






本文使用clions这款IDE,从https://github.com/google/googletest/tree/main/googletest下载googletest,放在clions文件中,包含头文件:
#include "gtest/gtest.h"以下全是基于googletest所做的单元测试,如果对于googletest中断言不清楚的请参考:
https://blog.csdn.net/weixin_42227520/article/details/107060073
那么继续了,首先要记录的是:
1)auto,decltype
在写作过程中,我发现decltype这个对于函数返回不能是void的空类型,
TEST(autoTest, test01){
int i = 10;
auto a = i;//这里a为int类型
auto &b = i;//b为 int&
auto *c = &i;//c为int*
//推导数组
int d[10] = {0};
auto f = d;//f为int* f指向数组首个地址
//这里需要区分顶层const与底层const
const int _x = 1;
auto _y = _x;//这里_x中const为顶层const,因此_y为int类型
auto _z = &_x;//这里对_x取地址是一种底层const,这里的类型为const int*
const auto _m = _x;//可以看出也是一种顶层const,auto->int
}
int func(){return 0;}
TEST(decltype, test01){
decltype(func()) i;//推导i为int
int x = 0;
decltype(x) y;
decltype(x + y) z;//同理
}
深入理解返回值后置类型语法就是为了解决函数返回值类型依赖于参数但是却难以确定返回值类型:
template<class T, class U>//返回值后置类型语法,
//我感觉这个玩意儿在Lambda表达式也出现了,不知道是不是一样的,
auto add(T t, U u) ->decltpye(t + u) {
return t + u;
}
TEST(posttype, test01){
auto _add = add(1,2);
decltype(add(1,2)) _add1;//_add1为int类型
//在c14中提出了decltype(auto)的使用方式,我感觉没什么用,。。
decltype(auto) _add2 = add(1,3);
//如果读者不知道如何输出上述类型,可将_add2等等视为变量
std::cout << _add2 << std::endl;
}
作为程序员,对于复杂类型可以使用auto图个方便,但是为了代码的可读性,还是尽量使用原本的类型,当然在clions编译器中,使用auto关键词会在其后显示类型,还不错吧,请看图1。
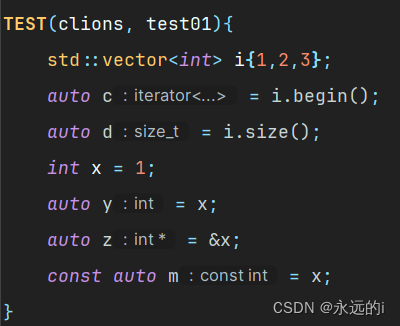
图1 clions编译器
那么继续下一个东东,刚才不提到Lambda表达式吗?那就先说说看:
2)Lambda表达式
在https://en.cppreference.com/w/官方网站是这么使用Lambda表达式的,
//Lambda_Study
void abs_sort(float* x, unsigned n){
std::sort(x, x + n,
[](float a, float b) ->bool {//看到没,这个->bool跟后置类型是不是一样
return (std::abs(a) < std::abs(b));
}
);
}
TEST(abs_sort, test01)
{
float x[] = {1.1,1.2,1.5,-1.8,1.1};
abs_sort(x, 5);
for(float i : x)//C11引入遍历方法
std::cout << i << std::endl;
}其中[]为捕获对象,()为参数列表,->bool为返回类型,{表达式},这就是Lambda表达式的全部,神奇吧。在看书过程中,有人称Lambda为匿名表达式,从代码中一眼就可以看出,确实是没有名字,那我非要加个名字怎么办,那你就加呗,让我看看名字怎么加上去的。
//懒得写TEST测试单元了,
auto func1 = ([]{std::cout << "Hello world" << std::endl;});有没有看到,func1就是后面表达式的名字,啊,作者这Lambda表达式怎么用啊,你就一个func1,蠢了吧!
func1();就这么用,嘿嘿。有没有发现在捕获[]以及表达式{}中间我们并没有写->void,这是编译器帮我们推导出return 类型,func1没有返回即为[] ->void{}。
其实上面两行代码体现不出Lambda的强大之处,当然官方给出的案例,那的的确确体现了Lambda的强大,使用#include<functional>中的sort,使用Lambda表达式作为sort的第三参数,好像啰嗦了些,那么在官方之外的捕获呢?
