







1. 函数
● 聚合函数(用来进行数据聚合的函数),属于窗口函数的其中一种。
参见 2. DML语言【专题:聚合函数(进行汇总求值)】
● 算术函数(用来进行数值计算的函数)
● 字符串函数(用来进行字符串操作的函数)
● 日期函数(用来进行日期操作的函数)
● 转换函数(用来转换数据类型和值的函数)
1.2 算术函数(用来进行数值计算的函数)
(1)算术运算符
算术运算符具有“根据输入值返回相应输出结果”的功能,因此它们是出色的算术函数。
+ - * /
(2)ABS函数:计算绝对值,即一个数到原点的距离。
ABS(数值)
参数为NULL时,结果也是NULL.
绝大多数函数对于NULL都返回NULL.
(3)MOD函数:计算除法余数(求余)
MOD(被除数,除数)
小数计算中并没有余数的概念,所以只能对整数类型的列使用MOD函数。
主流的DBMS都支持 MOD函数,只有 SQL Server 不支持该函数。
SQL Server使用特殊的运算符(函数)“%”来计算余数。
(4)ROUND函数:四舍五入
ROUND(对象数值,保留小数的位数)
1.3 字符串函数(用来进行字符串操作的函数)
1.3.1 || 拼接函数
# 字符串1 + 字符串2 + ...
字符串1 || 字符串2 || ...
如果其中包含 NULL,那么得到的结果也是NULL.
|| 函数 在SQL Server 和 MySQL 中无法使用。
SQL Server使用“+”运算符(函数)来连接字符串。
字符串1 + 字符串2 + ......MySQL使用CONCAT函数来完成字符串的拼接。
CONCAT(字符串1, 字符串2, ......)
1.3.1.1 GROUP_CONCAT函数:组内字符串连接
MySQL中的GROUP_CONCAT()函数详解与实战应用———李少兄
在 MySQL 数据库中,GROUP_CONCAT() 是一个非常实用的聚合函数。
主要用于将属于一组的相关行的数据项进行合并,并以字符串的形式返回。
GROUP_CONCAT([DISTINCT] column_name [,column_name ...]
[ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC]
[SEPARATOR 'separator_string']])
DISTINCT : 可选参数,用于去除重复值。
column_name : 要连接的列名,可以是多个。
ORDER BY : 可选参数,用于指定连接字符串时的排序键。
ASC | DESC : 用于指定排序的方式。
SEPARATOR : 可选参数,用于指定分隔符,默认为逗号“ , ” .
由于GROUP_CONCAT函数,会使表中记录变少,所以GROUP_CONCAT是一个聚合函数。
同其它常用的聚合函数(COUNT、SUM、AVG、MIN、MAX )一样:
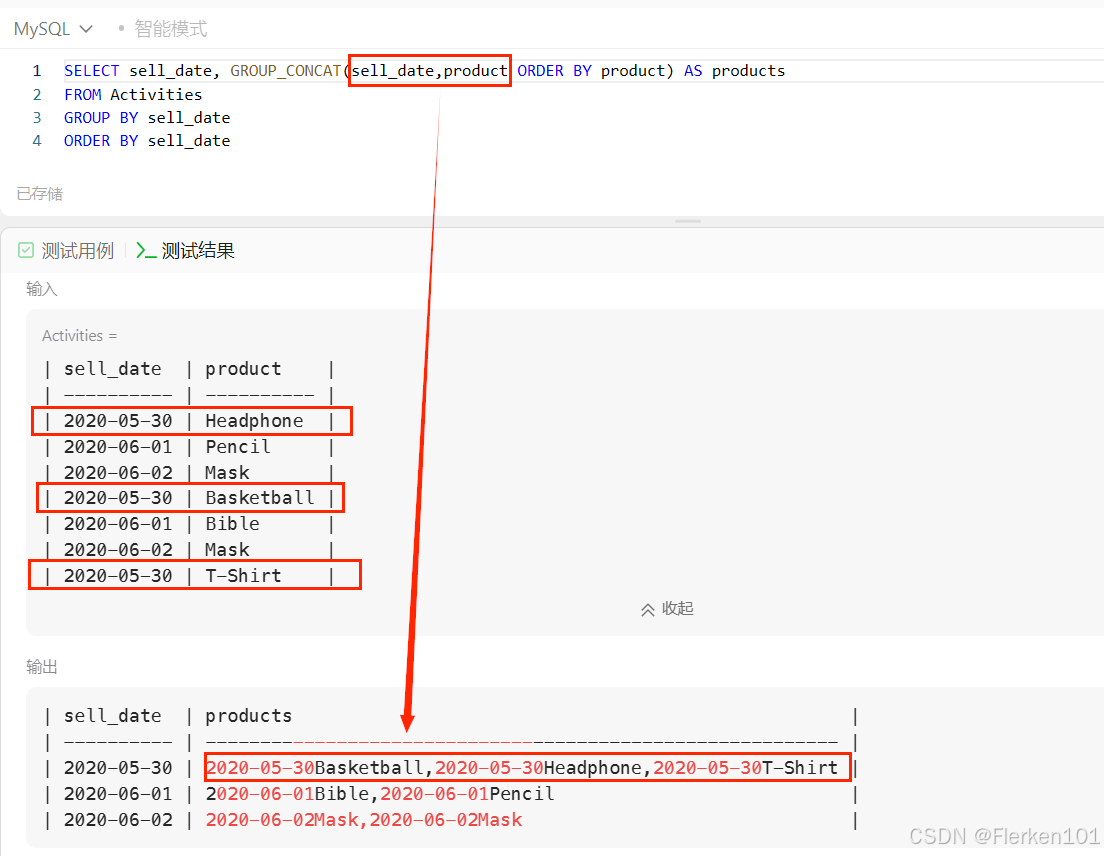
1484. 按日期分组销售产品
DQL语句中,不含GROUP BY子句时,GROUP_CONCAT函数的作用对象为整个表中的所有记录。
DQL语句中,含有GROUP BY子句时,GROUP_CONCAT函数的作用对象为每组中的所有记录。
不同于常用的聚合函数(COUNT、SUM、AVG、MIN、MAX ):GROUP_CONCAT函数并不能作为 聚合窗口函数 来使用,所以它又仅仅是一个聚合函数。
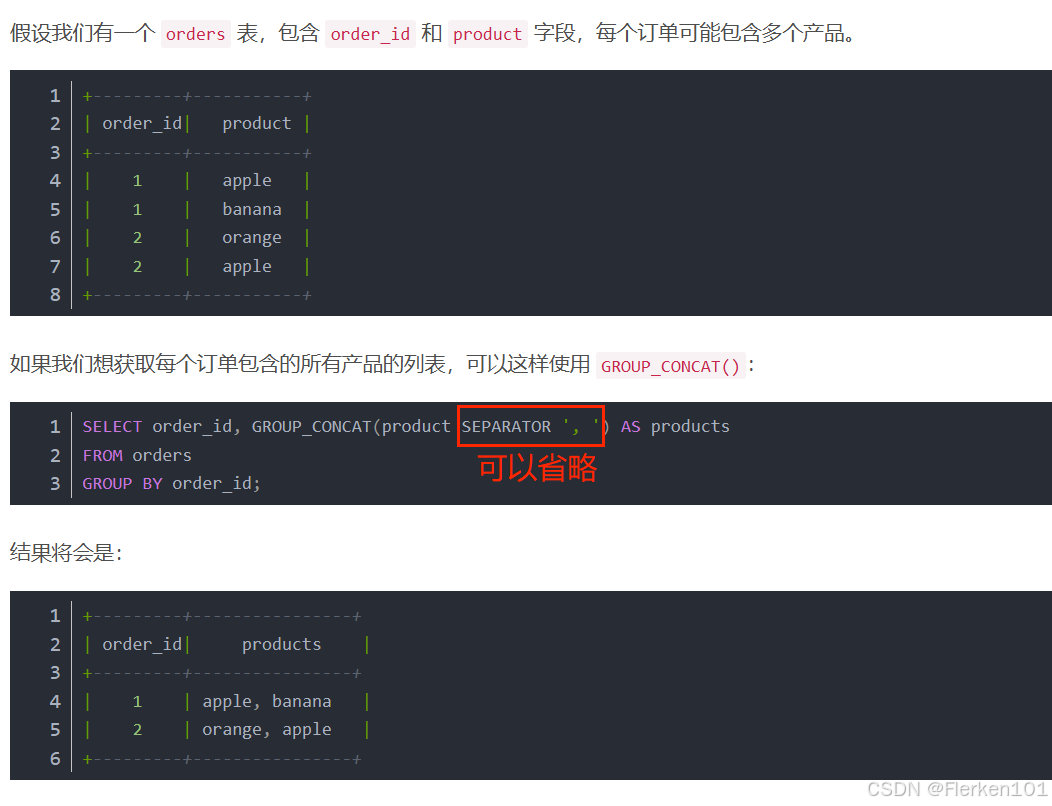
当column_name有多个列名时:
先将一条记录中的目标列名依次连接(中间没有任何分隔符号);
再将每一条记录中连接好的内容依次连接(使用SEPARATOR中指定的分隔符号)。
1.3.2 LENGTH函数:字符串字节个数
返回字符串中包含的字节个数。可在MySQL中使用。
LENGTH(字符串)
MySQL中还存在计算字符串长度(字符个数)的自有函数CHAR_LENGTH.
LENGTH函数无法在SQL Server 中使用。
SQL Server使用LEN函数来计算字符串的字符个数,其中不包含尾随空格。
使用DATALENGTH返回字符串所占用的字节数。LEN (字符串) -- 字符个数,字符串长度 DATALENGTH (字符串) -- 字节个数
在Oracle中:
lengthb(string)计算string所占的字节长度:返回字符串的长度,单位是字节
length(string)计算string所占的字符长度:返回字符串的长度,单位是字符
因此,同样是 LENGTH函数,不同DBMS的执行结果也不尽相同。
对于全部为单字节字符的字符串,占用的字节个数和其字符串长度是一样的。
半角英文字母占用 1 字节,汉字这样的全角字符会占用 2 个或以上的字节(称为多字节字符)。
字节(byte)是计算机中用来表述数据大小的基本单位。
单位 千字节(KB)是字节(byte)的1024倍,
单位 兆字节(MB)是千字节(KB)的1024倍,
单位 千兆字节(GB)是兆字节(MB)的1024 倍。
表示硬盘容量时经常会使用的“100 GB”等, 其中100 GB指的是可以存储:
1024×1024×1024×100= 107,374,182,400个字节(byte),
即能存储这么多个半角英文字母。
1.3.3 LOWER、UPPER函数
LOWER函数:
只针对英文字母,将参数中的字符串全都转换为小写。
不影响原本就是小写的字符。
LOWER(字符串)
UPPER函数:
只针对英文字母,将参数中的字符串全都转换为大写。
不影响原本就是大写的字符。
UPPER(字符串)
1.3.4 REPLACE函数:字符串的替换
将对象字符串的一部分替换为其他的字符串。
(1)对象字符串1 中若包含 替换前的字符串2,则将 对象字符串1 中 替换前的字符串2 那部分,替换为 替换后的字符串3 ;
(2)对象字符串1 中若不包含 替换前的字符串2,则对 对象字符串1 什么也不做。
REPLACE(对象字符串1,替换前的字符串2,替换后的字符串3)
1.3.5 SUBSTRING:字符串的截取
截取出字符串中的一部分字符串。
字符串的起始位置从最左侧开始计算。
SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数)
-- 当截取剩余全部字符时,‘FOR 截取的字符数’ 可省略
虽然上述SUBSTRING函数的语法是标准SQL承认的正式语法,但现在只有PostgreSQL和MySQL支持该语法。(即可以用FROM…FOR,也可以用下面的。)
# SQL Server将 SUBSTRING函数 的语法内容进行了简化
SUBSTRING(对象字符串,截取的起始位置,截取的字符数)
-- 当截取剩余全部字符时,‘截取的字符数’ 参数可省略
# Oracle和DB2将语法进一步简化
SUBSTR(对象字符串,截取的起始位置,截取的字符数)
1.4 日期函数(用来进行日期操作的函数)
被标准SQL 承认的可以应用于 绝大多数DBMS的函数。
1.4.1 CURRENT_DATE函数:当前日期
返回SQL执行的日期,也就是该函数执行时的日期。
由于没有参数,因此无需使用括号。
# 语法
CURRENT_DATE
# PostgreSQL、MySQL
SELECT CURRENT_DATE;
''' CURRENT_DATE函数无法在SQL Server 中执行
CURRENT_TIMESTAMP()函数返回带时区的当前日期和时间(即时间戳)。
SQL Server使用CURRENT_TIMESTAMP函数来获得当前时间戳,
再使用CAST函数将CURRENT_TIMESTAMP转换为日期类型。 '''
SELECT CAST(CURRENT_TIMESTAMP AS DATE) AS CUR_DATE;
# 在Oracle中使用CURRENT_DATE函数时,需要在FROM子句中指定临时表(DUAL)
SELECT CURRENT_DATE
FROM dual;
# 在DB2中使用CURRENT_DATE函数时,需要在CRUUENT和DATE之间添加半角空格,并且还需要指定临时表 SYSIBM.SYSDUMMY1
SELECT CURRENT DATE
FROM SYSIBM.SYSDUMMY1;
1.4.2 CURRENT_TIME函数:当前时间
能够取得SQL 执行的时间,也就是该函数执行时的时间。
由于该函数也没有参数,因此同样无需使用括号。
# 语法
CURRENT_TIME
# PostgreSQL、MySQL
SELECT CURRENT_TIME;
''' CURRENT_TIME函数无法在SQL Server中执行
CURRENT_TIMESTAMP()函数返回带时区的当前日期和时间(即时间戳)。
SQL Server使用CURRENT_TIMESTAMP函数来获得当前时间戳,
再使用CAST函数将CURRENT_TIMESTAMP转换为时间类型。 '''
SELECT CAST(CURRENT_TIMESTAMP AS TIME) AS CUR_TIME;
# CURRENT_TIMESTAMP函数返回当前日期和时间
# 在Oracle中使用CURRENT_TIMESTAMP函数时,需要在FROM子句中指定临时表(DUAL)
SELECT CURRENT_TIMESTAMP -- Oracle中没有CURRENT_TIME函数
FROM dual;
# 在DB2中使用CURRENT_TIME函数时,需要在CRUUENT和TIME之间添加半角空格,并且还需要指定临时表 SYSIBM.SYSDUMMY1
SELECT CURRENT TIME
FROM SYSIBM.SYSDUMMY1;
1.4.3 CURRENT_TIMESTAMP函数:当前日期和时间
CURRENT_TIMESTAMP函数具有CURRENT_DATE + CURRENT_TIME的功能。
使用该函数可以同时得到当前的日期和时间,当然也可以从结果中截取日期或者时间。
CURRENT_TIMESTAMP
# SQL Server / PostgreSQL / MySQL
SELECT CURRENT_TIMESTAMP;
# 在Oracle中使用CURRENT_TIMESTAMP函数时,需要在FROM子句中指定临时表(DUAL)
SELECT CURRENT_TIMESTAMP
FROM dual;
# 在DB2中使用CURRENT_TIMESTAMP函数时,需要在CRUUENT和TIMESTAMP之间添加半角空格,并且还需要指定临时表 SYSIBM.SYSDUMMY1
SELECT CURRENT TIMESTAMP
FROM SYSIBM.SYSDUMMY1;
1.4.4 EXTRACT函数:截取 单个/多个 日期元素
截取出日期数据中的一部分,例如“年”“月”,或者“小时”“秒”等。
该函数的返回值并不是日期类型,而是数值类型。
1.4.4.1 截取 单个 日期元素
# 语法
EXTRACT(日期元素 FROM 日期)
# PostgreSQL、MySQL
SELECT
CURRENT_TIMESTAMP,
EXTRACT( YEAR FROM CURRENT_TIMESTAMP ) AS year,
EXTRACT( MONTH FROM CURRENT_TIMESTAMP ) AS month,
EXTRACT( DAY FROM CURRENT_TIMESTAMP ) AS day,
EXTRACT( HOUR FROM CURRENT_TIMESTAMP ) AS hour,
EXTRACT( MINUTE FROM CURRENT_TIMESTAMP ) AS minute,
EXTRACT( SECOND FROM CURRENT_TIMESTAMP ) AS second;
''' EXTRACT函数无法在SQL Server中执行
SQL Server使用DATEPART函数从CURRENT_TIMESTAMP中截取元素。 '''
SELECT
CURRENT_TIMESTAMP,
DATEPART ( YEAR, CURRENT_TIMESTAMP ) AS year,
DATEPART ( MONTH, CURRENT_TIMESTAMP ) AS month,
DATEPART ( DAY, CURRENT_TIMESTAMP ) AS day,
DATEPART ( HOUR, CURRENT_TIMESTAMP ) AS hour,
DATEPART ( MINUTE, CURRENT_TIMESTAMP ) AS minute,
DATEPART ( SECOND, CURRENT_TIMESTAMP ) AS second;
# 在Oracle中使用EXTRACT函数时,需要在FROM子句中指定临时表(DUAL)
SELECT
CURRENT_TIMESTAMP,
EXTRACT( YEAR FROM CURRENT_TIMESTAMP ) AS year,
EXTRACT( MONTH FROM CURRENT_TIMESTAMP ) AS month,
EXTRACT( DAY FROM CURRENT_TIMESTAMP ) AS day,
EXTRACT( HOUR FROM CURRENT_TIMESTAMP ) AS hour,
EXTRACT( MINUTE FROM CURRENT_TIMESTAMP ) AS minute,
EXTRACT( SECOND FROM CURRENT_TIMESTAMP ) AS second
FROM dual;
# 在DB2中使用CURRENT_TIMESTAMP函数时,需要在CRUUENT和TIMESTAMP之间添加半角空格,并且还需要指定临时表 SYSIBM.SYSDUMMY1
SELECT
CURRENT TIMESTAMP,
EXTRACT( YEAR FROM CURRENT TIMESTAMP ) AS year,
EXTRACT( MONTH FROM CURRENT TIMESTAMP ) AS month,
EXTRACT( DAY FROM CURRENT TIMESTAMP ) AS day,
EXTRACT( HOUR FROM CURRENT TIMESTAMP ) AS hour,
EXTRACT( MINUTE FROM CURRENT TIMESTAMP ) AS minute,
EXTRACT( SECOND FROM CURRENT TIMESTAMP ) AS second
FROM SYSIBM.SYSDUMMY1;
1.4.4.2 截取 多个 日期元素时:
EXTRACT(YEAR_MONTH FROM a.program_date)='202006'
等价于:DATE_FORMAT(a.program_date, '%Y-%m') = '2020-06'


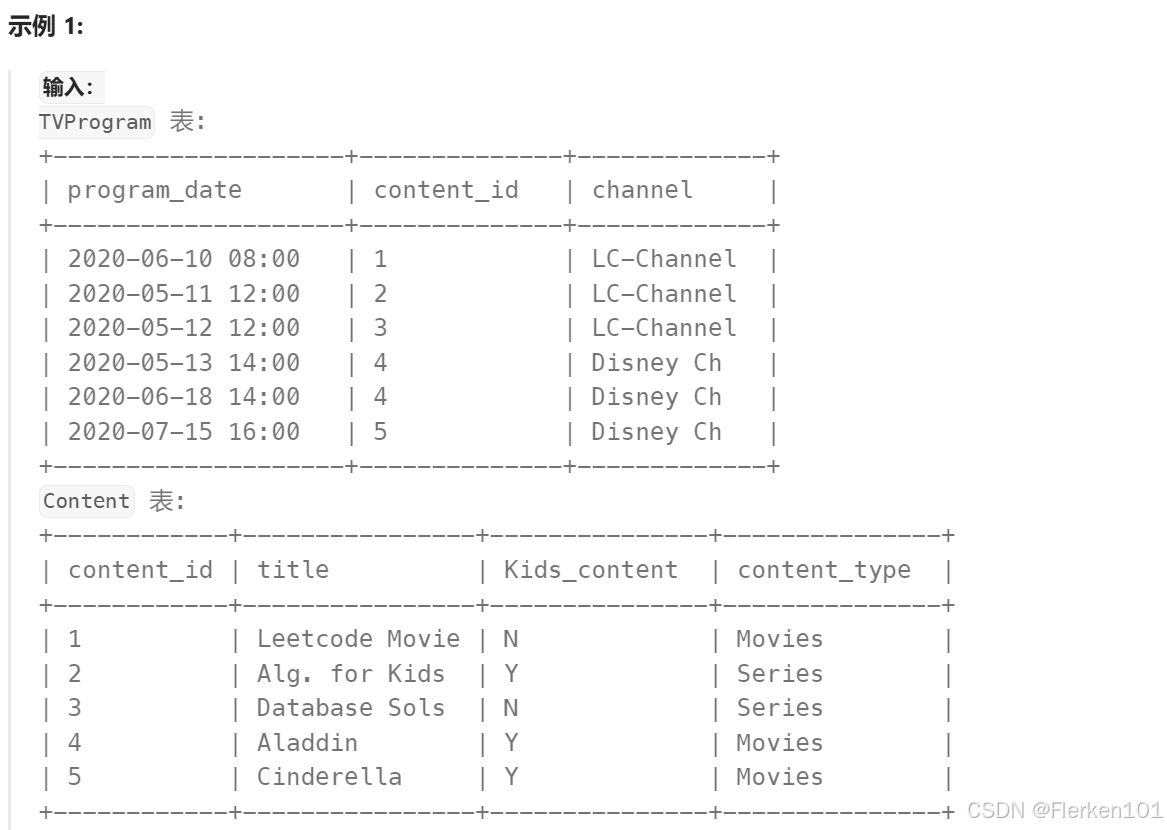

SELECT b.title
FROM TVProgram a
LEFT OUTER JOIN Content b
ON a.content_id = b.content_id
WHERE EXTRACT(YEAR_MONTH FROM a.program_date)='202006'
-- DATE_FORMAT(a.program_date, '%Y-%m') = '2020-06'
AND b.Kids_content = 'Y'
AND b.content_type = 'Movies'
GROUP BY b.title
1.4.5 DATE_FORMAT函数:截取 单个/多个 日期元素
MySQL DATE_FORMAT() 函数
在 MySQL 中,通过 DATE_FORMAT 函数可以将日期类型的数据按照指定的格式进行输出。
基本语法:
DATE_FORMAT(date,format)
DATE_FORMAT函数,可以接受以下五种,所有类型的日期或时间值。
MySQL日期和时间数据类型(DATE、TIME、 DATETIME、 TIMESTAMP和YEAR)——ErbaoLiu

