






01、数据分析是每个运营的必备技能
SKU,全称Stock Keeping Unit,库存管理的基本单元。
商店里的每一件衣服、每一个电子产品,都有它独特的身份号码,这就是SKU.比如,同一款T恤的不同尺码和颜色,就会对应不同的SKU,方便商家精确管理库存和销售数据。
通常,SKU会包含品牌名、型号、颜色、尺寸、包装类型等信息,比如"Nike Air Max 270 - 黑色 - 42号 - 独立包装"。
对于买家,SKU意味着能找到需要的具体产品版本,比如大小、颜色、材质等个性化选项。
对于卖家,SKU是追踪销售、补货和定价的关键,确保不会混淆相似但不同的产品。"仅剩3件,立即购买"这样的信息,就是通过SKU数量实时更新的。
解密电商新词汇:SKU,网购界的黑话你懂了吗?
SPU,Standard Product Unit,即标准化产品单元,是商品信息聚合的最小单位。
它代表了一组可复用、易于检索的标准化信息集合,这些信息描述了产品的特性。
通俗地说,属性值和特性相同的商品可被视为一个SPU.
SPU是什么意思 SKU和SPU的区别——百度知道
SKU和SPU的区别与联系: SKU是SPU下的具体表现形式,SPU加上颜色和尺寸可以构成一个SKU.
例如:
品牌苹果型号5s可以确定一个产品,即SPU(标准化产品单元);
再加入颜色(如白色)和尺码(如4.0),即表示一个SKU(库存管理的基本单元)。
案例:
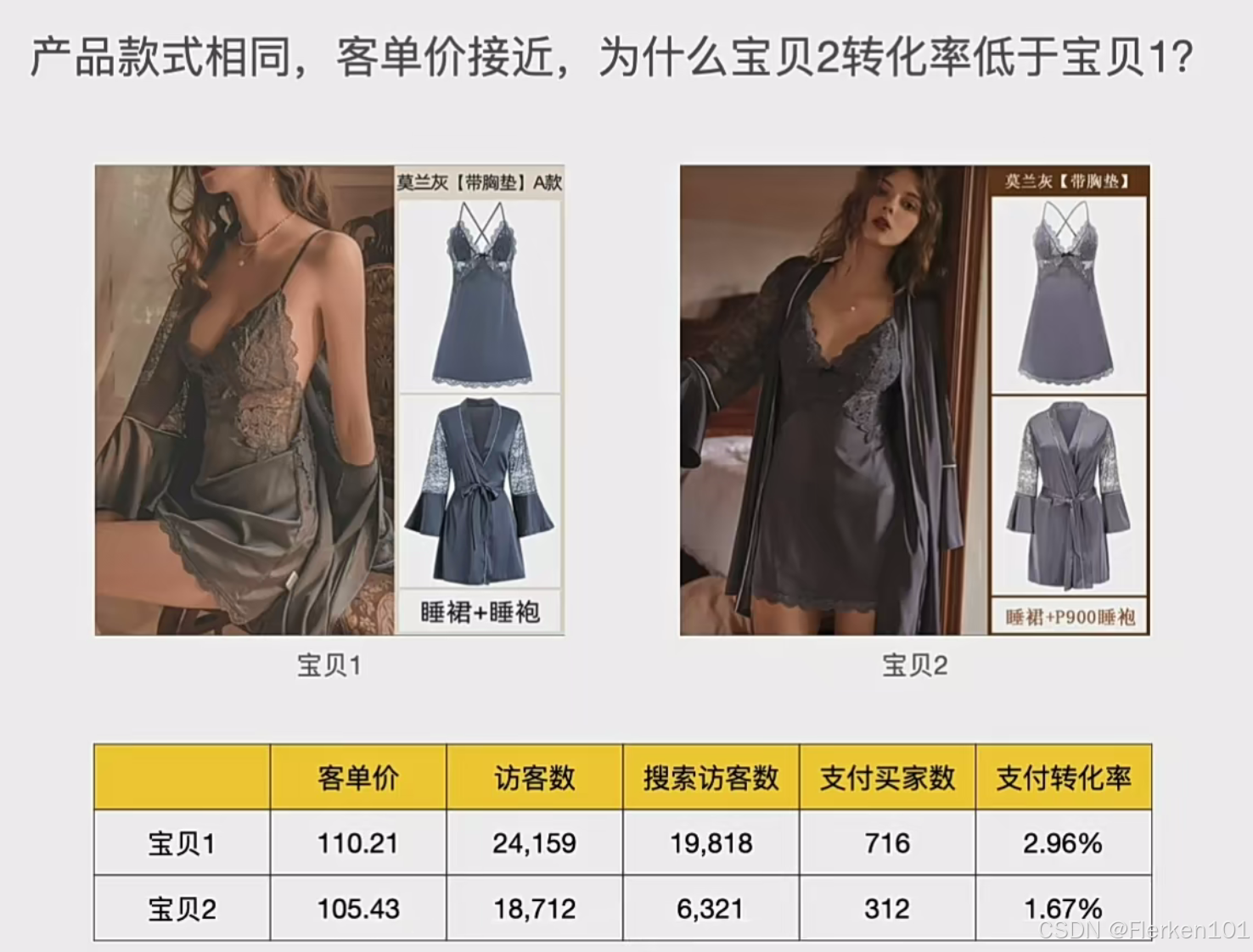
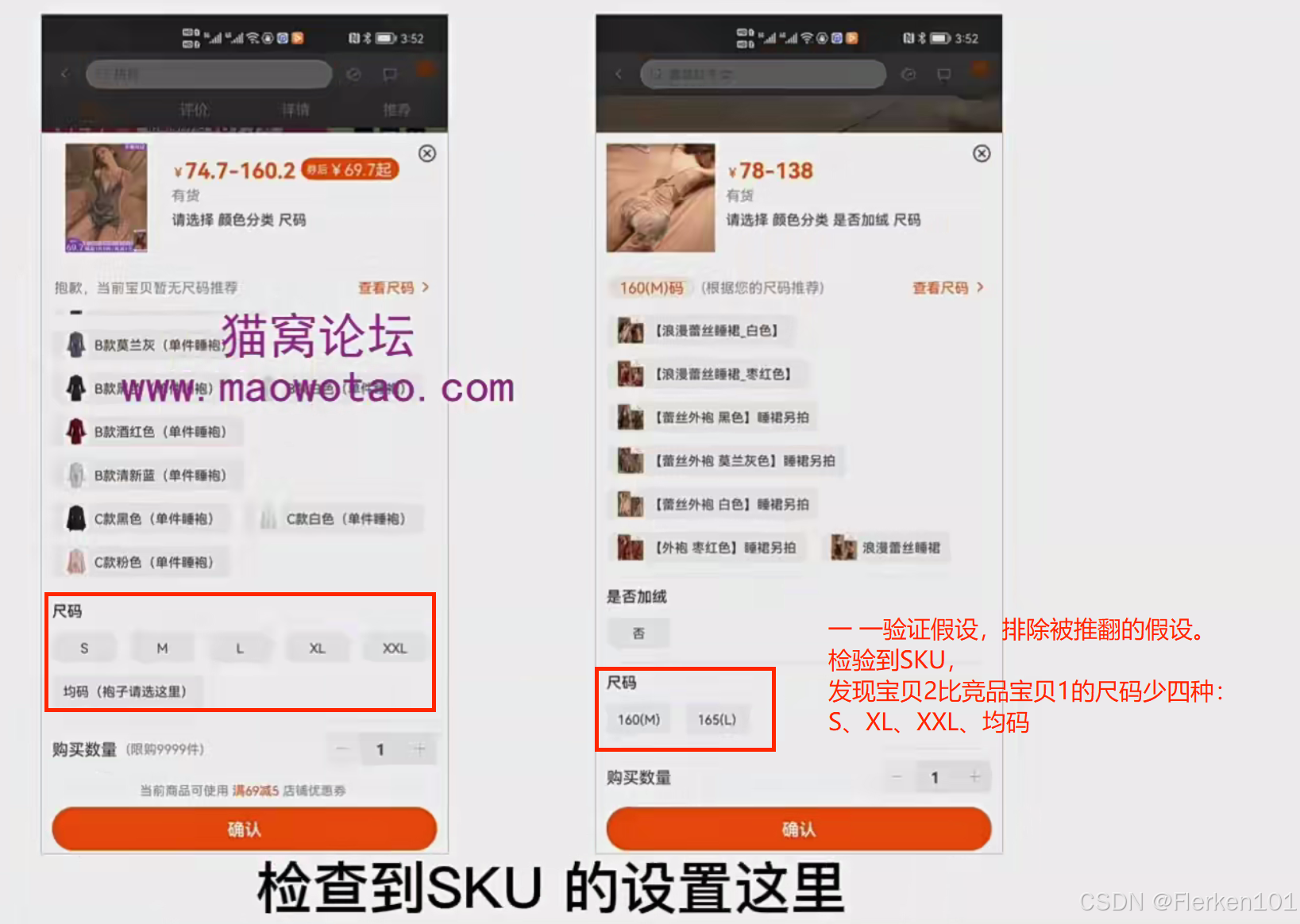
宝贝2缺失的三种尺码:S、XL、XXL,占据了宝贝1(竞品)销量的41.68%.
说明宝贝2要设置SKU,增加这三种尺码。
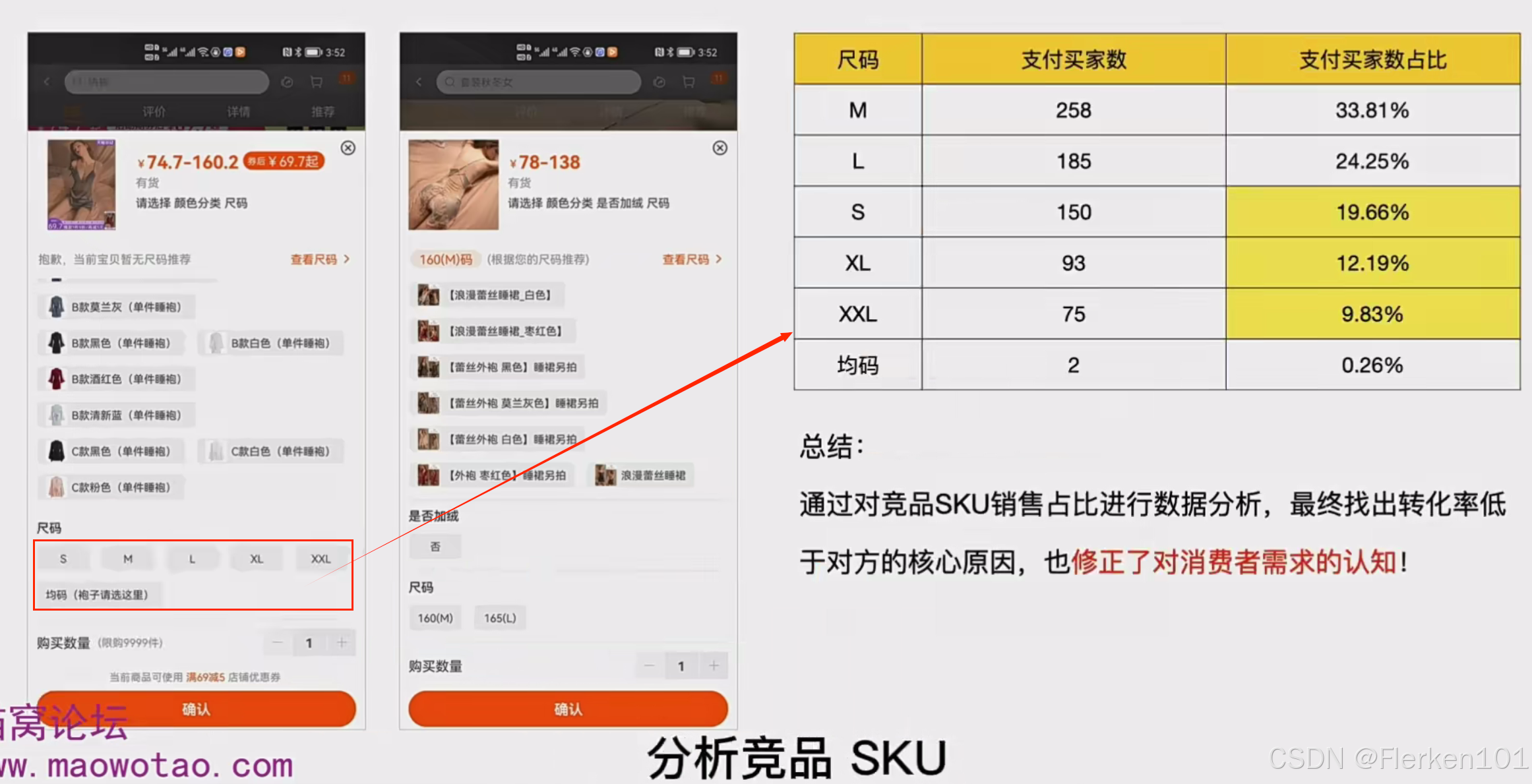
市场是动态的,消费者需求也会不断在变化。
但数据是客观的,通过数据,我们对市场,对消费者会有更准确的认知。
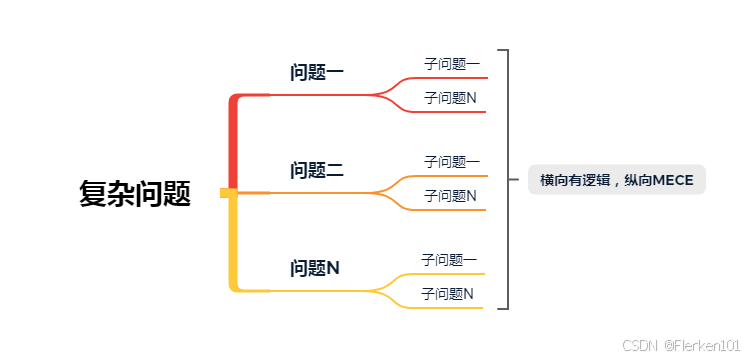
1. 不知道要分析什么,无法准确的定义问题
有时候我们自己可能也不太清楚问题到底是什么,该怎么去定义,那么这个时候我们可以:
(1) 先做个假设。
(2)然后再通过数据分析的方法,去论证我们的假设是否成立,
(3)最终定义清楚我们要解决的问题,并且找到答案。
在前文的案例中,看到这样的数据:有一个商品维度和多个数据指标。
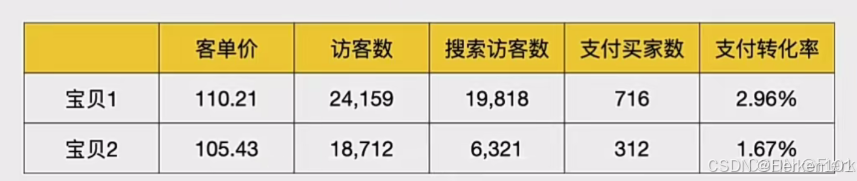
不知道要分析什么,那么就先进行假设:
①分析客单价?——发现两种商品的客单价相差不大;
②分析访客数?——那么就要看访客数的时间趋势,访客的来源渠道,访客的地域分布等;
③分析搜索访客数?——那么就要看搜索关键词的构成及其带来的访客数,搜索访客的搜索习惯,对比不同搜索渠道带来的搜索访客数等;
④分析支付买家数?——那么就要看支付买家数的时间趋势,支付买家的购买频次,支付买家的地域、年龄、性别等特征分布等;
⑤分析支付转化率?——那么就要看影响支付转化率的各个环节。
如上,为了找到问题的答案,先做了很多假设,然后一一论证和排除。
最终确定了分析的目标是“⑤支付转化率”。
确定了问题是: 为什么宝贝2的支付转化率比竞争对手的低?
而且确定了SKU,是宝贝2的支付转化率,比竞争对手低的原因所在。
2. 分析工具的功能不熟练-不会使用分析工具
主要指:EXCEL
很多场景下只需要掌握EXCEL 20%的功能,就可以解决掉电商数据分析中遇到的80%的问题了。
3. 分析效率低下,80%的时间都在复制和粘贴数据,而不是在分析
使用Power Query这样的工具,来自动做数据清洗,可以极大的降低表格的工作填写量。
只要用生意参谋下载表格,然后刷新就可以呈现出结果。
那么,把时间节约下来,就会有更多的时间去做分析。
4. 对数字不敏感,没有利用数据可视化
其实并不是每个人对数字都非常敏感,在密密麻麻的表格中。要看到数字的变化和规律,有时候其实并不是很容易的事情。
这时候建议学习一些可视化的方法,通过一些图表能更好的去观察数据,从中间找到数据的变化或者规律。
5. 不知道怎么去分析-缺少系统的分析方法
对于电商数据分析来说,大部分数据都来自于电商平台。
平台其实已经定义好很多数据维度了,我们只需要在平台定义的基础之上,用好几个常用的方法,就可以做好很好的分析。
还可以积累很多常见的数据分析模型,在没有分析思路时,帮助自己构建分析思路。
见04、常见的数据分析模型
很多成熟的分析模型,前人都做了大量的调研和分析,且经过了大量案例的论证;而且还具备一定的理论基础, 所以使用分析模型可以让自己的论证过程更具备逻辑性和条理性,同时也让结论更具备说服力。
6. 不懂电商业务,无法构建电商业务分析模型
不懂电商业务,无法构建出电商业务的分析模型,其实是最难解决的一个问题,决定了做数据分析这件事情的上限在什么地方。
需要对电商企业,对店铺的业务模式有充分的了解。
而每个企业的经营模式不同,所需要的分析模型也不太一样。
如果对业务完全不了解,哪怕工具用的再熟练,其实也很难做出很好的分析。
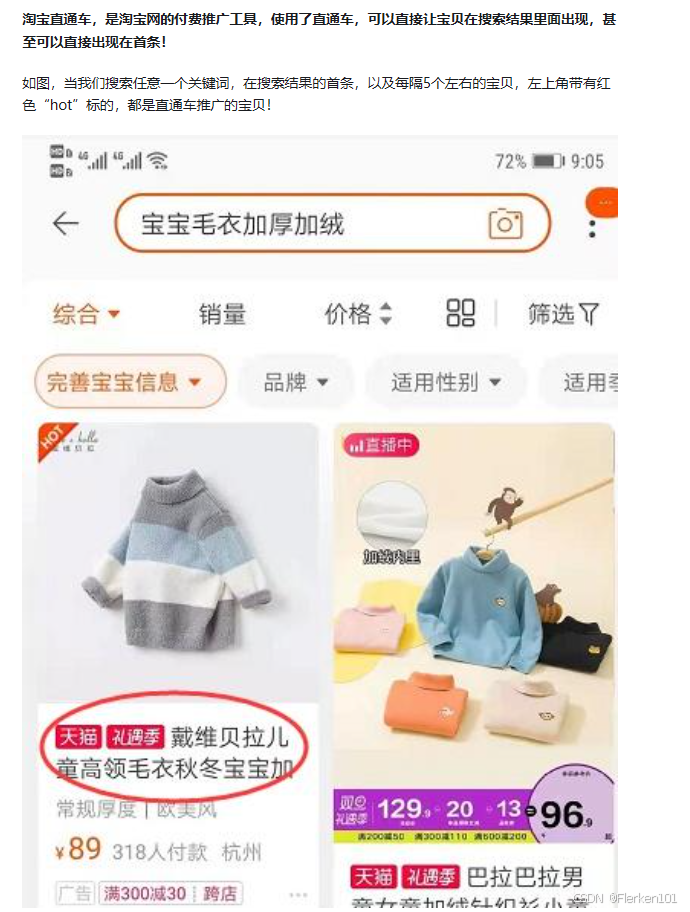
比如:如果都不了解直通车拉升搜索的底层逻辑,那么怎么可能构建出一个特别有效的分析表格,用来去分析其中拉升效率呢?
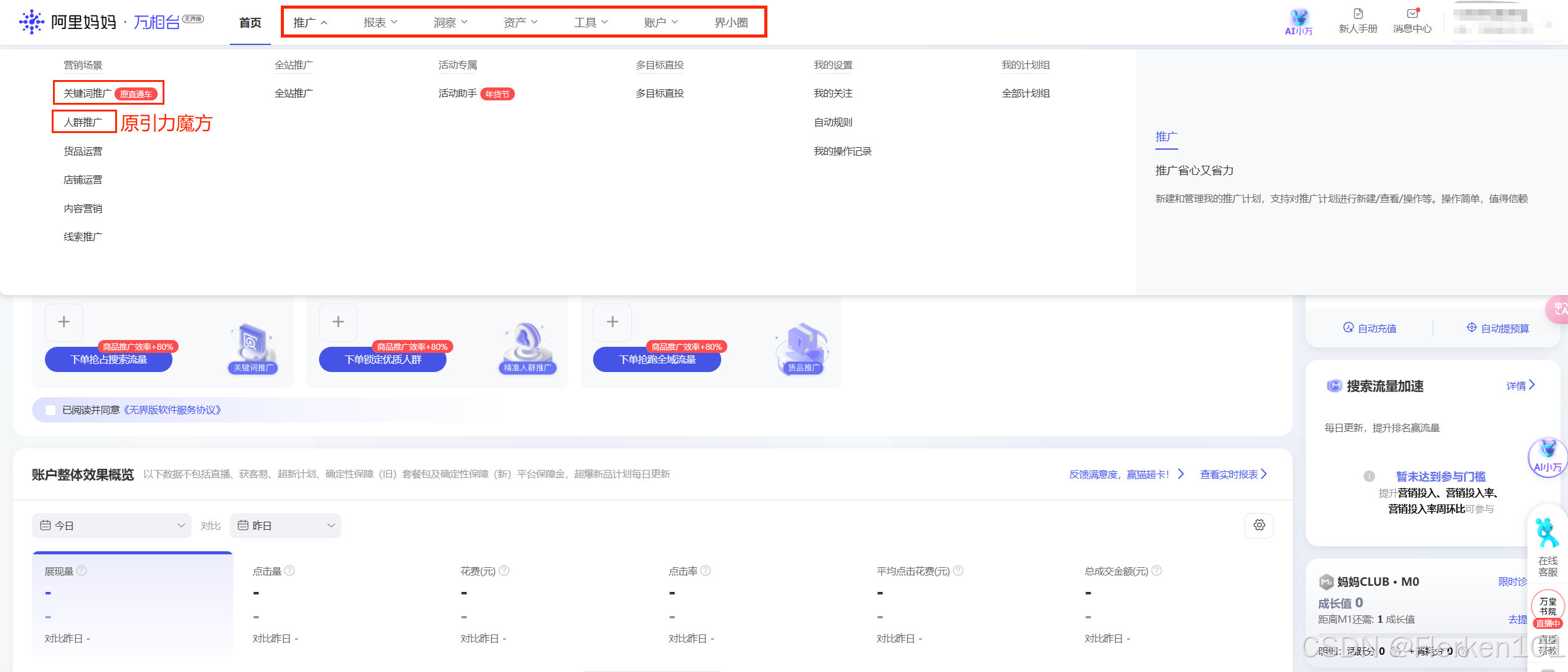
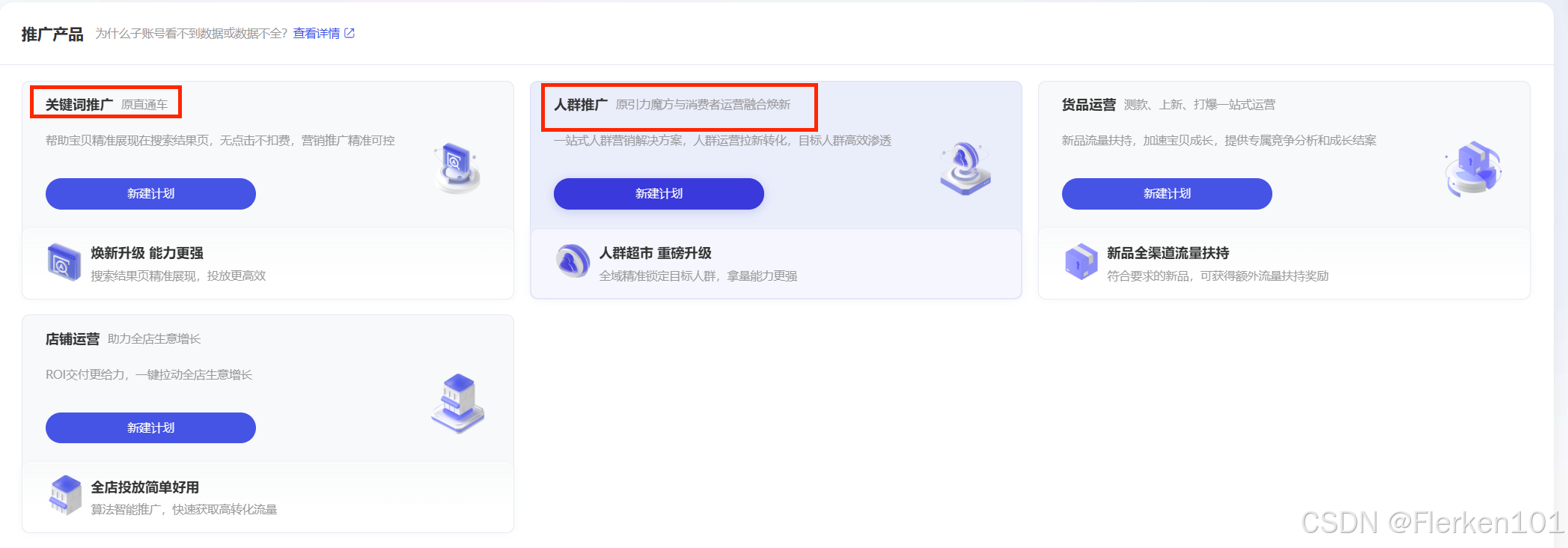
淘宝直通车已停运,变为“万相台无界版”中的“关键词推广”,但是底层原理没有发生根本性变化。
在搜索结果界面的标志也没有发生变化,仍是左上角显示“HOT”。
万相台无界版关键词推广的基本逻辑——海蓝邦

淘宝的流量主要分为免费流量和付费流量,前期主要是做免费流量。
免费流量包括手淘搜索、手淘首页、拍立淘、购物车、微淘等;
付费流量包括关键词推广(原直通车)、超级推荐、淘宝客等。

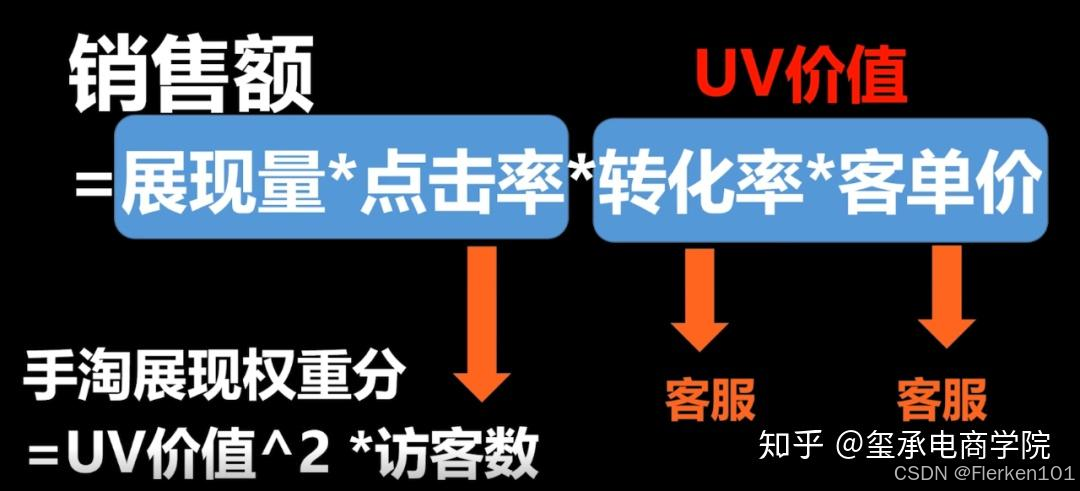
手淘展现权重分影响着商家在手淘的展现机会,权重分越高,展现机会就越多,反之则越少。
(这里的手淘展现,主要是指手淘免费流量,包括手淘搜索。)坑产,即坑位产出。通常会说是GMV销售额。
可以这样理解“坑位”,产品在某一个类目(即搜索关键词),经搜索就会出现该商品的展位,该方形图文展位就是你产品的“坑位”,例如淘宝的童鞋。手淘展现的核心公式是:
手淘展现权重分 = UV价值 * 坑产
手淘展现权重分 = (客单价 * 转化率) *(点击人数UV * 转化率 * 客单价)
手淘展现权重分 = 客单价^2 * 转化率^2 * 点击人数UV
手淘展现权重分 = (UV价值) ^2 * 点击人数UV通过下面的图片可看出,客服通过询单可以提升转化率,通过关联推荐可以提升客单价,这两个指标都直接影响我们的销售额和手淘展现权重。所以客服在平时的工作中就显得尤为重要。

什么是淘宝直通车?一文看懂!——资深电商人樊剑
直通车推广6大误区,看完少亏10w+,速看!!!——资深电商人樊剑



其三:测试数据,包括:测款、测图、测词、测人群。



营业收入/销售收入中,不包含利润,也不直接扣除成本(也不包含成本)。
但营业收入是计算利润的基础。
根据营业收入计算利润,有两种方式:
①利润是营业收入减去相关成本和费用后的结果。
②利润是营业收入乘以利润率的结果。
ROI,ROAS,ACos三个概念理解——Robin
(1)净利润ROI = (销售额 - 所有成本)/ 所有成本 ,常常简称ROI,也叫投资回报率;其中,所有成本 = 直接成本 + 间接成本,其中广告费包含在直接成本中。
净利润ROI大于0代表有纯收益。(2)营收ROI = 销售额 / 所有成本,也叫投产比。
营收ROI大于 1/毛利率 代表有纯收益。ROAS,Return on Advertising Spend.
① 广告的 营收ROI = 广告的投产比 = ROAS = 广告费 : 销售额 ;
亚马逊术语:ACos,广告费在总销售额中的占比
ACos = 广告费 / 销售额 * 100%
ACos,通俗点儿说就是广告费在总销售额中的占比。②或者将公式倒过来,广告的营收ROI = 广告的投产比 = ROAS = 销售额 / 广告费 ;
(①②两种计算方式都会采用,但更多的使用②.
所以一定要清楚ROAS的统计口径,以及计算方式是什么。)【即使是计算方式②,ROAS ≠ 营收ROI 】
如果计算方式是②,ROAS通俗点儿说,就是销售额是广告费的几倍。
不管是营收ROI还是净利润ROI,都是越高越好(在同一外界环境下,成本可假定不变)。
ROI越高意味着投资效益越好。
下面图里的营收ROI,应该改为直通车这种广告费用的ROAS,而且计算方式为②,即 销售额 / 直通车广告费。

搞清楚淘宝直通车带动搜索流量的底层逻辑,就能快速实现弯道超车——电商前沿君_

业务问题需要在工作中间不断的积累,加强自己对业务的理解能力。
相信随着对业务的理解能力越来越通透,分析效率和分析模型也会越来越好。
02、电商业务数据的三要素
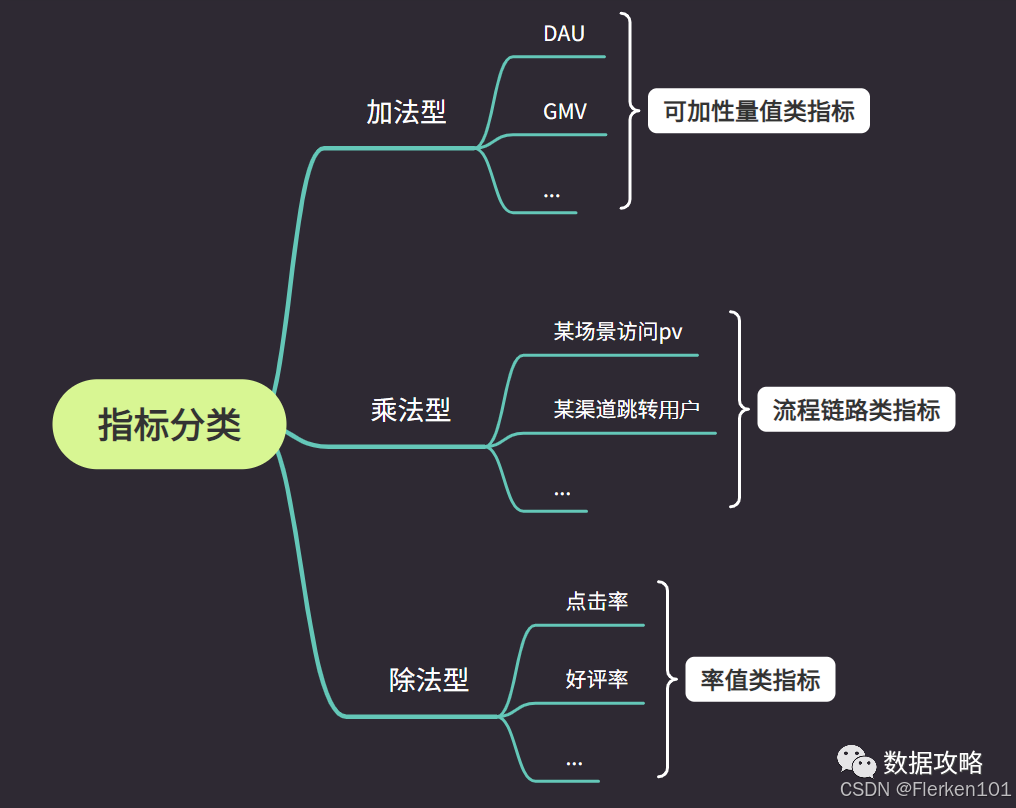
(1)指标【最常用】
(2)维度【最常用】
(3)分析方法
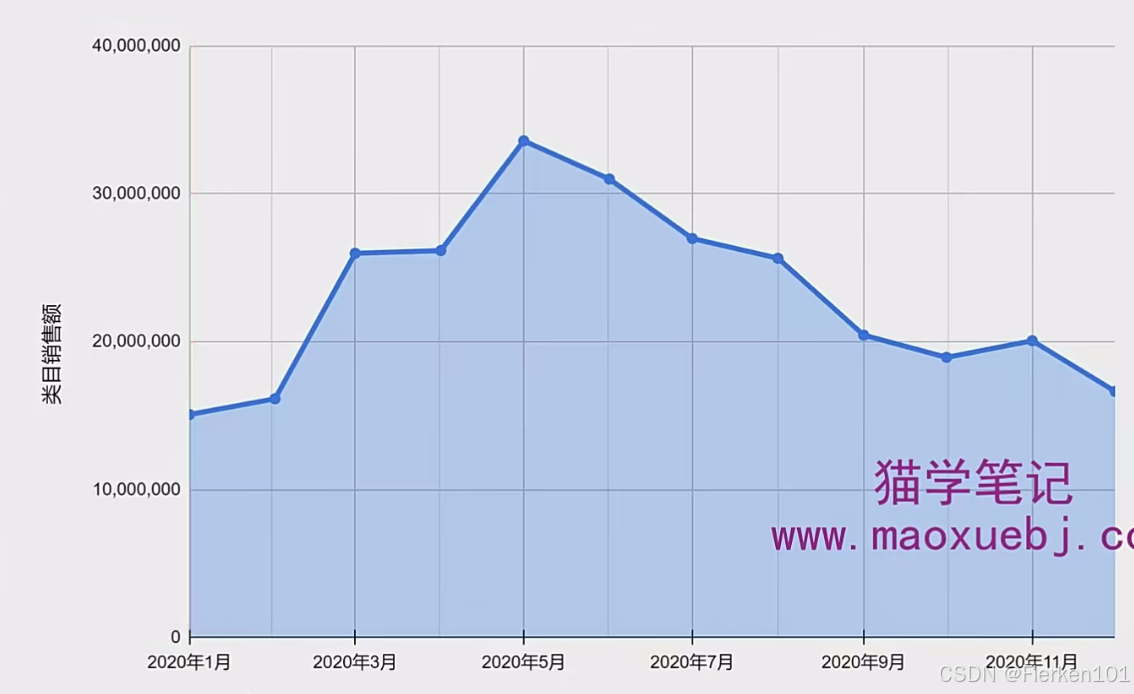
在数据分析的图表里面,横坐标轴放置的一般都叫维度,竖坐标轴放置的一般都叫指标。
在这个图里面,横坐标轴就是时间维度,而竖坐标轴放置的是类目销售额指标。
2.1 要素一:指标【最常用】
指标是用于衡量事物发展程度的具体数值,一般都是可以量化的数据。
在电商运营领域,用来衡量运营情况的核心指标:
访客数、 销售额、客单价、访客价值、点击率、转化率、加购率、毛利率等
生意参谋中已经非常的清晰地,展示了其各种指标的含义:
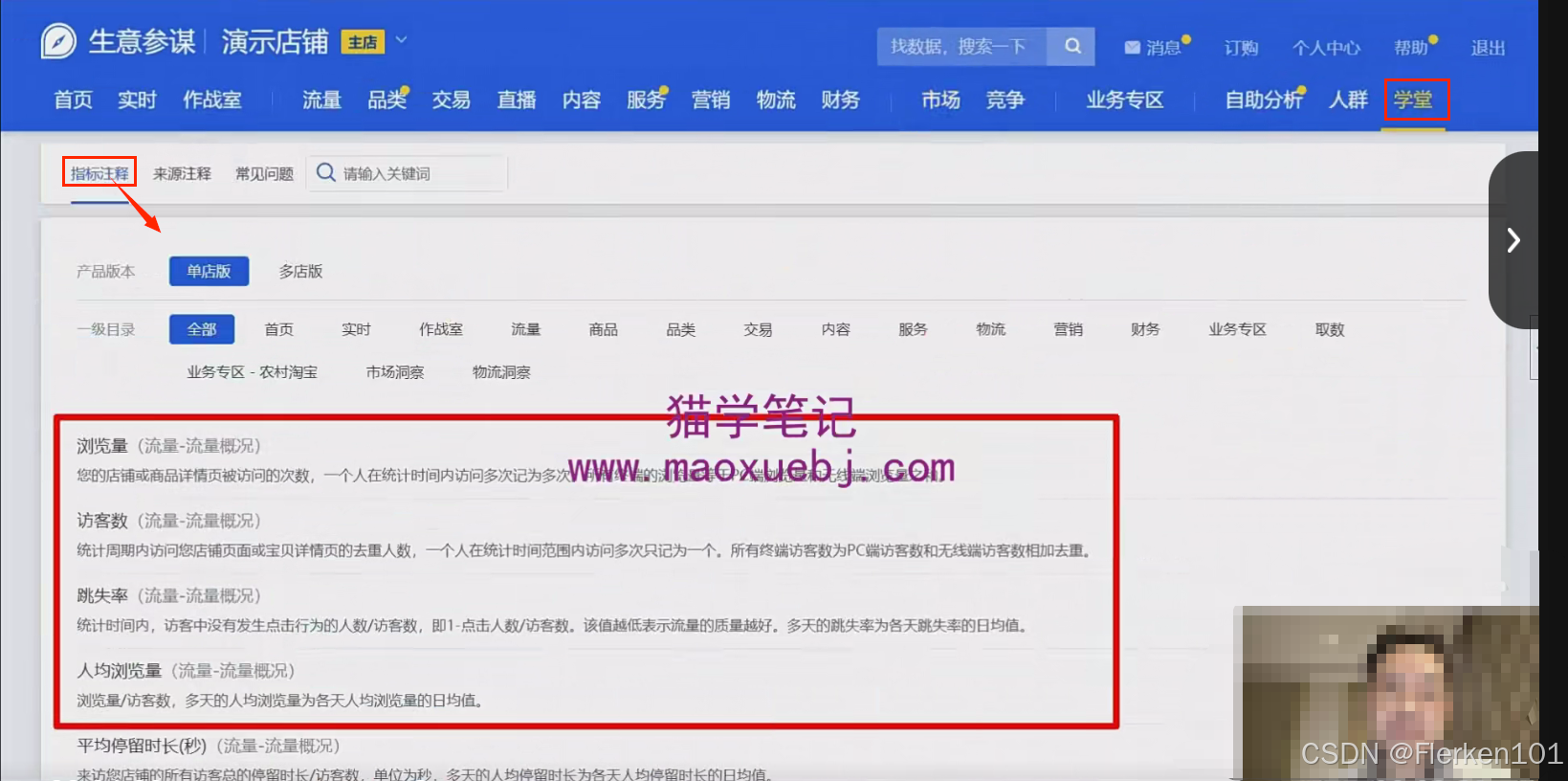
2.2 要素二:维度【最常用】
维度是指事物或者现象的某种特征。
例如:一般是从某种角度出发,进行数据统计。那么这个角度就可以说是一个维度。
电商常见的维度有:渠道、地区、时间、用户、类目、品牌、商品、店铺等。
比如:关键词的人群画像,就有从性别角度,来描述这个关键词(轻奢品牌)的人群特征,那么性别就是一个维度。
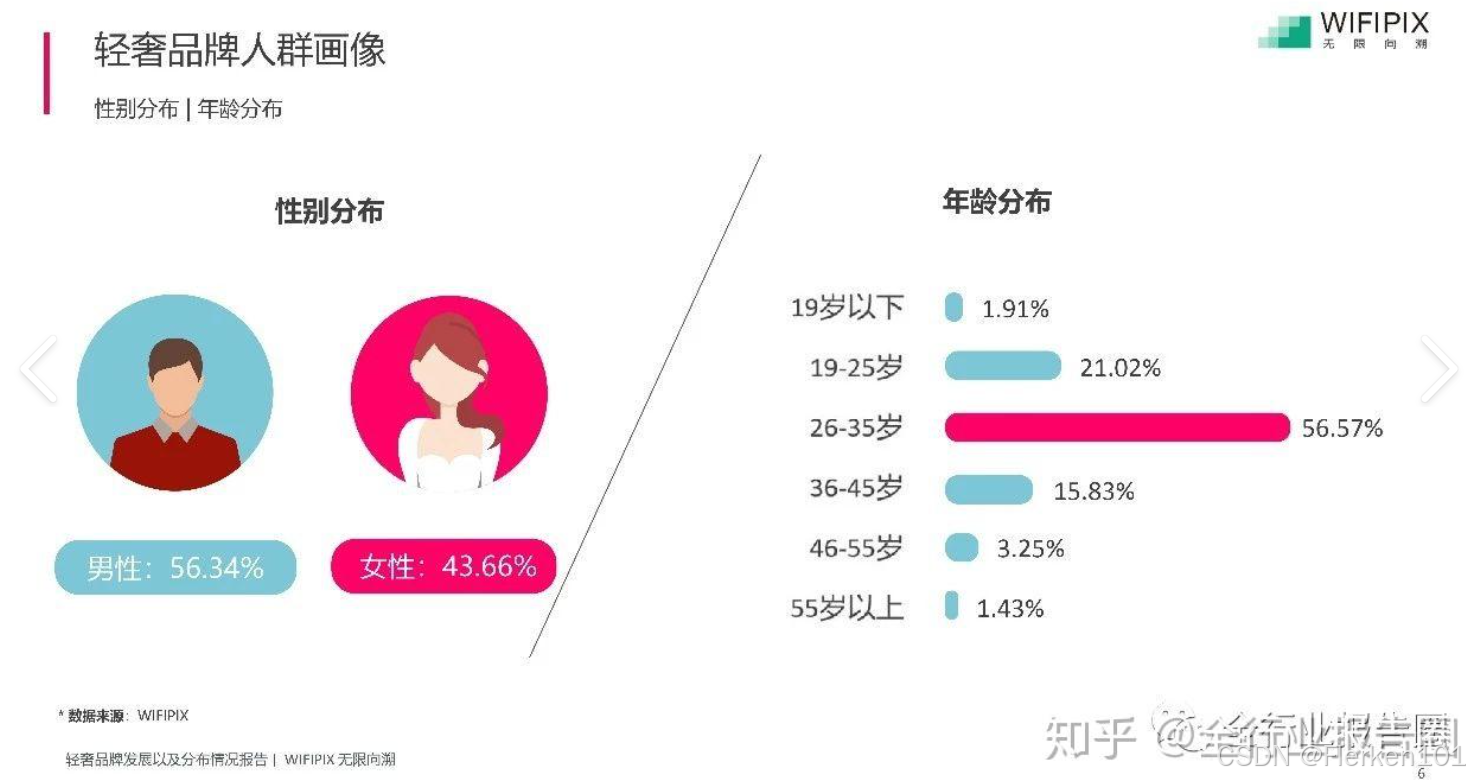
天猫八大人群,是基于天猫平台全品类消费数据,所归纳出的具有不同特征的八类消费者群体画像,并非针对某个特定品牌或品类。
每个人群画像中的内容,包括以下几个维度:
①人口统计学维度(年龄、性别、地域);
②社会经济维度(收入、职业与社会地位);
③消费行为维度(消费偏好、购物习惯);
④心理与价值观维度(生活态度、消费观念)。


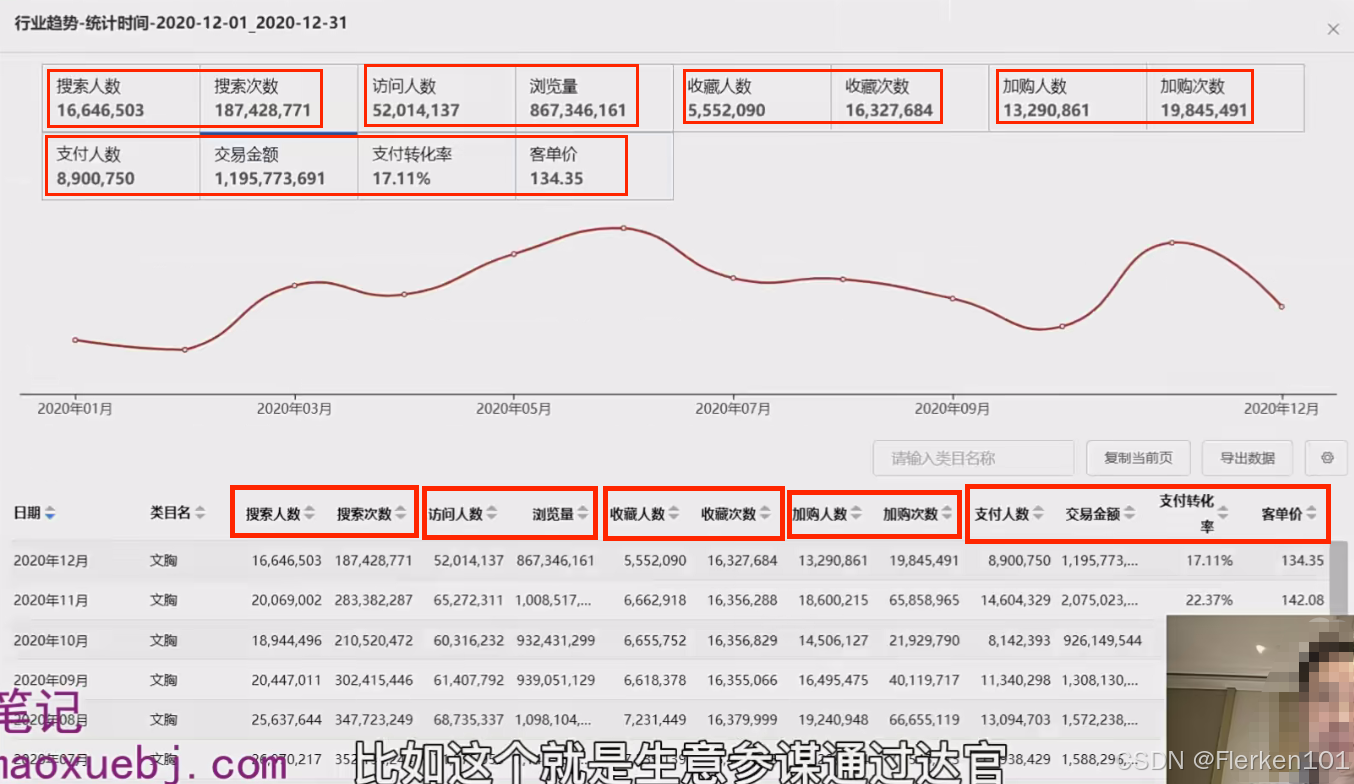
下图中的维度就是时间,反映了行业的交易金额在月度上的变化情况。
可以看到行业在这一年每个月的大盘体量的走势。
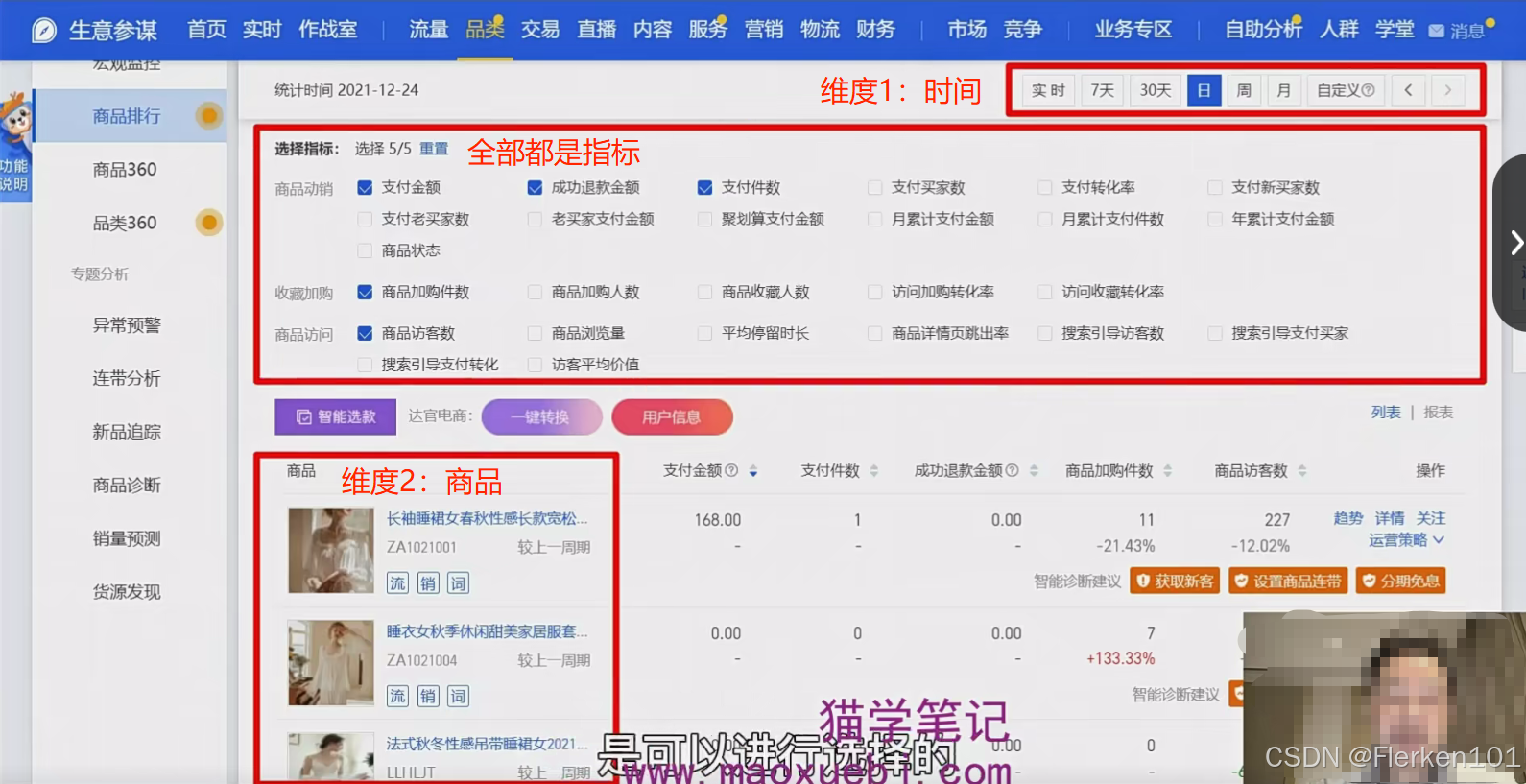
达官电商的 “智能选款” 功能,就是通过横向对比多个宝贝的数据指标,从而找到店铺的优质宝贝。
2.3 要素三:分析方法
2.3.1 最常用分析方法一:对比
将两个或两个以上的数据进行比较,分析它们的差异,从而揭示这些数据所代表的事物发展变化情况和规律性。
它可以非常直观地看出事物某方面的变化或差距,并且可以准确、量化地表示出这种变化或差距是多少。

