






1 接上文整合讲,
2本例与上文关系不大。 这里我没配置数据库,自行增加
2.1首先我们需要把/usr/local/solr/solr-7.7.0/contrib/extraction/lib 所有的jar 放到tomcat下的solr的web_info下的lib里
/usr/local/solr/apache-tomcat-8.5.31/webapps/solr7/WEB-INF/lib
2.2 以及还要把
把dataimport插件(/usr/local/solr/solr-7.7.0/dist 下)的依赖的jar包添加到/usr/local/solr/solrhome/contrib/dataimporthandler/lib下,lib目录没有就创建一个
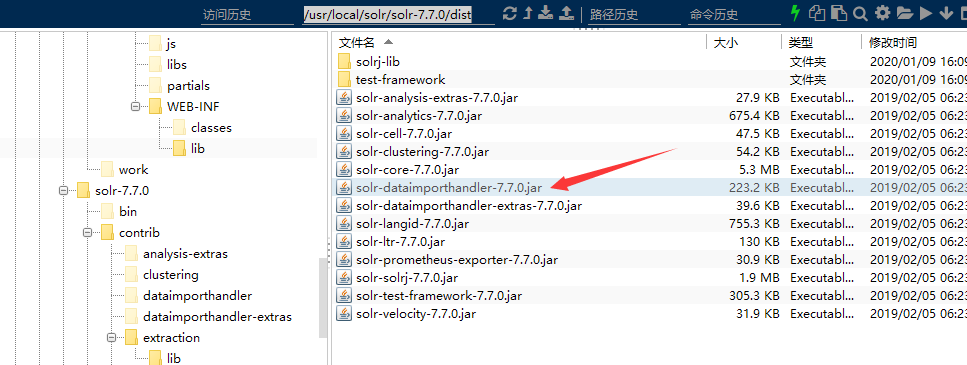
3jar都放好后,需要对new_core 进行配置
3.1打开 /usr/local/solr/solrhome/new_core/conf 下的solrconfig.xml
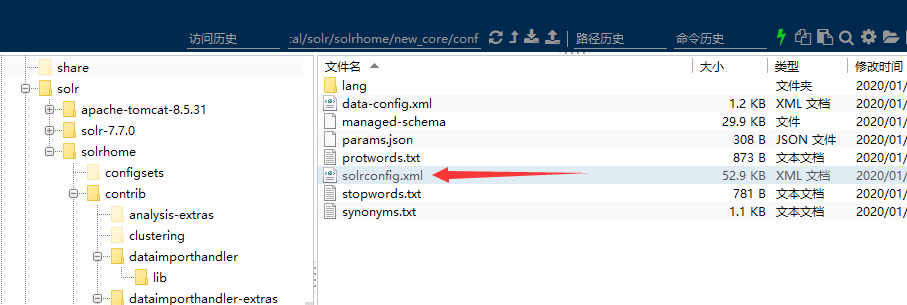
添加以下:
<lib dir="${solr.install.dir:..}/contrib/dataimporthandler/lib" regex=".*\.jar" />
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3.2 以及在该目录下 创建 data-config.xml。
我自己的solr服务器用 /usr/file 存放pdf.doc等文件
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="/usr/file" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false">
<field column="file" name="id"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>
<entity name="pdf" processor="TikaEntityProcessor"
url="${file.fileAbsolutePath}" format="text">
<field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased,
but in Solr schema it is lower-cased
-->
<!--- 这里的分词需要在managed-schemea 设置自己的分词规则-->
<field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
managed-schemea:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Solr managed schema - automatically generated - DO NOT EDIT -->
<schema name="default-config" version="1.6">
<uniqueKey>id</uniqueKey>
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/"/>
</analyzer>
</fieldType>
<fieldType name="binary" class="solr.BinaryField"/>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<fieldType name="delimited_payloads_float" class="solr.TextField" indexed="true" stored="false">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="float"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_int" class="solr.TextField" indexed="true" stored="false">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="integer"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_string" class="solr.TextField" indexed="true" stored="false">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="identity"/>
</analyzer>
</fieldType>
<fieldType name="descendent_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="location" class="solr.LatLonPointSpatialField" docValues="true"/>
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType" geo="true" maxDistErr="0.001" distErrPct="0.025" distanceUnits="kilometers"/>
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="pdate" class="solr.DatePointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="pfloat" class="solr.FloatPointField" docValues="true"/>
<fieldType name="pfloats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="phonetic_en" class="solr.TextField" indexed="true" stored="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory" inject="false"/>
</analyzer>
</fieldType>
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="pints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="point" class="solr.PointType" subFieldSuffix="_d" dimension="2"/>
<fieldType name="random" class="solr.RandomSortField" indexed="true"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" docValues="true" multiValued="true"/>
<fieldType name="text_ar" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ar.txt" ignoreCase="true"/>
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.ArabicStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_bg" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_bg.txt" ignoreCase="true"/>
<filter class="solr.BulgarianStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ca" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ElisionFilterFactory" articles="lang/contractions_ca.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ca.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Catalan"/>
</analyzer>
</fieldType>
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_cz" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_cz.txt" ignoreCase="true"/>