但无论输入的是哪种日期或时间类型,DATE_FORMAT函数都会根据指定的格式将其转换为相应的字符串类型(VARCHAR )表示。
同时,又因为只有以上五种日期或时间数据类型,可以直接用于日期和时间的相关的比较、计算等操作。
这意味着DATE_FORMAT函数返回的结果可以用于文本显示、拼接等操作,但不能直接用于日期或时间的计算。
但在MySQL中,只要DATE_FORMAT函数返回的字符串,符合一定的格式要求,就会发生类型的隐式转换,将其转换为对应的数据类型。
从而使得DATE_FORMAT函数返回的结果,不但可以用于文本显示、拼接等操作(作为VARCHAR类型),还可以直接用于日期和时间的相关的比较、计算等操作(作为以上五种日期或时间数据类型)。
见1.4.5.3 MySQL隐式类型转换。
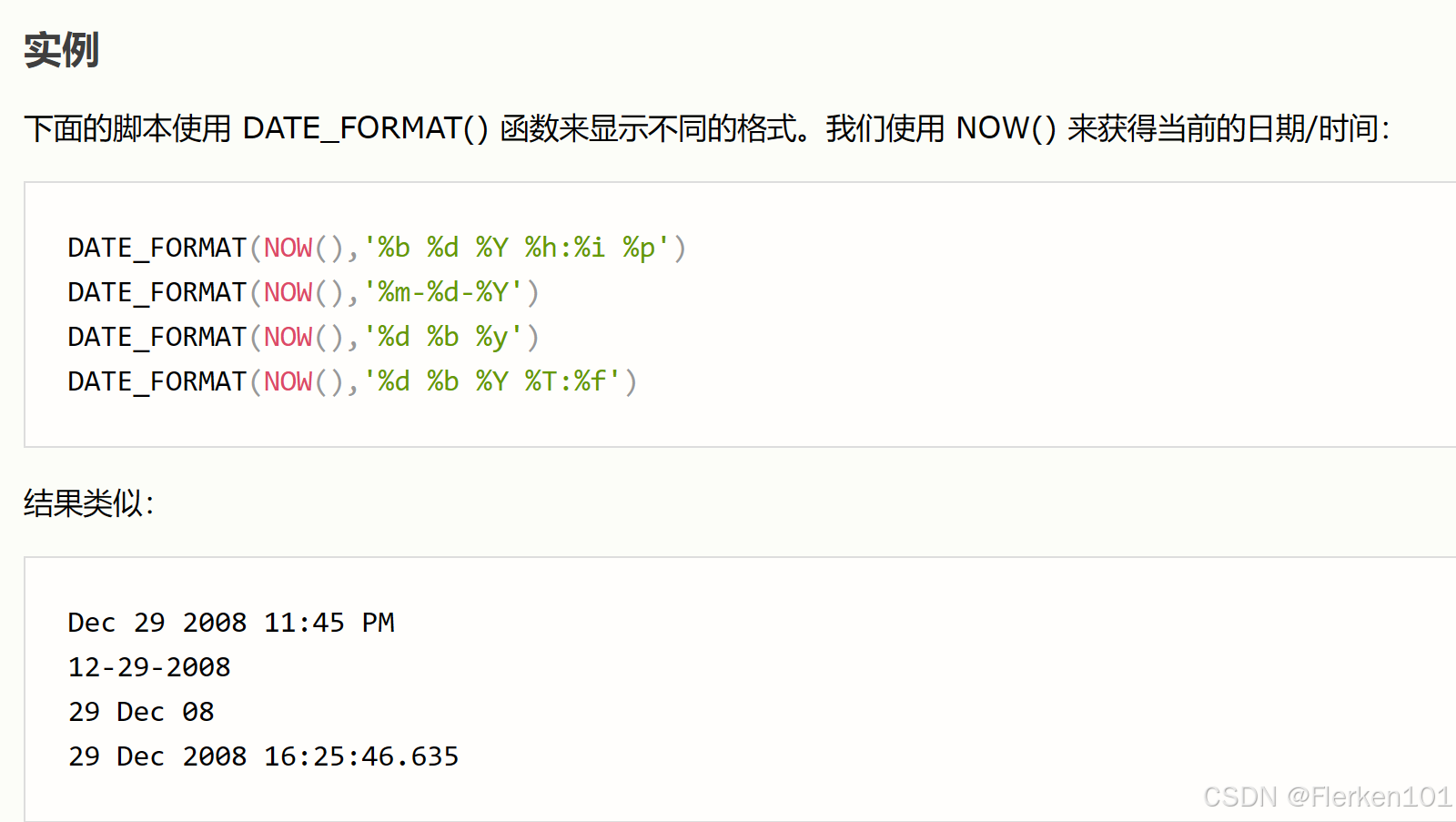
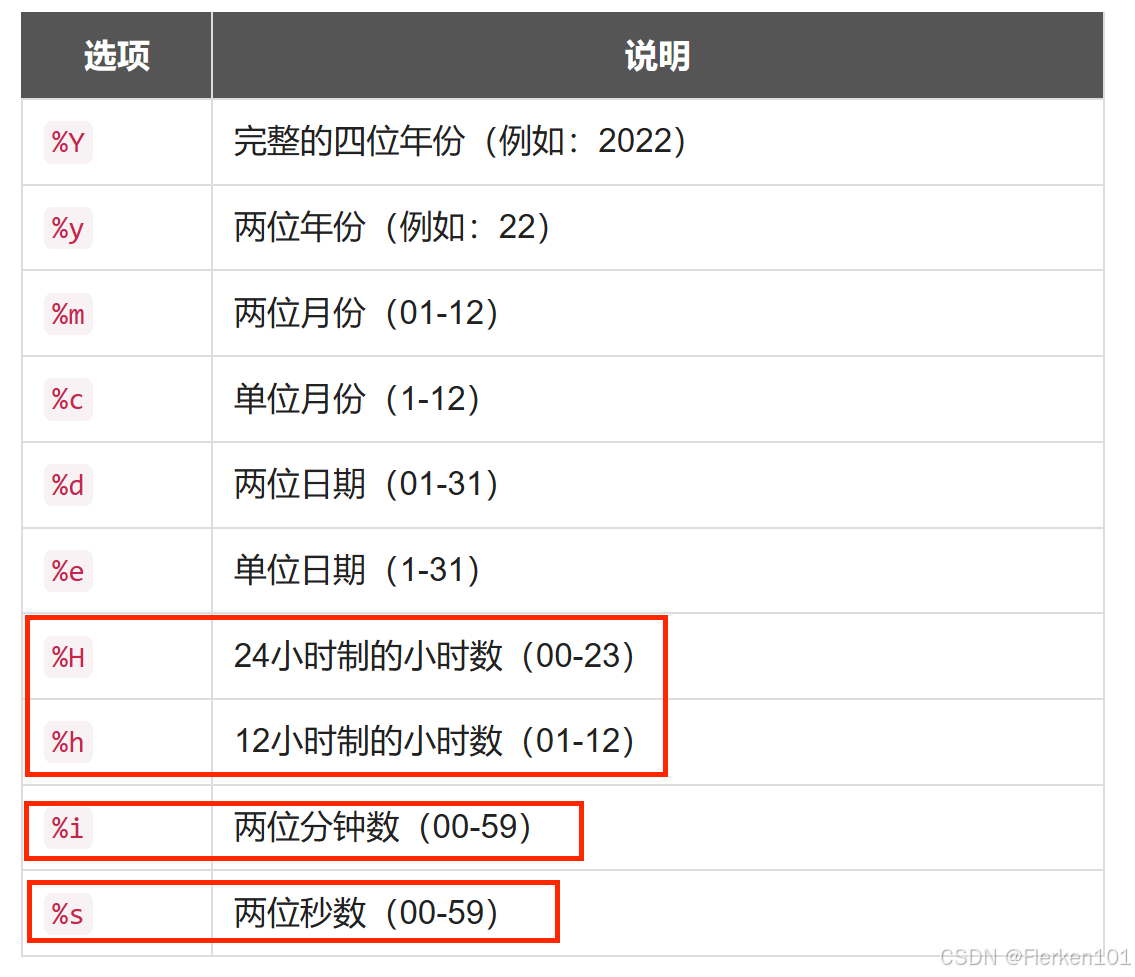
format举例:
%Y 年,4 位
%y 年,2 位
%M 月名
%m 月,数值(00-12)
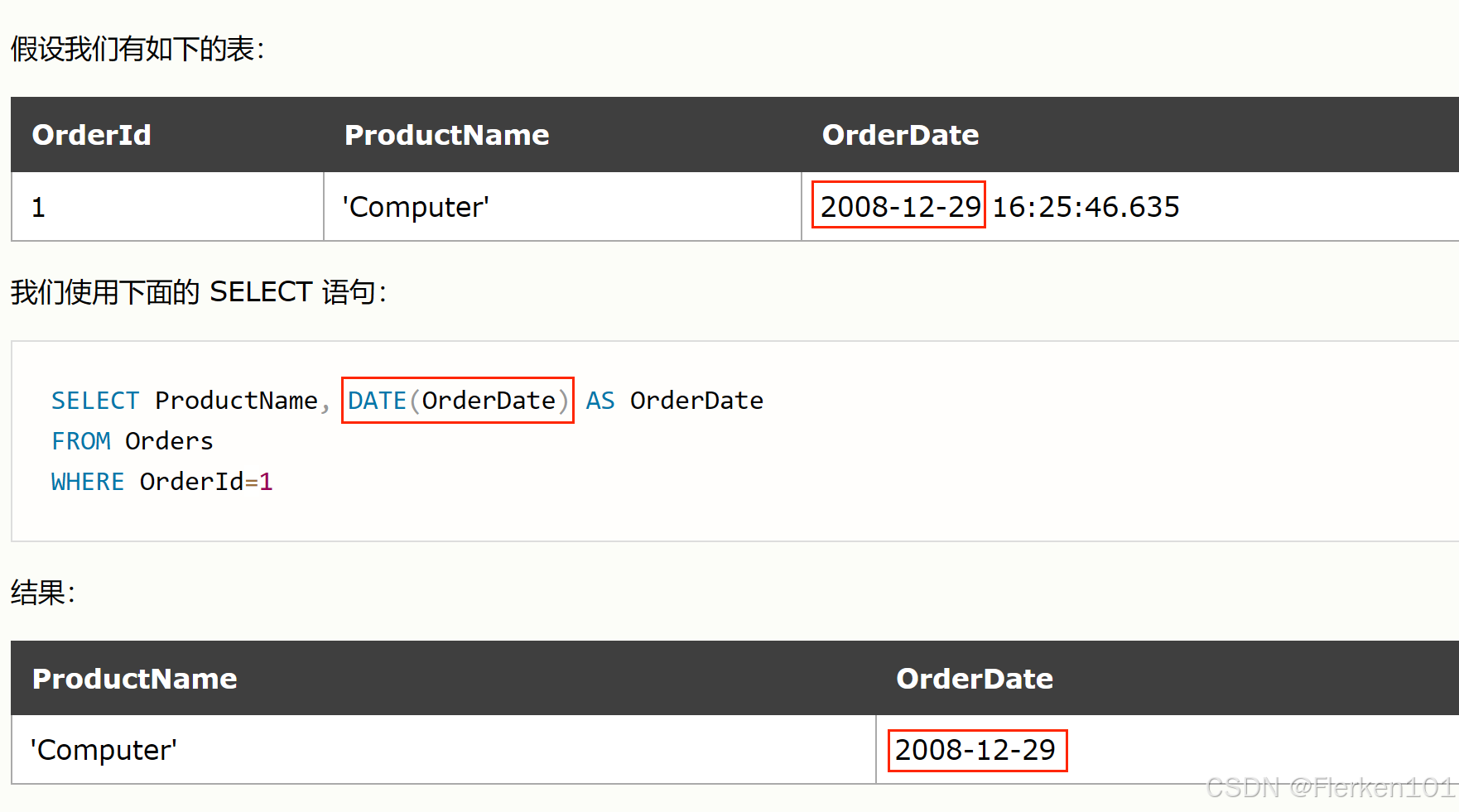
1.4.5.1 DATE函数:截取年月日
DATE(date)
DATE函数,接受的参数date是一个DATETIME、TIMESTAMP 或者符合日期时间格式的字符串,返回的结果DATE 类型。
这意味着返回的值可以直接用于日期相关的比较、计算等操作。
1.4.5.2 TIME函数:截取时分秒
TIME(date)
TIME函数,接受的参数date是一个DATETIME、TIMESTAMP、包含时分秒且符合日期时间格式的字符串。
返回的结果是TIME 类型,可以直接用于时间相关的比较、计算等操作。
1.4.5.3 MySQL隐式类型转换
MySQL会将符合一定格式的字符串,隐式转换为其它数据类型。例如:
(1)日期和时间数据类型的转换:
①会将YYYY-MM-DD、YYYY/MM/DD、YYYYMMDD形式的字符串(VARCHAR类型),转化为DATE类型;
所以从TIMESTAMP类型时间戳列中,截取DATE类型的日期列(年月日)时,可以直接使用DATE_FORMAT函数。
②会将HH:MM:SS、HHMMSS、HH:MM、HH形式的字符串(VARCHAR类型),转化为TIME类型;
所以从TIMESTAMP类型时间戳列中,截取TIME类型的时间列(时分秒)时,可以直接使用DATE_FORMAT函数。
(记得将分割符换成冒号。)
③会将YYYY-MM-DD HH:MM:SS、YYYYMMDDHHMMSS形式的字符串(VARCHAR类型),转化为DATETIME 或 TIMESTAMP 类型;
(2)会将由数字组成的字符串,没有其他非数字字符,可转换为相应的数值NUMERIC类型(如 INT、FLOAT 等)。
虽然 MySQL 支持这些隐式转换,但在实际开发中,为了避免潜在的错误和提高代码的可读性,建议显式地使用类型转换函数进行数据类型转换。
Oracle中时间日期转化函数to_date和to_char用法总结——旺旺_123
在 Oracle 中,可以使用 CAST、TO_DATE、TO_CHAR 函数来格式化日期和时间的形式,以及转换其数据类型,并生成新的结果列。
在mysql中,可以使用 CAST、CONVERT 、str_to_date、date_format函数来格式化日期和时间的形式,以及转换其数据类型,并生成新的结果列。
str_to_date(date,‘%Y-%m-%d’) -------------->oracle中的to_date();
date_format(date,‘%Y-%m-%d’) -------------->oracle中的to_char();
CAST见《1.5.1 CAST函数》
更改已经存在的字段的数据类型,要使用ALTER语句。
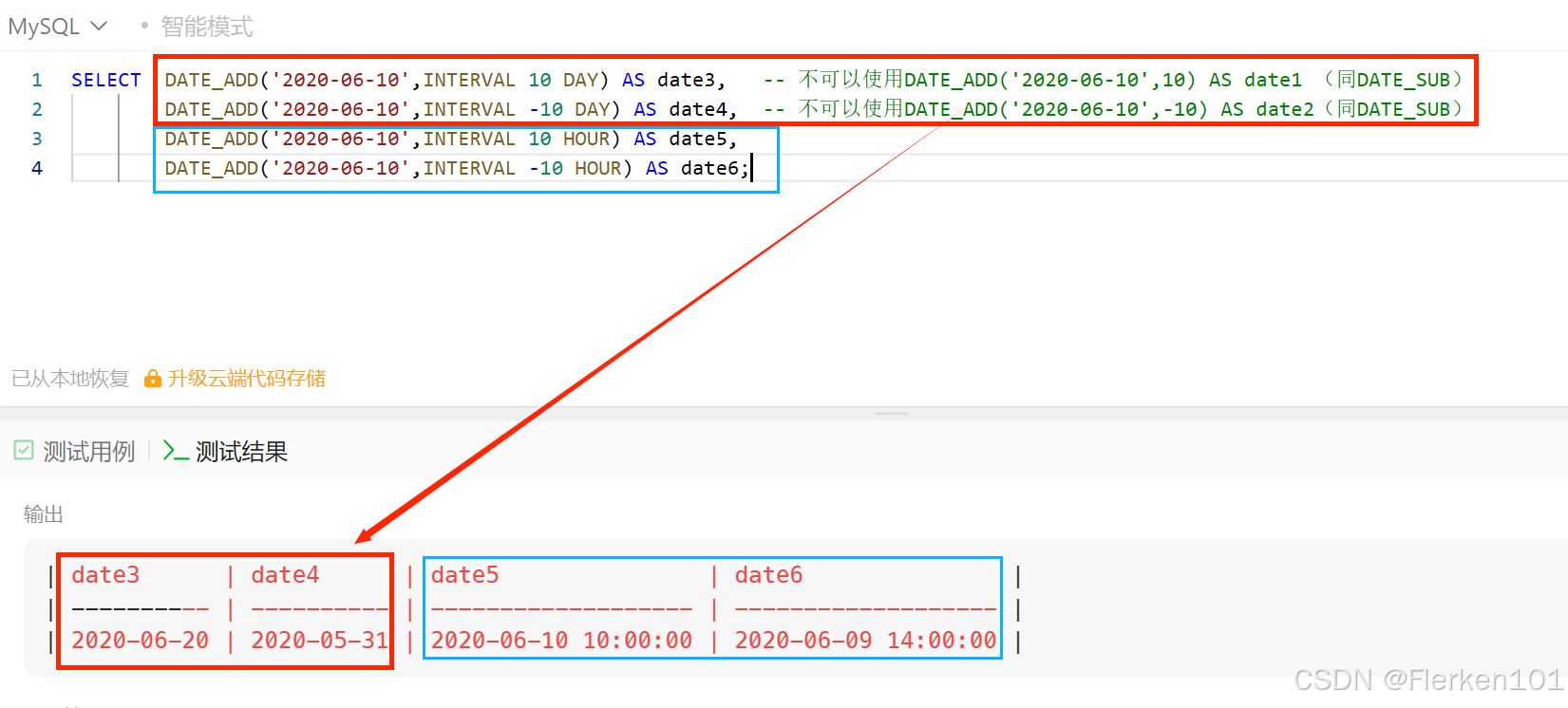
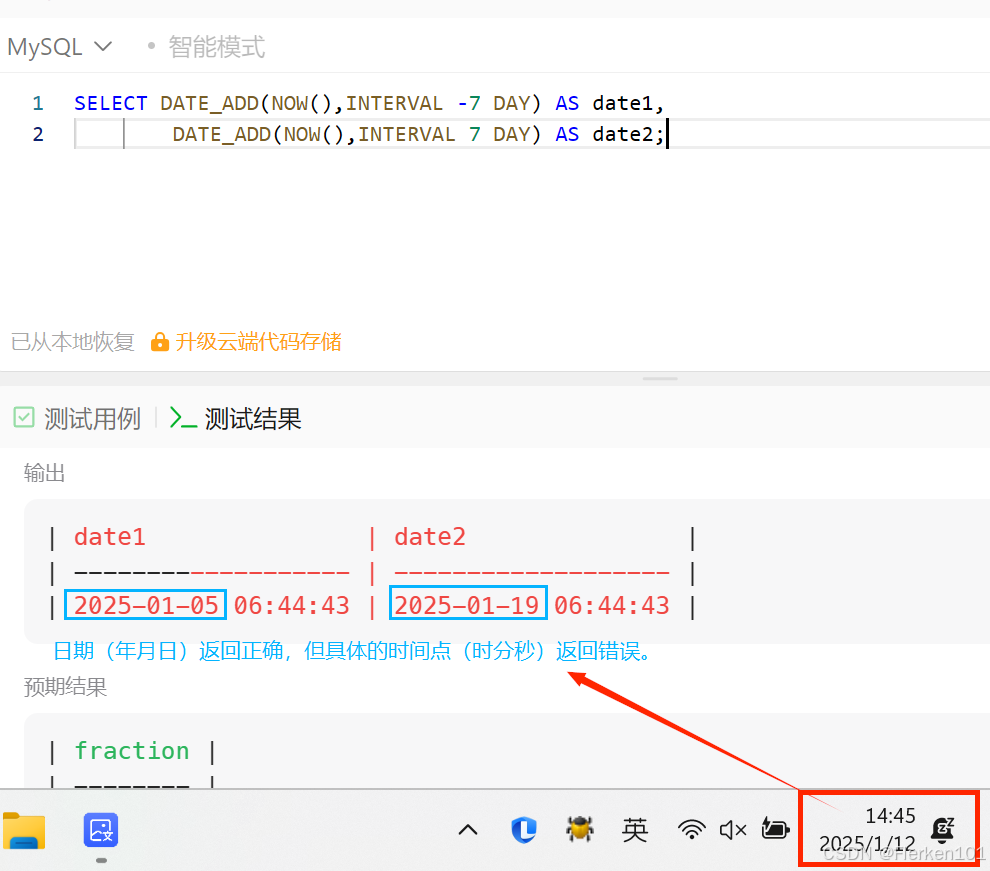
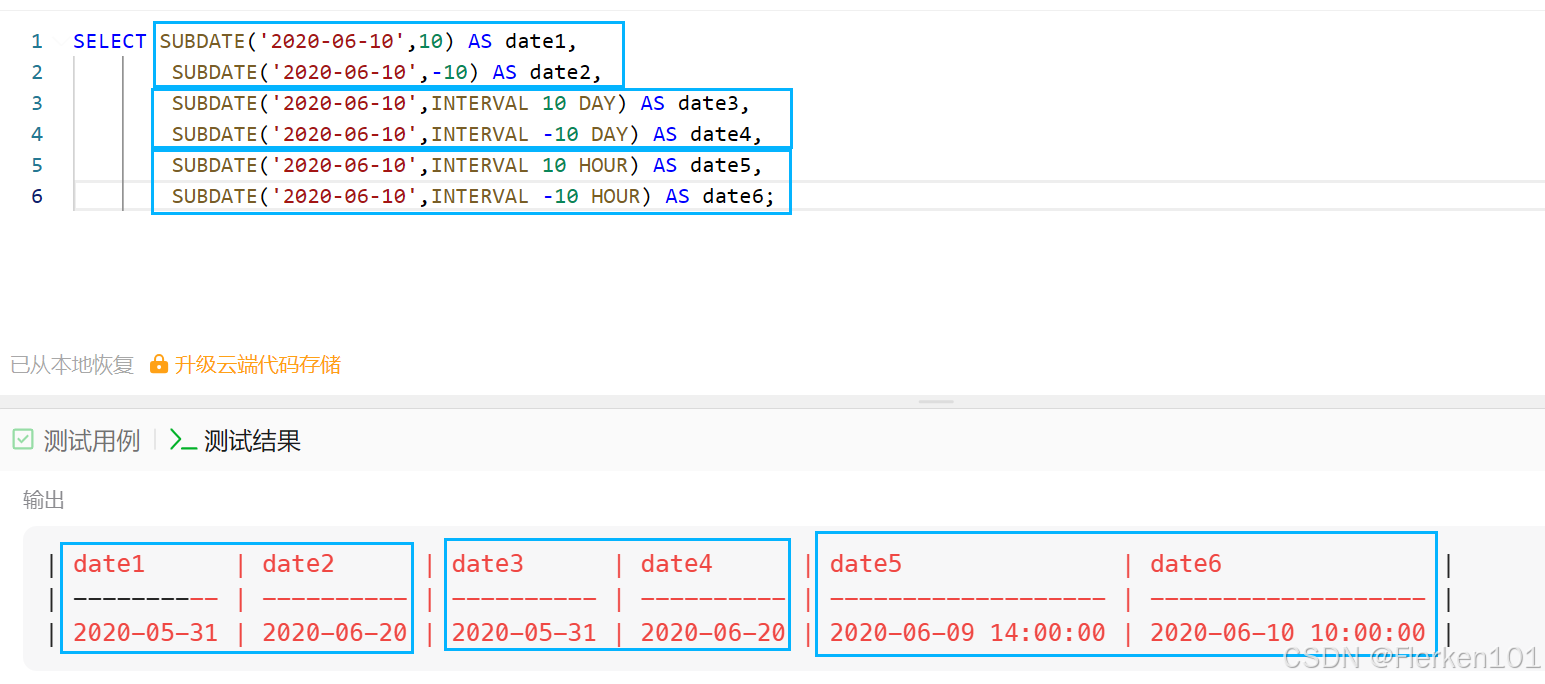
1.4.6 DATE_ADD函数 和 DATE_SUB/SUBDATE函数(时间加减)
【1.4.6 和 1.4.7 关于时间加减的函数,网络上的教程中,很多例子实际执行都无法成功,需要自己在数据库中试,然后总结出正确的语法。】
实际上在数据库中,可用的用法,并没有那么复杂和难以区分。
在Oracle和MySQL中,日期(天数)都可直接加减。
但要避免这种写法,用DATE_ADD 和 DATE_SUB函数去实现。date + N date - N
MySQL中:
2023 年 2 月没有 29 日(非闰年的 2 月只有 28 天),所以日期会自动调整为2023 - 02 - 28。
即MySQL 在处理日期计算时,为了保证日期的合法性会进行自动调整。
1.4.6.1 DATE_ADD函数:加上指定时间间隔
DATE_ADD() 函数向日期添加指定的时间间隔。
语法:
DATE_ADD(date,INTERVAL expr type)
date :合法的日期表达式。
INTERVAL :必须的,说明时时间间隔数据类型。照抄就行。
expr: 希望添加的时间间隔,可正可负。
type:必需的。时间/日期间隔的单位。可以是以下值中的一个:
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
SECOND_MICROSECOND
MINUTE_MICROSECOND
MINUTE_SECOND
HOUR_MICROSECOND
HOUR_SECOND
HOUR_MINUTE
DAY_MICROSECOND
DAY_SECOND
DAY_MINUTE
DAY_HOUR
YEAR_MONTH
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.4.6.2 DATE_SUB/SUBDATE函数:减去指定时间间隔
DATE_SUB/SUBDATE() 函数,均为在指定的日期/时间上,减去指定的时间间隔,并返回新的日期/时间。
所以要加的话,应该使用负值。
SUBDATE函数有两种语法:
SUBDATE函数的第一种语法:减去的时间间隔类型为天数时,可以直接写数字。
(DATE_SUB 函数没有这种语法。)
SUBDATE(date, days)
date:必需的。需要操作的日期。
days:必需的。在 date 上减去的天数。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
SUBDATE函数的第二种语法,也是DATE_SUB 和 SUBDATE函数共有的语法:
DATE_SUB/SUBDATE(date, INTERVAL expr type)
INTERVAL :必须的,标志着时间间隔数据类型的开始。照抄就行。
expr:必需的。时间/日期间隔。正数和负数都是允许的。
type:必需的。时间/日期间隔的单位。可以是以下值中的一个:
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
SECOND_MICROSECOND
MINUTE_MICROSECOND
MINUTE_SECOND
HOUR_MICROSECOND
HOUR_SECOND
HOUR_MINUTE
DAY_MICROSECOND
DAY_SECOND
DAY_MINUTE
DAY_HOUR
YEAR_MONTH
 ---------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------------------