纵向比较中的同比和环比:
【同比,与同期相比,可反应长期变化趋势。】
“同期”的意思为:
①月的同比——减去和除以的月份不变,其它比“月”大的日期单位,即年份在变;
②日的同比——减去和除以的日不变,其它比“日”大的日期单位在变。
即:日的月同比 中的 日不变, 月在变;日的周同比 中的 日不变,周在变。
【环比,与前面的临期相比,可反应短期变化趋势。】
“上期”的意思:连续2个统计周期中的前一个
年环比——减去和除以的年份往前推1;
月环比——减去和除以的月份往前推1,其它比“月”大的日期单位,即年份不变;
日环比——减去和除以的日往前推1,其它比“日”大的日期单位,即年份、月均不变。

年环比= (本年的值 - 上一年的值)/ 上一年的值
月环比=(本月的值 - 上一个月的值)/ 上一个月的值
月同比=(本年本月的值 - 上一年同一月的值)/ 上一年同一月的值
日环比=(今日的值 - 昨日的值)/ 昨日的值
昨日的日期直接减1即可。
日的月同比 =(本月本日的值 - 上个月同一日的值)/ 上个月同一日的值
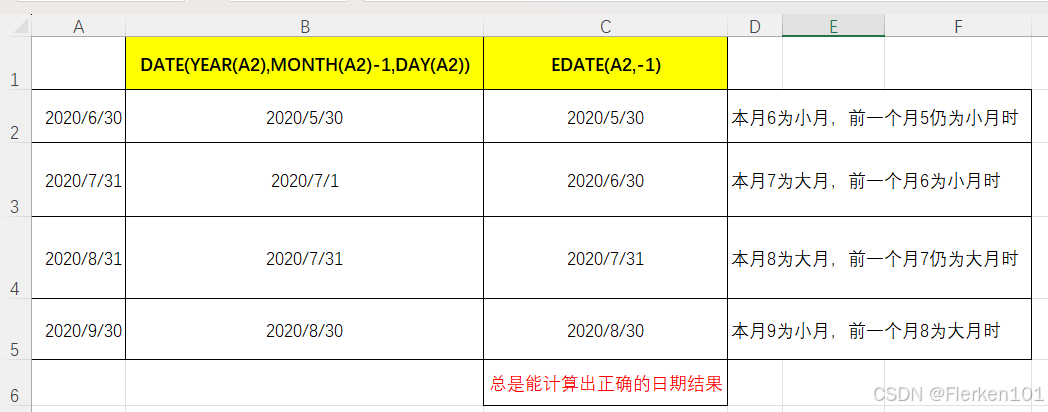
计算上个月同一日的日期:
①如果使用DATE(YEAR(本年本月本日), MONTH(本年本月本日)-1, DAY(本年本月本日))
DATE函数在碰到本月为有31天的大月,上月为小月时,为了得到有效的日期,会将得到的日期数往后推1天。
如2020年7月31日,根据上面的公式,返回值为2020/7/1.(将2020/6/30往后推了一天。)②如果在实际工作中,需要当前日期,前一个月同一日的最准确日期,可以使用EDATE函数。
EDATE(2020/7/31,-1)将返回2020/6/30.
使用EDATE函数,总能计算出当前日期,往前或往后推n个月的正确日期。
日的周同比 =(本周本日的值 - 上周同一日的值)/ 上周同一日的值
上周同一日的日期直接减7即可。
2.3.2 最常用分析方法二:细分
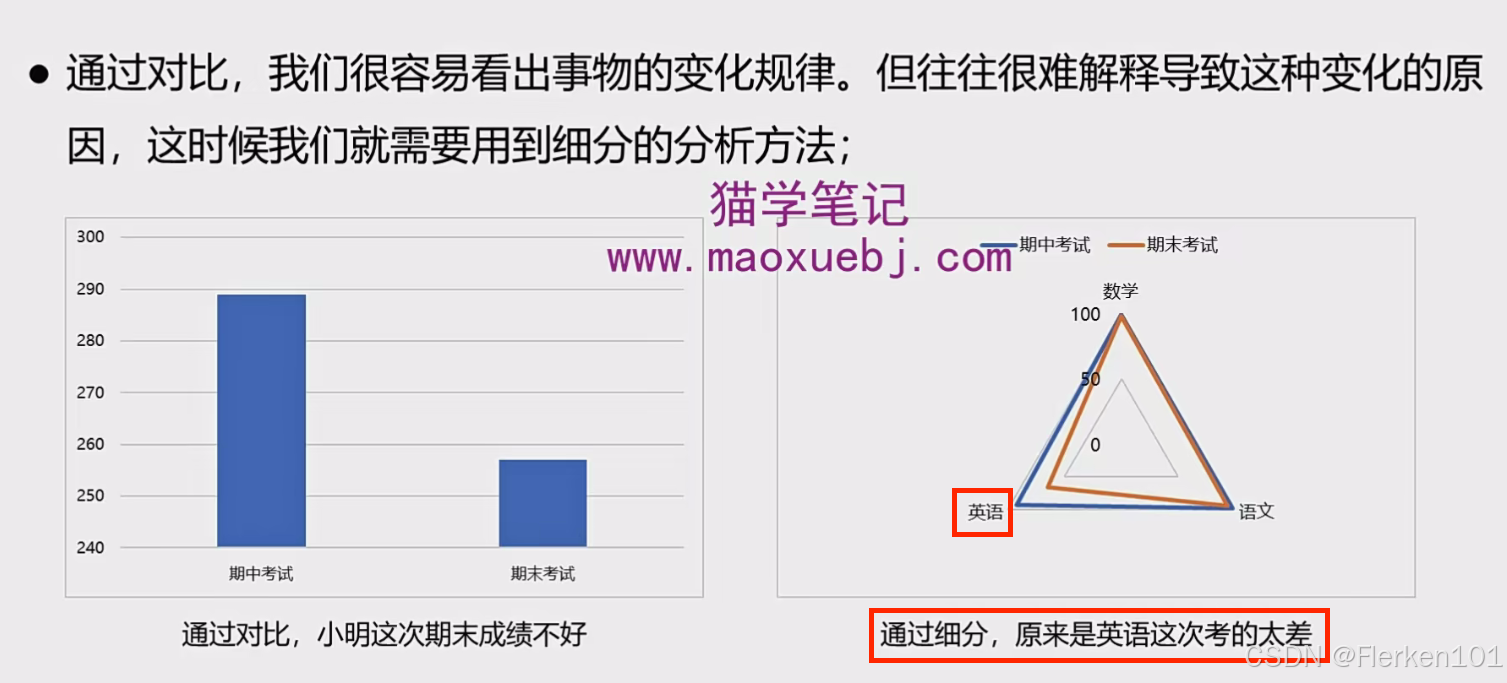
在电商运营的时候也会有类似的问题,比如今天访客数对比昨天下降了5%.
如果只是看今天访客的数据,很难知道具体下滑的原因。
但如果再对不同的流量渠道做分析,就很有可能找到下滑的主要原因是什么。
基本上只要能作为维度的,很多都是可以用来进行细分分析的。
除了下图中的渠道、地区、时间和用户,还可以进行类目、品牌、商品、店铺等等的细分分析。

2.3.3 最常用分析方法三:趋势分析

趋势分析在电商数据分析中非常重要。
专门以时间作为维度的趋势分析:
——是对比分析中,同一事物,在不同时期的纵向比较;
——也是对比分析中,同类但不相同的事物,在时间维度/层次上的横向比较;
——也是细分分析中,按时间维度进行的细分分析。
一般来说,趋势分析,主要就是看拐点以及差异点。
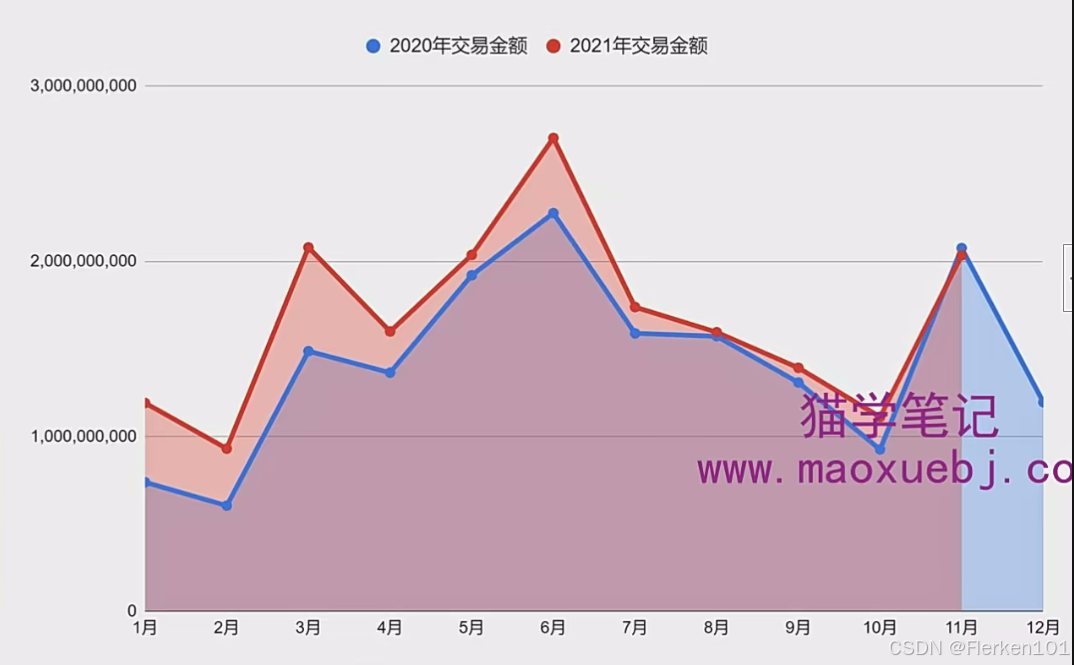
2.3.3.1 拐点(纵向对比分析)
拐点:一般指两边的曲线夹角小于90度的点。
可以看到这张图上,每种事物(每年的交易金额)对应的每条折线图,都有三个拐点,分别出现了在三月份,六月份和十一月份,有一种非常强烈的季节性的变化。
(这是一种文胸的两年成交金额折线图,所以会呈现出这种季节性的趋势。)
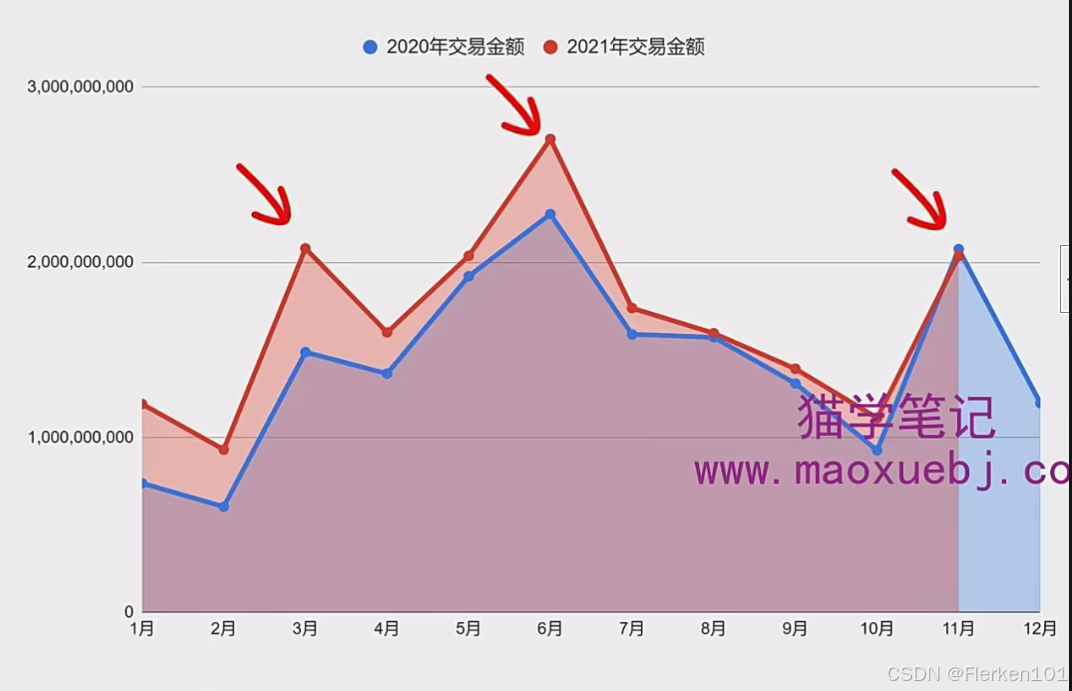
2.3.3.2 差异(纵向对比分析)
纵向对比分析:一般指在同一个维度和同一个指标下,同一个事物,在不同时间点上的差异对比。
例1:
同一个维度:时间;
同一个指标:交易金额;
同一个事物:2020年的交易金额 或 2021年的交易金额;
不同时间点上:在不同的月份中。
————比如这个图,可以通过对比2021年每个月交易额的变化幅度,来推断2021年12月的交易金额。
例2:
同一个维度:时间;
同一个指标:交易金额;
同一个事物:2020年的交易金额 与 2021年的交易金额 之间的差值;
不同时间点上:在不同的月份中。
————比如这个图,可以通过对比2020年和2021年,每个月交易额差异的变化幅度,来推断2021年12月的交易金额差异。
趋势分析在电商场景中的应用:

2.3.4 生意参谋中的分析方法
虽然数据分析的方法有很多种,但在电商运营的数据分析里,使用最多的还是以上三种方法。
如果留意观察,会发现生意参谋基本上都是不断地,用这三种方法,在不同的指定时间周期内,做各种维度的,数据指标的呈现。
2.3.4.1 店铺监控——对比法
对比分析:
将两个或两个以上的数据进行比较,分析它们的差异,从而揭示这些数据所代表的事物发展变化情况和规律性。
它可以非常直观地看出事物某方面的变化或差距,并且可以准确、量化地表示出这种变化或差距是多少。
比如生意参谋中店铺监控的功能,就是在固定的时间周期内,在被监控店铺的维度上,进行各种数据指标的对比分析。
通过这样的对比分析,就可以很容易地知道在这个时间周期内,哪些店铺,在什么指标上表现更好。
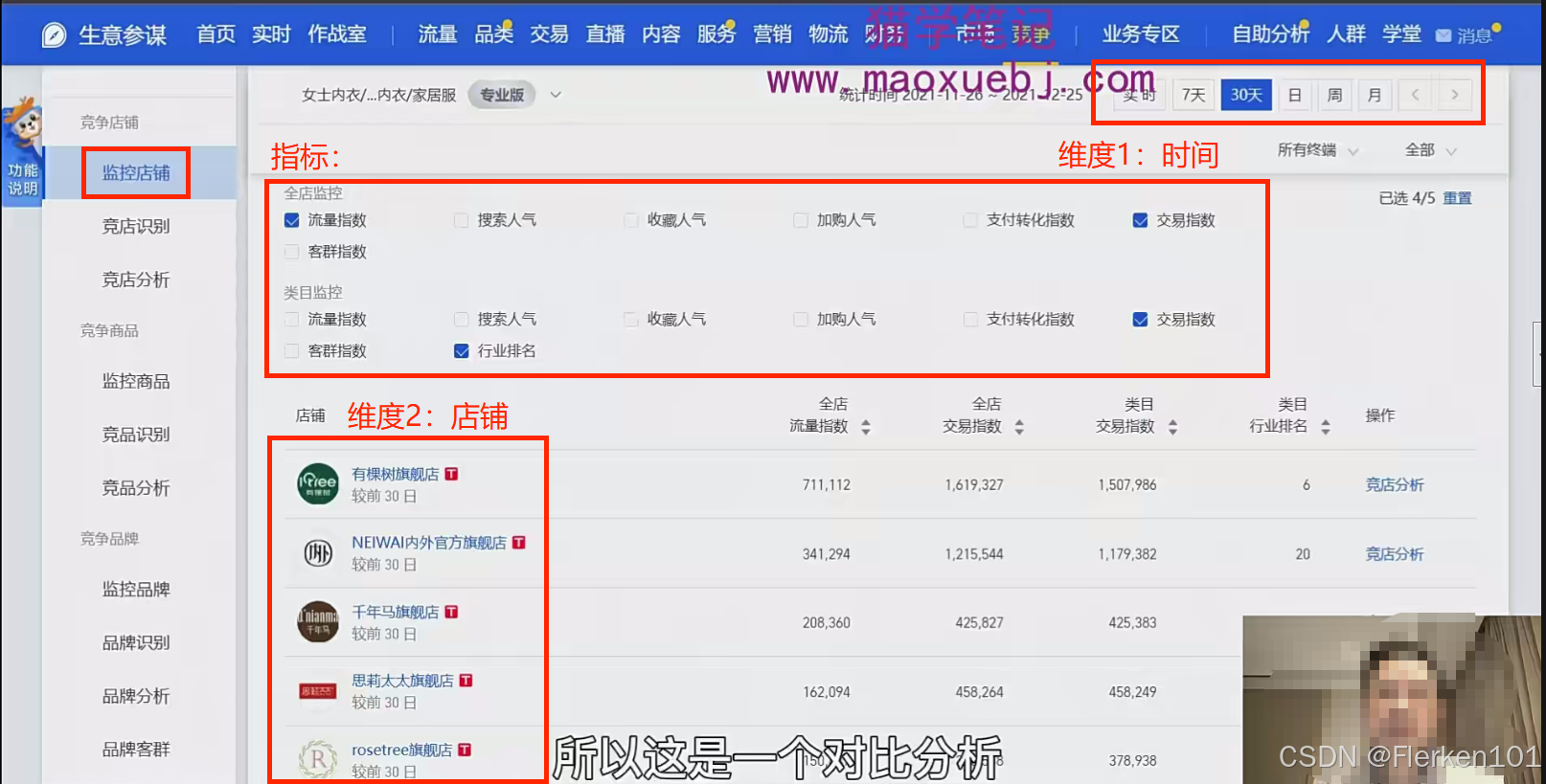
2.3.4.2 运营视窗——对比法
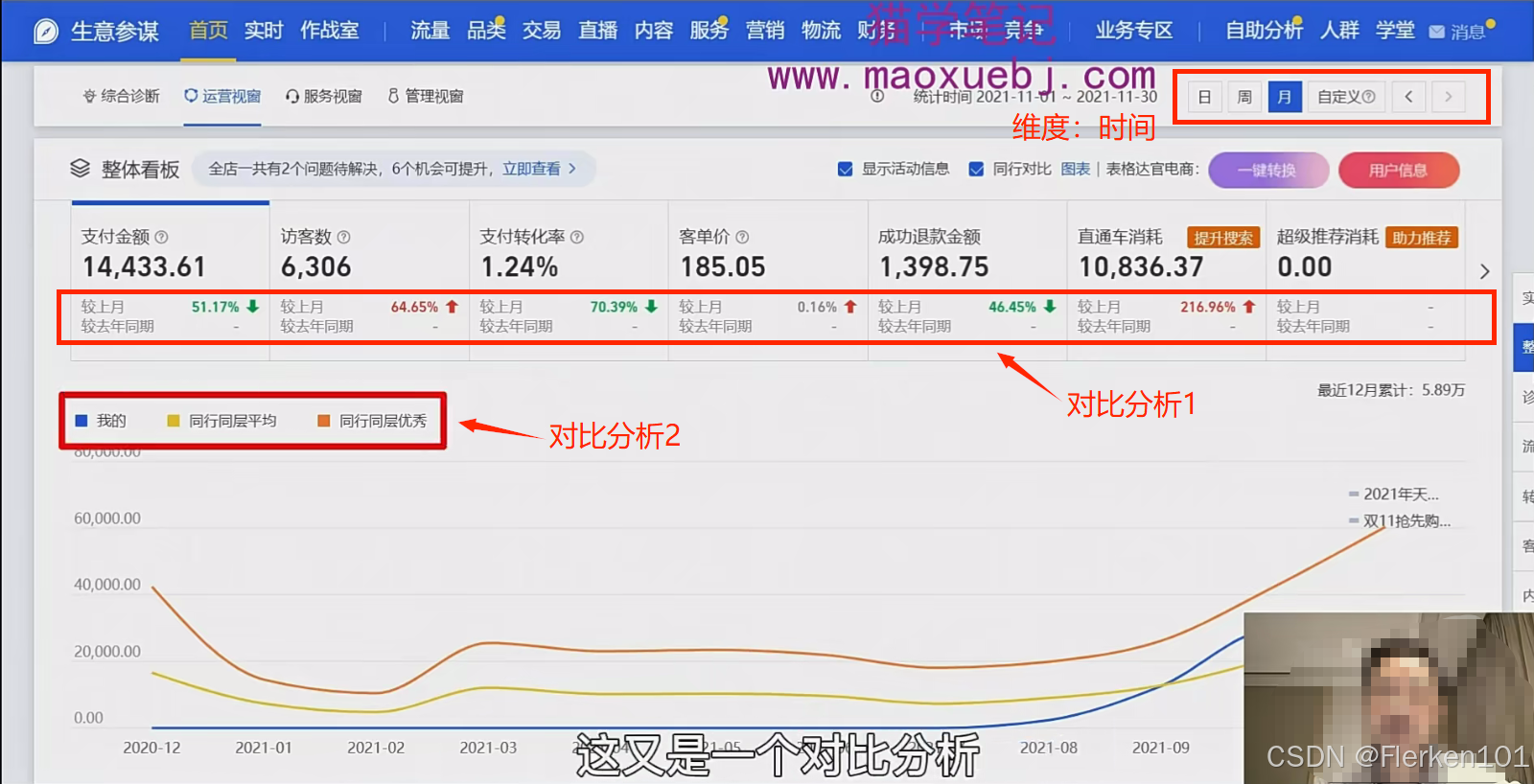
再比如,生意参谋首页的“运营视窗”也呈现出了一个店铺,在时间维度上,不同的数据指标的变化趋势。
所以每天通过这个地方,就可以很容易地知道,店铺昨天的运营情况怎么样,判断运营情况的好坏。
同时,在下方,生意参谋还显示了一个同行的情况,这又是一个对比分析。
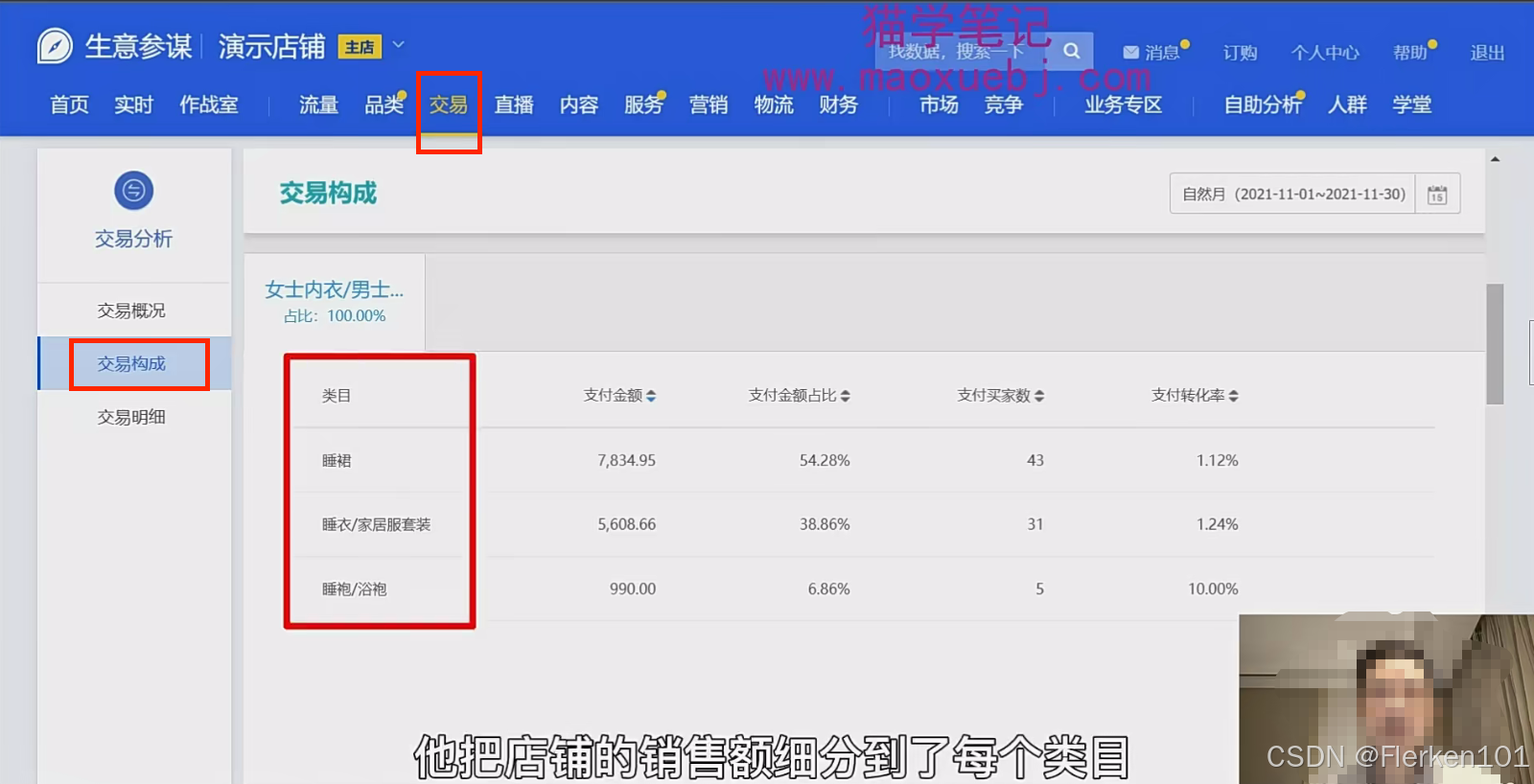
2.3.4.3 交易构成——细分法
生意参谋交易模块,里面的交易构成,把店铺的销售额细分到了每个类目,从而让我们很清晰的知道店铺主要是在哪个类目里面经营。
2.3.5 电商数据分析万能公式
电商运营的数据分析好像可以用这样一个万能的公式来表达:
①在…周期内(时间维度) ———— 要素一:维度
②…维度下(商品、店铺维度等) ———— 要素一:维度
③…数据指标的 ———— 要素二:指标
④趋势分析 / 细分分析 / 对比分析 ———— 要素三:分析方法

03、数据分析的流程及模型
数据分析的本质:

数据分析并不只是套用一些表格,更重要的它是一个完整的分析过程。
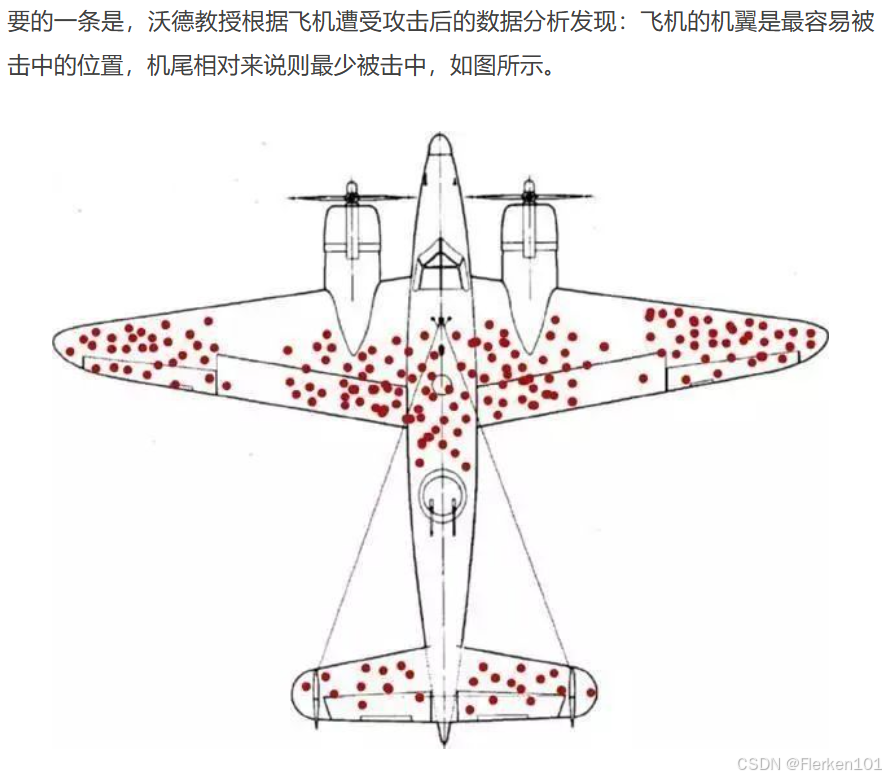
大型客机的发动机通常在机翼下方,而小型飞机或战斗机的发动机在尾部。
下例中的飞机是战斗机,发动机在尾部。
终于有人说清楚 “幸存者偏差” 了——CMKT咨询圈
要保护幸存者中,受到的攻击更少之处。(因为正是由于受到的攻击少,所以才能幸存。)
幸存者中,受到的攻击更多之处,反而是其最不需要担忧的方面。

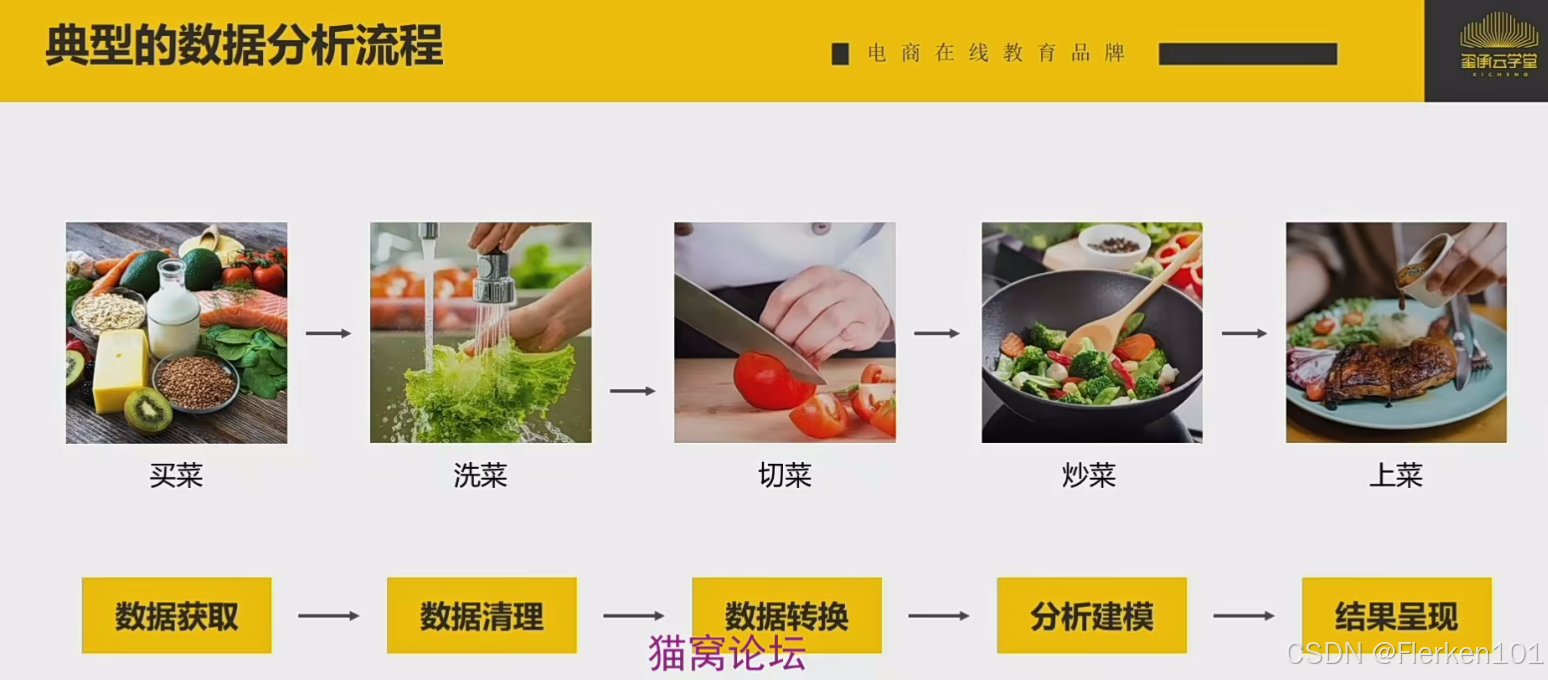
数据分析其实是一个不断循环的过程,每天打开生意参谋后台,分析昨天的数据,然后再根据昨天的数据调整今天的策略。每天不断的重复。
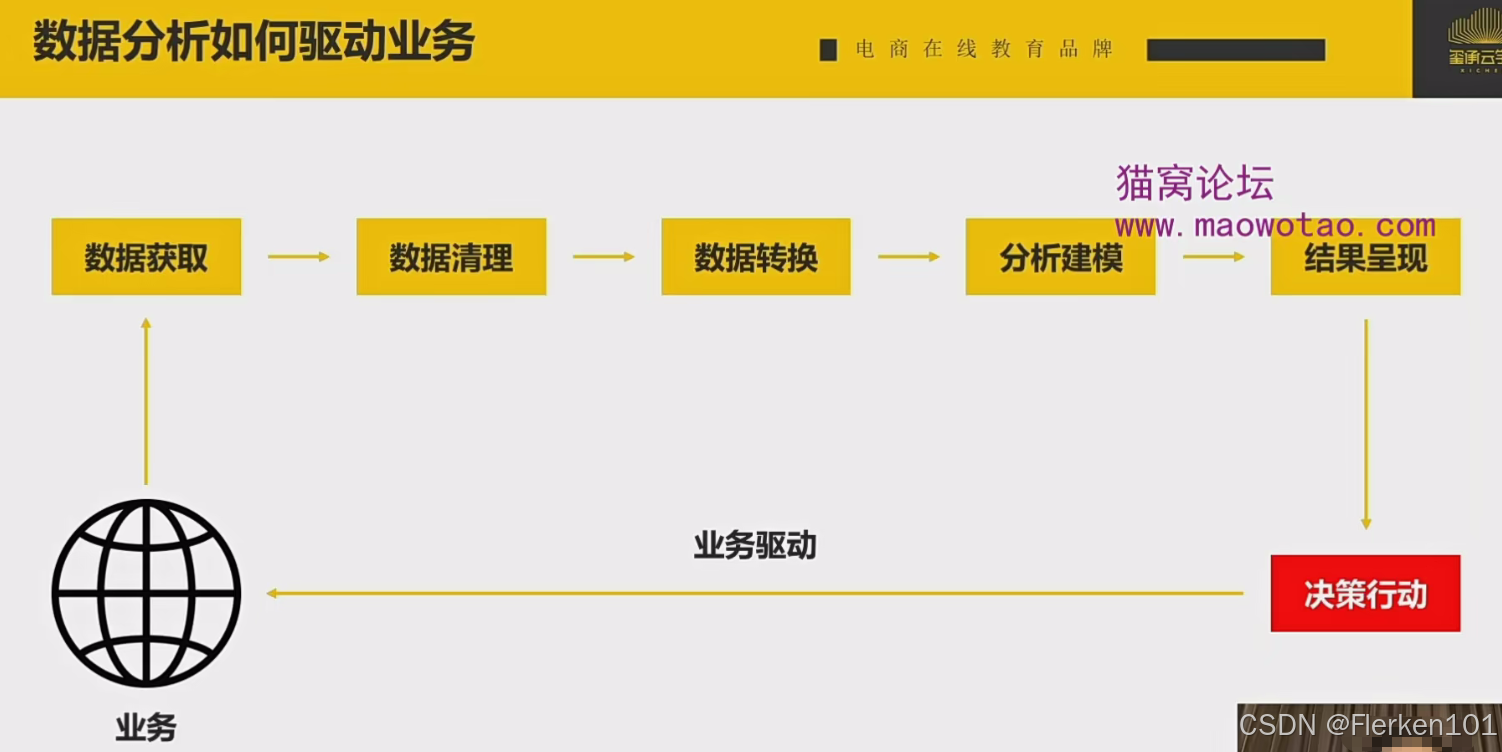
3.1 数据获取/数据采集
淘系电商数据采集渠道:

3.1.1 运营类数据
3.1.1.1 生意参谋直接下载
在生意参谋的某些模块里面提供了直接下载数据的地方。
从淘宝网,进入商家后台“千牛卖家中心”的方式:
再从商家后台“千牛卖家中心”,进入到“生意参谋”的方式:

3.1.1.2 生意参谋+浏览器插件
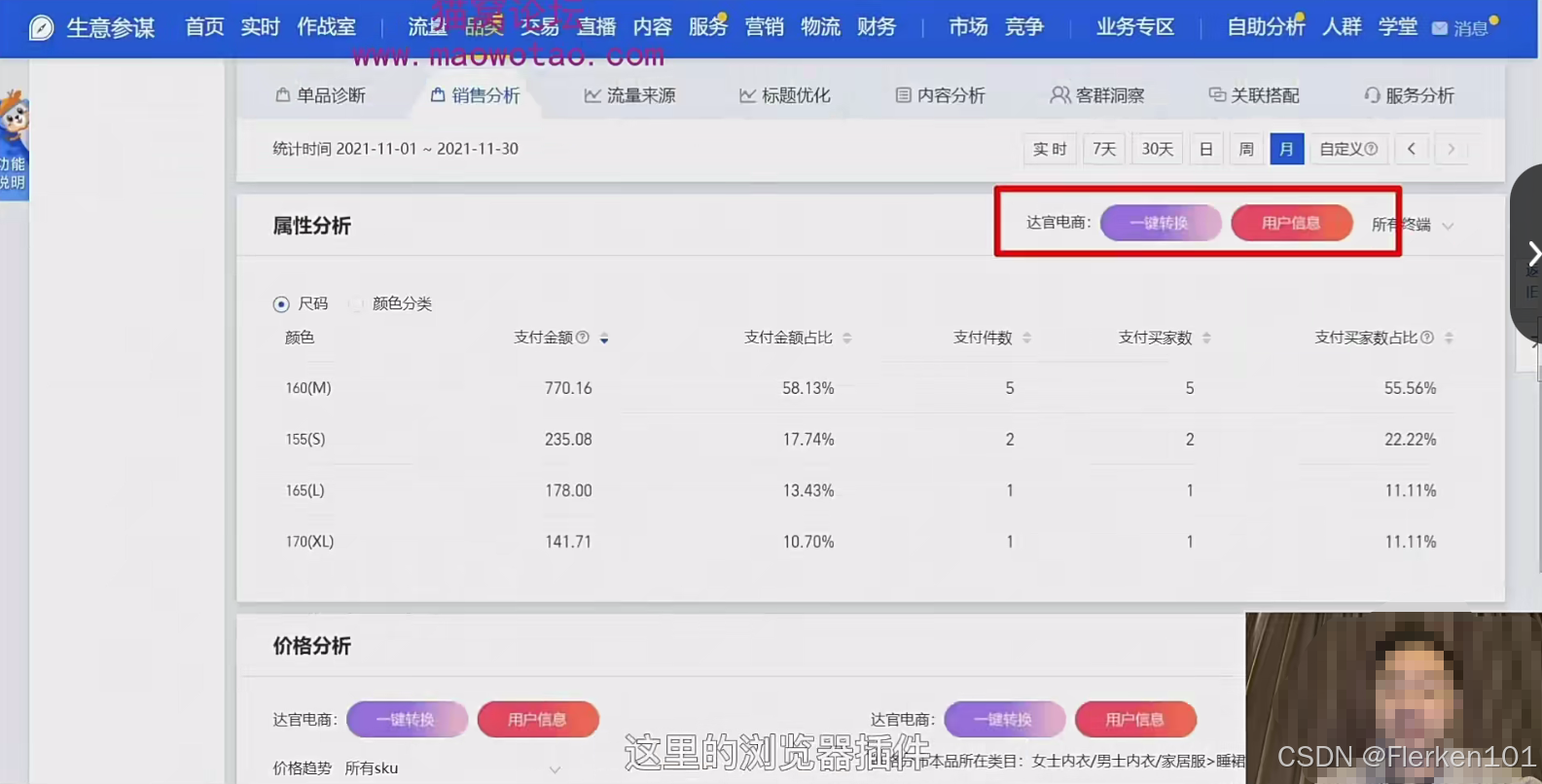
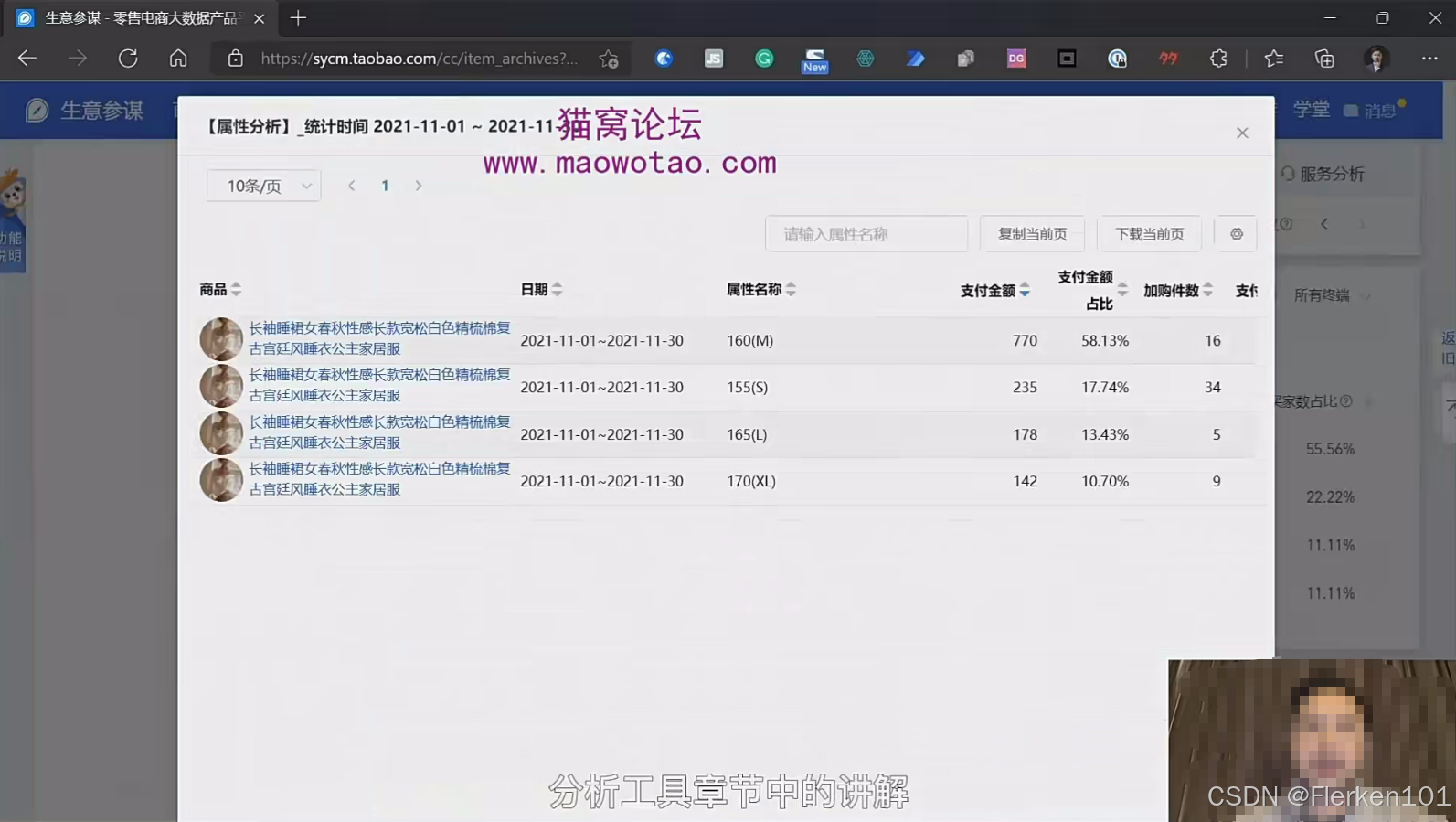
对于生意参谋没有提供下载的数据,需要借助达官电商的浏览器插件(七天试用期)来完成数据的下载。
3.1.1.3 生意参谋自助分析
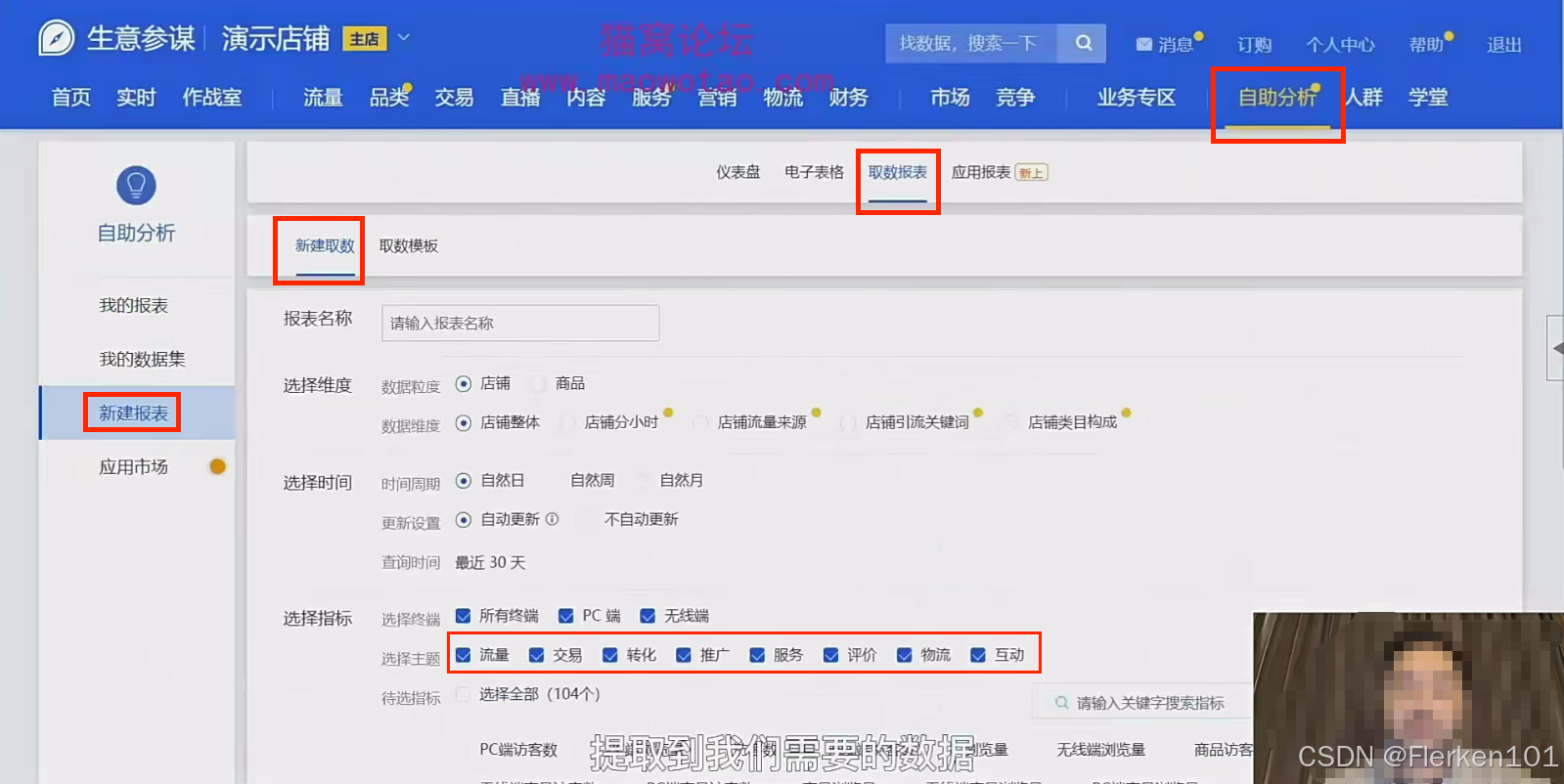
利用生意参谋“自助分析”的“取数报表”,提取到我们需要的数据。
3.1.2 推广类数据
淘系平台(包括淘宝、天猫、聚划算、阿里妈妈等)的推广工具都提供了数据报表的功能。
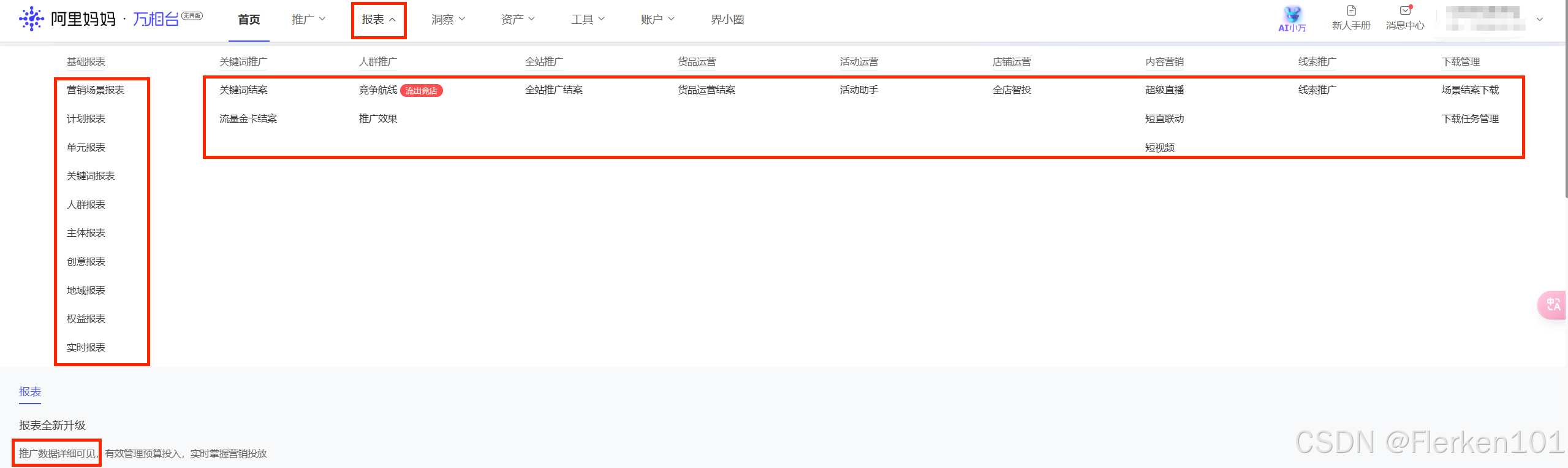
在阿里妈妈——万相台无界版的“报表”功能区中,可以直接下载推广数据。
从淘宝网,进入商家后台“千牛卖家中心”的方式:
再从商家后台“千牛卖家中心”,进入到“阿里妈妈——万相台无界版”的方式:
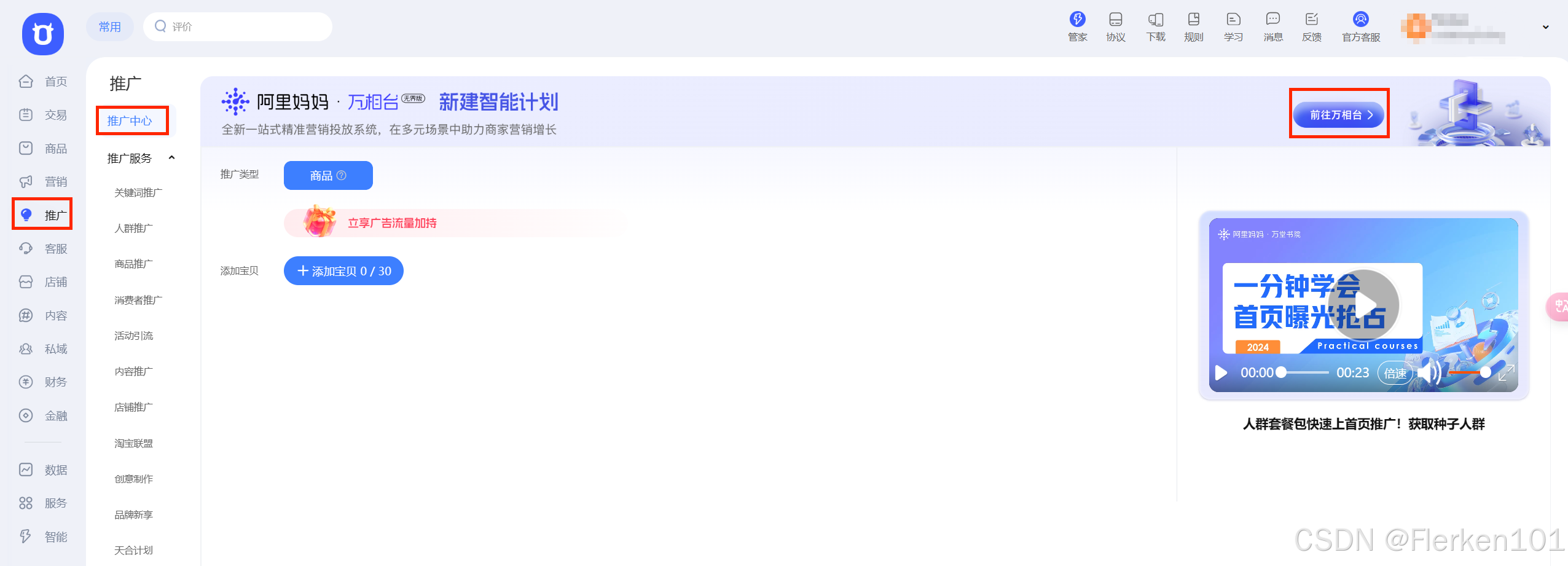
淘宝平台重大变更:直通车、引力魔方及万相台将停运,万相台无界版上线——平台运营专家-honglou


