






ElasticSearch全文搜索引擎
文章目录
前言
全文搜索引擎在很多领域都有广泛的应用,包括互联网搜索引擎、企业搜索、内容管理系统、电子邮件搜索、日志分析等
一、全文搜索Lucene
1.Lucene是什么?
Lucene是apache下的一个开源的全文检索引擎工具包(一堆jar包)。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在小型目标系统中实现全文检索的功能
2.Lucene索引原理
核心:索引创建,索引搜索
Lucene全文搜索的执行流程,如下图:

索引创建:
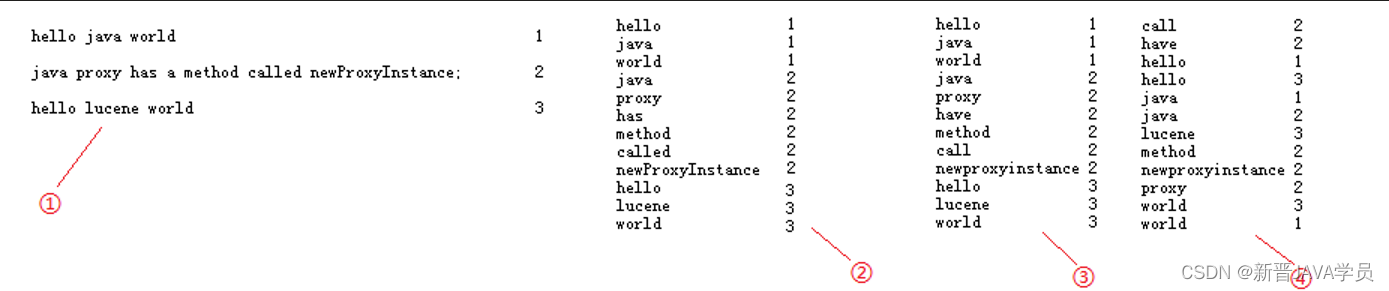
在①处分别为3个句子加上编号,然后使用分词器进行分词,把被一个单词分解出来与编号对应放在②处;按规则统一变为小写放在③处;要加快搜索速度,就必须保证这些单词的排列时有一定规则,这里按照字母顺序排列后放在④处;最后简化索引,合并相同的索引,就得到如下结果:【倒排索引文档】
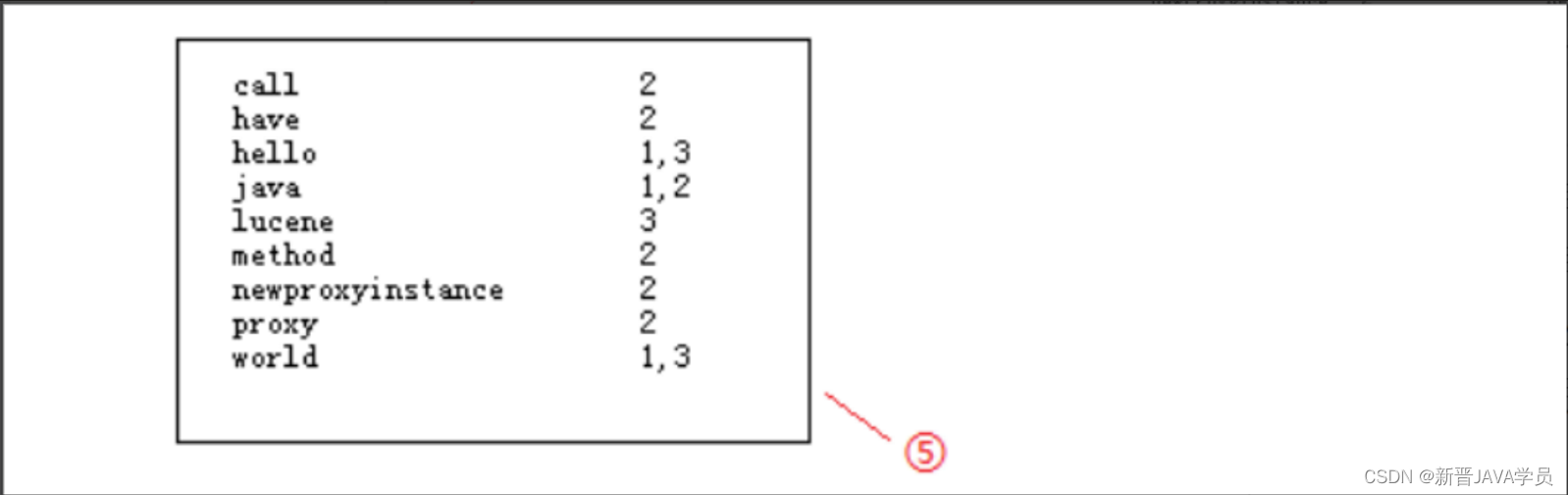
索引搜索:
处理用户的查询请求,搜索索引库中的的索引,然后返回结果的过程

