






数据库基础知识
数据定义语言
1 数据库的增删改查
-- 查看系统中有哪些数据库
show databases;
-- 创建test数据库
create database test;
-- 选择进入数据库
use test;
-- 删除数据库(慎用)
drop database test;
2 数据表的增删改查
-- 创建数据表
create table department(
deptno int,
dname varchar(15),
loc varchar(10));
-- 从另一张表复制表结构创建表
create table tb_name like tb_name_old
-- 从另一张表的查询结果创建表
CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options
-- 查看当前数据库中有哪些表
show tables;
-- 查看表结构
desc emp;
-- 删除数据表(慎用)
drop table department;
3 常用数据类型
• int:大整数型,有符号大小-2147483648~2147483647, 无符号大小0~4294967295,默认长度最多为11个数字,如int(11)
• float:单精度浮点型,默认float(10,2),表示最多10个数字,其中有2位小数
• decimal:十进制小数型,适合金额、价格等对精度要求较高的数据存储。默认decimal(10,0),表示最多10位数字,其中0位小数。
• char:固定长度字符串型,长度为1-255。如果长度小于指定长度,右边填充空格。如果不指定长度,默认为1。如char(10),‘abc
• varchar:可变长度字符串型,长度为1-255。必须指定长度,如varchar(10),‘abc’
• text:长文本字符串型,最大长度65535,不能指定长度
• date:日期型,‘yyyy-MM-dd’
• time:时间型,‘hh:mm:ss’
• datetime:日期时间型,‘yyyy-MM-dd hh:mm:ss’
• Timestamp:时间戳,在1970-01-01 00:00:00和2037-12-31 23:59:59之间,如1973-12-30 15:30,时间戳为:19731230153000
4 数据库常用约束条件
4.1 主键约束
• 每个表中只能有一个主键
• 主键值须非空不重复
• 可设置单字段主键,也可设置多字段联合主键
• 联合主键中多个字段的取值完全相同时,才违反主键约束
• 添加主键约束:
--列级添加主键约束:
create table <表名> (<字段名1> <字段类型1> primary key,……<字段名n> <字段类型n>);
--表级添加主键约束:
create table <表名>(<字段名1> <字段类型1>,......<字段名n> <字段类型n>,[constraint 主键约束名] primary key(字段名1[,字段名2,...字段名n]));
4.2 非空约束
• 字段的值不能为空
--创建非空约束:
create table <表名> (<字段名1> <字段类型1> not null,……<字段名n> <字段类型n>);
4.3 唯一约束
• 指定字段的取值不能重复,可以为空,但只能出现一个空值
• 添加唯一约束:
--列级添加唯一约束:
create table <表名> (<字段名1> <字段类型1> unique,……<字段名n> <字段类型n>);
--表级添加唯一约束:
create table <表名> (<字段名1> <字段类型1,……<字段名n> <字段类型n>,[constraint 唯一约束名] unique (字段名1[,字段名2...字段名n]));
4.4 自动增长列
• 指定字段的取值自动生成,默认从1开始,每增加一条记录,该字段的取值会加1
• 只适用于整数型,配合主键一起使用
• 多个约束条件不分前后顺序,用空格隔开就可以
--创建自动增长约束:
create table <表名> (<字段名1> <字段类型1> primary key auto_increment,……<字段名n> <字段类型n>);
4.5 默认约束
• 如果新插入一条记录时没有为该字段赋值,系统会自动为这个字段赋值为默认约束设定的值
--创建默认约束:
create table <表名> (<字段名1> <字段类型1> default value,……<字段名n> <字段类型n>);
4.6 外键约束
在一张表中执行数据插入、更新、删除等操作时,DBMS都会跟另一张表进行对照,避免不规范的操作,以确保数据存储的完整性。
• 某一表中某字段的值依赖于另一张表中某字段的值
• 主键所在的表为主表,外键所在的表为从表
• 每一个外键值必须与另一个表中的主键值相对应
--创建外键约束:
create table <表名> (<字段名1> <字段类型1>,……<字段名n> <字段类型n>,[constraint 外键约束名]foreign key(字段名) references <主表>(主键字段));
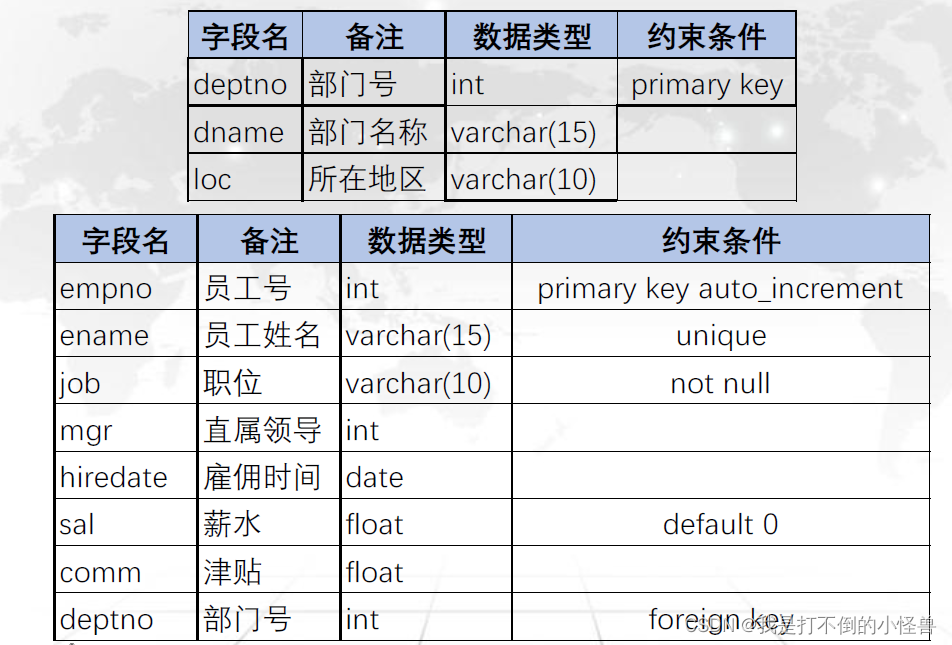
4.7 创建带有约束条件的表
-- 创建带有约束条件的表(因为两张表中有主外键约束,所以需要先创建主键所在的dept,再创建外键所在的emp)
create table dept(
deptno int primary key,
dname varchar(15),
loc varchar(10)
);
create table employee(
empno int primary key auto_increment,
ename varchar(15) unique,
job varchar(10) not null,
mgr int,
hiredate date,
sal float default 0,
comm float,
deptno int ,
foreign key(deptno) references dept(deptno)
);
5 修改数据表
-- 修改表名
alter table employee rename emp;
-- 修改字段名(主键,从键,唯一约束不可改,非空,默认,自动增长列可改)
alter table emp change empno empid int;
-- 修改字段类型(8.0版本int类型无需加宽度)
alter table emp modify empid float;
-- 添加字段(可指定位置,不指定则默认为最后一列)
alter table emp add ppp int;
-- 修改字段的排列位置:
alter table emp modify ppp int first;
alter table emp modify ppp int after empid;
-- 删除字段
alter table emp drop ppp;
数据操作语言
1 插入数据
- 字段名与字段值的数据类型、个数、顺序必须一一对应
-- 指定字段名插入
insert into dept(deptno,dname,loc) values (10,'accounting','new york'),
(20,'research','dallas');
-- 不指定字段名插入
insert into dept values (30,'sales','chicago'),
(40,'operations','boston');
2 批量导入数据
- 路径中不能有中文,‘\’在编程语言中是转义符,需要将‘\’改为‘\’或‘/’
-- 先有部门,才能存储每个部门的员工信息,所以先添加dept的部门信息,再导入emp的员工信息
load data infile "C:/ruanjian/mysql/Uploads/employee.csv"
into table emp
fields terminated by ','