“品销宝”是天猫店铺的推广工具。
主要面向企业级商家和品牌商,提供更全面的电商服务方案。其服务包括店铺管理、商品审核、订单管理、物流管理、会员管理、数据报表分析、活动策划和营销推广等全方位的支持。
商家可以通过天猫品销宝实现全链路营销管理,并与天猫平台实现深度对接,提升客户体验,提高销售效果。

3.1.3 订单类数据
3.1.3.1 千牛卖家中心——已卖出的宝贝
可以直接从商家后台“千牛卖家中心”,“已卖出的宝贝”下载订单的数据。
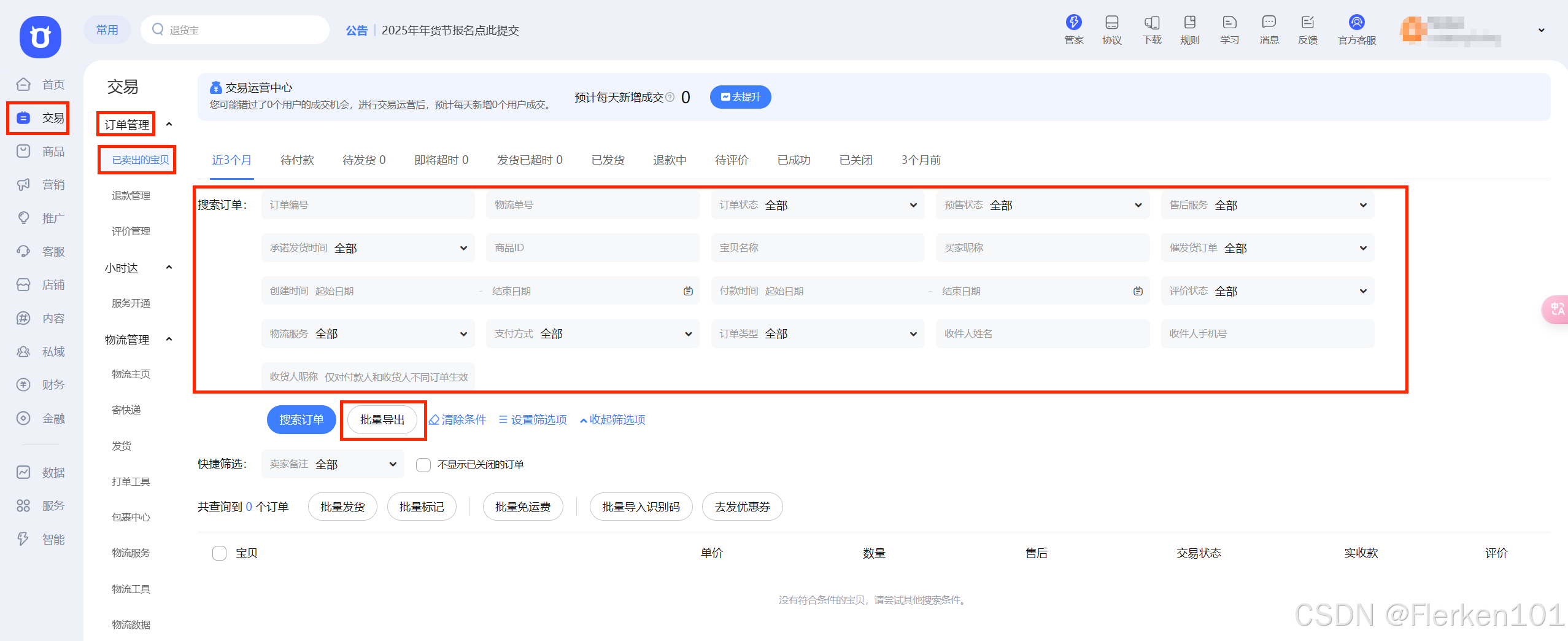
订单数据里面包括了很多客户的详细信息。
比如下图是一个店铺,最近30天的订单数据。
里面包括了订单的编号,买家会员名,支付宝账号,支付金额,姓名,收货地址,手机以及付款时间等很多非常有用的信息。
这类客户详细信息,是生意参谋不会直接提供的。但对于做客户分析是非常有价值的。
3.1.3.2 生e经
在 淘宝服务市场 搜索 “生e经”。
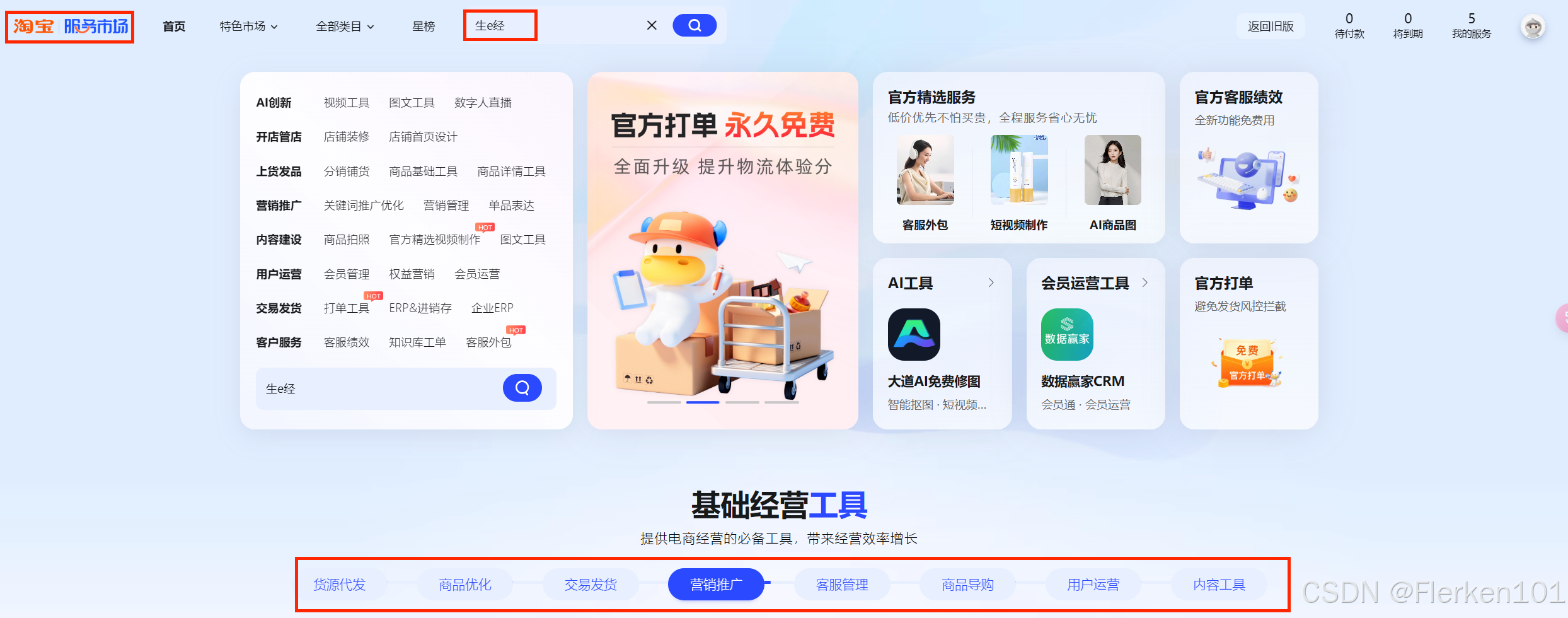
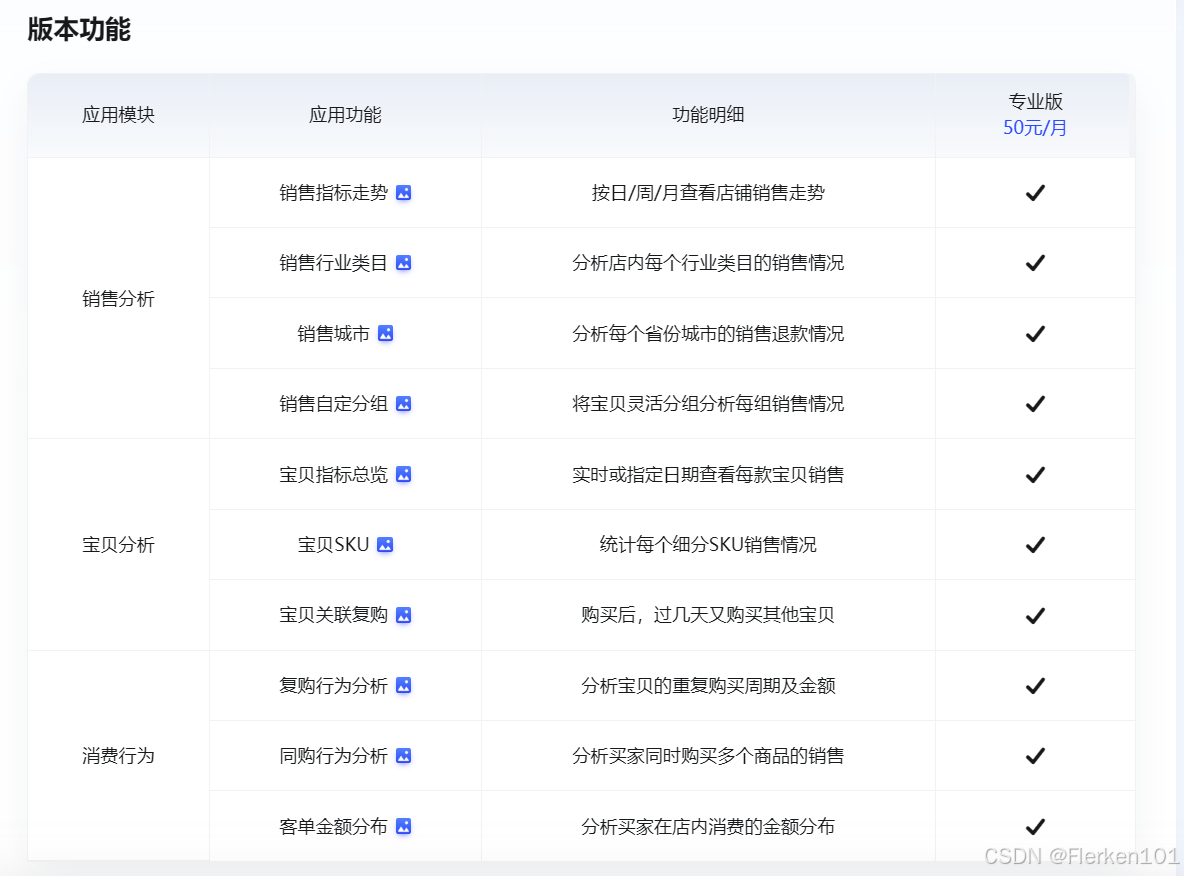
对本店销售数据进行全方位深度分析,助力商家日常经营的生意经:
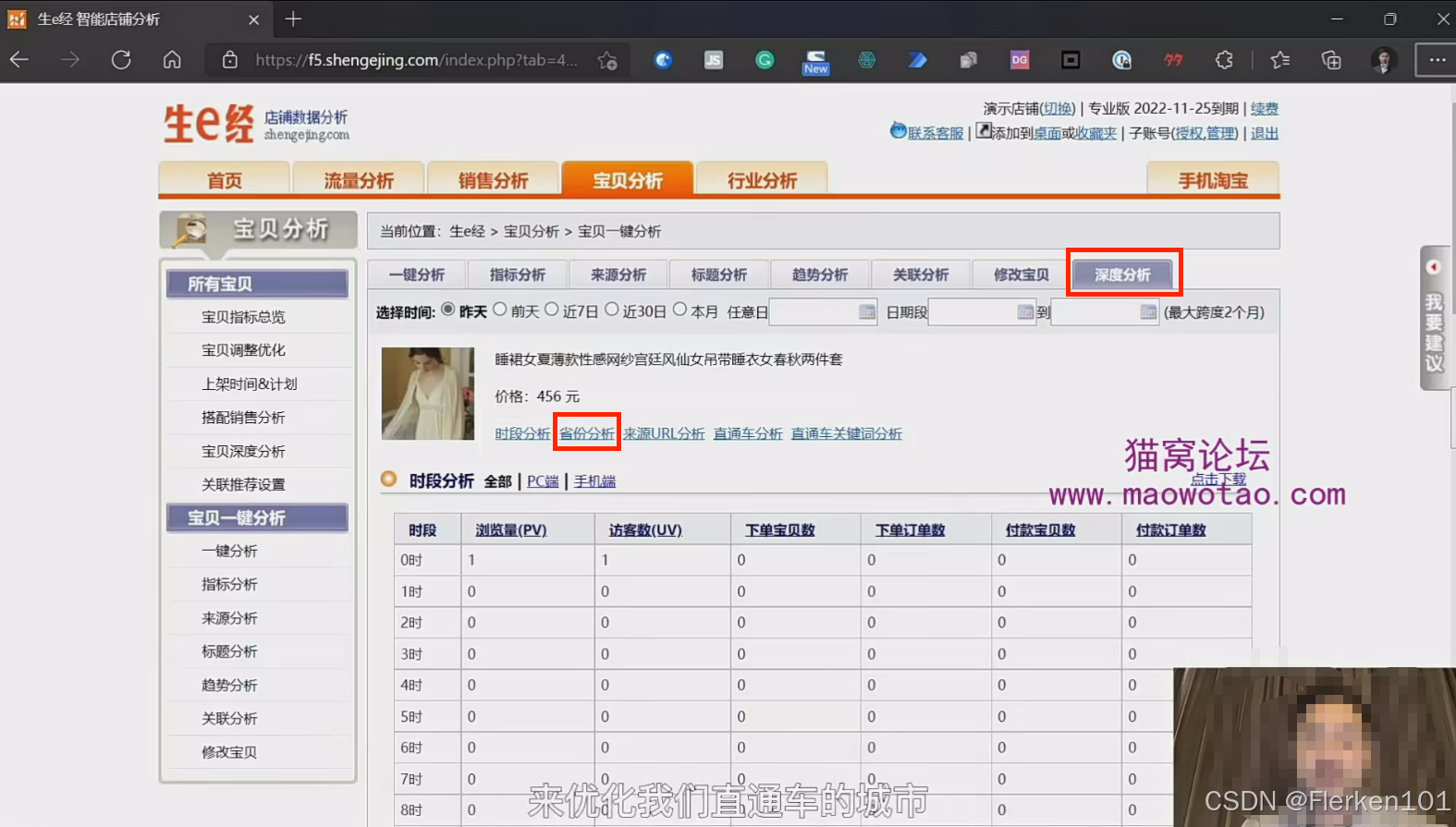
比如经常会用 “生e经” 特定宝贝 “深度分析” 的 地域报表 (销售省份与城市数据)来优化 万相台无界版中的关键词推广(原直通车)的城市。
下图界面是比较老的界面,但思路是不过时的。详细步骤见 3.6 案例.
3.1.4 信息类数据
3.1.4.1 宝贝的主图/详情页/主图视频等
在宝贝详情页上面通过达官插件辅助下载。
3.1.4.2 评价数据、问大家数据
在宝贝详情页上面通过达官插件辅助下载。
3.2 数据清理
当采集到数据后,部分数据的格式未必完全符合分析要求,那么就需要对数据进行清理。
数据清理的工作可以通过表格来完成,主要会用到表格的下面几个功能:

3.2.1 删除不需要的列或者行(配合筛选)
有时候从生意参谋上下载的表格,在前面几行会有生意参谋的广告,就需要删除这些行。
有时候还需要配合筛选功能,只保留一些需要的数据行。
3.2.2 转化为数字
有时候从生意参谋上下载的表格,单元格里面内容并不是正确的数字格式,就需要转化为数字。
3.2.3 查找和替换
在表格里面把对应的数据找出来,替换成需要的值。
3.2.4 分列
把一个单元格里的内容分列成几个。
比如订单里面的地址,包括了省份,城市等数据,就需要对地址进行分列,把城市和省份分出来。
3.2.5 设置单元格格式
一般用的比较多的格式是整数、小数、百分比和日期。
比较特殊的是宝贝ID,需要把宝贝ID单元格设置成文本,才能显示正确。
3.2.6 增加需要的列
通过计算,增加需要的字段列。
比如有时候表格里面没有访客价值UV,就需要通过 用户转化率 和客单价来进行计算。
因为:GMV = UV * 用户转化率 * 客单价
所以:访客价值 = GMV/UV = 用户转化率 * 客单价

