







准备环境
本教程基于 Solr 7.7 官方文档
JDK 要求:java8+
在开始本教程前,推荐使用虚拟机构建 3 台 Linux 系统服务,用于服务的搭建和部署以及环境的隔离。
笔者在本地使用了两台 CentOS 7 的机器来部署 Demo 服务。
下载并解压 Solr
Solr 官方的下载地址:https://solr.apache.org/downloads.html
9.0 之前版本的 Lucene 地址:https://archive.apache.org/dist/lucene/solr/
下载好的 Solr 压缩包进行解压:
[root@stackstone-002 solr]# pwd
/opt/solr
[root@stackstone-002 solr]# ls
solr-7.7.2.tgz
[root@stackstone-002 solr]# tar -zxvf solr-7.7.2.tgz
解压后进入到 solr-7.7.2 目录中,其结构如下:
[root@stackstone-002 solr-7.7.2]# pwd
/opt/solr/solr-7.7.2
[root@stackstone-002 solr-7.7.2]# ls -lh
总用量 1.6M
drwxr-xr-x. 3 root root 147 1月 3 09:59 bin
-rw-r--r--. 1 root root 821K 5月 21 2019 CHANGES.txt
drwxr-xr-x. 11 root root 190 5月 29 2019 contrib
drwxr-xr-x. 4 root root 4.0K 1月 3 09:59 dist
drwxr-xr-x. 3 root root 38 1月 3 09:59 docs
drwxr-xr-x. 6 root root 88 1月 3 09:59 example
drwxr-xr-x. 2 root root 28K 1月 3 09:59 licenses
-rw-r--r--. 1 root root 13K 5月 17 2019 LICENSE.txt
-rw-r--r--. 1 root root 689K 5月 28 2019 LUCENE_CHANGES.txt
-rw-r--r--. 1 root root 26K 5月 17 2019 NOTICE.txt
-rw-r--r--. 1 root root 7.4K 5月 17 2019 README.txt
drwxr-xr-x. 10 root root 157 1月 3 09:59 server
练习1:索引 Techproducts 样例数据
本练习会启动 2 个节点的 solr 集群并在启动时创建 Collection。随后我们索引一些样例数据并装配 Solr 并执行一些基础查询。
用 SolrCloud 模式启动 Solr
启动 Solr:
- 类 Unix 系统:
bin/solr start -e cloud; - Windows 系统:
bin\solr.cmd start -e cloud;
我们会启动两个 Solr 服务,这个命令有一个选项 -noprompt 可以在不提升输入的情况下运行,由于我们需要修改其中两个默认值,所以我们不使用该选项。
[root@stackstone-002 solr-7.7.2]# ./bin/solr start -e cloud
*** [WARN] *** Your open file limit is currently 1024.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 45841.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
Welcome to the SolrCloud example!
This interactive session will help you launch a SolrCloud cluster on your local workstation.
To begin, how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes) [2]:
NOTE:
上面的命令打印出了 WARN 信息,Apache Solr在启动时会检查系统的某些资源限制设置,以确保它能在最佳状态下运行。你所看到的这两条警告信息是关于这些资源限制的。
- 打开文件限制(Open File Limit): 当前设置为1024。这个限制是指一个进程可以同时打开的最大文件数量。Solr需要能够打开许多文件,尤其是在处理大量数据时。如果这个限制太低,可能会导致Solr无法打开更多的文件,进而影响其性能和稳定性。因此,Solr建议将这个限制提高到65000。
- 最大进程限制(Max Processes Limit): 当前设置为45841。这个限制是指一个用户可以拥有的最大进程数。与打开文件限制类似,如果这个限制太低,可能会限制Solr的性能,尤其是在高负载情况下。Solr同样建议将这个限制提高到65000。
如果不希望看到这个提示,可以在
solr.in.sh中设置 SOLR_ULIMIT_CHECKS 为 false。如何更改 Linux 相关设置
在CentOS 7上修改文件打开限制和进程限制通常涉及以下步骤:
编辑limits.conf文件:
- 打开
/etc/security/limits.conf文件。你可以使用文本编辑器,如vi或nano。- 在文件末尾添加或修改以下行:
* soft nofile 65000 * hard nofile 65000 * soft nproc 65000 * hard nproc 65000- 这里
*代表所有用户,nofile代表打开文件的数量限制,nproc代表进程数量限制。soft限制是警告限制,hard限制是硬性限制。修改systemd的限制:
- CentOS 7使用systemd,你可能还需要修改systemd的限制。
- 编辑或创建
/etc/systemd/system.conf文件,添加或修改以下行:DefaultLimitNOFILE=65000 DefaultLimitNPROC=65000- 这将为所有通过systemd启动的服务设置默认限制。
应用更改:
- 完成编辑后,保存文件并关闭编辑器。
- 为了让更改生效,你需要重启系统或重新登录。
验证更改:
- 重启后,你可以使用
ulimit -Hn和ulimit -Hu命令来验证硬性限制是否已正确设置。
第一个提示询问我们想运行多少节点,默认启动 2 个节点,所以这里我们直接输入回车(enter)键。
Ok, let's start up 2 Solr nodes for your example SolrCloud cluster.
Please enter the port for node1 [8983]:
这里指定第一个节点运行的端口,默认为 8983,这里可以根据自己需要进行端口的更改,如果不需要修改直接输出回车键。
Please enter the port for node2 [7574]:
这里需要指定第二个节点的运行端口,这里我将其改成了8984。
如果控制台显示:
Creating Solr home directory /opt/solr/solr-7.7.2/example/cloud/node1/solr
Cloning /opt/solr/solr-7.7.2/example/cloud/node1 into
/opt/solr/solr-7.7.2/example/cloud/node2
Starting up Solr on port 8983 using command:
"bin/solr" start -cloud -p 8983 -s "example/cloud/node1/solr"
WARNING: Starting Solr as the root user is a security risk and not considered best practice. Exiting.
Please consult the Reference Guide. To override this check, start with argument '-force'
ERROR: Failed to start Solr using command: "bin/solr" start -cloud -p 8983 -s "example/cloud/node1/solr" Exception : org.apache.commons.exec.ExecuteException: Process exited with an error: 1 (Exit value: 1)
该问题是由于尝试以root用户身份启动Apache Solr造成的。Solr出于安全考虑,默认不允许以root用户运行,因为这会带来潜在的安全风险。运行Solr或类似的服务时,使用具有较少权限的用户是一种更安全的做法。
解决方法为两个步骤:
- 创建非root用户:
- 在你的系统上创建一个新用户,专门用于运行Solr。
- 你可以使用adduser命令创建新用户。例如,adduser solruser。
- 以新用户身份运行Solr:
- 使用su或sudo命令切换到新创建的用户,然后再次尝试启动Solr。
- 例如,使用su - solruser切换用户,然后再执行Solr的启动命令。
如果你确实需要以root用户身份启动Solr,可以添加-force参数来覆盖安全检查:
./bin/solr start -e cloud -force
如正常运行会显示:
Starting up Solr on port 8983 using command:
"bin/solr" start -cloud -p 8983 -s "example/cloud/node1/solr" -force
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=2586). Happy searching!
Starting up Solr on port 8984 using command:
"bin/solr" start -cloud -p 8984 -s "example/cloud/node2/solr" -z localhost:9983 -force
Waiting up to 180 seconds to see Solr running on port 8984 [\]
Started Solr server on port 8984 (pid=2757). Happy searching!
INFO - 2024-01-03 11:04:54.720; org.apache.solr.common.cloud.ConnectionManager; zkClient has connected
INFO - 2024-01-03 11:04:54.744; org.apache.solr.common.cloud.ZkStateReader; Updated live nodes from ZooKeeper... (0) -> (2)
INFO - 2024-01-03 11:04:54.767; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
此处启动了两个solr实例,因为我们使用的是 SolrCloud 模式,而且我们并没有指定外部 ZooKeeper 集群,Solr 会启动其自身的 Zookeeper 并且两个节点均连接到该 Zookeeper。
启动完成后,我们需要创建一个 Collection。
Now let's create a new collection for indexing documents in your 2-node cluster.
Please provide a name for your new collection: [gettingstarted]
此处我们将collection命名为“techproducts”。
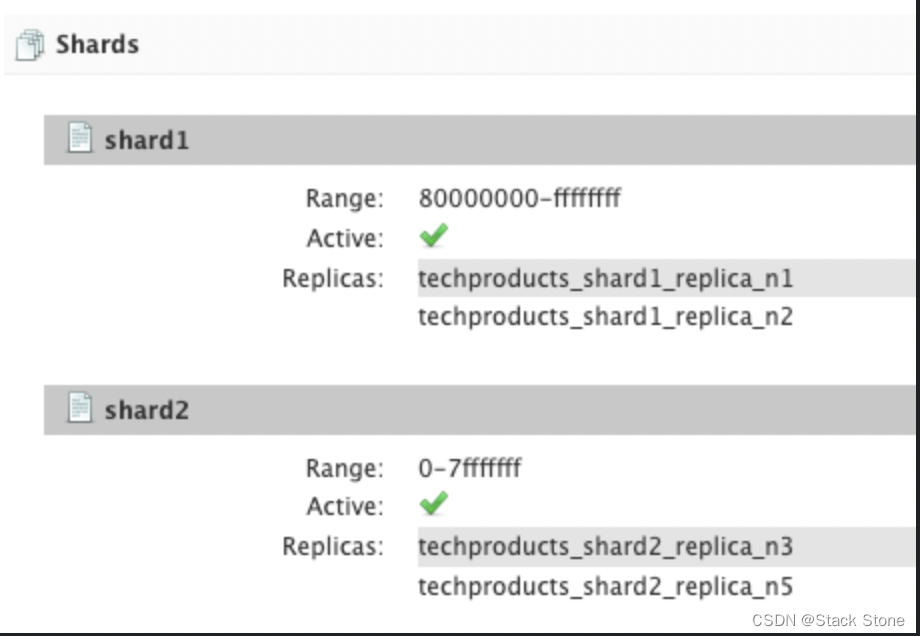
How many shards would you like to split techproducts into? [2]
此处询问我们在这两个节点上将索引拆分成多少分片(Shard),默认值是 2 意味着我们将在两个节点上相对均匀地分割索引,我们此处直接使用该默认值。
How many replicas per shard would you like to create? [2]
副本 (replica) 是用于故障转移的索引副本(可参阅 Solr Glossary definition ),我们此处也用该默认值,指定每个 Shard 创建 2 个副本。
Please choose a configuration for the techproducts collection, available options are:
_default or sample_techproducts_configs [_default]
Solr 有两个开箱即用的配置文件示例集(称为 configSet)。
一个集合必须有一个 configSet,它至少包含 Solr 的两个主要配置文件:模式文件(名为 Managed-Schema 或 schema.xml)和 solrconfig.xml。
这里的问题是想让我们从哪个 configSet 开始。 _default 是一个简单的选项,但请注意,有一个名称包含“techproducts”,该选项与我们的集合命名的名称相同。这个 configSet 是专门为支持我们想要使用的示例数据而设计的,因此在提示符下输入sample_techproducts_configs并按回车键。
到此处,Solr 将创建 Collection 并在控制台输出如下信息:
Created collection 'techproducts' with 2 shard(s), 2 replica(s) with config-set 'techproducts'
Enabling auto soft-commits with maxTime 3 secs using the Config API
POSTing request to Config API: http://localhost:8983/solr/techproducts/config
{"set-property":{"updateHandler.autoSoftCommit.maxTime":"3000"}}
Successfully set-property updateHandler.autoSoftCommit.maxTime to 3000
SolrCloud example running, please visit: http://localhost:8983/solr
此时 Solr 已经启动成功,可以准备数据了。
我们可以访问 Solr 的 Admin UI 管理界面:http://localhost8983/solr/。
Solr 现在运行了两个节点,一个端口号是 8983,另一个是 8984。自动创建了一个 collection techproducts,两个 shard 每个有两个副本。

索引 Techproducts 数据
现在 Solr 服务已经启动,但还没有任何数据,不能查询。
Solr 包含 bin/post 工具,以便于轻松索引各种类型的文档。我们将在下面的索引示例中使用此工具。
NOTE:
目前 bin/post 工具没有类似的 Windows 脚本,但调用的底层 Java 程序是可用的。
下面展示了 Windows 的示例,可以参阅发布工具文档的 Windows 部分以了解更多详细信息。
我们要索引的数据位于 example/exampledocs 目录下,这些文档采用多种文档格式(例如:JSON,CSV 等),我们可以一次性全部索引他们。
Linux/Mac
solr-7.7.0:$ bin/post -c techproducts example/exampledocs/*
Windows
C:\solr-7.7.0> java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs\*
执行上述命令后,会看到类似如下的输出:
[root@stackstone-002 solr-7.7.2]# bin/post -c techproducts example/exampledocs/*
java -classpath /opt/solr/solr-7.7.2/dist/solr-core-7.7.2.jar -Dauto=yes -Dc=techproducts -Ddata=files org.apache.solr.util.SimplePostTool example/exampledocs/books.csv example/exampledocs/books.json example/exampledocs/gb18030-example.xml example/exampledocs/hd.xml example/exampledocs/ipod_other.xml example/exampledocs/ipod_video.xml example/exampledocs/manufacturers.xml example/exampledocs/mem.xml example/exampledocs/money.xml example/exampledocs/monitor2.xml example/exampledocs/monitor.xml example/exampledocs/more_books.jsonl example/exampledocs/mp500.xml example/exampledocs/post.jar example/exampledocs/sample.html example/exampledocs/sd500.xml example/exampledocs/solr-word.pdf example/exampledocs/solr.xml example/exampledocs/test_utf8.sh example/exampledocs/utf8-example.xml example/exampledocs/vidcard.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/techproducts/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
POSTing file books.json (application/json) to [base]/json/docs
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file more_books.jsonl (application/json) to [base]/json/docs
POSTing file mp500.xml (application/xml) to [base]
POSTing file post.jar (application/octet-stream) to [base]/extract
POSTing file sample.html (text/html) to [base]/extract
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr-word.pdf (application/pdf) to [base]/extract
POSTing file solr.xml (application/xml) to [base]
POSTing file test_utf8.sh (application/octet-stream) to [base]/extract
POSTing file utf8-example.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
21 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/techproducts/update...
