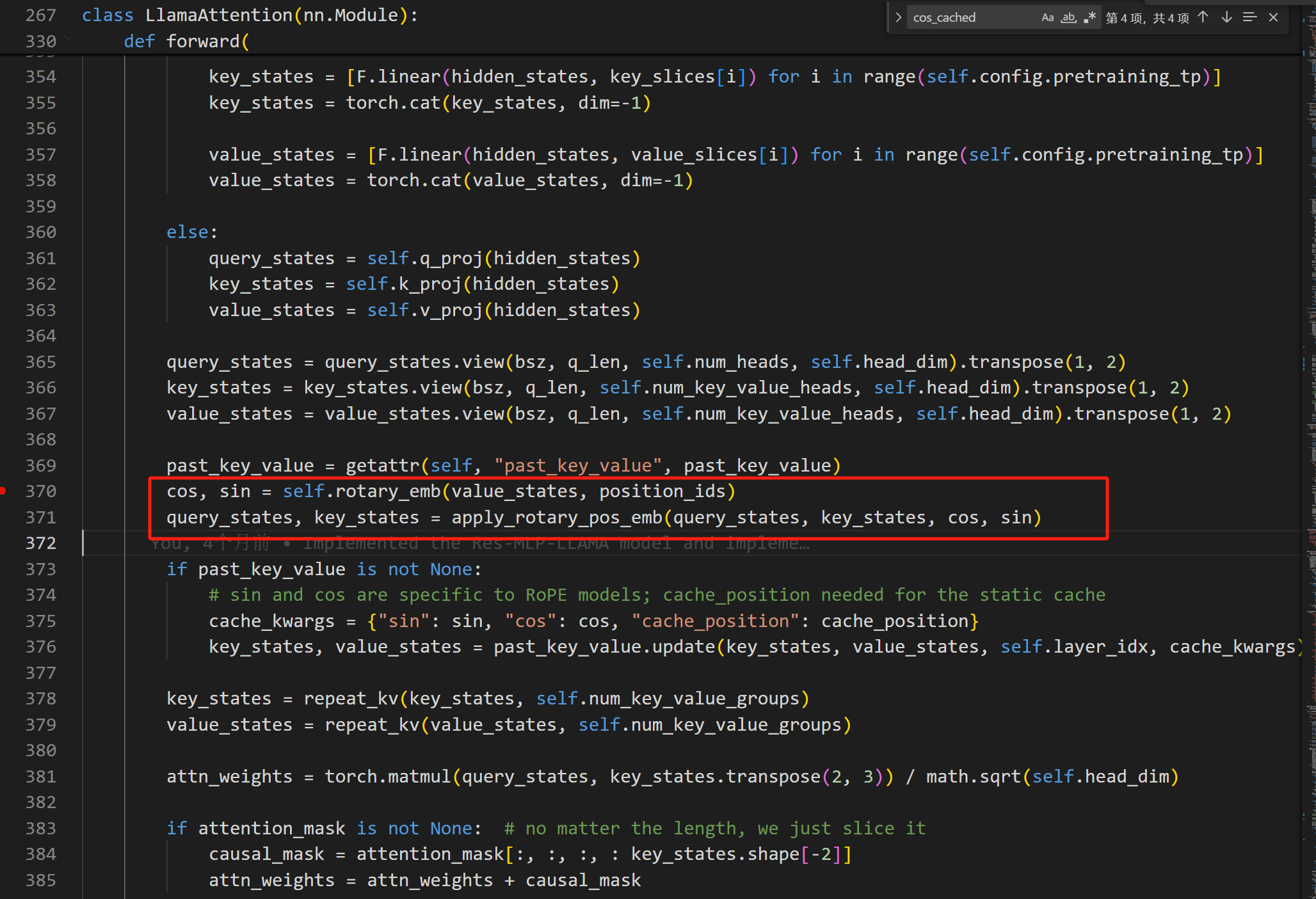
下面看一下llama3中实现这个公式的代码
总共分为两步,分别是计算RotaryEmbedding和将RotaryEmbedding apply 到 q q q和 k k k向量
计算RotaryEmbedding
首先,初始化上边公式里面的
θ
\theta
θ,在下面这个class的init方法里面。这个借鉴了最早Transformer中的绝对位置编码,我在下面也贴一下这个计算theta的公式
