







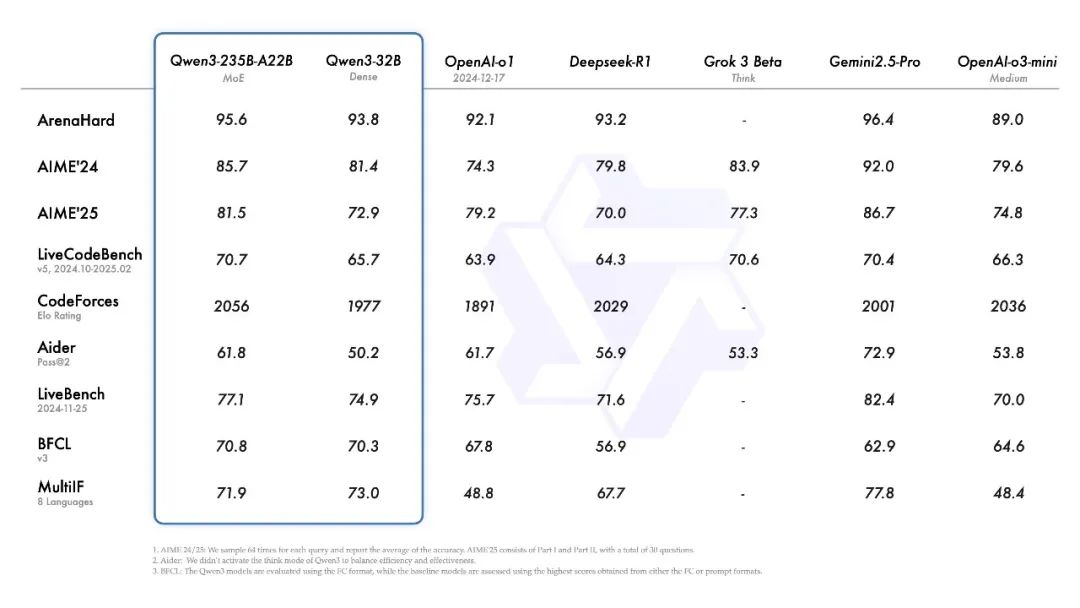
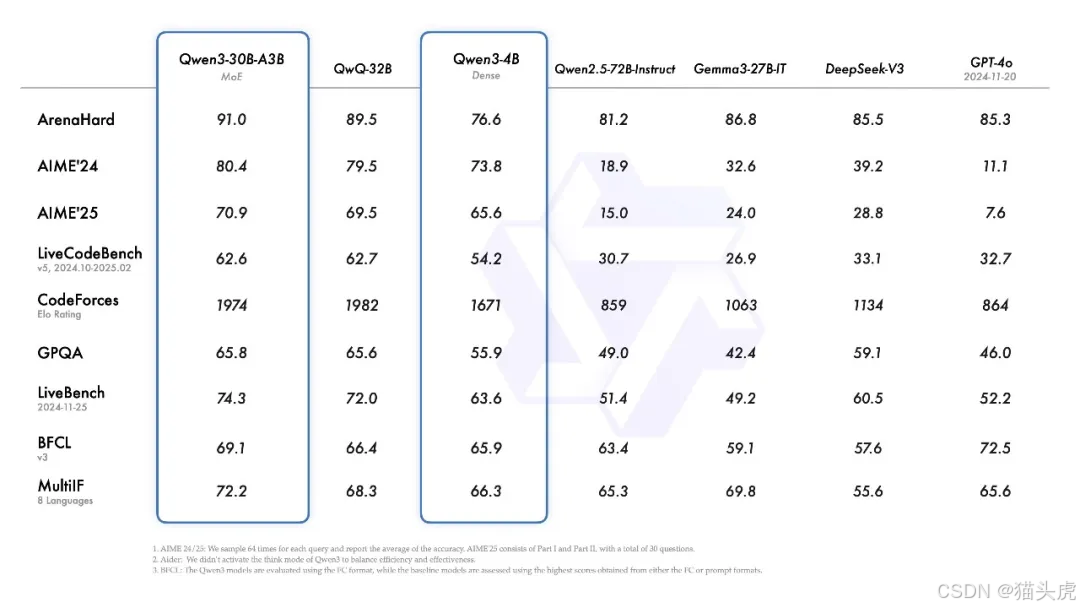
今天,阿里云正式发布了 Qwen3,这款新推出的模型属于 Qwen 系列大型语言模型的最新成员。根据最新基准测试,旗舰模型 Qwen3-235B-A22B 在代码、数学以及通用能力等方面,展现出强劲的竞争力,甚至与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型一较高下。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量仅为 QwQ-32B 的 10%,其性能表现更为卓越,而像 Qwen3-4B 这种小型模型也能够与 Qwen2.5-72B-Instruct 相媲美。
文章目录
作者简介
猫头虎是谁?
