







抽样的Python代码实现:
import random
import matplotlib.pyplot as plt
import numpy as np
def sample(num_of_samples, sample_sz):
data = [] # 用来收集每个样本的均值
for _ in range(num_of_samples):
# 从均匀分布的总体中模拟抽样
data.append(np.mean([random.uniform(0.0,1.0) for _ in range(sample_sz)]))
return data # 返回收集了每个样本的均值的列表
if __name__ == "__main__":
data = sample(10000,100)
plt.hist(data,bins='auto',rwidth=0.8) # 绘制直方图
plt.axvline(x=np.mean(data),c='red') # 绘制所有样本均值的均值对应的直线
plt.show()
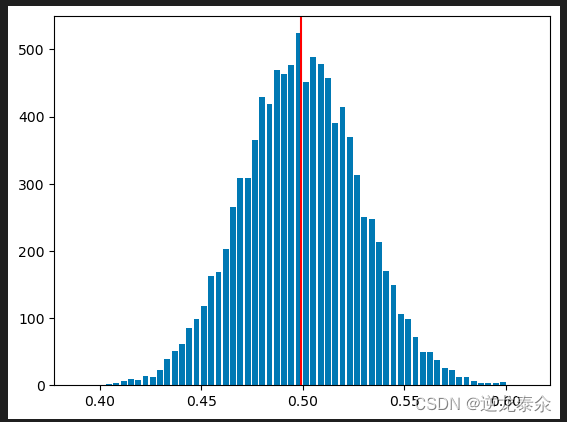
以上代码从侧面验证了统计学的一个重要定理,中心极限定理,中心极限定理支出,如果样本足够大,则变量均值的抽样分布将近似于正态分布,而与该变量在总体中的分布无关。
一、点估计
什么是点估计?
设总体X的分布形式已知,但它的一个或多个参数未知,借助于总体X的一个样本来估计总体未知参数的值的问题称为参数的点估计问题。
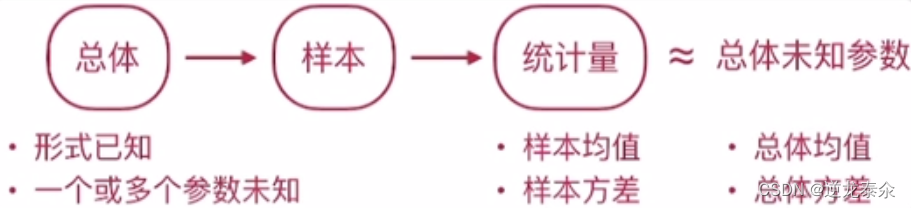
注意:点估计的问题就是要构造一个适当的统计量(估计量),用它的观察值作为未知参数的近似值(估计值)。
估计量的评选标准:
无偏性:
– 若估计量的数学期望存在,并且该期望等于总体参数,则称为无偏估计
–无偏估计的实际意义就是:“E(估计值) - 真值”的结果为0
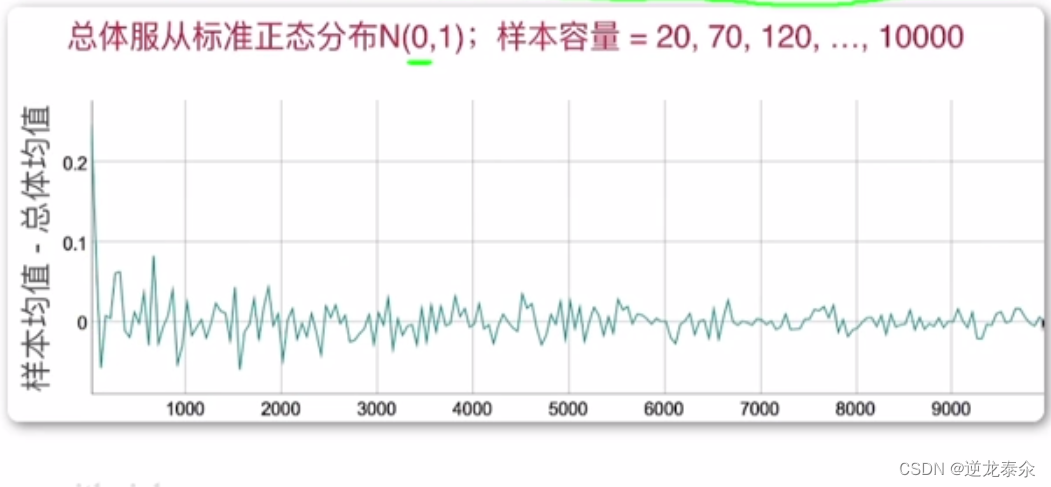
–不论总体服从什么分布,样本均值是总体均值的无偏估计,样本方差是总体方差的无偏估计。