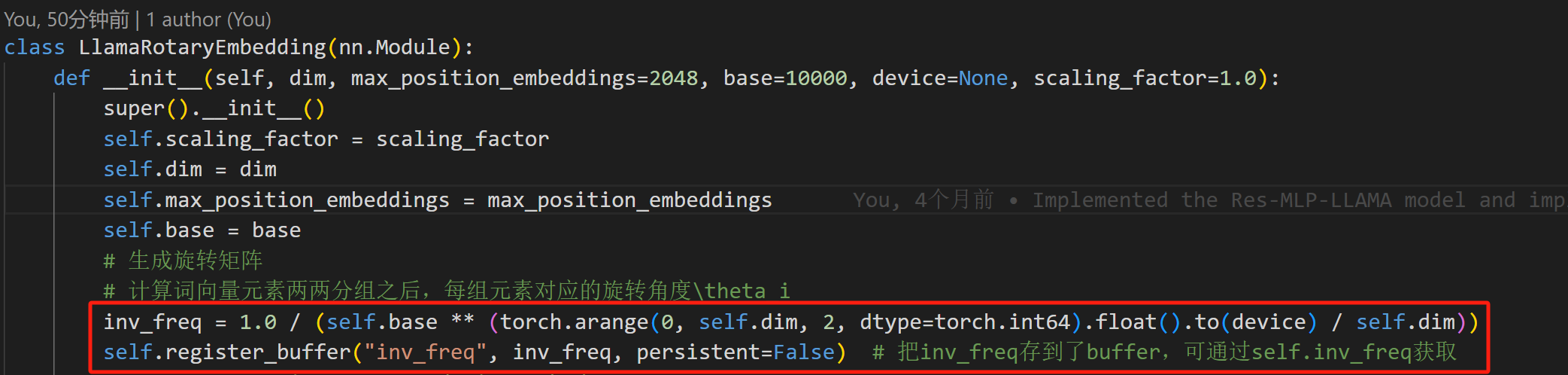
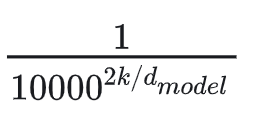
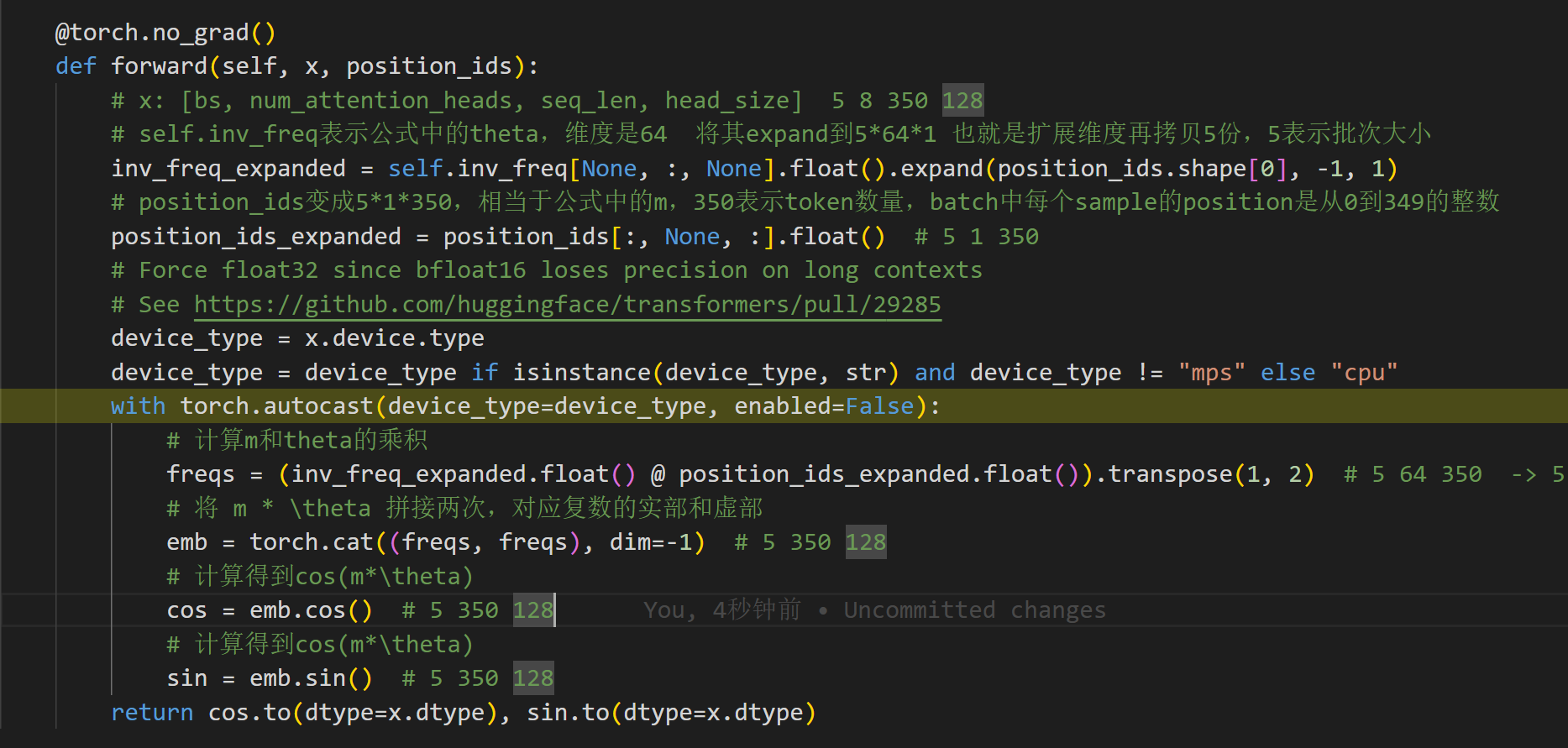
然后,算
m
m
m和
θ
\theta
θ的乘积,并计算得到
c
o
s
(
m
∗
θ
)
cos(m*\theta)
cos(m∗θ)和
s
i
n
(
m
∗
θ
)
sin(m*\theta)