1.4.7 DATEDIFF函数:返回两日期间隔的天数
DATEDIFF函数,求两日期间隔天数。
DATEDIFF(enddate,startdate)
日期大的enddate放在前面,日期小的startdate放在后面。
返回enddate减去startdate后的天数:
enddate>startdate,为正数;
enddate<startdate,为负数。
不能再加其它参数,该函数就只能返回间隔的天数。
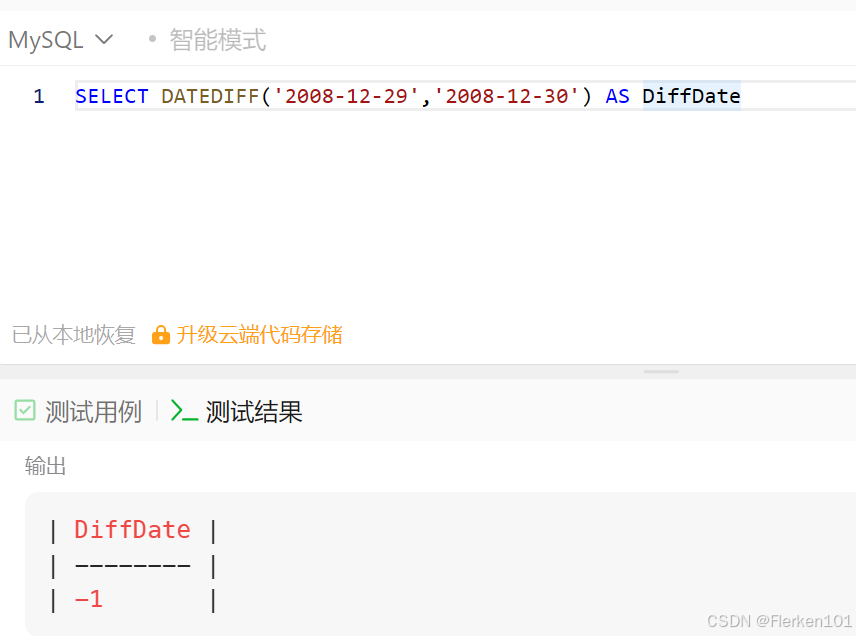
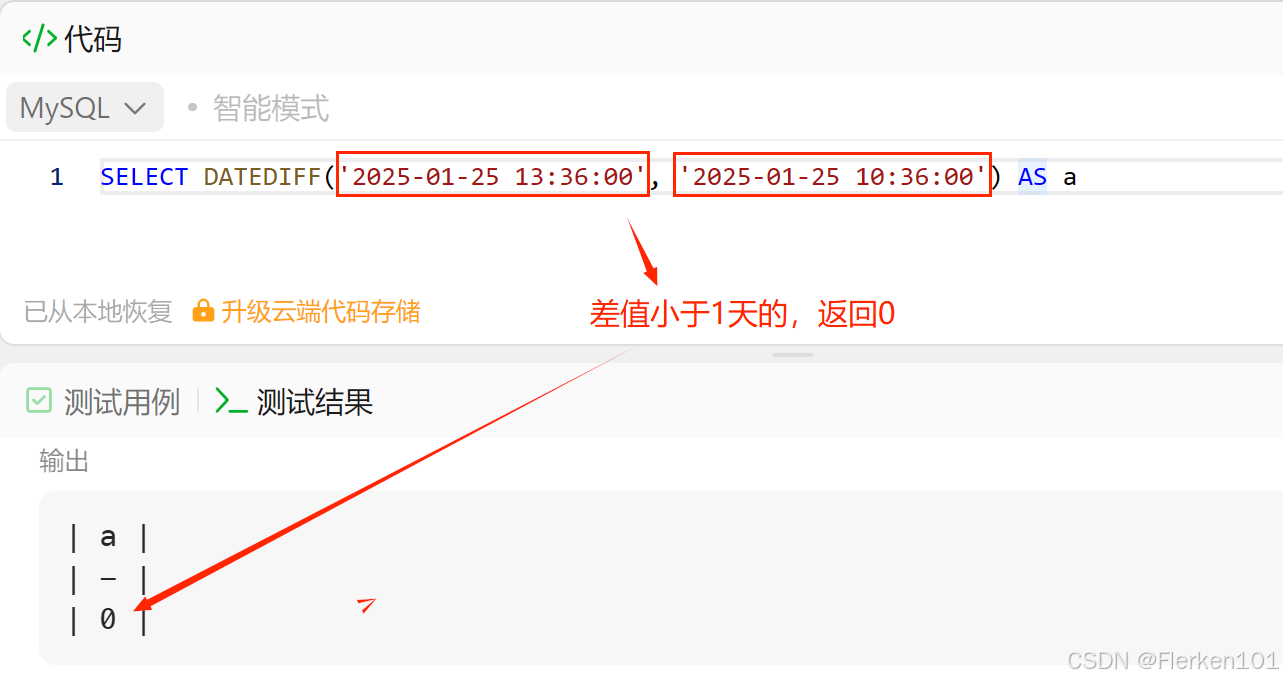
但DATEDIFF函数,不能定位到小时、分钟和秒。
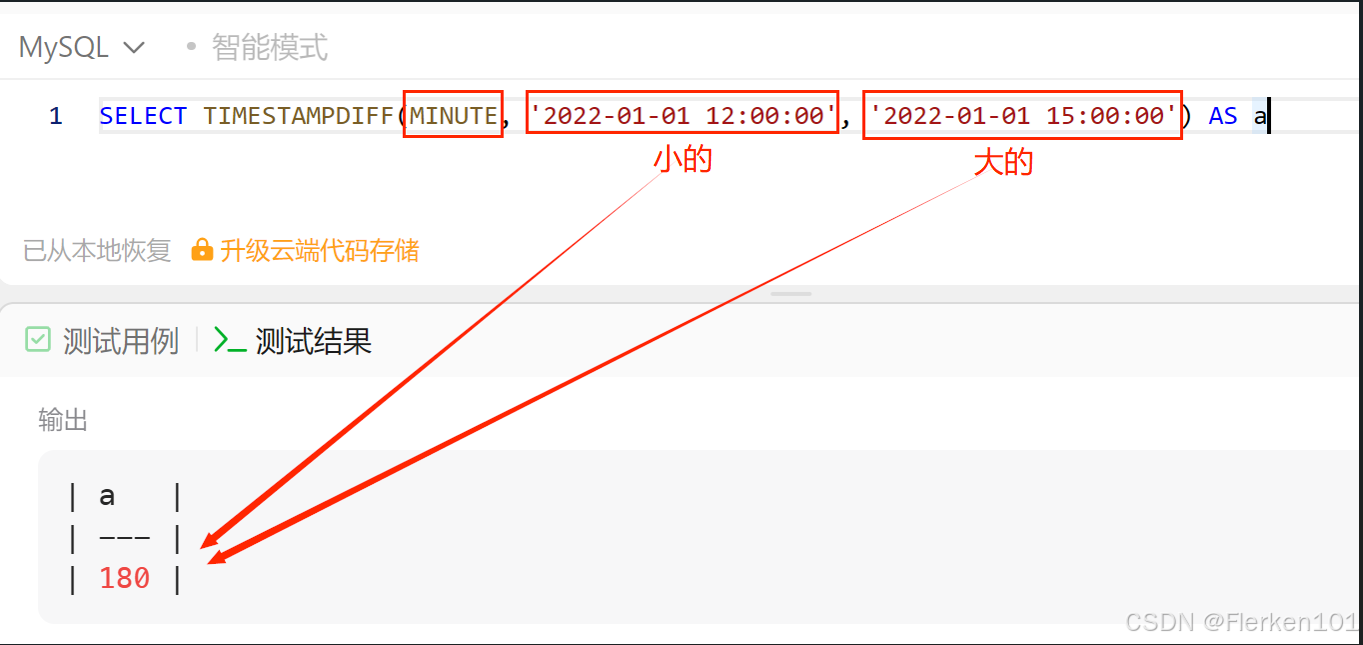
1.4.8 TIMESTAMPDIFF函数:返回两日期间隔的天数、小时数、分钟数、秒数
MySQL的时间差函数TIMESTAMPDIFF、DATEDIFF的用法——laowang2915
TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND),使用起来比datediff函数更加灵活。
而且与DATEDIFF函数另一个不同之一在于:
对于比较的两个时间参数,时间小的放在前面,时间大的放在后面。
1.4.9 FROM_UNIXTIME函数:把整数型INT时间戳转化为可读形式的时间戳TIMESTAMP
TIMESTAMP本身是一种字符形式保存的,时间戳数据类型。
mysql中timestamp(0)中的0是什么意思——不知何许人也

一般使用整数类型int(11)时间戳来保存时间,方便查询时提高效率。
但这样有个缺点,显示的时间戳,很难知道真实日期时间。
INT(1)的意思表示字段值范围在[-2147483648,2147483647](即[-2³¹, 2³¹-1]之间)。
int(1)、int(4)、int(11)和int(110)表示意思是一样的。
navicat设置MySQL字段类型的长度解释说明——斗破大陆wawa
惭愧!直到今天才真正明白为什么int型的取值范围是-231~231-1——Marsview低代码平台
mysql 时间戳格式化函数from_unixtime使用说明——傲雪星枫
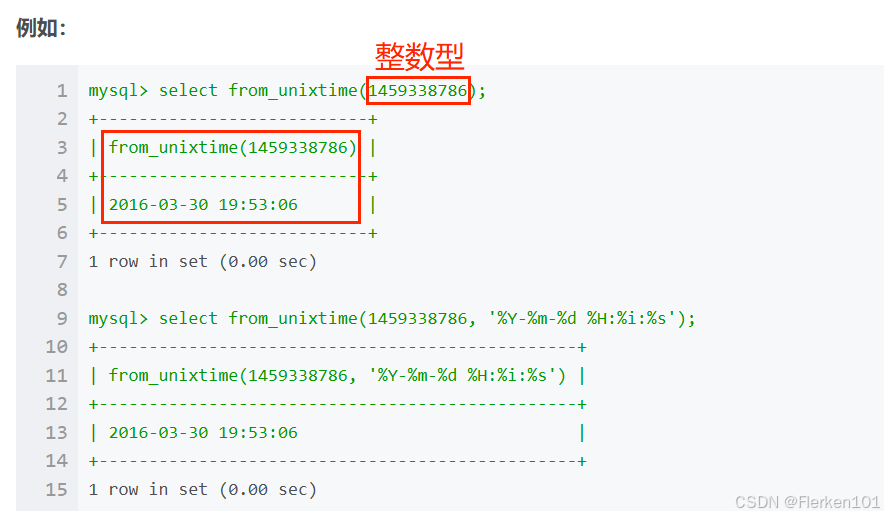
from_unxitime语法说明:
from_unixtime(unix_timestamp, format)
其中unix_timestamp为整数型,被称为Unix 时间戳。
Unix 时间戳是指自1970年1月1日 00:00:00 GMT 以来经过的秒数。
from_unixtime函数会根据format格式化,返回unix_timestamp代表的人类可读的时间戳,类型为TIMESTAMP.
如果format为空默认会使用 %Y-%m-%d %H:%i:%s 的格式。
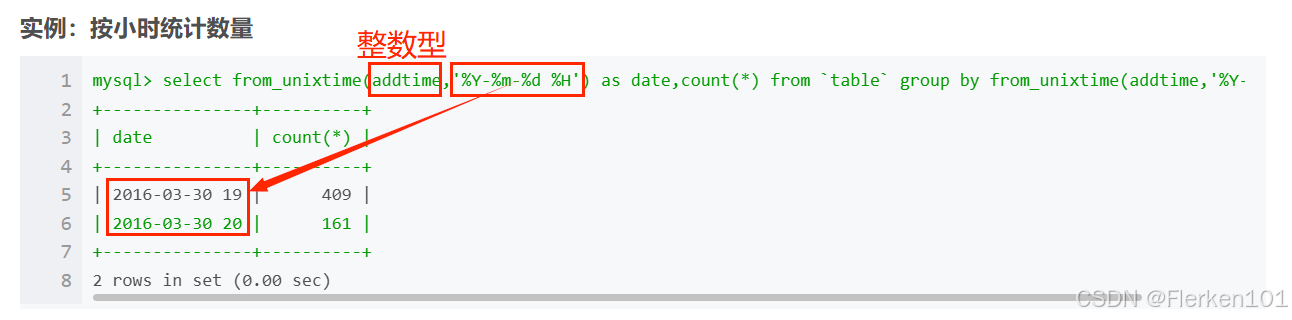
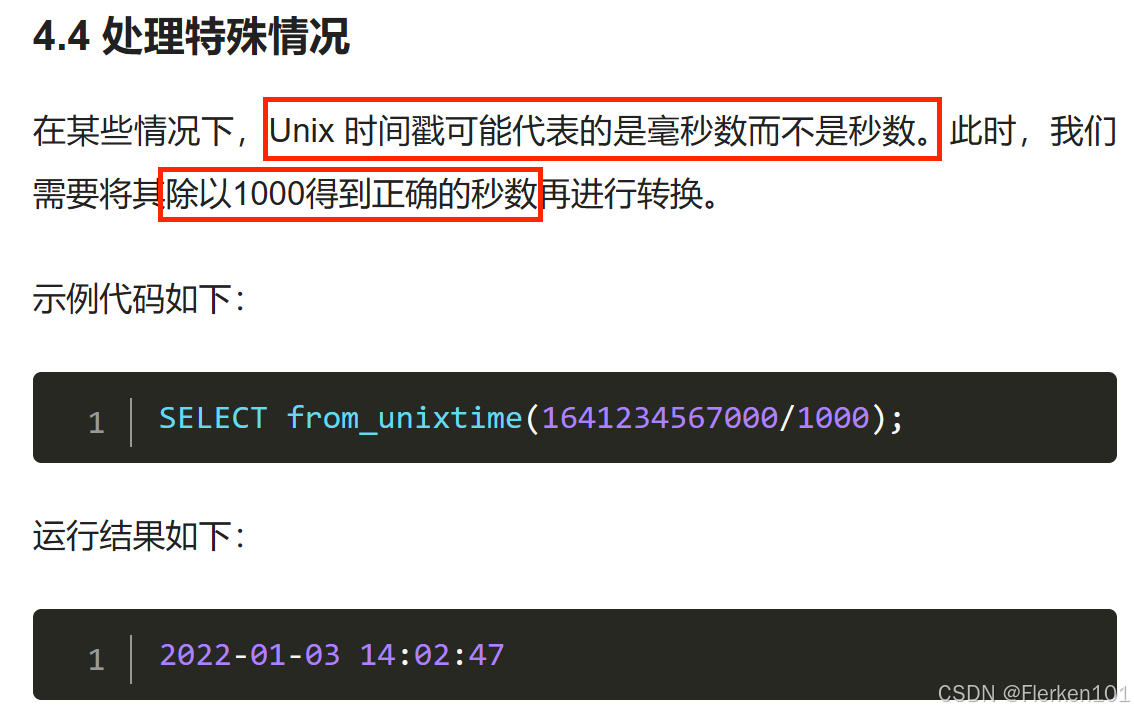
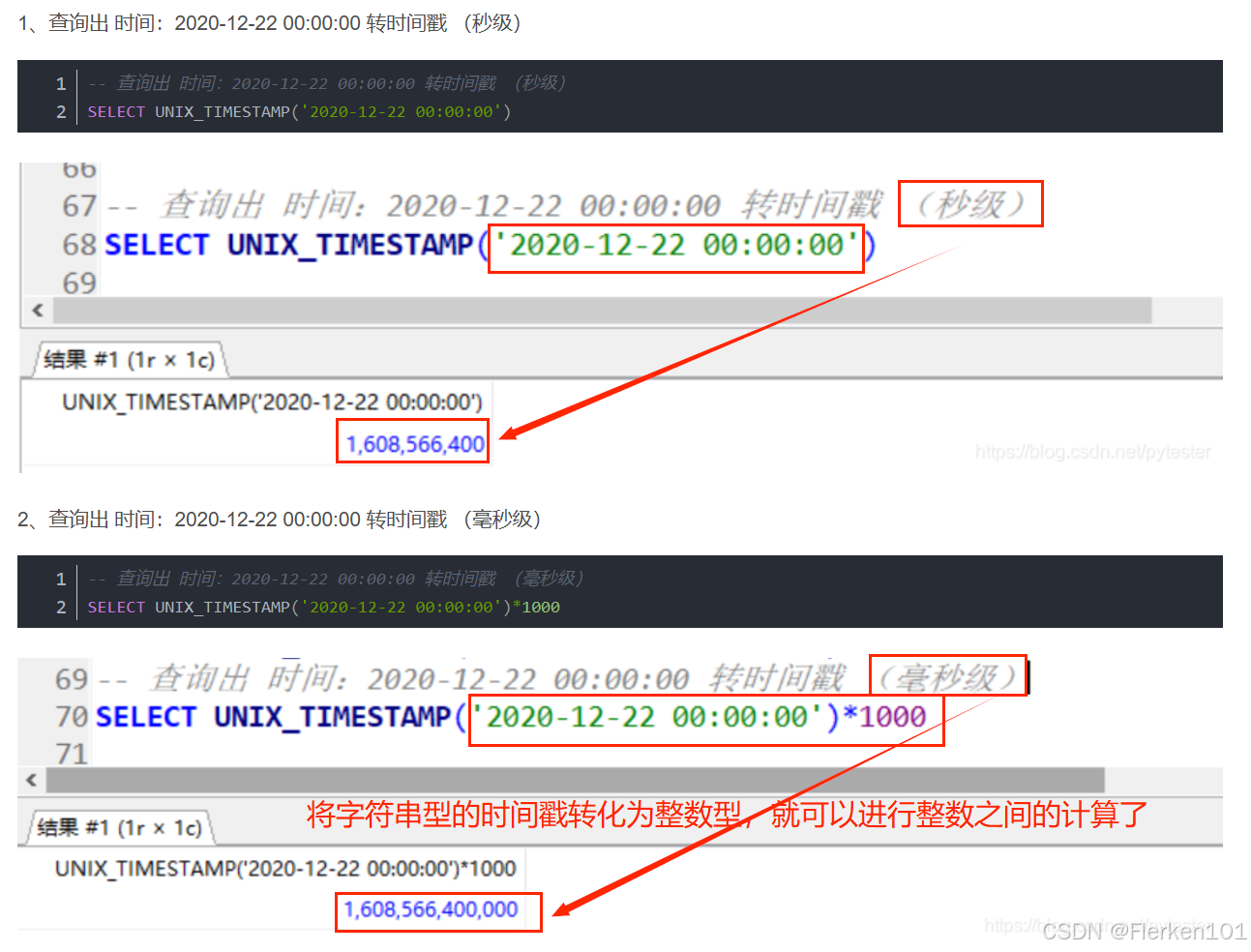
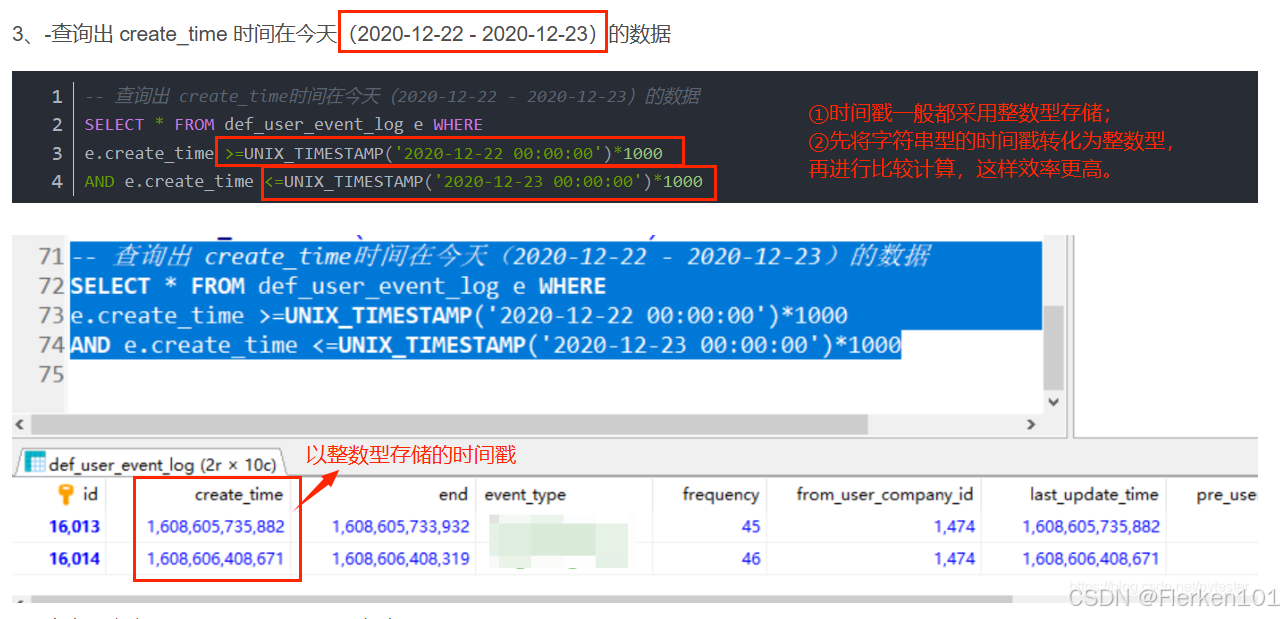
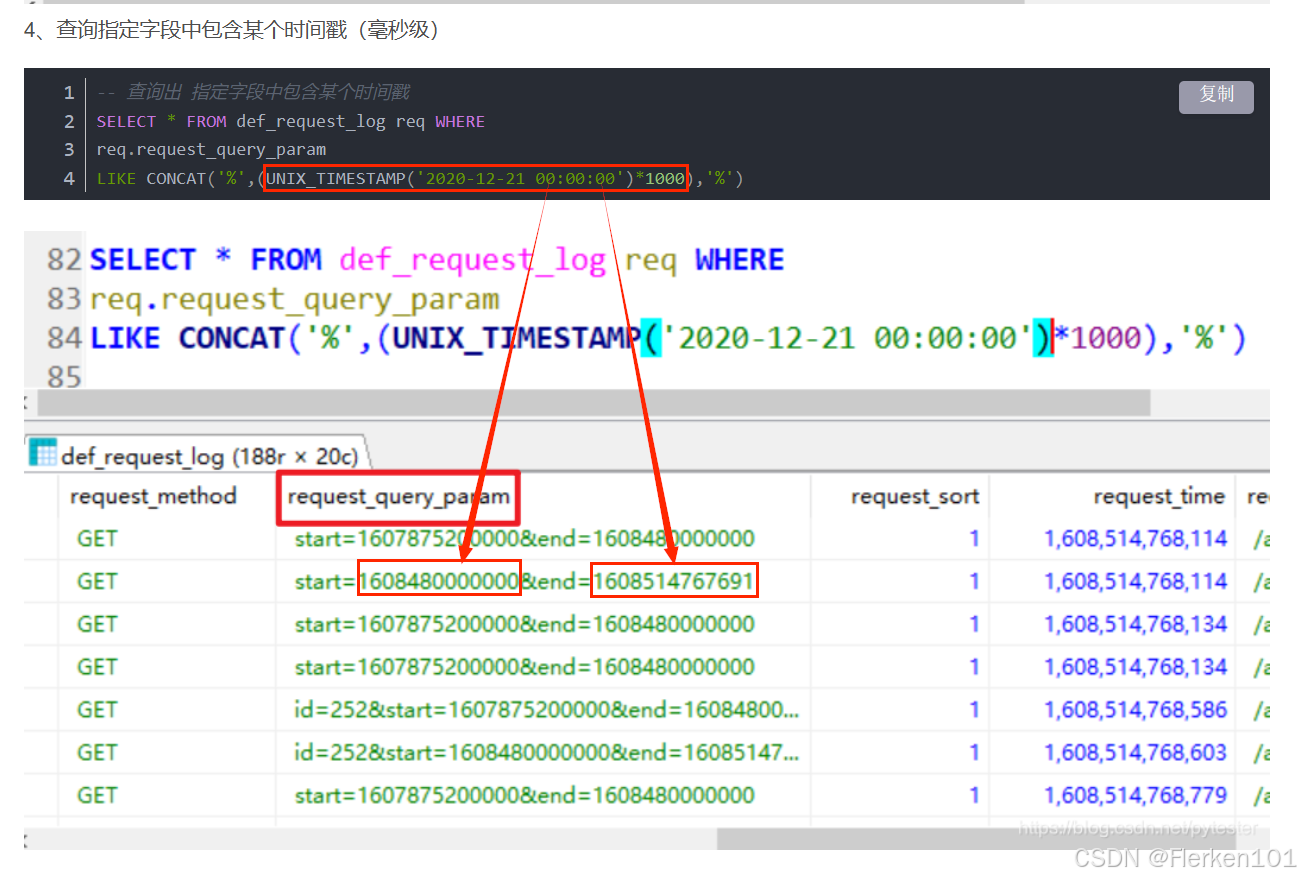
1.4.10 UNIX_TIMESTAMP函数:把可读形式的时间戳TIMESTAMP、字符串类型VARCHAR的时间戳转化为整数型INT时间戳
MySQL中的 UNIX_TIMESTAMP 函数使用总结(附详例)——pytester
在平时计算过程中,一般使用整数型的时间戳,这样可以提高计算效率。
基本语法:
UNIX_TIMESTAMP([date])
date可以是可读形式的TIMESTAMP类型的时间戳,也可以是 满足yyyy-MM-dd HH:mm:ss 或 yyyy-MM-dd 形式的字符串类型时间戳(VARCHAR类型)。
UNIX_TIMESTAMP函数将返回一个表示该日期或时间的UNIX时间戳(整数型时间戳)。
如果未提供参数,则默认返回当前日期和时间的UNIX时间戳。
1.5 转换函数(用来转换数据类型和值的函数)
1.5.1 CAST函数:类型转换
更改已经存在的字段的数据类型,要使用ALTER语句。
# 语法
CAST(转换前的值 AS 想要转换的数据类型)
MySQL 字符串 转 int/double CAST与CONVERT 函数的用法——修行者 坚守者
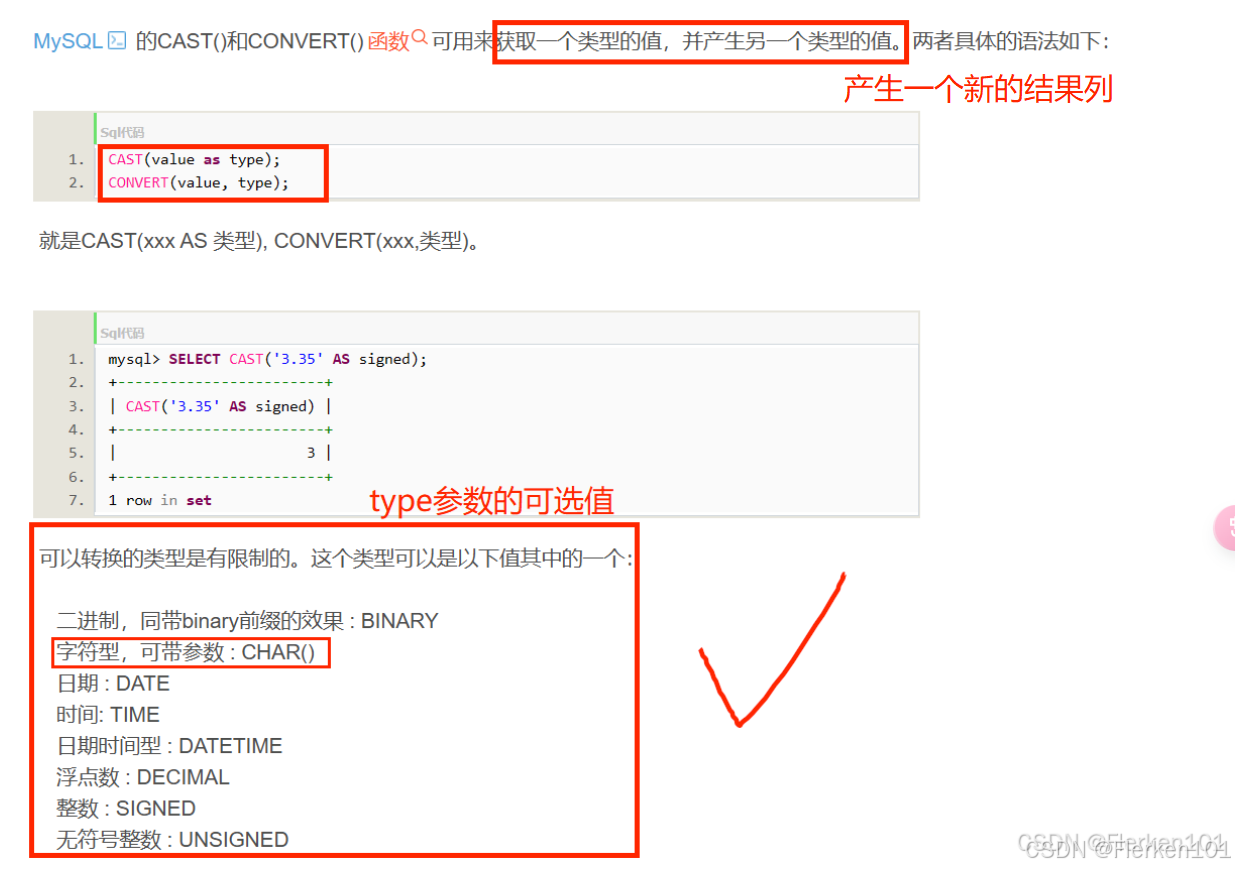
提前进行数据类型转换的原因:
(1)可能会插入与表中数据类型不匹配的数据;
(2)在进行运算时由于数据类型不一致发生了错误;
(3)进行自动类型转换会造成处理速度低下。
类型转换其实并不是为了方便用户使用而开发的功能,而是为了方便DBMS内部处理而开发的功能。
# 在Oracle中
-- (1)将字符串类型转换为数值类型
SELECT CAST('0001' AS INTEGER) AS int_col FROM DUAL;
--(2)将数值类型转换为字符串类型(转换为字符串类型时,要表明最大长度。)
SELECT CAST(1 AS VARCHAR2(4)) AS int_col FROM DUAL;
'''
TO_DATE函数即可以使用'2009-12-14'的日期形式,也可以使用'14-12月-09'/'14-12月-2009'的日期形式;
TO_TIMESTAMP函数仅能使用'2009-12-14'的日期形式;
CAST函数仅能使用'14-12月-09'/'14-12月-2009'的日期形式。'''
-- (3)将字符串类型转换为日期类型
-- CAST函数:转换前的字符串中不能包含时间,转换后的DATE类型中包含时间且置为00:00:00
SELECT CAST('14-12月-2009' AS DATE) AS date_col FROM DUAL; ---->2009-12-14 00:00:00
SELECT CAST('14-12月-09' AS DATE) AS date_col FROM DUAL; ---->2009-12-14 00:00:00
--当月份为各位数时,前面不用加0
SELECT CAST('1-1月-0001' AS DATE) AS date_col FROM DUAL; ---->0001-01-01 00:00:00
SELECT CAST('14-9月-2009' AS DATE) AS date_col FROM DUAL; ---->2009-09-14 00:00:00
# 等价于:使用TO_DATE函数时,且不包含时间
SELECT TO_DATE('14-12月-2009', 'dd-mon-yy') FROM dual; ----->2009-12-14 00:00:00
SELECT TO_DATE('14-12月-09', 'dd-mon-yy') FROM dual; ----->2009-12-14 00:00:00
# 也可在使用TO_DATE函数时,包含时间【注意与下面的秒的区别】
SELECT TO_DATE('2009-12-14 10:30:00', 'YYYY-MM-DD HH24:MI:SS') AS converted_date FROM dual; ----->2009-12-14 10:30:00
-- (4)将字符串类型转换为日期+时间(时间戳)类型
''' CAST函数:转换前的字符串中包不包含时间均可,转换后的TIMESTAMP类型一定包含。
若转换前的字符串中包含时间,转换后的TIMESTAMP类型中的时间,即为输入值;
若转换前的字符串中不包含时间,转换后的TIMESTAMP类型中的时间,即为00:00:00.000000'''
SELECT CAST('14-12月-2009 10:30:00' AS TIMESTAMP) AS converted_timestamp FROM dual; ----->2009-12-14 10:30:00.000000
SELECT CAST('14-12月-09' AS TIMESTAMP) AS converted_timestamp FROM dual; ----->2009-12-14 00:00:00.000000
【注意:
SELECT CAST('14-12月-2009' AS TIMESTAMP) AS converted_timestamp FROM dual;
-----> 2020-12-14 09:00:00.000000
在原字符串中不包含时间又要转化为TIMESTAMP类型时,结果年份不正确了,所以尽量用上面两种方式。】
# 等价于:使用TO_TIMESTAMP函数
SELECT TO_TIMESTAMP('2009-12-14 10:30:00', 'YYYY-MM-DD HH24:MI:SS') AS Tstamp FROM dual; ----->2009-12-14 10:30:00.000000000
SELECT TO_TIMESTAMP('2009-12-14', 'YYYY-MM-DD') AS Tstamp FROM dual; ----->2009-12-14 00:00:00.000000000
1.5.2 COALESCE函数:将NULL转换为其他值
COALESCE函数会返回可变参数中左侧开始第1个不是NULL的值。
参数个数是可变的,因此可以根据需要无限增加。
但是它们的数据类型都必须相同。
COALESCE(数据1,数据2,数据3……)
运算或者函数中含有 NULL时,结果全都会变为 NULL。
能够避免这种结果的函数就是COALESCE。
Oracle中coalesce函数的用法——百度文库
条件函数(CASE、COALESCE、NULLIF、NVL、NVL2、GREATEST、LEAST)—— 阿里云
SELECT
COALESCE( NULL, 1 ) AS col_1,
COALESCE( NULL, 'test', NULL ) AS col_2,
COALESCE( NULL, NULL, '2009-11-01' ) AS col_3
FROM DUAL;