3.3 数据转换
3.4 分析建模
见04、常用的数据分析模型
3.5 结果呈现
EXCEL图表:EXCEL: (二) 常用图表——Flerken101
Tableau可视化:Tableau数据可视化与仪表盘搭建——Flerken101
3.5.1 常用EXCEL图表
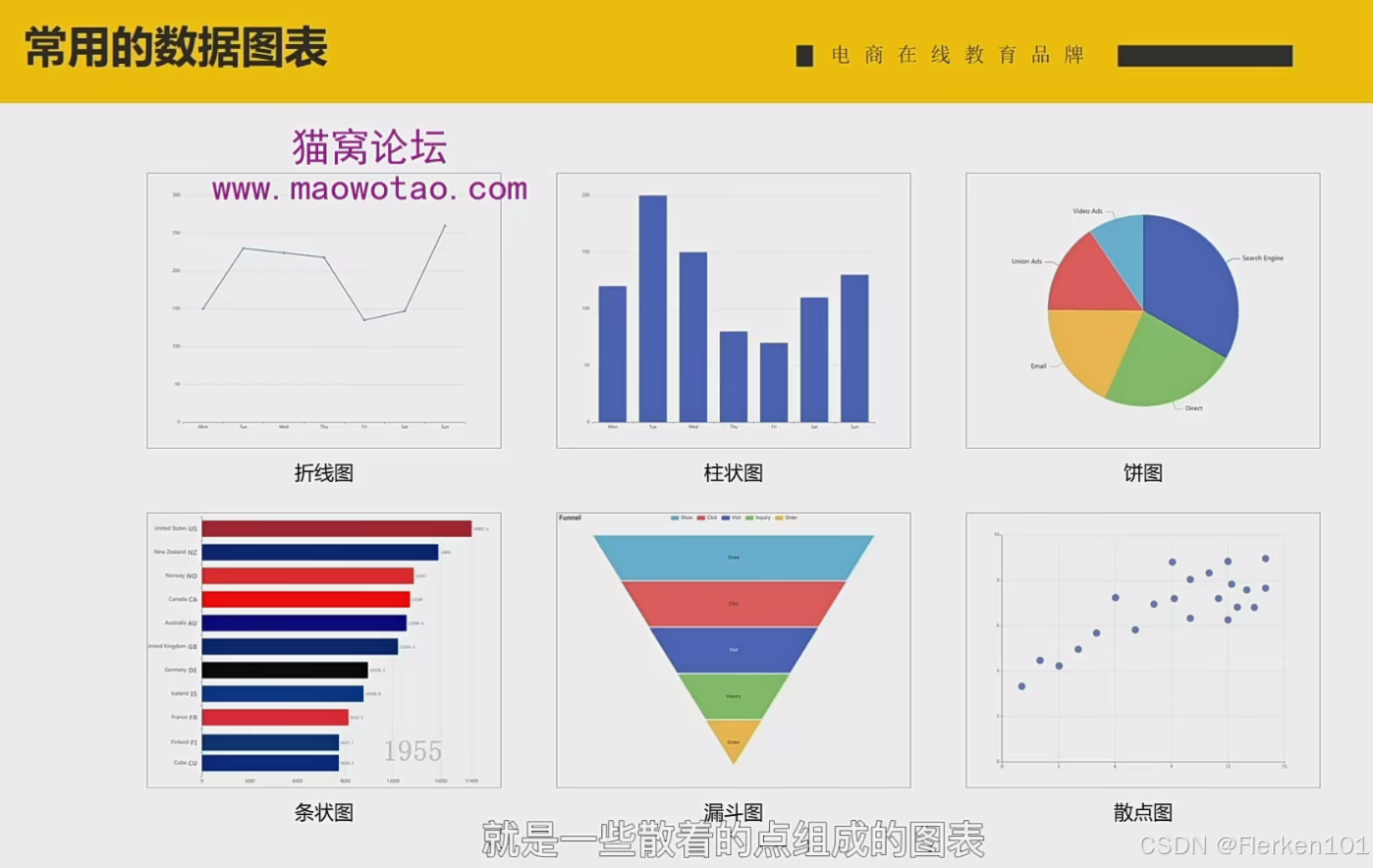
折线图: 一般比较用来适合表达趋势。
柱状图: 更适合用来表达对比的情况。
条形图: 当要对比的数据维度很多时,柱状图的横向坐标轴受制于宽度,很难看清楚全部维度。此时可以把维度放在竖坐标轴上,从而形成条形图。
饼图: 用来呈现分布与占比,如店铺流量 的来源渠道以及其流量大小占比。
漏斗图: 用来表达多个步骤中,每一步的衰减、流失情况。如消费者从浏览,到加购,到下单,到支付,每一步的转化情况。
散点图: 顾名思义,就是一些散着的点组成的图表。这些点在图表上的位置是由其x值和y值决定的。散点图比较适合用来展示数据的分布情况或聚合情况。
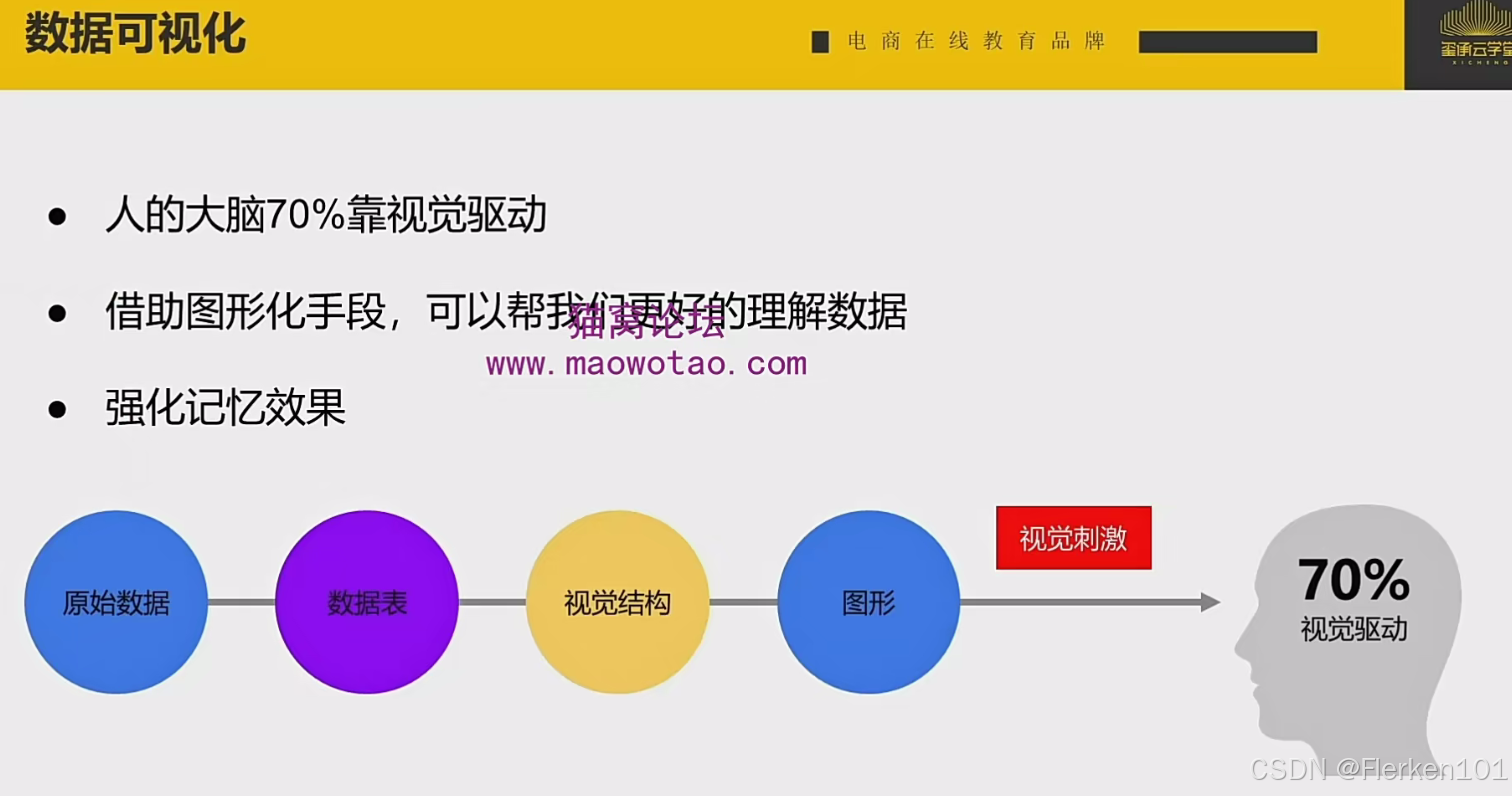
3.5.2 数据可视化
3.6 案例——(帕累托图)利用生e经订单类数据中的地域报表,进行关键词推广(原直通车)的地域优化
3.6.1 数据获取/数据采集
(1)前提工作:把要分析的宝贝提前先加到生意经的宝贝深度分析里面。
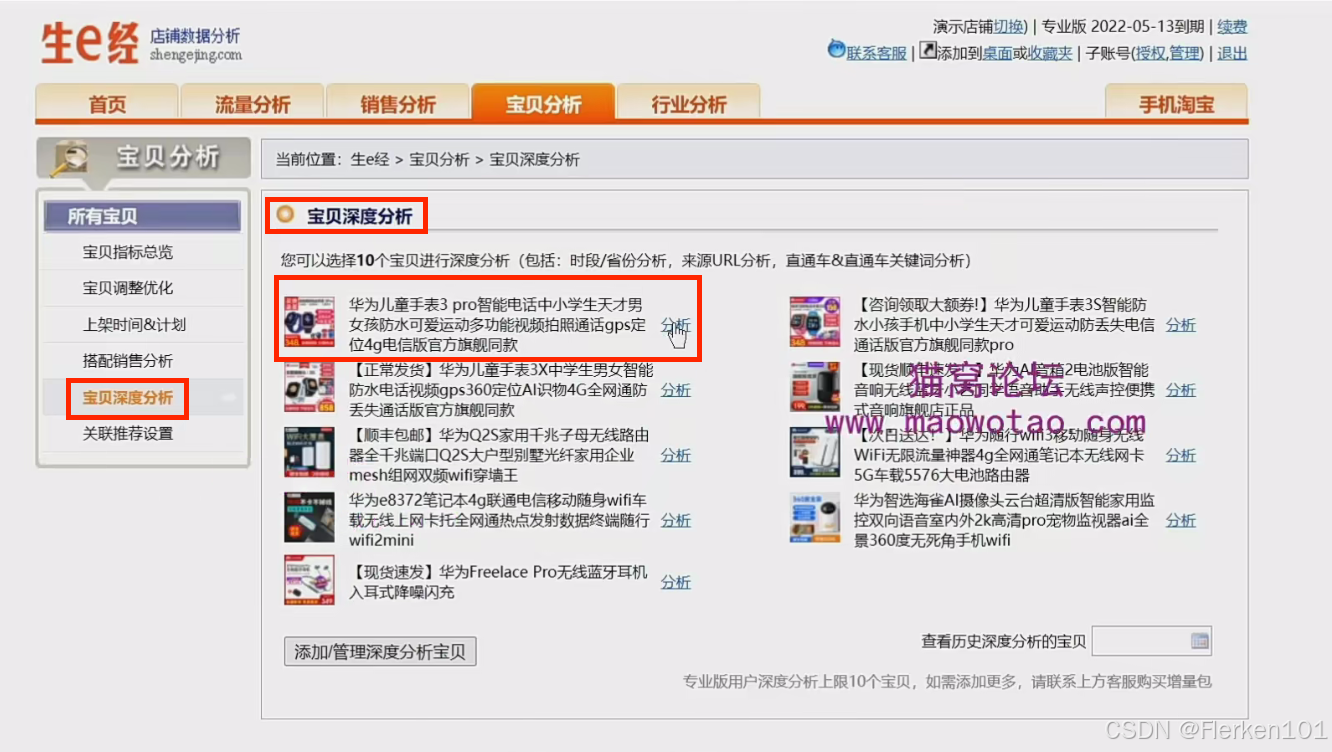
(2)进入生e经“宝贝深度分析”,找到要进行直通车地域优化的宝贝。
(3)时间选30天,选择省份分析,选择省份和城市,点击下载。
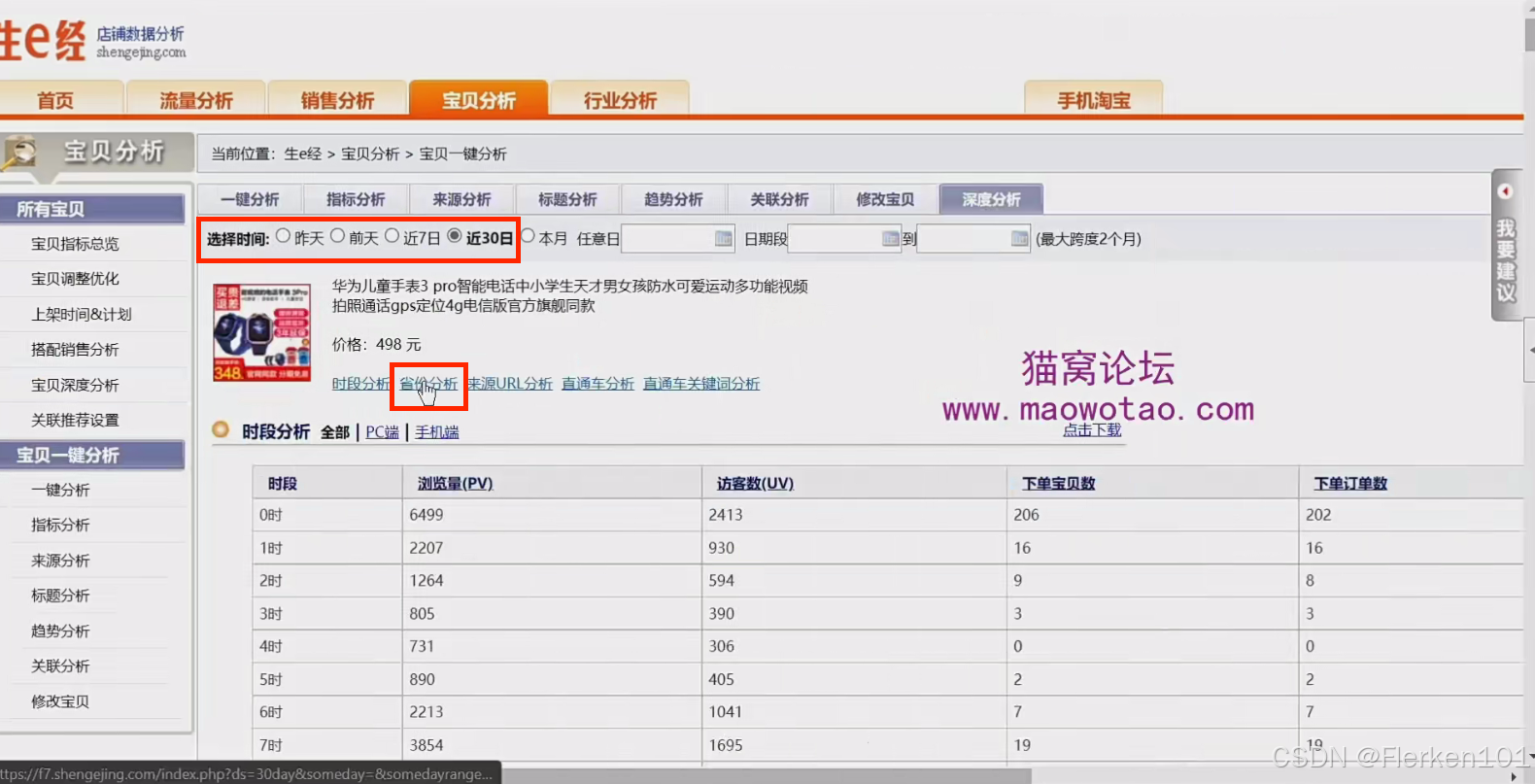
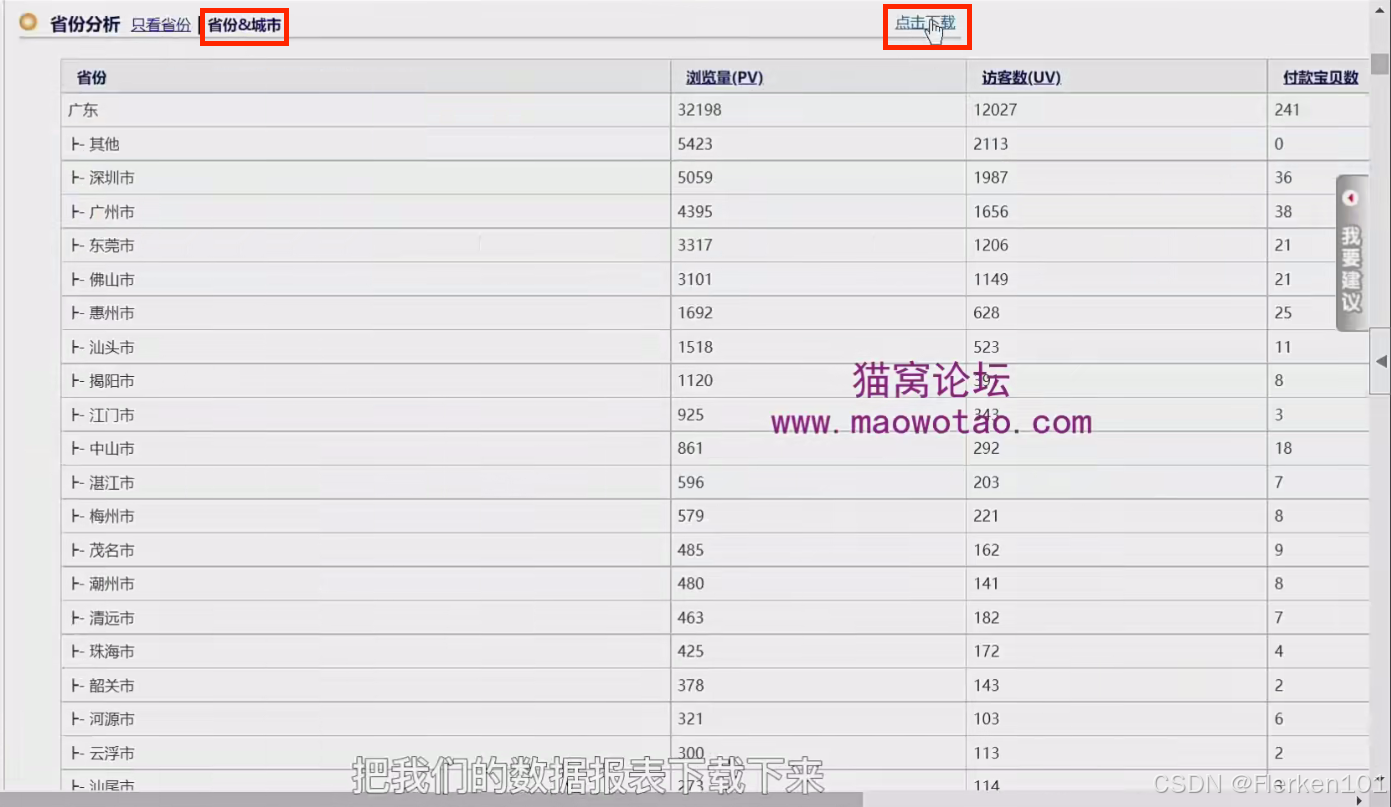
生e经的深度省份城市分析的报表:
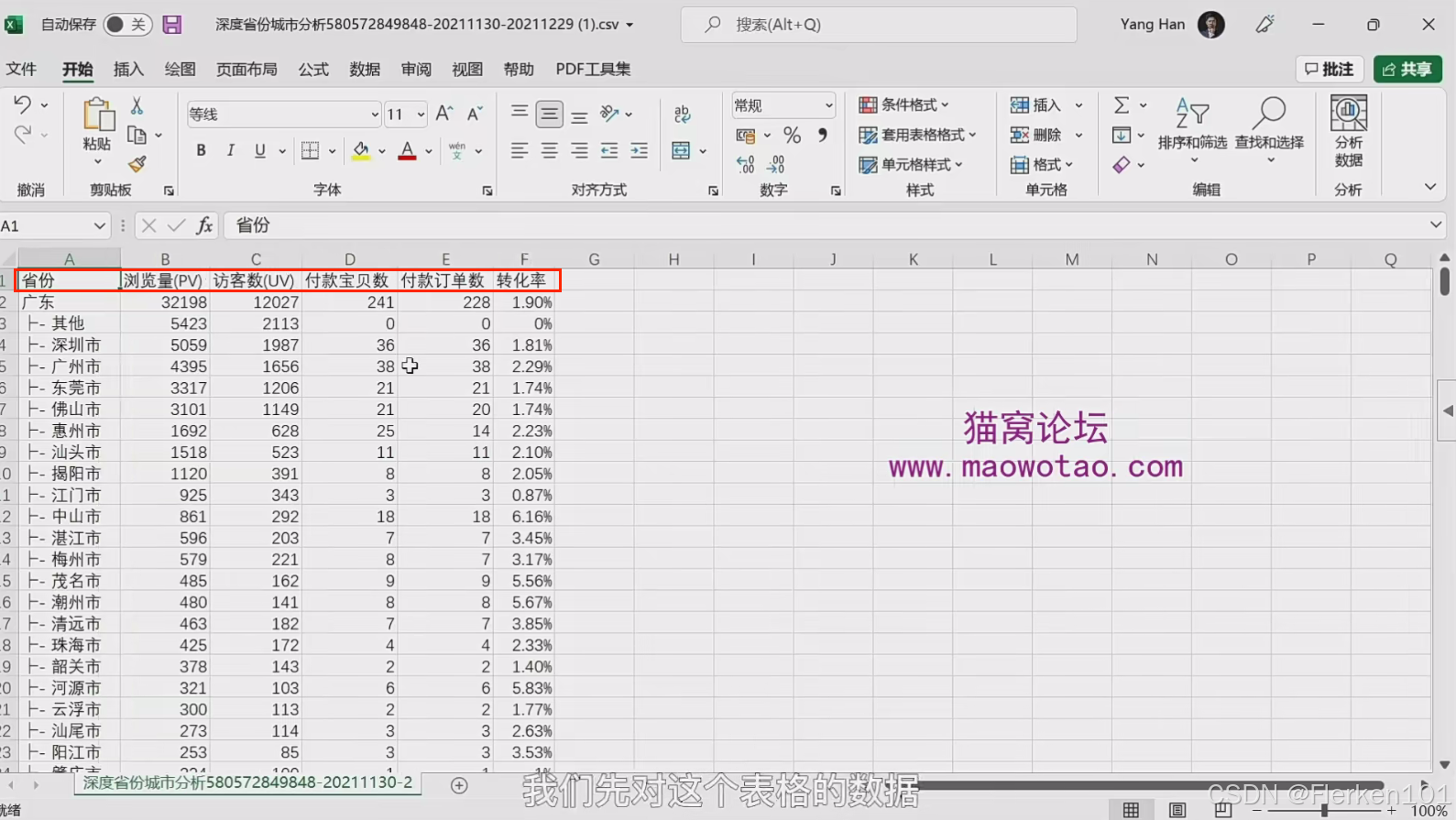
3.6.2 数据清理
(1)删除不需要的行(配合筛选)
①删除省份的数据行,只保留城市的数据行。
但省份中 北京、天津、上海、重庆 四个直辖市的数据要留下。
②城市数据中,删除字段值为“其它”的数据行。
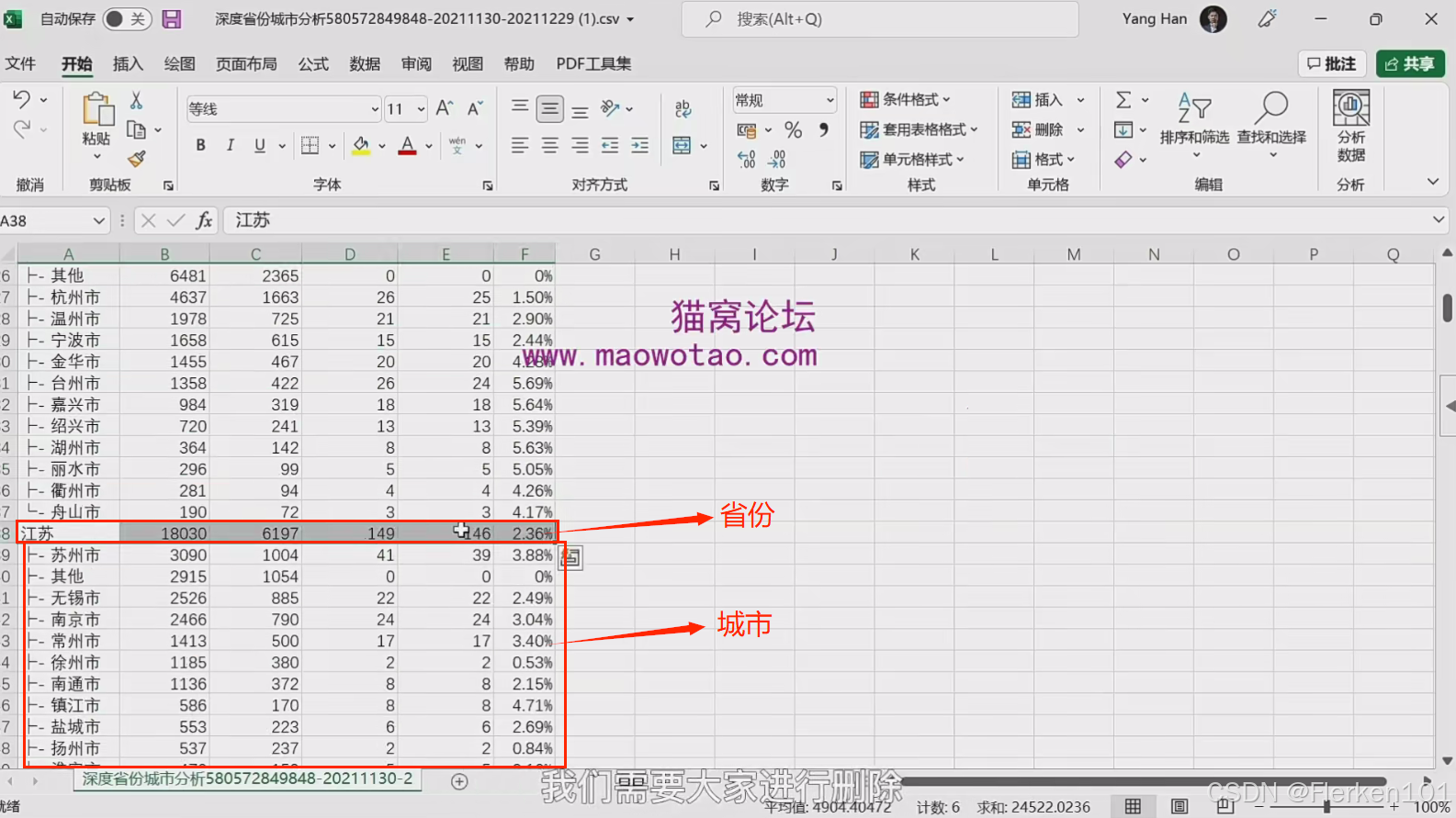
(2)查找和替换
查找和替换 特殊符号 为空。
(3)按照访客数 降序排列。
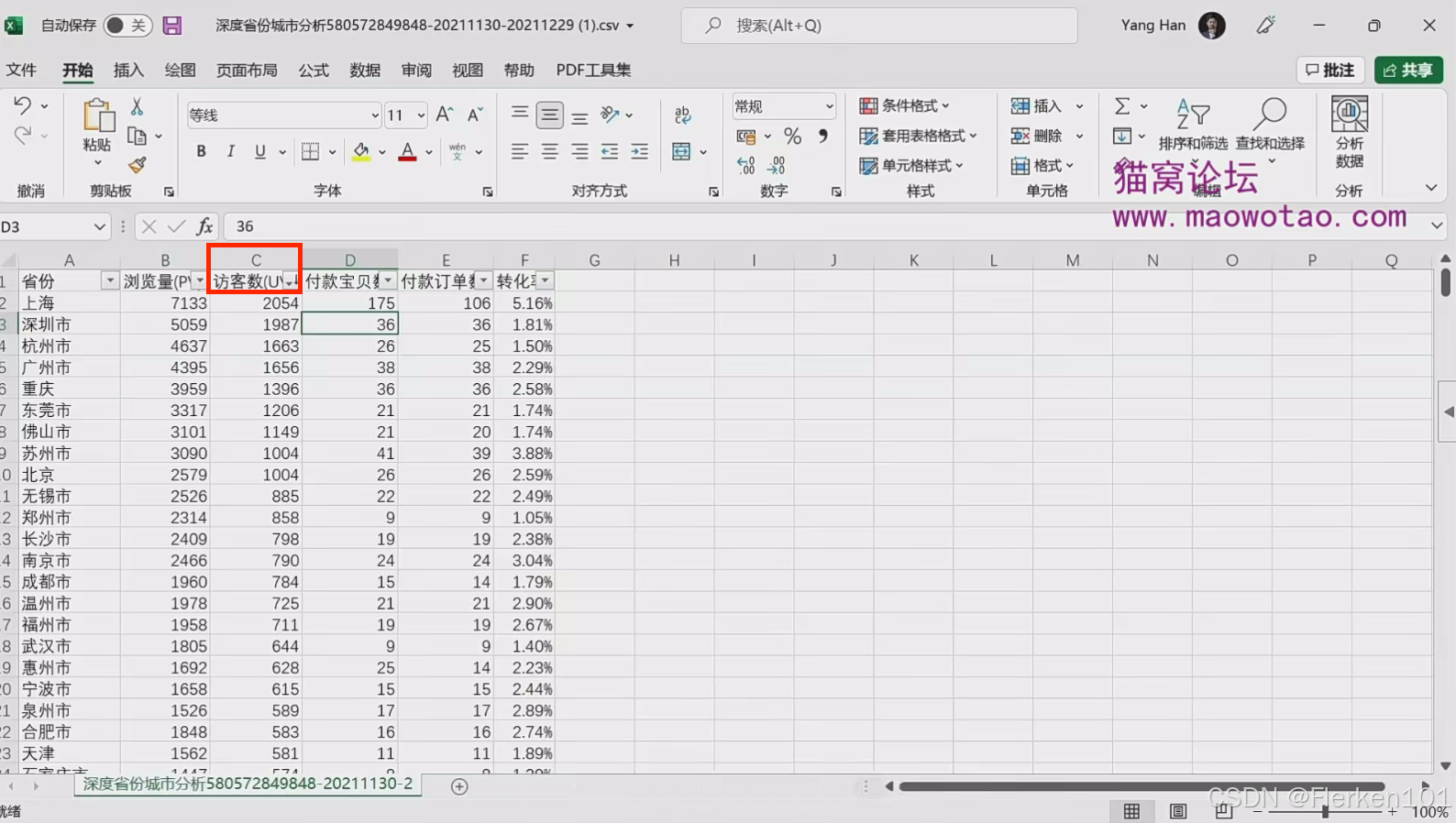
3.6.3 数据转换
无
3.6.4 分析建模
(1)先明确本次分析的目的
在生意参谋中看到:
①这个宝贝在过去30天,直通车的支付转化率 和 手淘搜索的支付转化率 差距比较大;
直通车的支付转化率 << 手淘搜索的支付转化率
②这个宝贝在过去三天,直通车的访客数非常高。
因此,本次分析的目的是:提升直通车的访客精准度。
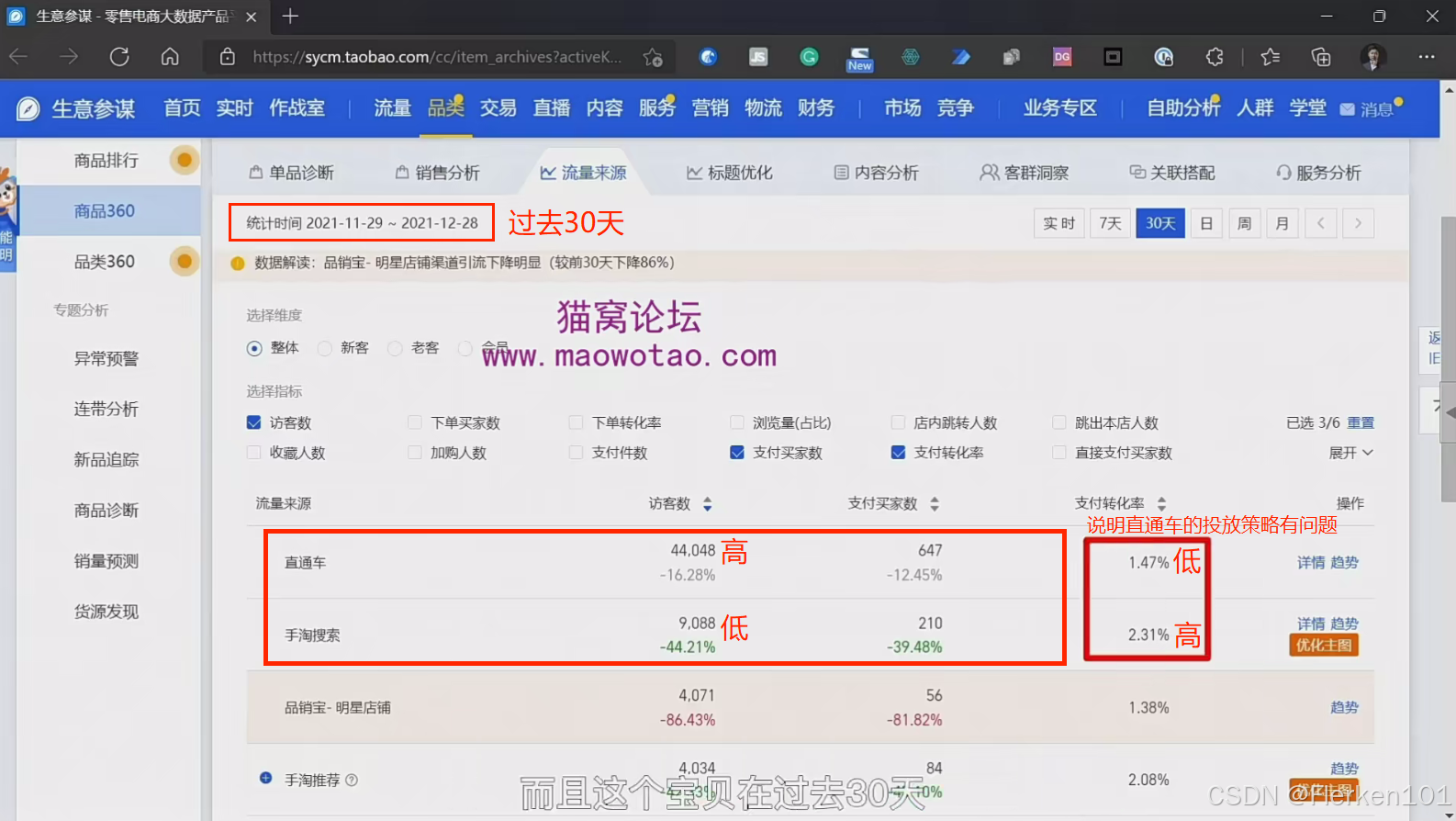
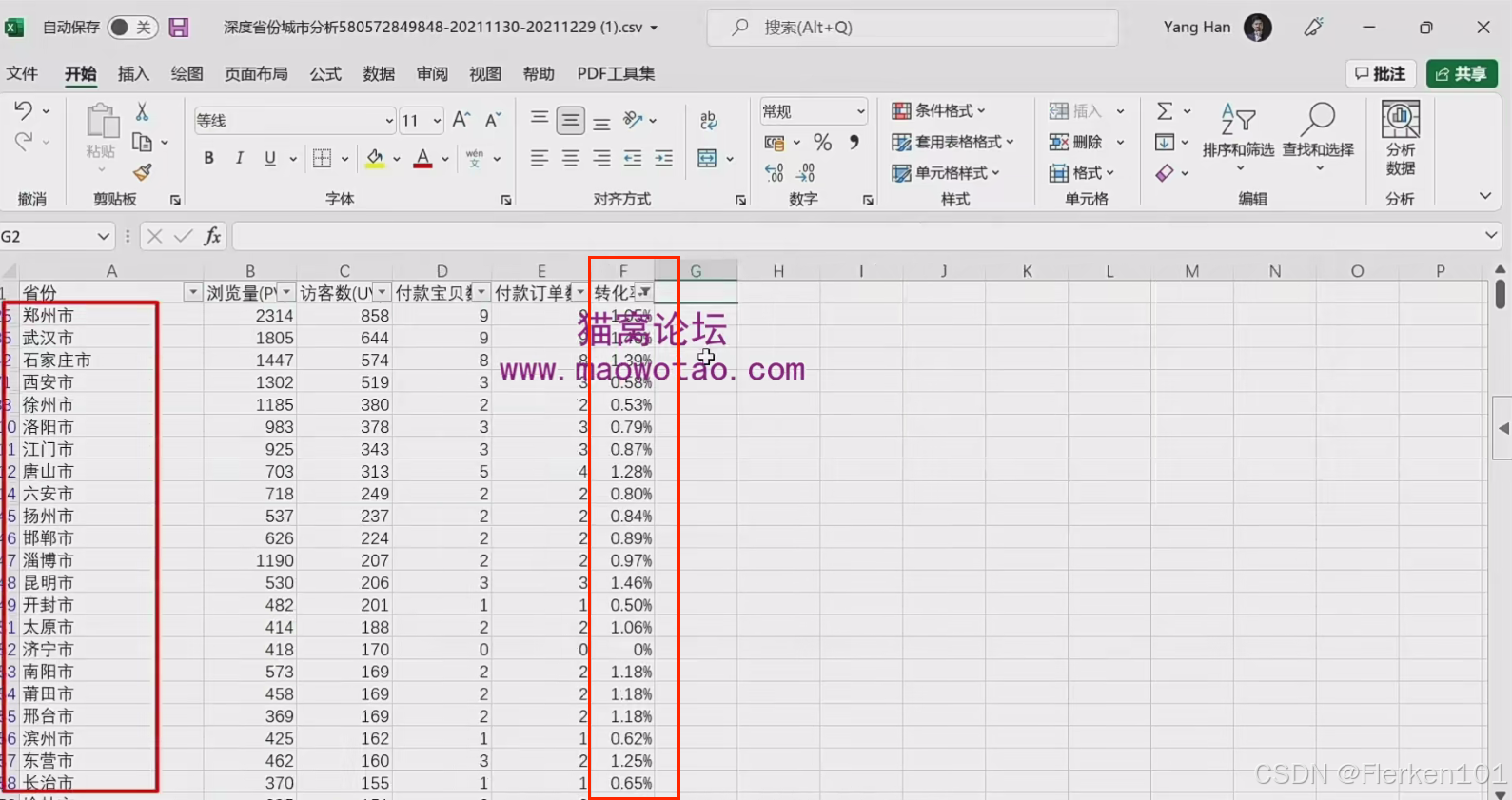
(2)根据 直通车的支付转化率 和 城市的转化率 筛选优先投放的城市
因为直通车的支付转化率是1.47%,因此先把表格中转化率低于1.47%的城市筛选出来。
对于这些城市,可以把它单独开到另外一个计划里面,减少对这些城市的投放。
把更多的推广预算划到高转化率的城市上面,以获得更多的订单以及更好的转化率。
应减少投放的城市:
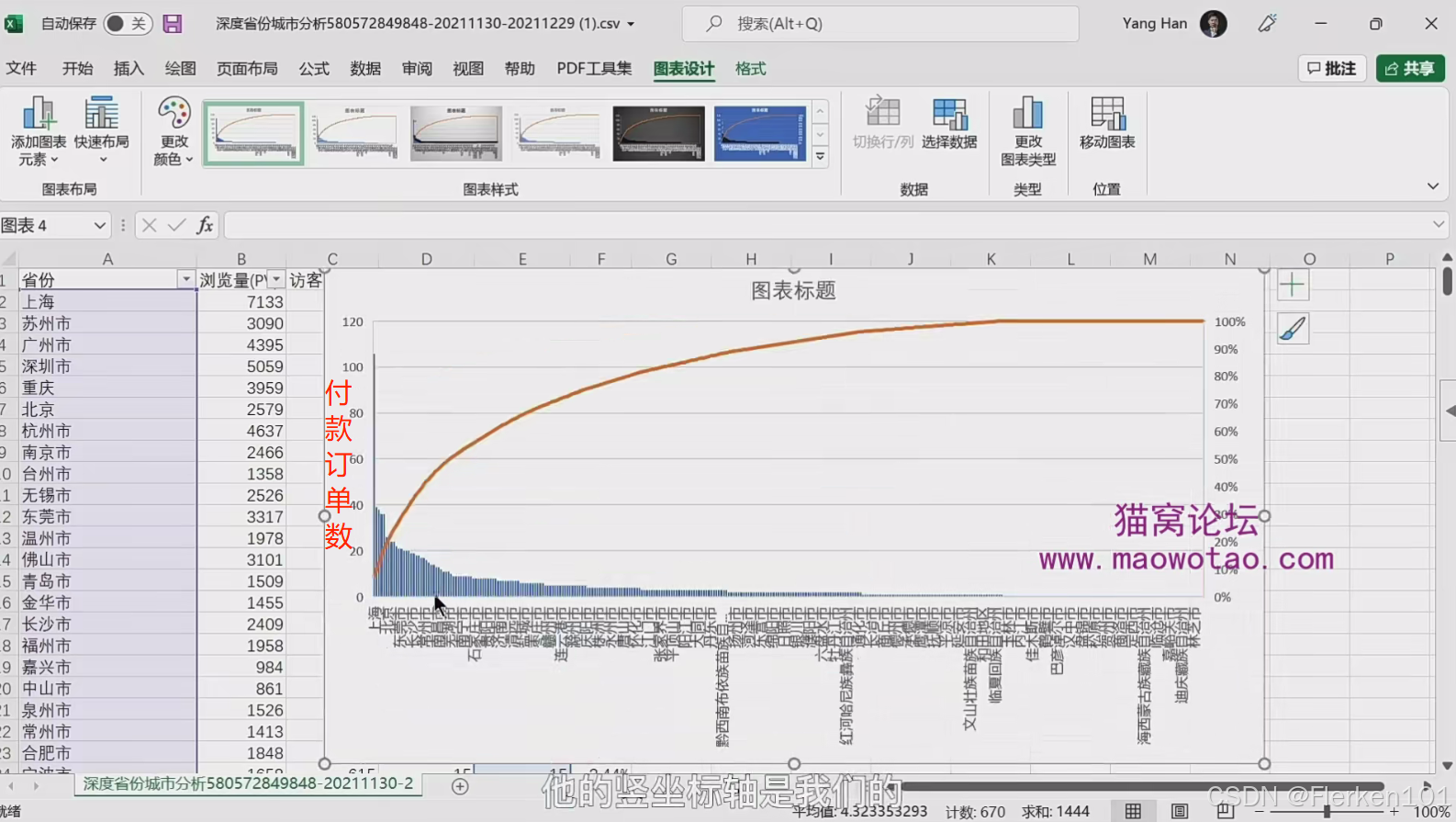
(3)使用帕累托图进行分析
如何用Excel制作帕累托图——Excel广场
直通车里共有360多个城市,并不是每个城市都需要开直通车。
使用帕累托图,看看贡献更多订单的城市到底是哪些。
【帕累托图的竖坐标轴是每个城市的付款订单数。】
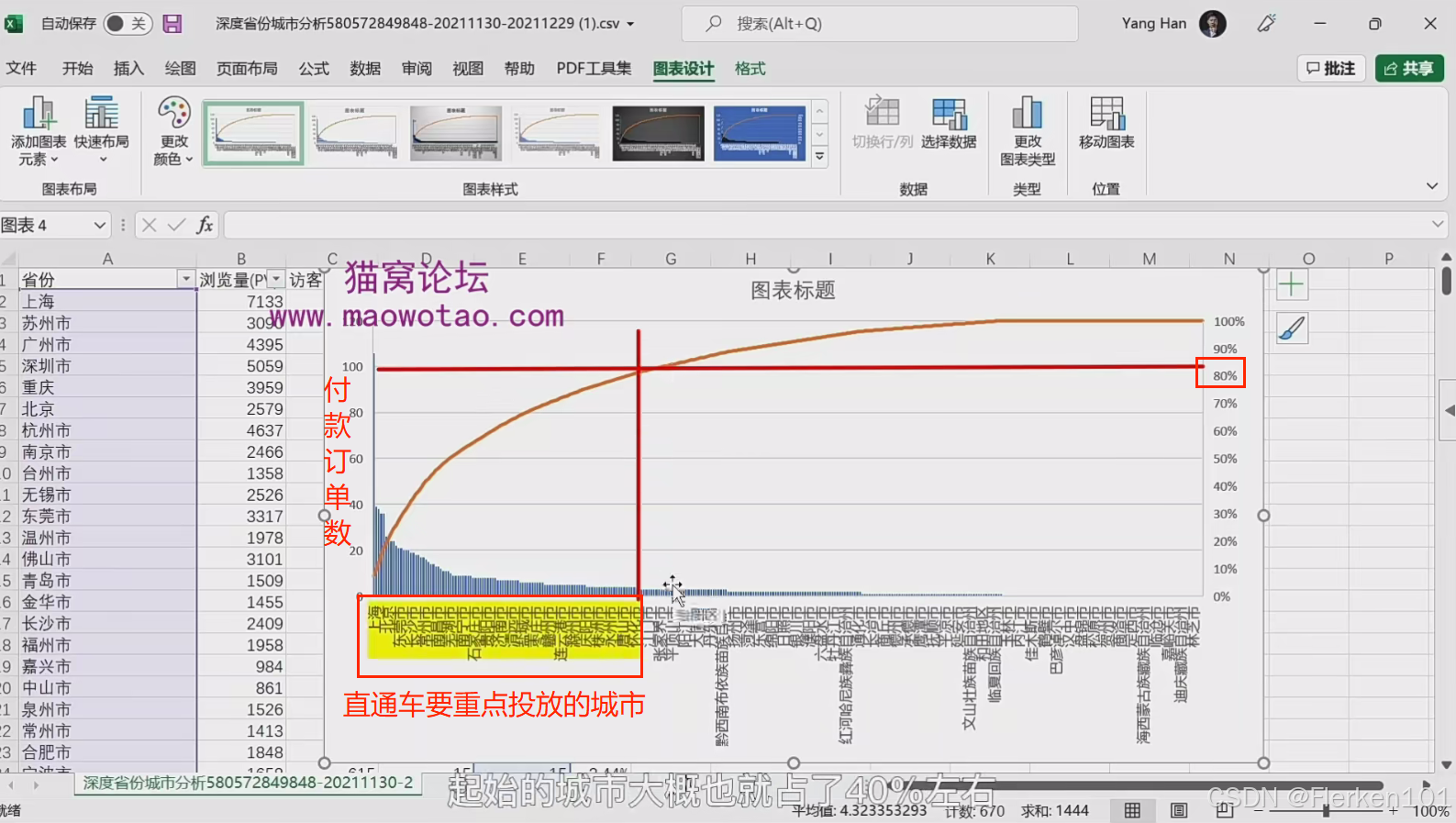
3.6.5 结果呈现
贡献了80%订单的城市大概也就占了40%左右。
那么这40%的城市,其实就是直通车应该去重点优化和重点投放的城市。
剩下的60%的城市,为了节省费用,提高资金利用效率,可以选择不去投放,直接放弃。
————这也是帕累托分析法和ABC分析法的区别所在。
04、常用的数据分析模型
很多成熟的分析模型,前人都做了大量的调研和分析,且经过了大量案例的论证;而且还具备一定的理论基础, 所以使用分析模型可以让自己的论证过程更具备逻辑性和条理性,同时也让结论更具备说服力。
在做分析的时候,如果不知道怎么分析,不妨先套用一些分析模型,来帮助自己构建分析思路。
4.1 时间流程分析
4.1.1 用户转化及行为分析模型
4.1.1.1 转化漏斗——漏斗图
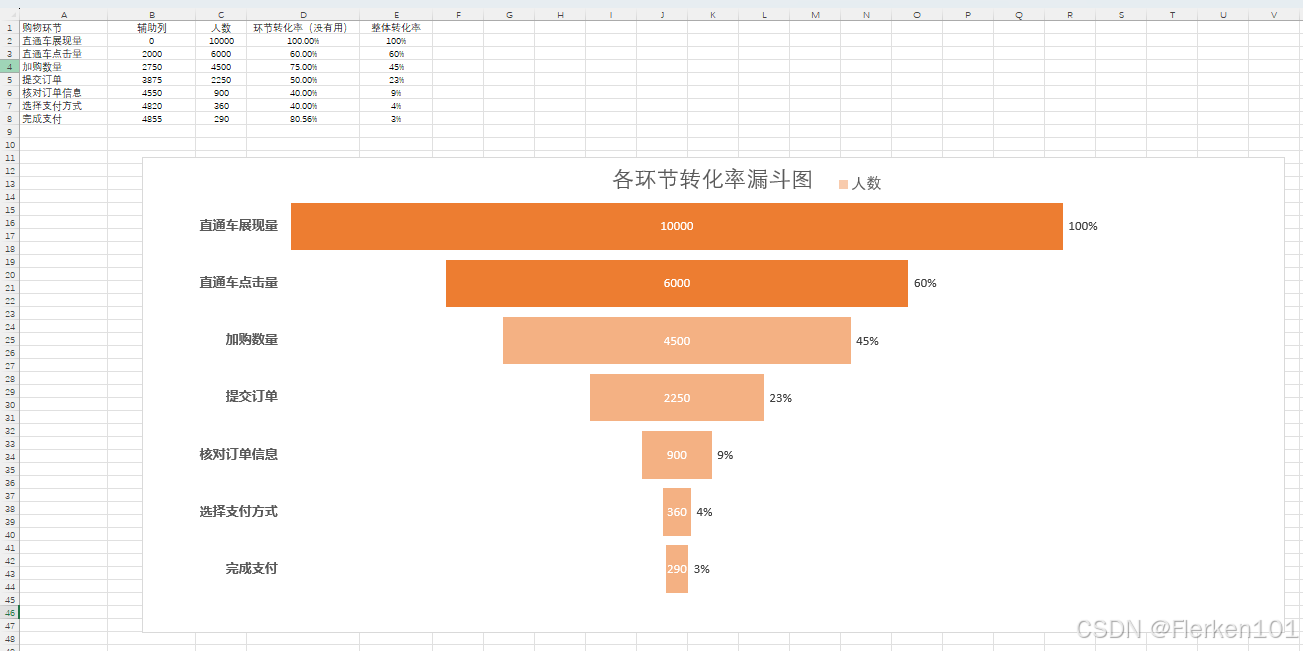
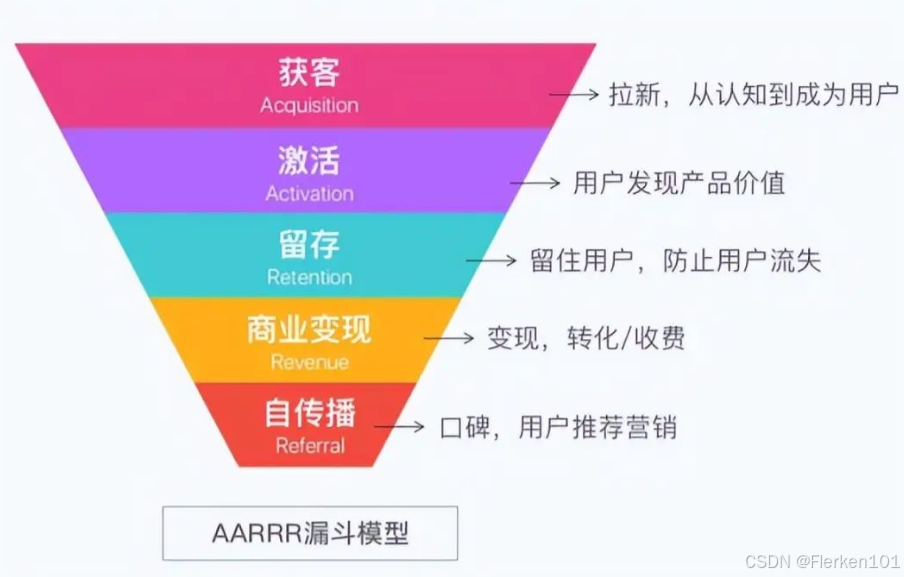
4.1.1.2 AARRR模型(海盗模型)——漏斗图
AARRR模型也被称为海盗模型、海盗指标、增长黑客理论模型、增长模型、2A3R模型、决策模型。
是硅谷著名风险投资人戴夫·麦克卢尔提出的。
AARRR分别代表了五个单词,分别对应了客户生命周期中的五个阶段,展现了获客和维护客户的原理:
Acquisition [获取]:用户从不同渠道来到你的产品;
Activation [激活]:用户在你的产品上完成了一个核心任务(并有良好体验);
Retention [留存]:用户回来继续不断的使用你的产品;
Revenue [收益/商业变现]:用户在你的产品上发生了可使你收益的行为;
Referral [推荐/自传播]:用户通过你的产品,推荐引导他人来使用你的产品。
客户生命周期的五个阶段,的另一种说法:
(1)引入期
(2)成长期
(3)成熟期
(4)休眠期
(5)流失期
可以与AARRR结合起来,客户生命周期的各个阶段为:
(1)引入期——获取
(2)成长期——激活、留存
(3)成熟期——收益/商业变现、推荐/自传播
(4)休眠期
(5)流失期
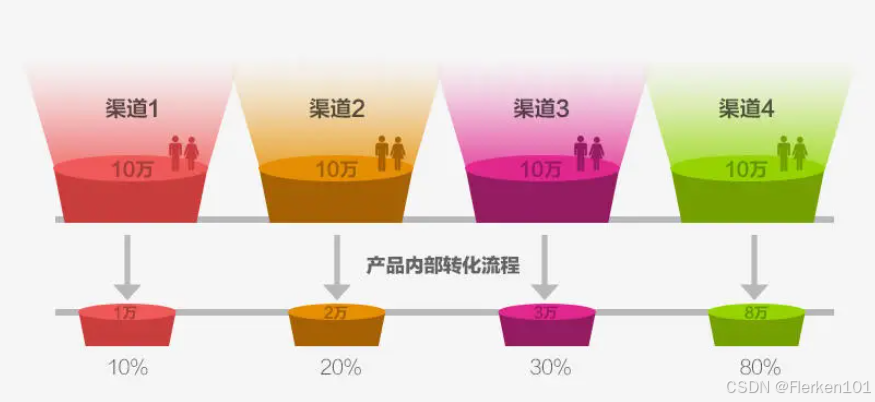
4.1.1.3 不同维度的转化对比分析——漏斗图
假设四种渠道在资金及人力投入相同的情况下,并且都能拉到10万用户(为了方便理解,都用简单的整数),渠道1的转为率为10%,渠道4的转化率为80%,那么在对比了四个渠道后,我们应该做的是加大渠道4的投入减少渠道1的投入。
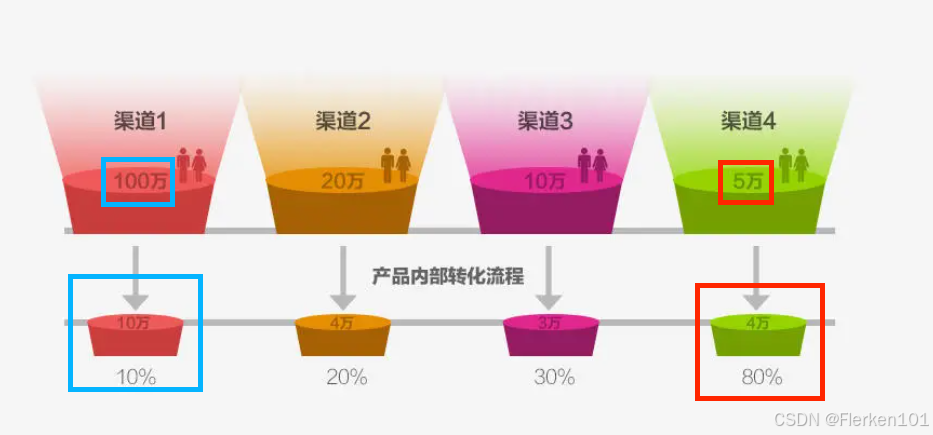
假设四种渠道在资金及人力投入相同的情况下,渠道1能拉到100万用户,渠道4能拉到5万用户,虽然渠道1的转化率很低,只有10%,远低于渠道4的80%的转化率,但是用户吸纳数量却是渠道1的2.5倍,那么这个时候,就应该加大在渠道1的投入。
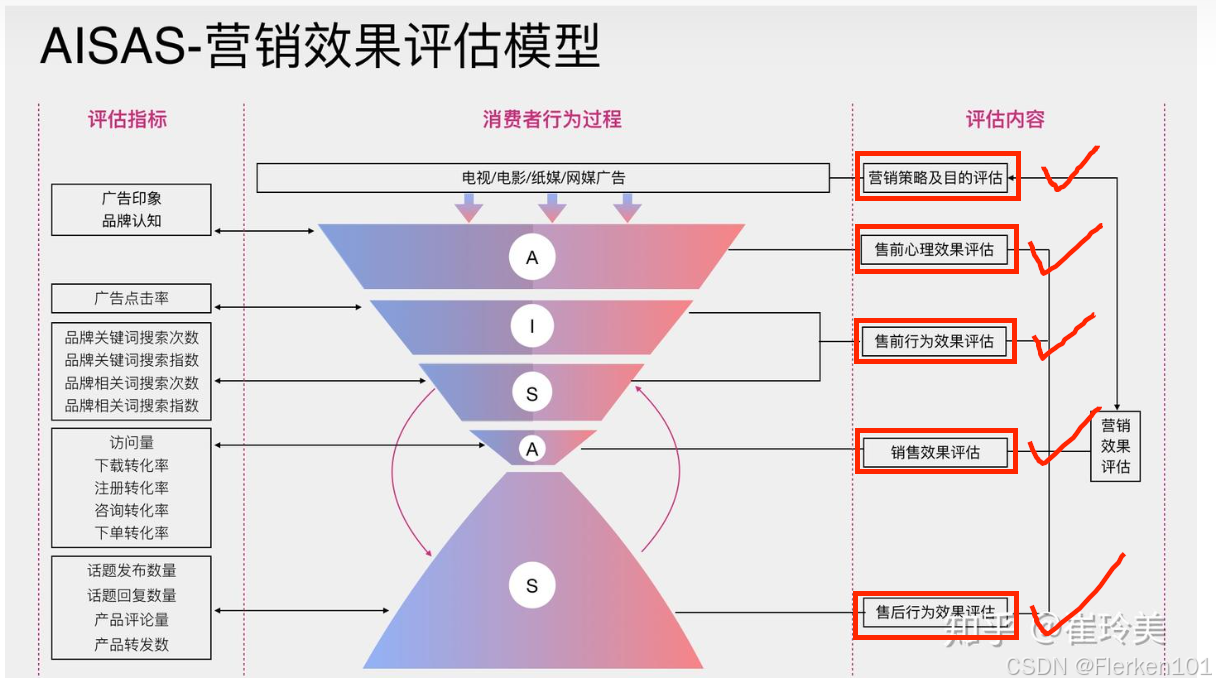
4.1.1.4 用户消费行为模型(AIDMA—AISAS—SIPS—SICAS—ISMAS—ADMAS)
一文讲透用户消费行为模型(AIDMA、AISAS、SIPS、SICAS、ISMAS)——崔玲美
- AIDMA强调媒体的重要性,对用户的消费心理历程把握得很到位,适用于品牌广告或高卷入度的产品。
【高卷入度的商品,通常指价格相对比较昂贵,消费者需要支付较大一笔费用的商品,比如房子、汽车,还有诸如手表和价格较高的数码类产品。消费者会主动搜寻产品相关信息,比较品牌间的差异,以求能够做出最符合需要的决策。】
-
AISAS强调用户的搜索和分享,及搜索指标的营销效果评估。
-
SICAS需要有精细化、大数据的广告效果监测能力,对使用的企业有一定的门槛要求。
-
ISMAS 和 ADMAS 强调在去广告媒体的环境中,消费者的兴趣占据主导地位,口碑对消费者决策有重要作用。

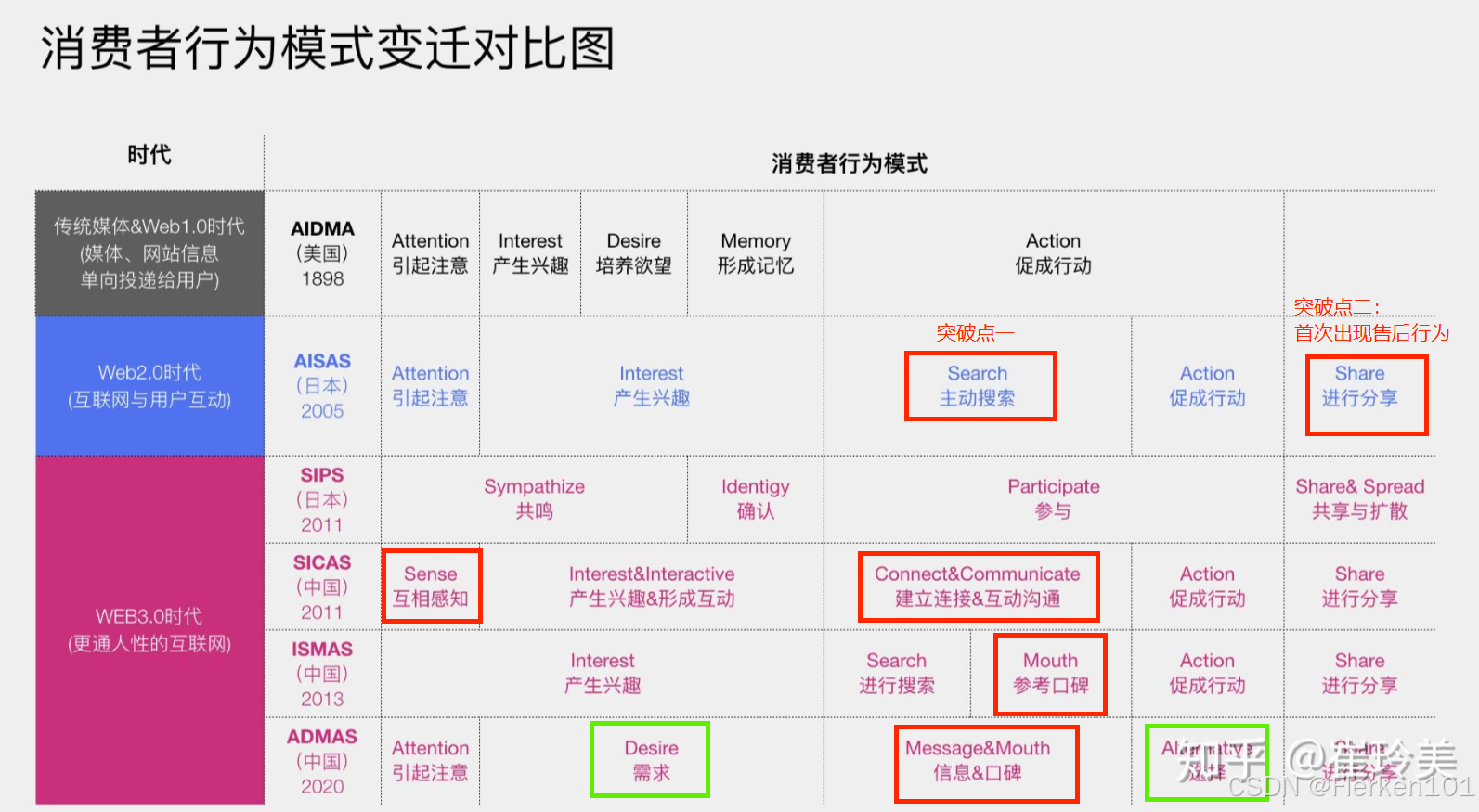
4.1.1.4.1 AIDMA
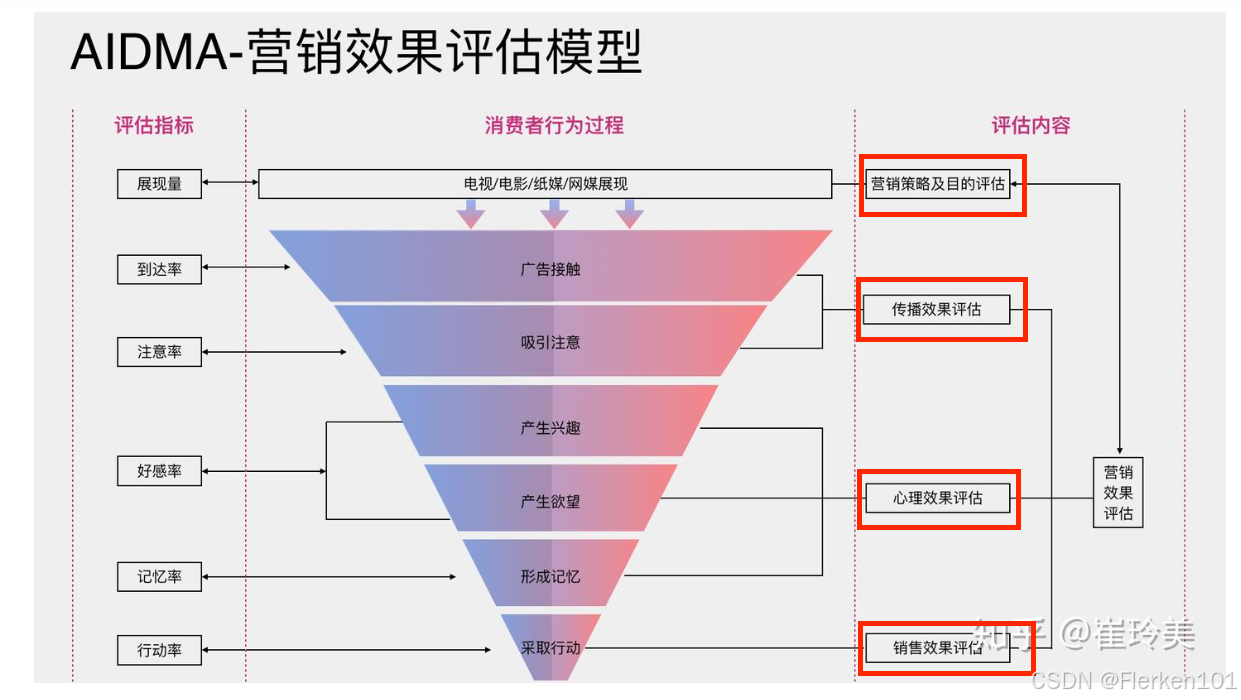

4.1.1.4.2 AISAS

基于AISAS模型的用户大数据时代商家精准营销效果评价指标体系的构建——施芬

4.1.1.4.3 SICAS

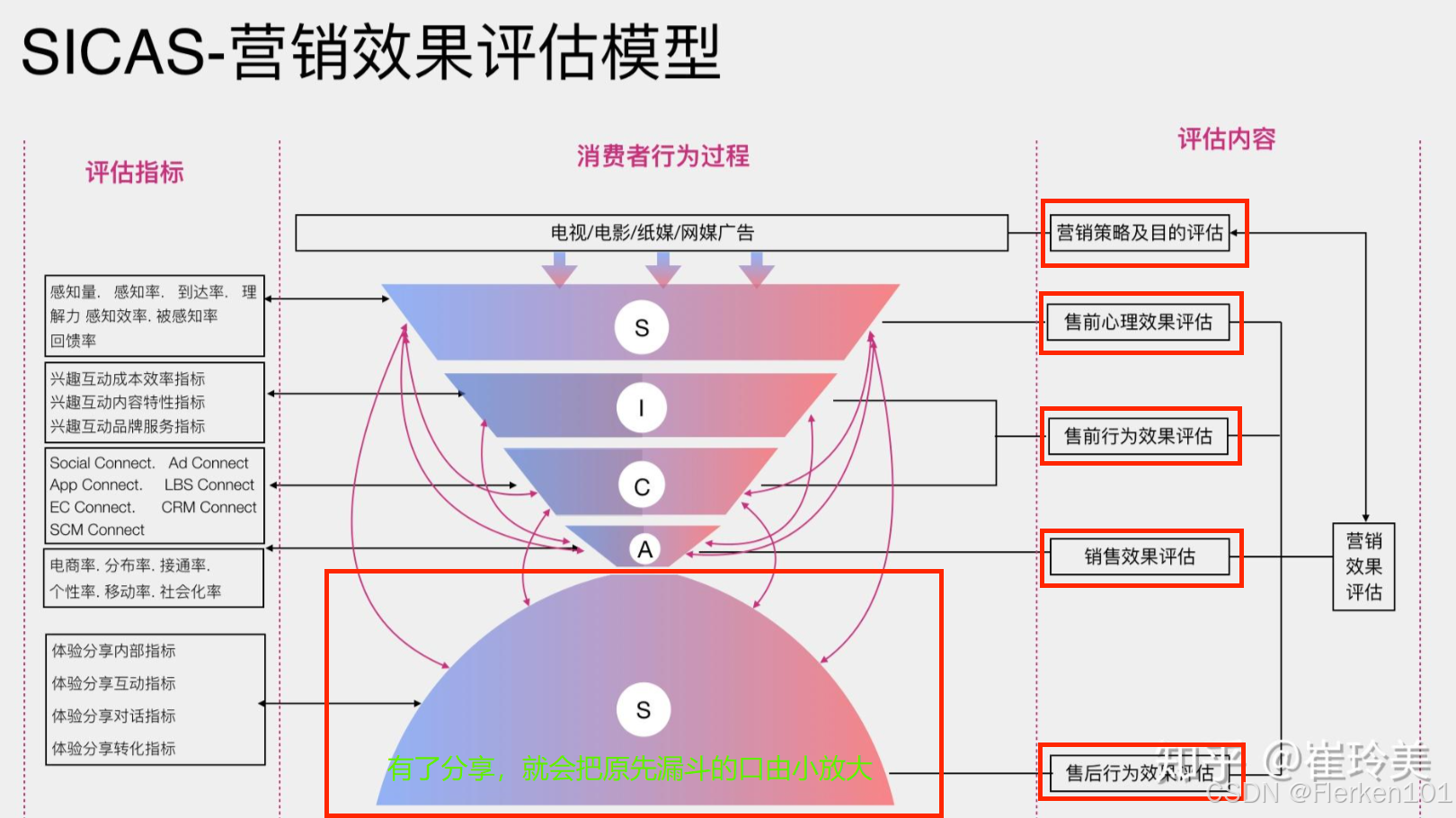
在互联网Web3.0时代,智能化的互联网应用为消费者行为的实时监测提供了可能性。
SICAS需要有精细化、大数据的广告效果监测能力,对使用的企业有一定的门槛要求。
DCCI通过技术手段对用户进行实时、连续、长期的监测后发现:用户的消费行为正在由线性的行为消费过程转变为网状、多点双向基于感知的连接,用户的体验分享正在成为真正意义上的消费源头。
以Iphone品牌触点图为例,社会化平台(社交平台)的品牌到达率、PV占有率及用户浏览时长均超过了门户官方网站,对用户的购行为决策的影响更大,是品牌接触的重要触点和未来发展的趋势。
SICAS建立了一套开放式的营销效果评估模型,帮助品牌商家解决“我知道我的广告费浪费了一半,但是却不知道哪一半被浪费了!”。
广告界有一个著名的“歌德巴赫式猜想”,那就是著名广告大师约翰•沃纳梅克提出的:“我知道我的广告费有一半浪费了,但遗憾的是,我不知道是哪一半被浪费了?
” 约翰•沃纳梅克被认为是百货商店之父,他也是第一个投放现代广告的商人。该问题的解决方式就是:实时、全面洞察消费者行为,并及时采取营销措施。
品牌商家首先要基于互联网的产品形态建立全网触点,来实时感知消费者行为动态,来敏捷指导、评估营销决策,让品牌信息能及时出现在消费者关心、可能产生消费欲望或消费需求的地方,精细化销售效果评估数据,精确考核ROI,品牌商家不仅要关注消费者的分享行为,还要参与、引导消费者的分享行为。
4.1.1.4.4 ISMAS、ADMAS
ISMAS 和 ADMAS都依赖的重要一环也是最难逾越的一环是“口碑”。
SICAS重视消费者的分享行为的价值,认为其有可能会是消费生产力的重要来源。
而在现在,社交媒体时代人际关系被重塑,口碑的形成的过程被搬到社交网络上进行,而更深层次的变化是,传播对象由地域/家庭组织,变成了由年龄/兴趣组织,这也改变了口碑的传播方式和影响范围。
ISMAS 和 ADMAS 强调在去广告媒体的环境中,消费者的兴趣、实际需求占据主导地位,口碑对消费者决策有重要作用。
进入互联网Web3.0时代,SICAS、ISMAS、ADMAS就对商家提出了更高的要求。
而ADMAS 更加发现了,消费者方面的一个变化:
不再是对产品产生兴趣,而是从消费者自身,产生了切实需求才可能购买,消费者也会更加理智,根据自己的想法,选择想要购买的商品。
所以,现在商家要做好:
①与消费者相互感知,建立连接,形成多维互动(实时、全面洞察消费者行为);
②过硬的产品力(形成良好口碑);
③及时有效的营销手段(让品牌信息能及时出现在消费者关心、可能产生消费欲望或消费需求的地方)、
④充分挖掘消费者的需求,并在同品类中保持竞争优势。
4.1.1.5 字节O-5A
从抖音“O-5A人群”与“巨量云图”看数字化营销的新革命(转)——小马哥
”抖音”根据营销大师菲利浦•科特勒提出的消费者购买行为理论,从研究消费者在抖音商城上的购买行为模式,总结出了实践版的5A人群,并通过”巨量云图“来做5A人群的数据化分析。
O-5A人群就是消费者从开始注意到商品,到最终购买商品及到长期拥护品牌,在这一流程中,分化出的5个阶段的特征人群。

