






Stream流
当我们需要对集合中的元素进行操作的时候,除了必须的添加,删除,获取外,最经典的就是集合遍历
Stream流的含义: 获取流,过滤流张,过滤长度,注意打印,使得代码更加的简介直观。
一、Stream流的获取方式
通过collection获取
List list = Arrays.asList(1,2,3,4,5,6);
Stream stream = list.stream();
map接口没有实现Collection接口,这时我们可以根据Map获取对应的key,value的集合。
Map map = new HashMap();
Stream stream = map.keySet().stream();
Collection values = map.values();
Stream stream1 = values.stream();
通过Stream的of方法
在实际开发中我们不可避免的还会操作到数组中的数据。由于数组中不可能添加默认的方法,所以Stream流提供了静态方法of
// 方式1
Integer[] nums = {1,2,3,4,5,6,7};
Stream<Integer> nums1 = Stream.of(nums);
// 方式2
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7)
二、Stream常用方法介绍
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法,不支持链式调用
非终结方法,仍然是Stream流,支持链式调用。
注意
Stream只能操作一次
Stream返回的是一个新的流
Stream不调用终结方法的话,那么他是不会执行的。
1、foreach方法
用于遍历流中的数据
void forEach(Consumer<? super T> action);
该方法接收一个Consumer接口,会将每一个流元素交给函数处理。
Stream.of(1,2,3).forEach(System.out::println);
2、count方法
Stream流中的count方法用来统计其中的元素个数。
long count = Stream.of(1, 2, 3).count();
3、 filter方法
filter方法的作用是用来过滤数据的,返回符合条件的数据。
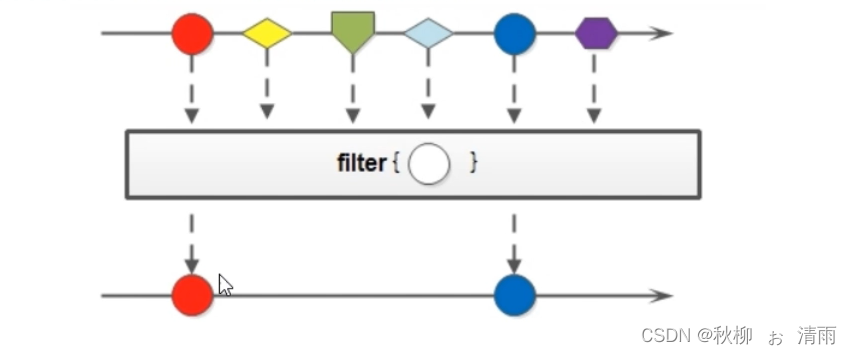
Stream<T> filter (Predicate<? super T> predicate);
该接口接收一个Predicate函数式接口参数作为筛选条件。
Stream.of(1,2,3).filter(s -> {
return s>=2? true:false;
}).forEach(s->{
System.out.println(s);
});
4、limit方法
可以对流进行截取处理,只取出前几个数据。
Stream<T> limit(long maxSize)
Stream.of(1,2,3).limit(2).forEach(System.out::println);
5、 skip方法
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的流。
Stream<T> skip (long n);
Stream.of(1,2,3).skip(1).forEach(System.out::println);
6、map方法
如果我们需要将流中的元素映射到另一个流中,可以使用map方法。
<R> Stream<R> map(Function <? super T, ? extends R> mapper);
可以将流中T型的数据,转换为R类型的数据。
Stream.of("1","2","3")
.map(Integer::parseInt)
.forEach(System.out::println);
Stream.of("a","b","c").map(s->{
return s + "123";
}).forEach(System.out::println);
7、sorted方法
如果需要将数据进行排序,可以使用该方法
Stream<T> sorted();
Stream.of("1","2","3")
.map(Integer::parseInt)
.sorted()
.forEach(System.out::println);
Optional<Integer> max = Stream.of("2", "1", "3", "3")
.map(Integer::parseInt)
.sorted((a,b) -> a -b)
.findFirst();
System.out.println(max.get());
8、distinct方法
如果要是重复数据,可以使用distinct方法
他的是否相同是通过equals方法来进行判断的
Stream<T> distinct();
Stream.of("1","2","3","3")
.map(Integer::parseInt)
.distinct()
.forEach(System.out::println);
9、match方法
如果需要判断数据是否符合指定的条件,可以使用match相关的方法。
boolean anyMatch(Rredicate<? super T> predicate); //元素是否有任意一个满足条件
boolean allMatch(Rredicate<? super T> predicate); //元素是否都满足条件
boolean noneMatch(Rredicate<? super T> predicate); //元素是否都不满足条件
boolean b = Stream.of("1", "2", "3", "3")
.map(Integer::parseInt)
.allMatch(s -> s > 0);
boolean b = Stream.of("1", "2", "3", "3")
.map(Integer::parseInt)
.anyMatch(s -> s > 2);
boolean b = Stream.of("1", "2", "3", "3")
.nonemap(Integer::parseInt)