//那么第一种呢是值的方式
int num2 = 100;
auto fun2 = ([num2]{std::cout << num2 << std::endl;});有人就问了,num2如果是全局变量呢,Lambda是函数,函数访问全局变量不是轻轻松松嘛,没错,你真是个天才,但是呢,如果这两行代码放入函数中,Lambda表达式就不认识了。这个嘛,其实就是Lambda的这种捕获机制,全局函数具有全局可见性,局部变量可能不在我搜索的范围内吧,这个问题我还真不太清楚嘞,有会的留个言说一下。
系统说:Variable 'num2' cannot be implicitly captured in a lambda with no capture-default specified,嘿嘿我不能隐式捕获num2,你必须给我抓到他。
//第二种[=]捕获=标志值传递方式捕获所有父作用域的变量(包括this)
int num3 = 100;
int _num3 = 1000;
auto func3 = ([=] {
std::cout << num3 << ' ' << _num3 << std::endl;} );
func3();
//第三种[&var]表示引用传递捕获变量var
int num4 = 100;
auto func4 = ([&num4]{
num4 = 1000;
std::cout << "[&var]\t" << num4;
});
func4();
std::cout << ' ' << num4 << std::endl;
//第四种[&]表示引用捕获所有父作用域的变量(包括this)
auto func5 = ([&]{num4 = 1000;});
func5();
std::cout << num4 << std::endl;//改变了num4的值那么第5种,先稍微说明以下,首先this存在与类中,随类的构造而存在,随类的析构而消失。因此,下面这个Lambda存在与类中,某些情况下函数很有用滴,
class myLambda{
public:
myLambda() = default;//默认
myLambda(const myLambda& my) = delete;//禁用
//myLambda() : x(0){}//初始化成员变量
void lambda(){
auto function = ([this] {
this-> _x = 1;});
function();
}
int _x;
};
//[this]表示值传递方式捕获当前的this指针
myLambda demo;
demo.lambda();这里又得在说明一下,C11引入类的成员变量初始化列表,初始化成员变量就这么用准没错。要说这么做的好处呢,那么就得相比较于构造赋值操作了,如果成员变量为引用类型、常量等,赋值操作就不得行咯,这是很明显的,因为引用、常量必须在定义时就初始化。既然类出现了,添加一个新东西吧,default,delete,一个使用默认构造拷贝构造,另一个禁用。看代码就明白了。
话说回来,this捕获仅仅只是类中,其实使用[&]捕获也能捕获this。
其实吧,这里的捕获还可以混合使用,
//[=, &a, &b]表示以引用的方式捕获变量a和b,以值传递方式捕获其他所有变量
int index6 = 1;
int num6 = 2;
int num6_ = 5;
auto func6 = ([=, &index6, &num6]{
std::cout << index6 << ' ' << num6 << std::endl;//index6以及num6可以修改的
}
);
func6();我其实不建议使用混合捕获,如果存在这样一种情况,我们使用=捕获所有值传递,那么在捕获index6,是不是就重复捕获了,这就会导致系统在编译时期出错,不过呢,clions你这么写就不让,其他的编译器尚未尝试。
一点小小的建议:Lambda表达式,如果逻辑过于复杂,还是使用函数的形式吧!
连Lambda表达式都说, 那么还有一个东西用于函数封装,std::function,这个呢,就是在函数外面加一个套,有用吧它又没什么用。。。实际应用中,我肯定是不会用滴,可能在重构代码时候为了方便调用函数,这个还是不错的。那么就来说一说吧!
3)std::function
//有这么一个函数,
void print(int x, int y){
std::cout << "hello" << std::endl;}//为了更有说明性,索性填两个形参吧
std::function<void(int,int)> myFunctionPrint = print;//参数:<返回类型(两个形参)>
//测试
//调用
myFunctionPrint(1,2);这玩意吧,其实有一些复杂的用法,俺不会如果真用到,去cplusplus看吧。作为程序员记忆是有限的。我主打一个丰富基础,地基不牢地动山摇嘿嘿。上述介绍了auto、Lambda等,C11最好的东西来。
4)智能指针
困扰C++程序员多年的内存管理它来了,随创建而创建,随析构而析构,随离开作用域而消失。暂且这么说吧。智能指针包含头文件#include <memory>中。
4.1)std::shared_ptr
C11中这个共享指针,我们可以这么理解,这个构造函数里面有一个计数器,每次构造count++;每次析构count--;是不是引用计数的智能指针,值得注意的是,每一个shared_ptr的拷贝都指向相同的内存。那么我们来看一个案例:
//以一个类为例穿插一组new,delete来说明
class sharePtr{
public:
sharePtr(){
_data = new int[5];//在堆区申请数组大小为5的int类型
}
//那么
void print(){
std::cout << "hello" << std::endl;
_ptr = std::make_shared<int>(10);//这里将10申请到堆区,
//有没有发现我们并没有在析构中释放,而int[5]释放了
//调用函数print()结束时,自动释放。
}
~sharePtr(){
if(_data != nullptr) delete[] _data;
}
int* _data;
std::shared_ptr<int> _ptr;
};
void sharePrint(std::shared_ptr<sharePtr> ptr){
ptr->print();
}
//测试
std::shared_ptr<sharePtr> ptr1 = std::make_shared<sharePtr>();
//有没有发现std::share_ptr<sharePtr>非常的长,这个时候就可以使用auto了,
//其实还有一种方法,
using shareClass = std::shared_ptr<sharePtr>;
shareClass ptr2 = ptr1;//using关键词也是c11中一个有用的,比C中typedef更具有可读性
ptr2->print();假如我们想要将上述代码使用类指针接收由智能指针指向的类怎么办?
sharePtr* ptr3 = ptr1.get();
ptr3->print();注意事项,挑两个正常人能理解的,拿种很难理解的我还是喜欢遇到了再解决:
1)尽量使用make_shared,少用new
2)不要delete get()回来的裸指针,这个明显吧,get()回来的又不代表我智能指针放弃对数据的管理,你给我删了我删什么?嘿嘿。
3)共享共享,你给我整个无限套娃,我系统都走完了,你还在循环引用这个智能指针。
自定义删除器,我想可能并不会用到,没错下面代码是一个Lambda表达式。当引用计数为0时,自动调用自定义删除器。反正我没用过嘿嘿,会的给我讲讲也行。
std::shared_ptr<int> ptr(new int, [](int* p){delete p;});4.2)std::weak_ptr
这个弱指针是为了防止引用计数相互引用形成环,简称环形引用,那么就会发生一个什么情况呢?