O是指机会(Opportunity)人群,是指5A人群之前要先对机会人群进行提前规划。
A1人群是指顾客被动接受信息,是品牌知名度主要的来源。
A2人群是指增加顾客的品牌印象,创造短期记忆或扩大成长期记忆。
A3人群是指适度引发顾客的好奇,引发顾客搜集信息的行为。
A4人群是指用户的实际购买行为。
A5人群是指品牌的粉丝,对品牌已经形成长期拥护。
4.1.1.6 阿里AIPL
品牌数据引擎,是淘系专门进行消费者全生命周期运营(AIPL)的平台。
品牌数据引擎——入口
AIPL模型是一种将品牌用户资产定量化、链路化运营的手段。
A、I、P、L用于描述消费者与品牌的亲密度阶段。
其中:
A(Awareness): 品牌认知用户,一般指与品牌被动发生接触的用户,例如品牌广告触达和品类词搜索的人。
I(Interest): 品牌兴趣用户,一般指与品牌主动发生接触的用户,例如广告点击、浏览品牌/店铺主页、参与品牌互动、浏览产品详情页、品牌词搜索、领取试用、订阅/关注/入会、加购收藏的人。
P(Purchase): 品牌购买用户,包括发生过购买行为的人。
L(Loyalty): 品牌忠诚用户,例如购买用户中,发生了复购行为或对品牌有正面评价、分享的人。
说明:
阶段排序为A<I<P<L,若用户同时满足多个阶段的条件,则会被划归到最高级别阶段。例如:用户满足P,但是不满足L,会被划归到P,不论是否满足A、I.
AIPL用户分析
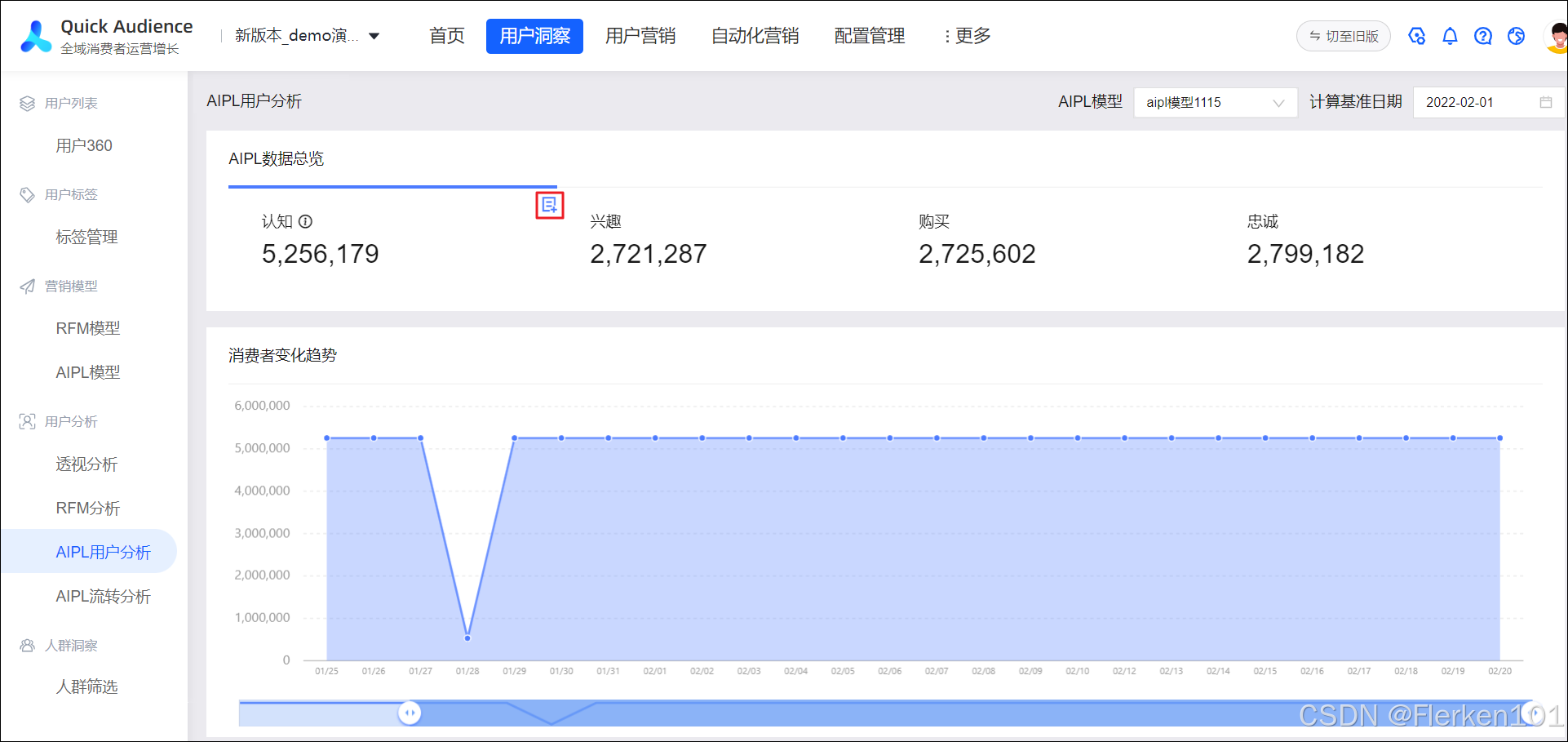
随着用户行为表数据更新,AIPL模型中的用户的AIPL状态可能发生变化,或存在新的用户进入AIPL模型等情况,此时可以通过AIPL流转分析,衡量一段时间内的用户运营是否成功。
AIPL流转分析
AIPL流转分析用于分析指定时间段内AIPL模型中各类用户的转化、流失情况,如下图所示。
若用户向下一种AIPL状态转化,说明其品牌忠诚度增加;若用户的AIPL状态回退或流失,可以将他们保存为人群,对其进行挽留或唤醒。
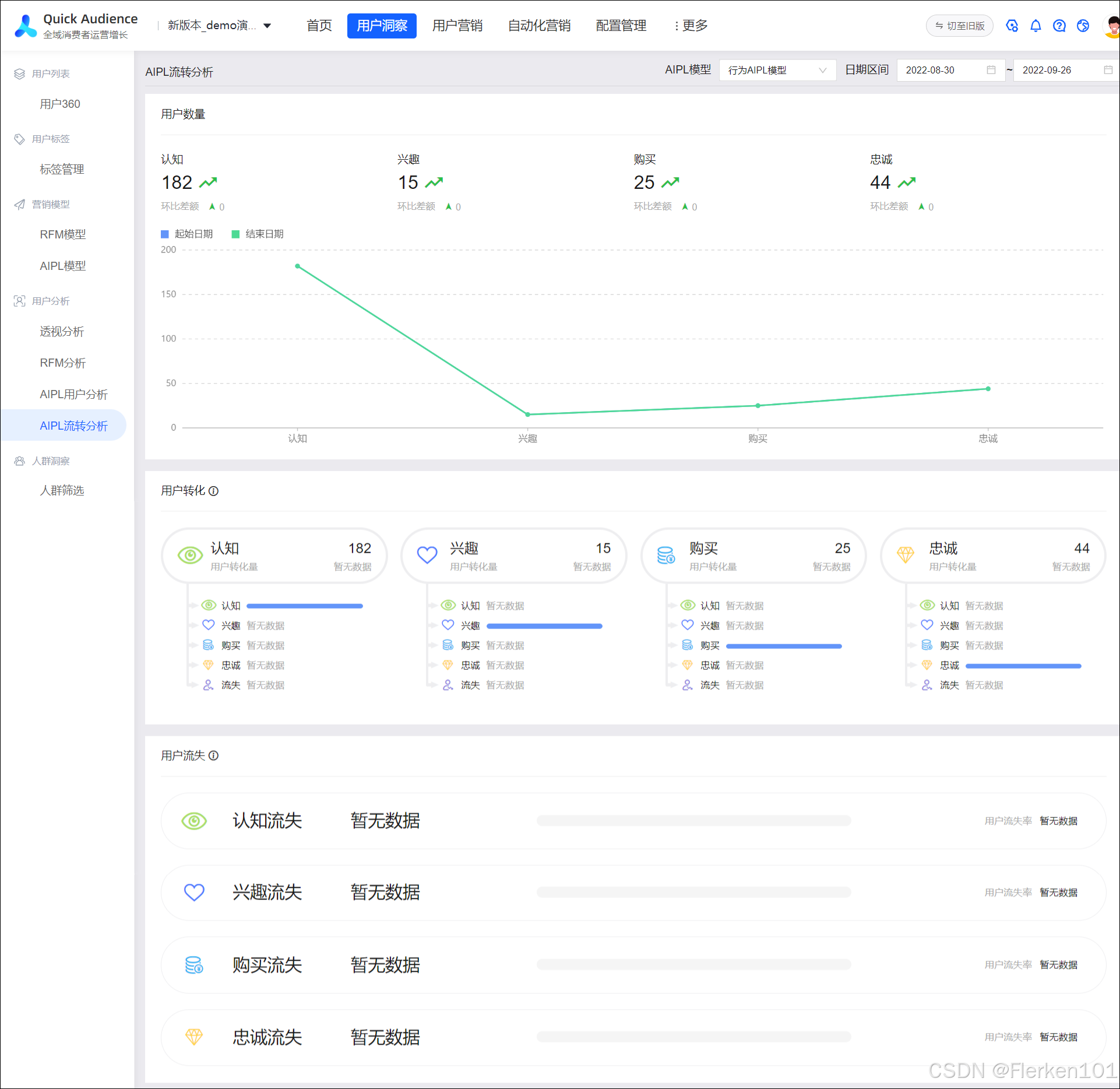
AIPL模型筛选——阿里云-用户洞察-洞察分析-群体筛选
AIPL模型筛选是基于AIPL模型的人群筛选,可按用户的AIPL模型类型或流转状态筛选。
按类型筛选:选择处于A认知、I兴趣、P购买、L忠诚阶段的用户加入人群。
按流转状态筛选:选择AIPL模型阶段发生变化的用户,例如从A认知阶段转化为P购买阶段的用户加入人群。
4.1.1.7 用户行为路径分析——桑基图
要保证每一次流转,各数量之和均保持不变。
在VisActor VChart 中,需要自己设置。
在Tableau中,可以直接实现。
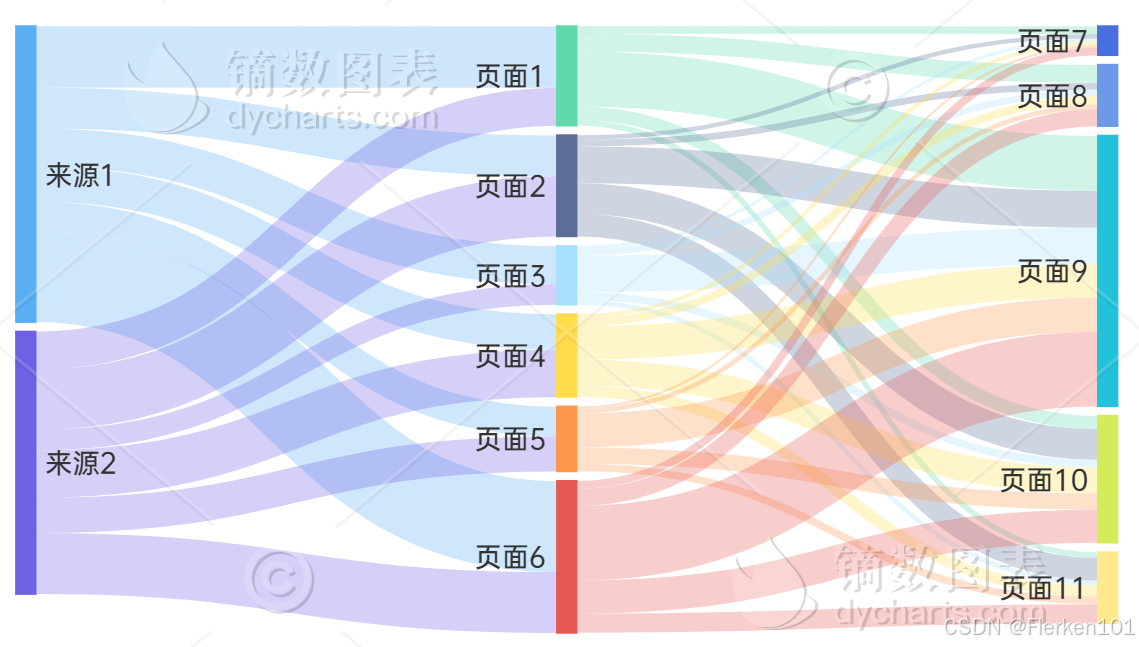
镝数图表官网——桑基图
在 镝数图表 最多只能制作三阶桑基图,而且有水印。
但只要根据桑基图要的数据结构,上传EXCEL表格即可。
origin绘图|如何整理桑基图的数据?——小也小也爱学习
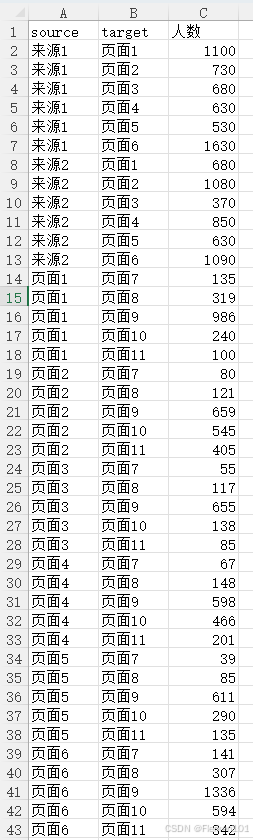
如果要制作三阶以上的桑基图,可以使用:
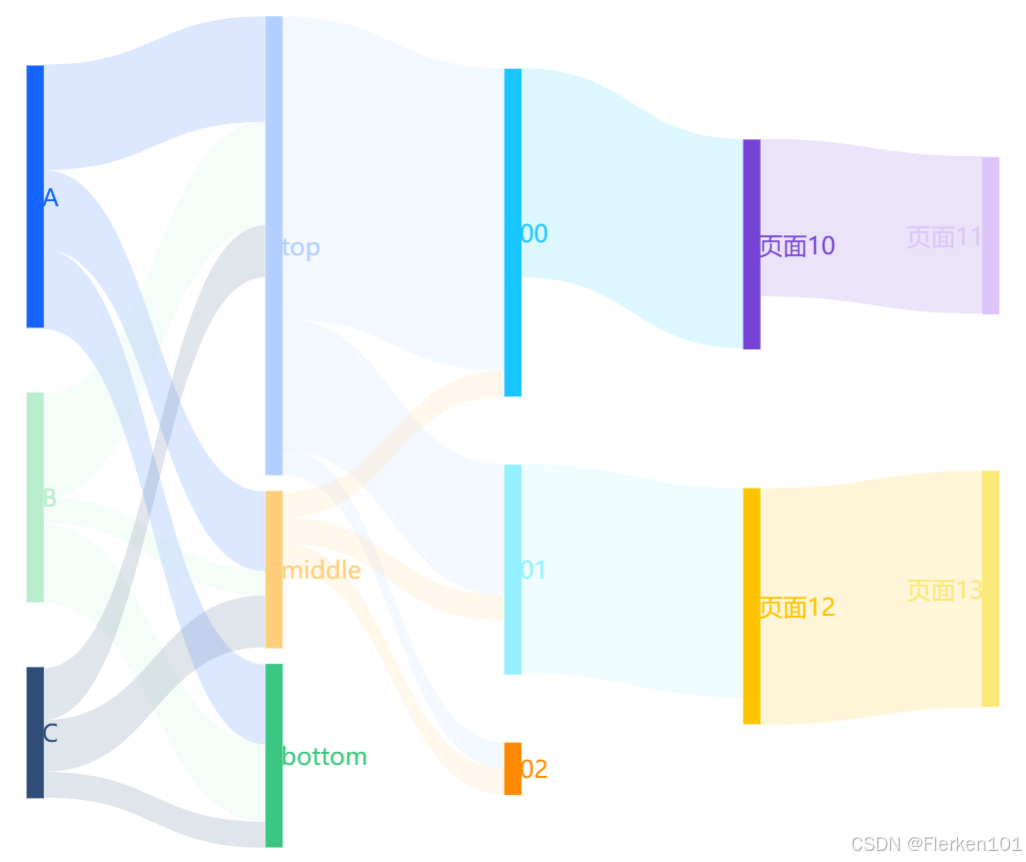
VisActor VChart 1.13.3——层级桑基图
要保证每一次流转,各数量之和均保持不变。
但网站中的示例并不是这样的,制作时需要自己设置。
每一个竖线/结点node结构,以及层级关系的设定都较简单,都可以用下面三个属性来定义:
{
value: 50, -- 流转过来的数值大小
name: 'C', -- 该标签的名称
children: [
{
name: 'top',
value: 20 -- 如果需要,先加上逗号,后面还可以再写childern
},
{
name: 'middle',
value: 20 -- 如果需要,先加上逗号,后面还可以再写childern
},
{
name: 'bottom',
value: 10 -- 如果需要,先加上逗号,后面还可以再写childern
}
]
}
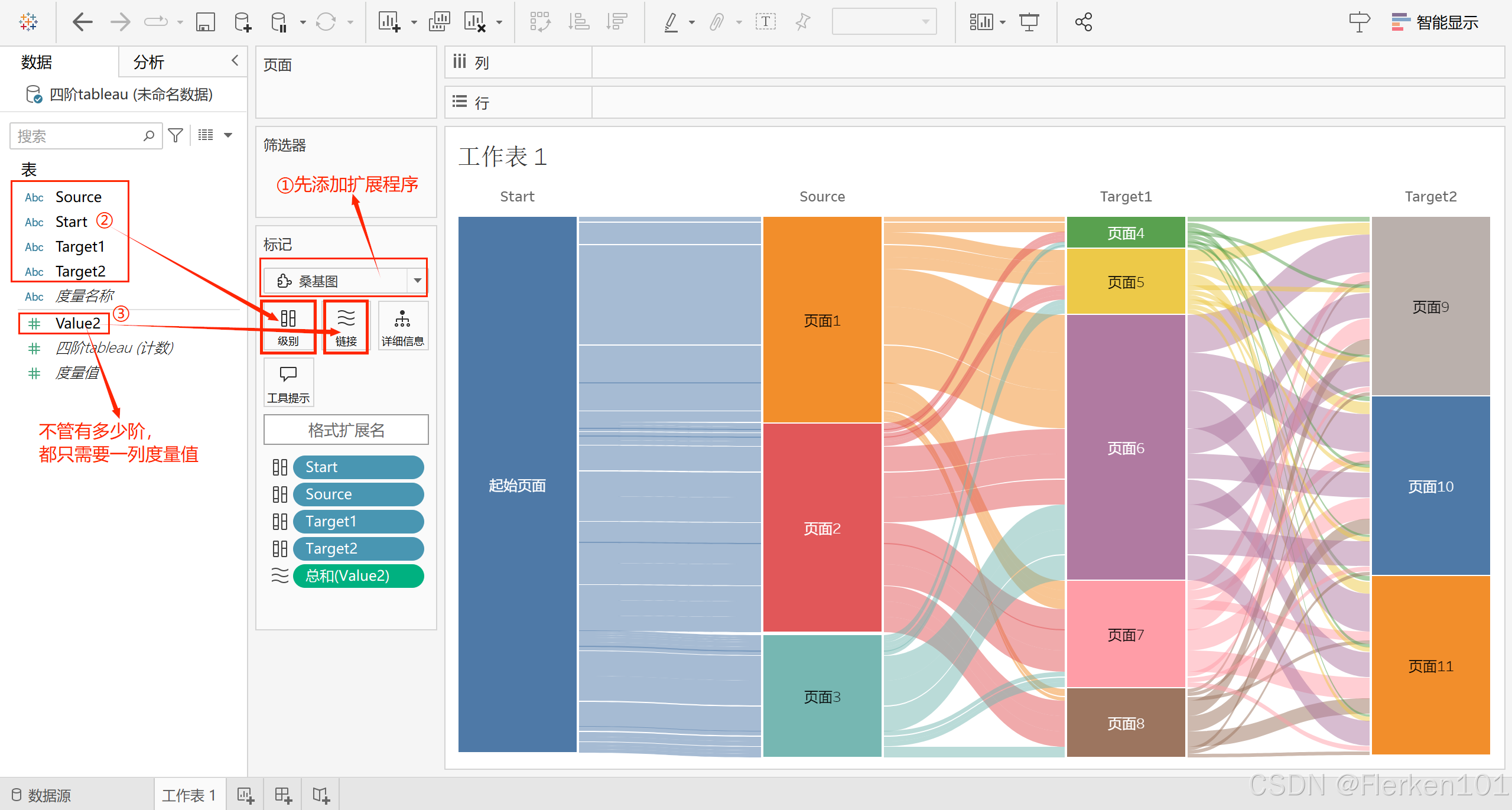
在Tableau中,可以制作任意阶数的桑基图:
①不需要整理数据结构为两列,有几阶就有几个维度。
②不管多少阶,都只需要最后一阶(最低阶)的度量值;
③且会自动对高阶的维度求和,从而保证每一次流转,各数量之和均保持不变。
4.1.2 用户体验
4.1.2.1 用户体验地图
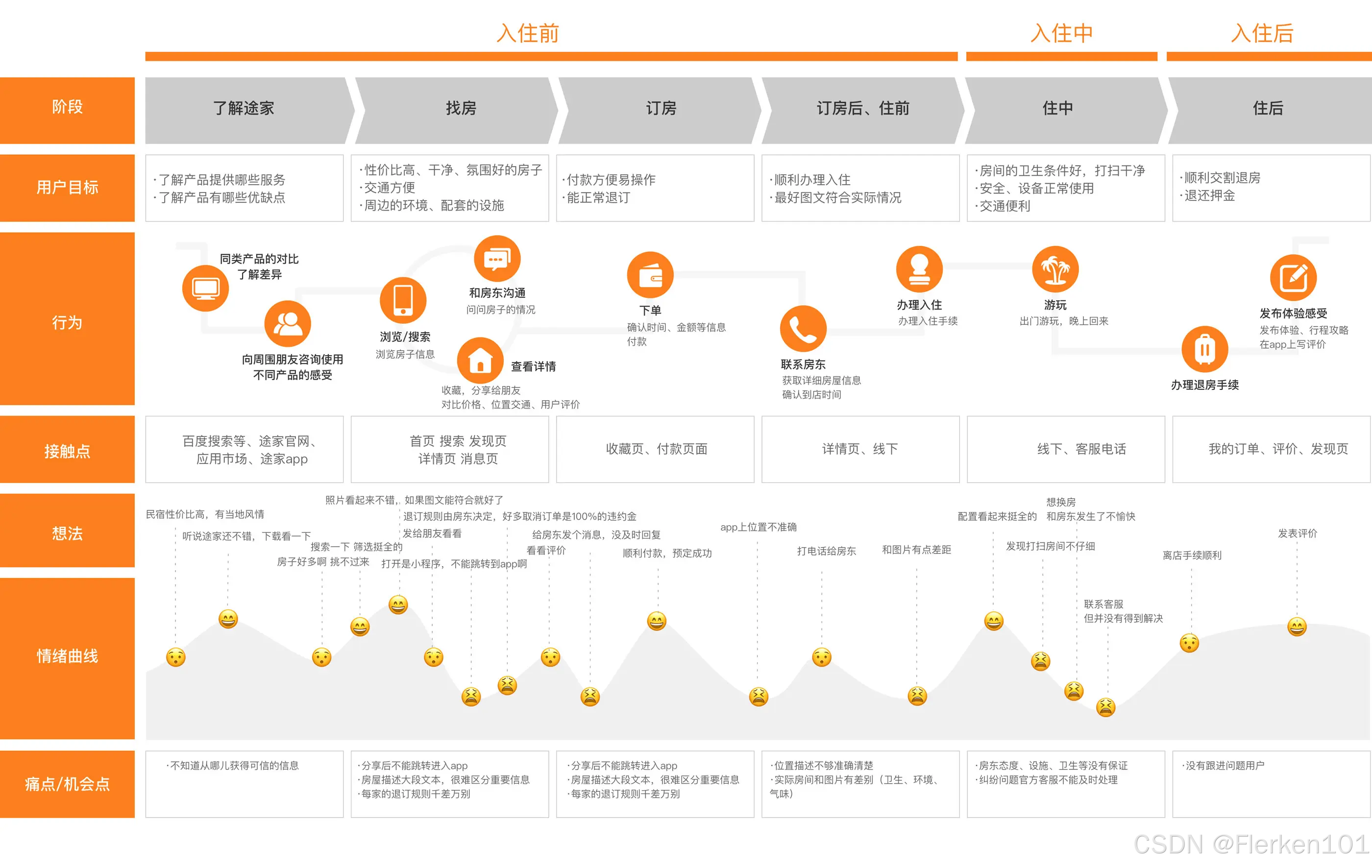
用户体验地图,是从用户的视角出发,去理解用户、产品或者服务交互的一个重要的设计工具。
它以可视化的形式,来表现一个用户使用产品或接受服务的体验情况,来发现用户在整个体验过程中的问题点与情绪点,从中提取出产品的优化点。
对于1-∞的产品来说,用户体验地图是用户增长策略的一部分,是产品优化的重要工具。
用户体验地图示例-途家
4.1.2.2 NPS模型(客户忠诚度)



NPS计算公式的逻辑是:推荐者会继续购买并且推荐给其他人来加速你的成长,而批评者则能破坏你的名声,并在负面的口碑中阻止你的成长。
现在,NPS已经成为了一个非常重要的来衡量产品的指标,这种调查工具以消费体验为核心,可以直观反映出人们内心对品牌的认可程度和购买意愿。

进一步细分:
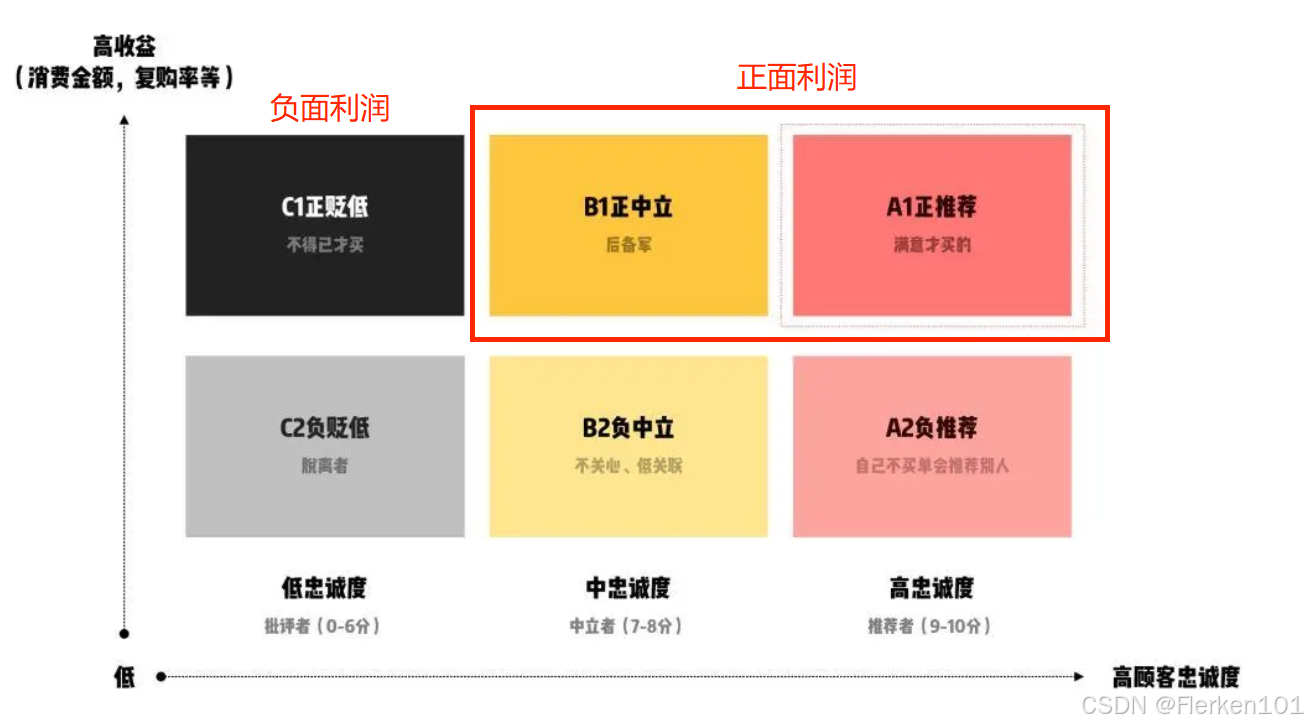
正代表 获得利润的客户;
(但“正”里面又分为正推荐、正中立、正贬低。)
其中,正推荐、正中立 属于 正面利润;正贬低 属于 负面利润。

负代表 没有获得利润,或者获得利润很低的客户。
(同样,“负”里面又分为负推荐、负中立、负贬低。)

如果你的产品真的不好,贬低型客户会处于正义感,帮助别人,不想让别人被坑、被骗的心理,劝说其它用户不要来买你的产品。
通过以上分析,了解到了某个用户的态度和行为,以及这个用户是否是你应该继续发展的用户,净推荐值可以帮助企业找到工作中的缺陷存在。
举例来说:如果你进行了一笔生意,但给你钱的客户是个贬损者,付完钱他就开始对你进行负面传播,那么实际上你可以说没有收益。
在现有的环境中,大量的市场趋于饱和、利润增速放缓,因此我们可以转向重视用户价值的运营方式,维持超级用户群体,努力将贬损者转化成推荐者,持续的发现问题并且优化,行为一个以用户为核心的运营优化体系。
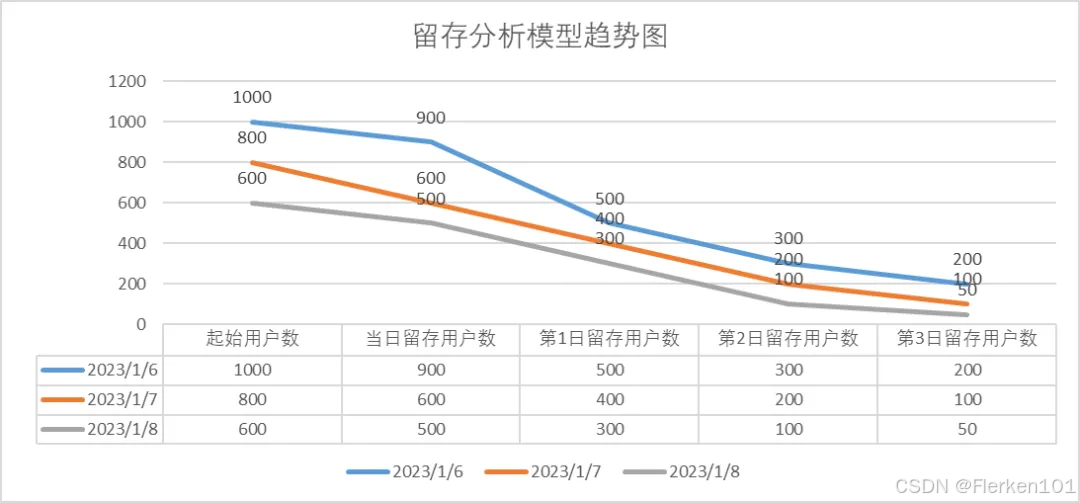
4.1.3 留存分析
用户行为分析模型实践(四)—— 留存分析模型——vivo 互联网大数据团队- Wu Yonggang、Li Xiong
3日内的留存用户趋势图:

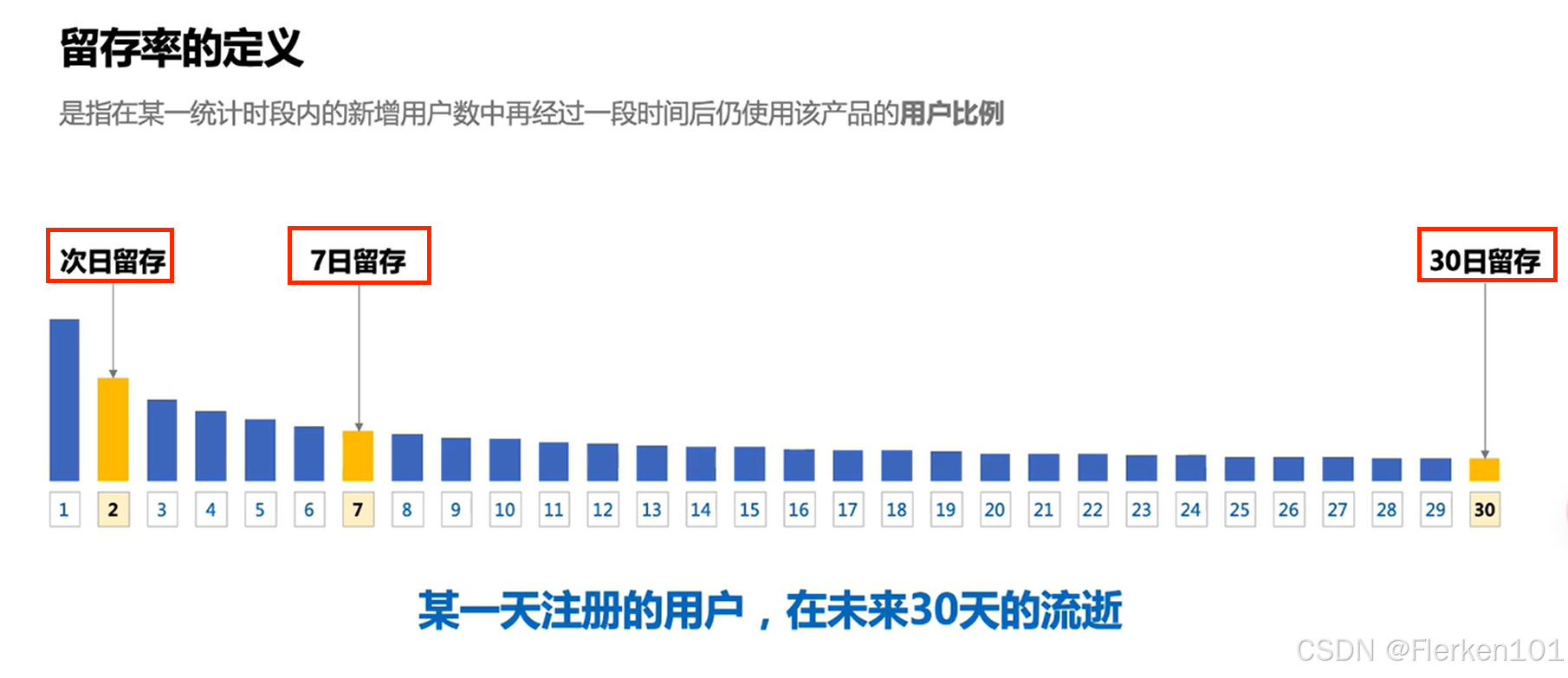
4.1.3.1 留存率是如何影响用户的
4.1.3.2 每日活跃用户数是怎么样被构成的
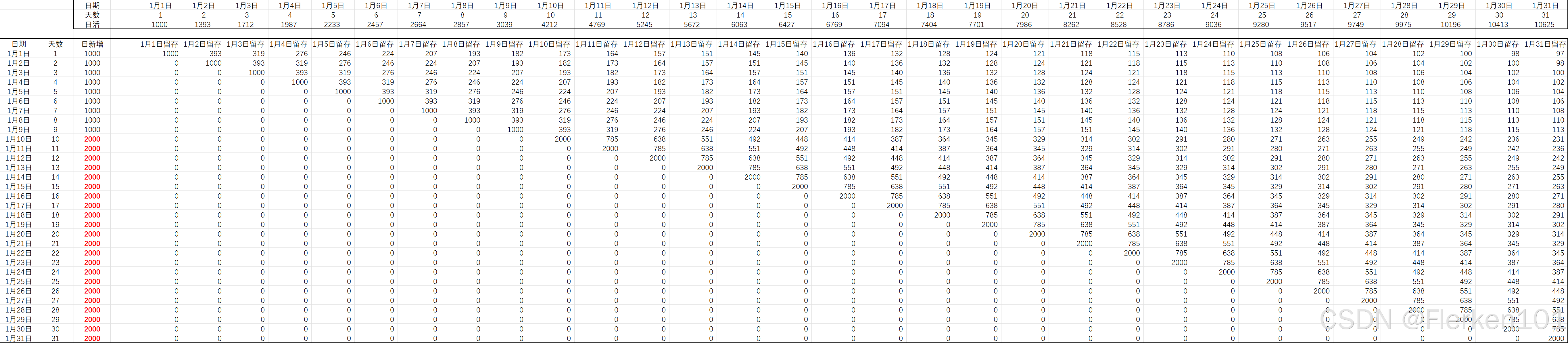
假设产品运营是稳定不变的,每日的新增用户数也相同。
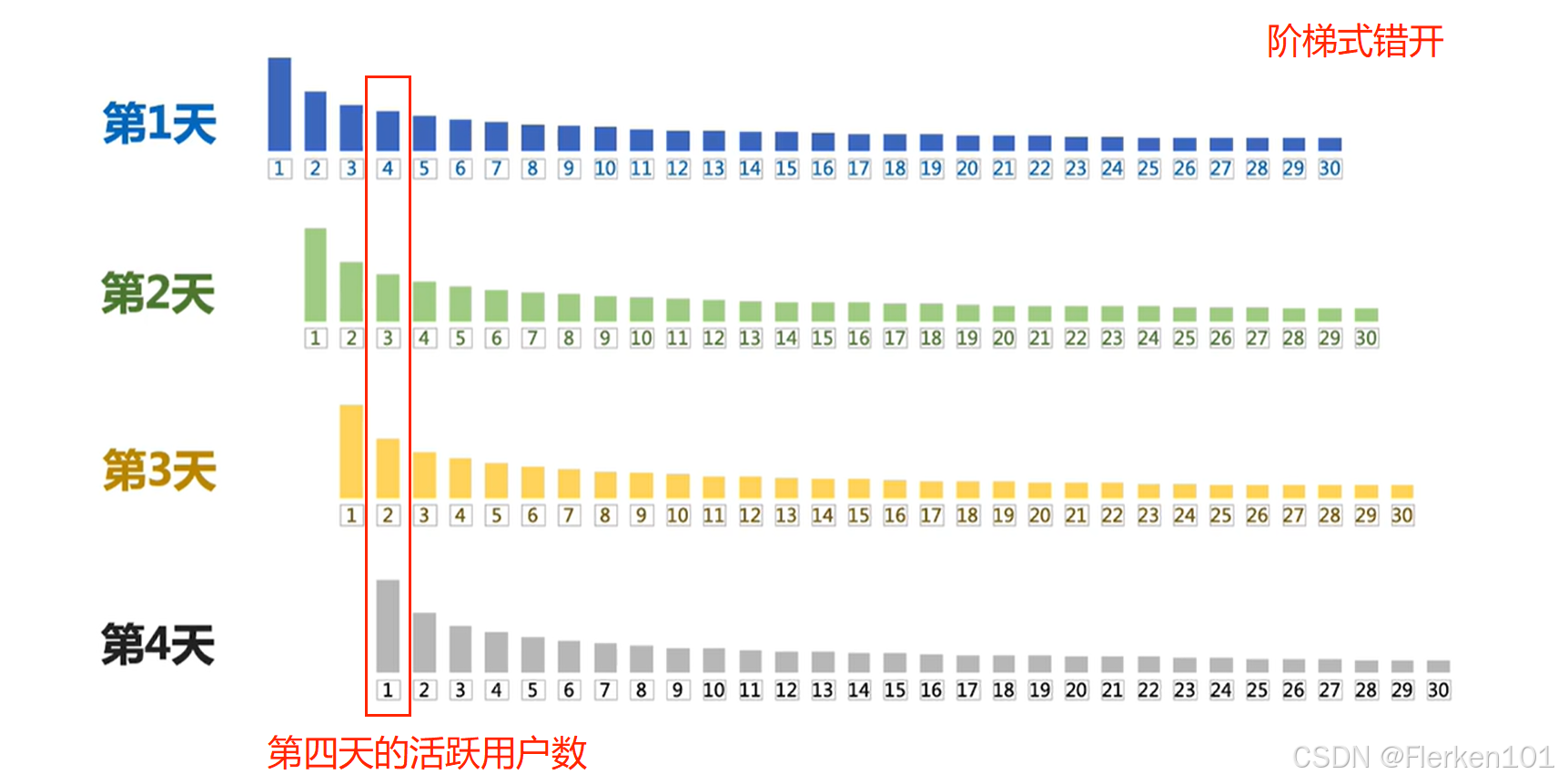
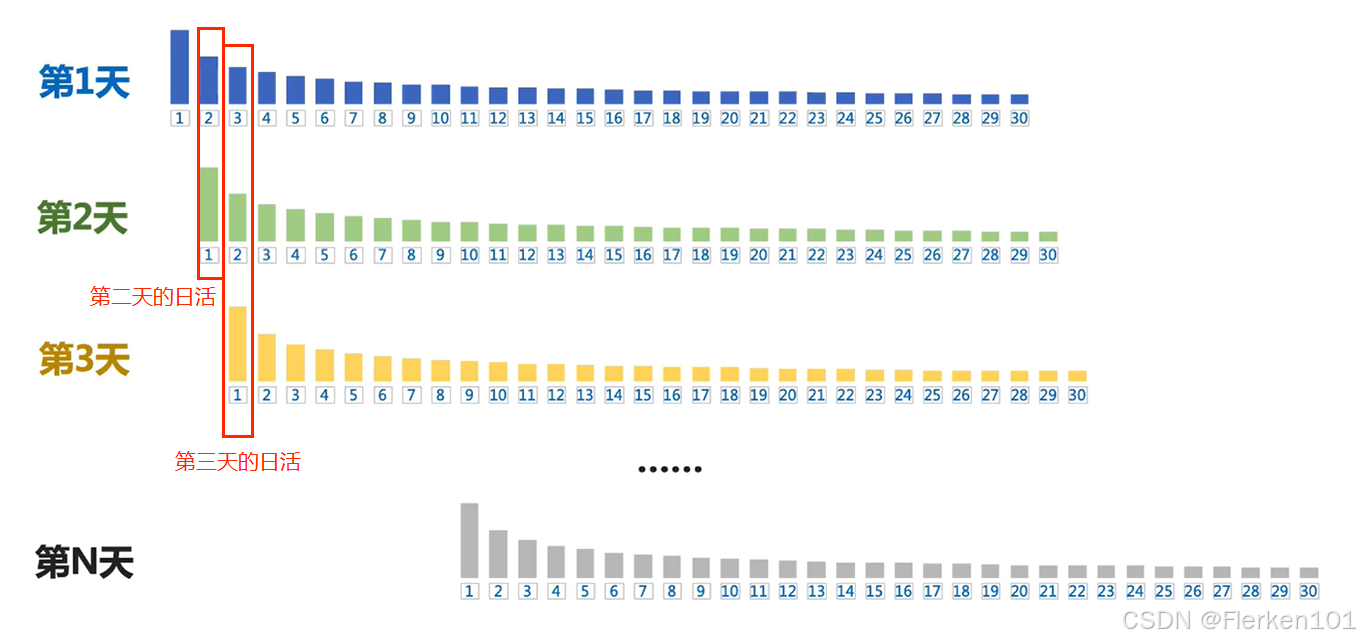
在假设下,第4天的活跃用户,共包含4个片段:
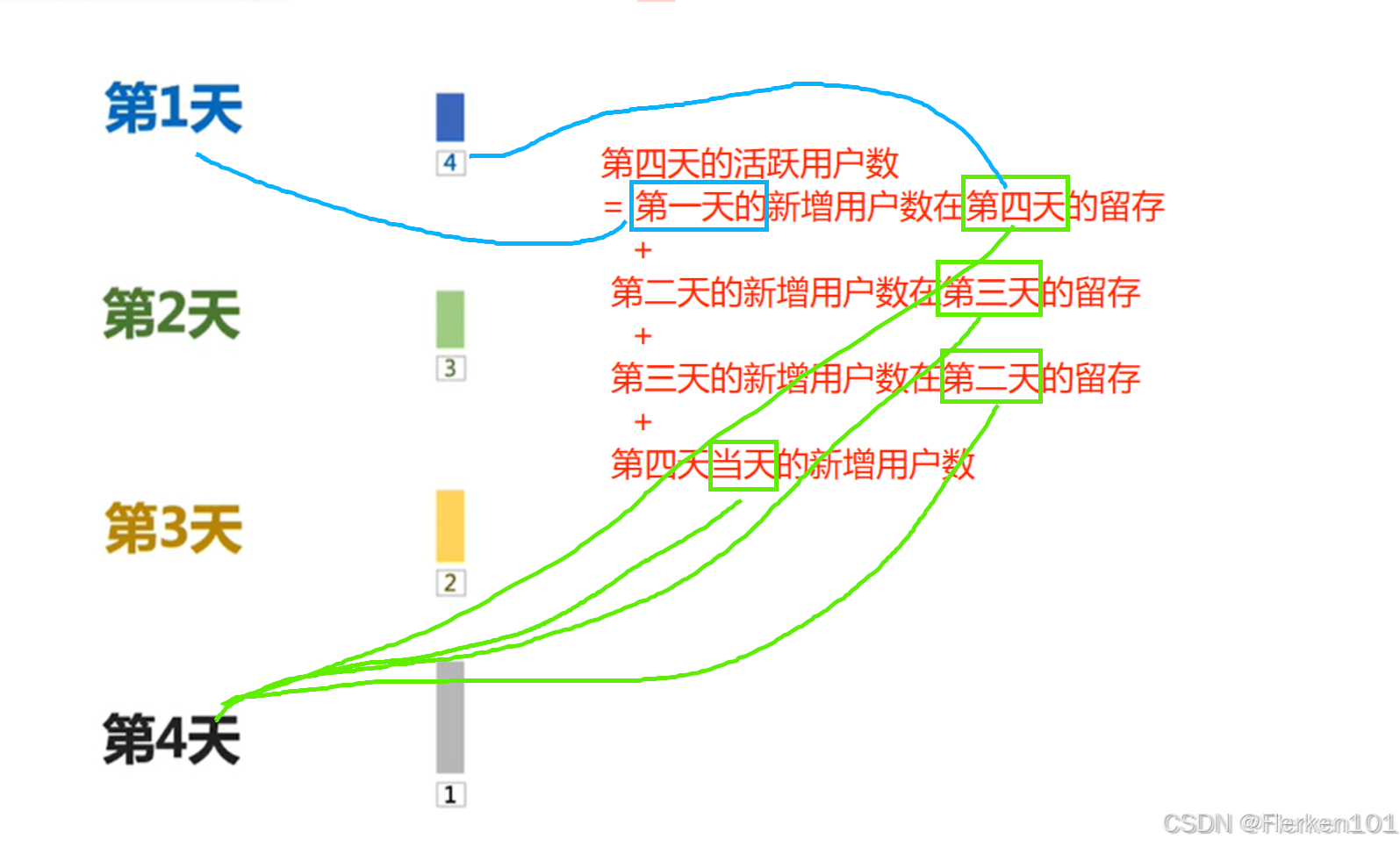
在假设下,第30天的活跃用户,共包含30个片段:
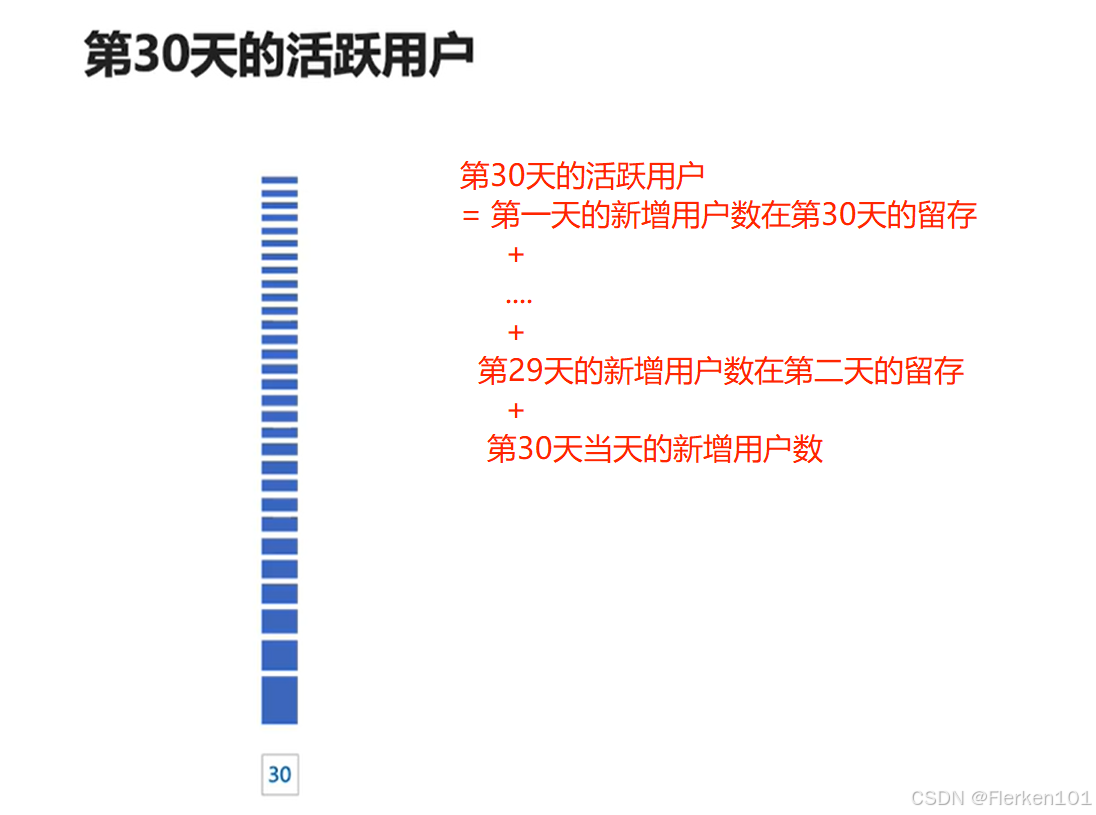
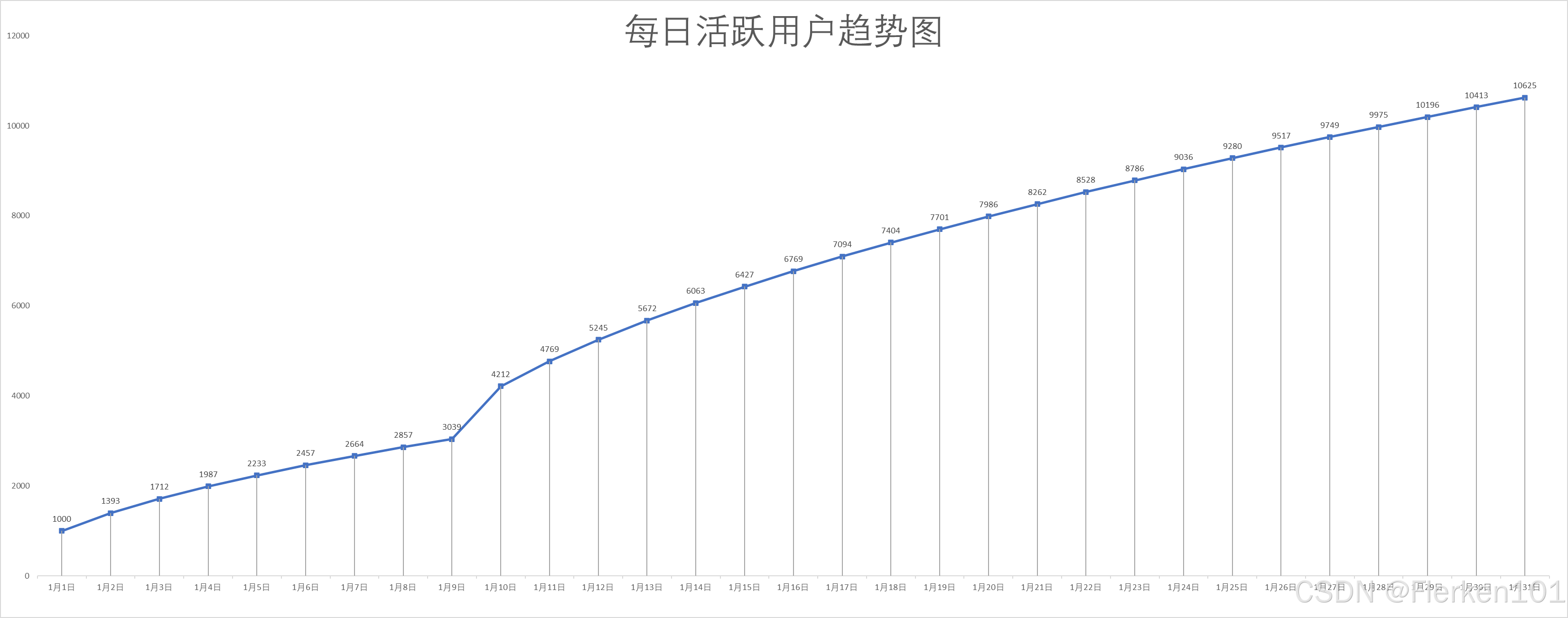
4.1.3.3 题目一:计算第30天的日活

要在EXCEL计算中抽象出变量(此处新增用户数、常数、幂都是变量),只要修改变量的值,就可以修改所有的计算结果值。
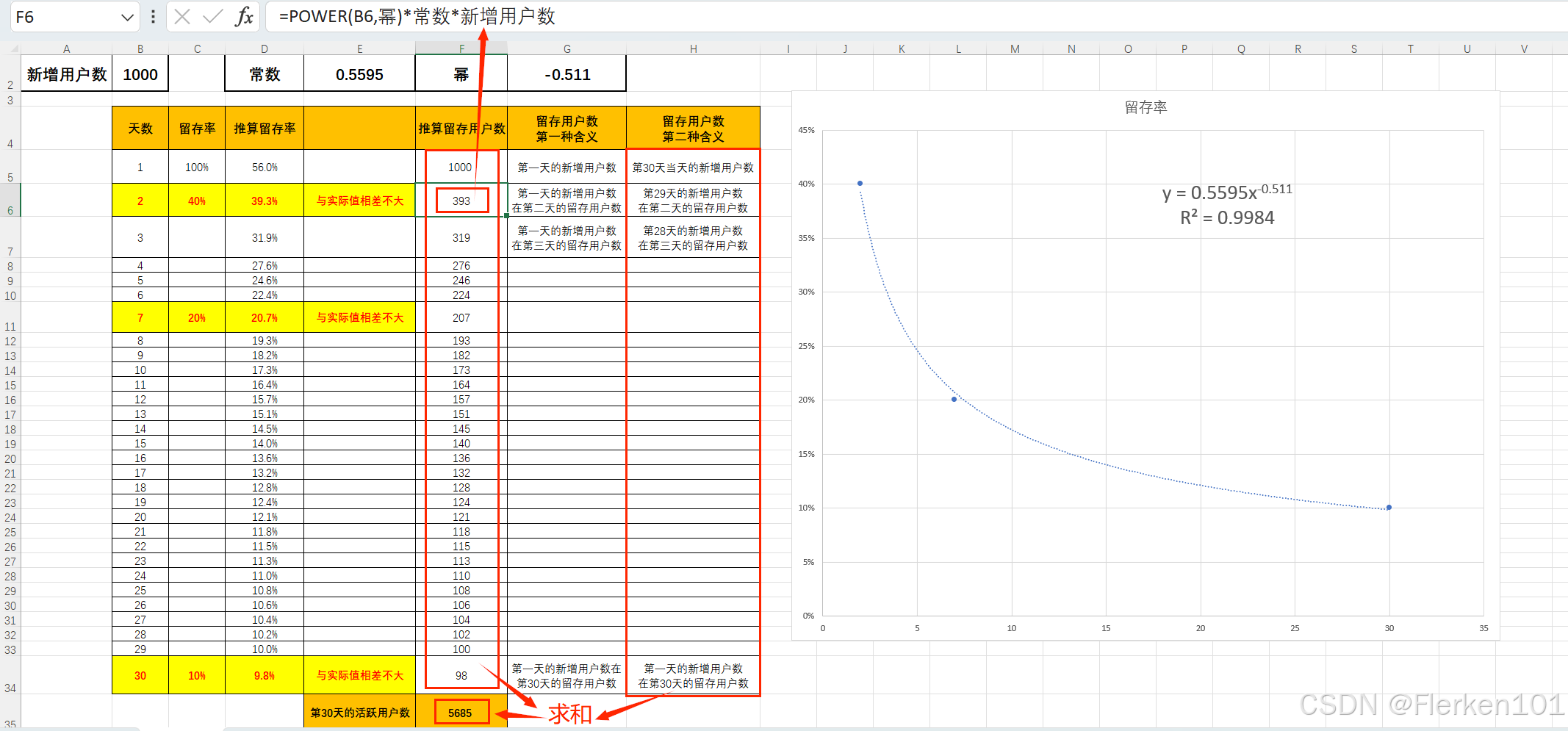
4.1.3.4 题目二:计算本月的1日-30日每天的日活