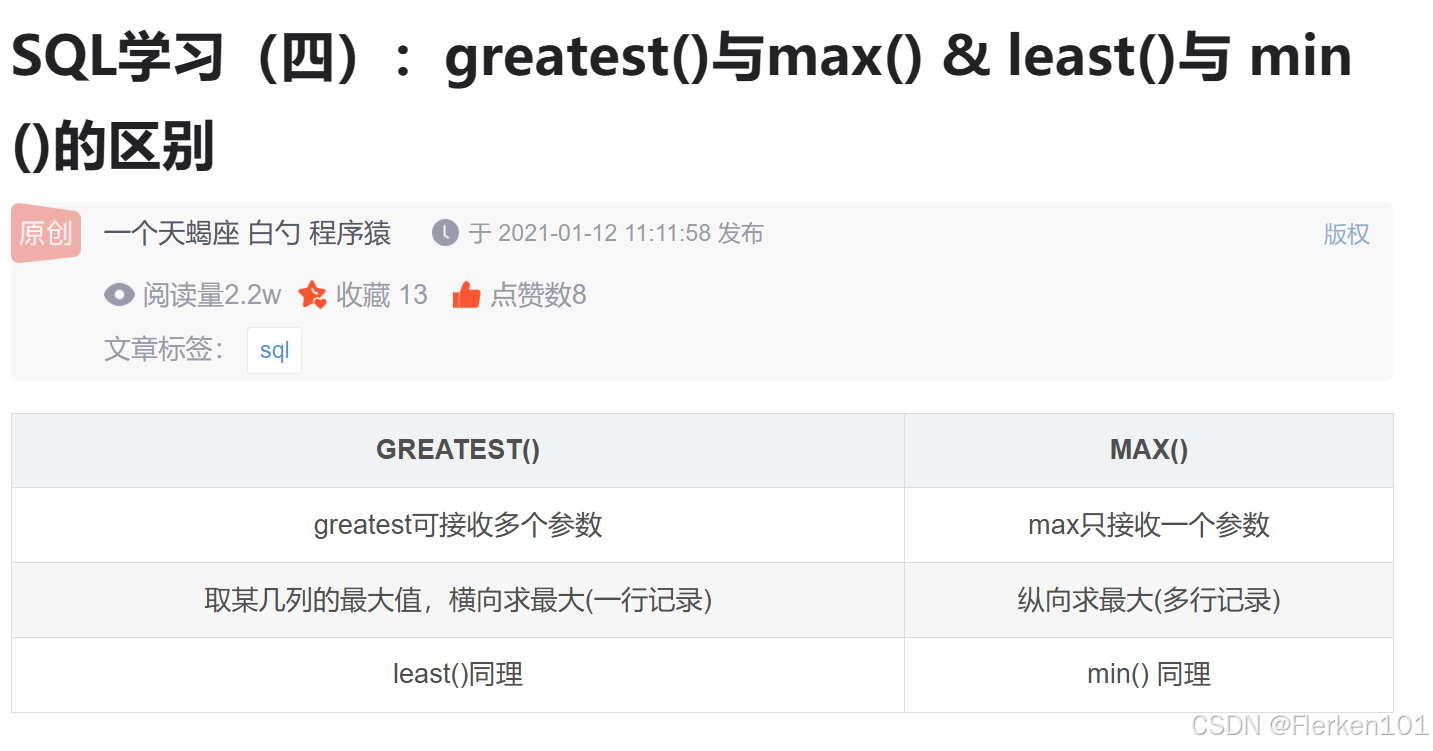
1.5.3 LEAST 和 GREATEST函数
LEAST返回逗号分隔的一系列表达式中的最小值。
GREATEST返回逗号分隔的一系列表达式中的最大值。
至少需要 2 个参数。
若任一参数为 NULL,LEAST 和 GREATEST 函数会返回 NULL。
有时需要额外处理 NULL 值(例如使用 COALESCE)以避免 NULL 影响结果。
SQL学习(四):greatest()与max() & least()与 min()的区别——一个天蝎座 白勺 程序猿

SELECT LEAST(from_id, to_id) AS person1,
GREATEST(from_id, to_id) AS person2,
COUNT(*) AS call_count,
SUM(duration) AS total_duration
FROM Calls
GROUP BY LEAST(from_id, to_id), GREATEST(from_id, to_id)
-- 直接修改原表,生成一个新表
SELECT a.person1, a.person2, COUNT(*) AS call_count, SUM(duration) AS total_duration
FROM (SELECT CASE
WHEN from_id < to_id THEN from_id
WHEN from_id > to_id THEN to_id
END AS person1,
CASE
WHEN from_id < to_id THEN to_id
WHEN from_id > to_id THEN from_id
END AS person2,
duration
FROM Calls) a
GROUP BY a.person1, a.person2
2. 谓词
谓词也是函数中的一种。
谓词的返回值全都是真值(TRUE/ FALSE/UNKNOWN)。
【通常的其它函数返回值可能是数字、字符串或者日期等。就不能称作“谓词”。】
常见的谓词有:
● 所有的比较运算符(=、<> 、>=、<=、>、<)
● 所有的逻辑运算符(NOT、AND、OR)
● LIKE
● BETWEEN
● IS NULL、IS NOT NULL
● IN、NOT IN
● EXISTS、NOT EXISTS
2.1 LIKE谓词:字符串的部分一致查询
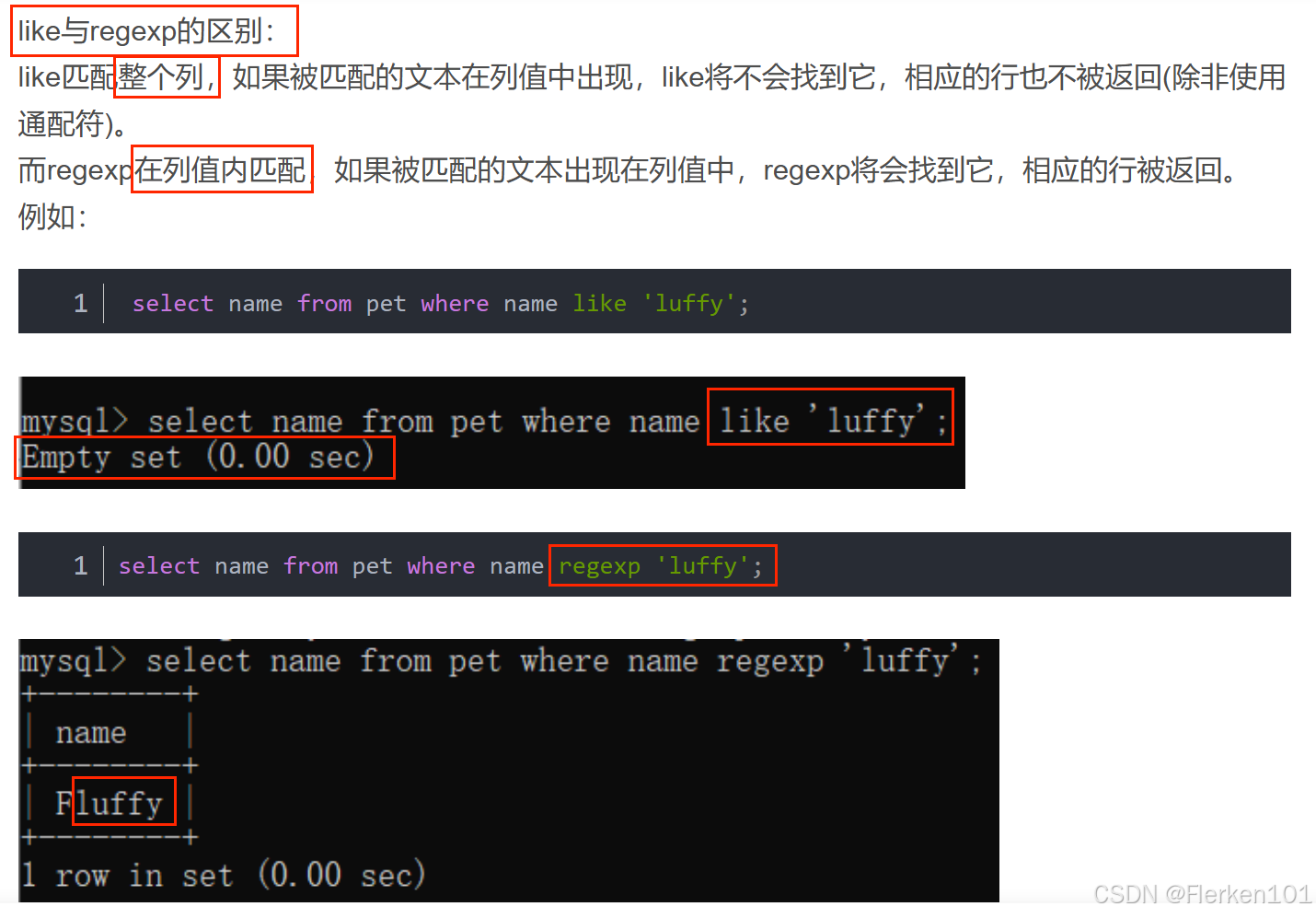
<字段名> LIKE '<查询条件字符串及其规则(模式)>'
区别比较运算符=:
使用字符串作为查询条件时,如果使用的是比较运算符=,
即: 查询对象字符串 = 查询条件字符串 ,这种形式,
那么只有在查询条件与查询对象字符串完全/全部一致时比较运算才为真。
模式匹配:
不使用 “=” 来指定查询条件字符串,而以查询对象字符串中是否包含某一条件的规则为基础的查询称为模式匹配。
模式:
其中的模式也就是指 查询条件字符串 中包含的规则。
当进行 查询条件与查询对象 字符串的 部分一致查询时,需要使用LIKE谓词。
正则表达式是另一种更复杂,但比LIKE谓词应用更广泛的“部分一致查询”模式匹配方法。
SQL中常用的通配符有两个 “%” 和 “_”
% 代表 “0个字符以上(≥1个字符)的任意字符串” 的特殊符号(不强调包含的字符个数也不强调字符串中的内容)。
_(下划线)代表了 “任意1个字符” (强调字符个数,内容不限)。
EXCEL中 “?” 和 “*” 两个通配符的用法: =VLOOKUP("?"&H3&"?"客户信息表!B:E,4,0) =VLOOKUP("*"&H3&"*"客户信息表!B:E,4,0)