Time spent: 0:00:02.481
现在我们的 Solr 里已经索引了数据,现在可以开始准备搜索了~
基础检索
Solr 可以通过 REST 客户端、curl、wget、Chrome POSTMAN 等以及可用于多种编程语言的本机客户端进行查询。
Solr Admin UI 包含一个查询构建器界面,通过 techproducts 集合的“查询”选项卡(位于 http://localhost:8983/solr/#/techproducts/query)。
如果单击“Execute Query”按钮而不更改表单中的任何内容,我们将获得 10 个 JSON 格式的文档:
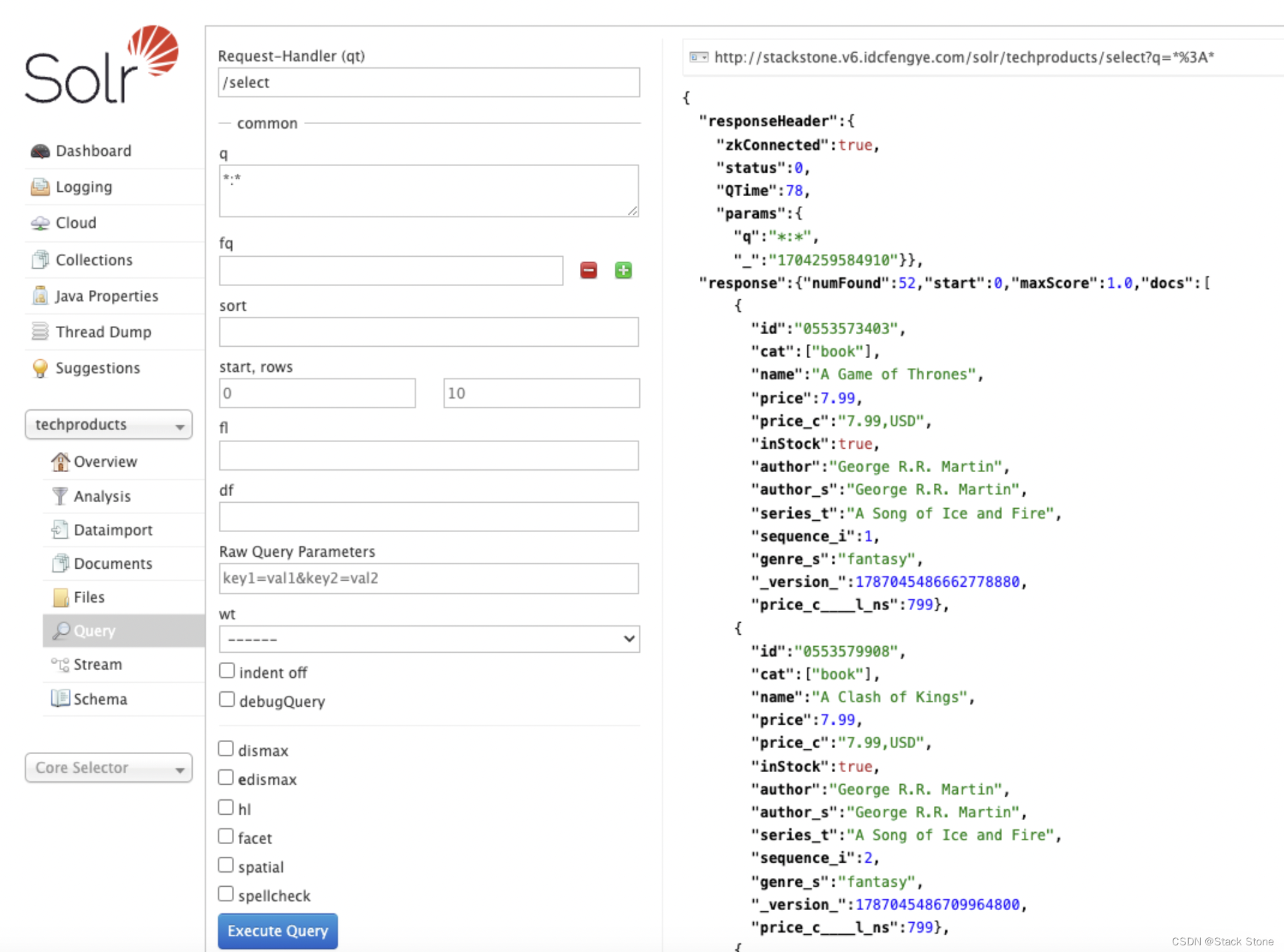
上图中右上角的浅灰色的连接是我们发送的请求 URL,如果单机它,我们的浏览器会显示原始的响应。
使用 curl 命令如下:
curl "http://localhost:8983/solr/techproducts/select?indent=on&q=*:*"
上面的请求中,我们使用 Solr 的查询参数(q)和特殊语法来请求索引(:)中的所有文档。并不是所有的文档都返回给我们,参数 rows 控制着返回文档的条数,上图中可以看到 rows 被设置了 10。我们可以在 UI 界面更改我们想要修改的参数。
Solr 具有非常强大的搜索选项,本教程无法涵盖所有这些选项。但我们可以涵盖一些最常见的查询类型。
搜索单个 Term
要搜索 Term,我们在搜索页面将更改参数 q 的值,将*:*替换成我们要检索的 Term。
输入 “foundation” 并点击 [Execute Query] 按钮。
如果你想使用 curl 可以输入如下命令:
curl "http://localhost:8983/solr/techproducts/select?q=foundation&rows=1"
我们会得到如下内容:
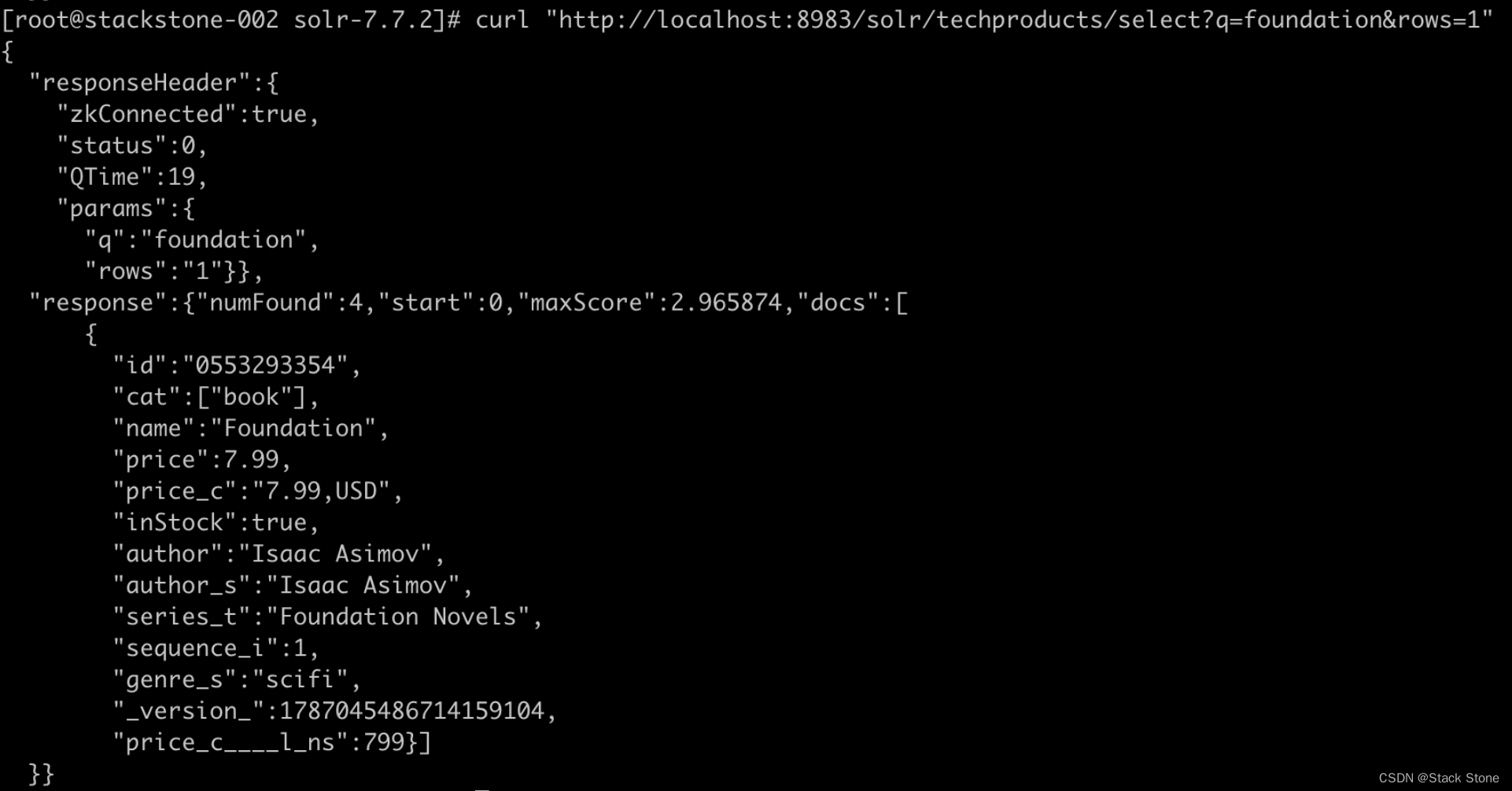
响应表明有 4 个命中 (“numFound”:4),我们只在上面的示例输出中包含了一个文档。
注意文档之前的responseHeader,此标题将包含您为搜索设置的参数。默认情况下,它仅显示您为此查询设置的参数。
我们返回的文档包括每个已索引文档的所有字段,这也是默认的行为。如果要限制响应中的字段,可以使用 fl 参数,该参数采用逗号分隔的字段名称列表。这是Admin UI 界面中查询表单上的可用字段之一。
