






2023/11/15更新
笔者后来用此方法,发现还是无法实现真正意义上的cpu密集型多线程
后来上网查询发现可以用多进程,实现cpu资源的利用,详情见博客:https://blog.csdn.net/chenpe32cp/article/details/79644994
#################################################################################################
问题:
想通过以下代码实现多线程
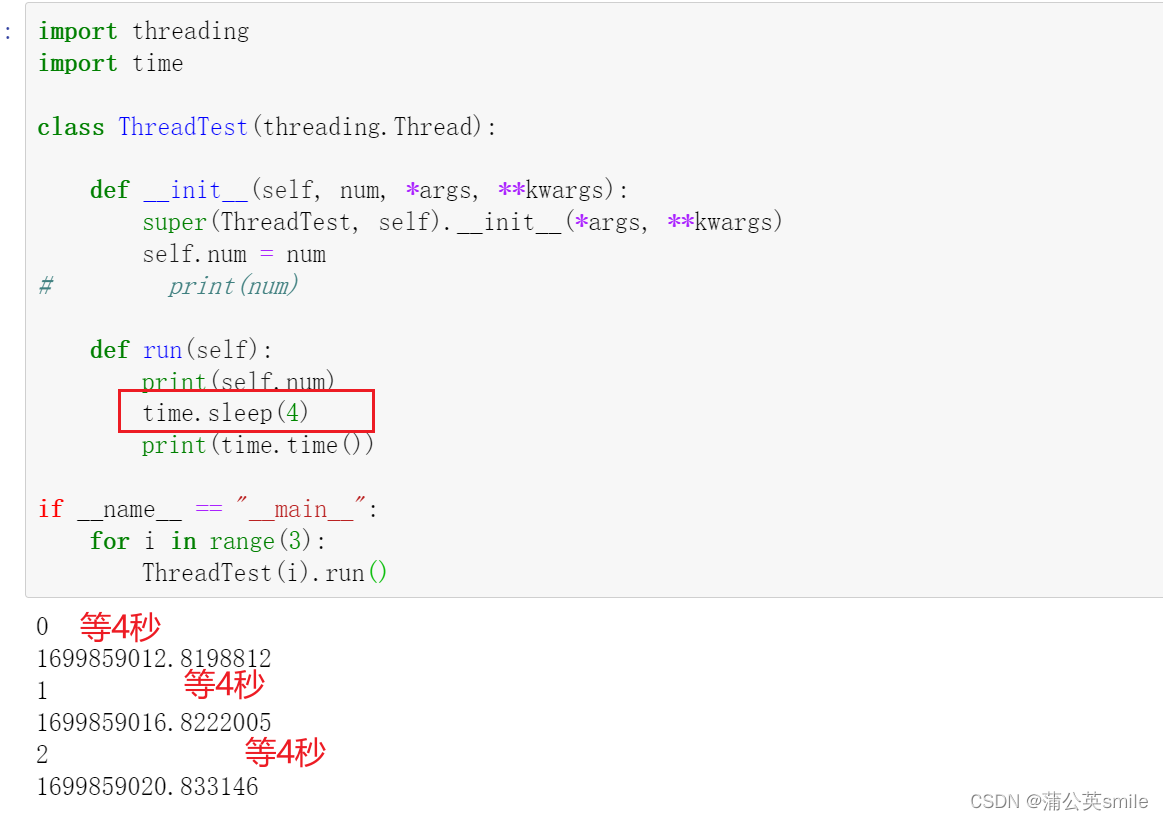
class ThreadTest(threading.Thread):
def __init__(self, num, *args, **kwargs):
super(ThreadTest, self).__init__(*args, **kwargs)
self.num = num
print(num)
def run(self):
print(self.num)
print(time.time())
if __name__ == "__main__":
for i in range(3):
ThreadTest(i).run()
但实际发现是串行计算。打印结果如下:
真正实现多线程:
import threading
import time
class ThreadTest(threading.Thread):
def __init__(self, num, *args, **kwargs):
super(ThreadTest, self).__init__(*args, **kwargs)
self.num = num
# print(num)
def run(self):
print(self.num)
time.sleep(4)
print(time.time())
if __name__ == "__main__":
t0 = ThreadTest(0)
t1 = ThreadTest(1)
t0.start()
t1.start()
t0.join()
t1.join()
总结
python如果单纯去调用run方法,实际上还是会串行计算,但如果使用start()方法,则结果显示中会以并发形式存在。但如果直接使用start()方法,如果主线程结束了,主线程不会等待子线程而会导致整个流程提前结束,所以需要一个阻塞主线程join的方法,但一般join其实是给最长的那个线程增加join就足够了。
————————————————
版权声明:本文为CSDN博主「谷隐凡二」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_37570494/article/details/124729426















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