ignore 1 lines;
select * from emp; -- 检查导入数据内容
select count(*) from emp; -- 检查导入数据总行数
3 更新数据
-- set sql_safe_updates=0; -- 设置数据库安全权限
update emp set sal=sal+1000 where ename='smith';
4 删除数据
-- 删除数据
delete from emp where deptno=20;
-- 清空数据
truncate emp;
数据查询语言
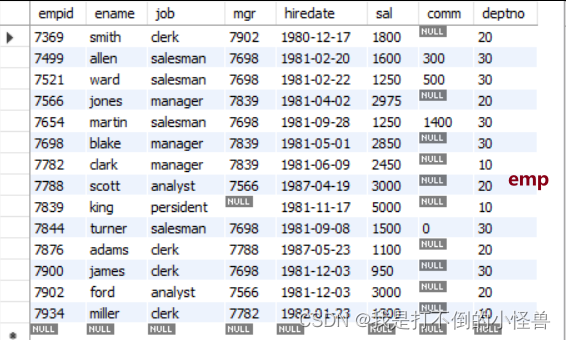
1 单表查询
1.1 全表查询、查询指定列
-- 全表查询
select * from emp;
-- 查询指定列:查询emp表中ename,job,sal
select ename,job,sal from emp;
1.2 设置别名
-- 设置别名:查询每位员工调整后的薪资(基本工资+1000)
-- as关键字可省略department
select *,sal+1000 as 调薪 from emp;
-- 练习:查询每位员工的年薪(基本工资*12):empid,ename,年薪
select empid,ename,sal*12 as 年薪 from emp;
1.3 查询不重复的数据
-- 查询不重复的数据:查询emp表中有哪些部门
select distinct deptno from emp;
select distinct deptno,job from emp;
1.4 条件查询
-- 查询基本工资大于等于2000小于等于3000的员工信息
select * from emp where sal>=2000 and sal<=3000;
-- 查询10号部门和20号部门中sal低于2000的员工信息
select * from emp where (deptno=10 or deptno=20) and sal<2000;
-- 练习:查询salesman的所属部门:姓名,职位,所在部门
select deptno,ename,job from emp where job='salesman';
1.5 空值查询
-- 查询 mgr为空的记录
select * from emp where mgr is null;
-- 练习:查询 comm不为空的记录
select * from emp where comm is not null;
1.6 模糊查询
-- 查询姓名以a开头的员工信息
select * from emp where ename like 'a%';
-- 查询姓名中包含a的员工信息
select * from emp where ename like '%a%';
-- 查询姓名中第二个字符为a的员工信息
select * from emp where ename like '_a%';
-- 练习:查询员工姓名中不包含s的员工信息
select * from emp where ename not like '%s%';
1.7 查询结果排序
-- 多字段排序时,先按第一个字段排序,第一个字段值相同时再按第二个字段排序
-- 单字段排序:查询所有员工信息按sal降序显示
select * from emp order by sal desc;
-- 多字段排序:查询所有员工信息按deptno升序、sal降序显示
select * from emp order by deptno asc,sal desc;
1.8 限制查询结果数量
-- 查询基本工资最高的前5位员工
select * from emp order by sal desc limit 5;
-- 查询基本工资第6到10名的员工
-- 第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
select * from emp order by sal desc limit 5,5;
-- 练习:查询最后入职的5位员工
select * from emp order by hiredate desc limit 5;
1.9 聚合运算
-- 查询emp表中员工总数、最高工资、最低工资、平均工资及工资总和
select count(*) 员工总数,max(sal) 最高工资,min(sal) 最低工资,
avg(sal) 平均工资,sum(sal) 工资总和 from emp;
1.10 分组查询
-- 查询各部门的平均工资
select deptno,avg(sal) 部门平均工资 from emp group by deptno;
-- 查询各部门不同职位的平均工资
select deptno,job,avg(sal) from emp group by deptno,job;
-- 练习:查询各部门的员工数
select deptno,count(ename) from emp group by deptno;
-- 练习:查询各部门不同职位的人数
select deptno,job,count(ename) from emp group by deptno,job order by deptno;
1.11 分组后筛选
- where条件查询的作用域是针对数据表进行筛选,而having条件查询则是对分组结果进行过滤。
- where在分组和聚合计算之前筛选行,而having在分组和聚合之后筛选分组的行,因此where子句不能包含聚合函数。
-- 查询各部门clerk的平均工资
select deptno,job,avg(sal) from emp group by deptno,job having job='clerk';
select deptno,job,avg(sal) from emp where job='clerk' group by deptno;
-- 查询平均工资大于2000的部门
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
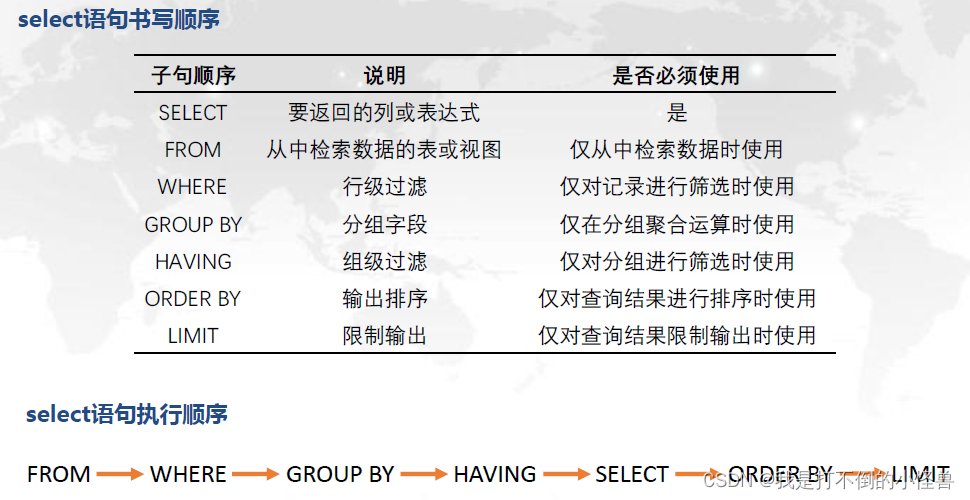
1.12 select语句书写顺序、执行顺序
2 多表查询
2.1 内连接,左连接,右连接
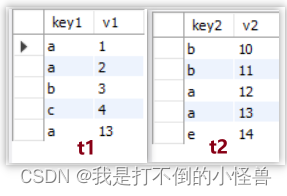
-- 内连接
select * from t1 inner join t2 on t1.key1=t2.key2;
-- 左连接
select * from t1 left join t2 on t1.key1=t2.key2;
-- 右连接
select * from t1 right join t2 on t1.key1=t2.key2;
2.2 纵向合并
-- union去重
select * from t1 union select * from t2;
-- union all不去重
select * from t1 union all select * from t2;
2.3 联合查询
-- 查询每位员工的ename,dname,sal
select ename,dname,sal
from emp left join dept on emp.deptno=dept.deptno;
-- 查询各地区的员工数
select loc,count(empid) 员工数
from dept left join emp on emp.deptno=dept.deptno
group by loc;
-- 查询manager的姓名、所属部门名称和入职日期:ename,dname,job,hiredate(内连接/笛卡尔积连接)
select ename,dname,job,hiredate
from emp inner join dept on emp.deptno=dept.deptno
where job='manager';