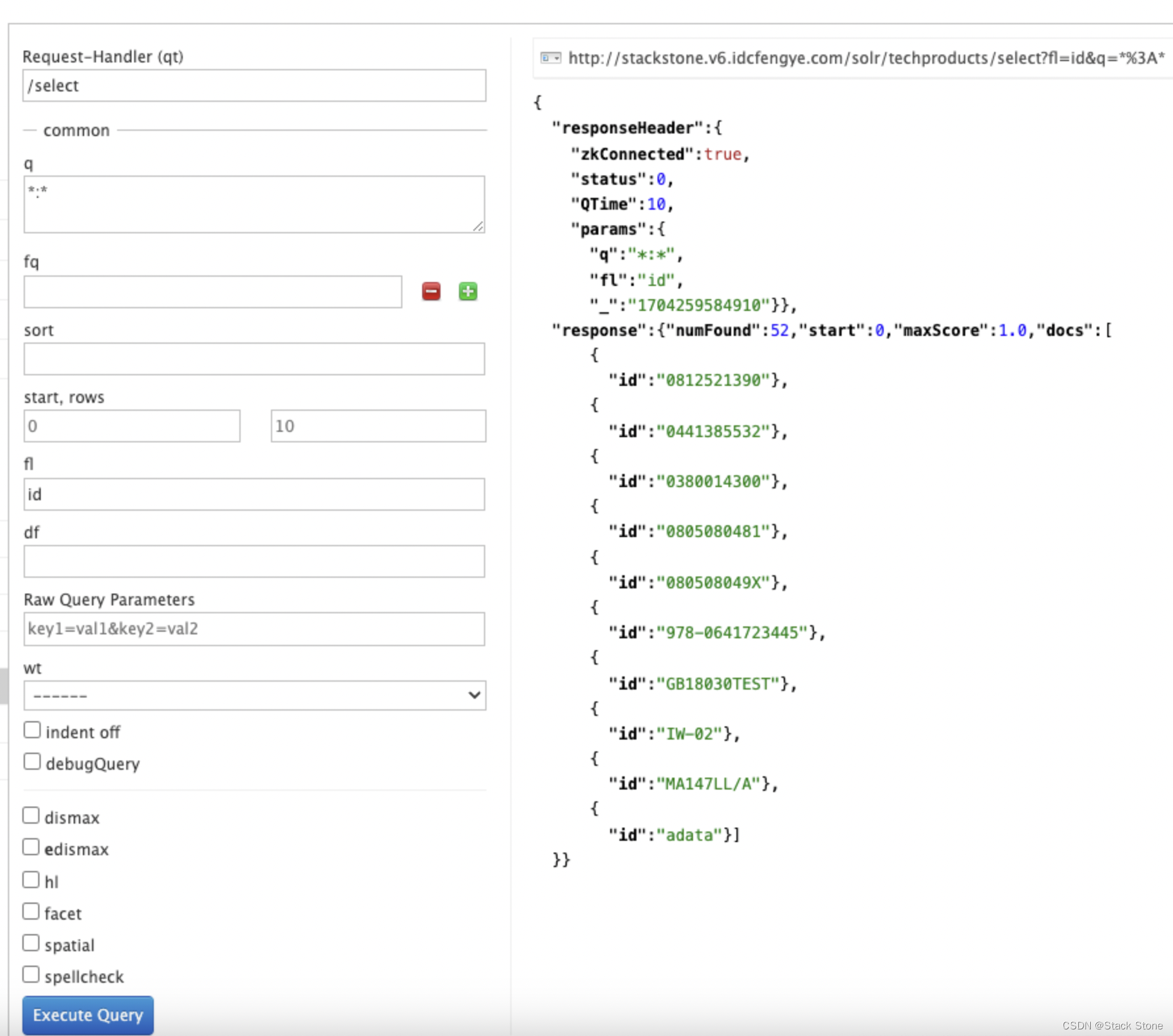
我们将 id 填写到 fl 输入框中,再次执行查询,或在 curl 中明确指定:
curl "http://localhost:8983/solr/techproducts/select?q=foundation&fl=id"
此时应该只能看到返回的匹配记录的 ID。
字段检索(Field Searches)
所有 Solr 查询都会使用某个字段查找文档。通常,我们希望同时查询多个字段,这就是我们迄今为止在“基础”查询中所做的事情。这可以通过使用复制字段来实现,这些字段已经使用这组配置进行了设置。我们将在练习 2 中更多地介绍复制字段。
但有时,我们希望将查询限制为单个字段。这可以使查询更加高效,并且结果与用户更加相关。
我们的小样本数据集中的大部分数据都与产品相关。假设我们想要查找索引中的所有“electronics”产品。在 q 框中输入“Electronics”并执行查询,我们会得到 14 个结果,如下:
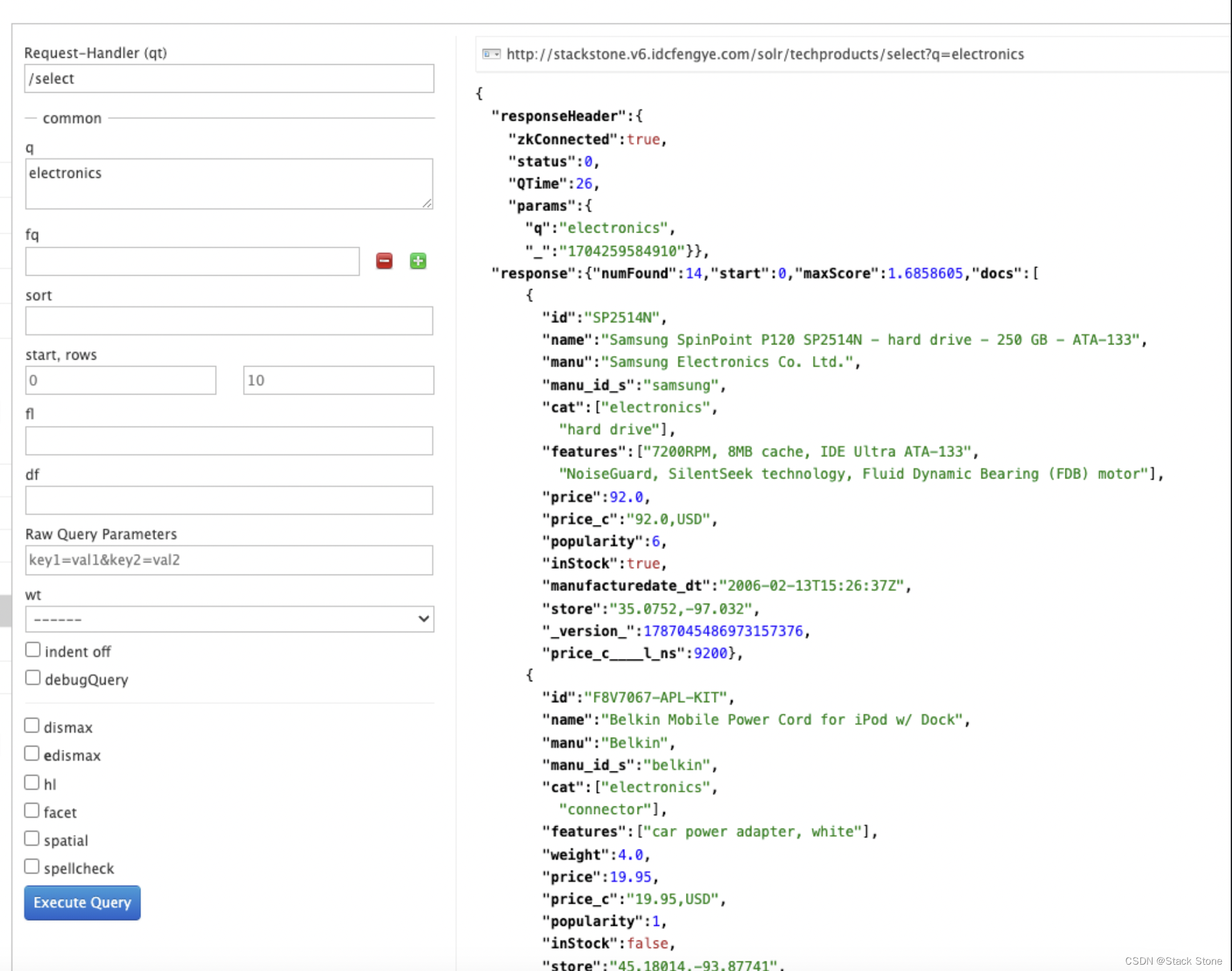
此搜索会查找索引字段中任何位置包含术语“electronics”的所有文档。但是,我们可以从上面看到有一个 cat 字段(用于“类别”)。如果我们将搜索限制为仅搜索“electronics”类别的文档,那么结果对于我们的用户来说将会更加精确。
更改 q 为 cat: electronics。现在我们得到 12 个结果:
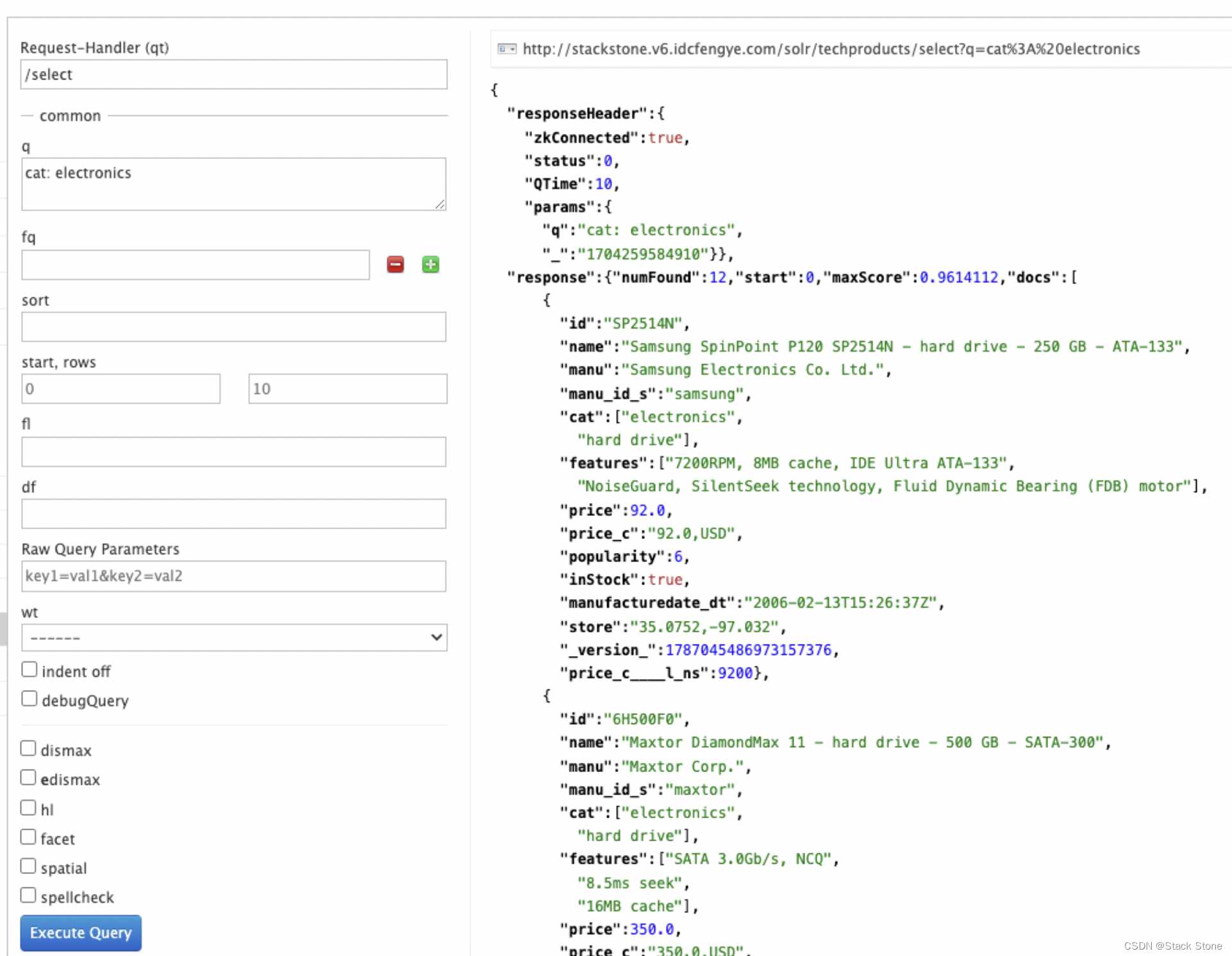
短语查询(Phrase Search)
要搜索多术语短语,请将其括在双引号中:q="multiple terms here"。例如,我们修改 q 为:“CAS latency”
如果使用curl,请注意术语之间的空格必须转换为URL中的“+”,如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=\"CAS+latency\""
我们将得到 2 个结果:
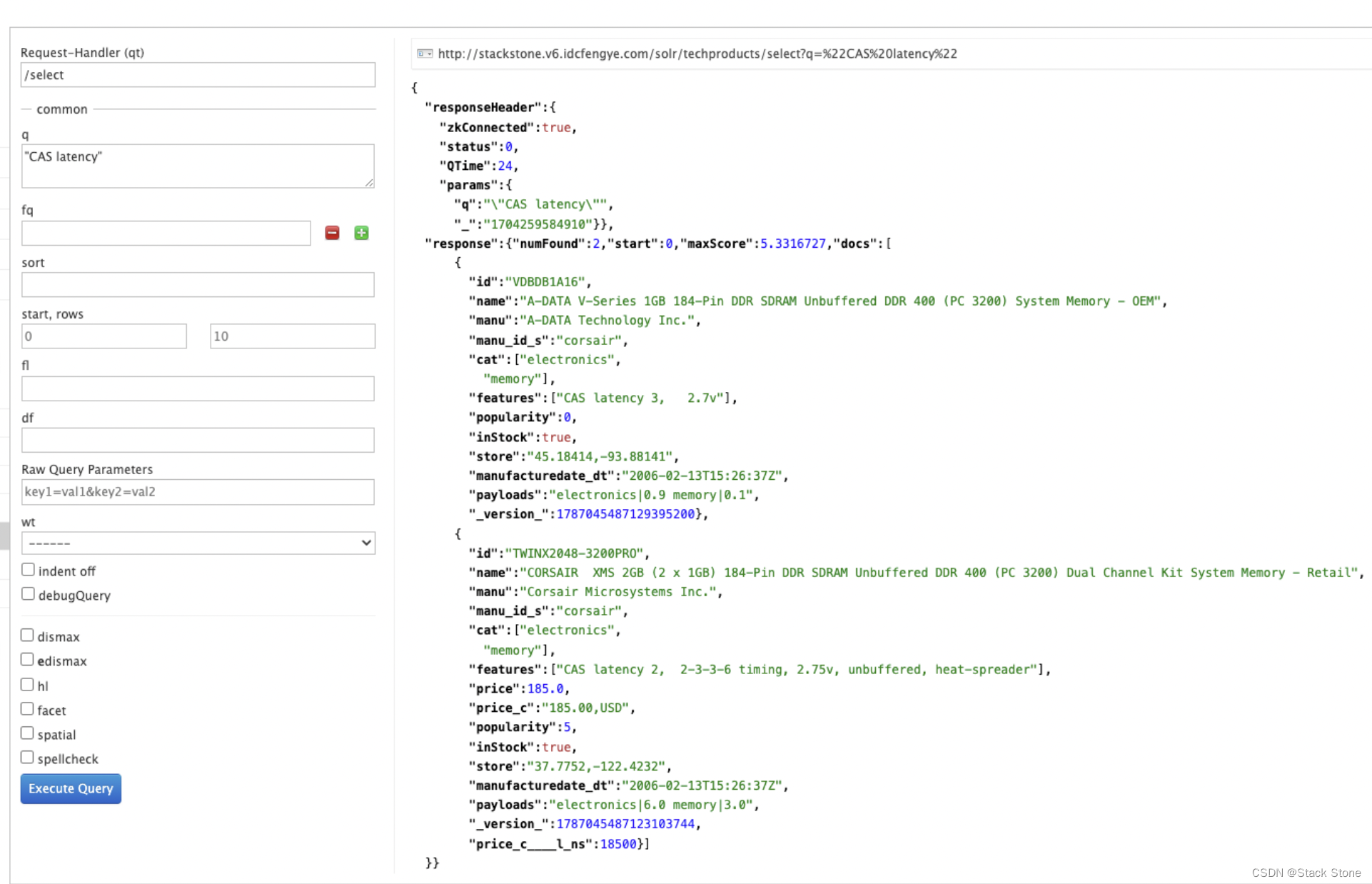
组合查询(Combining Searches)
默认情况下,当在单个查询中搜索多个Term and/or 短语时,Solr 将只要求其中之一存在,以便文档匹配。包含更多 Term 的文档将在结果列表中排序得更高。
可以通过在术语或短语前加上 + 前缀来要求其存在;相反,要禁止出现某个术语或短语,请在其前面加上 - 前缀。