部分一致大体可以分为前方一致、中间一致和后方一致三种类型。
(1)前方一致查询
选取出作为查询条件的字符串(假如是“ddd”、“abc”)与查询对象字符串起始部分相同的记录的查询方法。
# 选取出 strcol列的值为以ddd开头的 记录
SELECT *
FROM SampleLike
WHERE strcol LIKE 'ddd%';
# 选取出 strcol列的值为 “abc + 任意1个字符”的记录
SELECT *
FROM SampleLike
WHERE strcol LIKE 'abc_'; -- 后面只能有1个字符,内容不限
(2)中间一致查询
选取出查询对象字符串中含有作为查询条件的字符串(“ddd、abc”)的记录的查询方法。
无论 该查询条件的字符串 出现在 查询对象字符串 的最后还是中间都没有关系。
因此要在字符串的起始和结束位置都加上% 或 _
查询条件最宽松,也就是能够取得最多记录的是中间一致查询。
因为它同时包含前方一致和后方一致的查询结果。
# 选取出 strcol列的值中包含ddd的 记录
SELECT *
FROM SampleLike
WHERE strcol LIKE '%ddd%';
# 选取出 strcol列的值为 “任意1个字符 + abc + 任意1个字符” 的记录
SELECT *
FROM SampleLike
WHERE strcol LIKE '_abc_'; -- 前、后都只能有1个字符,内容不限
(3)后方一致查询
选取出作为查询条件的字符串(“ddd、abc”)与查询对象字符串的末尾部分相同的记录的查询方法。
# 选取出 strcol列的值为以ddd结尾的 记录
SELECT *
FROM SampleLike
WHERE strcol LIKE '%ddd';
# 选取出 strcol列的值为 “任意1个字符 + abc”的记录
SELECT *
FROM SampleLike
WHERE strcol LIKE '_abc'; -- 前面只能有1个字符,内容不限
2.2 BETWEEN谓词:范围查询
使用3个参数。
# 选取出字段值处在 [下限, 上限] 范围中的记录
(WHERE) <字段名> BETWEEN <下限> AND <上限>
BETWEEN的结果中会包含上、下限这两个临界值。
如果不想让结果中包含临界值,那就必须使用<和>.
# 选取出字段值处在 (下限, 上限) / [下限+1, 上限-1] 范围中的记录
(WHERE) <字段名> > <下限>
AND <字段名> < <上限>
2.3 IS NULL、IS NOT NULL谓词:判断是否为NULL
选取出字段值为NULL的列的数据,不能使用=,只能使用特定的谓词IS NULL.
(WHERE) <字段名> IS NULL
选取字段为NULL以外的数据时,需要使用IS NOT NULL.
(WHERE) <字段名> IS NOT NULL
2.4 IN、NOT IN谓词
# 指定多个字段值(相当于=和OR的结合)
# 选取出字段值为: 值1 或 值2 或 值3...的记录
(WHERE) <字段名> IN(值1, 值2, 值3, ……)
# 排除多个字段值(相当于<>和AND的结合)
# 选取出字段值不为值1, 且不为值2, 且不为值3...的记录
NOT IN(值1, 值2, 值3, ……)
在使用IN和NOT IN时是无法选取出NULL数据的。
即:即使 IN(值1, 值2, 值3, ……)中包含NULL
NOT IN(值1, 值2, 值3, ……) 中不包含NULL
也都取不出该字段值为NULL的记录。
2.4.1 使用普通SELECT查询、子查询、视图作为IN谓词的参数
普通SELECT查询、子查询和视图,都可以看成是SQL内部生成的表。
“能够将表作为IN的参数”。
“能够将普通SELECT查询作为IN的参数”。
“能够将视图作为IN的参数”。
“能够将子查询作为IN的参数”。(普通子查询、标量子查询、关联子查询)
仍然是按照先内层查询,后外层查询的顺序来执行的。
# 例子:使用普通SELECT查询作为IN的参数
# 选取在000C号店铺销售的商品(product_id)的商品名称(product_name)和销售单价(sale_price)
SELECT product_name, sale_price
FROM Product
WHERE product_id IN (SELECT product_id
FROM ShopProduct
WHERE shop_id = '000C');
# 以上例子等价于如下:使用关联子查询作为IN的参数
-- 关联子查询执行时,是按每条记录进行的。
SELECT product_name, sale_price
FROM Product P
WHERE product_id IN (SELECT product_id -- 只能有一个字段,且与IN前面的字段相对应
FROM ShopProduct SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
# 还等价于2.5.1中使用关联子查询作为EXISTS谓词的参数
# 且一般将 关联子查询和EXISTS及NOT EXISTS谓词 搭配使用
2.4.2 使用普通SELECT查询、子查询、视图作为NOT IN谓词的参数
仍然是按照先内层查询,后外层查询的顺序来执行的。
# 例子:使用普通SELECT查询作为NOT IN的参数
# 选取在000C号店铺以外销售的商品(product_id)的商品名称(product_name)和销售单价(sale_price)
SELECT product_name, sale_price
FROM Product
WHERE product_id NOT IN (SELECT product_id
FROM ShopProduct
WHERE shop_id = '000C');
# 以上例子等价于如下:使用关联子查询作为NOT IN的参数
-- 关联子查询执行时,是按每条记录进行的。
SELECT product_name, sale_price
FROM Product P
WHERE product_id NOT IN (SELECT product_id -- 只能有一个字段,且与IN前面的字段相对应
FROM ShopProduct SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
# 还等价于2.5.2中使用关联子查询作为NOT EXISTS谓词的参数
# 且一般将 关联子查询和EXISTS及NOT EXISTS谓词 搭配使用
!!!SQL中最危险的陷阱:(属于中级学习的范畴。)
NOT IN的参数中包含NULL时结果通常会为空,也就是无法选取出任何记录。因此,在指定值的情况下,NOT IN的参数中不能包含 NULL;
在使用普通SELECT查询、子查询、视图作为NOT IN的参数时,它们的返回值也不能是NULL.
2.5 EXISTS、NOT EXISTS谓词
【一般使用复数 EXISTS 和 NOT EXISTS. 在Oracle中就没有 EXIST 和 NOT EXIST 这两个关键字。 】
2.5.1 使用关联子查询作为EXISTS谓词的参数
EXISTS谓词的作用就是“判断是否存在满足某种条件的记录”。
如果存在这样的记录就返回真(TRUE),如果不存在就返回假(FALSE)。
EXISTS通常都会使用关联子查询作为参数。
EXISTS只关心记录是否存在,因此返回哪些列都没有关系。
所以其参数关联子查询中,一般写成SELECT *
而且要把在EXISTS的子查询参数中书写 SELECT * 当作书写SQL的一种习惯。
# 例子:使用关联子查询作为 EXISTS 的参数
# 选取在000C号店铺销售的商品(product_id)的商品名称(product_name)和销售单价(sale_price)
-- 关联子查询执行时,是按每条记录进行的。
SELECT product_name, sale_price
FROM Product P
WHERE EXISTS (SELECT * --可以是几个列、全部列*、常数。一般写全部列*
FROM ShopProduct SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
# 等价于2.4.1中使用普通SELECT查询、关联子查询作为IN的参数的两种书写方式
# 但一般使用这种,将 关联子查询和EXISTS及NOT EXISTS谓词 搭配使用
2.5.2 使用关联子查询作为NOT EXISTS谓词的参数
NOT EXISTS与EXISTS相反,当 “不存在” 满足关联子查询中指定条件的记录时返回真(TRUE)。
# 例子:使用关联子查询作为 NOT EXISTS 的参数
# 选取在000C号店铺以外销售的商品(product_id)的商品名称(product_name)和销售单价(sale_price)
-- 关联子查询执行时,是按每条记录进行的。
SELECT product_name, sale_price
FROM Product P
WHERE NOT EXISTS (SELECT * --可以是几个列、全部列*、常数。一般写全部列*
FROM ShopProduct SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
# 等价于2.4.2中使用普通SELECT查询、关联子查询作为NOT IN的参数的两种书写方式
# 但一般使用这种,将 关联子查询和EXISTS及NOT EXISTS谓词 搭配使用
严格来说EXISTS和NOT EXISTS 与 IN和NOT IN并不相同。
EXISTS和NOT EXISTS 拥有 IN和NOT IN 所不具有的便利性,
但没有必要勉强使用 EXISTS和NOT EXISTS 来替代IN和NOT IN .
2.6 ALL谓词
ALL 谓词用于将一个值与子查询返回的所有值进行比较。
只有当该值与子查询返回的每一个值,都满足比较条件时,才会返回 TRUE。
它通常与 比较运算符(如 >, <, >=, <=, != 等) 一起使用。

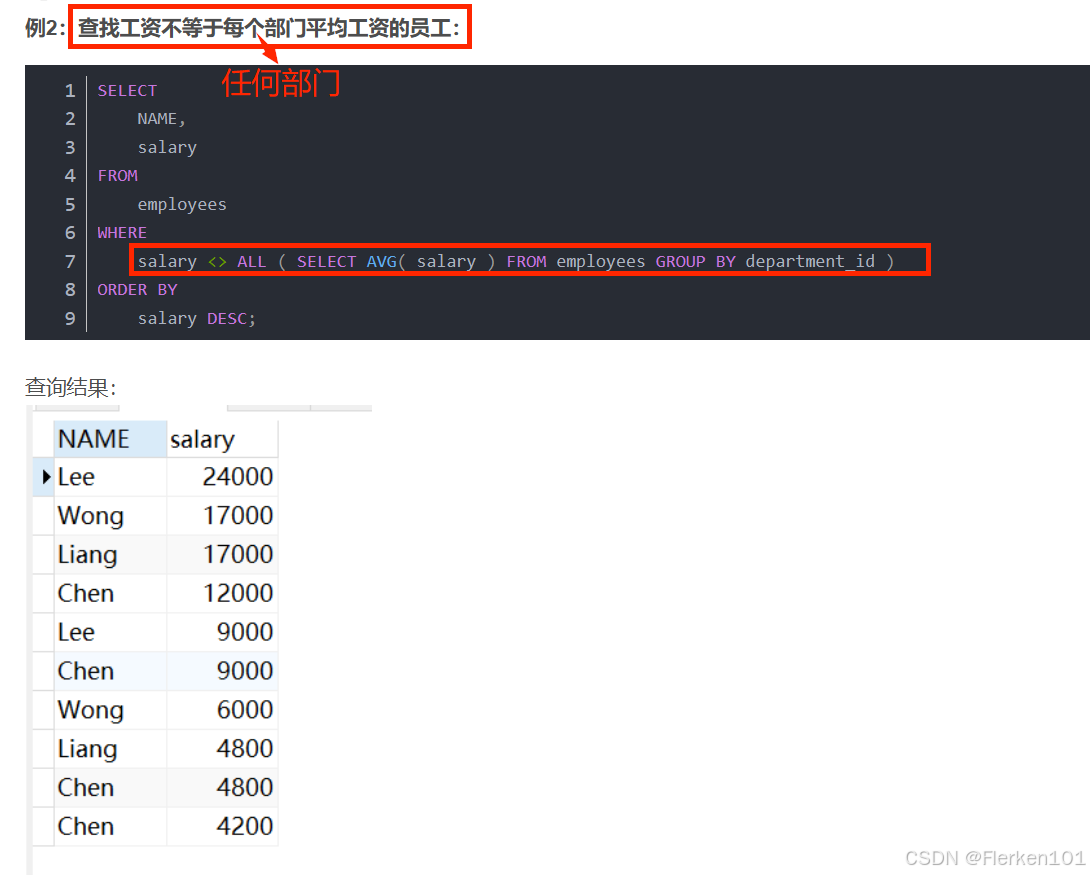
2.7 ANY谓词
ANY 谓词会把一个值和子查询返回的一组值进行比较。
只要该值与子查询返回的任意一个值,满足比较条件,就会返回 TRUE。
它一般和 比较运算符(像 >, <, >=, <=, != 等) 一起使用。
IN 谓词用于判断一个值是否在一组指定的值或者子查询返回的值集合中。
如果该值存在于集合中,则返回 TRUE;否则返回 FALSE。
【 与ANY谓词相比,IN谓词仅仅相当于 ANY与比较运算符 = 一起使用的情况。
即:expression = ANY (subquery) 这种形式和 expression IN (subquery) 是等价的。】

3. CASE表达式
无论是简单CASE表达式,还是搜索CASE表达式:
其返回的 ①THEN 和 ②ELSE 子句后面的 <表达式> ,数据类型都必须是一致的;
如果提前设置了CASE表达式③所在列的数据类型,那么①②还要跟③该字段所规定的数据类型保持一致;
①②③中,凡是不一致的要进行转化。
3.1 简单CASE表达式
类似C语言中的SWITCH函数。
-- 语法:其中的每个<表达式>都可以是字段、常数、计算表达式中的任意一种。
CASE <表达式ʘ>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
...
ELSE <表达式> --可省略,会被默认为ELSE NULL
END --END不能忘记!需要时还可在后面加“AS 列别名”
-- 一般是将整个CASE表达式括起来,设置一个别名,作为一列输出。根据需求定。
--例如:
case sex
when '1' then '男'
when '2' then '女’
else '其他'
end AS "性别"
其中的每个<表达式>,都可以是字段、常数或计算表达式中的任意一种。
可能不需要进行计算,即为字段或常数;
为计算表达式时,需要进行计算,其返回值可能是数字、字符串或者日期等等。
3.1.1 简单CASE表达式的执行过程
(1)当 “CASE <表达式ʘ> ” 中的 “<表达式ʘ>” 为计算表达式时,对其进行求值。
当其为字段或常数时,直接进行第二步。
(2)如果<表达式ʘ>的值 与 WHEN子句中<表达式>的值 相等(这里默认有一个使用谓词=进行的比较运算),那么就返回其后THEN子句中的表达式,CASE表达式的执行到此为止。
(3)如果<表达式ʘ>的值 与 WHEN子句中<表达式>的值 不相等,那么就比较<表达式ʘ>与下一条WHEN子句的<表达式> 的值。
并重复(2)、(3).
(4)如果直到最后<表达式ʘ>的值 都与 WHEN子句中<表达式>的值 不相等,那么就返回ELSE中的表达式,CASE表达式执行终止。
ELSE子句也可以省略不写,这时会默认为ELSE NULL。
总之,CASE表达式最终只会返回一个值。
且CASE表达式最后的“END”是不能省略的。
3.2 搜索CASE表达式
与简单CASE表达式相比,优点: 可在WHEN子句中指定不同列。
CASE
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
...
ELSE <表达式> --可省略,会被默认为ELSE NULL
END --END不能忘记!需要时还可在后面加“AS 列别名”
-- 一般是将整个CASE表达式括起来,设置一个别名,作为一列输出。根据需求定。
--例如:
case when sex = '1' then '男'
when sex = '2' then '女'
else '其他'
end AS "性别"
3.2.1 搜索CASE表达式的执行过程
WHEN子句中的<求值表达式> ,特别强调了“求值”,更准确的,其实应该写为 “求真值”。
因为这里的<求值表达式>特指:使用谓词编写出来的表达式,返回值只会为真值(TRUE/FALSE/UNKNOWN)。
其它没有加“求值”的<表达式> ,都可以是字段、常数或计算表达式中的任意一种。
可能不需要进行计算,即为字段或常数;
为计算表达式时,需要进行计算,其返回值可能是数字、字符串或者日期等等。
搜索CASE表达式的执行过程:
(1)对第一个WHEN子句中的“< 求值表达式 >”进行求真值。
所谓求真值,就是要调查该表达式的真值是什么。
(2)如果WHEN子句结果的为真(TRUE),那么就返回其后THEN子句中的表达式,CASE表达式的执行到此为止。
(3)如果WHEN子句的结果不为真,那么就跳转到下一条WHEN子句的求真值之中。
并重复(2)、(3).
(4)如果直到最后的WHEN子句为止,返回结果都不为真,那么就返回ELSE中的表达式,CASE表达式执行终止。
ELSE子句也可以省略不写,这时会默认为ELSE NULL。
总之,CASE表达式最终只会返回一个值。
且CASE表达式最后的“END”是不能省略的。
3.2.2 搜索CASE表达式的书写位置
CASE表达式同其它表达式一样,可以书写在任意位置。
在对SELECT 语句的结果进行编辑时,CASE 表达式能够发挥较大作用。
使用搜索CASE条件表达式和SUM()函数,可以根据不同的条件,计算和汇总数据。
例如:可以利用搜索CASE表达式将下述SELECT语句结果中的行和列进行互换:
-- 根据商品种类计算出销售单价的合计值
SELECT product_type,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type;

--对按照商品种类得到的销售单价合计值进行行列转换
SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes,
SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen,
SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_office
FROM Product;

可以实现转化的原理:
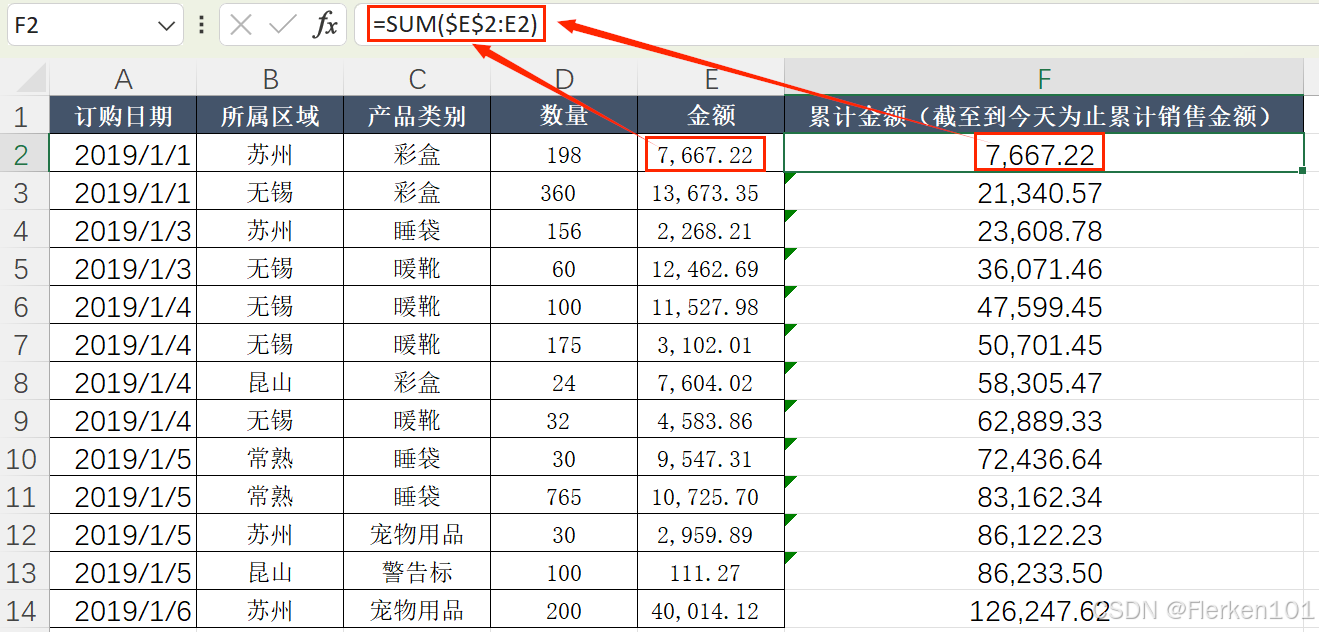
(1)SQL语言中的SUM函数只能接受,而且只能接受一个列名。【编程语言中的SUM函数,接受的是需要相加的多个参数,int sum(int m, int n). 】
【EXCEL中,给SUM函数传递的是一个需要求和的区域,可以是一个单元格,也可以是多行多列的区域范围。】
当是一个单元格时,可以改为区域(加一个冒号,再写一次单元格的行列坐标),从而实现累计求和。
035-相对引用与绝对引用
在SQL语言中,将列名作为参数传递给SUM函数,它将返回该列中所有值的总和。
还可以在SUM函数中使用关于列的条件语句,返回满足条件的所有记录,目标列的值的总和。
即设定条件的列 可以和要求值的列不是同一个。(2)CASE表达式是一种灵活的条件语句,正好可以满足上一句的要求。(艺术)
对CASE表达式中的每个WHEN条件,如果条件满足(即WHEN子句中的“< 求值表达式 >”返回的真值为TRUE),则会将该WHEN条件后面THEN子句中的<表达式>作为CASE表达式的返回值。
而且仍然满足以下原则:
使用聚合键或聚合函数时的SELECT子句 以及 使用聚合函数时的HAVING子句中,都只能存在以下三种元素:
● 常数
● 聚合函数(COUNT、SUM、AVG、MAX、MIN)及其参数 (其参数也可以是除聚合键之外的其它列名)
● GROUP BY子句中指定的列名(也就是聚合键)(如果没有GROUP BY子句,就没有这个)
关于第二段代码中SELECT子句、SUM函数、CASE表达式、AS列别名的执行顺序与情况的说明:
(1)SELECT:
SELECT语句的执行顺序为:
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
这里执行完FROM 之后,没有WHERE、GROUP BY、 HAVING子句,则直接执行SELECT子句.
【SELECT跟其它子句一样,地位平等(而且顺序还靠后),都是对原表的操作与计算。也并不直接管理输出过程。
把SELECT子句看作在前面FROM、WHERE、GROUP BY、 HAVING子句的操作结果基础上,要进行的计算。若只有字段名和常数,那就代表不用进行计算,只进行选择即可。 】
即会先把表中所有的记录都读取到,以所有记录为单位进行SELECT中计算的操作,并把指针定位到第一个记录。
【如果有 GROUP BY 的话,就会先进行分组,以组为单位执行下面的操作。并把指针定位到第一组的第一个记录。】
(2)CASE表达式: (按从内到外的顺序执行,CASE在第一个SUM函数的内部。)
第一个SUM函数中的CASE表达式中的WHEN条件是“product_type = ‘衣服’”,且当该条件满足时,返回当时记录的sale_price字段。不满足时返回0值。
即:这里进行求和的列,也就是给SUM函数传递的参数列名,是sale_price列。
通过CASE表达式会对一个操作单位(即所有记录)的sale_price列进行这样一个改变:
sale_price列中所有“product_type = '衣服’的记录,保持原值不变,否则就将其值变为0.
【在临时表中操作,肯定不是在原表中操作。】
当SUM函数为:
SUM(CASE WHEN product_type = ‘衣服’ THEN 1 ELSE 0 END) AS sum_clothes 时,
则会使用一个新的临时列,存储实体原表Product中各个记录对应的该CASE表达式的返回值(1或0),并在第(3)步中,对该临时列中的各记录值求和。求出来的即为实体原表Product中,满足product_type = ‘衣服’ 的记录总数。
利用下面的原理,可以写出与其等价的写法:
所有的聚合函数,如果以列名为参数,那么在计算之前就已经把NULL排除在外了。
因此,无论有多少个NULL 都会被无视。与其等价的写法为:
COUNT( CASE WHEN product_type = '衣服' THEN product_id -- 可为任意字段 ELSE NULL -- 必须是NULL END ) AS sum_clothes,
(3)SUM函数: 整理好sale_price列中全部的值后,使用SUM函数,对列中所有的记录进行求和。
(4)AS列别名: 将求和得到的值,作为要输出的列sum_price_clothes的第一个记录。
(5)对SELECT中的第二、第三个聚合函数SUM,重复(2)(3)(4).
至此,执行完SELECT子句中的全部内容。
(6)没有ORDER BY子句,直接输出最终结果sum_price_clothes、sum_price_kitchen、sum_price_office.
CASE 表达式是标准 SQL 所承认的功能,因此在任何DBMS 中都可以执行。
但是,有些 DBMS 还提供了一些特有的 CASE 表达式的简化函数,例如 Oracle 中的DECODE、MySQL中的 IF等。
# 通过简单CASE表达式将A~C的字符串加入到商品种类当中
SELECT product_name,
CASE product_type
WHEN '衣服' THEN 'A:' || product_type
WHEN '办公用品' THEN 'B:' || product_type
WHEN '厨房用具' THEN 'C:' || product_type
ELSE NULL
END AS abc_product_type
FROM Product;
# 通过搜索CASE表达式将A~C的字符串加入到商品种类当中
SELECT product_name,
CASE WHEN product_type = '衣服' THEN 'A:' || product_type
WHEN product_type = '办公用品' THEN 'B:' || product_type
WHEN product_type = '厨房用具' THEN 'C:' || product_type
ELSE NULL
END AS abc_product_type
FROM Product;
--使用Oracle中特有的DECODE代替CASE表达式,将A~C的字符串加入到商品种类当中
SELECT product_name,
DECODE(product_type, '衣服', 'A:' || product_type,
'办公用品', 'B:' || product_type,
'厨房用具', 'C:' || product_type,
NULL) AS abc_product_type
FROM Product;

3.2.3 搜索CASE表达式和聚合函数
利用聚合函数和搜索CASE表达式【如 SUM ( CASE WHEN …… THEN …… ELSE …… END ) 】将结果中的行和列进行互换是常用的方法。
(在一些数据处理中,这是唯一的实现方式。)
处理数据时,要先思考自己要得到结果:
①需要什么样的表形式(主要是需要什么样的字段);
②才能进行怎样的处理,从而得到结果。
然后先去生成需要的表形式。