select ename,dname,job,hiredate
from emp,dept
where emp.deptno=dept.deptno and job='manager';
-- 查询每位员工的工资等级;empno,ename,sal,grade(不等值连接)
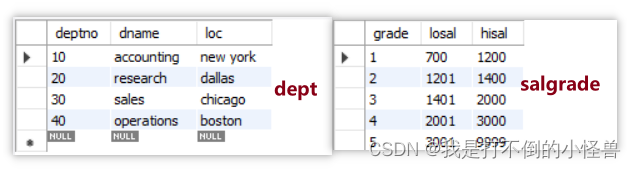
select empid,ename,sal,grade
from emp left join salgrade on sal between losal and hisal;
-- 查询每个工资等级的员工数
select grade,count(empno) 员工数
from salgrade left join emp on sal between losal and hisal
group by grade;
-- 查询所有员工姓名及其直属领导姓名(自连接:通过别名,将同一张表视为多张表)
select 员工表.ename 员工姓名,领导表.ename 领导姓名
from emp as 员工表 left join emp as 领导表 on 员工表.mgr=领导表.empid;
-- 查询入职日期早于其直属领导的员工:empno,ename,dname
select 员工表.empid,员工表.ename,dept.dname
from emp as 员工表
left join emp as 领导表 on 员工表.mgr=领导表.empid
left join dept on 员工表.deptno=dept.deptno
where 员工表.hiredate<领导表.hiredate;
2.4 子查询

2.4.1 标量子查询
-- 查询基本工资高于公司平均工资的员工信息
select * from emp where sal>(select avg(sal) from emp);
-- 练习:查询和allen同一个领导的员工:empid,ename,job,mgr
select empid,ename,job,mgr from emp where mgr=(select mgr from emp where ename='allen');
2.4.2 行子查询
-- 查询和smith同部门同职位的员工:empid,ename,job,deptno
select empid,ename,job,deptno from emp
where (deptno,job)=(select deptno,job from emp where ename='smith');
2.4.3 列子查询
-- 查询普通员工的工资等级:empid,ename,sal,grade
select empid,ename,sal,grade from emp left join salgrade on sal between losal and hisal
where empid not in (select distinct mgr from emp where mgr is not null);
-- 练习:查询员工数不少于5人的部门的所有员工:empid,ename,deptno
select empid,ename,deptno from emp
where deptno in (select deptno from emp group by deptno having count(empid)>=5);
-- 查询基本工资高于30号部门任意员工的员工信息
select * from emp where sal>any(select sal from emp where deptno=30) and deptno<>30;
-- 查询基本工资高于30号部门所有员工的员工信息
select * from emp where sal>all(select sal from emp where deptno=30) and deptno<>30;
2.4.4 from子查询
-- 查询各部门最高工资的员工:empid,ename,sal,deptno
select empid,ename,sal,emp.deptno from emp
left join (select emp.deptno,max(sal) as 最高工资 from emp group by emp.deptno) as t
on emp.deptno=t.deptno
where sal=最高工资;
3 常用函数
3.1 字符串函数

- 合并字符串
-- CONCAT(str1,str2,...) 把多个文本字符串合并成一个长字符串()
select concat('CDA','数据', '分析');
select concat('CDA',null, '分析'); -- 返回空值
- 字符串位置
-- INSTR(str,substr) 返回子字符串substr在文本字符串str中第一次出现的位置()
select instr('CDA', 'A');
select instr('数据分析', 'CDA'); -- 返回0
- 截取字符串
-- LEFT(str,len) 返回字符串str的左端len个字符
select left('CDA数据分析', 3);
-- RIGHT(str,len) 返回字符串str的右端len个字符
select right('CDA数据分析', 4);
-- MID(str,pos,len) 返回字符串str的位置pos起len个字符
select mid('CDA数据分析', 4, 2);
select mid('CDA数据分析', 4); -- 返回位置4后所有字符
-- SUBSTRING ( expression, start, length ) 截取字符串
-- expression:字符串、二进制字符串、文本、图像、列或包含列的表达式。请勿使用包含聚合函数的表达式。
-- start:整数或可以隐式转换为int的表达式,指定子字符串的开始位置。
-- length:整数或可以隐式转换为int的表达式,指定子字符串的长度。
select substring('CDA数据分析',1,3);
select substring('CDA数据分析',6); -- 返回位置6后所有字符
- 删除空格
-- LTRIM(str) 返回删除了左空格的字符串str
-- RTRIM(str) 返回删除了右空格的字符串str
-- TRIM(str) 返回删除了两边空格的字符串str
select trim(' CDA数据分析 ');
- 替换字符串
-- REPLACE(str,from_str,to_str) 用字符串to_str替换字符串str中的子串from_str并返回
select replace('CDA数据分析', 'CDA', 'cda');
- 重复字符串
-- REPEAT(str,count) 返回由count个字符串str连成的一个字符串
select repeat('CDA', 3);
- 颠倒字符串
-- REVERSE(str) 颠倒字符串str的字符顺序并返回
select reverse('CDA');
- 大小写转换
-- UPPER(str) 返回大写的字符串str
-- LOWER(str) 返回大写的字符串str
select lower('CDA');
-- 练习:将每位员工的姓名首字母转换为大写
select concat(upper(left(ename,1)),mid(ename,2)) from emp;
3.2 数学函数
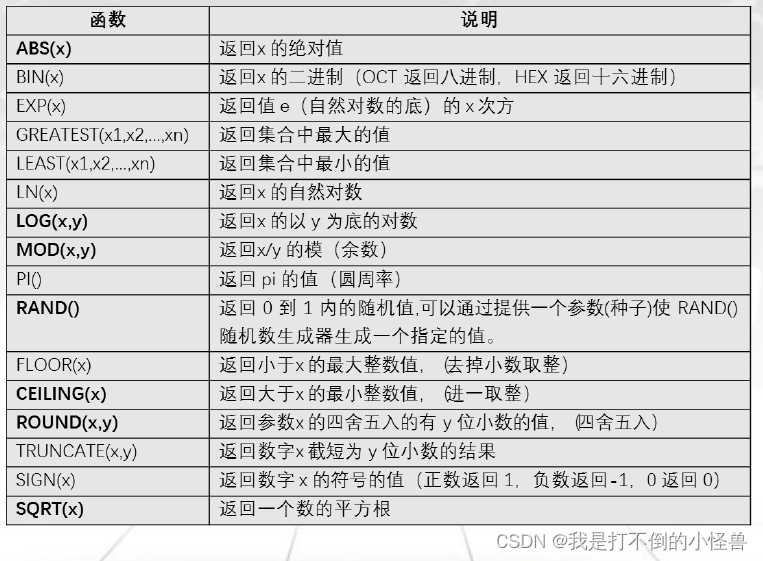
-- ABS(n) 返回n的绝对值
select abs(-32);
-- FLOOR(n) 返回不大于n的最大整数值
-- CEILING(n) 返回不小于n的最小整数值
select floor(1.23);
select ceiling(1.23);
-- ROUND(n,d) 返回n的四舍五入值,保留d位小数(d的默认值为0)