大家好,我是 猫头虎,AI全栈工程师,某科技公司CEO,猫头虎技术团队创始人,也被大家称为虎哥。我目前是COC北京城市开发者社区主理人、COC西安城市开发者社区主理人,以及云原生开发者社区主理人,在多个技术领域如云原生、前端、后端、运维和AI都有超多内容更新。
感谢全网三十多万粉丝的持续支持,我希望通过我的分享,帮助大家更好地掌握和使用各种技术产品,提升开发效率与体验。
作者名片 ✍️
- 博主:猫头虎
- 全网全平台搜索关键词 猫头虎 即可与我建联
- 作者微信号:Libin9iOak
- 作者公众号:猫头虎技术团队
- 更新日期:2025年04月22日
- 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
加入我们AI共创团队 🌐
- 猫头虎AI共创社群矩阵列表:
加入猫头虎的AI共创变现圈,一起探索编程世界的无限可能! 🚀
正文
同时,阿里云已开源了两款 MoE 模型的权重:Qwen3-235B-A22B,一个拥有超过 2350 亿参数和 220 亿激活参数的大型模型,以及 Qwen3-30B-A3B,一个小型 MoE 模型,拥有约 300 亿参数和 30 亿激活参数。除此之外,Qwen3 系列还包括六款 Dense 模型(Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B),所有这些模型都已在 Apache 2.0 许可下开源。
| Models | Layers | Heads (Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
| Models | Layers | Heads (Q / KV) | Experts (Total/ Activated) | Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
经过后训练的模型,如 Qwen3-30B-A3B,以及其预训练基座模型(如 Qwen3-30B-A3B-Base)现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署方面,推荐使用 SGLang 和 vLLM 等框架,而对于本地使用,Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具同样是不错的选择。这些工具为用户提供了更加便捷的 Qwen3 集成方式,适用于研究、开发及生产环境。
Qwen3 的发布与开源,标志着大型基础模型研究与开发迈出了重要一步。对于全球研究人员、开发者和企业组织来说,这将极大地助力他们在构建创新解决方案时,能够借助前沿技术的支持。
在 Qwen Chat 网页版 (chat.qwen.ai) 和 通义 APP 中,用户可以直接体验 Qwen3 的强大功能。
实测体验
代码能力测试:
提示词:
Write a p5.html script that simulates 25 particles in a vacuum space of a cylindrical container, bouncing within its boundaries. Use different colors for each ball and ensure they leave a trail showing their movement. Add a slow rotation of the container to give better view of what's going on in the scene. Make sure to create proper collision detection and physic rules to ensure particles remain in the container. Add an external spherical container. Add a slow zoom in and zoom out effect to the whole scene.