有效性:

相合性:
随着样本容量的增大,一个估计量的值稳定于待估参数的真值,满足此条件的估计量为相合估计量。
二、区间估计
区间估计用来估计总体未知参数的区间范围。
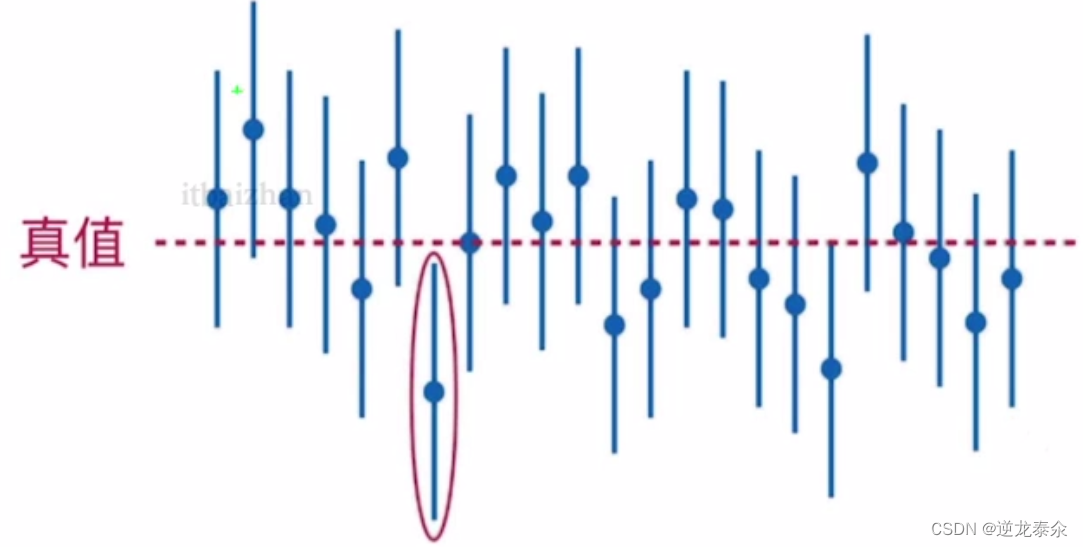
对于位置参数,我们不仅要得到近似值(点估计),还希望估计出一个范围(区间),并希望知道这个范围包含参数真值的可信程度,这种形式的估计称为区间估计,这样的区间称为置信区间。

注意:
对于置信区间和置信水平的理解:
1、固定样本容量n,若反复抽样多次,每个样本值确定一个区间,每个这样的区间要么包含θ的真值,要么不包含θ的真值;
2、在这么多区间中,包含真值的约占100(1-α)%,不包含真值的占100α%;
3、计算得到的区间属于那些包含真值的区间的可信程度为100(1-α)%,或“该区间包含真值”这一程序的可信程度为100(1-α)%。
三、求置信区间的步骤
较优的点估计应该属于置信区间,这是求置信区间的起始和基本思想。