select round(1.58);
-- RAND(n) 返回在范围0到1.0内的随机浮点值(可以使用数字n作为初始值)
select rand();
3.3 时间日期函数
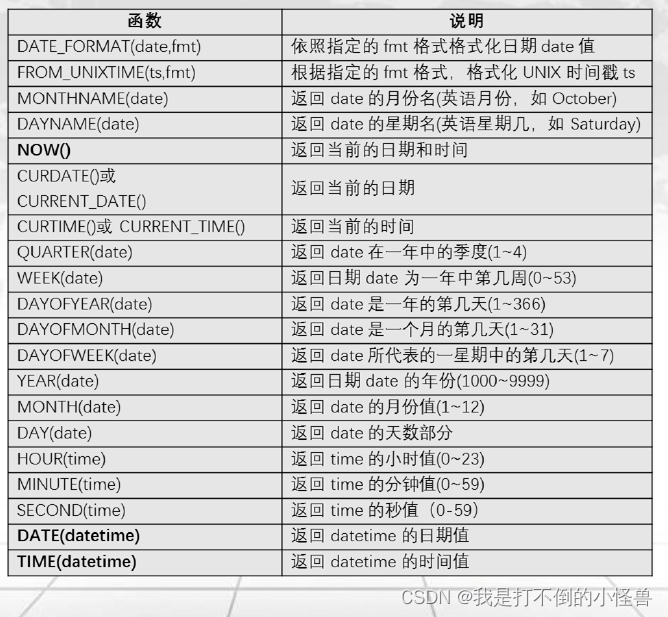
- 返回指定日期的周数,月份,季度,年份
-- DATE(date) 返回指定日期/时间表达式的日期部分或将文本转为日期格式
select date('20200101');
-- WEEK(date) 返回指定日期是一年中的第几周
select week('2019-01-01'); -- 默认第一周为第0周
select week('2019-01-01',0); -- 若第一周不是从周一开始,则第一周为第0周
select week('2019-01-01',1); -- 若第一周不是从周一开始,则第一周为第1周
-- MONTH(date) 返回指定日期的月份
select month('2020-01-01');
-- QUARTER(date) 返回指定日期是一年的第几个季度
select quarter('2020-01-01');
-- YEAR(date) 返回指定日期的年份(范围在1000到9999)
select year('20-01-01');
- 对日期时间进行加减运算
-- DATE_ADD(date,interval expr type) = ADDDATE(date,interval expr type)
select date_add("2020-01-01",interval 1 day);
-- DATE_SUB(date,interval expr type) = SUBDATE(date,interval expr type)
select date_sub("2020-01-01", interval 1 day);
- 对日期时间进行格式化
-- DATE_FORMAT(date,format) 根据format字符串格式化date值
select date_format('20-01-01 12:00:00','%Y-%m-%d');
-- CURDATE() 以'yyyy-mm-dd'或yyyymmdd格式返回当前日期值
-- CURTIME() 以'hh:mm:ss'或hhmmss格式返回当前时间值
-- NOW()以'yyyy-mm-dd hh:mm:ss'或yyyymmddhhmmss格式返回当前日期时间
-- 均根据返回值所处上下文是字符串或数字
select curdate();
select curdate() + 0; -- 字符串格式
- 时间差
-- DATEDIFF(expr1,expr2) 返回结束日expr1和起始日expr2之间的天数
-- 查询每位员工的工龄:ename,hiredate,工龄
select empid,ename,job,hiredate,datediff(curdate(),hiredate)/365 工龄 from emp;
-- 练习:查询每位员工的工龄:ename,hiredate,工龄
select empid,ename,job,hiredate,datediff(curdate(),hiredate)/365 工龄 from emp;
- 时间戳
-- UNIX_TIMESTAMP() 返回一个unix时间戳(从'1970-01-01 00:00:00'开始的秒数,date默认值为当前时间)
select unix_timestamp();
select unix_timestamp('2020-01-01');
-- FROM_UNIXTIME(unix_timestamp)以'yyyy-mm-dd hh:mm:ss'或yyyymmddhhmmss格式返回时间戳的值
-- 根据返回值所处上下文是字符串或数字
select from_unixtime(1577808000);
select from_unixtime(1577808000) + 0; -- 字符串格式
3.4 分组合并函数
-- GROUP_CONCAT([distinct] str [order by str asc/desc] [separator])
-- 将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
-- 示例:查询每个部门的员工姓名
select deptno,group_concat(ename) from emp group by deptno;
select deptno,group_concat(distinct ename ) from emp group by deptno;
select deptno,group_concat(ename order by sal asc) from emp group by deptno;
select deptno,group_concat(ename order by ename) from emp group by deptno;
select deptno,group_concat(ename separator'/') from emp group by deptno; -- 默认分隔符为','
3.5 逻辑函数
-- IFNULL(expression, alt_value)
-- 判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值。
-- 查询每位员工的实发工资(基本工资+提成):ename,sal,实发工资
select ename,sal,sal+ifnull(comm,0) 实发工资 from emp;
-- IF(expr1,expr2,expr3)
-- 如果expr1的值为true,则返回expr2的值,如果expr1的值为false,则返回expr3的值。
-- 查询每位员工的工资级别:3000及以上为高,1500-3000为中,1500及以下为低
select ename,sal,if(sal>=3000,'高',if(sal>=1500,'中','低')) 工资级别 from emp;
-- CASE WHEN expr1 THEN expr2 [WHEN expr3 THEN expr4...ELSE expr] END
-- 如果expr1的值为true,则返回expr2的值,如果expr3的值为false,则返回expr4的值
-- 查询每位员工的工资级别:3000及以上为高,1500-3000为中,1500及以下为低
select ename,sal,case when sal>=3000 then '高' when sal>=1500 then '中'else '低' end 工资级别 from emp;
3.6 开窗函数
开窗函数是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。开窗函数的本质还是聚合运算,只不过它更具灵活性,它对数据的每一行,都使用与该行相关的行进行计算并返回计算结果。
开窗函数的一个概念是当前行,当前行属于某个窗口,窗口由over关键字来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,开窗函数基于所有行进行计算;如果不为空,则有三个参数来设置窗口:
partition by子句:按照指定字段进行分区,两个分区由边界分隔,开窗函数在不同的分区内分别执行,在跨越分区边界时重新初始化。
order by子句:按照指定字段进行排序,开窗函数将按照排序后的记录顺序进行编号。可以和partition by子句配合使用,也可以单独使用。
frame子句:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用。
对于滑动窗口的范围指定,通常使用 between frame_start and frame_end语法来表示行范围, frame_start和frame_end可以支持如下关键字,来确定不同的动态行记录:
current row 边界是当前行,一般和其他范围关键字一起使用
unbounded preceding 边界是分区中的第一行
unbounded following 边界是分区中的最后一行
expr preceding 边界是当前行减去expr的值
expr following 边界是当前行加上expr的值
比如下列都是合法的范围:
--窗口范围是当前行、前一行、后一行一共三行记录。
rows between 1 preceding and 1 following
--窗口范围是当前行到分区中的最后一行。
rows unbounded preceding
--窗口范围是当前分区中所有行,等同于不写。
rows between unbounded preceding and unbounded following
-- 开窗函数名([<字段名>]) over([partition by <分组字段>] [order by <排序字段> [desc]] [<细分窗口>])
-- 聚合函数用于开窗函数
-- 开窗函数,返回一列值,按入职时间顺序显示
-- 查询所有员工的平均工资
select avg(sal) 所有员工平均工资 from emp; -- 聚合函数,返回一个值
select *,avg(sal) over() 所有员工平均工资 from emp; -- 开窗函数,返回一列值,相当于表中多了一个字段
-- 查询各部门平均工资
select deptno,avg(sal) 部门平均工资 from emp group by deptno; -- 聚合函数,返回三行记录
select *,avg(sal) over(partition by deptno) 部门平均工资 from emp; -- 开窗函数,返回一列值,按分区顺序显示
select *,avg(sal) over(partition by deptno order by hiredate) 部门平均工资 from emp;
-- 查询各部门按入职日期计算当前行的前一行和后一行的平均工资
select *,avg(sal) over(partition by deptno order by hiredate
rows between 1 preceding and 1 following) 部门平均工资 from emp; -- 分区计算
3.7 序号函数
-- row_number() 显示分区中不重复不间断的序号
-- dense_rank() 显示分区中重复不间断的序号
-- rank() 显示分区中重复间断的序号
-- 查询员工信息并按照工资高低显示排名
select *,row_number() over(order by sal desc) 排名 from emp;
-- 查询员工信息并按照各部门的工资高低显示排名
select *,row_number() over(partition by deptno order by sal desc) 排名1,
dense_rank() over(partition by deptno order by sal desc) 排名2,
rank() over(partition by deptno order by sal desc) 排名3
from emp;
-- 若有重复值:排名1:1 2 3 4 排名2:1 1 2 3 排名3:1 1 3 4
数据库练习
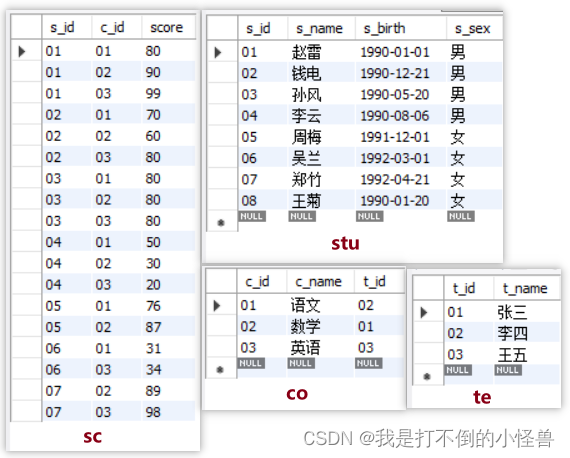
-- 创建数据库school
create database school;
-- 选择进入school数据库
use school;
-- ------------建表导数-------------
-- 创建stu
create table stu(
s_id varchar(10) primary key,
s_name varchar(10) not null,
s_birth date,
s_sex varchar(10));
-- 导入数据
insert into stu values
('01' , '赵雷' , '1990-01-01' , '男'),
('02' , '钱电' , '1990-12-21' , '男'),
('03' , '孙风' , '1990-05-20' , '男'),
('04' , '李云' , '1990-08-06' , '男'),
('05' , '周梅' , '1991-12-01' , '女'),
('06' , '吴兰' , '1992-03-01' , '女'),
('07' , '郑竹' , '1992-04-21' , '女'),
('08' , '王菊' , '1990-01-20' , '女');
select * from stu; -- 检查数据
select count(*) from stu; -- 检查总行数8
-- 创建co
create table co(
c_id varchar(10) primary key,
c_name varchar(10),
t_id varchar(10));
-- 导入数据
insert into co values
('01' , '语文' , '02'),
('02' , '数学' , '01'),
('03' , '英语' , '03');
select * from co; -- 检查数据
select count(*) from co; -- 检查总行数3
-- 创建te
create table te(
t_id varchar(10) primary key,
t_name varchar(10));
-- 导入数据
insert into te values
('01' , '张三'),
('02' , '李四'),
('03' , '王五');
select * from te; -- 检查数据
select count(*) from te; -- 检查总行数3
-- 创建sc
create table sc(
s_id varchar(10),
c_id varchar(10),
score int);
-- 导入数据
insert into sc values
('01' , '01' , 80),
('01' , '02' , 90),
('01' , '03' , 99),
('02' , '01' , 70),
('02' , '02' , 60),
('02' , '03' , 80),
('03' , '01' , 80),
('03' , '02' , 80),
('03' , '03' , 80),
('04' , '01' , 50),
('04' , '02' , 30),
('04' , '03' , 20),
('05' , '01' , 76),
('05' , '02' , 87),
('06' , '01' , 31),
('06' , '03' , 34),
('07' , '02' , 89),
('07' , '03' , 98);
select * from sc; -- 检查数据
select count(*) from sc; -- 检查总行数18
-- ----------------------------------------------------------------------------------
-- 1、查询"01"课程比"02"课程成绩高的学生信息及课程分数(选修的每一门课程的分数)
#查询"01"课程的成绩
select * from sc where c_id='01';
#查询"02"课程的成绩
select * from sc where c_id='02';
select stu.*,sc.c_id,sc.score
from (select * from sc where c_id='01') t1