要查找同时包含术语“electronics”和“music”的文档,请在“管理 UI 查询”选项卡的 q 中输入 +electronics +music。
如果使用curl,则必须对+字符进行编码,因为它在URL中具有保留用途(对空格字符进行编码)。 + 的编码是 %2B,如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic"
我们应该只会得到单一结果:
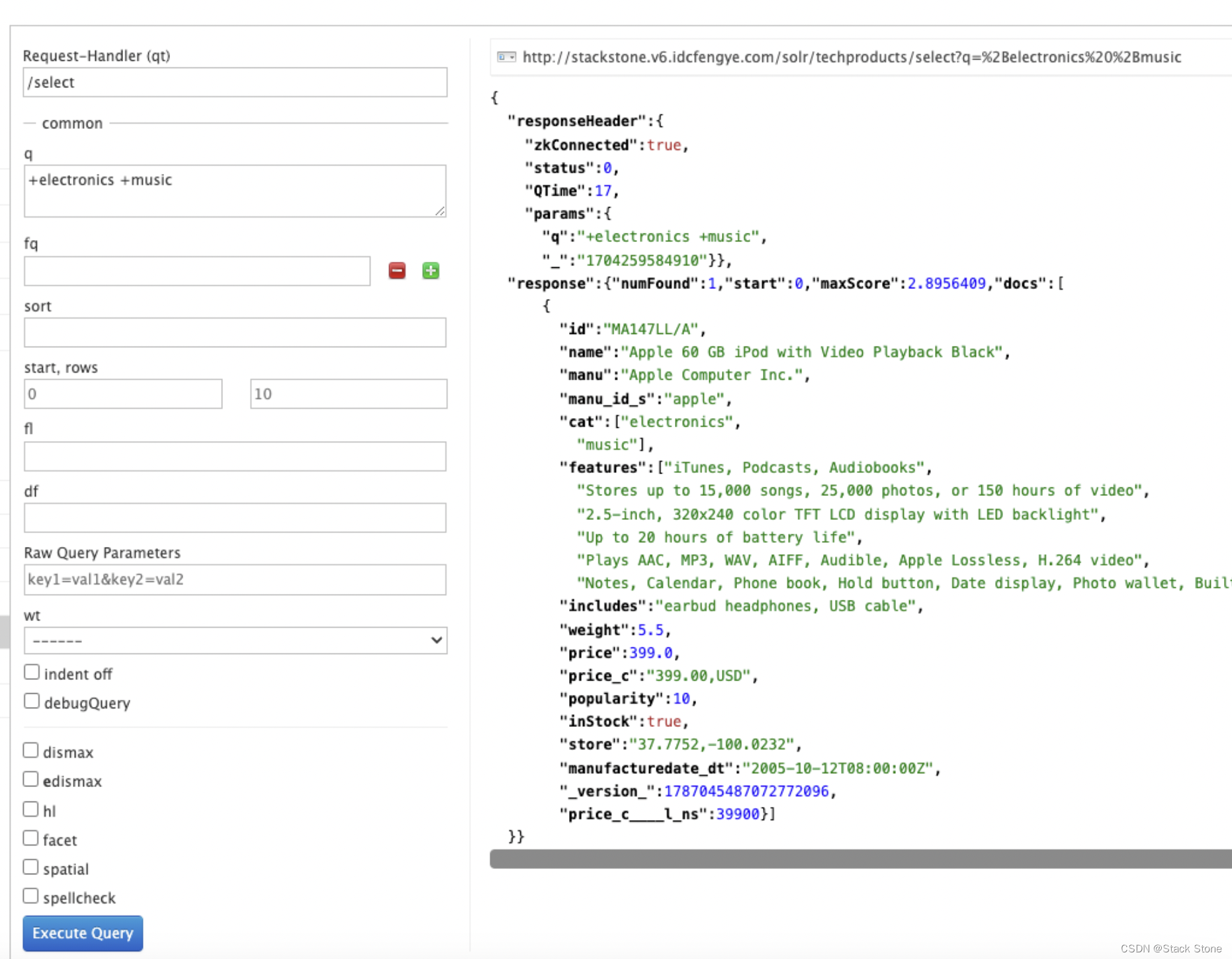
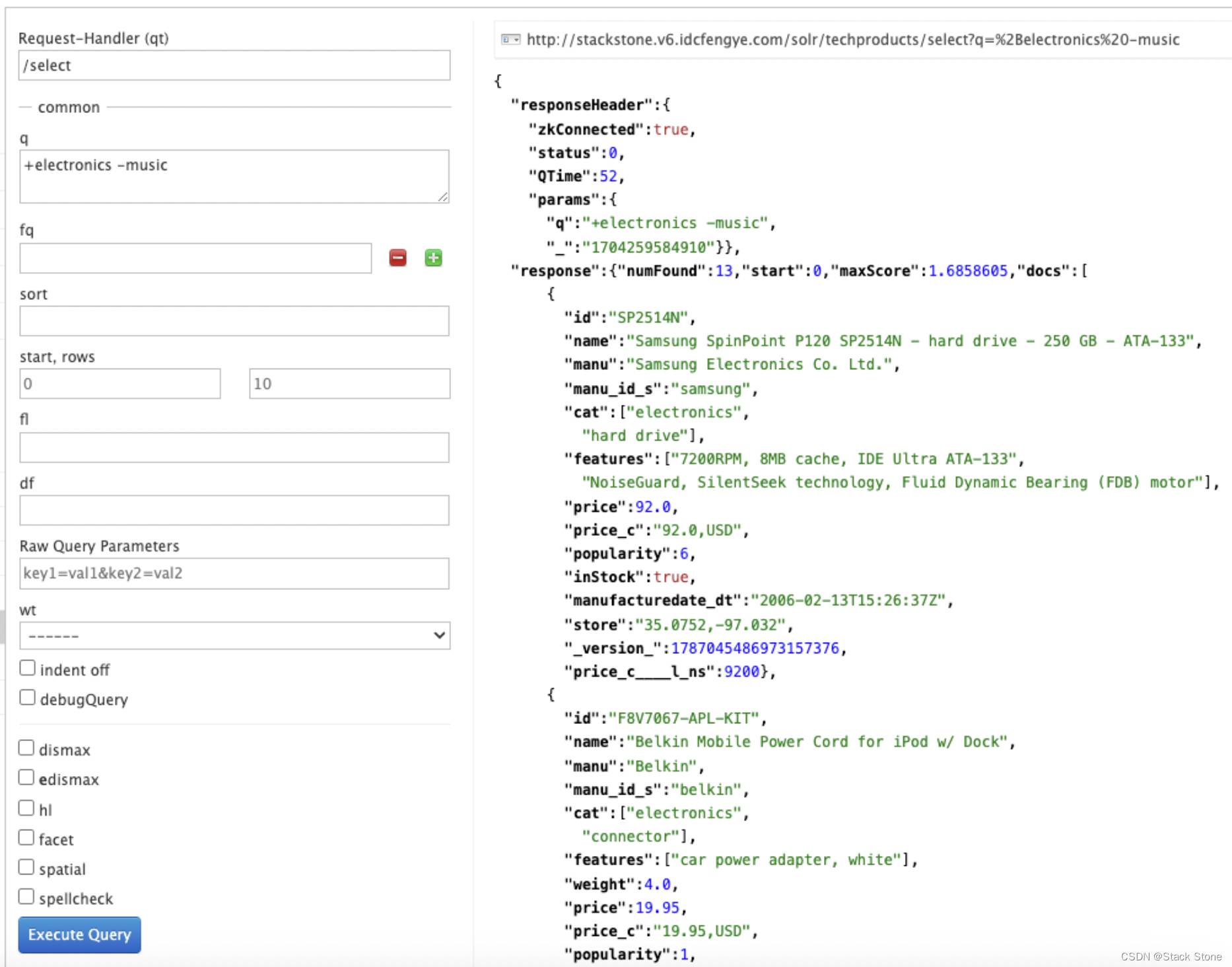
要搜索包含“electronics”但不包含“music”的文档,更改 q 为: + electronics -music。对于curl,再次将URL 编码为%2B,如下所示:
curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics+-music"
此时我们应该得到 13 个结果:
更多有关搜索的信息
我们只触及了 Solr 中可用搜索选项的表面。有关更多 Solr 搜索选项,请参阅搜索部分。
练习1 总结
至此,我们已经了解了 Solr 如何索引数据并完成了一些基本查询。如果你现在可以选择继续下一个示例,该示例将介绍更多 Solr 概念,例如分面结果和管理架构,或者你也可以自行解决。
如果想要删除练习中的数据可以执行:bin/solr delete -c techproducts,可以创建新的 collection:bin/solr create -c <yourCollection> -s 2 -rf 2,要停止我们启动的两个 Solr 节点,命令:bin/solr stop -all
有关 bin/solr 的启动/停止和收集选项的更多信息,请参阅 Solr 控制脚本。
练习 2:修改架构和索引影片数据
本练习将以上一个练习为基础,并向您介绍索引架构和 Solr 强大的 faceting 功能。
创建一个新的 Collection
我们将在本练习中使用一个全新的数据集,因此最好有一个新的集合,而不是尝试重用之前的数据集。
原因之一是我们将使用 Solr 中称为“字段猜测”的功能,Solr 在索引字段时尝试猜测字段中的数据类型。它还会自动在 schema 中为出现在传入文档中的新字段创建新字段。这种模式称为“Schemaless”。我们将了解这种方法的优点和局限性,帮助你决定在实际应用程序中如何以及在何处使用它。
什么是“Schema”?为什么需要一个?