代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Particle Simulation in Cylinder</title>
<script src="https://cdn.jsdelivr.net/npm/p5@1.9.0/lib/p5.min.js"></script>
<style>
body {
margin: 0;
overflow: hidden;
background-color: #000;
}
</style>
</head>
<body>
<script>
let particles = [];
const numParticles = 25;
const radiusInnerCylinder = 150;
const heightCylinder = 300;
const radiusOuterSphere = 400;
let rotAngle = 0;
let zoomFactor = 1;
let zoomDir = 0.001;
function setup() {
createCanvas(windowWidth, windowHeight, WEBGL);
colorMode(HSB, 255);
// Create particles
for (let i = 0; i < numParticles; i++) {
let r = random(10, 20);
let angle = random(TWO_PI);
let x = random(-radiusInnerCylinder / 2, radiusInnerCylinder / 2);
let z = random(-radiusInnerCylinder / 2, radiusInnerCylinder / 2);
let y = random(-heightCylinder / 2, heightCylinder / 2);
let vx = random(-2, 2);
let vy = random(-2, 2);
let vz = random(-2, 2);
let hue = map(i, 0, numParticles, 0, 255);
particles.push(new Particle(x, y, z, vx, vy, vz, r, color(hue, 200, 255)));
}
}
function draw() {
background(0);
// Zoom effect
zoomFactor += zoomDir;
if (zoomFactor > 1.5 || zoomFactor < 1) zoomDir *= -1;
scale(zoomFactor);
// Rotate scene
rotateY(rotAngle);
rotAngle += 0.005;
// Draw outer sphere
noFill();
stroke(255, 50);
sphere(radiusOuterSphere);
// Draw inner cylinder
push();
rotateX(PI / 2); // Align cylinder to Y-axis vertically
noFill();
stroke(255);
cylinder(radiusInnerCylinder, heightCylinder);
pop();
// Update and display particles
for (let p of particles) {
p.update();
p.checkCollision();
p.display();
p.drawTrail();
}
}
class Particle {