join (select * from sc where c_id='02') t2 on t1.s_id=t2.s_id
join stu on t1.s_id=stu.s_id
join sc on stu.s_id=sc.s_id
where t1.score>t2.score;
-- ----------------------------------------------------------------------------------
-- 2、练习:查询"01"课程比"02"课程成绩低的学生的信息及课程分数
select stu.*,sc.c_id,sc.score
from (select * from sc where c_id='01') t1
join (select * from sc where c_id='02') t2 on t1.s_id=t2.s_id
join stu on t1.s_id=stu.s_id
join sc on stu.s_id=sc.s_id
where t1.score<t2.score;
-- ----------------------------------------------------------------------------------
-- 3、查询平均成绩大于等于60分的同学的学生编号、学生姓名和平均成绩
select stu.s_id,s_name,avg(score) 平均成绩
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having avg(score)>=60;
-- ----------------------------------------------------------------------------------
-- 4、练习:查询平均成绩小于60分的同学的学生编号、学生姓名和平均成绩
select stu.s_id,s_name,avg(score) 平均成绩
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having avg(score)<60;
-- ----------------------------------------------------------------------------------
-- 6、查询"李"姓老师的数量
select count(t_id)
from te
where t_name like '李%';
-- ----------------------------------------------------------------------------------
-- 29、练习:查询名字中含有"风"字的学生信息
select *
from stu
where s_name like '%风%';
-- ----------------------------------------------------------------------------------
-- 7、查询学过"张三"老师授课的同学的信息
-- 法一:
-- 查询学过"张三"老师授课的同学id
select s_id
from sc
left join co on sc.c_id=co.c_id
left join te on co.t_id=te.t_id
where t_name='张三';
-- 查询学过"张三"老师授课的同学信息
select *
from stu
where s_id in(select s_id
from sc
left join co on sc.c_id=co.c_id
left join te on co.t_id=te.t_id
where t_name='张三');
-- 法二
select stu.*
from stu
left join sc on stu.s_id=sc.s_id
left join co on sc.c_id=co.c_id
left join te on te.t_id=co.t_id
where t_name='张三';
-- 法三:
select stu.*
from stu
left join sc on stu.s_id=sc.s_id
left join co on sc.c_id=co.c_id
where t_id=01;
-- ----------------------------------------------------------------------------------
-- 40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
select stu.*,score
from stu
left join sc on stu.s_id=sc.s_id
left join co on sc.c_id=co.c_id
left join te on te.t_id=co.t_id
where t_name='张三' and score=(select max(score)
from stu
left join sc on stu.s_id=sc.s_id
left join co on sc.c_id=co.c_id
left join te on te.t_id=co.t_id
where t_name='张三');
-- ----------------------------------------------------------------------------------
-- 8、练习:查询没学过"张三"老师授课的同学的信息
select *
from stu
where s_id not in(select s_id
from sc
left join co on sc.c_id=co.c_id
left join te on co.t_id=te.t_id
where t_name='张三');
-- ----------------------------------------------------------------------------------
-- 9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
select stu.*
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having group_concat(c_id order by c_id) like '01,02%';
-- ----------------------------------------------------------------------------------
-- 10、练习:查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
-- 法一:合并字符串
select stu.*
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having group_concat(c_id order by c_id) like '%01%' and group_concat(c_id order by c_id) not like '%02%';
-- 法二:先找学习了01和02课程的学生id
select *
from stu
where s_id in(select s_id from sc where c_id='01') and s_id not in (select s_id from sc where c_id='02');
select stu.*
from stu left join sc on stu.s_id=sc.s_id