Solr 的 Schema 是一个单一文件(XML 格式),用于存储有关 Solr 需要理解的字段和字段类型的详细信息。该 Schema 不仅定义字段或字段类型名称,还定义字段在索引之前应发生的任何修改。例如,如果您希望确保输入"abc"的用户和输入"ABC"的用户都能找到包含术语"ABC"的文档,您将希望在索引时将"ABC"标准化(在这种情况下转换为小写),并标准化用户查询以确保匹配。这些规则通常在您的模式(Schema)中定义。
在本教程的前面,我们提到了复制字段,这些字段由源自其他字段的数据组成。您还可以定义动态字段,它使用通配符(例如 *_t 或 *_s)动态创建特定字段类型的字段。这些类型的规则也在 schema 中定义。
当您最初在第一次练习中启动Solr时,我们可以选择要使用的configSet。我们选择的那个configSet具有预定义的模式,适用于我们后来索引的数据。这一次,我们将使用一个具有非常简单模式的configSet,并让Solr根据数据来确定要添加哪些字段。
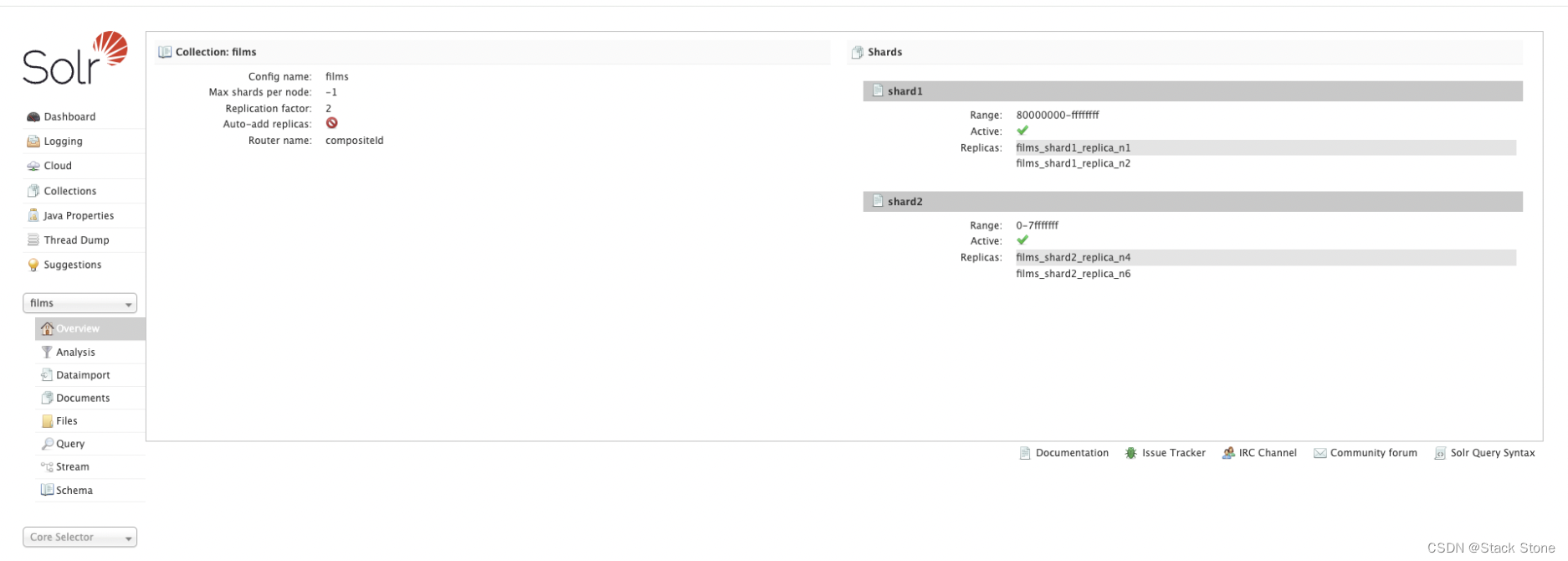
您要索引的数据与电影相关,因此首先创建一个名为“films”的集合,该集合使用 _default configSet:
bin/solr create -c films -s 2 -rf 2
上面的语句中我们没有指定 configSet,它将使用 _default,如果没有指定默认我们使用的是该配置。
参数 -s 和 -rf 表面了我们创建的 shard 数和副本数。这相当于我们在第一个练习的交互式示例中的选项。如果使用的是 root 账号在命令的最后加上 -force 选项。执行的结果如下:

该命令打印的第一件事是关于不在生产中使用此 configSet 的警告。
访问 http://localhost:8983/solr/#/films/collection-overview 我们应该会看到概述页面:
为电影数据准备 Schemaless
_default configSet 附带的模式会发生两个并行的事情。
首先,我们使用“托管模式”(managed schema),它被配置为只能由 Solr 的Schema API 修改。这意味着我们不应该手动编辑它,这样就不会混淆哪些编辑来自哪个来源。Solr 的 Schema API 允许我们更改字段、字段类型和其他类型的架构规则。
其次,我们使用“字段猜测”(field guessing),它在 solrconfig.xml 文件中配置(并且包括 Solr 的大多数各种配置设置)。字段猜测旨在让我们能够在尝试索引文档之前开始使用Solr,而无需定义我们认为文档中会包含的所有字段。这就是为什么我们称之为"无模式"(schemaless),因为您可以快速开始,并在Solr在文档中遇到字段时让其为您创建字段。
这听起来很不错,但是并不是如此,其也有局限性。这有点强制性,如果猜测错误,一旦数据被索引,您就无法对字段进行太多更改,而不必重新索引。如果我们只有几千个文档,这可能还不错,但如果您有数百万甚至数千万个文档,或者更糟糕的是,不再能够访问原始数据,那么这可能会成为一个真正的问题。
由于这些原因,Solr 社区不建议在没有您自己定义的模式的情况下投入生产。无模式功能一开始就很好,但我们仍然应该始终确保我们的模式(Schema)符合对数据索引方式以及用户查询方式的期望。
可以将无模式特性与已定义的模式混合使用。使用模式API,您可以定义一些您知道您想要控制的字段,同时让Solr猜测其他字段,这些字段可能不太重要,或者您有信心(通过测试)可以被猜测到您的满意程度。这就是我们要在这里做的。
创建“names”字段
我们要索引的电影数据包含每部电影的少量字段:ID、导演姓名、电影名称、发行日期和流派。
如果查看example/films,会看到第一个电影名称:.45,发行于 2006。

作为数据集中的第一个文档,Solr 将根据记录中的数据猜测字段类型。如果我们继续索引这些数据,第一个电影名称将向 Solr 表明该字段类型是“浮点”数字字段,并将创建一个类型为 FloatPointField 的“名称”字段。该记录之后的所有数据预计都是浮点数。
这肯定是行不通的,我们有像 A Mighty Wind 和 Chicken Run 这样的标题,它们是字符串而不是数字,更不是浮点数。如果我们让 Solr 猜测“name”字段是浮点数,那么后面的标题将导致错误并且索引将失败。
我们可以做的是在索引数据之前在 Solr 中设置“name”字段,以确保 Solr 始终将其解释为字符串。
在命令行中输入以下curl命令:
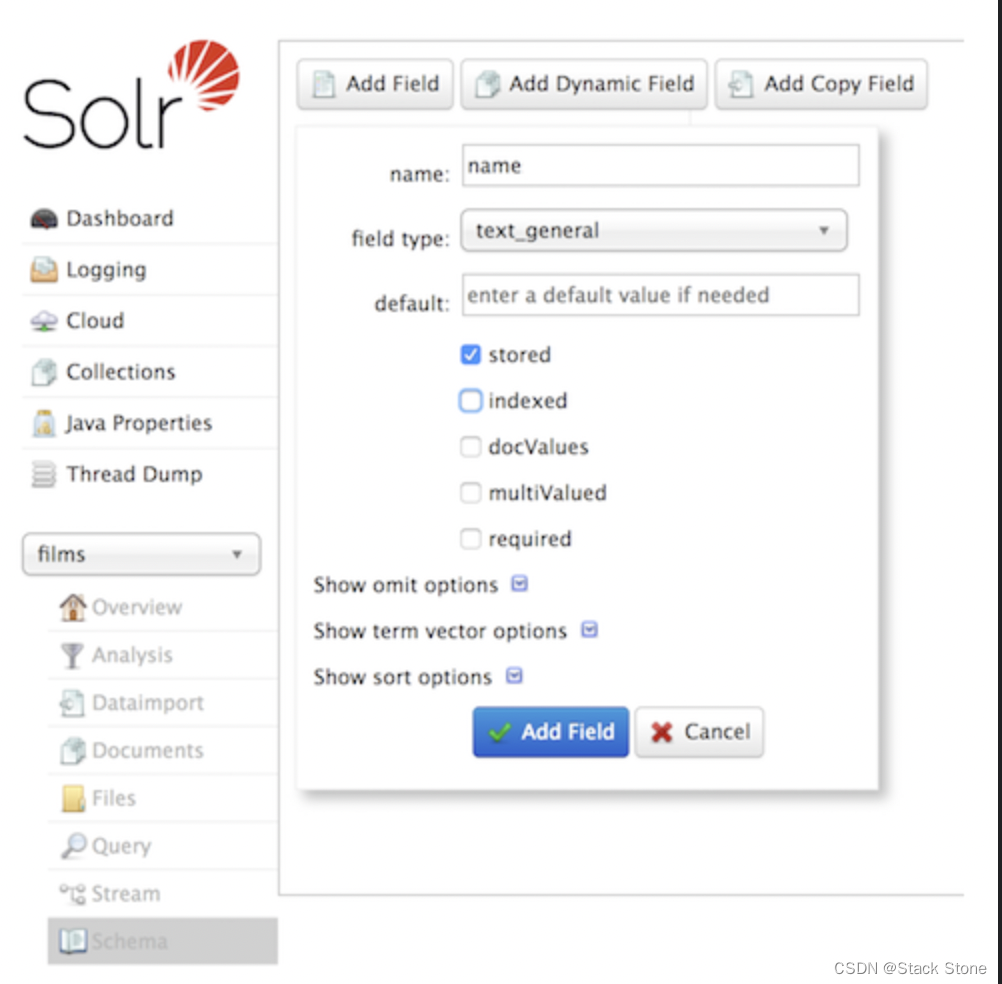
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' http://localhost:8983/solr/films/schema
此命令使用Schema API 显式定义名为“name”的字段,其字段类型为“text_general”(文本字段)。它不允许有多个值,但它将被存储(意味着可以通过查询检索它)。我们还可以使用Admin UI界面 创建字段,但它对字段属性的控制要少一些。不过,它适用于我们的情况:
创建“catchall”复制字段
在开始索引之前,还需要进行一项更改。在第一次练习中,当我们查询已经索引的文档时,无需指定要搜索的字段,因为我们使用的配置已经设置将字段复制到一个文本字段中,当查询中未定义其他字段时,该字段成为默认字段。