四、正太总体均值的置信区间(方差已知)
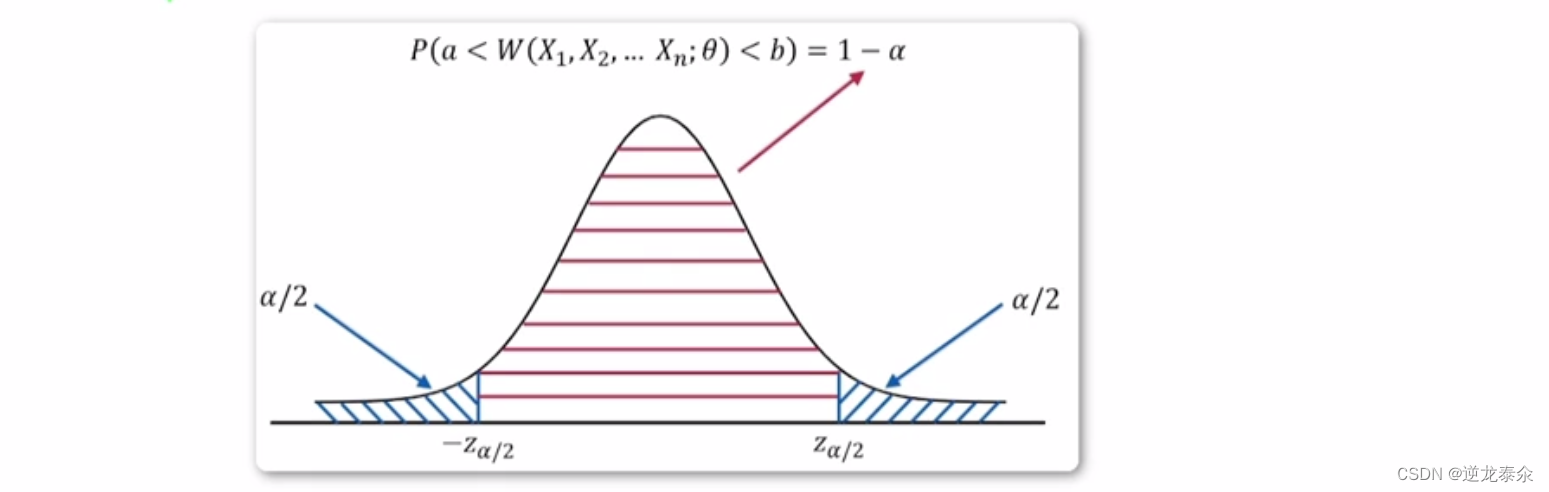

五、正太总体均值的置信区间(方差未知)