where c_id='01'and stu.s_id not in (select s_id from sc where c_id='02');
-- ----------------------------------------------------------------------------------
-- 45、查询选修了全部课程的学生信息
select *
from stu
where s_id in (select s_id
from sc
group by s_id
having count(c_id)=(select count(c_id) from co));
select stu.*
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having count(c_id)=(select count(c_id) from co);
-- ----------------------------------------------------------------------------------
-- 11、练习:查询没有学全所有课程的同学的信息
select *
from stu
where s_id not in (select s_id
from sc
group by s_id
having count(c_id)=(select count(c_id) from co));
select stu.*
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having count(c_id)<>(select count(c_id) from co);
-- ----------------------------------------------------------------------------------
-- 12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
select distinct stu.*
from stu left join sc on stu.s_id=sc.s_id
where c_id in (select c_id from sc where s_id='01') and stu.s_id<>'01';
-- ----------------------------------------------------------------------------------
-- 13、练习:查询和"01"号的同学学习的课程完全相同的其他同学的信息
select stu.*
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
having group_concat(sc.c_id)=(select group_concat(c_id) from sc where s_id='01') and stu.s_id!=01;
-- ----------------------------------------------------------------------------------
-- 35、查询所有学生的课程及分数情况(一维转二维)
select stu.s_id,
sum(if(c_id='01',score,0)) '01',
sum(if(c_id='02',score,0)) '02',
sum(if(c_id='03',score,0)) '03'
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id;
select stu.s_id,
sum(case when c_id='01' then score else 0 end) '01',
sum(case when c_id='02' then score else 0 end) '02',
sum(case when c_id='03' then score else 0 end) '03'
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id;
select stu.s_id,
ifnull(sum((c_id='01')*score),0) '01',
ifnull(sum((c_id='02')*score),0) '02',
ifnull(sum((c_id='03')*score),0) '03'
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id;
-- ----------------------------------------------------------------------------------
-- 17、练习:按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
select stu.s_id,
sum(if(c_id='01',score,0)) '01',
sum(if(c_id='02',score,0)) '02',
sum(if(c_id='03',score,0)) '03',
ifnull(avg(score),0) 平均成绩
from stu left join sc on stu.s_id=sc.s_id
group by stu.s_id
order by 平均成绩 desc;
-- ----------------------------------------------------------------------------------
-- 18、查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
#及格为:>=60,中等为:70-80,优良为:80-90,优秀为:>=90
select co.c_id,c_name,max(score) 最高分,min(score) 最低分,avg(score) 平均分,
avg(score>=60) 及格率,
avg(score>=70 and score<80) 中等率,
avg(score>=80 and score<90) 优良率,
avg(score>=90) 优秀率
from co left join sc on co.c_id=sc.c_id
group by co.c_id;
-- ----------------------------------------------------------------------------------
-- 23、练习:统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
select co.c_id,c_name,
sum((score>=85)) '[100-85]',
sum((score>=70 and score<85)) '[85-70]',
sum((score>=60 and score<70)) '[70-60]',
sum((score<60)) '[0-60]',
concat(avg(score>=85)*100,'%') '[100-85]百分比',
concat(avg(score>=70 and score<85)*100,'%') '[85-70]百分比',
concat(avg(score>=60 and score<70)*100,'%') '[70-60]百分比',
concat(avg(score<60)*100,'%') '[0-60]百分比'
from co left join sc on co.c_id=sc.c_id
group by co.c_id;
-- ----------------------------------------------------------------------------------