<filter class="solr.CzechStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_da" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_da.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Danish"/>
</analyzer>
</fieldType>
<fieldType name="text_de" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_de.txt" ignoreCase="true"/>
<filter class="solr.GermanNormalizationFilterFactory"/>
<filter class="solr.GermanLightStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_el" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.GreekLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_el.txt" ignoreCase="false"/>
<filter class="solr.GreekStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="1" splitOnCaseChange="1" generateWordParts="1" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="0" generateNumberParts="1" splitOnCaseChange="1" generateWordParts="1" catenateAll="0" catenateWords="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting_tight" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_es" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_es.txt" ignoreCase="true"/>
<filter class="solr.SpanishLightStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_eu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_eu.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Basque"/>
</analyzer>
</fieldType>
<fieldType name="text_fa" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.PersianCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.PersianNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_fa.txt" ignoreCase="true"/>
</analyzer>
</fieldType>
<fieldType name="text_fi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_fi.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Finnish"/>
</analyzer>
</fieldType>
<fieldType name="text_fr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ElisionFilterFactory" articles="lang/contractions_fr.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_fr.txt" ignoreCase="true"/>
<filter class="solr.FrenchLightStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ga" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ElisionFilterFactory" articles="lang/contractions_ga.txt" ignoreCase="true"/>
<filter class="solr.StopFilterFactory" words="lang/hyphenations_ga.txt" ignoreCase="true"/>
<filter class="solr.IrishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ga.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Irish"/>
</analyzer>
</fieldType>
<fieldType name="text_gen_sort" class="solr.SortableTextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" maxPosQuestion="2" maxFractionAsterisk="0.33" maxPosAsterisk="3" withOriginal="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_gl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_gl.txt" ignoreCase="true"/>
<filter class="solr.GalicianStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_hi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.IndicNormalizationFilterFactory"/>
<filter class="solr.HindiNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_hi.txt" ignoreCase="true"/>
<filter class="solr.HindiStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_hu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_hu.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Hungarian"/>
</analyzer>
</fieldType>
<fieldType name="text_hy" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_hy.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Armenian"/>
</analyzer>
</fieldType>
<fieldType name="text_id" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_id.txt" ignoreCase="true"/>
<filter class="solr.IndonesianStemFilterFactory" stemDerivational="true"/>
</analyzer>
</fieldType>
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<fieldType name="text_it" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ElisionFilterFactory" articles="lang/contractions_it.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_it.txt" ignoreCase="true"/>