当代码产生循环引用,导致两个智能指针引用计数为2,而离开作用域时引用计数-1,但永远不会为0,这不就导致了智能指针永远不会析构。那么看看程序是如何引用计数为2的吧。
struct A;
struct B;
struct A{
std::shared_ptr<B> bptr;
};
struct B{
std::shared_ptr<A> aptr;
};
TEST(Shard_Ptr, test02){
auto aaptr = std::make_shared<A>();
auto bbptr = std::make_shared<B>();
std::cout << aaptr.use_count();//use_count()查看引用计数,这里为1
std::cout << bbptr.use_count();
aaptr->bptr = bbptr;
bbptr->aptr = aaptr;
std::cout << aaptr.use_count();//而这里为2,
std::cout << bbptr.use_count();
//可想如何我们就此循环,引用计数是不是无限++呢??
}我们看到了错误的使用方法,如何正确使用请看如下代码
struct A;
struct B;
struct A{
std::shared_ptr<B> bptr;
void print(){
std::cout << "yoxi" << std::endl;
};
struct B{
std::weak_ptr<A> aptr;
void PrintA(){
if(!aptr.expired()){//监视shared_ptr的生命周期
//判断当前 weak_ptr 指针为否过期(指针为空,或者指向的堆内存已经被释放)。
auto ptr = aptr.lock();
//如果当前 weak_ptr 已经过期,则该函数会返回一个空的 shared_ptr 指针;
//反之,该函数返回一个和当前 weak_ptr 指向相同的 shared_ptr 指针。
ptr->Print();
}
}
};
TEST(SharedWeak_Ptr, test03){
auto aaptr = std::make_shared<A>();
auto bbptr = std::make_shared<B>();
aaptr->bptr = bbptr;
bbptr->aptr = aaptr;
std::cout << aaptr.use_count() << std::endl;//这里为1
std::cout << bbptr.use_count() << std::endl;//这里为2
bbptr->PrintA();
}有没有看到,weak_ptr并没有使得aaptr引用计数再次+1,那么我们会发现,当程序突出是,由引用计数-1,aaptr自动销毁,同时bbptr不在指向任何对象,由shared_ptr内部引用计数降为0,也同样被销毁。
需要注意的是,当 weak_ptr 类型指针的指向和某一 shared_ptr 指针相同时,weak_ptr 指针并不会使所指堆内存的引用计数加 1;同样,当 weak_ptr 指针被释放时,之前所指堆内存的引用计数也不会因此而减 1。也就是说,weak_ptr 类型指针并不会影响所指堆内存空间的引用计数。除此之外,weak_ptr<T> 模板类中没有重载 * 和 -> 运算符,这也就意味着,weak_ptr 类型指针只能访问所指的堆内存,而无法修改它。
4.3)std::unique_ptr
这个指针其实就没什么好说的了,独占式指针顾名思义就是不允许其他智能指针共享内部指针,这样不就没有了unique_ptr的拷贝以及赋值了吗?用法跟shared_ptr一样。
class A{};
auto uptr = std::make_unique<A>();智能指针的体会:初学者呢,我建议把new、new[]、delete、delete[]整明白了再来使用智能指针。
好像std::move也是C11的?应该是的,跟其同时出现的还有右值引用来着。
5)std::move and valueDefine
叫valueDefine也是我瞎叫的涉及左值、右值、纯右值、将亡值等等,这里挑几个大家不常用的讲讲吧,基础的都不知道的话,那就有点困难了。
上来就先说std::move嘛,排在前面,顺便引出右值引用吧,跟上咯
TEST(right_reference, test01)
{
std::string str = "hello";
std::string &&c = std::move(str);
std::cout << c << std::endl;
}耶,看到了撒,两个&&??没错这个就是右值引用,由std::move我称其为杀死str,大家大可以试试输出str,你会发现什么都没有,也就是挖空str咯。是不是又发现str是一个将亡值了呢,本帅选个案例可以吧。
注意咯,std::move(),针对于int,float等基础类型并没有优化效果,你会发现调用原本的值依然存在。
最后一点,其实吧无关紧要了拉。
6)nullptr替换了null
其实把就是null在C语言中就是0,然而void*也是0,那不就是计算机语言中的二义性咯。这里也没什么演示的。















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









