









 本文指导如何使用Python通过浏览器审查元素获取动态评论API地址,详解了利用requests库抓取并解析LiveRe API,获取用户评论内容的过程。
本文指导如何使用Python通过浏览器审查元素获取动态评论API地址,详解了利用requests库抓取并解析LiveRe API,获取用户评论内容的过程。
爬虫地址Hello world!
现在我们要爬取动态加载的评论。
结果展示:
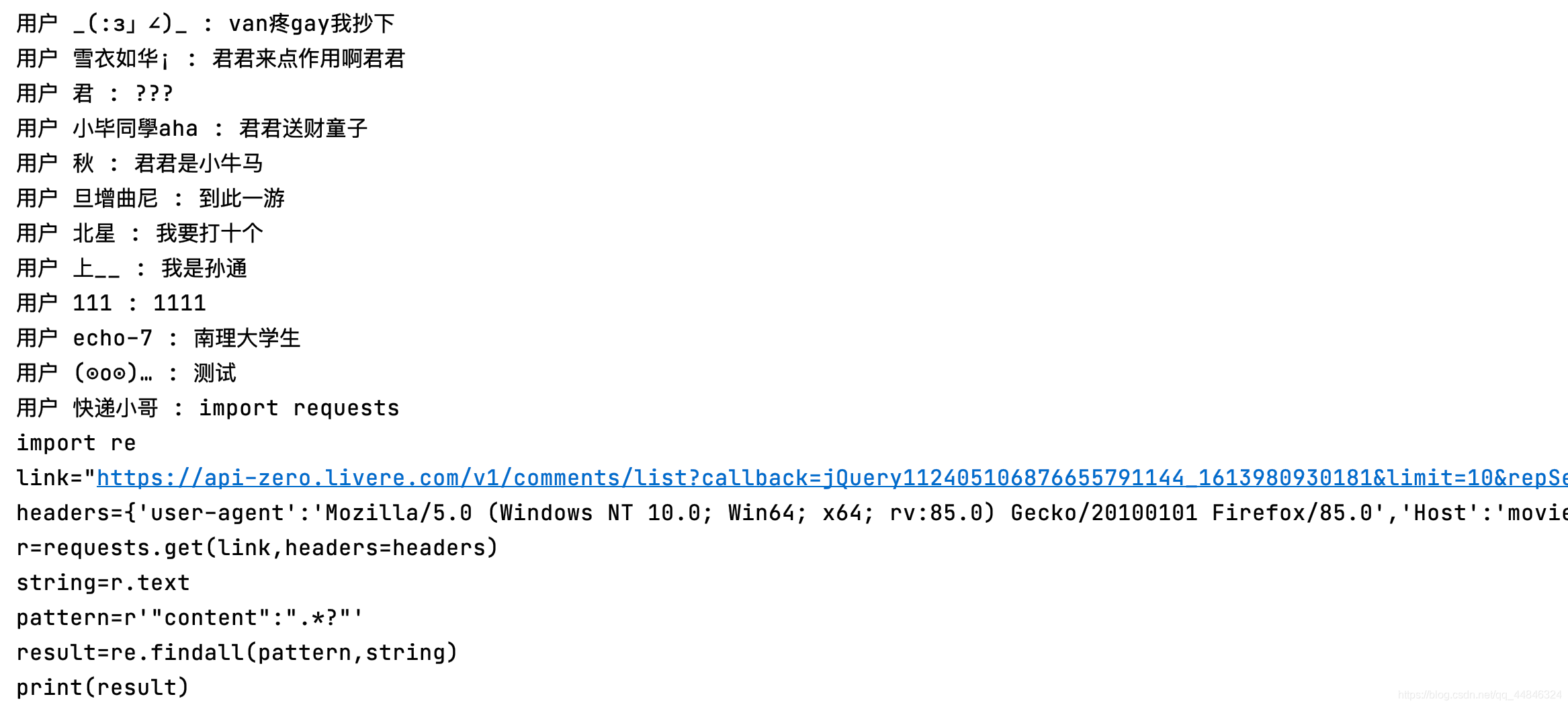
最重要的一步就是,我们要通过浏览器的审查元素去获取真正的地址。
import requests
import json
from util.randomHeaders import getHeader
link1 = "https://api-zero.livere.com/v1/comments/list?callback=jQuery112407330668384607038_1617262726311&limit=10" \
"&offset="
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154"
for i in range(1, 31):
# 通过链接的拼接实现跳转
link = link1 + str(i) + link2
r = requests.get(link, headers=getHeader())
s = r.text
# print(s)
# 解析json
json_data = json.loads(r.text[s.find('{'):-2])
response_code = json_data['resultCode']
if response_code == 200:
comment_list = json_data['results']['parents']
# print(comment_list)
for cmt in comment_list:
user = cmt['name']
comment_content = cmt['content']
print("用户 %s : %s" % (user, comment_content))

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