-- 19、查询学生的总成绩并进行排名
select s_id,sum(score) 总成绩,row_number() over(order by sum(score) desc) 排名
from sc
group by s_id;
-- ----------------------------------------------------------------------------------
-- 24、练习:查询每个学生平均成绩及其名次
select s_id,avg(score) 平均成绩,row_number() over(order by avg(score) desc) 排名
from sc
group by s_id;
-- ----------------------------------------------------------------------------------
-- 20、按各科成绩进行排序,并显示排名
select *,dense_rank() over(partition by c_id order by score desc) 排名
from sc;
-- ----------------------------------------------------------------------------------
-- 25、查询各科成绩前三名的记录
select *
from
(select *,dense_rank() over(partition by c_id order by score desc) 排名
from sc) t
where 排名<=3;
-- ----------------------------------------------------------------------------------
-- 42、练习:查询每门功成绩最好的前两名
select *
from
(select *,dense_rank() over(partition by c_id order by score desc) 排名
from sc) t
where 排名<=2;
-- ----------------------------------------------------------------------------------
-- 22、练习:查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
select *
from
(select stu.*,c_id,score,dense_rank() over(partition by c_id order by score desc) 排名
from stu join sc on stu.s_id=sc.s_id) t
where 排名 between 2 and 3;
-- ----------------------------------------------------------------------------------
-- 26、查询每门课程被选修的学生数
select c_id,count(s_id) 选修人数
from sc
group by c_id;
-- ----------------------------------------------------------------------------------
-- 43、练习:统计每门课程的学生选修人数(超过5人的课程才统计)
#要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
select c_id,count(s_id) 选修人数
from sc
group by c_id
having count(s_id)>5;
-- ----------------------------------------------------------------------------------
-- 30、查询同名同姓学生名单,并统计同名人数
select s_name,count(s_name)-1 同名人数
from stu
group by s_name;
-- ----------------------------------------------------------------------------------
-- 36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
select s_name,c_name,score
from stu
join sc on stu.s_id=sc.s_id
join co on sc.c_id=co.c_id
where score>70;
select s_name,c_name,score
from stu
join sc on stu.s_id=sc.s_id
join co on sc.c_id=co.c_id
where stu.s_id in (select s_id from sc where score>70);
-- ----------------------------------------------------------------------------------
-- 37、练习:查询出现过学生考试不及格的课程
select c_name,sc.c_id,score
from sc join co on sc.c_id=co.c_id
where score<60;
-- ----------------------------------------------------------------------------------
-- 41、查询课程不同、成绩相同的学生的学生编号、课程编号、学生成绩
select distinct t1.*
from sc t1 join sc t2 on t1.s_id=t2.s_id and t1.c_id<>t2.c_id and t1.score=t2.score;
-- ----------------------------------------------------------------------------------
-- 47、查询本周过生日的学生
select *
from stu
where week(s_birth)=week(curdate());
-- ----------------------------------------------------------------------------------
-- 48、练习:查询下周过生日的学生
select *
from stu
where week(s_birth)=if(week(curdate())=54,1,week(curdate())+1);
-- ----------------------------------------------------------------------------------
-- 49、查询本月过生日的学生
select *
from stu
where month(s_birth)=month(curdate());
-- ----------------------------------------------------------------------------------
-- 50、练习:查询下月过生日的学生
select *
from stu
where month(s_birth)=if(month(curdate())=12,1,month(curdate())+1);














 8856
8856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