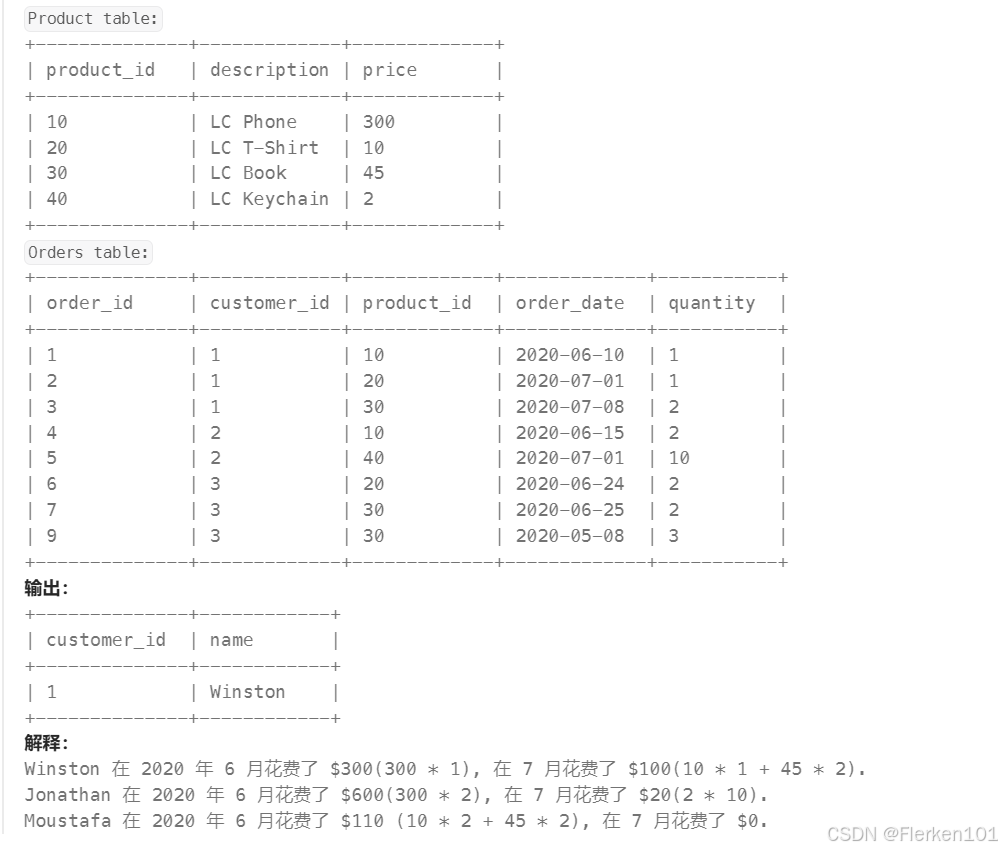
-- 可以将HAVING子句中的两个条件先写到SELECT子句中,辅助理解
SELECT c.customer_id, d.name
FROM (SELECT a.customer_id AS customer_id
FROM Orders a
LEFT OUTER JOIN Product b
ON a.product_id = b.product_id
WHERE DATE_FORMAT(a.order_date, "%Y-%m") = '2020-06' OR DATE_FORMAT(a.order_date, "%Y-%m") = '2020-07'
GROUP BY customer_id
HAVING SUM(CASE WHEN DATE_FORMAT(a.order_date, "%Y-%m") = '2020-06' THEN a.quantity * b.price ELSE 0 END) >= 100
AND SUM(CASE WHEN DATE_FORMAT(a.order_date, "%Y-%m") = '2020-07' THEN a.quantity * b.price ELSE 0 END) >= 100 ) c
LEFT OUTER JOIN Customers d
ON c.customer_id = d.customer_id
【 IF】
在MySQL中,IF既可以作为表达式用,也可在存储过程中作为流程控制语句使用。
SQL的IF语句——nichoo的博客
-- 在MySQL中,IF作为表达式用
select
machine_id,
round(2*avg(if(activity_type = 'start',-1,1)*timestamp),3) as processing_time
from
Activity
group by
machine_id;
在oracle中,IF仅做为流程控制语句(在存储过程中)使用。
oracle中没有IF表达式,只有CASE表达式,来实现“if-then-else”的逻辑计算功能。
数据库-Oracle条件判断语句——Alive_2020
oracle sql语句中if/else功能的实现的3种写法——顺其自然~
-- 在oracle中
SELECT machine_id,
ROUND(AVG(CASE activity_type WHEN 'start' THEN -timestamp ELSE timestamp end)*2, 3) AS processing_time
FROM Activity
group by machine_id;
4. 窗口函数
OLAP是OnLine Analytical Processing 的简称,意思是对数据库数据进行实时分析处理。
例如,市场分析、创建财务报表、创建计划等日常性商务工作。
窗口函数就是为了实现OLAP 而添加的标准SQL功能。
窗口函数也称为OLAP函数。
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。
4.1 窗口函数的语法
-- 窗口函数的语法
<窗口函数> OVER (PARTITION BY <分区依据列清单>
ORDER BY <排序用列清单 ASC(默认,升序)/DESC> -- 也可称为排序键
ROWS/RANGE <确定每个窗口内 框架范围(即汇总范围)的表达式> )
OVER: 关键字,表示前面的函数是OLAP实时分析处理函数,不是普通的聚合函数。
OVER关键字后面的半角括号中,即为窗口的定义子句。
4.1.1 窗口的定义子句
窗口的定义子句中可以包含三部分:
(1)PARTITION BY <分区依据列清单>
—— 将整个表中的所有记录按分区依据列进行分组,可省略。
通过PARTTION BY分组后,每组所有记录的集合称为窗口。将 “窗口” 理解为包含同一种类数据的范围。
与通过GROUP BY子句分割后的组一样,通过 PARTTION BY 分割后的各个窗口在定义上绝对不会包含共通的部分。就像刀切蛋糕一样,干净利落。
这里“窗口”代表的范围,也即为后面ORDER BY子句的作用范围。
在所有类别的窗口函数中,不指定 PARTITION BY 时的结果:
和使用没有GROUP BY子句的SELECT语句时的效果一样,也就是将整个表作为一个大的窗口来使用。
【分区和分组、分类都一个意思,此处叫分区仅是为了避免与GROUP BY子句常用的“分组”混淆。
这里的 “窗口” 跟组、类也都是一个意思,此处叫 “窗口” 也是为了避免与GROUP BY子句常用的“组”混淆。 】
常见考点:
使用 窗口聚合函数和PARTITION BY 之后,与使用 聚合函数和GROUP BY子句 之后不同,窗口聚合函数和PARTITION BY 之后 不会使表中的记录减少。知识点①: PARTITION BY 子句和GROUP BY子句一样具备分组功能,但是PARTITION BY 子句并不具备 GROUP BY子句具备的汇总功能。
问题②: 聚合函数和聚合窗口函数的区别?
当把聚合函数当作聚合窗口函数使用时,聚合窗口函数仍然具备对每个窗口的每个框架中,参数字段的所有记录进行汇总(输入多行,输出一行)和计算的功能,但不会使原表中的记录变少。
知识点③: 其它专用窗口函数也不会使原表中的记录变少。
(2)ORDER BY <排序键 ASC(默认,升序)/DESC>
——将每个窗口中的记录按排序键及指定的顺序进行排序
可以设有多个排序键,也可以直接省略ORDER BY子句。
PARTITION BY 在横向上对表进行分组;
ORDER BY 决定了每个窗口中记录纵向上排序的规则。
当ORDER BY子句省略时:窗口中的数据因为没有排序依据,呈无序状态。
此时,后面的框架子句无论是使用ROWS还是RANGE,都必须省略。
(省略后代表的框架详细内容,见下面Frame框架子句)
(3)ROWS/RANGE <确定每个窗口内 框架范围(即汇总范围)的表达式>
——— Frame框架子句,一般和窗口聚合函数一起使用。
用来在窗口中指定随着当前记录的变化,窗口聚合函数在当前窗口内更加详细、具体的作用范围(即:在不改变原表中记录数的情况下,进行汇总和计算的范围)。
将这种汇总范围称为框架。
框架设定好了就不会变了,但被作为汇总对象的记录范围会根据设定的框架,随着当前记录的变化而变化。
但无论使用哪种框架子句,对每条当前记录,都不会跨出当前窗口选取汇总记录。
注:当前记录所在窗口,本节中都简称为 “当前窗口” 。
当不省略ORDER BY子句时,可省略Frame框架子句;
或将Frame框架子句与ORDER BY子句一起省略。
Frame框架子句不能脱离ORDER BY子句而独自存在。
当不省略ORDER BY子句时,可省略Frame框架子句:
ORDER BY <一个/多个排序键> 等价于
ORDER BY <一个/多个排序键> RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW代表的框架范围为:当前窗口中,第一行记录排序键的值至当前行排序键的值。
当把ORDER BY子句和Frame框架子句都省略时,即 OVER(PARTITION BY <分区键>) 时聚合函数计算出来的结果, 等价于:
OVER ( PARTITION BY <分区键> ORDER BY <排序键> ROWS/RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING )每个窗口中的数据因为没有排序依据,呈无序状态。
代表框架是:当前窗口中的所有记录。
ROWS:当前窗口第一行记录到最后一行记录,即当前窗口中的所有记录。
RANGE:当前窗口从第一行记录排序键的值至最后一行记录排序键的值,也即当前窗口中的所有记录。所以此处同时省略ORDER BY子句和Frame框架子句时,对于使用RANGE关键字的框架情况:在当前窗口中,从第一行记录排序键的值至最后一行记录排序键的值这个范围,也可以当作其就是指当前窗口的所有记录,而不用去管起点和终点的值。
另一种比较官方的解释,见4.1.2.1 用到的关键字及其含义 中对RANGE关键字的介绍。
窗口定义子句中的ORDER BY只是用来决定
窗口函数在每个窗口中按照什么样的顺序进行计算的,对SELECT语句的最终结果的排列顺序并没有影响。
有些DBMS也可以按照窗口函数的ORDER BY子句所指定的顺序对SELECT语句的结果进行排序,但那也仅仅是个例而已。
尽管这两个ORDER BY看上去是相同的,但其实它们的功能却完全不同。
如果要对SELECT语句的最终结果进行排序,那么要在SELECT 语句的最后,单独使用ORDER BY子句进行指定。
4.1.2 使用窗口定义子句的注意事项
(1)不管有几个聚合键,哪几个聚合键,都不能直接在窗口函数中的子句中(主要是指窗口函数中的ORDER BY子句),使用聚合函数。
【窗口函数中的ORDER BY子句,不同于即将返回结果的最外层查询中的ORDER BY子句。
在最外层查询中的ORDER BY子句中,可以使用聚合函数和窗口函数;
但在任何位置的(包括位于最外层查询中的ORDER BY子句中的)窗口函数的ORDER BY子句中,都不可以再使用聚合函数。】

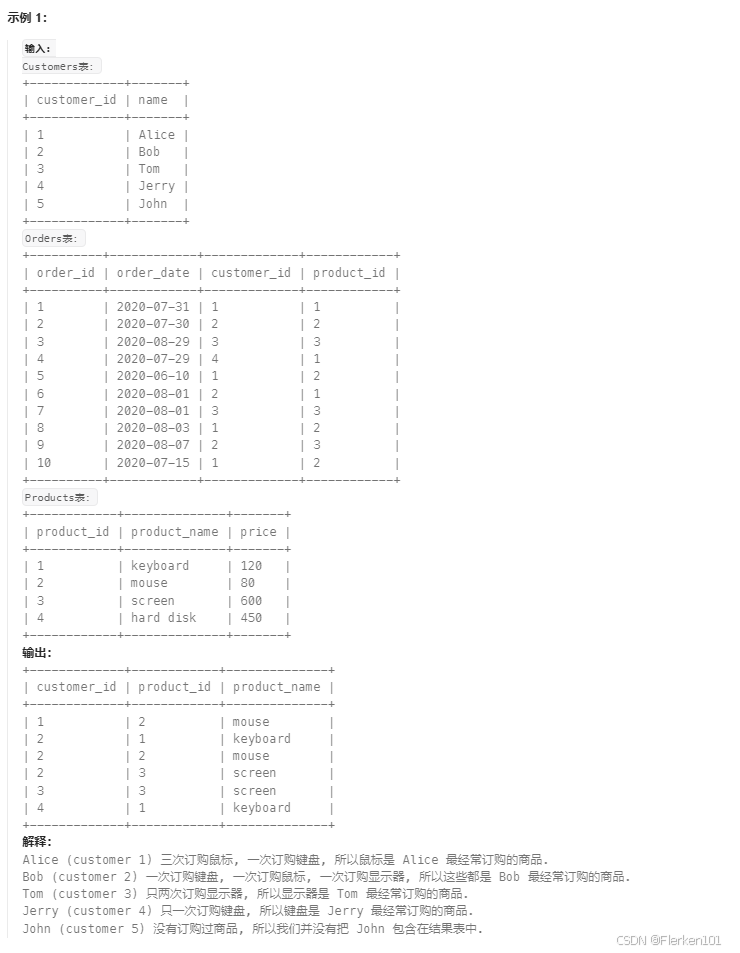
-- 正确代码:
SELECT a.customer_id,
a.product_id,
a.product_name
FROM (SELECT c.customer_id AS customer_id,
c.product_id AS product_id,
p.product_name AS product_name,
c.num,
DENSE_RANK() OVER(PARTITION BY c.customer_id ORDER BY c.num DESC) AS rk
FROM (SELECT customer_id, product_id, COUNT(*) AS num
FROM Orders
GROUP BY customer_id, product_id) c
LEFT OUTER JOIN Products p
ON c.product_id = p.product_id) a
WHERE a.rk = 1
即:不管有几个聚合键,哪几个聚合键,都不能直接在窗口函数DENSE_RANK()中的子句ORDER BY中,使用聚合函数COUNT(order_id).
所以下面三种都是不可以的:
【因为窗口函数的定义子句ORDER BY子句中都有聚合函数。】
DENSE_RANK() OVER(PARTITION BY customer_id, product_id ORDER BY COUNT(order_id) DESC) AS rk
DENSE_RANK() OVER(PARTITION BY customer_id ORDER BY COUNT(order_id) DESC) AS rk1,
DENSE_RANK() OVER(PARTITION BY product_id ORDER BY COUNT(order_id) DESC) AS rk2
必须要先对每个分组中包含的记录进行计数,求出num:
SELECT customer_id, product_id, COUNT(*) AS num
FROM Orders
GROUP BY customer_id, product_id
然后再使用窗口函数,对每个分组的上级分组中包含的记录个数进行排序,并返回排名序号。(上面的普通查询,起别名为c)
DENSE_RANK() OVER(PARTITION BY c.customer_id ORDER BY c.num DESC) AS rk
4.1.2 Frame框架子句
【明确 当前记录/行的 以下几个维度的信息(不是全部,用到哪个要清楚哪个):
① 属于哪个窗口;
② 窗口中的哪个行/记录(行数多少);
③ 窗口定义子句的ORDER BY中使用了一个还是多个排序键;
④ 具体是哪个/哪几个排序键(每个窗口的排序依据);
⑤ 当前记录排序键的值为多少。 】
-- / 都是或者的意思,只能选择一个
-- 以下终点和起点的各种类型可自由搭配
{ ROWS / RANGE }
BETWEEN
{UNBOUNDED PRECEDING / N PRECEDING / CURRENT ROW }
AND
{UNBOUNDED FOLLOWING / N FOLLOWING / CURRENT ROW }
--当终点是CURRENT ROW时,可省略
{ ROWS / RANGE }
BETWEEN --省略
{ UNBOUNDED PRECEDING / N PRECEDING / CURRENT ROW } -- 起点中不能出现FOLLOWING
AND --省略
{ CURRENT ROW } --当终点是CURRENT ROW时,可省略
等价于
{ ROWS / RANGE }
{UNBOUNDED PRECEDING / N PRECEDING / CURRENT ROW} -- 默认是起点
''' 在Oracle中,没有BETWEEN..AND关键字,只有一个点且不含FOLLOWING,则默认是起点;
终点默认为CURRENT ROW(所以起点中不能出现FOLLOWING)
见 4.1.2.2 不同框架的表达方式中的(2)'''
-- 当起点是CURRENT ROW时,不论N2为多少,终点都不能是PRECEDING
{ ROWS / RANGE }
BETWEEN
{ N1 PRECEDING }
AND
{ N2 PRECEDING } --当终点是PRECEDING时,起点也必须是PRECEDING
-- 且 N1与N2之间没有大小关系的严格要求
-- 但最好符合逻辑,比如起点代表的时间/数值 小于 终点(注意排序键是升序还是降序)
{ ROWS / RANGE }
BETWEEN
{ N3 FOLLOWING } -- 当起点是FOLLOWING时,终点也必须是FOLLOWING
AND
{ N4 FOLLOWING }
-- 且N3与N4之间没有大小关系的严格要求
-- 但最好符合逻辑,比如起点代表的时间/数值 小于 终点(注意排序键是升序还是降序)
4.1.2.1 用到的关键字及其含义
(1)ROWS和RANGE
ROWS和RANGE定义了一个窗口的每一行,都是用来指定在当前窗口内的框架范围的。
无论使用哪种框架子句,对每条当前记录,框架范围都不会超出当前窗口。
ROWS:代表物理范围,判断依据是当前记录行。
RANGE:代表逻辑范围,判断依据是在当前记录中ORDER BY 子句使用的排序键的值。
【RANGE子句定义了当前记录中排序键值的逻辑偏移量。】
窗口函数rows between 、range between的使用——卖山楂啦prss
使用RANGE关键字时,相同行会被合并成同一条数据再进行计算。
是否是相同行,是根据ORDER BY排序时的结果决定的。
有ORDER BY时:相同行是说在ORDER BY排序时不唯一的行。【即具有相同数值的行】
不同行是说ORDER BY排序时具有不同的数值的行。
没有ORDER BY:
相比较于有ORDER BY时的情况,因为没有任何依据可以区分出每个窗口中的不同行,
因此整个窗口中的所有行都会被认为是“相同行”。
从而,对当前窗口中每条记录,都会将整个窗口中的所有记录作为框架范围。
(2)BETWEEN … AND :定义当前窗口中框架的起点和终点。
AND之前的表达式:代表框架的起点;
AND之后的表达式:代表框架的终点。
【当排序键按升序排列时,起点和终点之间最好满足 起点排序键的值<终点排序键的值 ;
当排序键按降序排列时,起点和终点之间最好满足 起点排序键的值>终点排序键的值 。】
(3)PRECEDING 和 FOLLOWING
PRECEDING:在…之前。
FOLLOWING:在…之后。
PRECEDING / FOLLOWING 前面可以修饰的内容有:N 和 UNBOUNDED 两种。
① 在Oracle中,N可以是数字,也可以是一个能计算出数字的表达式。但只能是数字。
当使用RANGE关键字,且N是数字或者是能计算出数字的表达式,
要使用 N PRECEDING 和 N FOLLOWING 作为起点或终点,还必须满足:
ORDER BY 后面的排序键只有一个,且为整数型或日期类型
(因为简单且易于比较。)。
【使用ROWS关键字 和 N PRECEDING / FOLLOWING搭配时,无论是对排序键的个数,还是类型,都没有限制。】
在MySQL中,N还可以是interval类型的。(如:INTERVAL 6 DAY )
1321. 餐馆营业额变化增长在数据库中,interval是一种数据类型,用于表示时间间隔或时间差。
它可以用来计算两个日期之间的时间间隔,或者在某个日期上增加或减少一定的时间。
数据库interval什么意思——worktile在MySQL中:
若N是数字类型,那么在RANGE中使用 N PRECEDING 和 N FOLLOWING的要求,同Oracle中一样;
若N是时间间隔类型,那么 ORDER BY 后面的排序键只能有一个,且必须为日期类型。
MySQL窗口函数RANGE日期范围——CSDN文库
② UNBOUNDED:不受控制的,无限的
N PRECEDING:既能做起点,也能做终点
与ROWS连用时,代表当前窗口中,当前记录之前N行的记录;
与RANGE连用时,代表当前窗口中,当前记录排序键的值减N的值。
UNBOUNDED PRECEDING:只能做起点
与ROWS连用时,代表起点为当前窗口中的第一行记录;
与RANGE连用时,代表起点为当前窗口中,第一行记录排序键的值。
N FOLLOWING:既能做起点,也能做终点
与ROWS连用时,代表当前窗口中,当前记录之后N行的记录;
与RANGE连用时,代表当前窗口中,当前记录排序键的值加N的值。
UNBOUNDED FOLLOWING:只能做终点
与ROWS连用时,代表终点为当前窗口中的最后一行记录;
与RANGE连用时,代表终点为当前窗口中,最后一行记录排序键的值。
(4)CURRENT ROW
与ROWS连用时,代表当前窗口中,当前记录行;
与RANGE连用时,代表当前窗口中,当前记录排序键的值。
CURRENT ROW 同 N PRECEDING 和 N FOLLOWING一样,
既可以设置成起点,也可以设置成终点。
4.1.2.2 不同框架的表达方式
只列举其中一些,帮助理解,不包含所有情况。
(1)BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:
与ROWS连用时,代表当前窗口中,第一行记录至当前行记录;
与RANGE连用时,代表当前窗口中,第一行记录排序键的值到当前行记录排序键的值这个范围内。
ORDER BY <一个/多个排序键> 等价于
ORDER BY <一个/多个排序键> RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
注意:不等价于
ORDER BY <一个/多个排序键> ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
原因:使用RANGE关键字时,相同行(即ORDER BY中的排序键具有相同数值的行)会被合并(相应的,作为窗口函数参数的汇总项也会被进行汇总)成同一条数据再进行计算。 而相同情况下,使用ROWS关键字时,不会。
这样在求累计和的时候,就可以使用RANGE求出每组中的某个汇总项,而且不会减少表中的记录数。
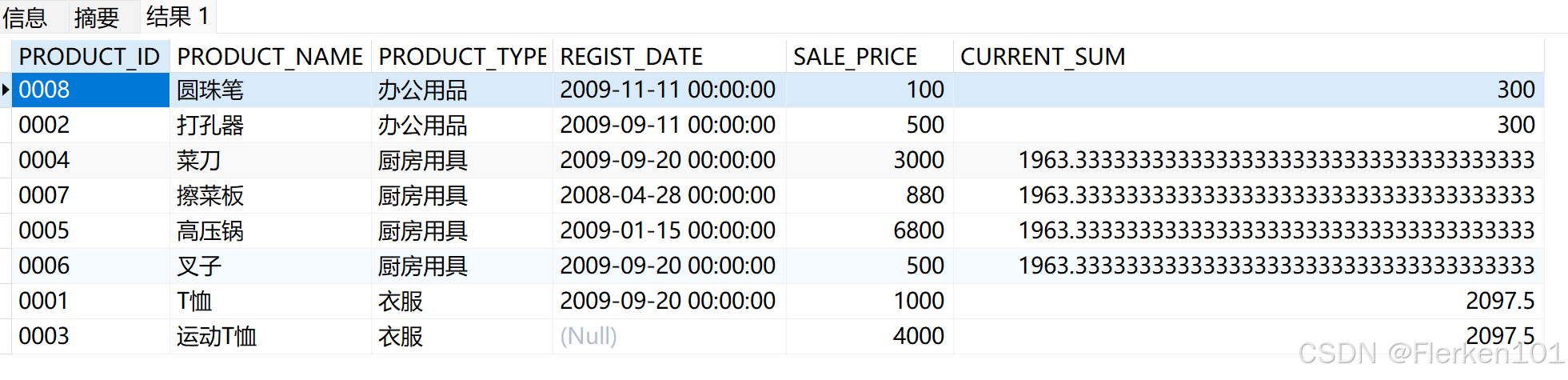
-- 使用RANGE,在每种product_type组内,对sale_price进行汇总求和SUM (sale_price)时:
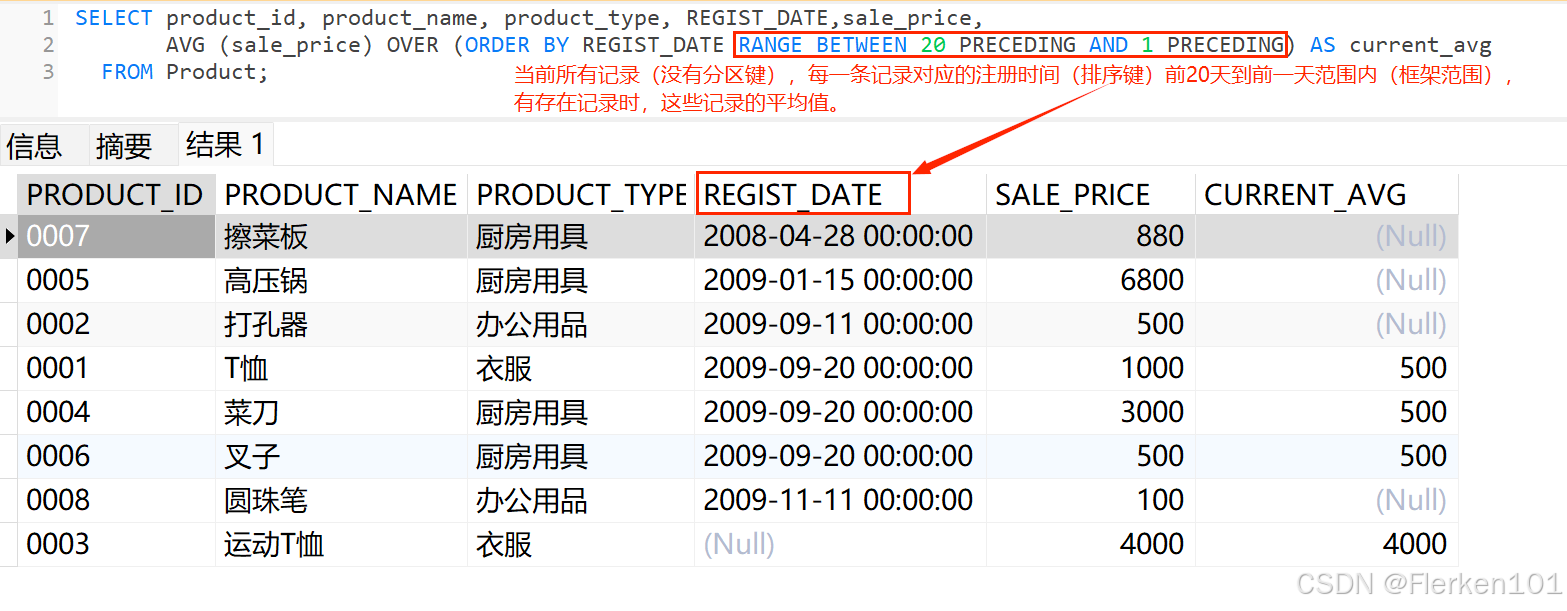
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
SUM (sale_price) OVER (PARTITION BY product_type ORDER BY product_type RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_sum
FROM Product;
--分组和排序键都是product_type
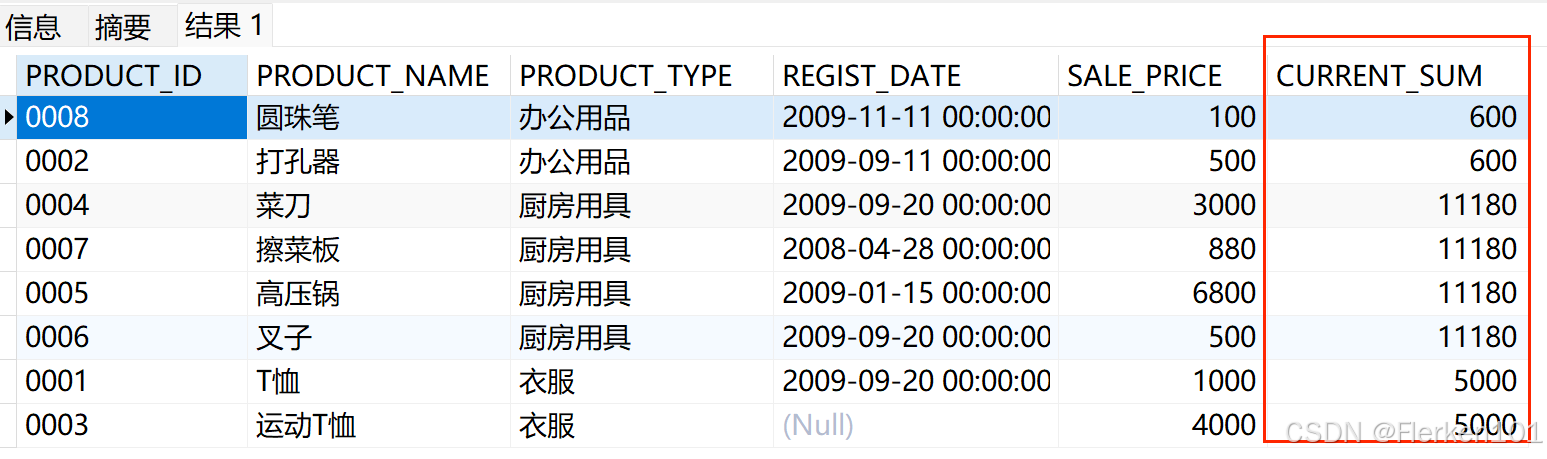
-- 使用RANGE,在每种product_type组内,对sale_price进行汇总求平均AVG (sale_price)时:
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
AVG (sale_price) OVER (PARTITION BY product_type ORDER BY product_type RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_sum
FROM Product;
-- 套入子查询,则可以求出每组的平均值
SELECT product_type,AVG(current_avg)
FROM (SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
AVG (sale_price) OVER (PARTITION BY product_type ORDER BY product_type RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_avg
FROM Product)
GROUP BY product_type;
-- 等价于
SELECT product_type,AVG(sale_price)
FROM Product
GROUP BY product_type;