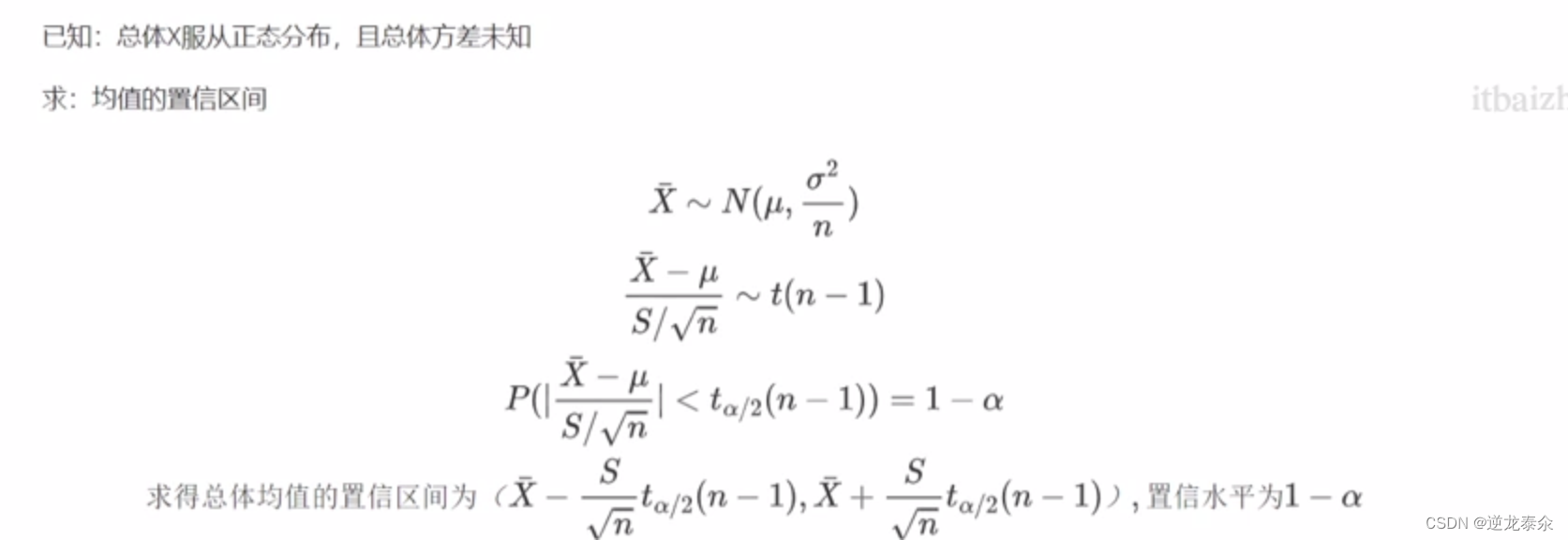
五、正太总体方差的置信区间(总体均值未知)
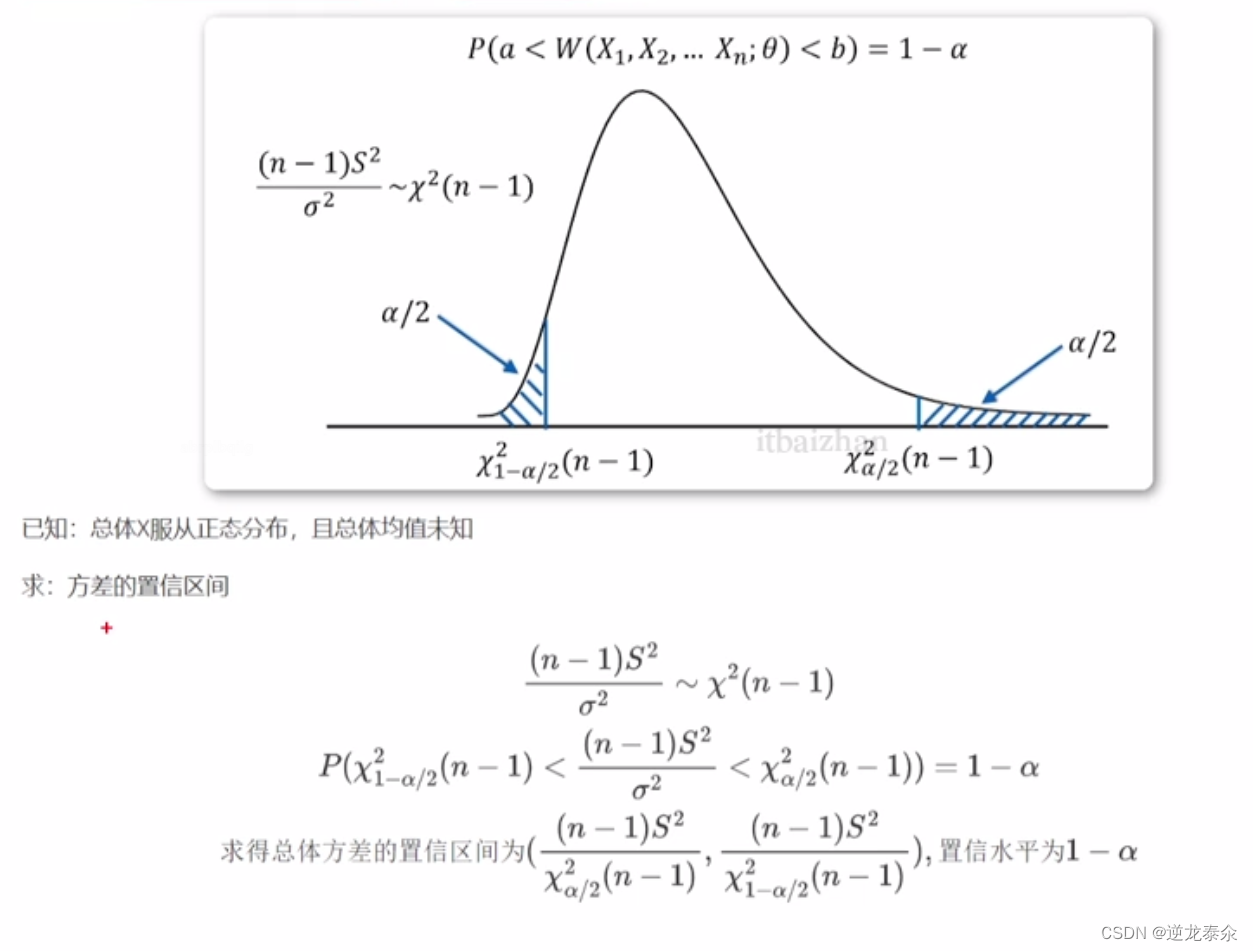
六、两正态总体均值差的置信区间(两个方差已知)
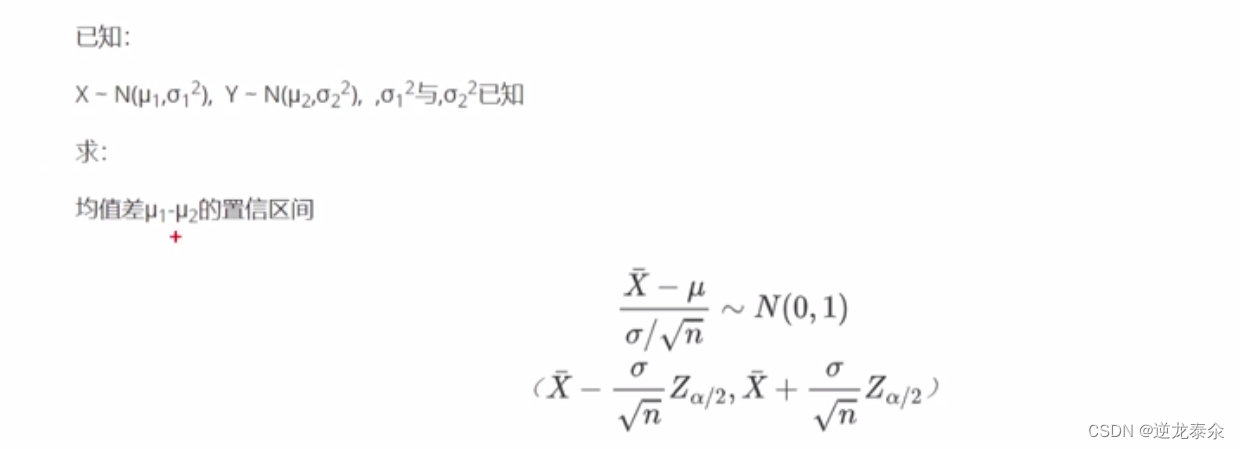

七、两正态总体均值差的置信区间(方差不等且未知)

注意:两个正太总体均值差的置信区间(方差不等且未知),构造的统计量虽然服从t分布,但该t分布自由度计算很复杂,不需要记住。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











