









- 一开始这个问题困扰了我半天,去网上搜索也找不到解决办法,后面发现是个小错误。
- 首先确保写了请求头防止被认出是爬虫而拒绝访问
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
}
- 在settings中开启管道
ITEM_PIPELINES = {
"spider2024.pipelines.doubanPipeline": 300,
}
- 然后检查你导入的库和写的代码:如下图
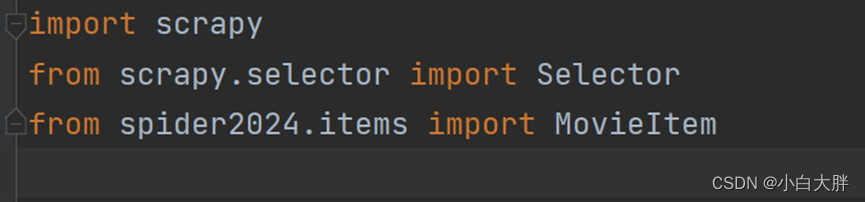
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# print(response.body)
sel = Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
#print(list_items)
movie_lists = []
for item in list_items():
movie_item = MovieItem()
movie_item['title'] = item.css("span.title::text").extract_first()
movie_item['rank'] = item.xpath('//span[@class="rating_num"]/text()').extract_first()
movie_item['subject'] = item.css("span.inq::text").extract_first()
movie_lists.append(movie_item)
yield movie_item运行则会出现以下错误:
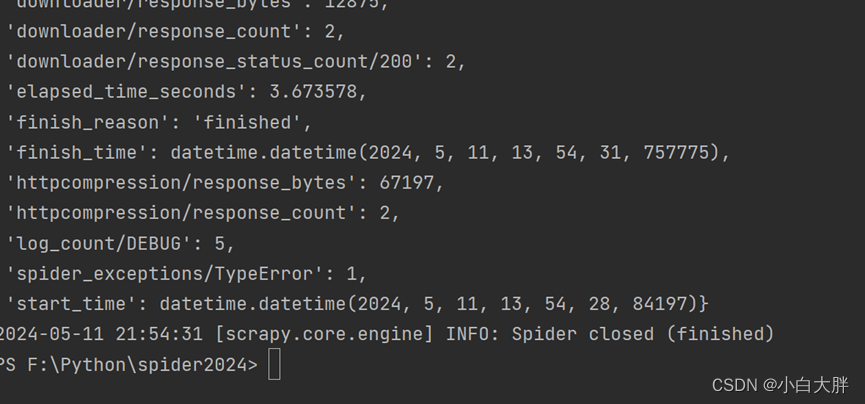
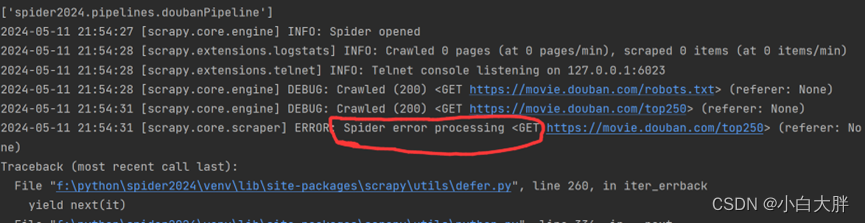
- 运行虽然完成了但没有任何数据产生,这说明没有爬取成功
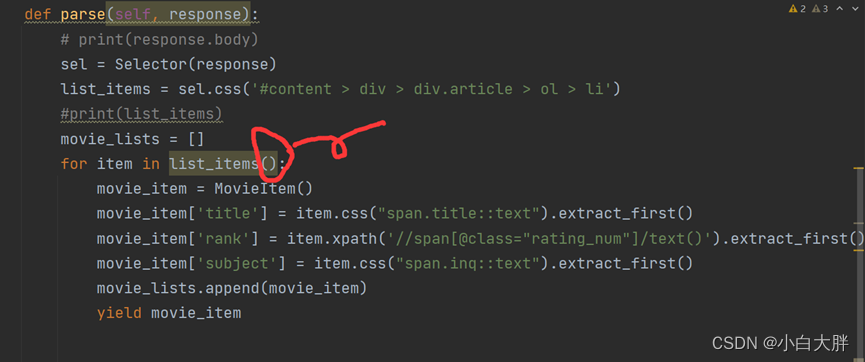
- 最后通过检查代码发现是语法问题,由于自己是在写for循环时习惯性的填了括号才导致出现这样的错误。将图中括号去除运行即可。
- 再继续在Terminal里运行代码:scrapy crawl douban
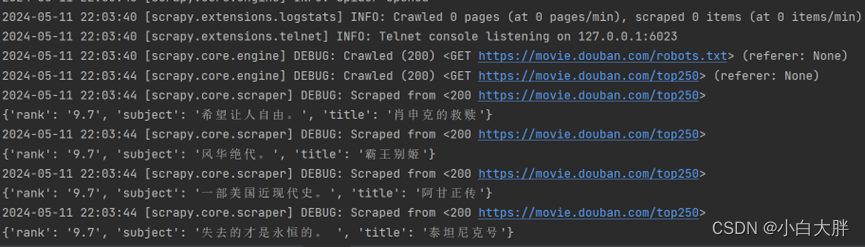
- 数据爬取成功,问题解决——祝大家学习愉快!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