返回的结果会进行相关性排序,原始数据中包含的搜索的索引越多,权重越重,排名就在最前面
二、ElasticSearch全文搜索引擎
1.什么是ElasticSearch?
ES是一个分布式的全文搜索引擎,为了解决原生Lucene使用中存在的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐Lucene的复杂性,从而让全文搜索变得简单
2.ES的特点:
-
分布式的实时文件存储
-
分布式全文搜索引擎,每个字段都被索引并可被搜索
-
能在分布式项目/集群中使用
-
本身支持集群扩展,可以扩展到上百台服务器
-
处理PB级结构化或非结构化数据
-
简单的 RESTful API通信方式
-
支持各种语言的客户端
-
基于Lucene封装,使操作简单
3.ES和lucene的区别:
-
Lucene只支持Java,ES支持多种语言
-
Lucene非分布式,ES支持分布式
-
Lucene非分布式的,索引目录只能在项目本地 , ES的索引库可以跨多个服务分片存储
-
Lucene使用非常复杂 , ES屏蔽了Lucene的使用细节,操作更方便
-
单体/小项目使用Lucene ,大项目,分布式项目使用ES
Elasticsearch 是建立在 Lucene 基础之上的分布式搜索和分析引擎,相对于 Lucene 具有更强大的功能、更好的性能和更丰富的生态系统。而 Lucene 则是一个更轻量级的全文搜索库,适用于一些简单的单机搜索场景
4.其他全文搜索引擎
- Solr:Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持
- Solr和ES比较
Solr 利用 Zookeeper(注册中心) 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES,但实时搜索效率低。
ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显高于 ES。
5.ES下载,安装,以及使用
ES下载:https://www.elastic.co/downloads/elasticsearch
ES安装:解压即可使用
ES启动:双击安装目录 bin/elasticsearch.bat => 可以通过修改 jvm.options 文件来修改内存
使用:Kibana5一个基于 Web 的开源数据可视化工具,用于展示、分析和交互式查询 Elasticsearch 中的数据。
Kibana5下载:https://www.elastic.co/downloads/kibana => 版本要与ES一致,避免版本冲突
Kibana5安装:解压即可安装
Kinbana连接ES配置:编辑config/kibana.yml,设置elasticsearch.url: “http://localhost:9200”
Kibana5启动:双击bin\kibana.bat
Kibana5使用:浏览器访问 http://localhost:5601,对es进行操作
6.ElasticSearch基础
- 基本概念:
Near Realtime:近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
Index:索引库
Type:类型
Document&field:文档,es中的最小数据单元 - 索引库CRUD
增加索引库:默认设置5个Master Shard分片,每个Master Shard分片有1个Replica Shard从分片 PUT index
查询索引库:
查询所有索引库 GET _cat/indices
查询指定索引库 GET _cat/indices/type
删除索引库:
DELETE 名字 - 文档的CRUD
添加文档:
代码如下(示例):
PUT /索引库/类型/id
{
json格式
}
注意:如果不指定文档的id,ES会自动生成文档id
获取文档:
代码如下(示例):
获取指定文档: GET /索引库/类型/id
指定返回的列: GET /索引库/类型/id?_source=字段名
只要内容不要元数据: GET /索引库/类型/id/_source
修改文档:
代码如下(示例):
整体修改: 会用最新的数据覆盖以前的所有数据
PUT /索引库/类型/id
{
json格式
}
局部修改: 只修改局部数据
POST /索引库/类型/id/_update
{
"doc"{
要修改的数据
}
}
删除文档:
代码如下(示例):
DELETE /索引库/类型/id
- 文档简单查询:
代码如下(示例):
查询所有:GET _search
查询指定索引库: GET /index/_search
查询指定类型:GET /index/type/_search
查询指定文档:GET /index/type/id
分页查询:&from=2&size=2
7.DSL查询与DSL过滤
- 什么是DSL查询?
DSL查询是由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。DSL有两部分组成:DSL查询和DSL过滤。 - .DSL查询语法:
代码如下(示例):
GET /index/type/_search
{
“query”{
"match_all":{} //查询所有数据
},
"from": , //从第几条数据开始查
"size": , //分页显示条数
"_source":[], //查询那几个列的数据
"sort":[] //排序
}
-
DSL过滤:
DSL过滤和DSL查询在性能上的区别:
过滤结果可以缓存并应用到后续请求。
查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
过滤语句可有效地配合查询语句完成文档过滤 -
DSL查询+过滤语法:
代码如下(示例):
GET /index/type/_search
{
"query"{ // 查询,所有的查询条件在query里面
"bool":{ // 组合搜索bool可以组合多个查询条件为一个查询对象,这里包含了 DSL查询和DSL过滤的条件
"must":{ // 必须匹配 :与(must) 或(should) 非(must_not)
"match":{ // 分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
"username":"hello word"
}
},
"filter":{ // 过滤
"term":{ // 词元查询,不会对查询条件分词
"username":"zf ls"
}
}
}
"match_all":{} //查询所有数据
},
"from": , //从第几条数据开始查
"size": , //分页显示条数
"_source":[], //查询那几个列的数据
"sort":[] //排序
}
- 查询方式:
全匹配(match_all):匹配所有文档
标准查询(match和multi_match):标准查询,会对查询的内容进行分词后,得到多个单词,分别带着多个单词去检索ESs索引库,只要有一个单词能查出结果,整个查询就有结果
单词搜索与过滤(Term和Terms):单词/词元查询 , 可以理解为等值查询,字符串,数字等都可以使用它,不会分词,将查询索引看做一个整体
组合条件搜索与过滤(Bool):组合搜索bool可以组合多个查询条件为一个查询对象
范围查询与过滤(range):range过滤允许我们按照指定范围查找一批数据,如: “range”:{gt:值,lt:值 }
前匹配搜索与过滤(prefix):匹配前缀
通配符搜索(wildcard):使用*代表0~N个,使用?代表1个,如:“name”:“李?四”
8.文档类型映射
- 什么是文档映射?
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型 - 创建映射:
代码如下(示例):
PUT index
{
"mappings":{
"_doc":{
"properties":{
"id":{
"type":"inteeger"
},
"info":{
"type":"text",
"analyzer":"ik_smart",
"searchAnalyzer":"ik_smart"
}
}
}
}
}
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了全文搜索引擎和ElasticSearch全文搜索引擎的使用。















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