constructor(x, y, z, vx, vy, vz, r, col) {
this.pos = createVector(x, y, z);
this.vel = createVector(vx, vy, vz);
this.radius = r;
this.color = col;
this.trail = [];
}
update() {
this.pos.add(this.vel);
// Add position to trail
this.trail.push(this.pos.copy());
if (this.trail.length > 20) this.trail.shift();
}
checkCollision() {
// Cylinder collision (radial + top/bottom)
let radialDist = sqrt(this.pos.x * this.pos.x + this.pos.z * this.pos.z);
if (radialDist + this.radius > radiusInnerCylinder) {
// Reflect radial velocity
let normal = createVector(this.pos.x, 0, this.pos.z).normalize();
let dot = this.vel.dot(normal);
this.vel.sub(p5.Vector.mult(normal, 2 * dot));
// Clamp position
let scale = (radiusInnerCylinder - this.radius) / radialDist;
this.pos.x *= scale;
this.pos.z *= scale;
}
// Top and bottom collision
if (abs(this.pos.y) + this.radius > heightCylinder / 2) {
this.vel.y *= -1;
this.pos.y = constrain(this.pos.y, -heightCylinder / 2 + this.radius, heightCylinder / 2 - this.radius);
}
// Outer Sphere collision
let distFromCenter = this.pos.mag();
if (distFromCenter + this.radius > radiusOuterSphere) {
let normal = this.pos.copy().normalize();
let dot = this.vel.dot(normal);
this.vel.sub(p5.Vector.mult(normal, 2 * dot));
// Clamp position
let scale = (radiusOuterSphere - this.radius) / distFromCenter;
this.pos.mult(scale);
}
}
display() {
push();
translate(this.pos.x, this.pos.y, this.pos.z);
noStroke();
fill(this.color);
sphere(this.radius);
pop();
}
drawTrail() {
noFill();
beginShape();
for (let i = 0; i < this.trail.length; i++) {
let alpha = map(i, 0, this.trail.length - 1, 0, 255);