.anyMatch(s -> s > 2);
match是一个终结方法
10、max和min方法
如果我么想要获取最大值和最小值,那么可以使用max和min方法。
Optional<Integer> max = Stream.of("1", "2", "3", "3")
.map(Integer::parseInt)
.max((a, b) -> a - b);
System.out.println(max.get());
11、reduce方法
如果需要将所有数据归纳得到一个数据,可以使用reduce方法。
Integer reduce = Stream.of("2", "1", "3", "3")
.map(Integer::parseInt)
// 第一个值是默认值
// 之后每次都会将上一次的操作结果赋值给x y 就是每次从数据中获取的元素。
.reduce(0, (a, b) -> {
return a + b;
});
System.out.println(reduce);
12、 map和reduce的组合
13、 mapToint方法
Integer占用的内存比int多很多,在stream流操作中会自动装箱和拆箱操作。
为了提高程序代码的效率,我们可以将流中Integer数据转换为int数据,然后再操作。
IntStream intStream = Stream.of("2", "1", "3", "3")
.map(Integer::parseInt)
.mapToInt(Integer::intValue);
intStream.filter(s -> s > 2)
.forEach(System.out::println);
14、 find方法
如果我们需要找到某些数据,可以使用find方法来实现
Optional<T> findFirst(); //获取到第一个元素
optional<T> findAny(); //随机的获取到一个元素
Optional<String> b = Stream.of("1", "2", "3", "3").findAny();
15、 concat方法
将两个流合并到一起
Stream<String> stringStream = Stream.of("2", "1", "3", "3");
Stream<Integer> integerStream = Stream.of(4, 5, 6, 7);
Stream.concat(stringStream, integerStream)
.filter(s->{
return s instanceof String;
}).forEach(System.out::println);
三、案例
定义两个集合,然后在集合汇总存储多个用户名称,然后完成如下的操作。
1、第一个队伍只保留姓名长度为3的成员
2、第一个队伍筛选之后只要前三人
3、第二个队伍只要性张的成员
4、第二个队伍筛选之后不要前两个人
5、将两个队伍合并为一个队伍
6、根据姓名创建Person对象
7、打印整个队伍的Person信息
四、结果收集到集合中
// 收集到list集合中
List<String> collect = Stream.of("a", "b", "c")
.collect(Collectors.toList());
// 收集到set集合中
Set<String> collect = Stream.of("a", "b", "c")
.collect(Collectors.toSet());
// 返回具体的实例
ArrayList<String> collect = Stream.of("a", "b", "c")
.collect(Collectors.toCollection(() -> new ArrayList<>()));
// 返回数组
Object[] collect = Stream.of("a", "b", "c")
.toArray();
String[] strings = Stream.of("a", "b", "c")
.toArray(String[]::new);
五、聚合计算
六、分组操作
Stream<Person> stream = Stream.of(new Person("小明", 20),
new Person("小花", 21),
new Person("小兰", 20));
Map<Integer, List<Person>> collect = stream
.collect(Collectors.groupingBy(Person::getAge));
collect.forEach((key,value)->{
System.out.println(key + " " + value.size());
});
七、对流中的数据做分区操作
Stream<Person> stream = Stream.of(new Person("小明", 20),
new Person("小花", 21),
new Person("小兰", 20));
Map<Boolean, List<Person>> collect = stream.collect(Collectors.partitioningBy(s -> s.getAge() > 20));
八、并行流
前面的Stream流都是串行流,也就是在一个线程上面执行。
parallelStream其实就是一个并行执行的流,他通过默认的ForkJoinPool
// stream的形式转换
Stream<Integer> parallel1 = Stream.of(1, 2, 3).parallel();
// list的形式转换
Stream<Integer> integerStream = Arrays.asList(1, 2, 3).parallelStream();
串行流和并行流的对比
并行流的效率是很高的,并行处理的过程会分而治之,也就是将一个大的任务分成了多个小的任务。每个任务都是一个线程操作。
并行流下的数据安全问题:
比如Arraylist不是线程安全的,这种的使用并行流就可能出现问题
问题的解决:
1、加锁
2、使用线程安全的容器vector














 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