情况1:假设1月1日是产品上线的第一天,在1月1日之前,没有任何历史客户。
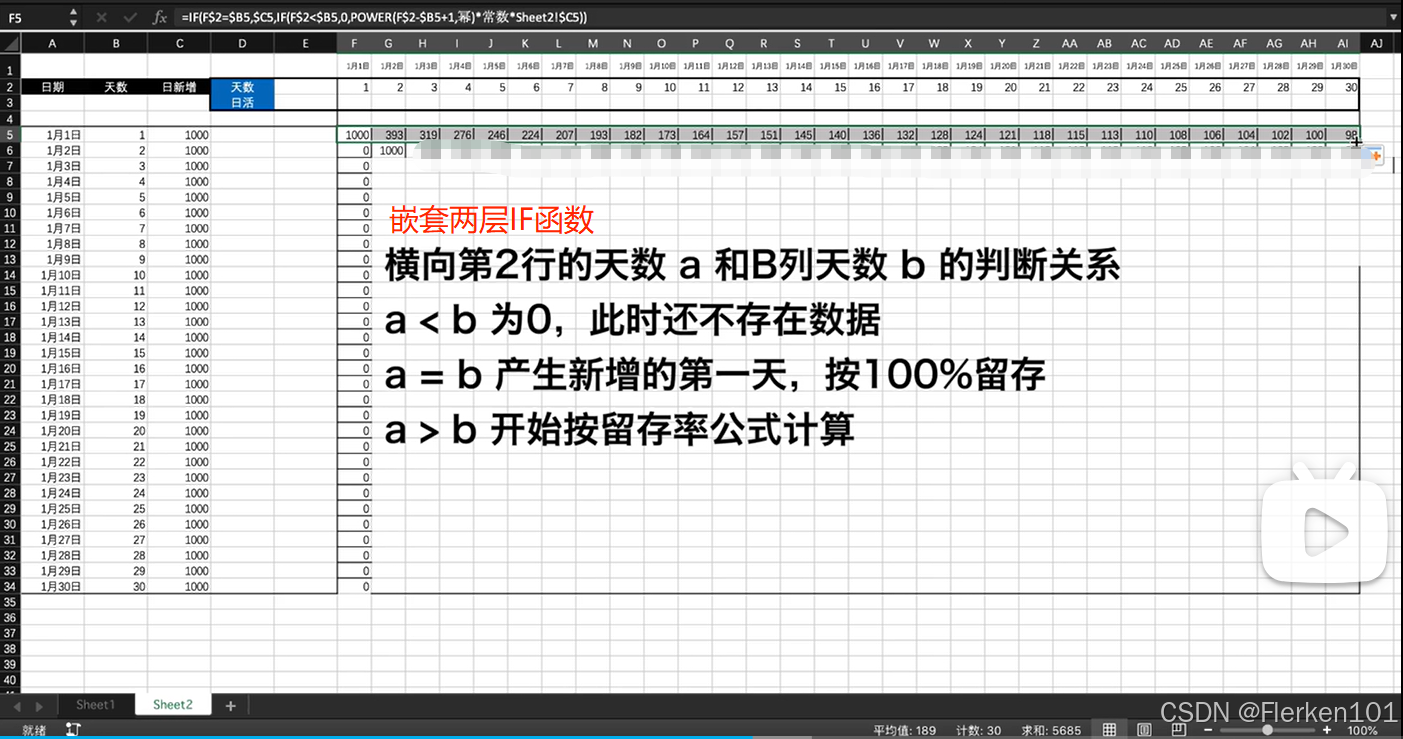
该趋势是严格单调递增的。
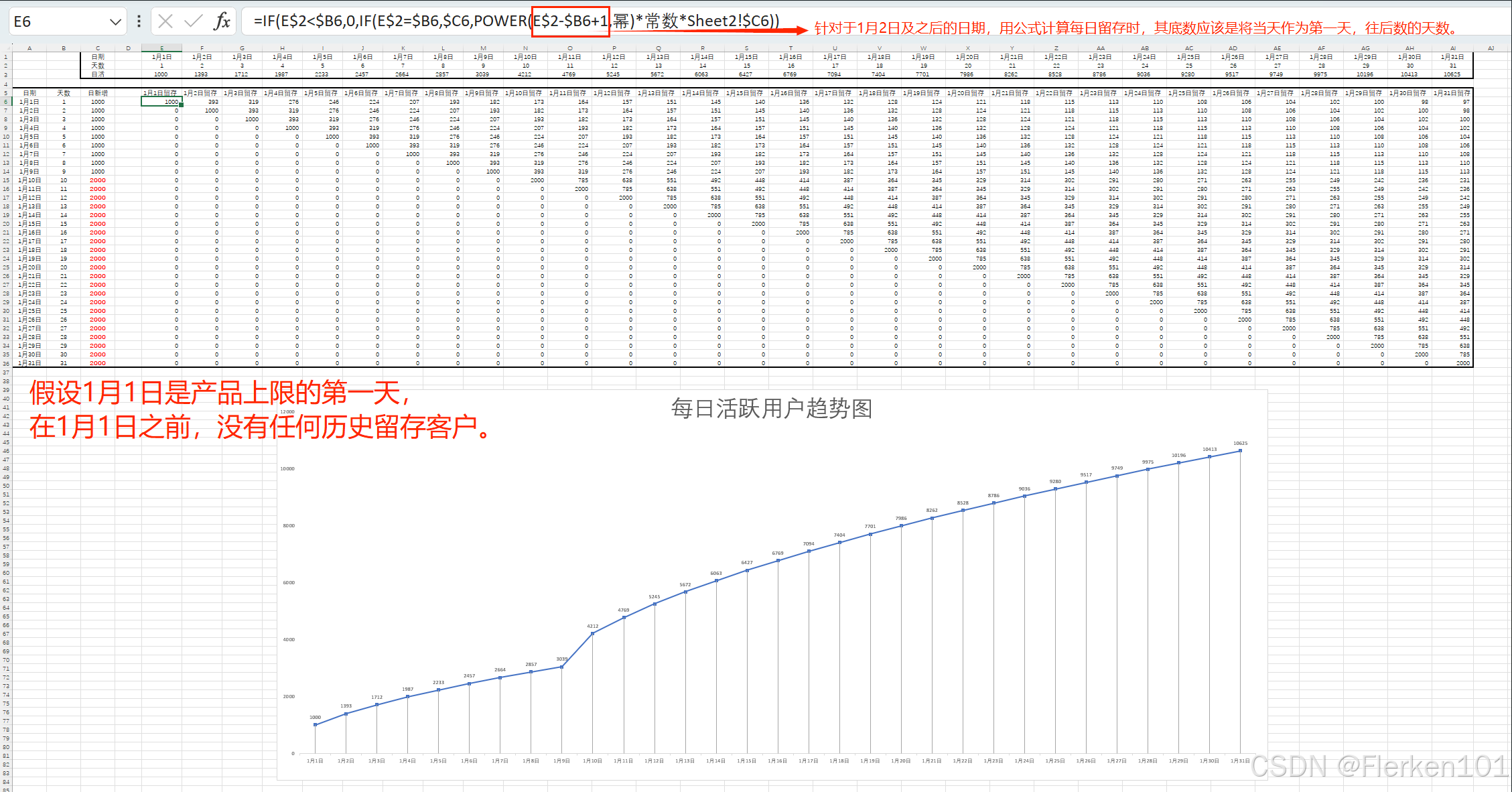
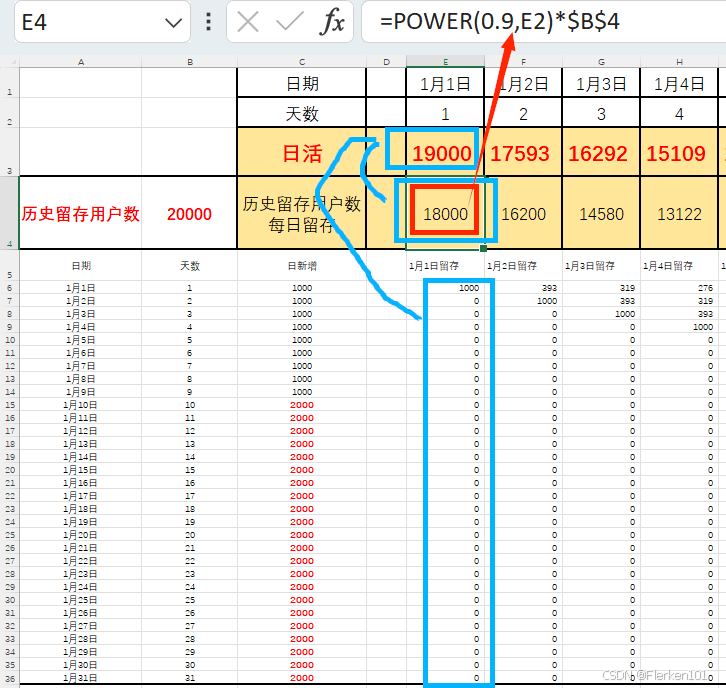
情况2:假设1月1日之前,有20000个历史留存客户。
且假设这部分用户,在1月1日及之后的每天,每天会流失掉10%的客户。每天会流失掉10%的客户,这个数字还是比较大的,一般可能是5%左右。
因为不清楚这20000个历史日活用户数,是哪一天新增的用户。所以无法使用这里的公式来计算每日留存
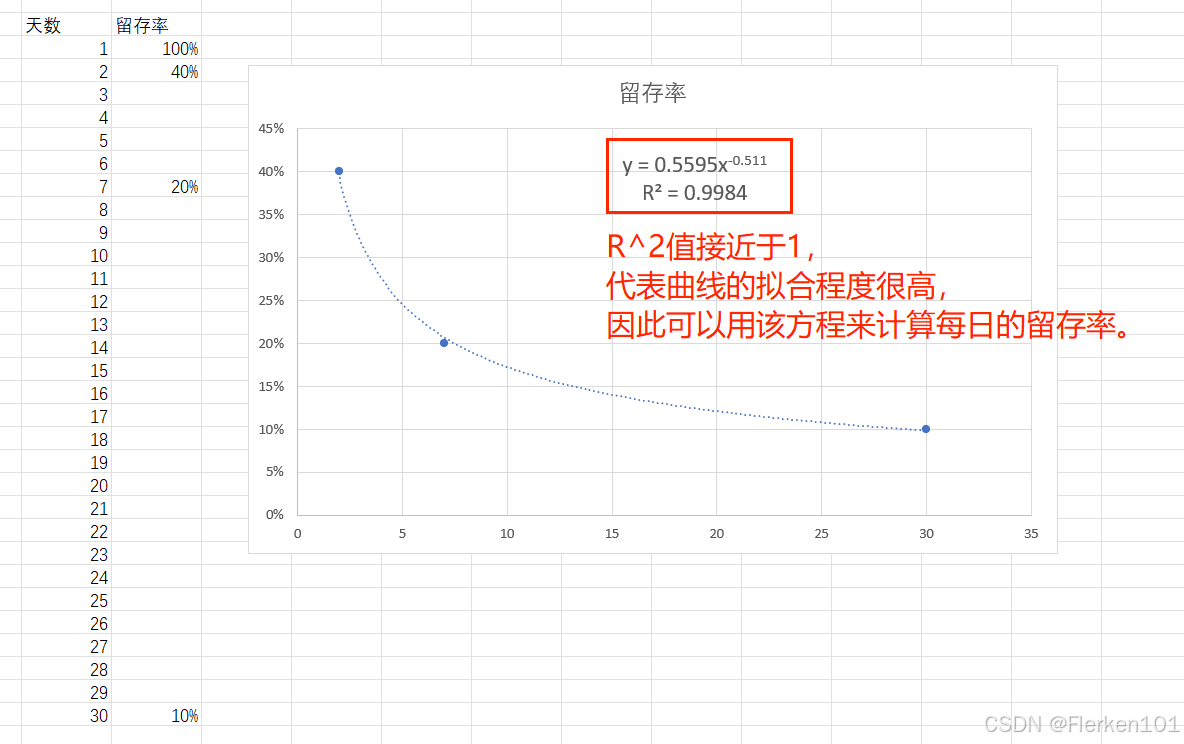
y = 0.5595 * x^(-0.511) [R^2=0.9984]如果有更好的历史数据,可以拟合出每日活跃用户数,在之后每一天的留存率,则可以使用历史数据进行拟合,得出新的公式,来计算在1月1日之前历史的这20000个用户,在1月1日及之后每天的留存数,再将其增加到1月1日及之后,每日活跃用户数中即可。
假设1月1日之前,有20000个历史留存客户。 且这部分用户,在1月1日及之后的每天,每天会流失掉10%的客户。
情况2结果:
可以发现如果假设在1月1日之前,已经有20000个历史日活用户, 且这部分用户,在1月1日及之后的每天,每天会流失掉10%的客户。
因为这部分历史留存用户减少得太快,即使加上1月1日及之后每日的新增用户数和自1月1日开始的每日留存用户数,1月1日及之后每日的活跃用户数也可能会先有一个下降的趋势。
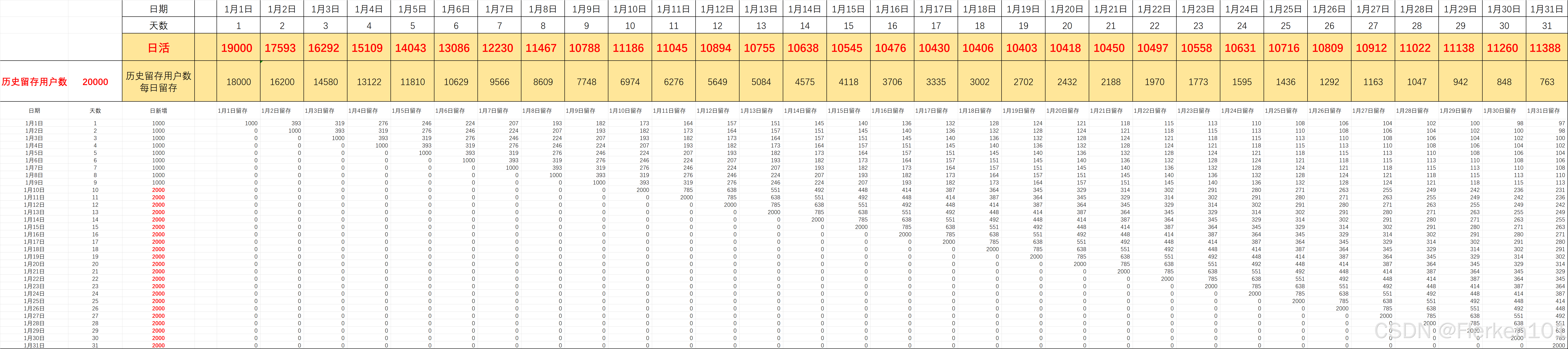
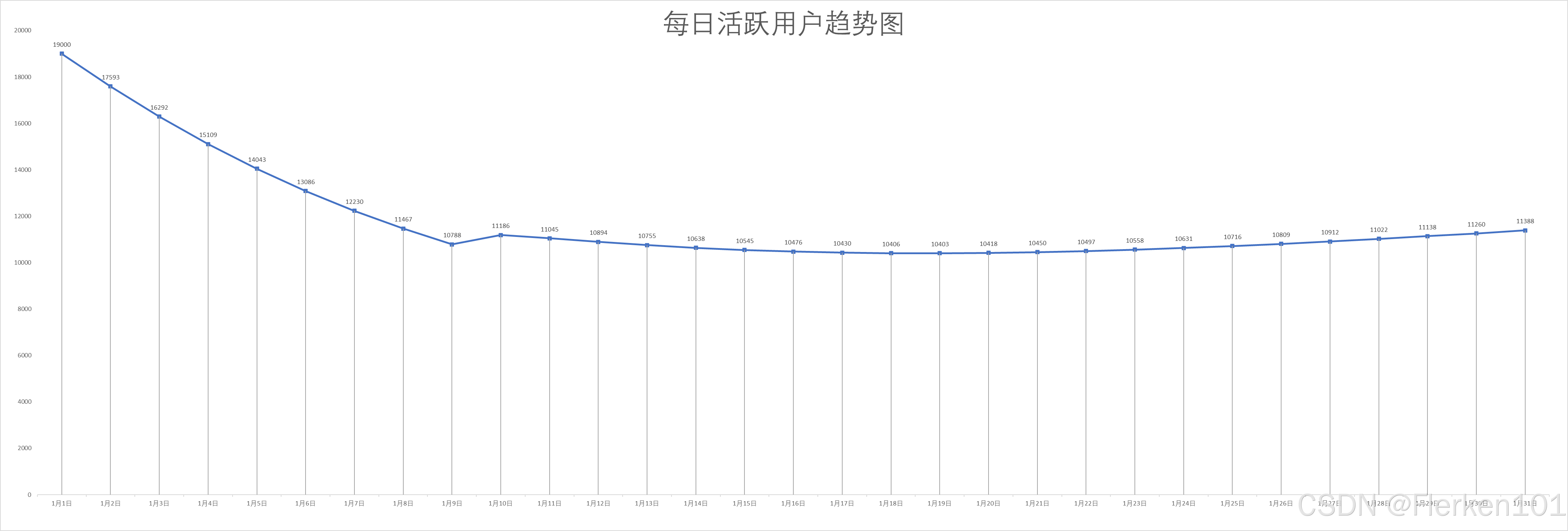
计算某一天(第41天)的当日活跃用户数

4.1.3.5 应用方式
可以通过以上方式,可以制作出一个季度、半年的用户增长的变化趋势图。
计算留存率和日活用户数,最重要的是明白两点:
①留存率是怎么去影响用户的;
②每日活跃用户数是怎么样被构成的。计算出留存率和日活用户数后,先解决留存和新增的问题:
①怎么去改变提升留存率;
(比如次日留存率从40%提升到50%,七日留存率从20%提升到40%,30日留存率从10%提升到30%等)
②怎么去提高每日新增的用户数(比如从1000到2000)。最后,再提升留存用户的用户价值:
每个用户到底是能提供2块钱的用户价值,还是200块钱的用户价值。
4.1.4 同环比分析
同比、环比图表怎么做?No.1漂亮的Excel双层数据分析图来了!——轩哥说Excel
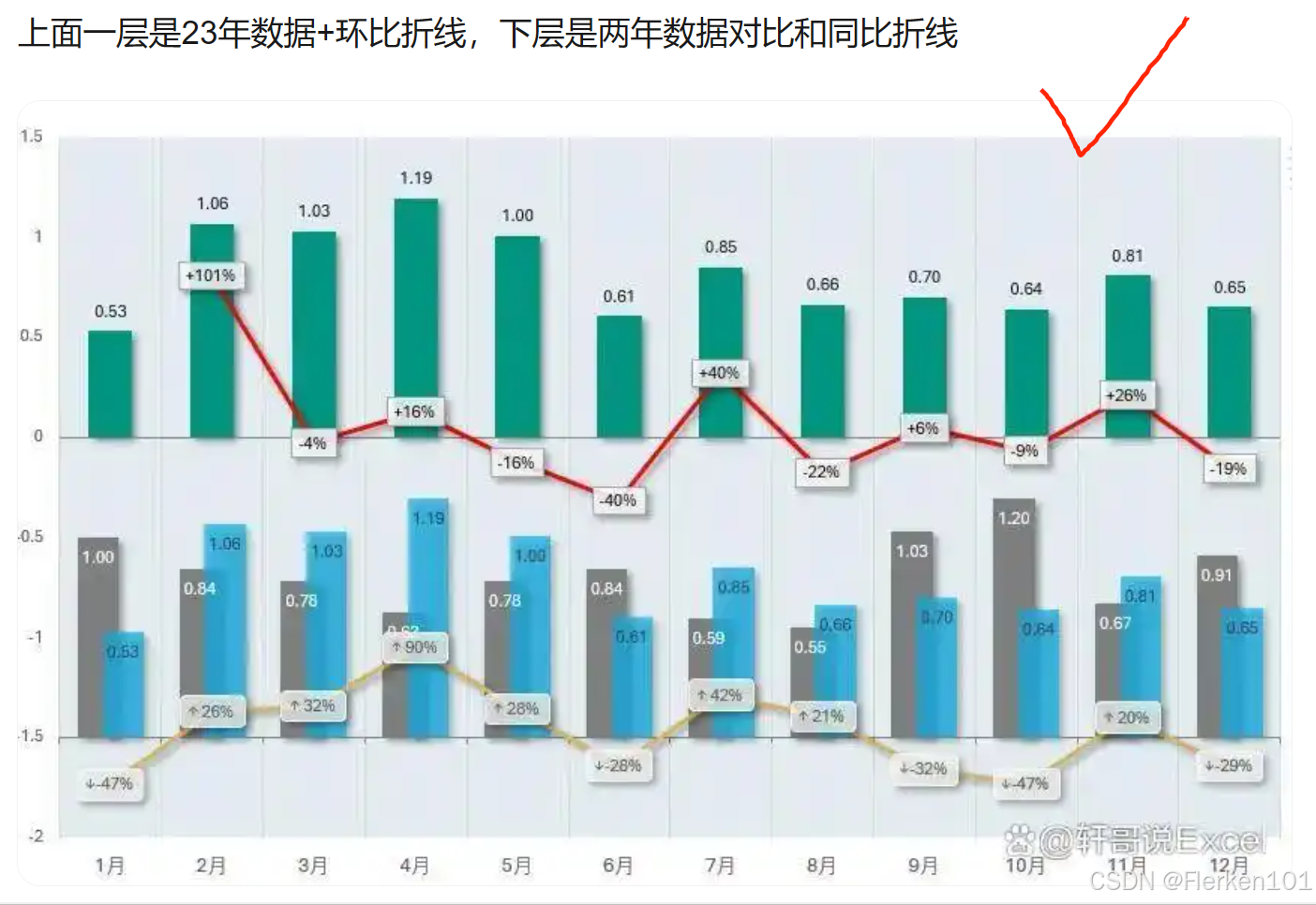
复现:
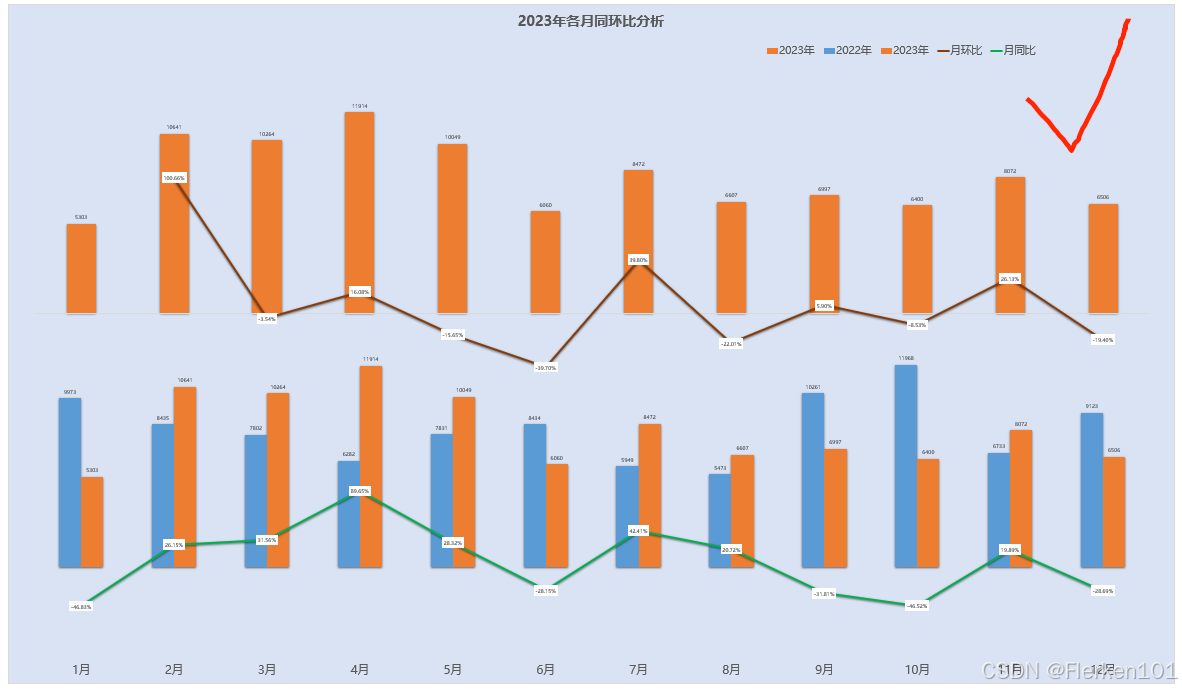
复现:
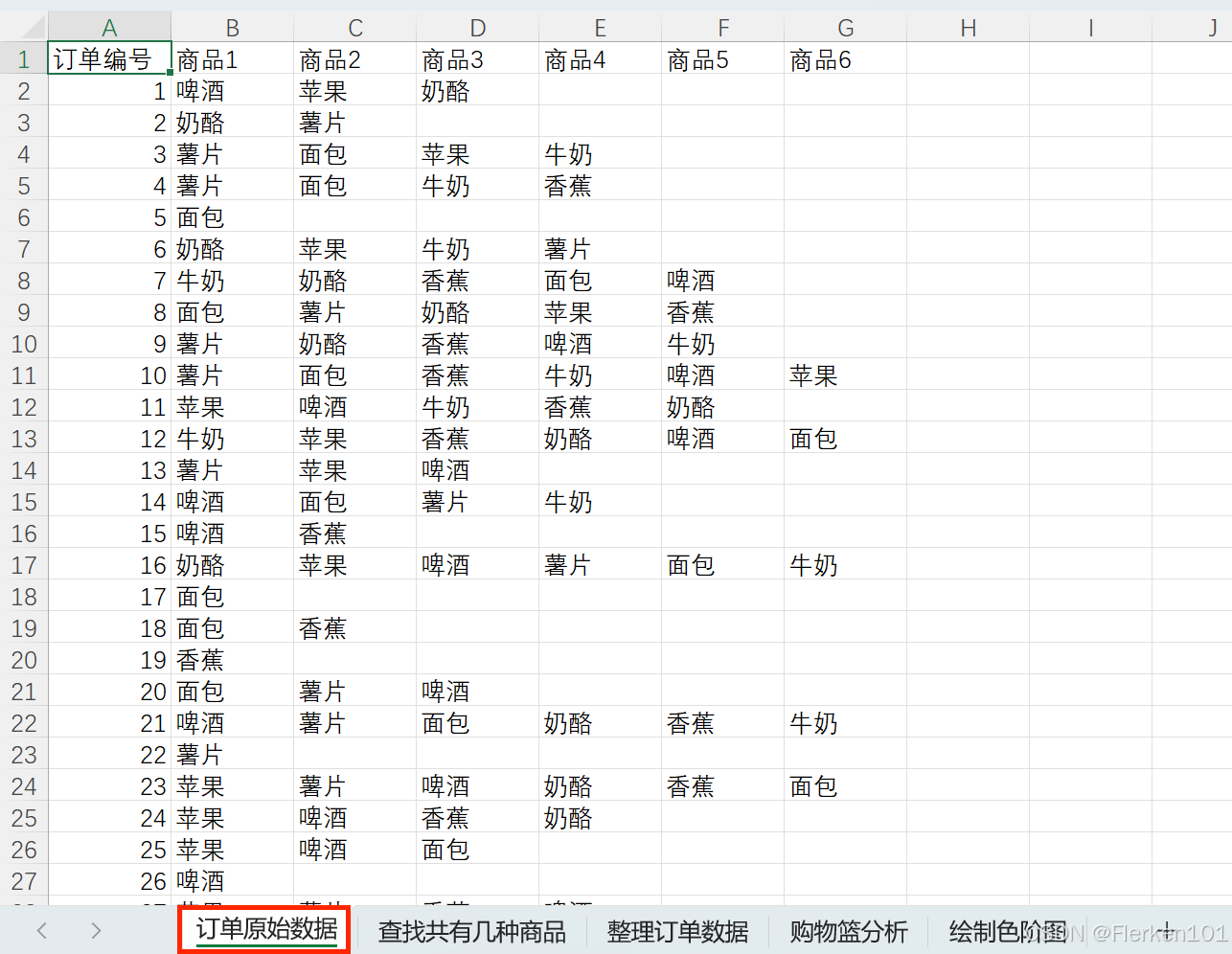
4.2 相关性分析——购物篮分析/关联分析法
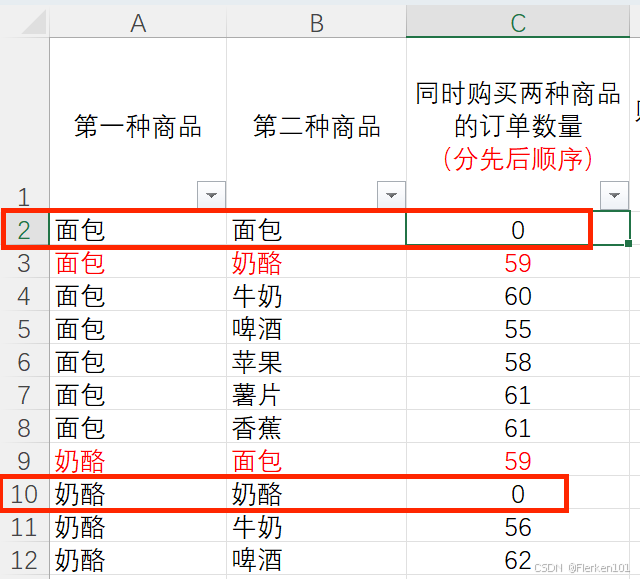
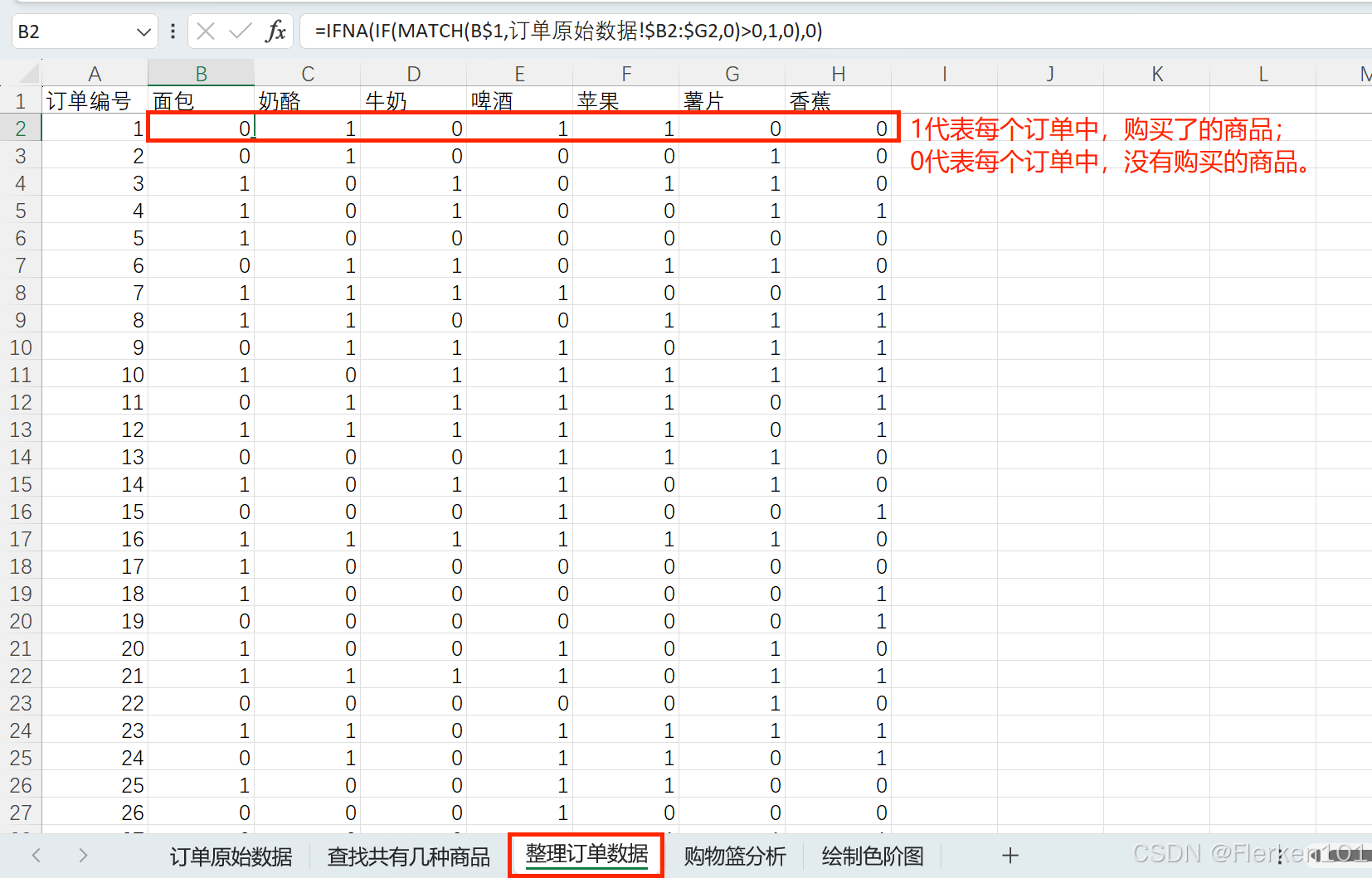
获取原始数据:
购物篮数据两种商品间的关联分析——qixinlei
复现其思路:
常用数据分析模型:购物篮模型——商品关联分析——邪恶马铃薯
EXCEL复现操作要点:
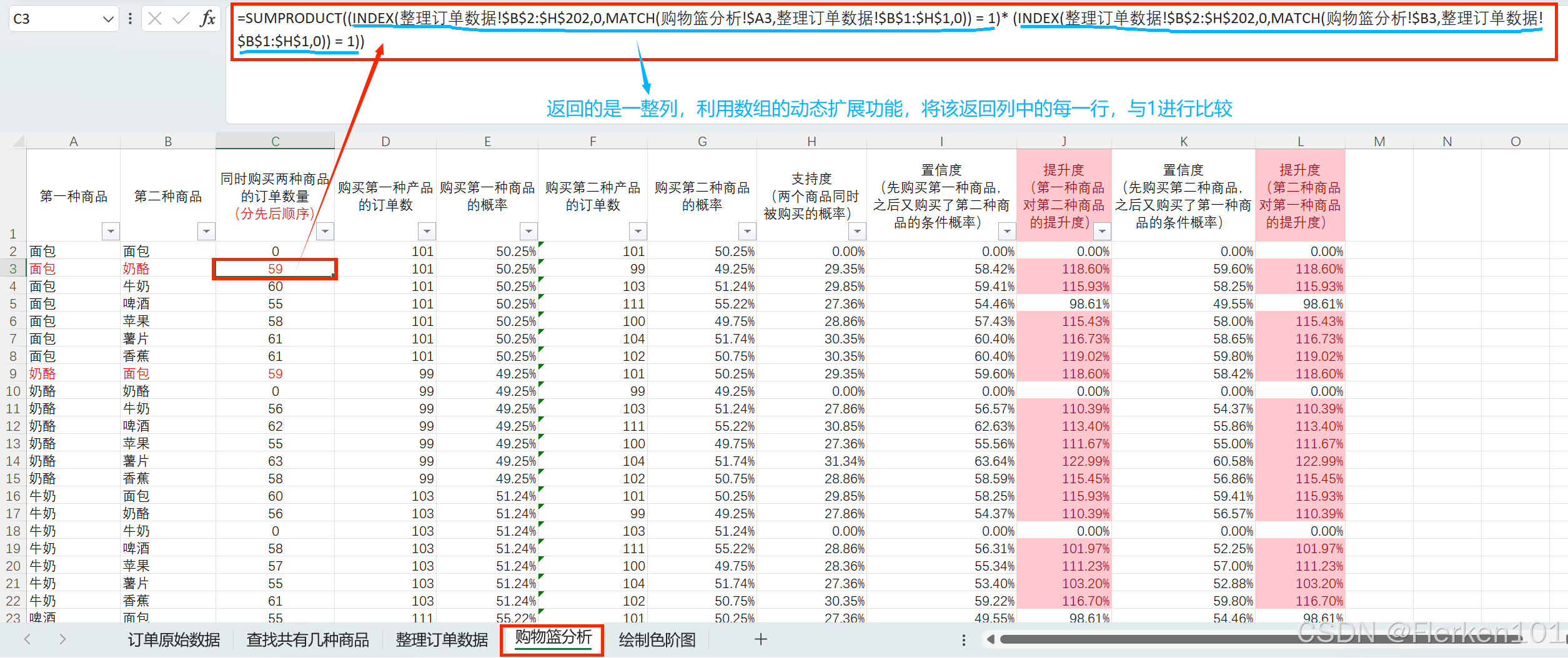
(1)返回同时满足多个条件的数量时,要使用SUMPRODUCT函数。
-- 返回B列中为1,同时C列中也为1的记录个数
=SUMPRODUCT((B2:B201=1)*(C2:C201=1))
实际操作中,要将两种商品相同时的订单数改为0.
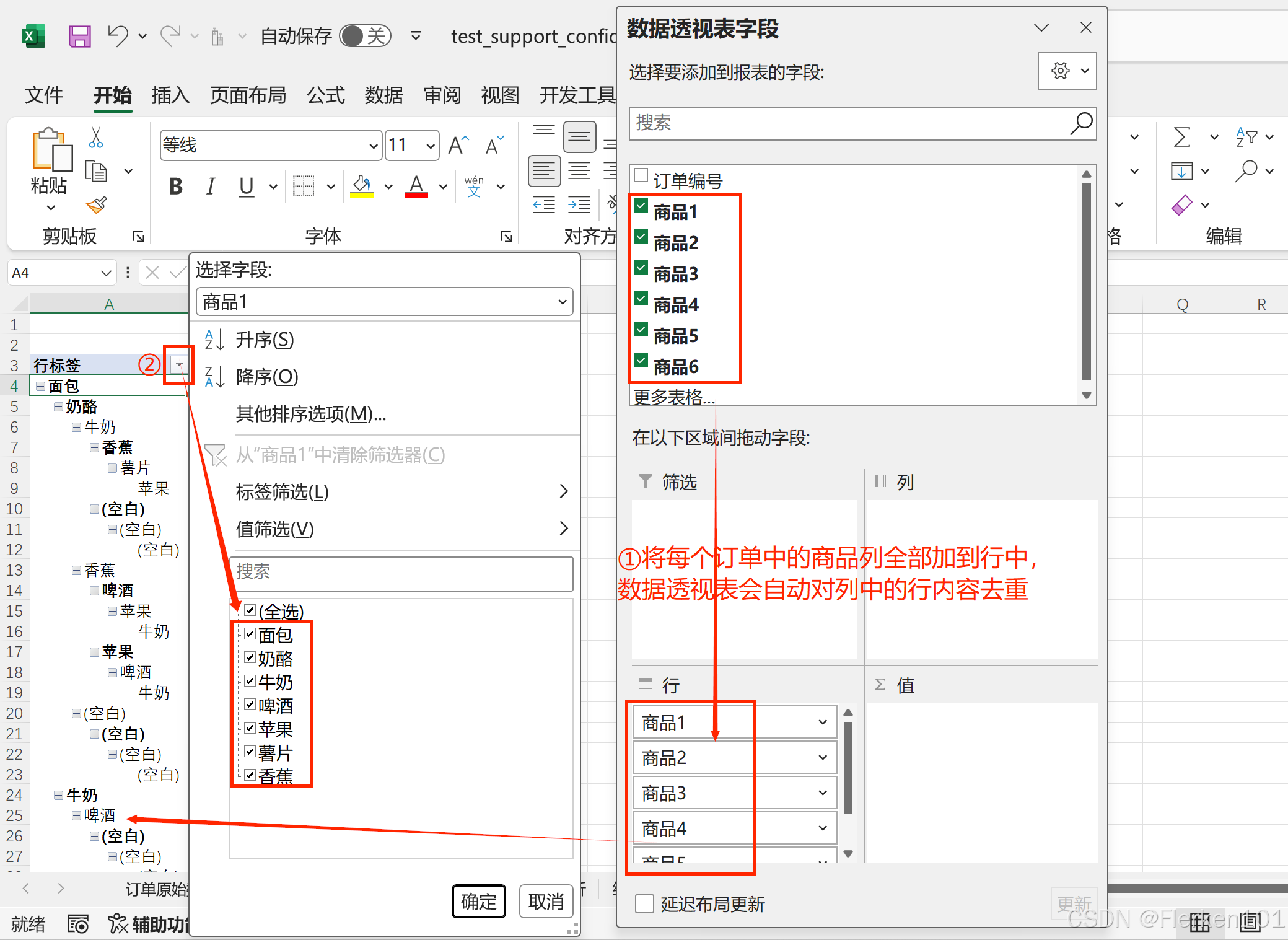
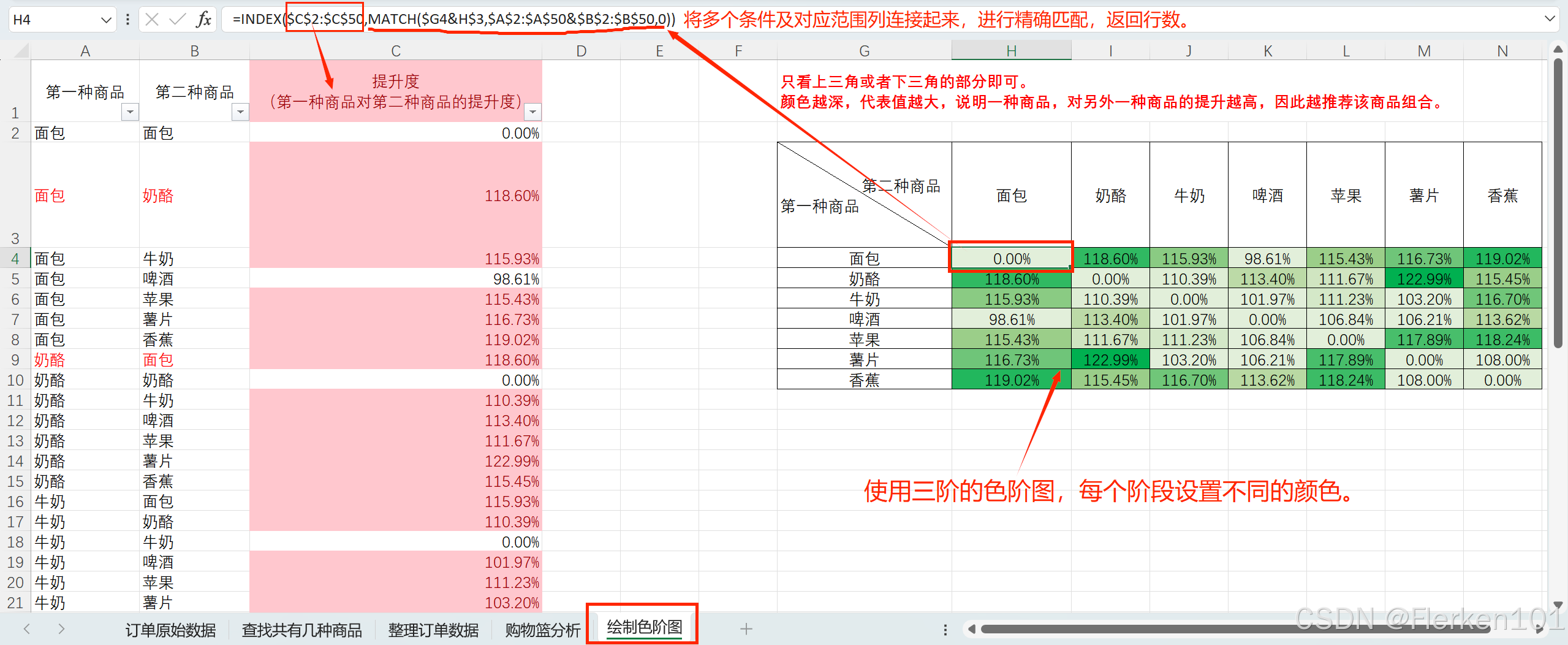
(2)要返回整列数据时,使用INDEX(范围,0,列数)。
其中行数设为0,代表了返回所有行。
(3)INDEX函数的行数 和 列数,都经常使用MATCH函数来返回数字。
(4)使用MATCH函数查找满足多个条件的记录所在行数/列数时,可以在查找值中将两个条件连接&起来,同时在查找范围中,将两个条件的对应列也连接&起来,再进行精确查找。
=MATCH("苹果"&"北京",A:A&B:B,0)
“苹果”&“北京” 是将两个条件连接起来,A:A&B:B 是将 A 列和 B 列的值对应连接起来,然后查找连接后与条件匹配的位置。0 表示精确匹配。
4.3 决定投入方向【优先级排序】
4.3.1 优先级分析法
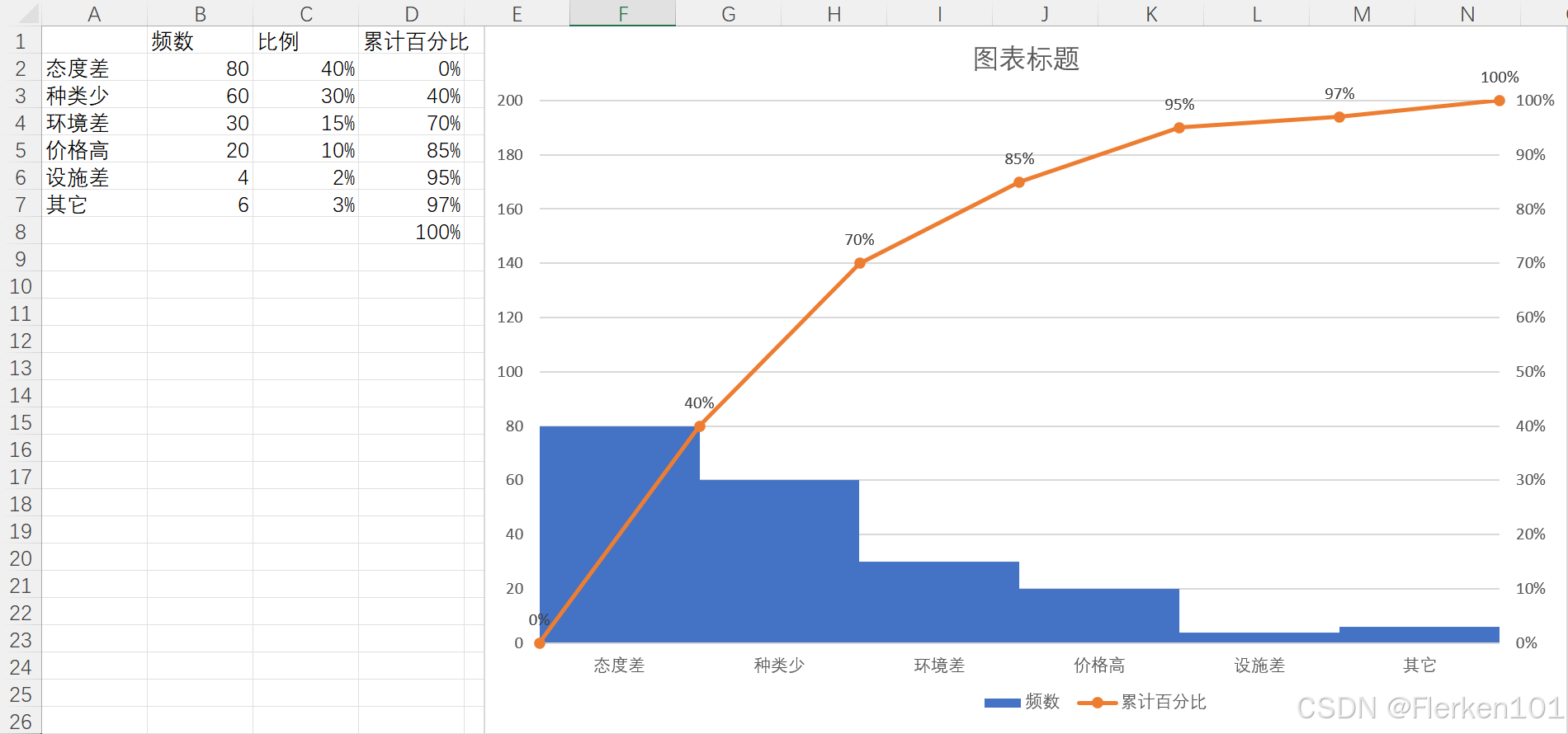
4.3.1.1 二八法则 / 帕累托分析法
二八法则:又称作帕累托法则,帕累托定律、二八定律、最省力法则和不平衡法则。
每一步都不能打乱顺序,或缺少。
标准的帕累托图:
4.3.1.2 ABC分类法 / 主次分析法
ABC分类法是由 二八法则 / 帕累托分析法 衍生出来的方法。
二八法则 / 帕累托分析法 与 ABC分类法 的不同之处:
①二八法则强调抓住关键,次要的事情可能直接放弃不做。像前面的3.6案例,利用生e经订单类数据中的地域报表,进行关键词推广(原直通车)的地域优化,最终只投放360多个城市中,贡献了80%订单的40%的城市,剩下60%的城市就全部放弃,不再投放了。
②ABC分类法强调的是分清主次,并将管理对象划分为A、B、C三类。
ABC分类法会关注所有的事情,并不是只关注占80%的那部分。但要将80%的那部分作为最重要的部分优先进行管理和投入,有区别地进行管理的方式。
ABC分类法的基本原理:运用数理统计的方法,对种类繁多的事物的同一属性,及该事物属性下每种种类所占的权重,按照不同的标准,进行排列和分类,将全部的种类划分为A、B、C种,分别给予重点、一般、次要等不同程度的相应管理。
ABC分析法的思想可以完成整体宏观分析要求(如客户分析),也可以满足单品的销售、毛利、库存(是否需要补货等)、淘汰等多种场景下的分析和操作需求。
比如在分析客户群体的时候,销售额累计达到80%的VIP客户们,绝对值得更多的关注,是销售们应该重点经营的目标。
而贡献了20%销售额的客户不是不关注,而是不需要过多的关注。
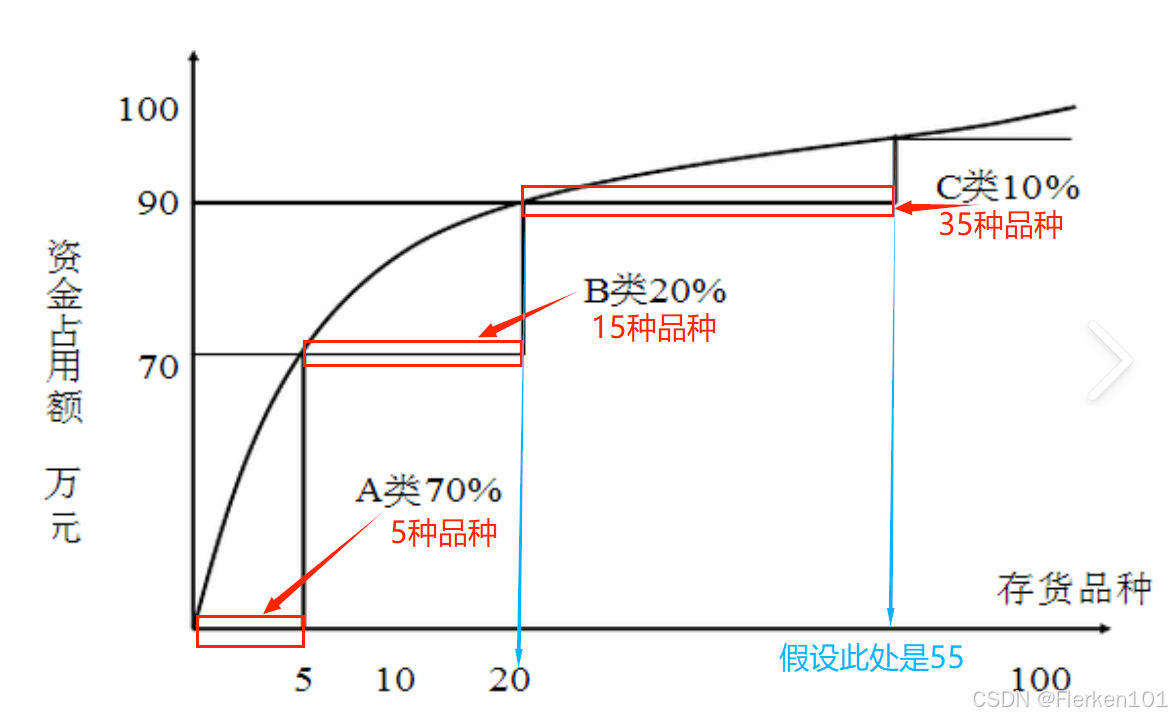
ABC分类法更经常用在库存管理中:
库存控制的ABC分类法,分什么?怎么分?具体怎么用?——卓弘毅
ABC分类法把库存商品分成分成A、B、C三类。
在库存管理中,ABC分类管理就是将库存物资按品种(SKU)和占用资金(比如销售额占比)的多少分为重要的A类,一般重要的B类和不重要的C类三个等级,针对不同等级,分别进行管理和控制的一种方法。
其具体分类方法为:
①重要的A类物资:所占品种SKU少一些,但品种占用的资金大;
②一般重要的B类物资:占用品种SKU比A类物资多一些,占用的资金比A类物资少一点;
③不重要的C类物资:所占品种SKU最多,但占用的资金最少。
ABC分类法的逻辑是把更多的精力放在A类物品上,实施更加严格的库存管控,而对于B和C类物品,可以用稍许宽松的方法进行管理。
换句话说,就是要把好钢用在刀刃上。
分析结论:
(1)抓大——需要重点关注库存价值最高的那部分A类物品,培养关键原材料供应商的长期合作关系,还需要逐步地削减库存天数,并有预见性地开发替代材料。
一方面保障了关键物料的稳定供应,同时把库存金额控制在合理的范围内。
开发替代材料是当供应链中断事件发生时(比如疫情导致的交通中断),可以迅速地找到原料替代方案,减少断供的损失。
(2)放小——C类物料并不值得花费很多时间精力去管理。
有些料每年的用量很少,例如不到100件的,可以进行一次性地采购或是生产。
虽然C类物料从库存周转率和库存天数等指标上会显得比较“难看”,但却节省下了采购成本,降低了生产效率损失,从更高层面分析的话,整体的成本或效率并没有什么损失。
(3)加强对A类物品的保管
由于A类物品价值高,需要加强仓库保管,比如分隔仓库,安装摄像头。在运输途中,使用专车或整柜集装箱,不与其他发货人的货物一起拼箱。
(4)加强需求预测
对于A类物品的需求预测管理要更加严格,滚动地分析预测与实际订单数量差异,针对超出正常范围的SKU,需要找到销售和市场部的同事一起再次核对数字。
(5)循环盘点
循环盘点是根据ABC分析法把库存品分类,根据价值的高低来制定盘点计划。
在一整个年度中,所有的库存品都会被盘点至少一次,价值越高被盘点的次数也越多。
仓库对于ABC三类物料制定出不同的盘点计划,比如A类物料每隔15天,B类物料每隔45天,C类物料每隔90天盘点一次。
通过循环盘点发现数量差异,仓库就能及时采取行动,纠正错误。
ABC分类法是基础的库存管理工具,通过“区分对待”,对不同的商品,或商品种类,采用不同的库存管理策略,集中资源,从而实现对于所有物品的高效管理。
4.3.2 矩阵分析法——合理分配资源和确定发展战略
4.3.2.1 四象限法 / 急迫性矩阵 / 重要性-迫切性模型