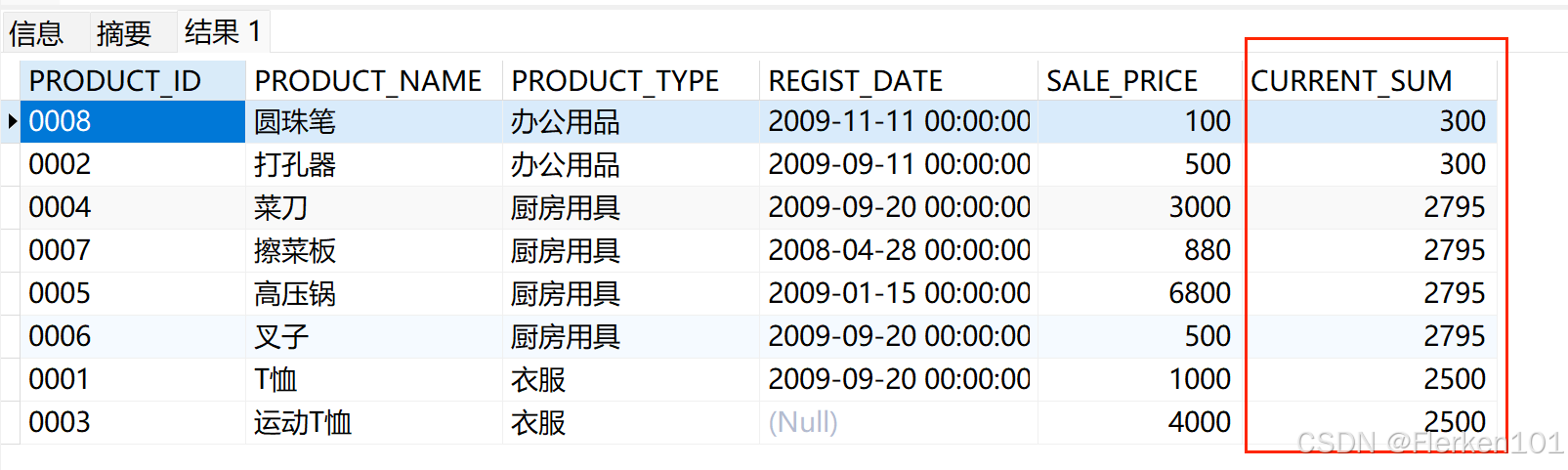
-- 如果直接省略掉PARTITION BY product_type,那么将对所有记录下的sale_price求和。
-- 其中,先对第一组求累计和,然后对第一组和第二组求累计和,……,逐步按组求累计和。
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
SUM (sale_price) OVER (ORDER BY product_type RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_sum
FROM Product;
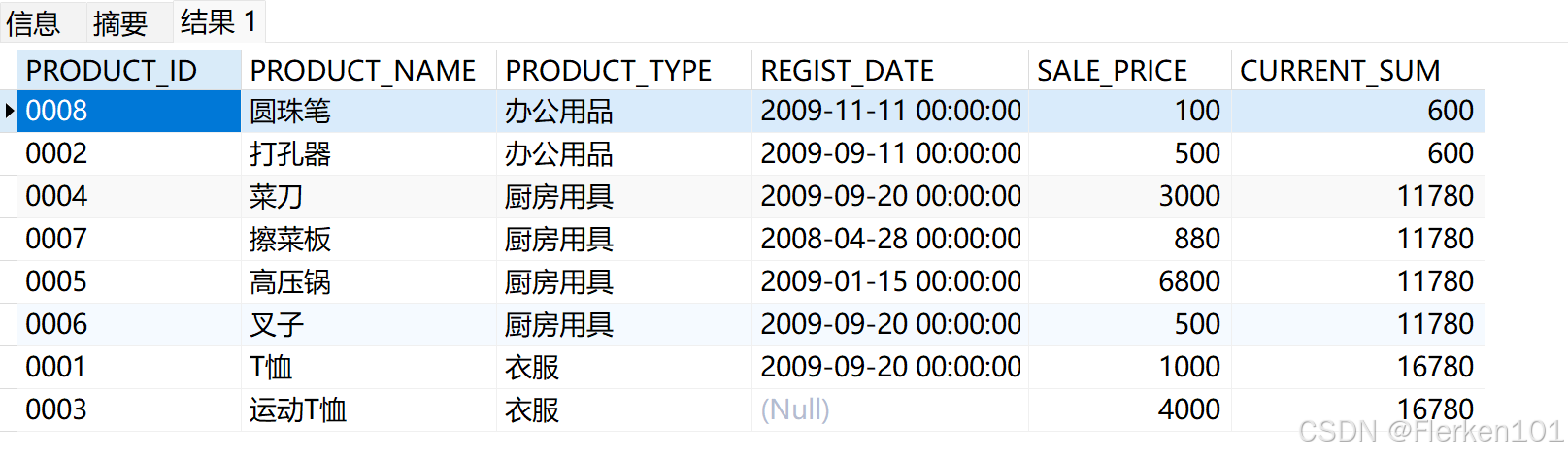
-- 如果直接省略掉PARTITION BY product_type,那么将对所有记录下的sale_price求平均。
-- 其中,先对第一组求平均,然后对第一组和第二组求平均,……,逐步按组求平均。
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
AVG (sale_price) OVER (ORDER BY product_type RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_sum
FROM Product;
-- 使用ROWS,在每种product_type组内,对sale_price进行逐行的汇总求和SUM (sale_price)时:
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
SUM (sale_price) OVER (PARTITION BY product_type ORDER BY product_type ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_sum
FROM Product;
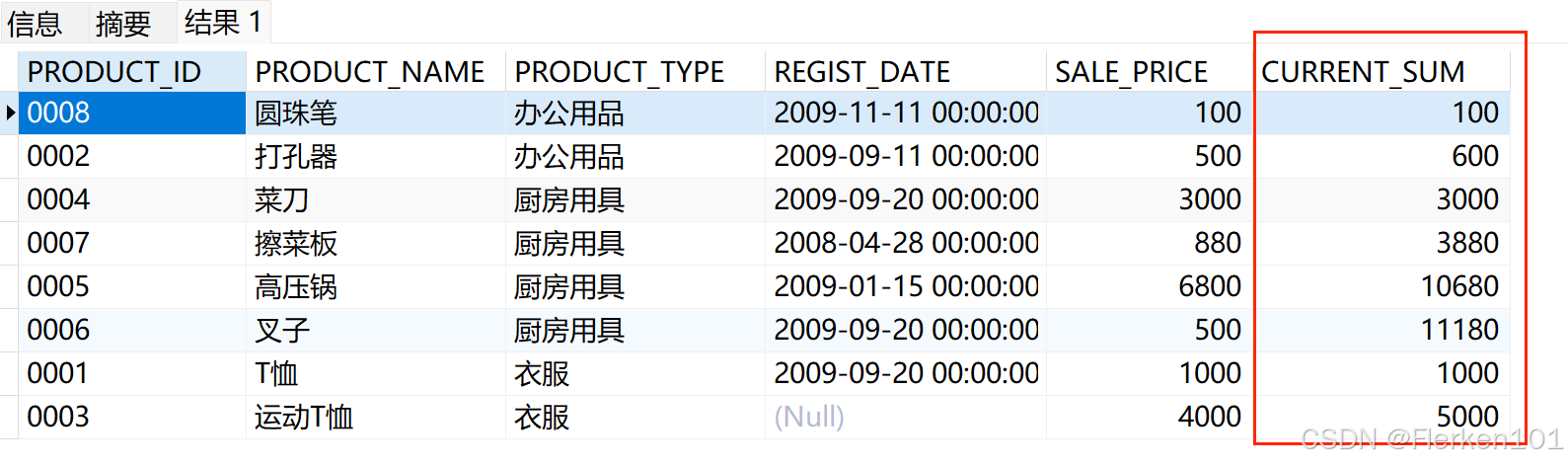
(2)BETWEEN N PRECEDING AND CURRENT ROW :
与ROWS连用时,代表当前窗口中,当前行之前的N行至当前行。
此时,ROWS窗口子句,即 ROWS BETWEEN N PRECEDING AND CURRENT ROW
可简写成ROWS N PRECEDING.
与RANGE连用时,代表当前窗口中,当前行排序键的值减N的值到当前行排序键的值这个范围内。
此时,RANGE窗口子句,即 RANGE BETWEEN N PRECEDING AND CURRENT ROW
可简写成RANGE N PRECEDING.
(3)BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING :
与ROWS连用时,代表当前窗口中,当前行至最后一行 ;(不可省略任何部分)
与RANGE连用时,代表当前窗口中,当前行排序键的值到最后一行排序键的值这个范围内。 (不可省略任何部分)
(4)BETWEEN CURRENT ROW AND N FOLLOWING:
与ROWS连用时,代表当前窗口中,当前行至当前行之后的N行; (不可省略任何部分)
与RANGE连用时,代表当前窗口中,当前行排序键的值到当前行排序键的值加N的值这个范围内。 (不可省略任何部分)
(5)BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:
与ROWS连用时,代表当前窗口中,第一行到最后一行,即当前窗口中的所有记录;
与RANGE连用时,代表当前窗口中,第一行排序键的值到最后一行排序键的值这个范围内。
当ORDER BY子句省略时,此时后面的框架子句无论是ROWS还是RANGE,都必须省略。
即说明:当把ORDER BY子句和框架子句都省略时,两种框架子句也都是等价的。
即 OVER() 等价于:OVER( ORDER BY <排序键> ROWS/RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
但此时,每个窗口中的数据因为没有排序依据,呈无序状态。
(6)BETWEEN N PRECEDING AND N FOLLOWING :
与ROWS连用时,代表当前窗口中,当前行之前的N行至当前行之后的N行;
与RANGE连用时,代表当前窗口中,当前行排序键的值减N的值到当前行排序键的值加N的值这个范围内。
4.2 窗口函数的种类
1.排名窗口函数 和 3.取值窗口函数 为专用窗口函数,即为标准SQL定义的OLAP专用函数。
两种专用窗口函数 都:
①不能省略ORDER BY 子句;
②PARTITION BY 子句都是可选的;
③框架子句都不是重点,有点甚至不支持框架子句(如LAG)。如何使用框架子句,依据具体情况而定,但一般情况下都省略,直接使用默认值。
排名窗口函数中:
RANK、DENSE_RANK、ROW_NUMBER、PERCENT_RANK、CUME_DIST无需参数,通常括号中都是空的。
NTILE必须有一个数值参数。
取值窗口函数中:
LAG、LEAD、NTH_VALUE必须有一个列参数和一个数值参数。
FIRST_VALUE和LAST_VALUE必须有一个数值参数。
窗口函数主要有三种:
4.2.1 排名窗口函数
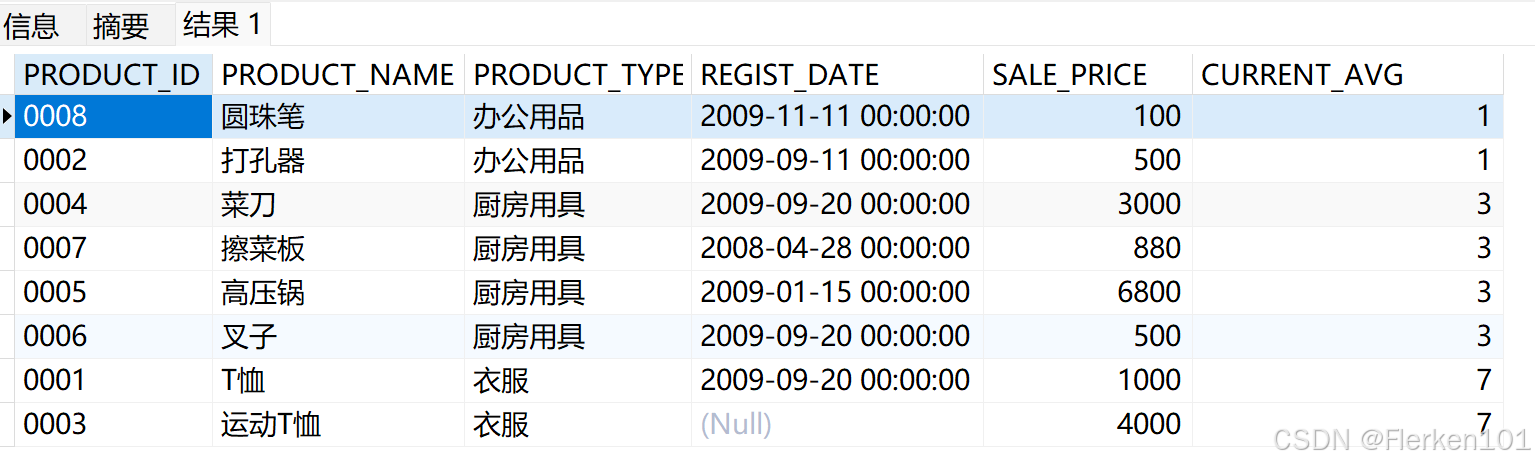
4.2.1.1 RANK函数:相等重复,会跳过
返回当前行在分区中的名次,如果存在名词相同的数据,后序的排名将会产生跳跃。
例如:有 3 条记录排在第 1 位时:1 位、1位、1位、4位……
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
RANK() OVER (ORDER BY product_type) AS current_avg
FROM Product;
4.2.1.2 DENSE_RANK函数:相等重复,不会跳过
返回当前行在分区中的名次,即使存在名词相同的数据,后序的排名也是连续值。
例如:有 3 条记录排在第 1 位时:1 位、1位、1位、2位……
4.2.1.3 ROW_NUMBER函数:相等不重复,不会跳过
为每个窗口中的每个记录分配唯一的连续位次。
例如:有 3 条记录排在第 1 位时:1 位、2位、3位、4位……
当存在值相同的记录时,DBMS会根据适当的顺序对这些记录进行排列。
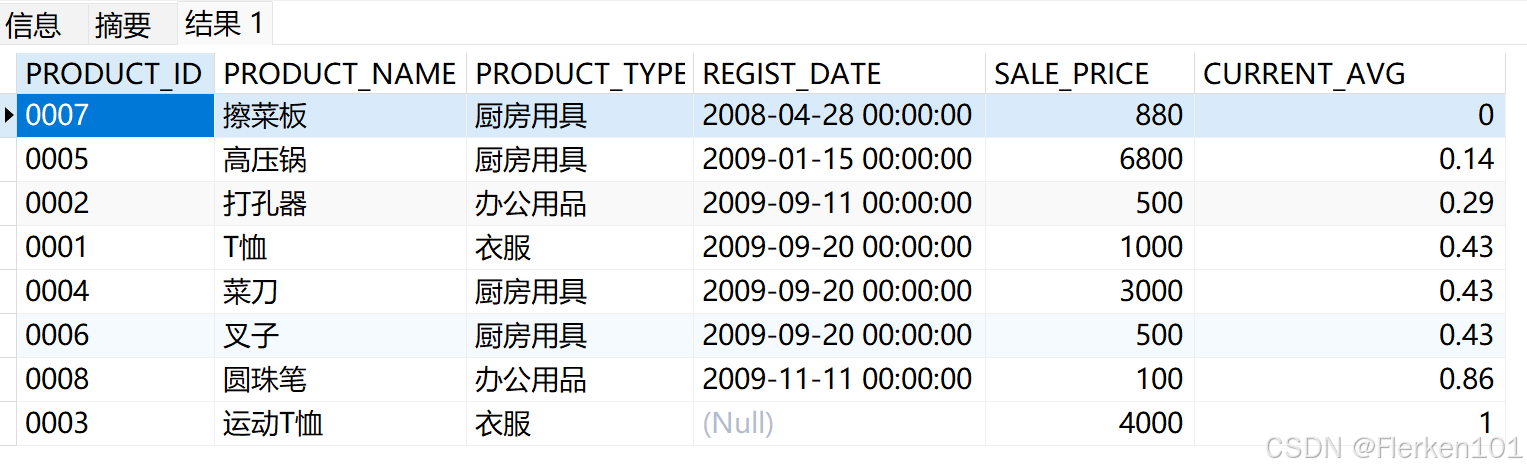
4.2.1.4 PERCENT_RANK函数:
以百分比的形式返回当前行在分区中的名次(即排序后的位置)。
【名次/总的记录数*100%】
默认使用RANK函数返回的位次类型,因此如果存在名次相同的记录,那么将可能返回相同的百分比位次,且其后续返回的百分比排名将会产生跳跃。
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
ROUND(PERCENT_RANK() OVER (ORDER BY REGIST_DATE),2) AS current_avg
FROM Product;
4.2.1.5 CUME_DIST:计算当前行在分区内的累计百分数
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
CUME_DIST() OVER (ORDER BY product_type) AS current_avg
FROM Product;
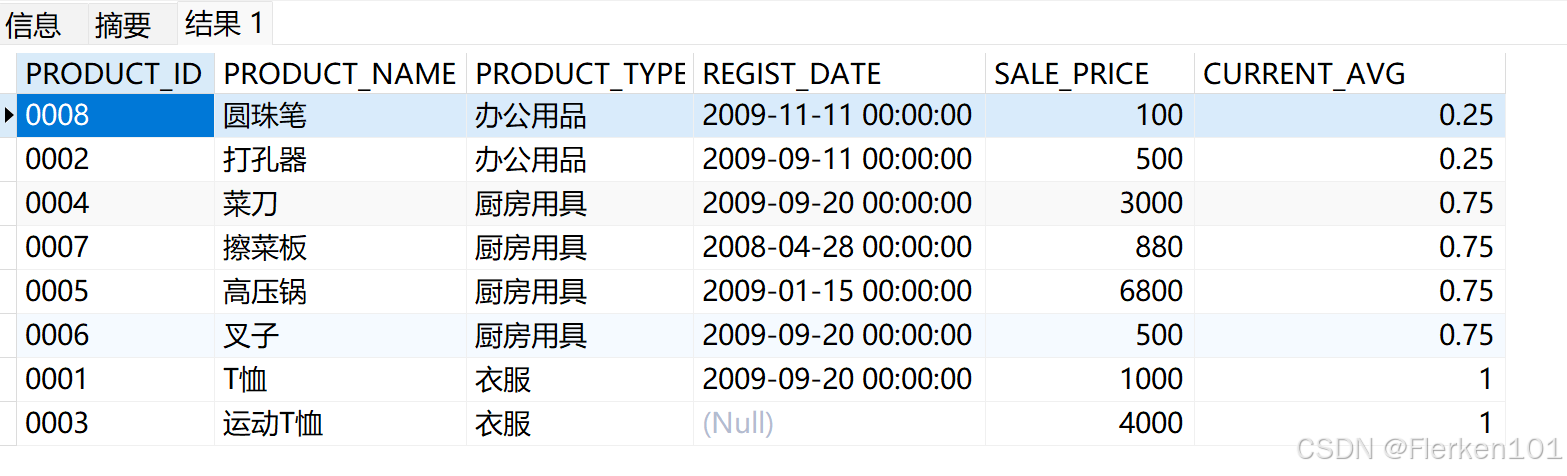
4.2.1.6 NTILE:将分区内的数据/记录分为N等份,并返回当前行所在的分片位置。
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
NTILE(2) OVER (ORDER BY REGIST_DATE) AS current_avg
FROM Product;
4.2.2 聚合窗口函数
当聚合函数和窗口定义一起使用,即被当作窗口函数使用时,称为:聚合窗口函数。
所有的聚合函数都能用作窗口函数,其语法和专用窗口函数完全相同,但需要在括号内指定作为汇总对象的列。
COUNT,MAX,MIN,SUM,AVG
因此,使用聚合窗口函数的窗口定义子句中,一般都不会省略Frame框架子句。
【即使省略的情况下,也是使用的默认框架。】
以 “自身记录(当前记录)” 作为基准进行统计,就是将聚合函数当作聚合窗口函数使用时的最大特征。
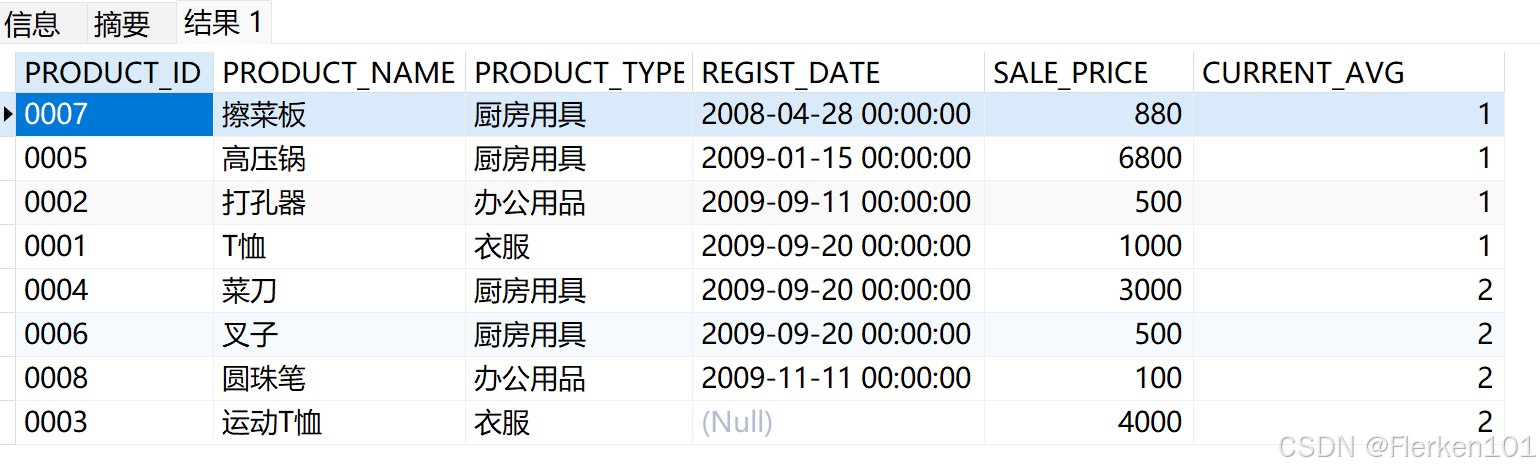
4.2.3 取值窗口函数
4.2.3.1 LAG:返回窗口内当前行之前的第N行数据;
(不支持任何框架子句)
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
LAG(REGIST_DATE,2) OVER (PARTITION BY product_type ORDER BY product_type) AS current_avg
FROM Product;
4.2.3.2 LEAD:返回窗口内当前行之后的第N行数据;
LEAD()函数可返回当前窗口内,某个字段当前行之后的几行数据。
与LAG()函数类似,LEAD()函数对于计算同一结果集中当前行和后续行之间的差异非常有用。
LEAD()函数的语法:
LEAD(<expression>[,offset[, default_value]])
OVER (PARTITION BY (expr)
ORDER BY (expr) )
expression:要返回的字段列。
offset:从当前行开始,向下数的行数,以获取值。
offset必须是一个非负整数。
如果offset为零,则LEAD()函数计算expression当前行的值。
如果省略 offset,则默认使用1。
【如果省略了offset参数,那么后面的参数default_value也必须省略。】
default_value:如果没有后续行时,则LEAD()函数要返回的内容。
例如,如果offset是1,则最后一行的返回值为default_value。
如果未指定default_value,则LEAD()函数将返回 NULL 。
PARTITION BY子句将结果集中的行,按照分区依据进行划分。
如果PARTITION BY未指定子句,则结果集中的所有行都将被视为单个分区。
ORDER BY子句确定每个分区中行的排列依据及排列方式。
示例:
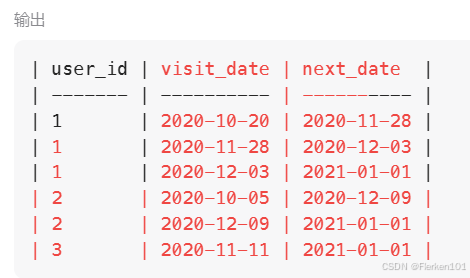
这里的第三个参数default_value参数非常关键。