<filter class="solr.ItalianLightStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ja" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ja.txt" ignoreCase="true"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ko" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KoreanTokenizerFactory" outputUnknownUnigrams="false" decompoundMode="discard"/>
<filter class="solr.KoreanPartOfSpeechStopFilterFactory"/>
<filter class="solr.KoreanReadingFormFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_lv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_lv.txt" ignoreCase="true"/>
<filter class="solr.LatvianStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_nl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_nl.txt" ignoreCase="true"/>
<filter class="solr.StemmerOverrideFilterFactory" dictionary="lang/stemdict_nl.txt" ignoreCase="false"/>
<filter class="solr.SnowballPorterFilterFactory" language="Dutch"/>
</analyzer>
</fieldType>
<fieldType name="text_no" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_no.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Norwegian"/>
</analyzer>
</fieldType>
<fieldType name="text_pt" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_pt.txt" ignoreCase="true"/>
<filter class="solr.PortugueseLightStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ro" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ro.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Romanian"/>
</analyzer>
</fieldType>
<fieldType name="text_ru" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_ru.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Russian"/>
</analyzer>
</fieldType>
<fieldType name="text_sv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_sv.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Swedish"/>
</analyzer>
</fieldType>
<fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ThaiTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_th.txt" ignoreCase="true"/>
</analyzer>
</fieldType>
<fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_tr.txt" ignoreCase="false"/>
<filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
</analyzer>
</fieldType>
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<field name="_root_" type="string" docValues="false" indexed="true" stored="false"/>
<field name="_text_" type="text_general" multiValued="true" indexed="true" stored="false"/>
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="content_ik" type="text_ik" indexed="true" stored="true"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="name" type="text_general"/>
<field name="title_ik" type="text_ik" indexed="true" stored="true"/>
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_ik" indexed="true" stored="true" omitNorms ="true"/>
<field name="author" type="string" indexed="true" stored="true"/>
<field name="fileSize" type="plong" indexed="true" stored="true"/>
<field name="fileLastModified" type="pdate" indexed="true" stored="true"/>
<field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
<dynamicField name="*_txt_en_split_tight" type="text_en_splitting_tight" indexed="true" stored="true"/>
<dynamicField name="*_descendent_path" type="descendent_path" indexed="true" stored="true"/>
<dynamicField name="*_ancestor_path" type="ancestor_path" indexed="true" stored="true"/>
<dynamicField name="*_txt_en_split" type="text_en_splitting" indexed="true" stored="true"/>
<dynamicField name="*_txt_sort" type="text_gen_sort" indexed="true" stored="true"/>
<dynamicField name="*_txt_rev" type="text_general_rev" indexed="true" stored="true"/>
<dynamicField name="*_phon_en" type="phonetic_en" indexed="true" stored="true"/>
<dynamicField name="*_s_lower" type="lowercase" indexed="true" stored="true"/>
<dynamicField name="*_txt_cjk" type="text_cjk" indexed="true" stored="true"/>
<dynamicField name="random_*" type="random"/>
<dynamicField name="*_t_sort" type="text_gen_sort" multiValued="false" indexed="true" stored="true"/>
<dynamicField name="*_txt_en" type="text_en" indexed="true" stored="true"/>