4.3.2.2 波士顿矩阵 / BCG Matrix
波士顿矩阵:
将市场占有率作为横坐标,将市场增长率作为纵坐标,以市场占有率和增长率的平均值为界,将坐标轴中的区域分成四个。
同时,把市场分成下面四种类型:
每种产品/业务,一定都会按照 “问题型市场——明星型市场——金牛型市场——瘦狗型市场” 的路径发展。
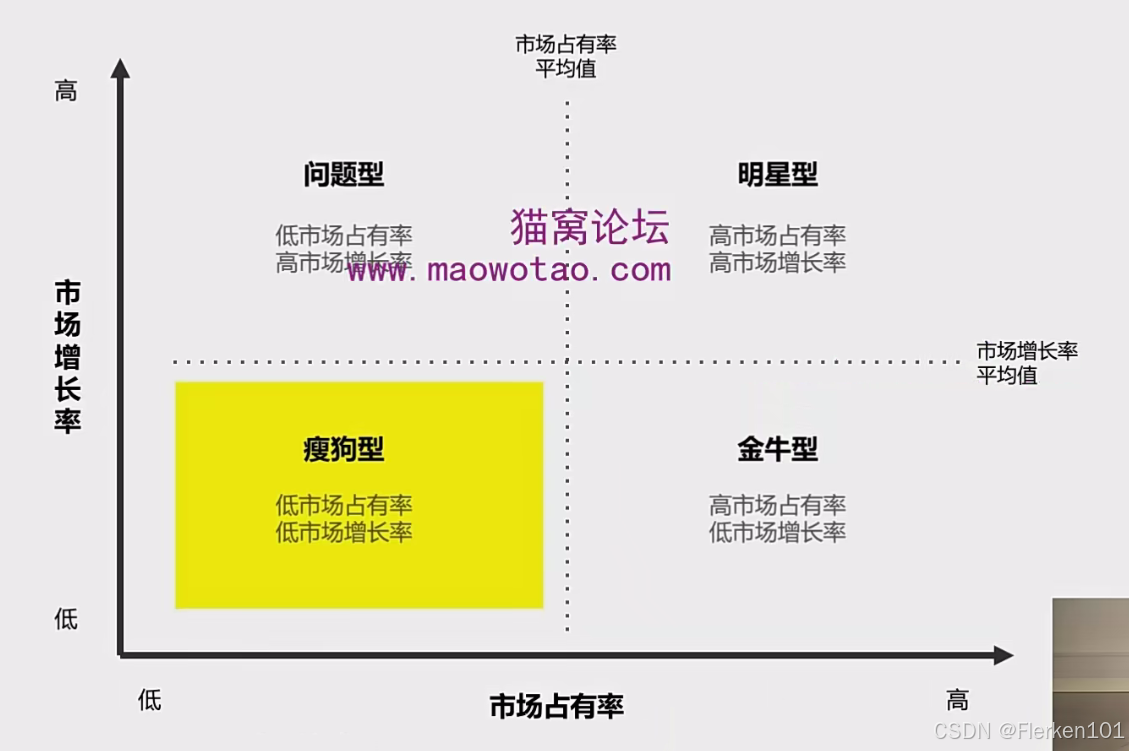
(1)问题型市场,低市场占有率,高市场增长率,左上。第三重要。
也叫“新业务”,这种市场往往是一些诞生期的市场,体量不大,但增长会非常快。
企业需要更加敏锐的关注度,一旦市场体量增大,就很有可能是下一个明星市场。
所以企业需要在 “问题型市场” / “新业务市场” 里面提前去做布局。
应该密切关注变化趋势,准备随时投入资源进行切入。
(2)明星型市场,高市场占有率,高市场增长率,右上。第一重要。
是企业必须要去占领的市场, 可以说是企业发展的战略要地。需要重点维护和关注,投入更多的资源。
(3)金牛型市场,高市场占有率,低市场增长率,右下,第二重要。
也叫“现金牛”,属于鼎盛期的市场,市场增长已经变缓慢了,但市场体量依然很大,
这种市场企业需要更多的去优化成本,关注 利润的获取 。
因为整体市场已经不怎么增长了,如果大家都要在这里面继续增长的话,市场的竞争就会加剧,竞争加剧就会导致利润降低,所以在这个市场里面经营,更多需要去关注利润。
不同的市场也不是一成不变的,随着市场的变化,四种类型的市场也会发生扭转。
比如明星型市场,一旦市场增长率放缓。就会进入金牛型市场,这个时候企业想要获得高增长率,就会变得困难。
很多明星型市场,假如增长率有40%,那么企业只要跟上大盘的趋势,也能保持至少40%的增长。
但如果到了金牛型市场,增长率可能只有个位数,这时企业如果还想保持两位数的增长率,肯定会变得比较困难。
所以,如果企业处在 “金牛型市场”,
一方面:企业需要寻找下一个明星型市场;
【寻找能转化为 “明星型市场” 的 “问题型市场” / “新业务市场”,可能来不及。
因为 “问题型市场” / “新业务市场” 的增长速度太慢,可能无法支撑企业存活,所以一定要寻找 “明星型市场” 。】
另一方面:对于金牛型市场,企业需要花更多的精力在利润的获取上,而不是盲目地去追求扩大规模。
一旦金牛型市场占有率下滑,那么很快就会变成瘦狗型市场。
(4)瘦狗型市场,低市场占有率,低市场增长率,左下,第四重要。
也叫“退出期市场”,市场面临转型,企业如果在这样的市场里面经营。
需要尽快对产品或战略方向做调整,尽快转型进入问题型市场或者金牛型市场。
这类商品基本上就可以考虑淘汰了,或者换其他商品做好转型的准备。
案例: 每种产品,一定都会按照 “问题型市场——明星型市场——金牛型市场——瘦狗型市场” 的路径发展。
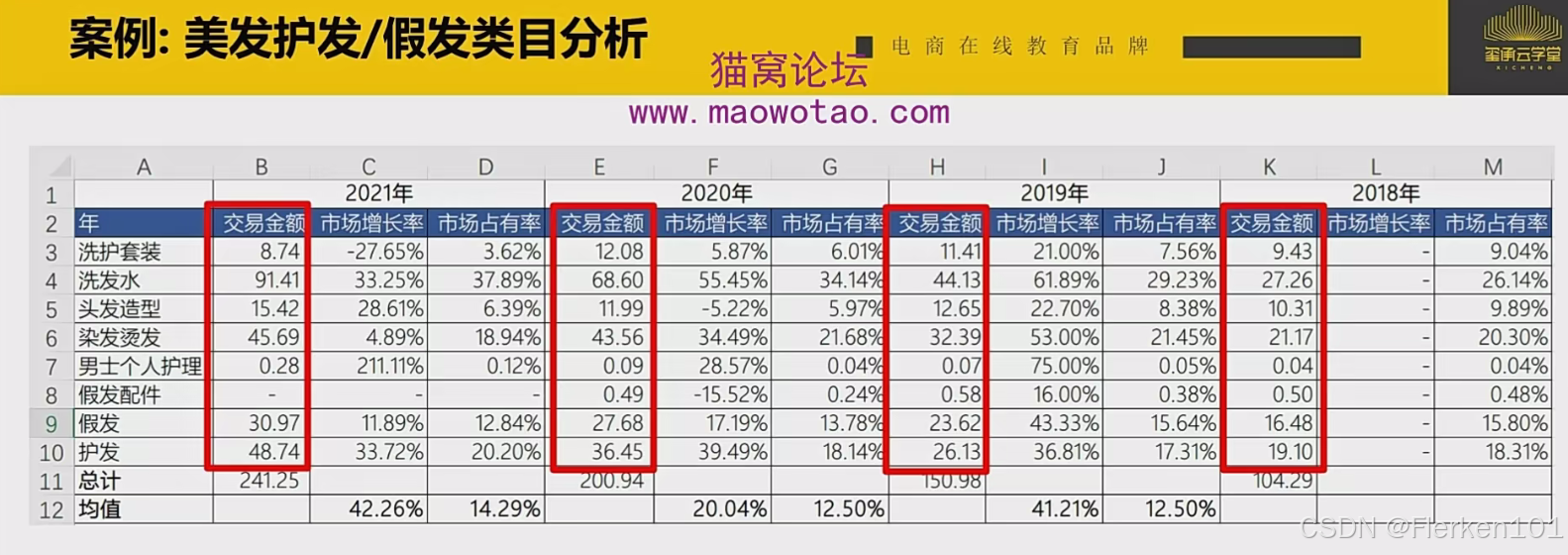
交易金额的单位:亿
2021年A产品的(年环比)市场增长率 = (2021年A产品的交易金额 - 2020年A产品的交易金额)/ 2020年A产品的交易金额
2021年A产品的市场占有率 = 2021年A产品的交易金额 / 2021年所有商品的交易金额总计
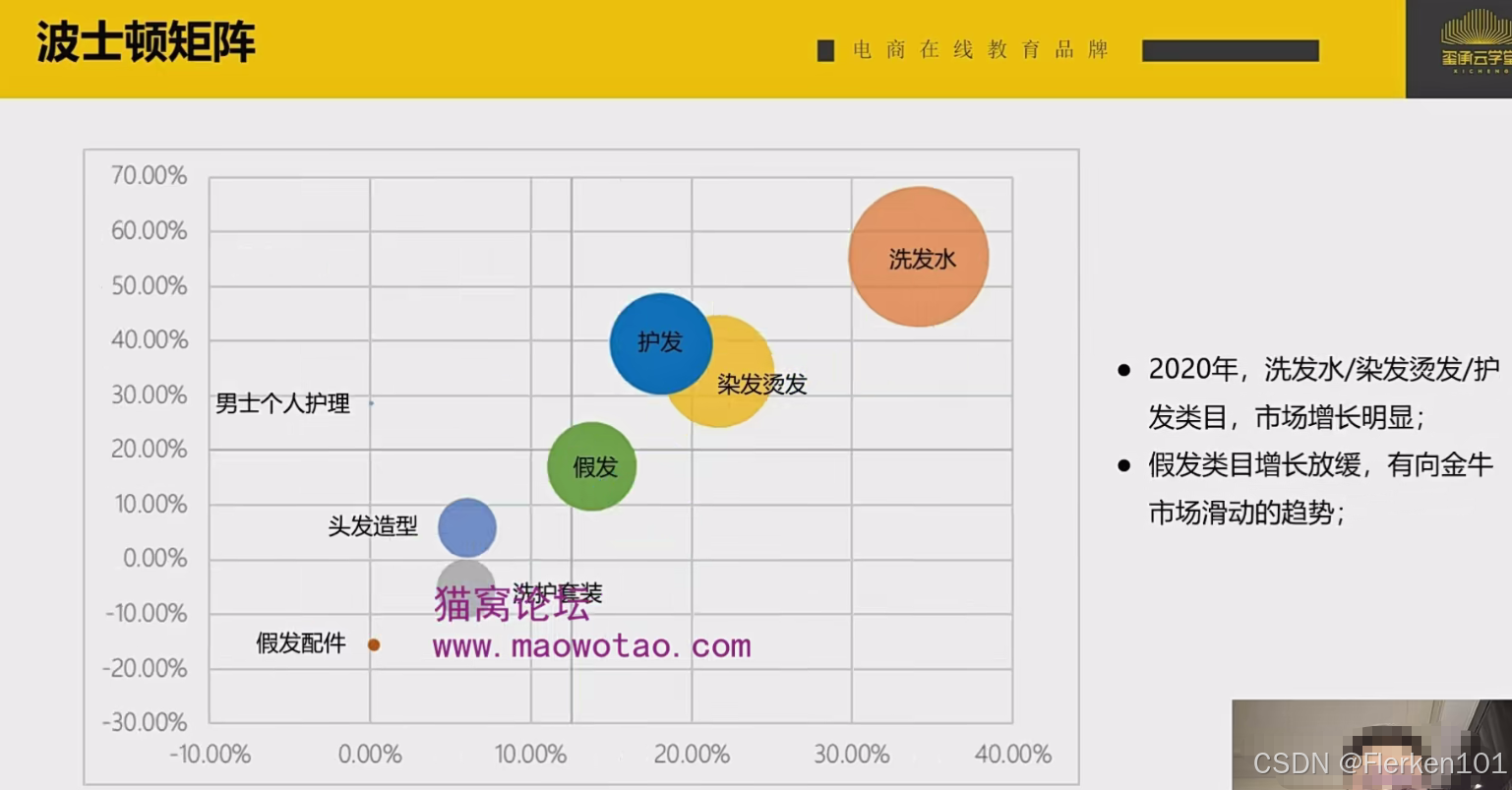
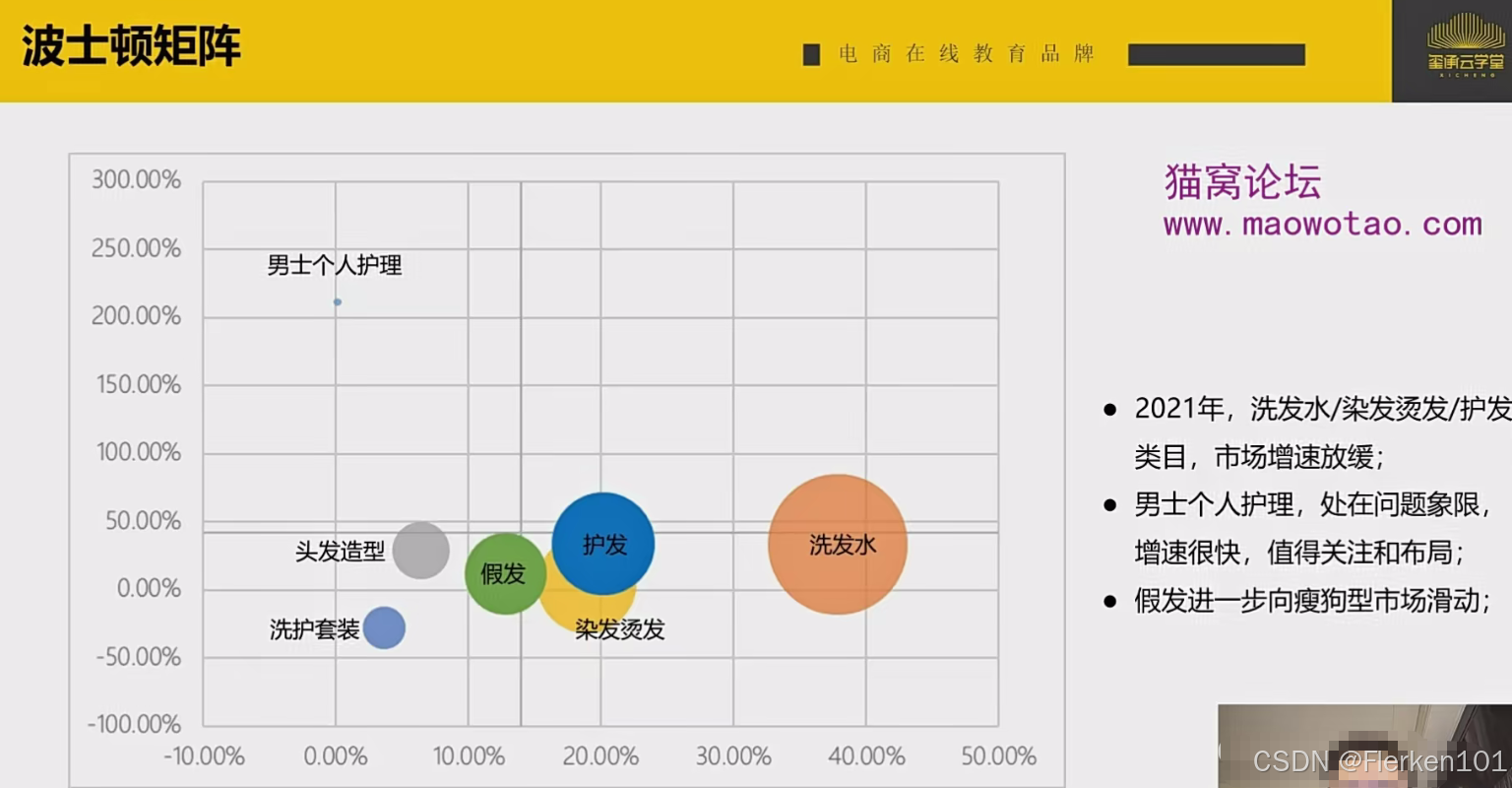
4.3.3 ROI分析
毛利润 = 总销售额 * 毛利率
也可以使用:毛利润 = 总销售额 – 直接成本 这个公式计算毛利润,但一般都采用毛利率计算毛利润。
这里的毛利润,可以是来自于活动的毛利润,也可以是来自于投放的毛利润。
营收ROI = 总销售额 / 成本 【这里的成本一般指直接成本。】
营收ROI = 毛利润 / (毛利率 * 成本)【这里的成本一般指直接成本。】
这里的直接成本,可以是来自于活动的直接成本,也可以是来自于投放的直接成本。
当 毛利润 = 成本 时,达到盈亏平衡。【这里的成本一般指直接成本。】
盈亏平衡时(毛利润 = 成本 时)的营收ROI = 1 / 毛利率
当 毛利润 > 成本 时,实现盈利。【这里的成本一般指直接成本。】
由:营收ROI = 毛利润 / (毛利率 * 成本)
得:毛利润 = 营收ROI * 毛利率 * 成本
当 毛利润 > 成本 时,营收ROI * 毛利率 * 成本 > 成本,营收ROI * 毛利率 > 1
即:营收ROI > 1 / 毛利率 时,才会盈利,并不是大于1就会盈利了。
不管是活动还是投放,都可以使用这个公式,判断活动 或者 投放,是否实现了盈利。
4.4 用户分群&精细化运营【精准施策】
在产品迭代的过程中,用户的需求也会发生不同的变化,不能针对所有用户采用“一刀切”的产品策略。
(如:同一类商品,比如服装,不同的用户有不同的需求、偏好等,要针对不同的用户推荐不同的商品,或者采取不同的营销策略。
————用户需求多样化,所以销售的商品种类也应该多样化。 )
用户分层的主要目的:满足不同用户的不同需求,为不同用户提供个性化服务,从而充分发挥每个层级用户的价值,达成产品目标、商品销售目标。
因此,用户分层底层逻辑为:基于底层业务目标,根据不同的指标划分,找到不同用户的各类需求。
在实际应用中,用户分层的功能主要表现在两方面:
①由于人群已经被细分,而且同一种人群的相似性较高。
所以不管是从发生问题(如销量低、转化率低等)的用户所属人群数量(较少)还是用户性质的一致上(较高), 都可以 快速定位导致问题的环节或步骤 ,找到后,可以根据问题进行优化;
②提升产品用户效益,针对不同的用户合理分配有限的资源,,最大化地满足不同用户的不同需求。
③充分发挥每个用户群的价值,达成产品转化率目标、商品销售额、利润等最大化目标。

用户分层的步骤:前期要尽可能多地收集信息。


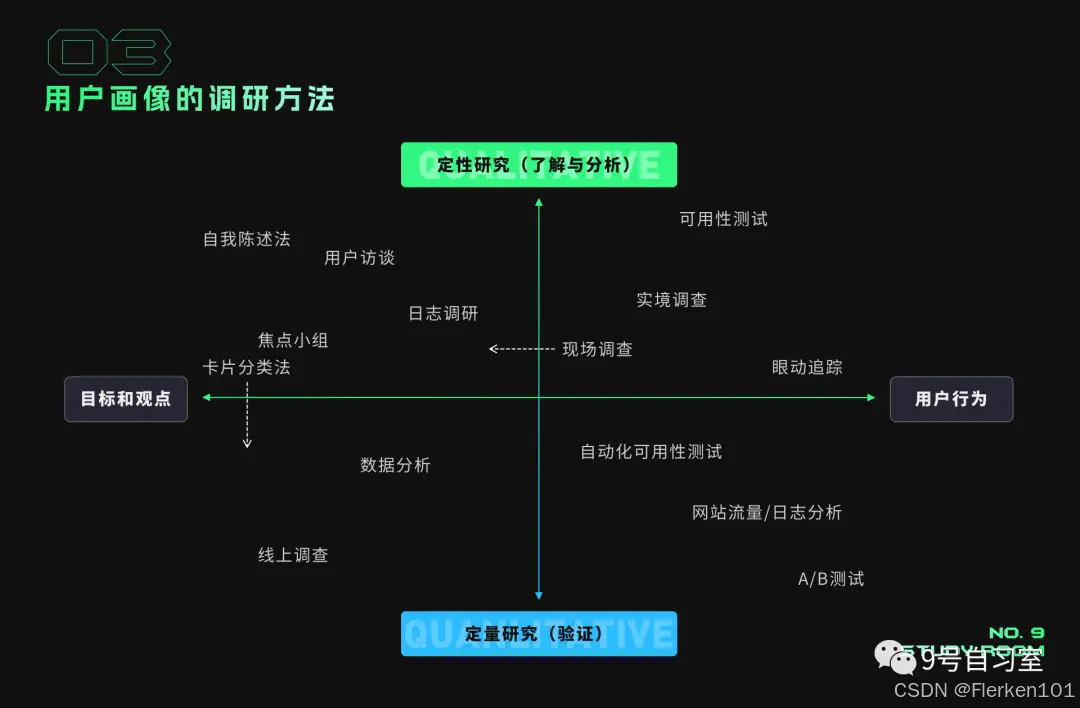
4.4.1 用户画像分析



4.4.2 RFM模型分析——实现八种客户分类
数据分析之RFM——用户模型分析(附案例数据和代码)——聪明的小k
4.4.2.1 理论基础
在下面的三维立方体中:
三个坐标轴均代表的是R、F、M的评分值大小(包括R值),所以R、F、M的评分值均是越大越好。
三个轴箭头的方向,均为指向数值大的。
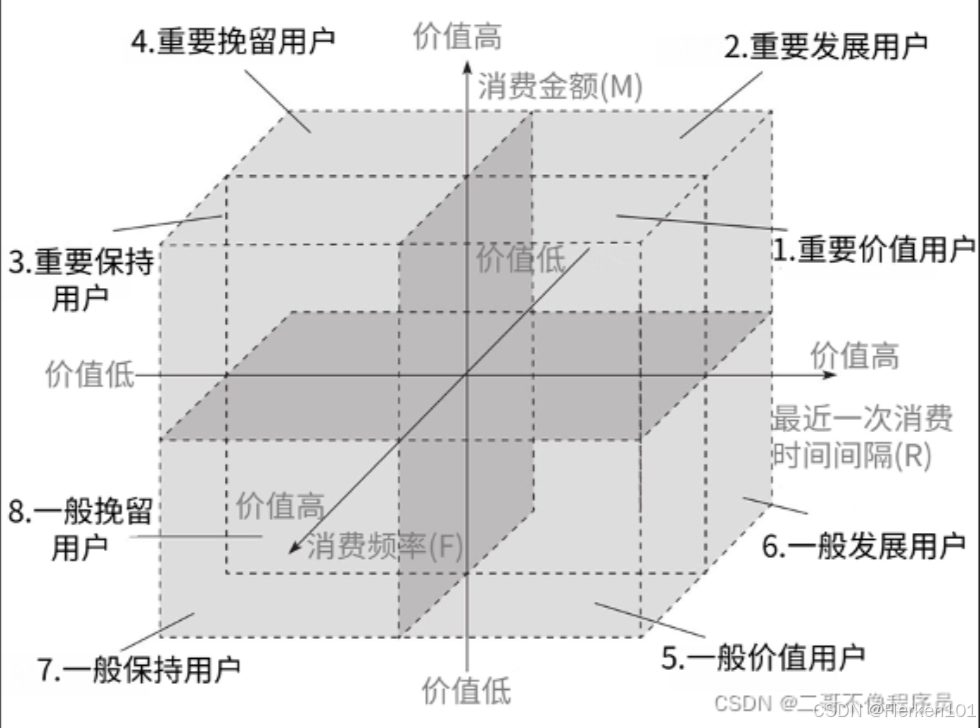

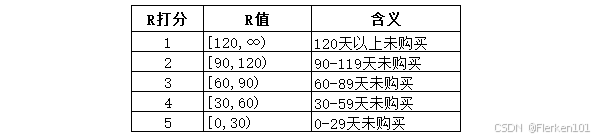
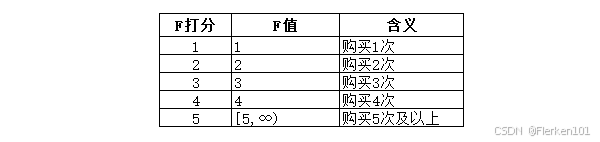
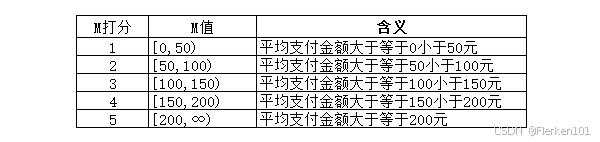
其中,三个分值 r_score、f_score、m_score 的评分方式假设为:
4.4.2.2 数据预览
(1)订单每一行代表着单个用户的单次购买行为。如果一个用户在一天内购买了4次,订单表对应记录着4行。
而在实际的业务场景中,一个用户在一天内的多次消费行为,应该从整体上看作一次。
比如,我今天10点在必胜客天猫店买了个披萨兑换券,11点又下单了饮料兑换券,18点看到优惠又买了两个冰淇淋兑换券。
这一天内虽然我下单了3次,但最终这些兑换券我会一次消费掉,应该只算做一次完整的消费行为,这个逻辑会指导后面F值的计算。
(2)在订单状态中,除了交易成功的,还有用户退款导致交易关闭的,但只有这两种状态。
其中退款订单对于模型价值不大,需要在后续清洗中剔除。
(3)订单一共28833行,没有任何缺失值。
(4)类型方面,付款日期是时间格式,实付金额、邮费和购买数量是数值型,其他均为字符串类型。
4.4.2.3 数据清洗
(1)剔除退款状态的订单记录
(2)RFM模型只需要买家昵称,付款时间和实付金额三个字段,其它的都可以删除。

(3)关键字段构造
构建模型所需的三个字段:
R(最近一次购买距今多少天),F(每个用户购买了多少次),M(每个用户每次的平均购买金额)。
首先是R值,即每个用户最后一次购买时间距今多少天。
如果用户只下单过一次,用“今天”的日期减去其付款日期即为R值;
若是用户多次下单,需先筛选出这个用户最后一次付款的时间,再用“今天”的日期减去它。
整个订单原始数据是2019年7月1日生成的,所以把“2019-7-1”当作“今天”,减去每个用户最后一次付款的时间,就得到每位用户的R值了。
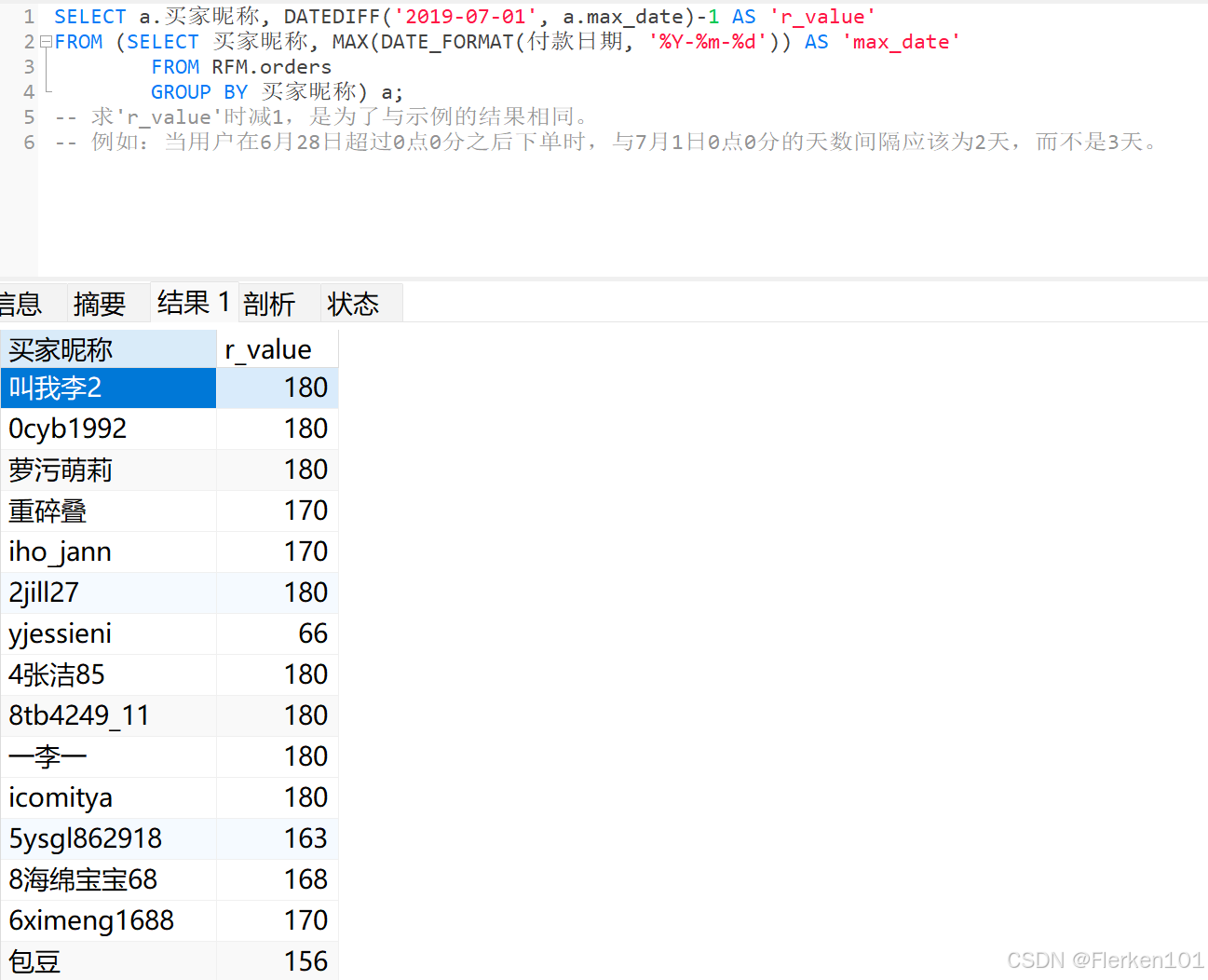
SELECT a.买家昵称, DATEDIFF('2019-07-01', a.max_date)-1 AS 'r_value'
FROM (SELECT 买家昵称, MAX(DATE_FORMAT(付款日期, '%Y-%m-%d')) AS 'max_date'
FROM RFM.orders
GROUP BY 买家昵称) a;
-- 求'r_value'时减1,是为了与示例的结果相同。
-- 例如:当用户在6月28日超过0点0分之后下单时,与7月1日0点0分的天数间隔应该为2天,而不是3天。
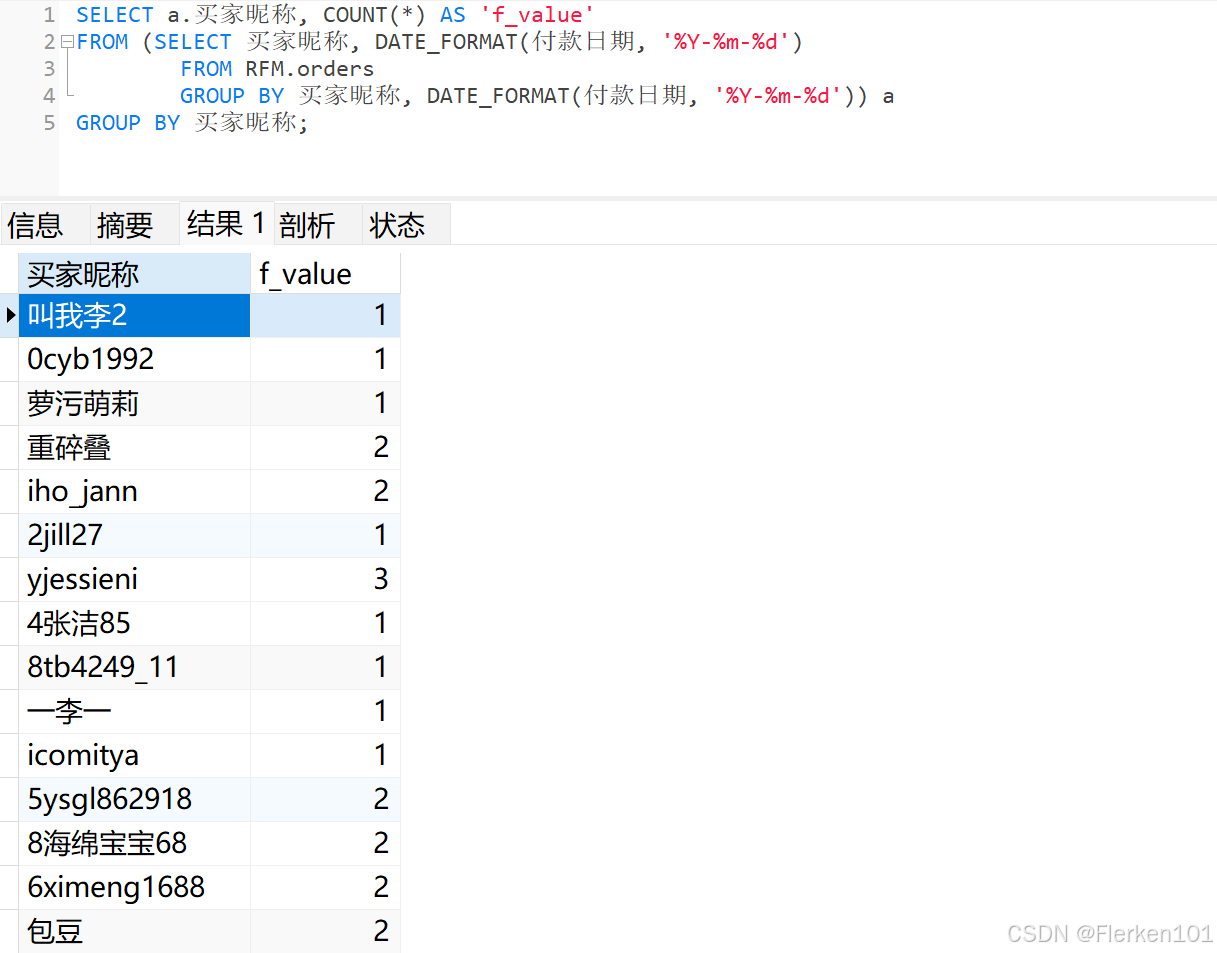
接着是F值,即每个用户累计购买频次。
在前面数据概览阶段,明确了“把单个用户一天内多次下单行为看作整体一次”的思路,所以引入一个精确到天的日期标签,依照“买家昵称”和“日期标签”进行分组,把每个用户一天内的多次下单行为合并,再统计每个用户的购买次数。
SELECT a.买家昵称, COUNT(*) AS 'f_value'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')
FROM RFM.orders
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称;
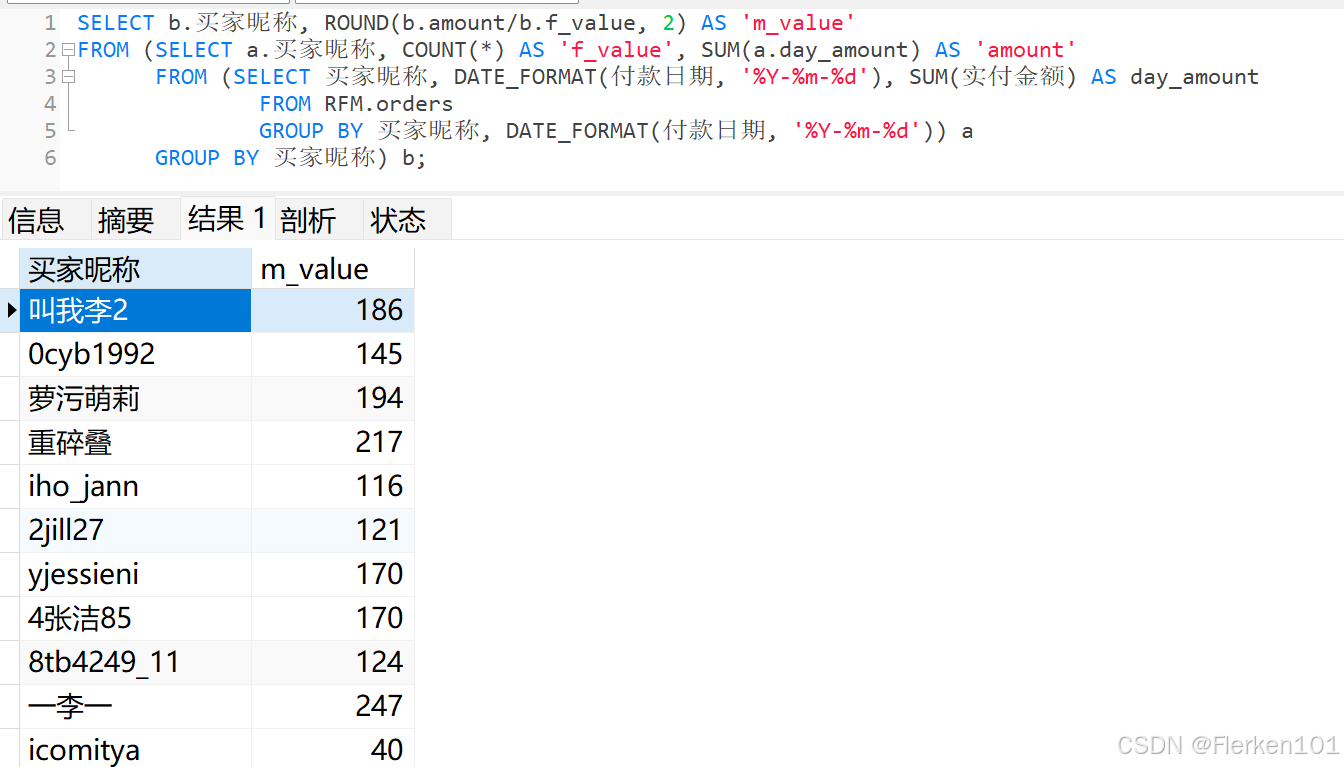
最后是M值,即每个用户每次的平均购买金额。
上一步计算出了每个用户的购买频次F值,这里只需要得到每个用户购买的总金额,再用总金额除以购买频次F值,就能得到每个用户每次的平均购买金额M值。
SELECT b.买家昵称, ROUND(b.amount/b.f_value, 2) AS 'm_value'
FROM (SELECT a.买家昵称, COUNT(*) AS 'f_value', SUM(a.day_amount) AS 'amount'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d'), SUM(实付金额) AS day_amount
FROM RFM.orders
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称) b;
最后,将三个指标根据用户昵称合并:
SELECT c.买家昵称, c.r_value, d.f_value, e.m_value
FROM (SELECT a.买家昵称, DATEDIFF('2019-07-01', a.max_date)-1 AS 'r_value'
FROM (SELECT 买家昵称, MAX(DATE_FORMAT(付款日期, '%Y-%m-%d')) AS 'max_date'
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称) a) c
LEFT OUTER JOIN (SELECT a.买家昵称, COUNT(*) AS 'f_value'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称) d
ON c.买家昵称 = d.买家昵称
LEFT OUTER JOIN (SELECT b.买家昵称, ROUND(b.amount/b.f_value, 2) AS 'm_value'
FROM (SELECT a.买家昵称, COUNT(*) AS 'f_value', SUM(a.day_amount) AS 'amount'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d'), SUM(实付金额) AS day_amount
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称) b) e
ON c.买家昵称 = e.买家昵称
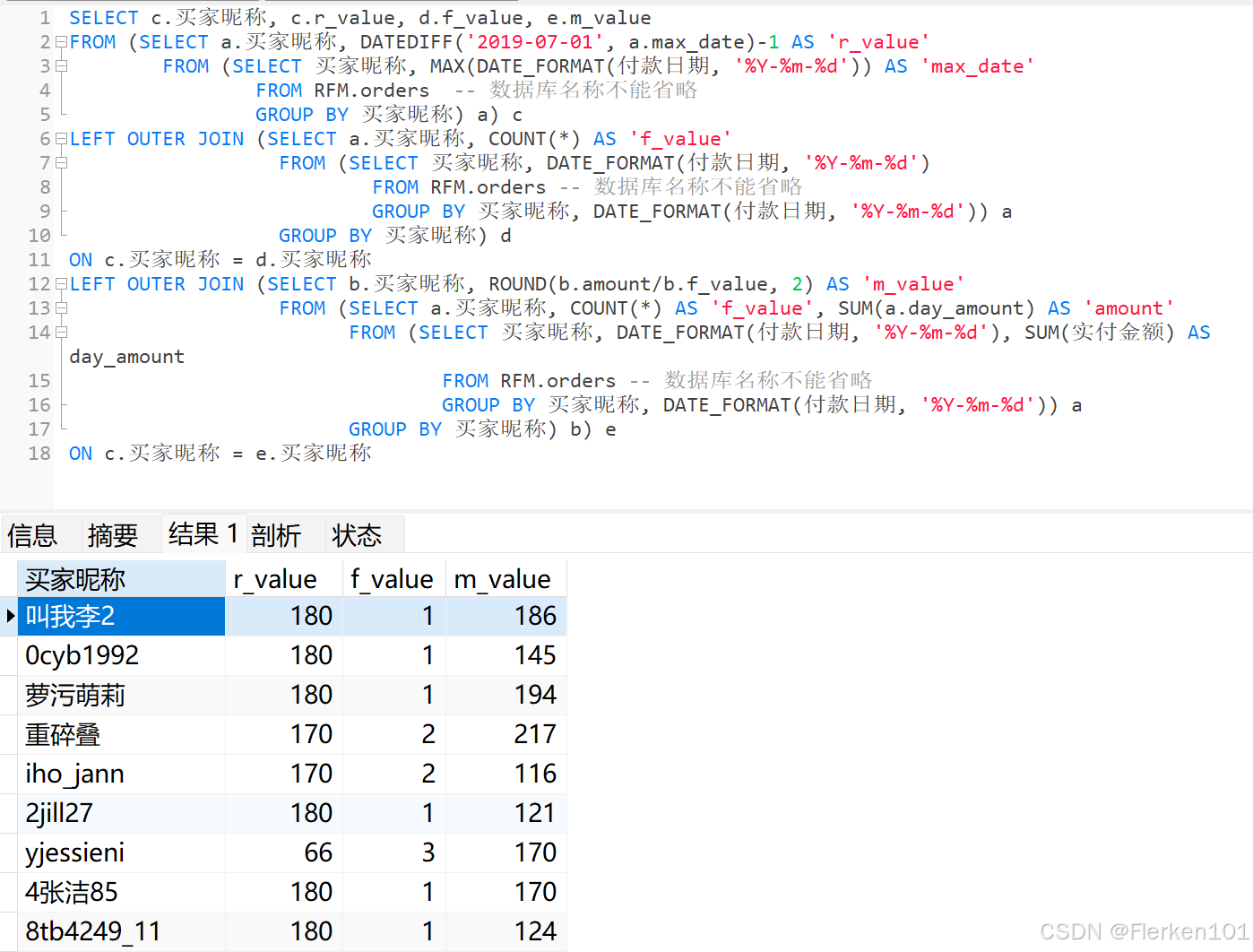
-- 将上述结果保存成视图 rfm_value
CREATE VIEW rfm_value(买家昵称, r_value, f_value, m_value)
AS
SELECT c.买家昵称, c.r_value, d.f_value, e.m_value
FROM (SELECT a.买家昵称, DATEDIFF('2019-07-01', a.max_date)-1 AS 'r_value'
FROM (SELECT 买家昵称, MAX(DATE_FORMAT(付款日期, '%Y-%m-%d')) AS 'max_date'
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称) a) c
LEFT OUTER JOIN (SELECT a.买家昵称, COUNT(*) AS 'f_value'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称) d
ON c.买家昵称 = d.买家昵称
LEFT OUTER JOIN (SELECT b.买家昵称, ROUND(b.amount/b.f_value, 2) AS 'm_value'
FROM (SELECT a.买家昵称, COUNT(*) AS 'f_value', SUM(a.day_amount) AS 'amount'
FROM (SELECT 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d'), SUM(实付金额) AS day_amount
FROM RFM.orders -- 数据库名称不能省略
GROUP BY 买家昵称, DATE_FORMAT(付款日期, '%Y-%m-%d')) a
GROUP BY 买家昵称) b) e
ON c.买家昵称 = e.买家昵称;
4.4.2.4 维度打分
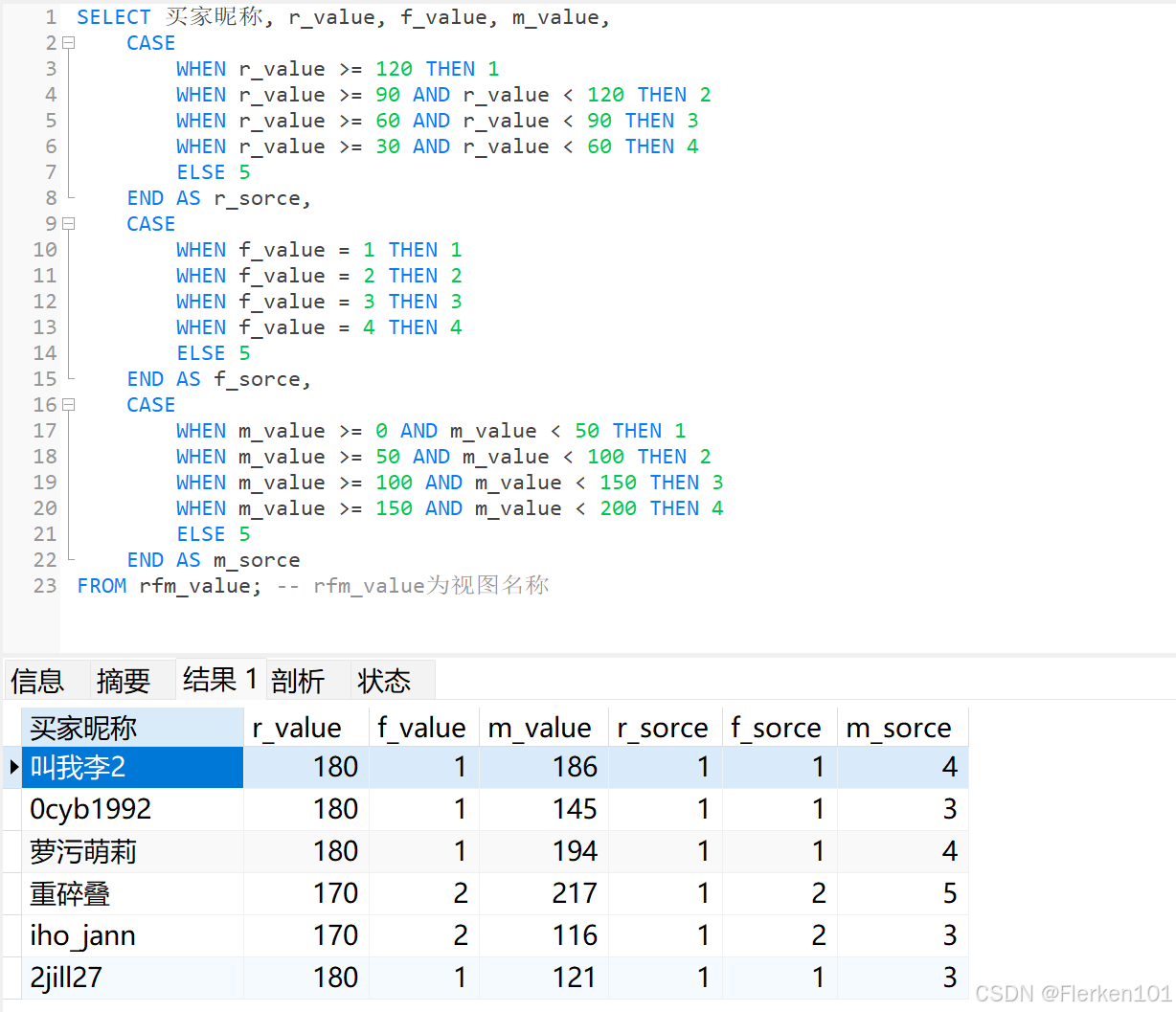
维度确认的核心是分值确定,按照设定的标准,给每个消费者的R/F/M值打分。
分值的大小取决于我们的偏好,即我们越喜欢的行为,打的分数就越高。
R值 r_value 代表了用户有多少天没来下单,这个值越大,用户流失的可能性越大,我们当然不希望用户流失,所以R值 r_value 越大,R的分值 r_score 越小。
F值 f_value 代表了用户购买频次,M值 m_value 则是用户平均支付金额,这两个指标是越大越好,即数值 f_value、m_value越大,得分 f_score、m_score 越高。
RFM模型中打分一般采取5分制,有两种比较常见的方式:
一种是按照数据的分位数来打分;
另一种是依据数据和业务的理解,进行分值的划分。而且这种方式更好。
R值根据行业经验,设置为30天一个跨度,区间左闭右开:
F值和购买频次挂钩,每多一次购买,分值就多加一分:
可以先对M值做个简单的区间统计,然后分组,这里我们按照50元的一个区间来进行划分:
4.4.2.5 分值计算
SELECT 买家昵称, r_value, f_value, m_value,
CASE
WHEN r_value >= 120 THEN 1
WHEN r_value >= 90 AND r_value < 120 THEN 2
WHEN r_value >= 60 AND r_value < 90 THEN 3
WHEN r_value >= 30 AND r_value < 60 THEN 4
ELSE 5
END AS r_sorce,
CASE
WHEN f_value = 1 THEN 1
WHEN f_value = 2 THEN 2
WHEN f_value = 3 THEN 3
WHEN f_value = 4 THEN 4
ELSE 5
END AS f_sorce,
CASE
WHEN m_value >= 0 AND m_value < 50 THEN 1
WHEN m_value >= 50 AND m_value < 100 THEN 2
WHEN m_value >= 100 AND m_value < 150 THEN 3
WHEN m_value >= 150 AND m_value < 200 THEN 4
ELSE 5
END AS m_sorce
FROM rfm_value; -- rfm_value为视图名称
WITH a AS (SELECT 买家昵称, r_value, f_value, m_value,
CASE
WHEN r_value >= 120 THEN 1
WHEN r_value >= 90 AND r_value < 120 THEN 2
WHEN r_value >= 60 AND r_value < 90 THEN 3
WHEN r_value >= 30 AND r_value < 60 THEN 4
ELSE 5
END AS r_sorce,
CASE
WHEN f_value = 1 THEN 1
WHEN f_value = 2 THEN 2
WHEN f_value = 3 THEN 3
WHEN f_value = 4 THEN 4
ELSE 5
END AS f_sorce,
CASE
WHEN m_value >= 0 AND m_value < 50 THEN 1
WHEN m_value >= 50 AND m_value < 100 THEN 2
WHEN m_value >= 100 AND m_value < 150 THEN 3
WHEN m_value >= 150 AND m_value < 200 THEN 4
ELSE 5
END AS m_sorce
FROM rfm_value) -- rfm_value为视图名称
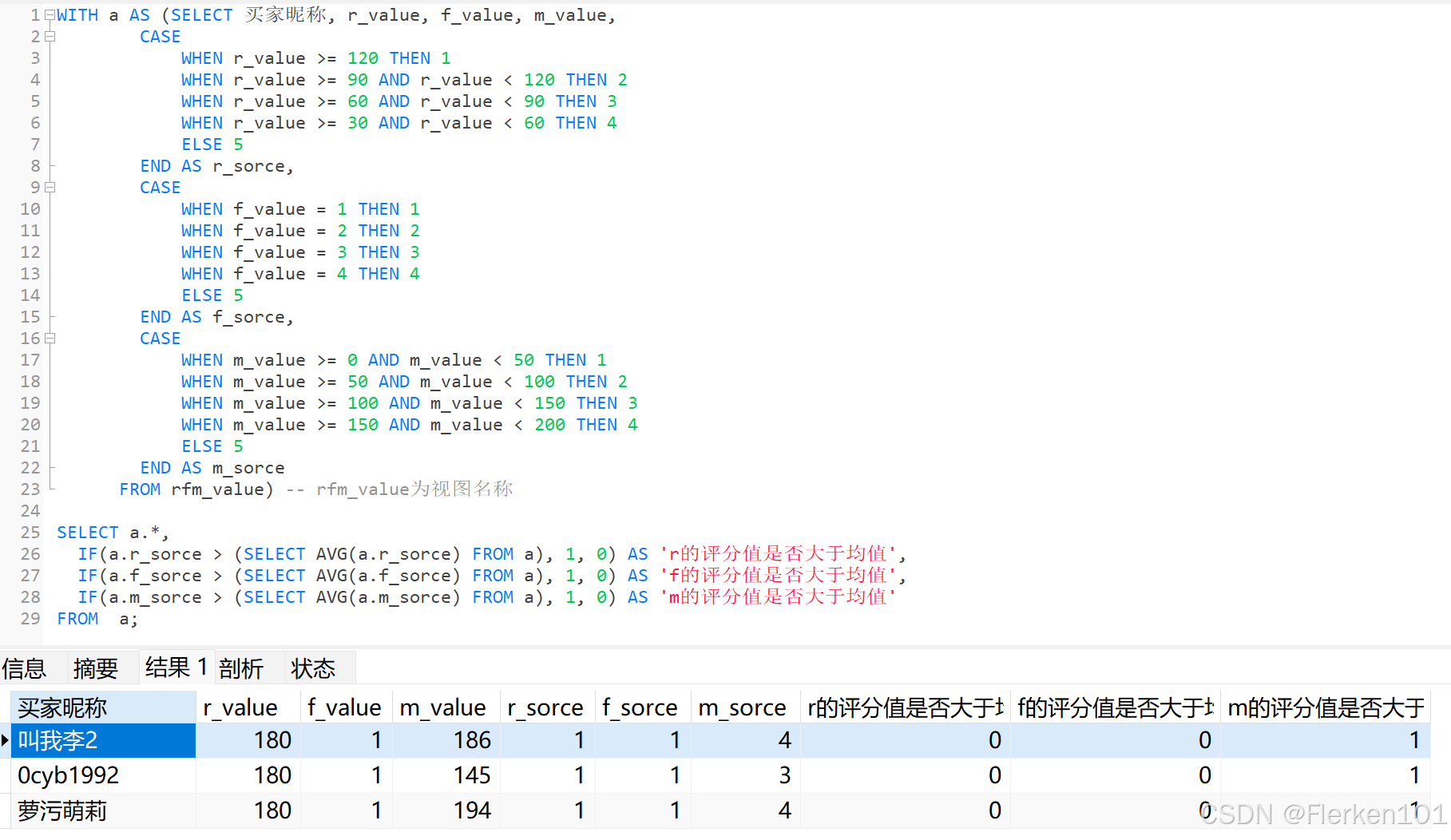
SELECT a.*,
IF(a.r_sorce > (SELECT AVG(a.r_sorce) FROM a), 1, 0) AS 'r的评分值是否大于均值',
IF(a.f_sorce > (SELECT AVG(a.f_sorce) FROM a), 1, 0) AS 'f的评分值是否大于均值',
IF(a.m_sorce > (SELECT AVG(a.m_sorce) FROM a), 1, 0) AS 'm的评分值是否大于均值'
FROM a;
4.4.2.6 客户分层