sin(m∗θ)
将RotaryEmbedding apply 到 q q q和 k k k向量
方法很简单,就是通过下面这两行代码实现的上面公式
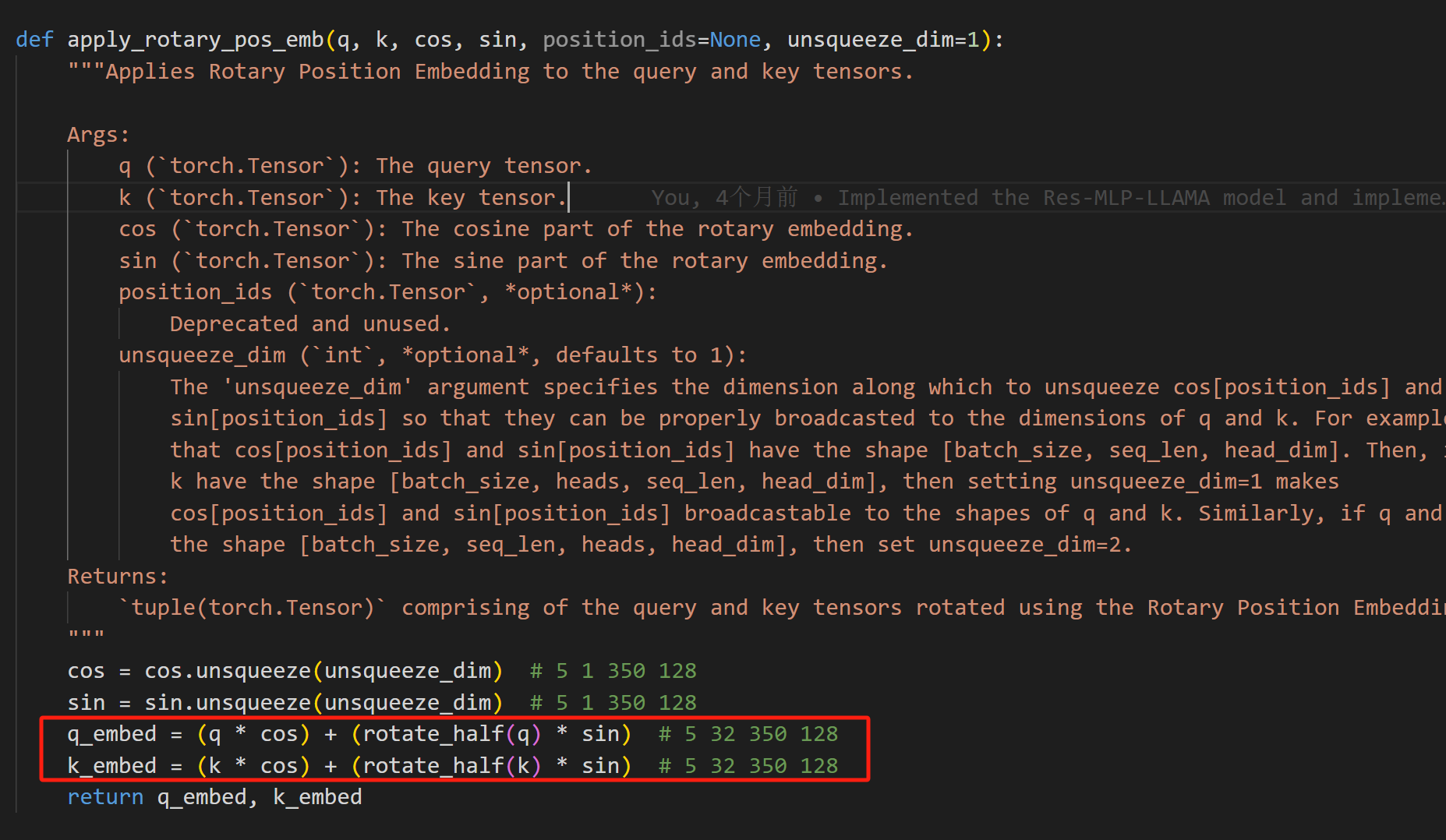
这里的rotate_half代码如下

那最后,我们可以得到了位置编码后的q和k,并按照常方法计算attention


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