<dynamicField name="*_txt_ar" type="text_ar" indexed="true" stored="true"/>
<dynamicField name="*_txt_bg" type="text_bg" indexed="true" stored="true"/>
<dynamicField name="*_txt_ca" type="text_ca" indexed="true" stored="true"/>
<dynamicField name="*_txt_cz" type="text_cz" indexed="true" stored="true"/>
<dynamicField name="*_txt_da" type="text_da" indexed="true" stored="true"/>
<dynamicField name="*_txt_de" type="text_de" indexed="true" stored="true"/>
<dynamicField name="*_txt_el" type="text_el" indexed="true" stored="true"/>
<dynamicField name="*_txt_es" type="text_es" indexed="true" stored="true"/>
<dynamicField name="*_txt_eu" type="text_eu" indexed="true" stored="true"/>
<dynamicField name="*_txt_fa" type="text_fa" indexed="true" stored="true"/>
<dynamicField name="*_txt_fi" type="text_fi" indexed="true" stored="true"/>
<dynamicField name="*_txt_fr" type="text_fr" indexed="true" stored="true"/>
<dynamicField name="*_txt_ga" type="text_ga" indexed="true" stored="true"/>
<dynamicField name="*_txt_gl" type="text_gl" indexed="true" stored="true"/>
<dynamicField name="*_txt_hi" type="text_hi" indexed="true" stored="true"/>
<dynamicField name="*_txt_hu" type="text_hu" indexed="true" stored="true"/>
<dynamicField name="*_txt_hy" type="text_hy" indexed="true" stored="true"/>
<dynamicField name="*_txt_id" type="text_id" indexed="true" stored="true"/>
<dynamicField name="*_txt_it" type="text_it" indexed="true" stored="true"/>
<dynamicField name="*_txt_ja" type="text_ja" indexed="true" stored="true"/>
<dynamicField name="*_txt_ko" type="text_ko" indexed="true" stored="true"/>
<dynamicField name="*_txt_lv" type="text_lv" indexed="true" stored="true"/>
<dynamicField name="*_txt_nl" type="text_nl" indexed="true" stored="true"/>
<dynamicField name="*_txt_no" type="text_no" indexed="true" stored="true"/>
<dynamicField name="*_txt_pt" type="text_pt" indexed="true" stored="true"/>
<dynamicField name="*_txt_ro" type="text_ro" indexed="true" stored="true"/>
<dynamicField name="*_txt_ru" type="text_ru" indexed="true" stored="true"/>
<dynamicField name="*_txt_sv" type="text_sv" indexed="true" stored="true"/>
<dynamicField name="*_txt_th" type="text_th" indexed="true" stored="true"/>
<dynamicField name="*_txt_tr" type="text_tr" indexed="true" stored="true"/>
<dynamicField name="*_point" type="point" indexed="true" stored="true"/>
<dynamicField name="*_srpt" type="location_rpt" indexed="true" stored="true"/>
<dynamicField name="attr_*" type="text_general" multiValued="true" indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_str" type="strings" docValues="true" indexed="false" stored="false" useDocValuesAsStored="false"/>
<dynamicField name="*_dts" type="pdate" multiValued="true" indexed="true" stored="true"/>
<dynamicField name="*_dpf" type="delimited_payloads_float" indexed="true" stored="true"/>
<dynamicField name="*_dpi" type="delimited_payloads_int" indexed="true" stored="true"/>
<dynamicField name="*_dps" type="delimited_payloads_string" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="booleans" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="pfloats" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="pdoubles" indexed="true" stored="true"/>
<dynamicField name="*_dt" type="pdate" indexed="true" stored="true"/>
<dynamicField name="*_ws" type="text_ws" indexed="true" stored="true"/>
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_t" type="text_general" multiValued="false" indexed="true" stored="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_f" type="pfloat" indexed="true" stored="true"/>
<dynamicField name="*_d" type="pdouble" indexed="true" stored="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<copyField source="name" dest="name_str" maxChars="256"/>
</schema>
在solr页面操作
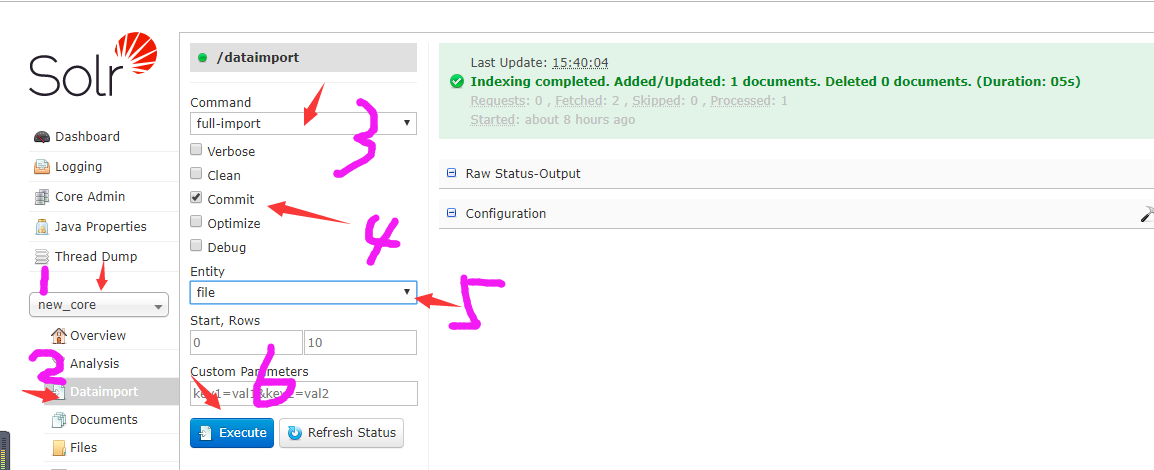
在验证下:
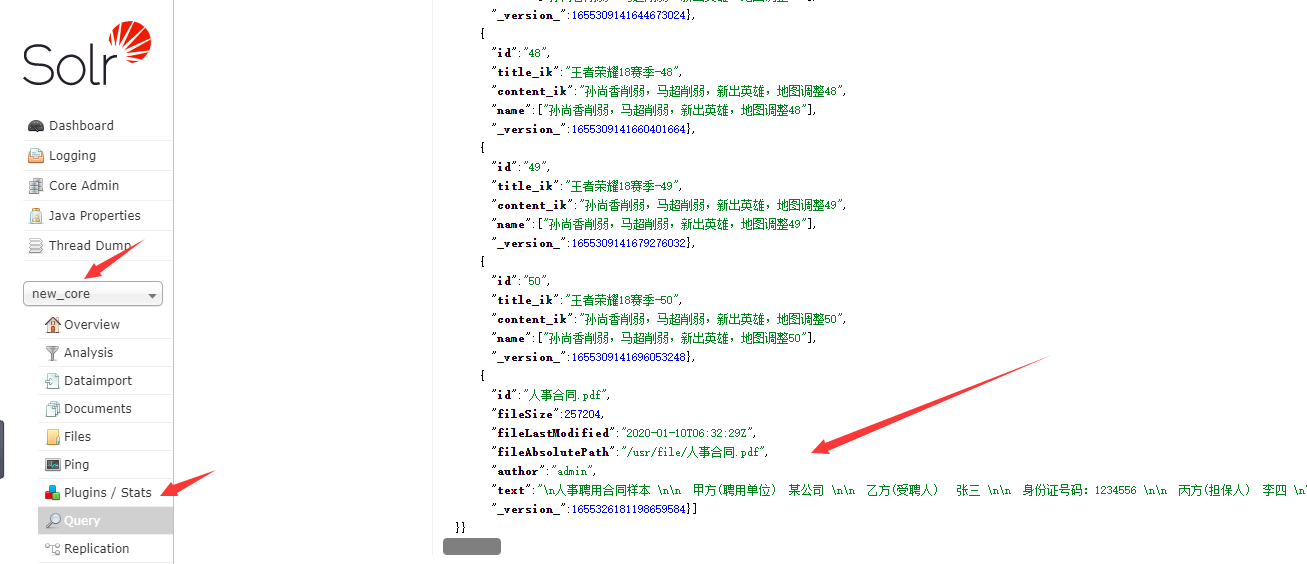
END: 在后面的篇章里,笔者会结合业务系统,做更多分析。















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









