






[scrapy爬虫框架ERROR downloading error processing] [scrapy.core.scraper] ERROR: Spider error processing <GET http://xxx.xxxx.xxxx/xx.html> [scrapy.core.scraper] ERROR: Error downloading <GET http://xxx.xxxx.xxxx/xx.html>
问题解决思路 首先说一下最老实检查代码错误的方法:从代码开头或者你觉得没问题的开始,把后面都注释了(两个’’'多行注释,#单行注释),然后运行程序,一般只要代码没错都是不会报错的。直到你运行到报错时就该注意了,你这行代码可能有问题,可以开始改代码了。这个方法说不上高效率,但很实用,大家应该都会吧。(改代码有时会把人搞蒙逼的。。)
言归正题,你要了解提示downloading、URL啥的错误一般来说肯定是链接的问题,而且一般都有提示。比如下图:

继续下滑,下面还有个提示:
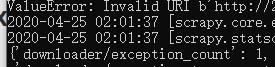
你也看到了有个invalid URI,人家都说白了是你的URL无效了,你就老老实实检查URL吧。我的是链接里多了个空格。。
还有这个错误说是什么error processing,继续往下看

还有这个提示:
我这个问题就是这个代码的里面第26行的hcurl这个链接出的问题,你要么把网站的那个链接直接搬过来试一下,用正则表达式提取出来的链接说不好还有问题(你正则表达式啥的怕是有问题,改改)。反正我是这样做的。
你去检查这个准没错,这两个错误大把握是你链接的问题,不嫌麻烦就用我开头的方法试代码,绝对能试出来是哪里的问题。省得全网找答案还找的一脸懵逼。
error processing网上还有用户说是以下原因:
1.xpath表达式错误xpath错误
2.callback = self.parse别加引号
3.其它形形色色的不想说了,懒得找就像我一样老老实实调试代码就好啦,费力不讨好,不如自己动手实在。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