SELECT a.user_id, MAX(DATEDIFF(next_date, visit_date)) AS biggest_window
FROM (SELECT user_id, visit_date,
LEAD(visit_date, 1, '2021-01-01') OVER(PARTITION BY user_id ORDER BY visit_date) AS next_date
FROM UserVisits) a
GROUP BY a.user_id
ORDER BY a.user_id
整个子查询中,内层普通SELECT查询的执行结果
SELECT user_id, visit_date,
LEAD(visit_date, 1, '2021-01-01') OVER(PARTITION BY user_id ORDER BY visit_date) AS next_date
FROM UserVisits
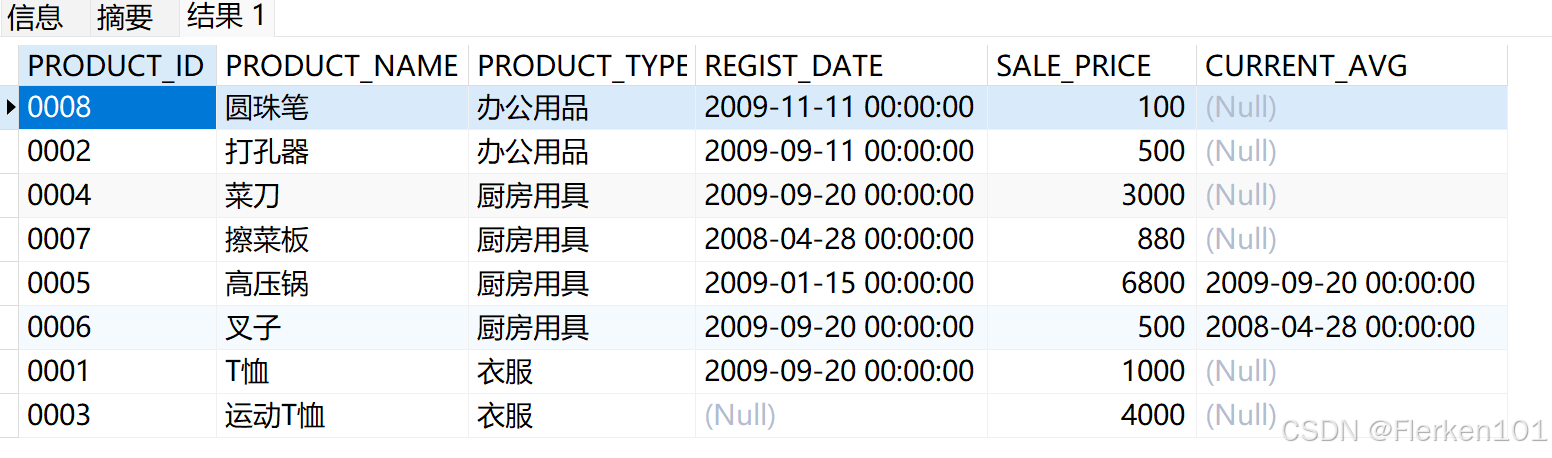
4.2.3.3 FIRST_VALUE:返回窗口的第一行数据;
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
FIRST_VALUE(product_type) OVER (PARTITION BY product_type ORDER BY product_type) AS current_avg
FROM Product;
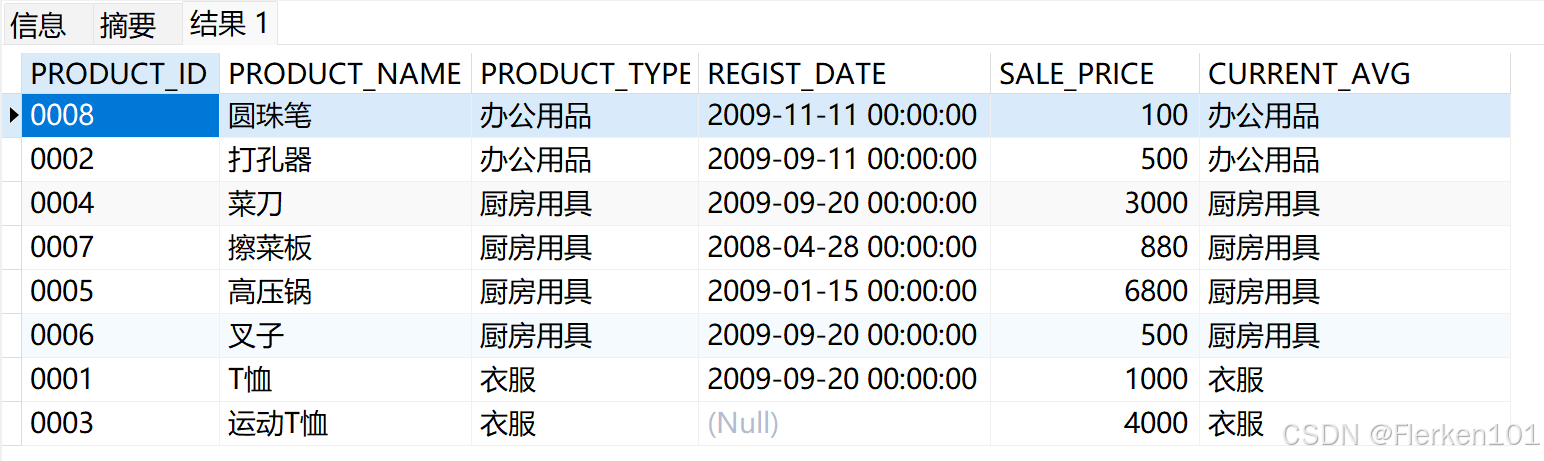
4.2.3.4 LAST_VALUE:返回窗口的最后一行数据;
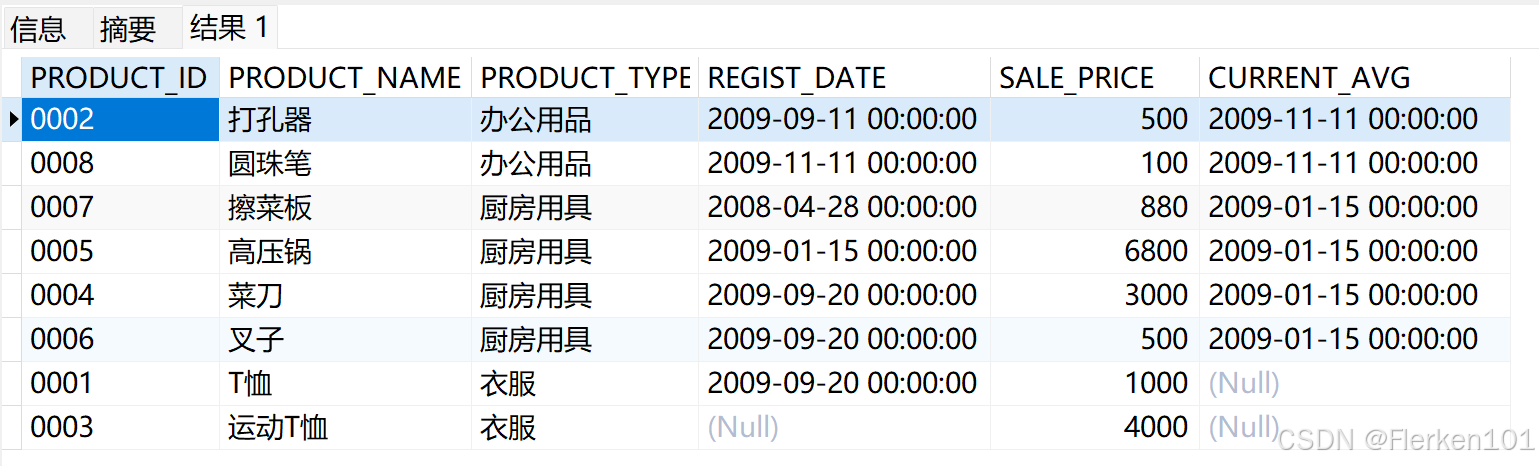
4.2.3.5 NTH_VALUE::返回窗口的第N行数据。
(支持两种框架子句)
SELECT product_id, product_name, product_type, REGIST_DATE,sale_price,
NTH_VALUE(REGIST_DATE,2) OVER (PARTITION BY product_type ORDER BY product_type) AS current_avg
FROM Product;
4.3 窗口函数的书写位置
只能在SELECT、 UPDATE 的SET子句、 ORDER BY子句中使用。
不能在FROM、 WHERE、 GROUP BY、HAVING子句中使用。
原因:
在DBMS内部,窗口函数是对WHERE子句或者GROUP BY子句、HAVING子句处理后的“结果”进行的操作。
在得到用户想要的结果之前,即使使用窗口函数,通过PARTITION BY 对表中的数据进行了分区,并通过ORDER BY对每个窗口中的记录进行了排序处理,结果也是错误的。
如在窗口函数中没有使用PARTITION BY,仅使用了ORDER BY ,并通过窗口函数中的ORDER BY得到了对表中所有记录的排序结果。
但之后,又通过WHERE子句中的条件除去了表中某些记录,或者又使用GROUP BY子句对表中的所有记录进行了分类及汇总处理,那好不容易通过窗口函数得到的排序结果也无法使用了。
正是由于这样的原因,所以在语法上才会有这样的限制。
反之,之所以在ORDER BY子句中能够使用窗口函数,是因为ORDER BY子句会在SELECT子句之后执行,并且保证不会减少结果记录。
4.4 计算移动平均
“计算移动平均”的统计方法,在希望实时把握“最近状态”时非常方便,因此常常会应用在对股市趋势的实时跟踪当中。
-- 将框架指定为截止到当前记录之前2行(最靠近的3行)
SELECT product_id, product_name, sale_price,
ROUND(AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING),2) AS moving_avg
FROM Product;


-- 将框架指定为截止到当前记录之后2行(最靠近的3行)
SELECT product_id, product_name, product_type, sale_price,
ROUND(AVG (sale_price) OVER (ORDER BY product_id ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING),2) AS moving_avg
FROM Product;


-- 将框架指定为当前记录及其前后1行
SELECT product_id, product_name, sale_price,
ROUND(AVG (sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING),2) AS moving_avg
FROM Product;


5. GROUPING运算符
合计行是不指定聚合键时得到的汇总结果。
-- 如使用如下方式得到合计
SELECT '合计' AS product_type, SUM(sale_price)
FROM Product
UNION ALL
SELECT product_type, SUM(sale_price)
FROM Product
GROUP BY product_type;
GROUPING运算符包含以下 3 种:
● ROLLUP
● CUBE
● GROUPING SETS
5.1 ROLLUP——同时得出合计和小计
GROUP BY 有按聚合键分类的功能,也有将各组中多个相同的聚合键值汇总为一行的功能。
ROLLUP必须和GROUP BY 一起使用。
ROLLUP是“卷起”的意思,比如卷起百叶窗、窗帘卷等等。
ROLLUP有依次取消/卷起由GROUP BY 中最后一个聚合键所产生的分组的功能,也有将每个新分组中多个相同的剩余聚合键值汇总为一行的功能。
RULLUP 同 GROUP BY 的执行顺序一样,在FROM、WHERE 后面,非常靠前。
具体来说是:FROM → WHERE → GROUP BY → HAVING → SELECT → RULLUP(执行多次) → SELECT(执行多次)
【对当前表中数据使用的聚合键个数 和 RULLUP的执行次数、表中数据的聚合级以及聚合单位 都成反比。】
GROUP BY (A1,A2,…An)
将表中的数据按原本所有的聚合键A1,A2,…An进行分组,并将每组中多个相同的聚合键值进行汇总
→ 有HAVING子句就执行 → SELECT
→ RULLUP(第一次执行)→ SELECT卷起由最后一个聚合键An产生的分组,并对每个新分组(称为“超级分组”)中多个相同的剩余聚合键A1,A2,…An-1的多个相同值进行汇总(这些聚合键的GROUPING函数返回值仍为0.),
将去掉的聚合键An的值都显示为NULL(这些聚合键的GROUPING函数返回值为1.)→ RULLUP(第二次执行)→ SELECT
卷起由最后一个聚合键An-1产生的分组,并对每个新分组(称为“超级分组”)中多个相同的剩余聚合键A1,A2,…An-2的多个相同值进行汇总(这些聚合键的GROUPING函数返回值仍为0.),
将去掉的聚合键An,An-1的值都显示为NULL(这些聚合键的GROUPING函数返回值为1.)→ …
→ RULLUP(第n次执行)→ SELECT
卷起由最后一个聚合键A1产生的分组,整个表的数据都在一组(仍为“超级分组”)中,没有了任何聚合键。将去掉的聚合键An, An-1…A1的值都显示为NULL(这些聚合键的GROUPING函数返回值均为1.)
-- 实例
--Oracle, SQL Server, DB2
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
--在MySQL中,要将最后依据改为GROUP BY product_type, regist_date WITH ROLLUP;
【这段代码整个执行结果中每一行都是对分组后各小组中所有记录的聚合键值及sale_price字段的汇总结果。】
执行顺序:
① GROUP BY (product_type, regist_date) → SELECT
→ ② RULLUP(卷regist_date) → SELECT
→ ③ RULLUP(卷product_type) → SELECT

其中,①所有未标色的行:也是(由GROUP BY子句)最先计算出来的结果行
GROUP BY (product_type, regist_date)
原本有product_type 和regist_date两个聚合键字段,由GROUP BY子句先按照所有这两个聚合键对原表中的数据进行分组,然后再对每组中多个相同的这两个聚合键值进行汇总。
sum_price是由SUM函数对上面每组内所有的sale_price字段值进行汇总和求和计算小计的结果。
此时使用的聚合键最多,数据被分成的组数就最多,表中的记录最分散。
且每个分组之间都完全相互独立,互不重复。
即:聚合程度最低,聚合级最小,聚合单位最小。
②标红的行:是第一次执行ROLLUP
GROUP BY (product_type)
卷起由最后一个聚合键regist_date产生的分组,得到对原表中数据的新分组,然后再对每个新组中多个相同的剩余聚合键product_type的值进行汇总的结果。所以regist_date这个字段值下面都为NULL.
sum_price是由SUM函数对新分组中每个组所有的sale_price字段值进行汇总和求和计算小计的结果。
使用的聚合键越少,分成的组数越少,表中的记录就越聚集。
即:聚合程度就越高,聚合级越大,聚合单位越大。
③标绿的行:是第二次执行ROLLUP
GROUP BY ()
卷起由最后一个聚合键product_type产生的分组。此时,没有了任何聚合键,得到的新分组即为原表中的所有数据,因此也无法再对剩余聚合键进行汇总。所以product_type 和regist_date两个字段值下面都为NULL.
sum_price是由SUM函数对原表中所有的sale_price字段值进行汇总和求和计算总计的结果。
随着聚合键减少到0,数据将会恢复到表中记录的最初情况,所有的记录都聚集到一起,处在同一组中,此时表中的记录就最聚集。
即:聚合程度最高,聚合级最大,聚合单位最大。
5.1.1 GROUPING函数——让NULL更加容易分辨
GROUPING函数只能在使用ROLLUP或CUBE的SELECT查询中使用。
只要是 由减少了原本的聚合键字段 所产生的分组,都是超级分组。
该函数在其参数列的值 为超级分组中除该分组正在使用的聚合键之外 的字段 的记录所产生的NULL时返回1,其他情况返回0.
具体而言:
GROUP BY使用原本的所有聚合键的对原表中所有记录进行分组,其产生的分组均为/称为普通分组。
在普通分组中,即使某个字段的值为NULL,GROUPING函数以这些字段为参数,其返回值仍为0.
只要开始执行ROLLUP函数,即开始减少原本的聚合键(卷起由原本聚合键中最后一个产生的分组),从而产生的新分组,都是超级分组。
因此,ROLLUP函数汇总的对象均为超级分组。
对每个超级分组中 除还在使用的剩余聚合键之外 的字段值,即对之前卷起其产生的分组的聚合键(去掉的聚合键),ROLLUP都会返回NULL
在超级分组中,当GROUPING函数 以没有使用的聚合键 为参数时,其返回值就为1.
在超级分组中,当GROUPING函数 以还在使用的聚合键 为参数时,其返回值仍为0.
当该超级分组中的 还在使用的聚合键值 为NULL时,该聚合键的GROUPING函数返回值仍为0.
——————————————————————————————————
从执行结果往执行过程推导,来分辨是来自超级分组记录中的NULL,还是来自原始数据本身的NULL:
【原始数据本身的NULL经过GROUP BY分类及汇总后,都会成为普通分组中的NULL.】
在某一条结果记录中,所有的以聚合键为参数的GROUPING函数返回值:
①全部为0,则说明该条结果记录是来自于普通分组的汇总结果。
如下图中未标色的记录。
②只要有一个为1,则说明该条结果记录是来自于超级分组的汇总结果。
如下图中标红色的记录。
【因为如果当前超级分组还在使用某个值为NULL的聚合键,那么该聚合键的GROUPING函数返回值仍为0. 因此,可以确定那些GROUPING函数返回值为0的聚合键,就一定是当前超级分组还在使用的聚合键。】
③全为1时,说明该条记录就一定是对原表中所有记录的汇总结果。且只会有一条全为1的记录。
如下图中标绿色的记录。
因为ROLLUP是从最后一个聚合键(regist_date)的分组开始卷起的,因此按照SQL语句中GROUP BY子句中原本聚合键的倒序(即从regist_date开始,到product_type),对GROUPING函数的返回值依次进行判断更方便一些。
-- 使用GROUPING函数来判断NULL
--Oracle, SQL Server, DB2
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);

-- 在超级分组记录的键值中插入恰当的字符串
--Oracle, SQL Server, DB2
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
-- CASE表达式的返回值必须一致
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);

5.2 CUBE——用数据来搭积木
所谓CUBE,就是将GROUP BY子句中聚合键的 “所有可能的组合” 的汇总结果集中到一个结果中。因此,组合(不区分顺序)的个数就是 2^n 个。
一个也没有:C(n,0) = 1;
只有一个聚合键:C(n,1)= n;
有两个聚合键:C(n,2);
…
有n个聚合键:C(n,n)= 1.
全部相加,最后得2^n.
执行顺序:
FROM → WHERE
→ GROUP BY CUBE将A1,A2,…An,n个聚合键的每一种组合(由多到少,不区分顺序,共2^n种)都执行一次GROUP BY 对原表的分类及汇总操作。
→ SELECT
每执行GROUP BY CUBE一次,就执行SELECT一次,以便用SELECT中的聚合函数SUM对每组中的相应字段进行汇总求和。
GROUP BY 发挥的仍然是将原表中的记录按聚合键分组,以及将各组中多个相同的聚合键值汇总为一行的功能。
CUBE影响的是每次执行BROUP BY使用的聚合键组合,以及执行次数。
-- 使用CUBE取得全部组合的结果
--Oracle, SQL Server, DB2
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY CUBE(product_type, regist_date);

5.3 GROUPING SETS——取得期望的积木
Oracle中grouping sets 操作符的使用,可以帮你生成多种分组统计结果——米多sir
Oracle GROUPING SETS——shangboerds
Oracle group by 扩展函数详解(grouping sets、rollup、cube)—— 鱼丸丶粗面
GROUPING SETS运算符可以用于从ROLLUP或者CUBE的结果中取出每个聚合键Ai单独对原表进行分类汇总的结果。
只取GROUP BY(Ai),i = 1, 2, …n
可以排除:
① 小计或总计记录(所有的合计记录,名字叫法不一样);
② 使用多个(≥2个)聚合键对原表进行分类汇总的记录。
GROUP BY GROUPING SETS (A,B,C)
等价与
GROUP BY A
UNION ALL
GROUP BY B
UNION ALL
GROUP BY C
-- 使用GROUPING SETS取得部分组合的结果
--Oracle, SQL Server, DB2
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_tanka
FROM Product
GROUP BY GROUPING SETS (product_type, regist_date);
-- 等价于:
-- 按商品种类分组
SELECT
product_type,
'登记日期 合计' AS regist_date,
SUM(sale_price) AS sum_tanka
FROM
Product
GROUP BY
product_type
UNION ALL
-- 按登记日期分组
SELECT
'商品种类 合计' AS product_type,
CAST(regist_date AS VARCHAR(16)) AS regist_date,
SUM(sale_price) AS sum_tanka
FROM
Product
GROUP BY
regist_date;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