stroke(hue(this.color), saturation(this.color), brightness(this.color), alpha);
vertex(this.trail[i].x, this.trail[i].y, this.trail[i].z);
}
endShape();
}
}
function windowResized() {
resizeCanvas(windowWidth, windowHeight);
}
</script>
</body>
</html>
运行效果图:
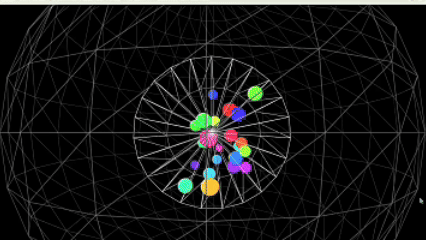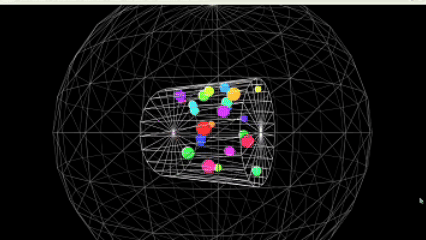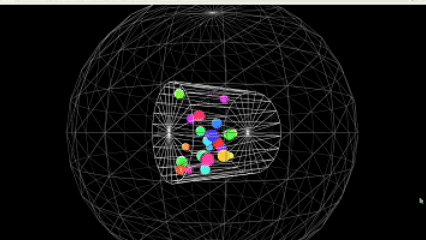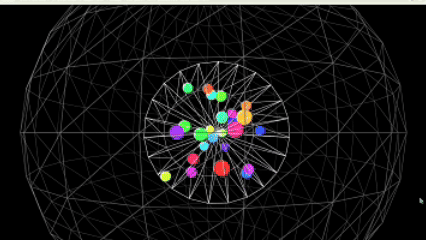
核心亮点
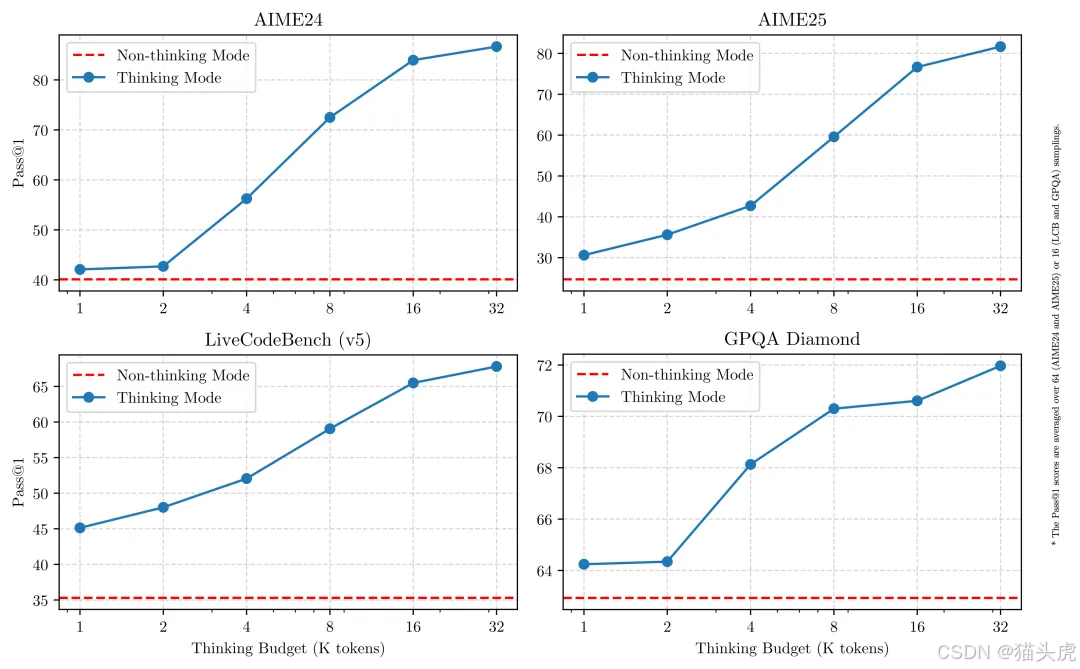
多种思考模式
Qwen3 模型支持两种思考模式,分别是:
- 思考模式:在此模式下,模型会逐步推理并经过深思熟虑后给出最终答案。非常适合那些需要深入分析和推理的复杂问题。
- 非思考模式:此模式下,模型能提供更快速、几乎即时的响应,适用于对速度要求较高的简单问题。
这种灵活的设计使得用户可以根据不同的需求自由调整模型的“思考”程度。例如,面对复杂问题时,可以通过延长推理步骤来获得更深入的答案,而简单问题则可以通过快速响应来实现高效的解决方案。两种模式的结合,不仅提升了推理的稳定性,也确保了高效的“思考预算”控制。这意味着,用户可以根据任务需要,灵活调整计算和推理的资源,确保成本效益与推理质量的平衡。
多语言支持
Qwen3 支持 119 种语言和方言,这使得它在全球应用中具备了广泛的适用性,不论是跨国企业、开发者还是研究人员,都能够受益于这一语言能力。
| 语系 | 语种&方言 |
|---|---|
| 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、罗马尼亚语、达里语、南非荷兰语、马其顿语、僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| 汉藏语系 | 中文(简体中文、繁体中文、粤语)、缅甸语 |
| 亚非语系 | 阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 |
| 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) |
| 德拉威语 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| 突厥语系 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| 壮侗语系 | 泰语、老挝语 |
| 乌拉尔语系 | 芬兰语、爱沙尼亚语、匈牙利语 |
| 南亚语系 | 越南语、高棉语 |
| 其他 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
预训练与数据集
Qwen3 的预训练数据集较 Qwen2.5 有了显著扩展。与 Qwen2.5 使用的 18 万亿 token 相比,Qwen3 的数据集几乎是前者的两倍,达到了 36 万亿个 token,涵盖了 119 种语言和方言。为了构建这个庞大的数据集,除了从网络上收集数据,阿里云还从 PDF 文档中提取信息。通过 Qwen2.5-VL 和 Qwen2.5 进行数据提取与质量改进,进一步提升了文档内容的质量。而在数学和代码数据领域,阿里云利用 Qwen2.5-Math 和 Qwen2.5-Coder 模型合成了大量数据,包含教科书、问答对及代码片段等。