我们现在使用的配置没有默认搜索字段的规则,因此每次查询都需要定义要搜索的字段。不过,我们可以通过定义一个复制字段来设置一个"捕获所有字段",这个复制字段将从所有字段中获取数据并将其索引到一个名为_text_的字段中。现在让我们这样做。
为此,可以使用Admin UI 或Schema API。
在命令行中,再次使用 Schema API 定义复制字段:
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"*","dest":"_text_"}}' http://localhost:8983/solr/films/schema
在 Admin UI 界面中,选择 [Add Copy Field] 然后填写字段的源和目标,如下图所示:
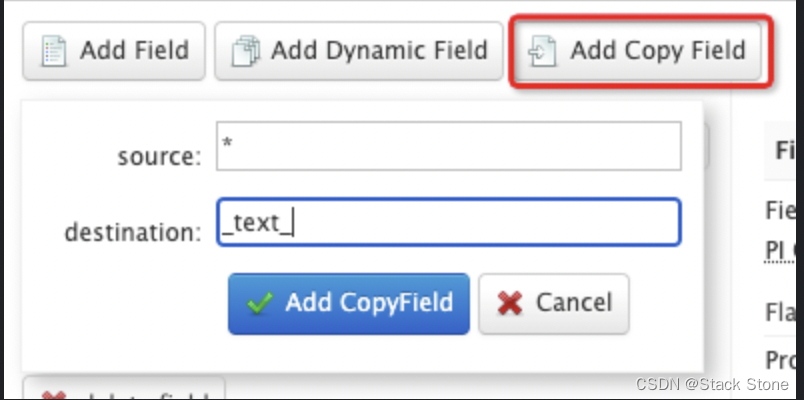
其作用是复制所有字段并将数据放入“text”字段中。
NOTE:
对生产数据执行此操作的成本可能非常高,因为它告诉 Solr 有效地将所有内容索引两次。它会使索引过程变慢,并使索引变大。对于生产数据,需要确保只复制真正适合的应用程序的字段。
现在我们准备好索引数据并开始使用它。
索引样例数据
索引的电影数据位于安装的 example/films 目录中。它提供三种格式:JSON、XML 和 CSV。
选择一种格式并将其索引到“films”集合中(在每个示例中,一个命令适用于 Unix/MacOS,另一个命令适用于 Windows):
-
To Index JSON Format:
bin/post -c films example/films/films.jsonC:\solr-7.7.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.json -
To Index XML Format
bin/post -c films example/films/films.xmlC:\solr-7.7.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.xml -
To Index CSV Format
bin/post -c films example/films/films.csv -params “f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|”C:\solr-7.7.0> java -jar -Dc=films -Dparams=f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=| -Dauto example\exampledocs\post.jar example\films\*.csv
每个命令都包含以下主要参数:
-c films: 这是用于索引数据的 Solr 集合。example/films/films.json(orfilms.xmlorfilms.csv): 这是要索引的数据文件的路径。可以简单地提供该文件所在的目录,但由于知道要索引的格式,因此指定该格式的确切文件会更有效。
请注意,CSV 命令包含额外参数。这是为了确保“genre”和“directed_by”列中的多值条目由竖线 (|) 字符分隔,在此文件中用作分隔符。告诉 Solr 以这种方式分割这些列将确保数据的正确索引。每个命令都会产生类似于下面在索引 JSON 时看到的输出:
[root@stackstone-002 solr-7.7.2]# bin/post -c films example/films/films.json
java -classpath /opt/solr/solr-7.7.2/dist/solr-core-7.7.2.jar -Dauto=yes -Dc=films -Ddata=files org.apache.solr.util.SimplePostTool example/films/films.json
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/films/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file films.json (application/json) to [base]/json/docs
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/films/update...
Time spent: 0:00:01.615
在 http://localhost:8983/solr/#/films/query 中执行查询,此时应该可以看到 1100 条结果。
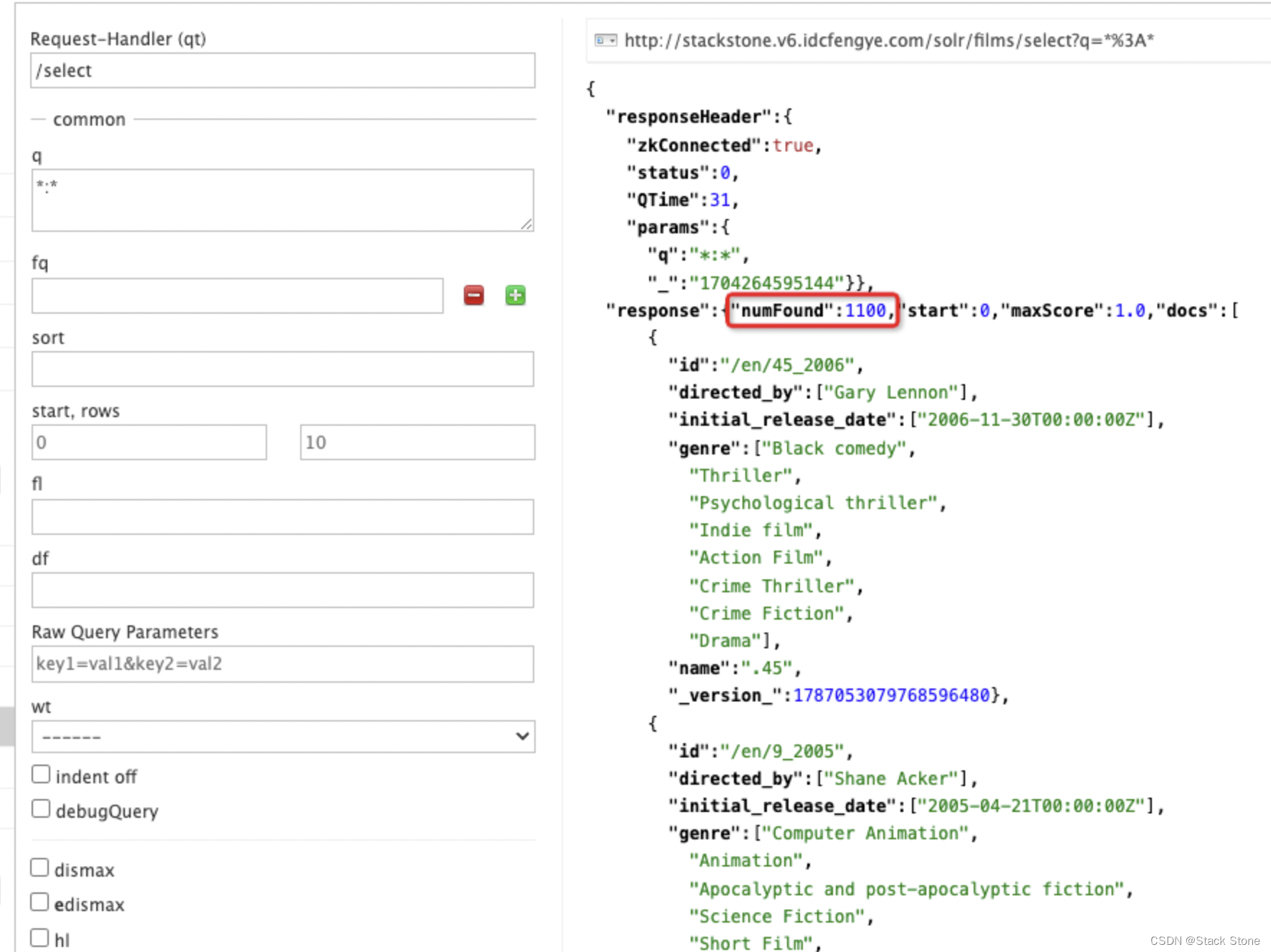
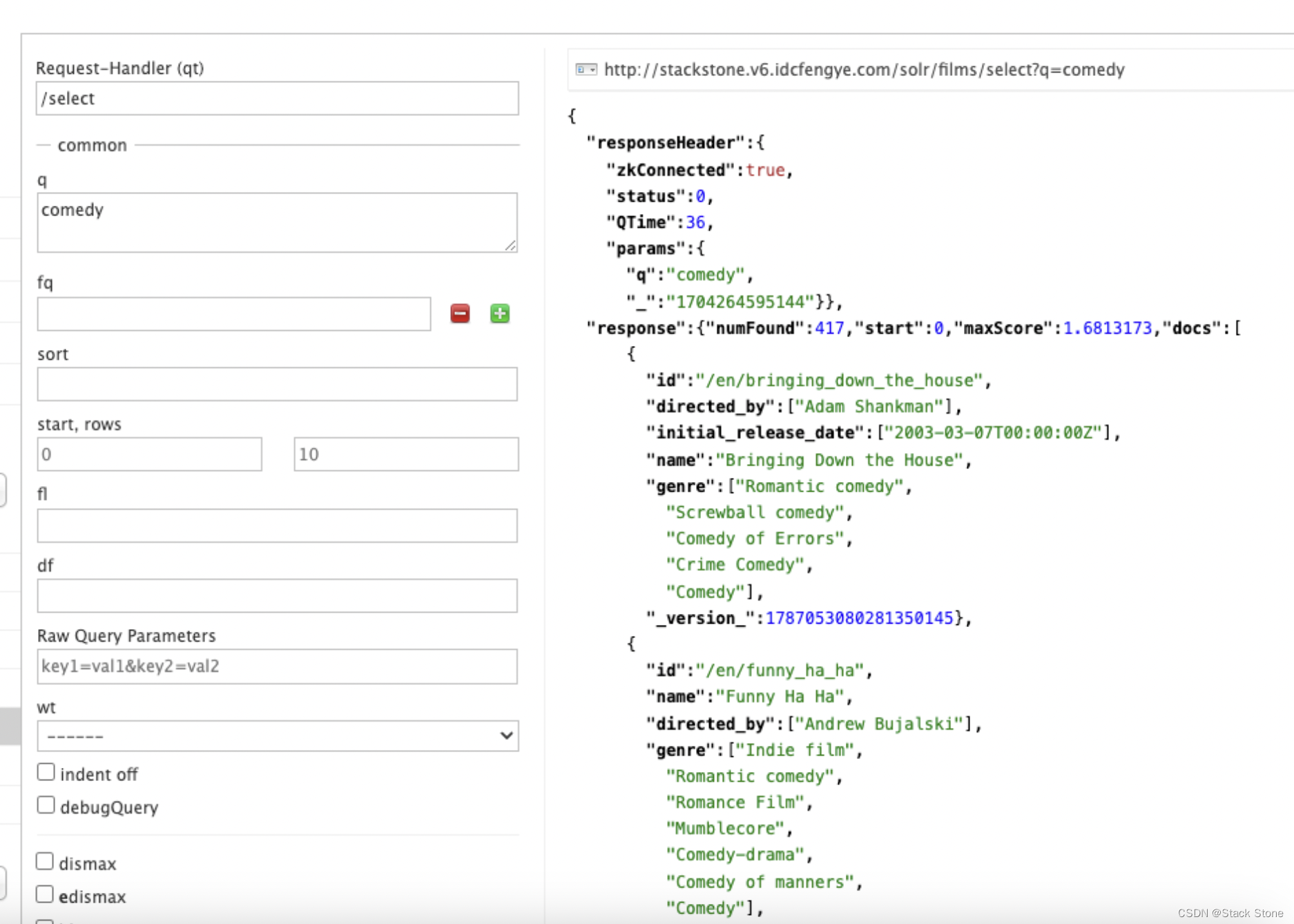
让我们进行一个查询,看看“catchall”字段是否正常工作。在 q 框中输入“comedy”,然后再次单击“执行查询”,应该会看到 417 个结果。
Faceting
Solr中最受欢迎的功能之一是分面(faceting)。分面允许将搜索结果排列成子集(或桶、或类别),为每个子集提供计数。有几种类型的分面:字段值、数值和日期范围、枢轴(决策树)以及任意查询分面。
Field Facets
除了提供搜索结果之外,Solr 查询还可以返回整个结果集中包含每个唯一值的文档数。
在 Admin UI 界面,如果勾选了 facet 选项,你将看到如下于 facet 的相关选项:
要查看所有文档的facet计数(q=:):请启用 facet(facet=true),并通过 facet.field 参数指定要进行 facet 计算的字段。如果只需要 facet 计数而不需要文档内容,请指定 rows=0。下面的curl命令将返回genre_str字段的 facet 计数。
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.field=genre_str"
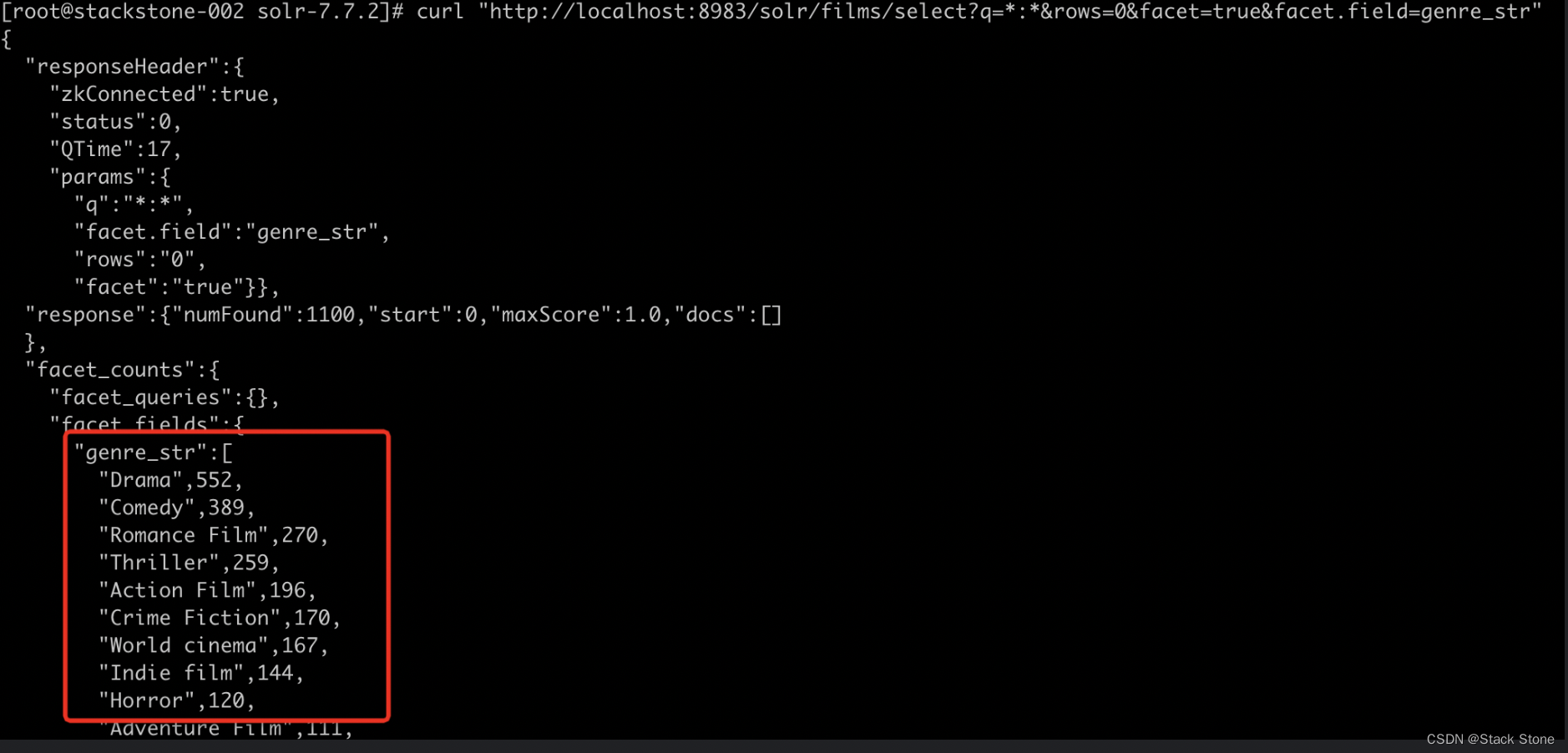
在 facet_counts 部分中,默认情况下您会看到索引中每个流派使用每种流派的文档数量。Solr 有一个参数 facet.mincount,您可以使用该参数将 facet 限制为仅包含一定数量文档的 facet(此参数未在UI 中显示)。
如果你想控制桶中的项目数量,你可以这样做:
curl "http://localhost:8983/solr/films/select?=&q=*:*&facet.field=genre_str&facet.mincount=200&facet=on&rows=0"
此时只会看到 4 个 facets 的返回。
还有大量其他参数可帮助我们控制 Solr 如何构建 facet 和 facet 列表。详情参阅 Faceting
Range Facets
对于数字或日期,通常需要将 facet 计数划分为范围而不是离散值。使用我们之前练习中的示例 techproducts 数据,数字范围 facet 的一个主要示例是价格。
电影数据包括电影的发行日期,我们可以使用它来创建日期范围 facet,这是范围 facet 的另一种常见用途。
Solr 管理 UI 尚不支持范围方面选项,因此您将需要使用curl或类似的命令行工具来完成以下示例。
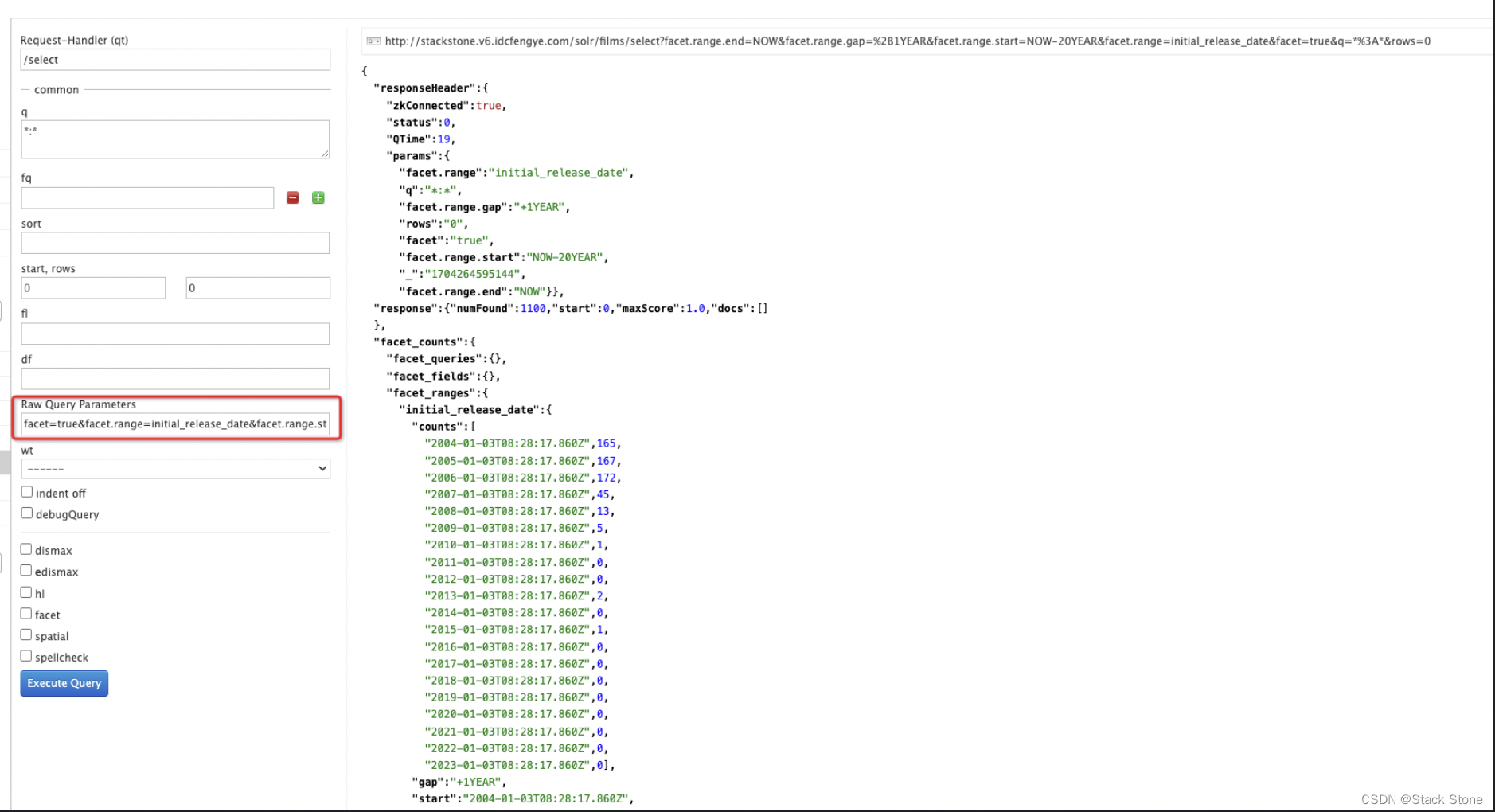
curl 'http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.range=initial_release_date&facet.range.start=NOW-20YEAR&facet.range.end=NOW&facet.range.gap=%2B1YEAR'
这要求所有电影按从 20 年前开始(我们最早的发行日期是 2000 年)到今天结束的年份进行分组。请注意,此查询 URL 再次将 + 编码为 %2B,结果如下:
[root@stackstone-002 solr-7.7.2]# curl 'http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.range=initial_release_date&facet.range.start=NOW-20YEAR&facet.range.end=NOW&facet.range.gap=%2B1YEAR'
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":42,
"params":{
"facet.range":"initial_release_date",
"q":"*:*",
"facet.range.gap":"+1YEAR",
"rows":"0",
"facet":"true",
"facet.range.start":"NOW-20YEAR",
"facet.range.end":"NOW"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"initial_release_date":{
"counts":[
"2004-01-03T08:25:44.751Z",165,
"2005-01-03T08:25:44.751Z",167,
"2006-01-03T08:25:44.751Z",172,
"2007-01-03T08:25:44.751Z",45,
"2008-01-03T08:25:44.751Z",13,
"2009-01-03T08:25:44.751Z",5,
"2010-01-03T08:25:44.751Z",1,
"2011-01-03T08:25:44.751Z",0,
"2012-01-03T08:25:44.751Z",0,
"2013-01-03T08:25:44.751Z",2,
"2014-01-03T08:25:44.751Z",0,
"2015-01-03T08:25:44.751Z",1,
"2016-01-03T08:25:44.751Z",0,
"2017-01-03T08:25:44.751Z",0,
"2018-01-03T08:25:44.751Z",0,
"2019-01-03T08:25:44.751Z",0,
"2020-01-03T08:25:44.751Z",0,
"2021-01-03T08:25:44.751Z",0,
"2022-01-03T08:25:44.751Z",0,
"2023-01-03T08:25:44.751Z",0],
"gap":"+1YEAR",
"start":"2004-01-03T08:25:44.751Z",
"end":"2024-01-03T08:25:44.751Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}
可以在 UI 界面在 Raw Query Parameters 填写相关的请求参数,效果如下:
Pivot Facets
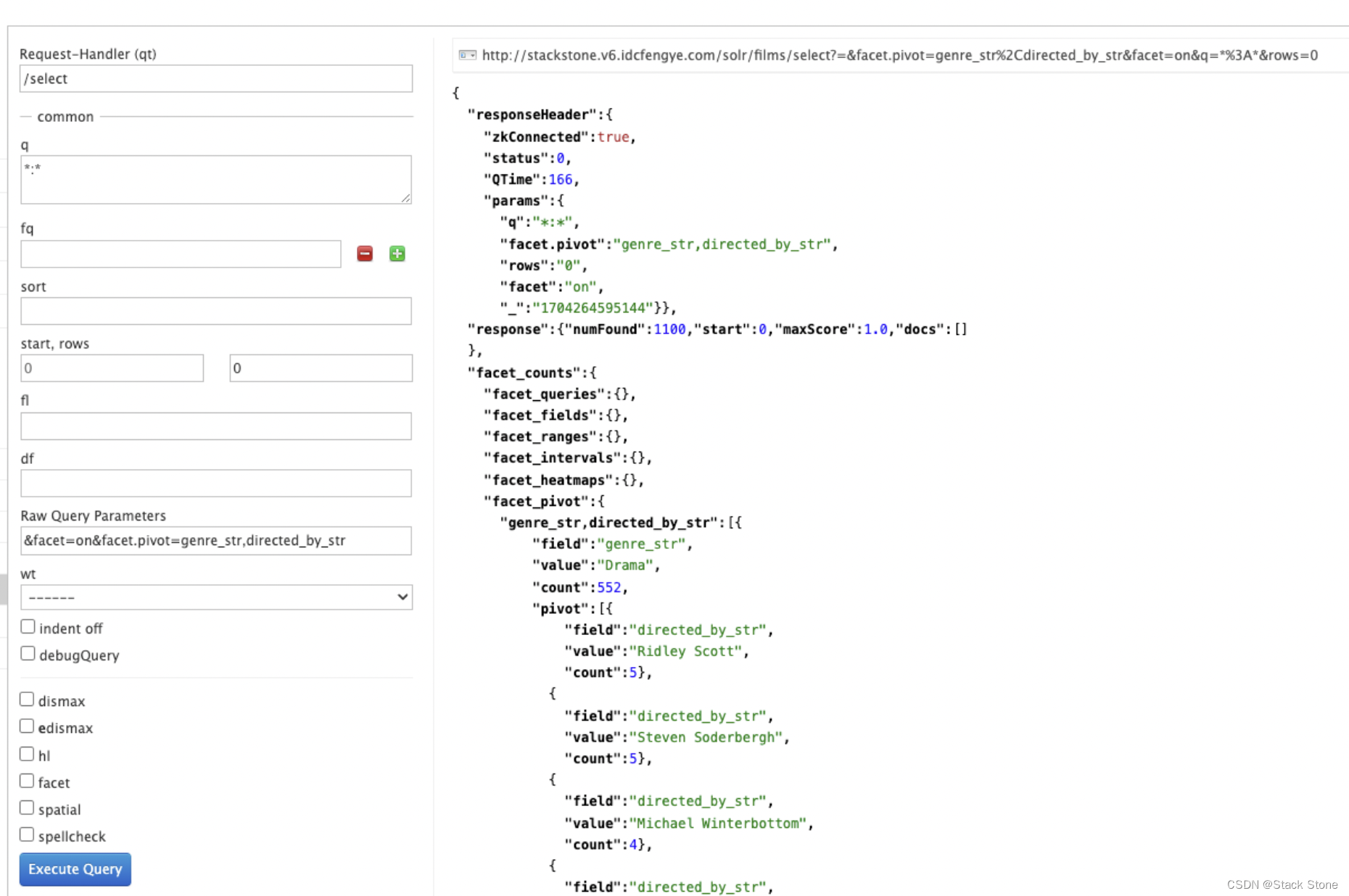
另一种分面类型是枢轴分面,也称为“决策树”,允许为所有各种可能的组合嵌套两个或多个字段。使用电影数据,数据透视面可用于查看“戏剧”类别(genre_str 字段)中有多少部电影是由导演执导的。以下是获取此场景的原始数据的方法:
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"
执行效果如下:
练习 3:索引自己的数据
对于最后一个练习,可以使用自己选择的数据集。这可以是本地硬盘上的文件、你之前使用过的一组数据,也可能是你打算为生产应用程序索引到 Solr 的数据样本。
索引方法
Local Files with bin/post
如果您有本地文件目录,则发布工具 (bin/post) 可以索引文件目录。我们在第一次练习中看到了这一点。
我们在练习中仅使用 JSON、XML 和 CSV,但 Post Tool 还可以处理 HTML、PDF、Microsoft Office 格式(例如 MS Word)、纯文本等。
在本例中,假设本地有一个名为“Documents”的目录。为了对其进行索引,我们将发出这样的命令(根据需要更正 -c 参数后面的集合名称):
./bin/post -c localDocs ~/Documents
在处理文档时,可能会遇到错误。这些错误可能是由字段猜测引起的,或者与文件类型不受支持有关。索引此类内容需要为我们依据数据来规划Solr,这需要理解数据,并可能需要一些试错过程。
DataImportHandler
Solr 包括一个称为数据导入处理程序 (DIH) 的工具,它可以连接到数据库(如果您有 jdbc 驱动程序)、邮件服务器或其他结构化数据源。
example/example-DIH 中的 README.txt 文件将为您提供有关如何开始使用此工具的详细信息。
SolrJ
SolrJ 是一个基于 Java 的客户端,用于与 Solr 交互。使用适用于基于 JVM 的语言的 SolrJ 或其他 Solr 客户端以编程方式创建要发送到 Solr 的文档。
Documents Screen
使用“管理 UI 文档”选项(位于 http://localhost:8983/solr/#/localDocs/documents)粘贴要索引的文档,或从 Document Type 下拉列表中选择 Document Builder 逐个字段构建文档。最后,单机表单下方的 Submit Document 按钮来索引您的文档。
更新数据
您可能会注意到,即使您多次索引本教程中的内容,它也不会重复找到的结果。这是因为示例 Solr schema(名为 Managed-Schema 或 schema.xml 的文件)指定了一个名为 id 的 uniqueKey 字段。每当您向 Solr POST 命令添加一个与现有文档具有相同 uniqueKey 值的文档时,它会自动为您替换它。
通过查看 Solr 管理页面的特定于核心的概述部分中的 numDocs 和 maxDoc 的值,您可以看到已经发生了这种情况。
numDocs 表示索引中可搜索文档的数量(并且将大于 XML、JSON 或 CSV 文件的数量,因为某些文件包含多个文档)。maxDoc 值可能会更大,因为 maxDoc 计数包括尚未从索引中物理删除的逻辑删除文档。您可以根据需要一遍又一遍地重新发布示例文件,并且 numDocs 永远不会增加,因为新文档将不断替换旧文档。
继续编辑任何现有示例数据文件,更改一些数据,然后重新运行 PostTool (bin/post)。你将可以看到更改反映在后续搜索中。
删除数据
如果您需要迭代几次才能获得正确的 schema,您可能需要删除文档以清除集合,然后重试。但请注意,仅删除文档不会更改基础字段定义。从本质上讲,这将允许您在根据需要更改字段后重新索引数据。
您可以通过将删除命令发布到更新 URL 并指定文档的唯一键字段的值或匹配多个文档的查询来删除数据。如果我们正确构造请求,我们也可以使用 bin/post 来删除文档。
执行以下命令删除特定文档:
bin/post -c localDocs -d "<delete><id>SP2514N</id></delete>"
要删除所有文档,您可以使用“delete-by-query”命令,例如:
bin/post -c localDocs -d "<delete><query>*:*</query></delete>"
您还可以修改上述内容以仅删除与特定查询匹配的文档。
空间查询(Spatial Queries)
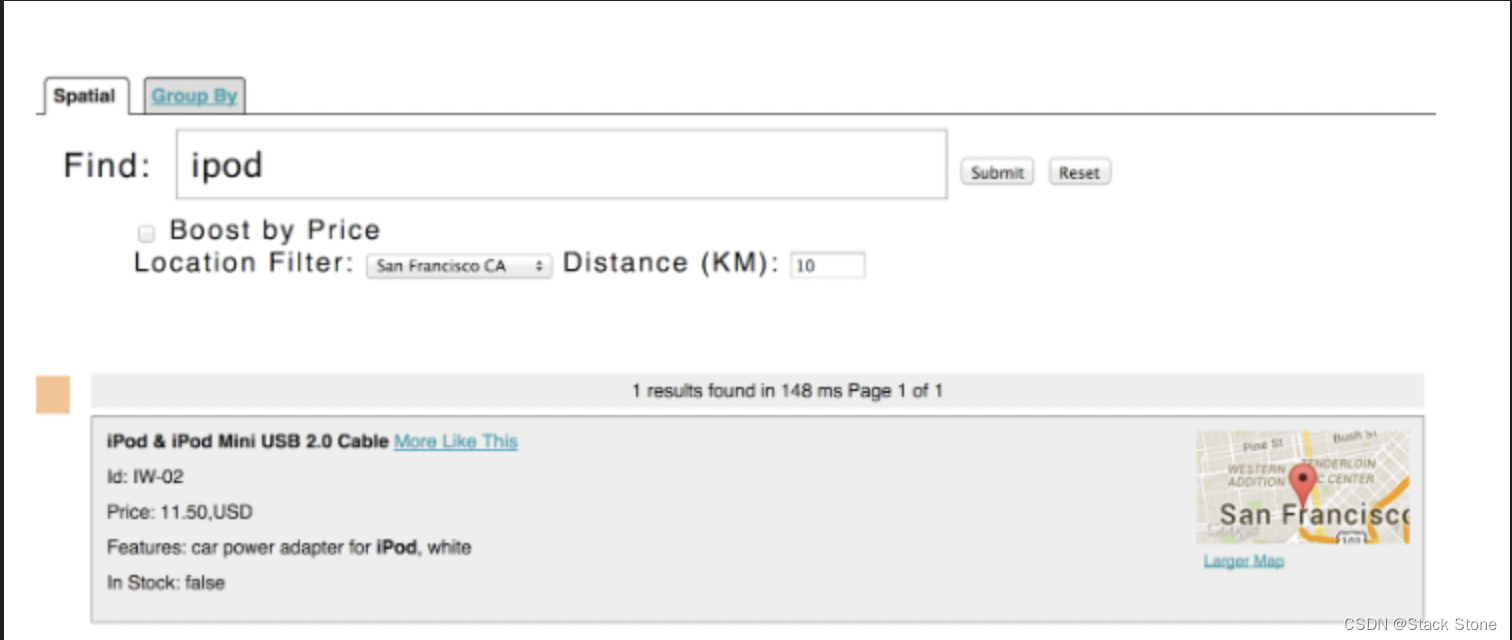
Solr 具有复杂的地理空间支持,包括在给定位置的指定距离范围内(或边界框内)进行搜索、按距离排序,甚至按距离增强结果。
我们在练习 1 中索引的一些示例技术产品文档具有与其关联的位置,以说明空间功能。
空间查询可以与任何其他类型的查询相结合,例如在距旧金山 10 公里范围内查询“ipod”的示例中:
了解更多关于 Solr 空间搜索请参阅 Spatial Search
参考:
https://solr.apache.org/guide/7_7/solr-tutorial.html#spatial-queries















 124
124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