Qwen3 的预训练过程分为三个阶段:
- 阶段一(S1):在超过 30 万亿个 token 上进行训练,提供了基本的语言技能和通用知识。
- 阶段二(S2):增加了更高比例的知识密集型数据(如 STEM、编程和推理任务),并在额外的 5 万亿个 token 上进行了预训练。
- 阶段三:使用高质量的长上下文数据,并将上下文长度扩展到 32K token,确保模型能够有效处理更长的输入。
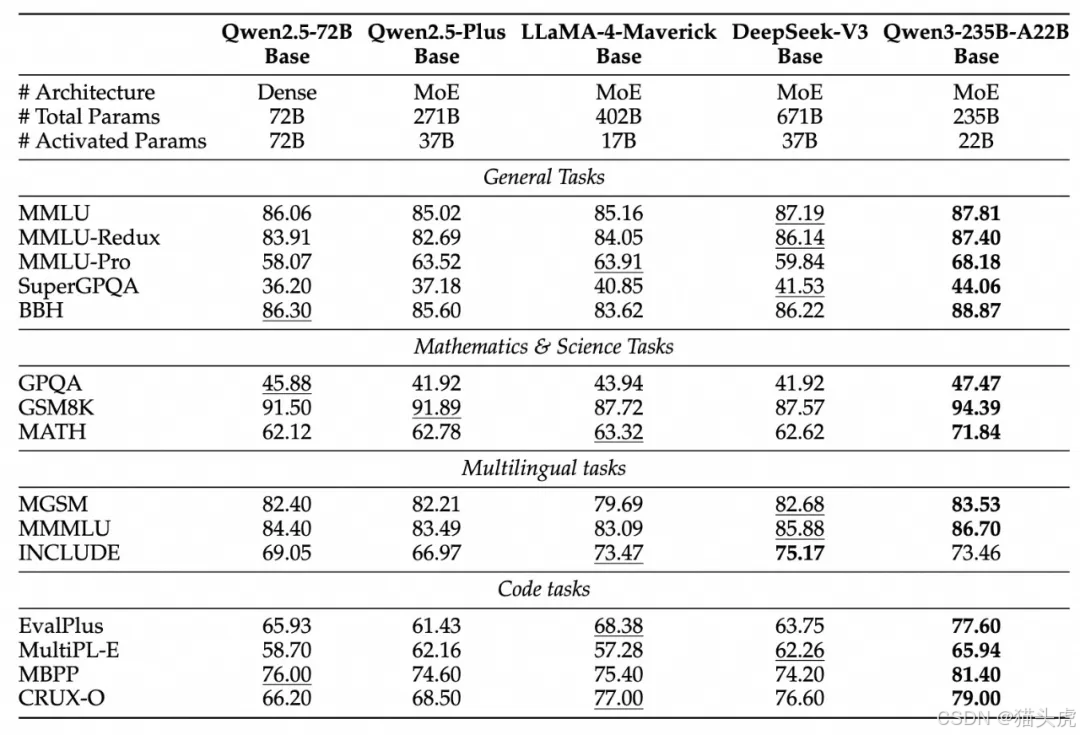
得益于架构的改进和训练数据的增加,Qwen3 在基础模型性能上超越了 Qwen2.5。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 的表现与 Qwen2.5-3B/7B/14B/32B/72B-Base 相当,甚至在 STEM、编码和推理领域超过了更大规模的 Qwen2.5 模型。特别是在 MoE 模型中,尽管激活参数仅为 10%,Qwen3 基础模型依然能够达到与 Qwen2.5 模型相似的性能,极大节省了训练和推理的成本。
后训练
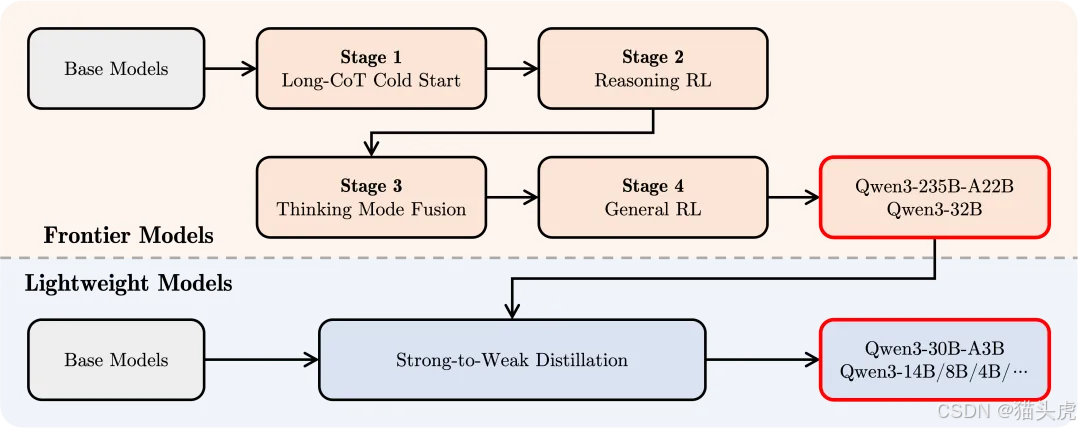
为了开发出一个同时具备思考推理和快速响应能力的混合模型,Qwen3 实施了一个四阶段的训练流程:
- 长思维链冷启动:对模型进行了初步微调,涵盖了数学、代码、逻辑推理等多个领域。
- 长思维链强化学习:通过基于规则的奖励,进一步提升模型的探索和推理能力。
- 思维模式融合:将思考模式与快速响应模式进行整合,确保推理和快速反应能力的无缝结合。
- 通用强化学习:在多个领域的任务上应用强化学习,以进一步提高模型的通用能力并优化行为。
接下来的部分将深入讨论如何开始使用 Qwen3 和其高级功能。
开始使用 Qwen3
如果你准备在自己的项目中使用 Qwen3,这里有一些简单的指南来帮助你开始。首先,在 Hugging Face Transformers 中使用 Qwen3-30B-A3B 模型的标准示例代码如下:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
要禁用思考模式,只需在调用时修改 enable_thinking 参数:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # 默认情况下,enable_thinking=True
)
部署 Qwen3
对于部署,推荐使用以下框架和工具:
-
SGLang:
使用 SGLang 运行一个与 OpenAI API 兼容的 API endpoint。python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3 -
vLLM:
vLLM 也是一个高效的部署框架,可以用来提供推理服务。vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1若要禁用思考模式,则可以移除
--reasoning-parser参数以及--enable-reasoning。 -
本地开发:
如果你是本地开发者,也可以通过以下命令在 Ollama 环境中与模型进行交互:ollama run qwen3:30b-a3b同样,其他本地开发工具如 LMStudio、llama.cpp 或 KTransformers 也支持本地开发和调试。
高级用法
Qwen3 还提供了强大的软切换机制,允许用户在启用思考模式时动态控制模型的行为。你可以通过在用户提示或系统消息中添加 /think 或 /no_think 来逐轮切换思考模式。例如:
用户: /think 你能告诉我量子物理的基本原理吗?
模型: 量子物理是一种描述微观世界的理论,基于波粒二象性等概念...
用户: /no_think 太阳是如何产生光和热的?
模型: 太阳通过核聚变反应,将氢转化为氦并释放大量的能量。
以下是一个多轮对话的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
classQwenChatbot:
def __init__(self, model_name="Qwen3-30B-A3B/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
通过这种方式,用户可以在多轮对话中自由切换思考模式,使得 Qwen3 更加灵活适应各种应用场景。
Agent 示例
Qwen3 在工具调用方面表现出色,特别是与 Qwen-Agent 配合使用时。Qwen-Agent 内部封装了工具调用模板和解析器,可以显著减少代码的复杂性,提升开发效率。你可以定义可用的工具,使用 MCP 配置文件,或者集成其他第三方工具来扩展功能。
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
这使得开发者能够更容易地集成 Qwen3 的强大功能,将其应用到各种任务中,比如自动化工作流、数据分析以及智能客服等。
参考资料:
1.Qwen3:思深,行速:https://mp.weixin.qq.com/s/OvobsCPW0IwxeSm8pljv-A
Qwen3 的未来发展
Qwen3 是通向通用人工智能(AGI)和超级人工智能(ASI)道路上的一个重要里程碑。通过扩大预训练和强化学习的规模,Qwen3 实现了更高层次的智能,并提供了更强大的推理与快速响应能力的结合。未来,阿里云计划继续优化模型架构和训练方法,进一步提升模型的表现。预期的提升包括:
- 扩展数据规模:进一步增加训练数据,提升模型的多样性和泛化能力。
- 增加模型大小:通过扩展参数规模,提高模型的推理能力。
- 延长上下文长度:增加模型能够处理的上下文长度,以便更好地处理长文本输入。
- 拓宽模态范围:将 Qwen3 的能力扩展到更多的数据模态,例如视觉、声音等。
- 强化学习:利用环境反馈来推进模型的长周期推理能力。
随着这些目标的实现,Qwen3 有望为各行各业的工作和生活带来更深远的影响。
结语
Qwen3 的发布不仅标志着阿里云在 AI 领域的技术突破,也为全球的开发者和研究者提供了强大的工具。通过开源、灵活的部署方案以及多语言支持,Qwen3 在推动人工智能技术应用普及方面发挥了重要作用。如果你希望体验或参与这一前沿技术,可以访问 Qwen Chat 网页版(chat.qwen.ai)或下载 通义 APP,开始使用 Qwen3!
文末粉丝专属福利
👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击文末名片获取更多信息。我是猫头虎,期待与您的交流! 🦉💬
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥66/月¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
粉丝福利 GO ! GO ! Go !
cursor随便用!
GPT4.5和GPT4.1 粉丝特享 66园子/🈷️
万粉变现入口:https://gitcode.com/qq_44866828/CSDNWF
AI编程工具特惠入口:https://yeka.ai/i/CHATVIP
GPT4.5/GPT4.1 粉丝特享 66园子/🈷️
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥66/月¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
联系我与版权声明 📩
- 联系方式:
- 猫头虎微信号: Libin9iOak
- 万粉变现经纪人微信号:CSDNWF
- 公众号: 猫头虎技术团队
- 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击✨⬇️下方名片⬇️✨,加入猫头虎AI共创社群,交流AI新时代变现的无限可能。一起探索科技的未来,共同成长。🚀



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