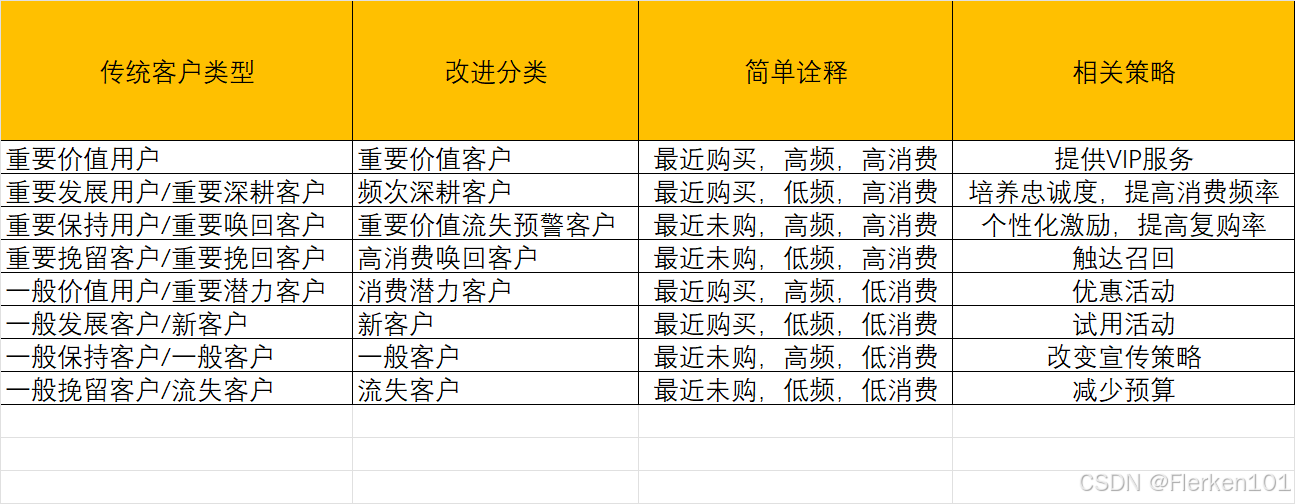
由于传统的分类,部分名称有些拧巴,像大多数分类前都冠以“重要”,“潜力”和“深耕”到底有什么区别?“唤回”和“挽回”有什么不一样?
本着清晰至上原则,对原来的名称做了适当的改进。强调了:
潜力是针对消费(平均支付金额M)
【m 的分值小于均值,但 r和f 的分值均大于均值,就称其为 消费潜力客户。】;
深耕是为了提升消费频次(客户在限定的期间内所购买的次数F)
【f 的分值小于均值,但 r和m 的分值均大于均值,就称其为 频次深耕客户。】
重要唤回客户其实和重要价值客户非常相似,只是最近没有回购了而已,应该做流失预警等等。
-- 求各类客户的人数
WITH a AS (SELECT 买家昵称, r_value, f_value, m_value,
CASE
WHEN r_value >= 120 THEN 1
WHEN r_value >= 90 AND r_value < 120 THEN 2
WHEN r_value >= 60 AND r_value < 90 THEN 3
WHEN r_value >= 30 AND r_value < 60 THEN 4
ELSE 5
END AS r_sorce,
CASE
WHEN f_value = 1 THEN 1
WHEN f_value = 2 THEN 2
WHEN f_value = 3 THEN 3
WHEN f_value = 4 THEN 4
ELSE 5
END AS f_sorce,
CASE
WHEN m_value >= 0 AND m_value < 50 THEN 1
WHEN m_value >= 50 AND m_value < 100 THEN 2
WHEN m_value >= 100 AND m_value < 150 THEN 3
WHEN m_value >= 150 AND m_value < 200 THEN 4
ELSE 5
END AS m_sorce
FROM rfm_value),
b AS (SELECT a.买家昵称,
IF(a.r_sorce > (SELECT AVG(a.r_sorce) FROM a), 1, 0) AS 'r的评分值是否大于均值',
IF(a.f_sorce > (SELECT AVG(a.f_sorce) FROM a), 1, 0) AS 'f的评分值是否大于均值',
IF(a.m_sorce > (SELECT AVG(a.m_sorce) FROM a), 1, 0) AS 'm的评分值是否大于均值'
FROM a),
c AS (SELECT b.*,
CASE
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 1 THEN '重要价值客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 0 THEN '消费潜力客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 1 THEN '频次深耕客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 0 THEN '新客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 1 THEN '重要价值流失预警客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 0 THEN '一般客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 1 THEN '高消费唤回客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 0 THEN '流失客户'
END AS 'class'
FROM b)
SELECT class, COUNT(*) AS num
FROM c
GROUP BY class;
WITH a AS (SELECT 买家昵称, r_value, f_value, m_value,
CASE
WHEN r_value >= 120 THEN 1
WHEN r_value >= 90 AND r_value < 120 THEN 2
WHEN r_value >= 60 AND r_value < 90 THEN 3
WHEN r_value >= 30 AND r_value < 60 THEN 4
ELSE 5
END AS r_sorce,
CASE
WHEN f_value = 1 THEN 1
WHEN f_value = 2 THEN 2
WHEN f_value = 3 THEN 3
WHEN f_value = 4 THEN 4
ELSE 5
END AS f_sorce,
CASE
WHEN m_value >= 0 AND m_value < 50 THEN 1
WHEN m_value >= 50 AND m_value < 100 THEN 2
WHEN m_value >= 100 AND m_value < 150 THEN 3
WHEN m_value >= 150 AND m_value < 200 THEN 4
ELSE 5
END AS m_sorce
FROM rfm_value),
b AS (SELECT a.买家昵称,
IF(a.r_sorce > (SELECT AVG(a.r_sorce) FROM a), 1, 0) AS 'r的评分值是否大于均值',
IF(a.f_sorce > (SELECT AVG(a.f_sorce) FROM a), 1, 0) AS 'f的评分值是否大于均值',
IF(a.m_sorce > (SELECT AVG(a.m_sorce) FROM a), 1, 0) AS 'm的评分值是否大于均值'
FROM a),
c AS (SELECT b.*,
CASE
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 1 THEN '重要价值客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 0 THEN '消费潜力客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 1 THEN '频次深耕客户'
WHEN r的评分值是否大于均值 = 1 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 0 THEN '新客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 1 THEN '重要价值流失预警客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 1 AND m的评分值是否大于均值 = 0 THEN '一般客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 1 THEN '高消费唤回客户'
WHEN r的评分值是否大于均值 = 0 AND f的评分值是否大于均值 = 0 AND m的评分值是否大于均值 = 0 THEN '流失客户'
END AS 'class'
FROM b)
SELECT e.人群分类, e.人数,
CONCAT(ROUND(100*e.人数 / (SELECT COUNT(*) FROM rfm_value), 2), '%') AS '人数占比',
e.距离最近一次交易平均间隔天数,
e.平均购买次数,
e.总消费金额,
CONCAT(ROUND(100*e.总消费金额 / (SELECT SUM(实付金额) FROM RFM.orders), 2), '%') AS '总消费金额占比',
ROUND(100*e.总消费金额 / e.人数, 2) AS '每人平均总消费金额',
e.每人每次的平均消费金额
FROM (SELECT c.class AS '人群分类',
COUNT(*) AS '人数',
ROUND(AVG(d.r_value), 0) AS '距离最近一次交易平均间隔天数',
ROUND(AVG(d.f_value), 0) AS '平均购买次数',
ROUND(SUM(d.f_value * d.m_value), 2) AS '总消费金额',
ROUND(AVG(d.m_value), 2) AS '每人每次的平均消费金额'
FROM rfm_value d
LEFT OUTER JOIN c
ON d.买家昵称 = c.买家昵称
GROUP BY c.class) e
ORDER BY e.人数 DESC;
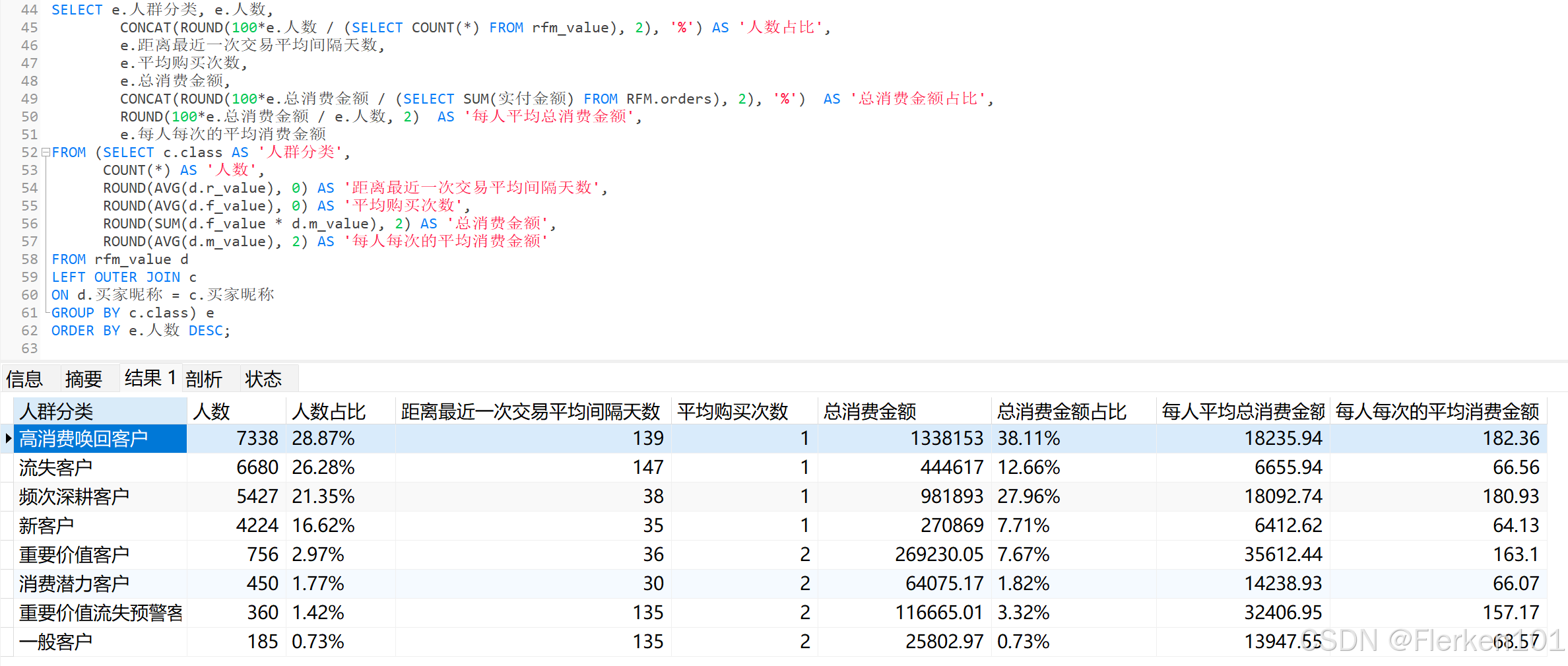
4.4.2.7 可视化及业务分析
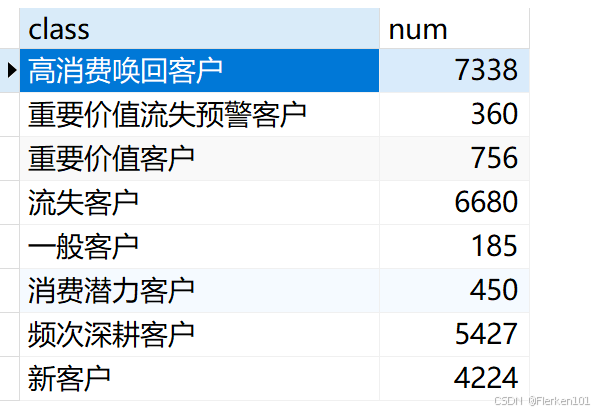
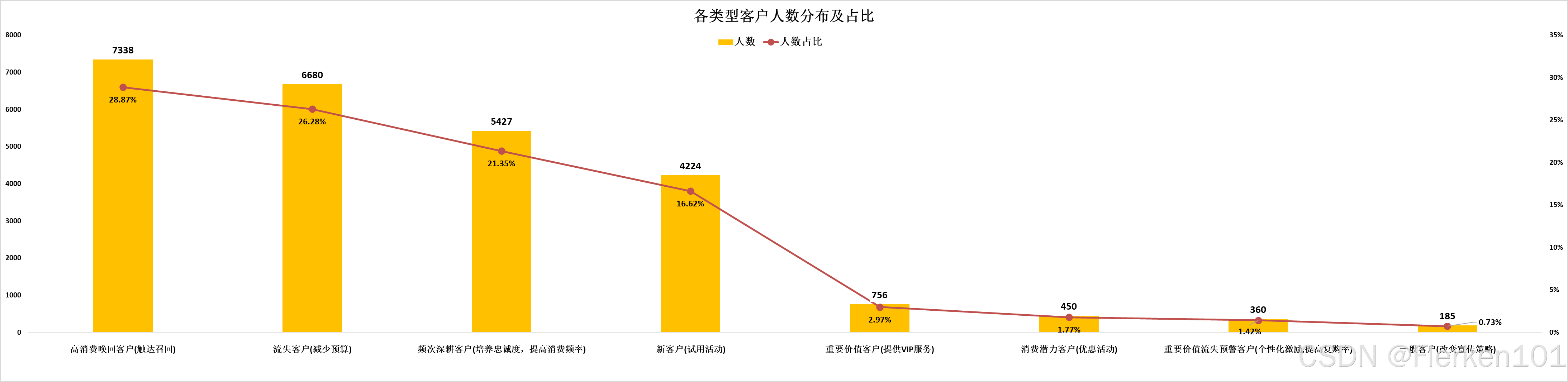
- 从各类型客户人数分布及占比结果,可以得到一些推断:
(1)客户流失情况严峻,高消费唤回客户、流失客户占比超过50%,怎么样制定针对性唤回策略迫在眉睫。
(2)重要价值客户占比仅2.97%,还有三个客户占比甚至不足2%.
模型打分可能不够科学,可以进一步调整打分区间进行优化。
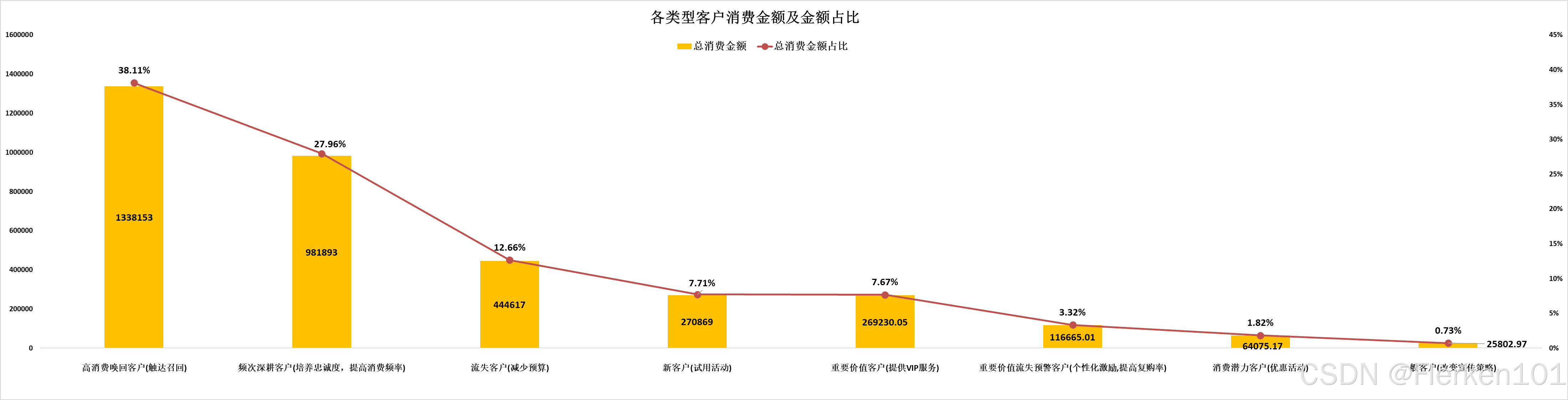
- 再结合金额进行分析:
(1)高消费唤回客户人数占比28.87%,金额占比上升到了38.11%,这部分客户是消费的中流砥柱,他们为什么流失,应结合订单和购买行为数据进一步展开挖掘。
(2)频次深耕客户金额占比紧随其后,这部分客户的特征是近期有消费、消费频次低、消费金额高,和高消费唤回客户仅有购买时间上的不同。
如何避免这部分客户向高消费唤回客户的流转是我们要思考的主要命题。
(3)流失客户人数占比26.28%,金额占比仅12.66%,这部分客户中有一部分是褥羊毛用户,有一部分是目标用户。
可以按如下方式调整引流策略:
①精准发放优惠券:不再广泛撒网式发放优惠券,而是根据用户的购买历史、行为数据等,对真正有潜力成为长期客户的目标用户进行精准推送,提高优惠券的使用效率,减少薅羊毛用户的获取。
②设置条件优惠:推出满减、套餐等形式的优惠,鼓励用户提高购买金额,吸引对价格相对敏感但有一定消费能力的目标用户,同时一定程度上限制薅羊毛用户只获取优惠而不增加消费金额的行为。
4.4.3 同理心地图(Empathy Map)
【设计思维】真正理解什么是同理心地图?(Empathy Map)——我有Yi个想法

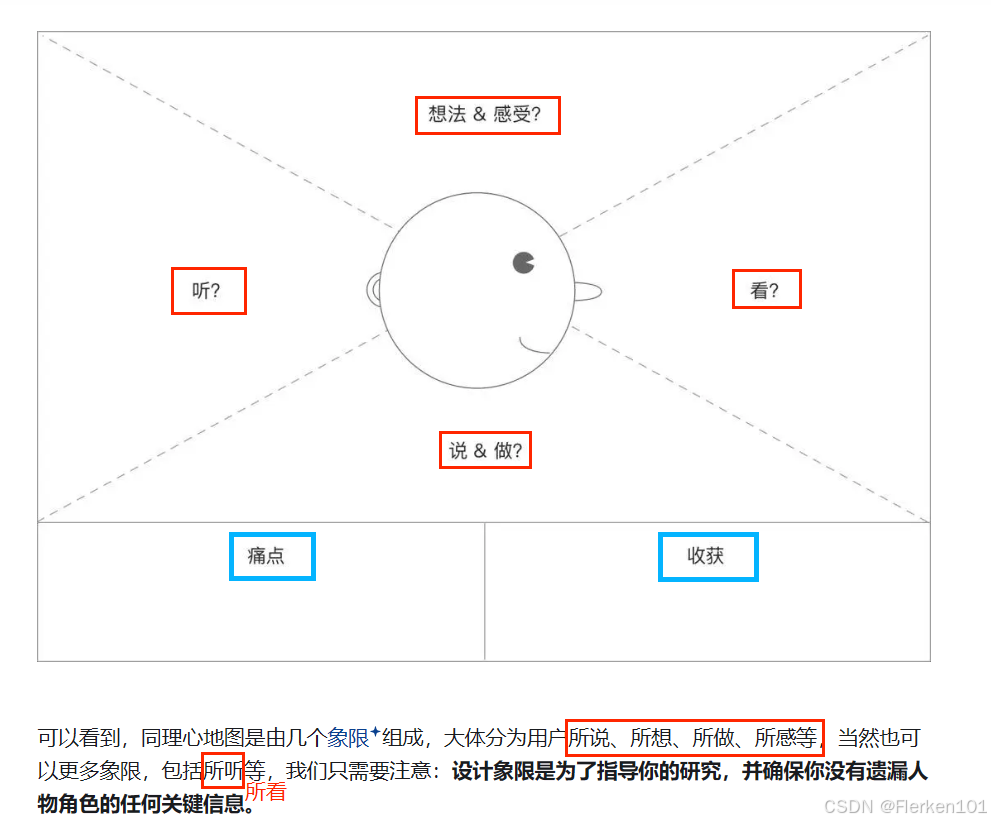


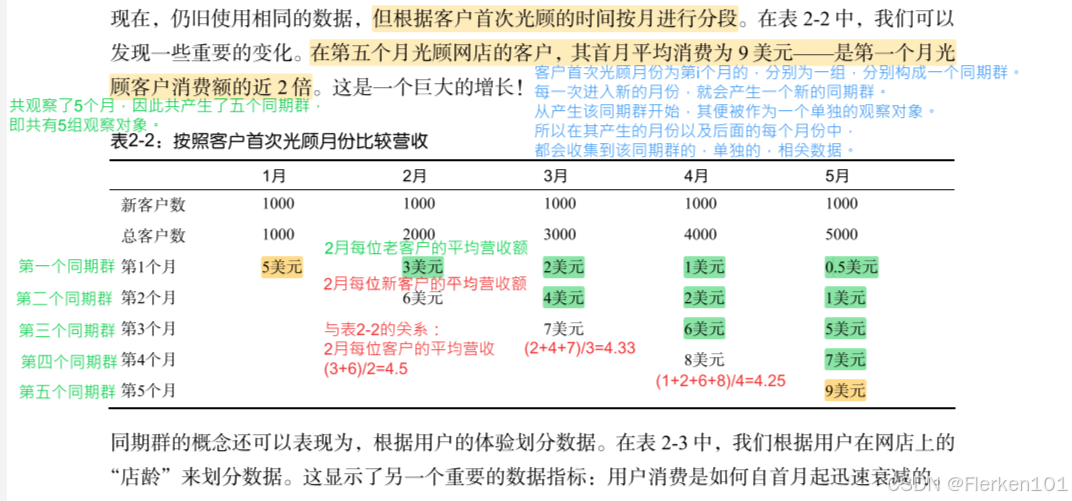
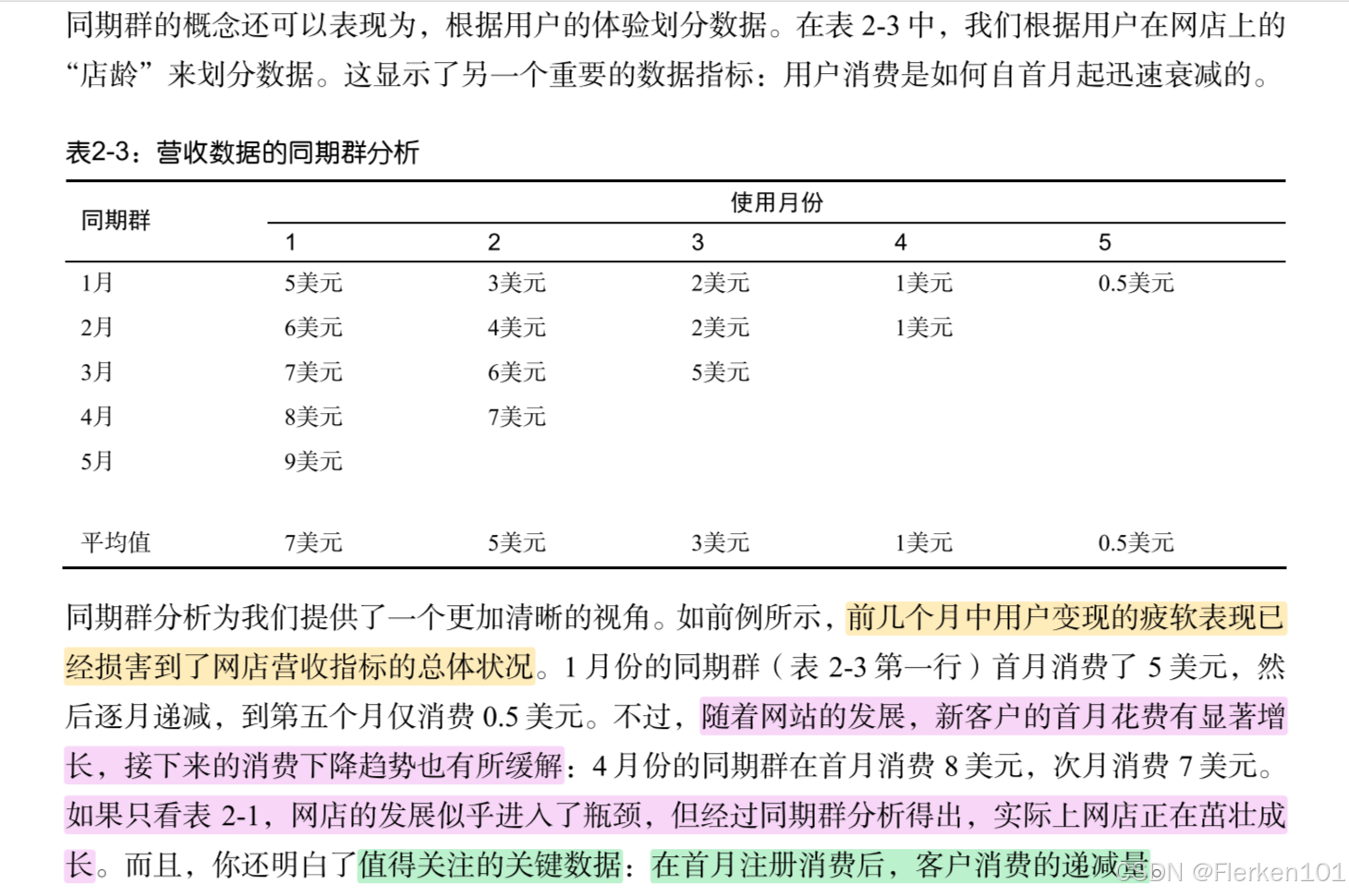
4.4.4 同期群分析
同期群分析使你能够观察处于生命周期不同阶段客户的行为模式,而非忽略个体的自然生命周期,对所有客户一刀切。
同期群分析适用于营收、客户流失率、口碑的病毒式传播、客户支持成本等任何你关注的数据指标。


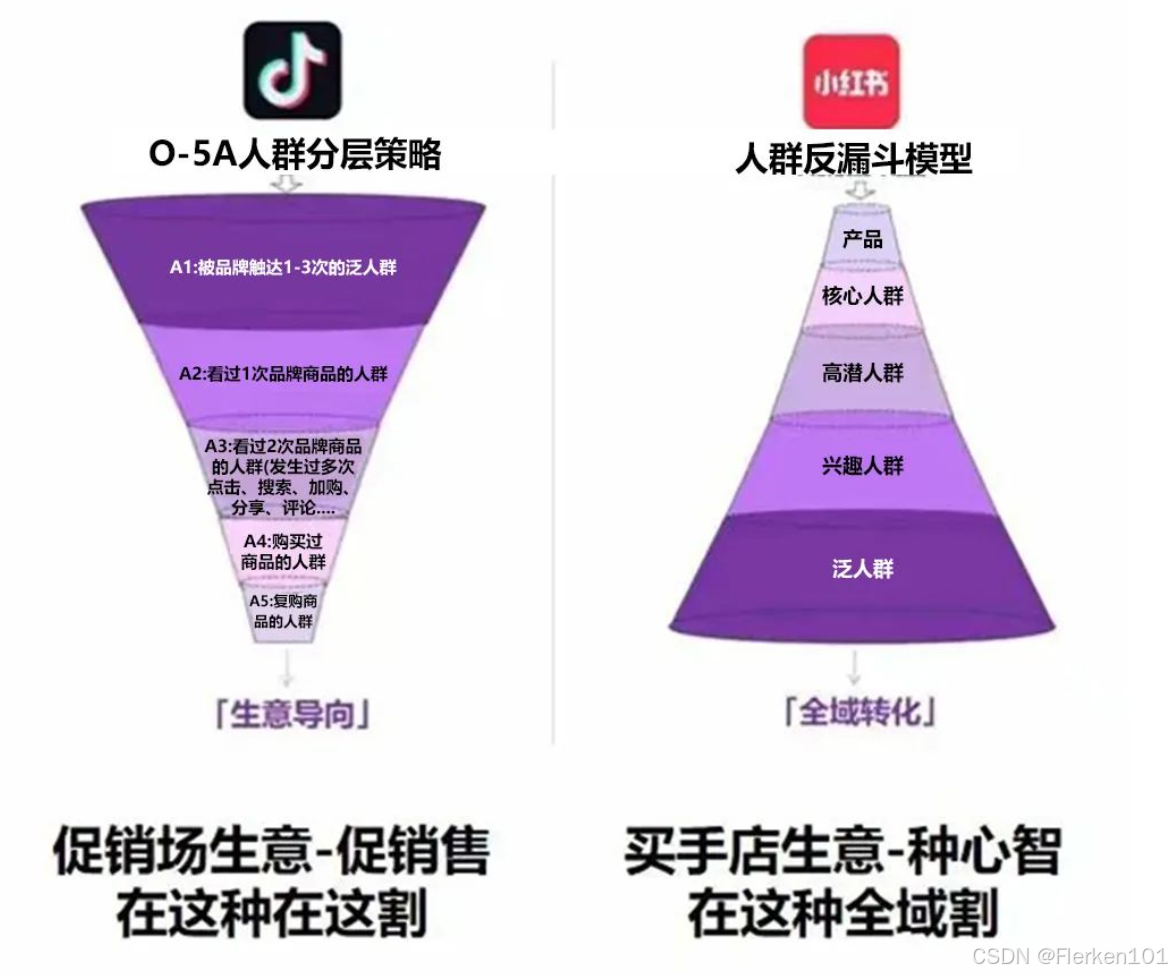
4.4.5 正漏斗人群分层策略 和 反漏斗人群破圈策略



4.5 测算模型
4.5.1 库存周转分析
1、库存周转率=销货成本/平均存货余额
把公式指标拆开来看,
①销货成本=单件销货成本*销售件数
②平均存货余额=(期初存货金额+期末存货金额)/2
其中,期初存货金额:上期账户结转至本期账户的余额,在数额上等于上期期末存货金额
期末存货金额=期初存货金额+本期增加发生额-本期减少发生额
如某制造公司在2003年一季度的销售物料成本为200万元,其季度初的库存价值为30万元,该季度底的库存价值为50万元,那么其库存周转率为 200 / [ (30+50) / 2 ] = 5次.
相当于该企业用平均40万的现金在一个季度里面周转了5次,赚了5次利润。
【一般情况下,如果每季度的库存平均值相对稳定,没有明显的季节性波动或其他特殊情况,每季度的库存平均值可以近似地被当作每年的库存平均值。】
照次计算,如果每季度平均销售物料成本不变(200万元),每季度底的库存平均值也不变,那么该企业的年库存周转率就变为 200 * 4 / 40=20次。
就相当与该企业一年用40万的现金赚了20次利润!
2、库存周转天数=360/库存周转率=(360*平均存货余额)/销货成本
库存周转天数是企业从取得存货开始,至消耗、销售为止所经历的天数。
通俗来说,就是库存周转率越高,周转天数就越小,说明存货变现速度越快,销售状况越良好。
4.5.2 杜邦分析法——目标拆解
4.5.2.1 原理

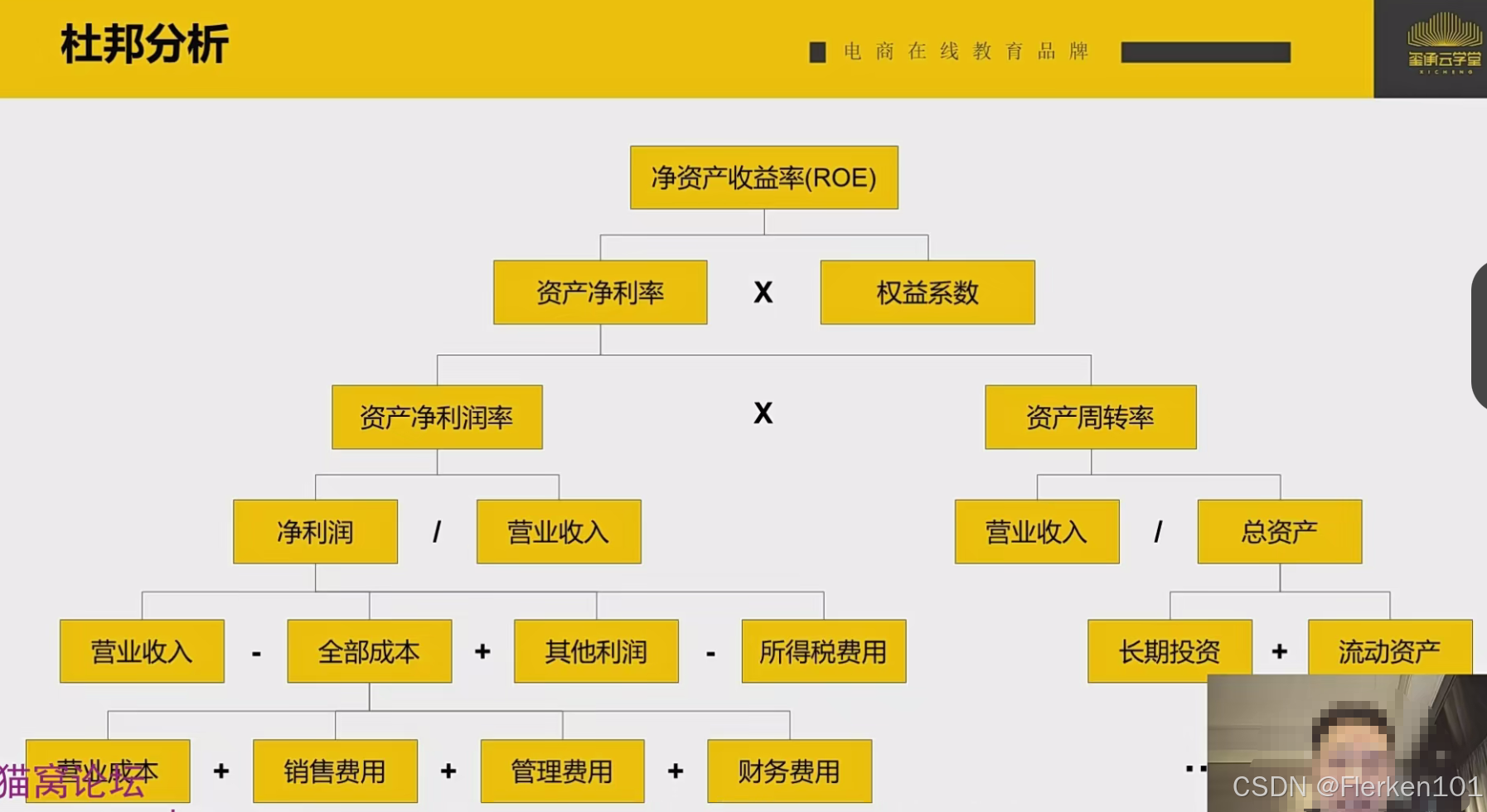
4.5.2.1 应用
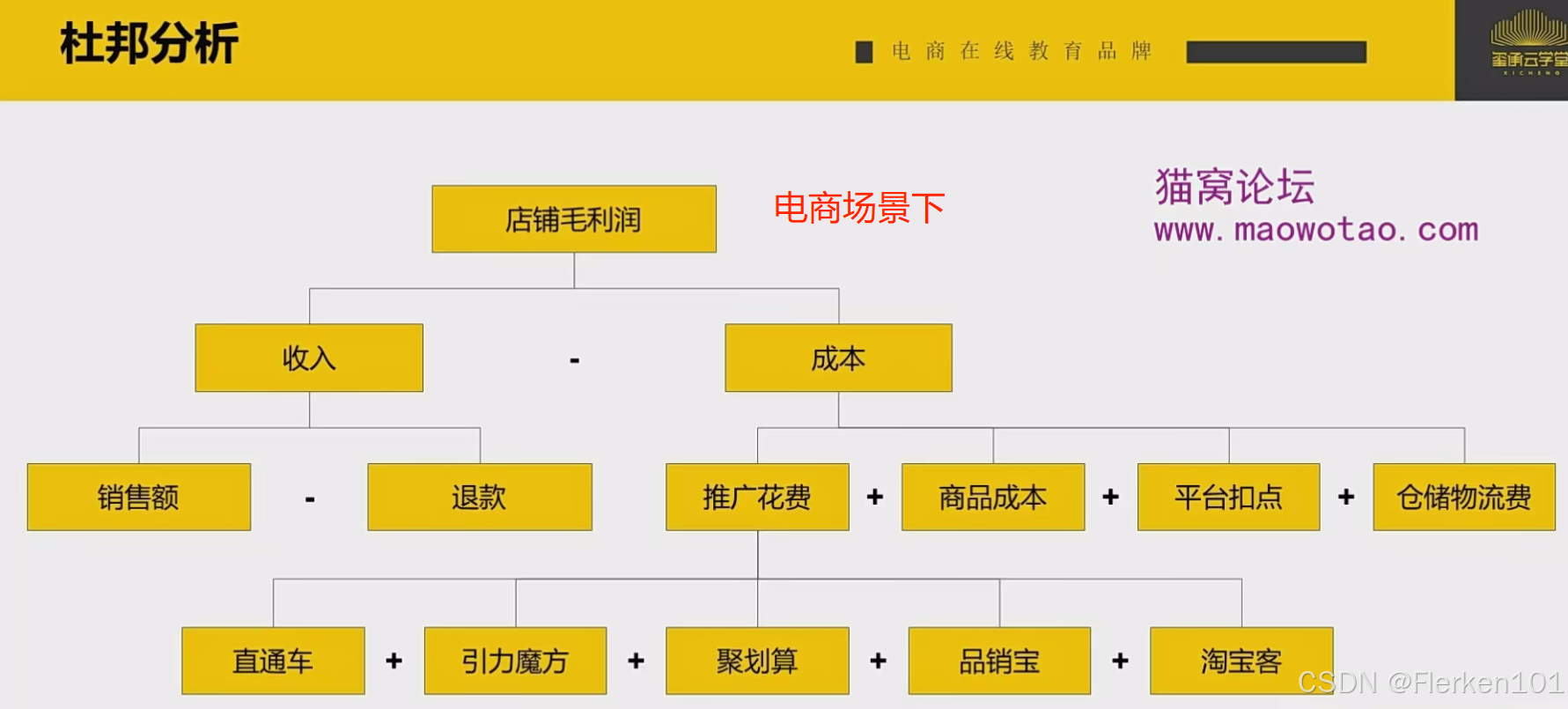
(1)拆分店铺毛利润
【这里的成本都是直接成本】
(2)拆分店铺销售额
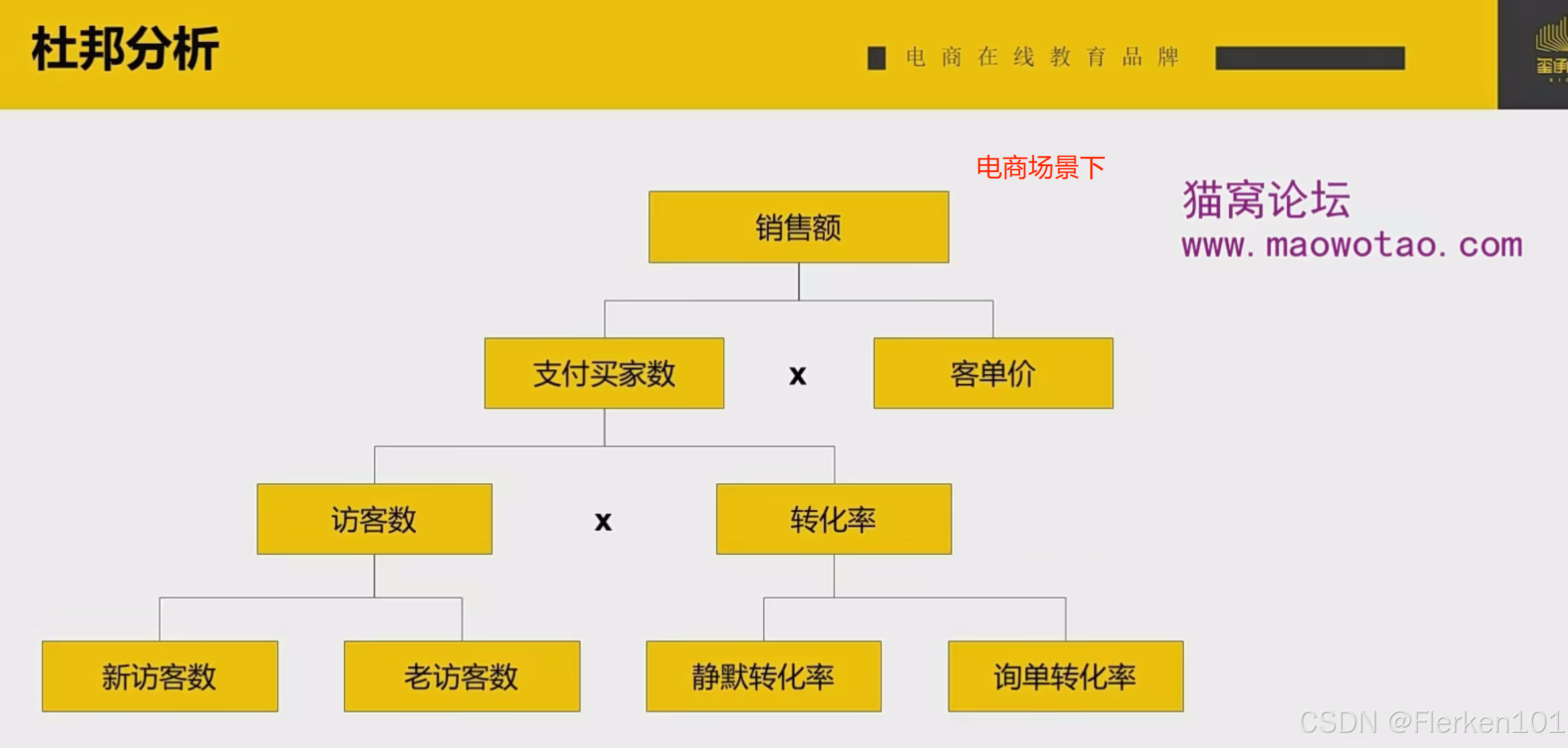
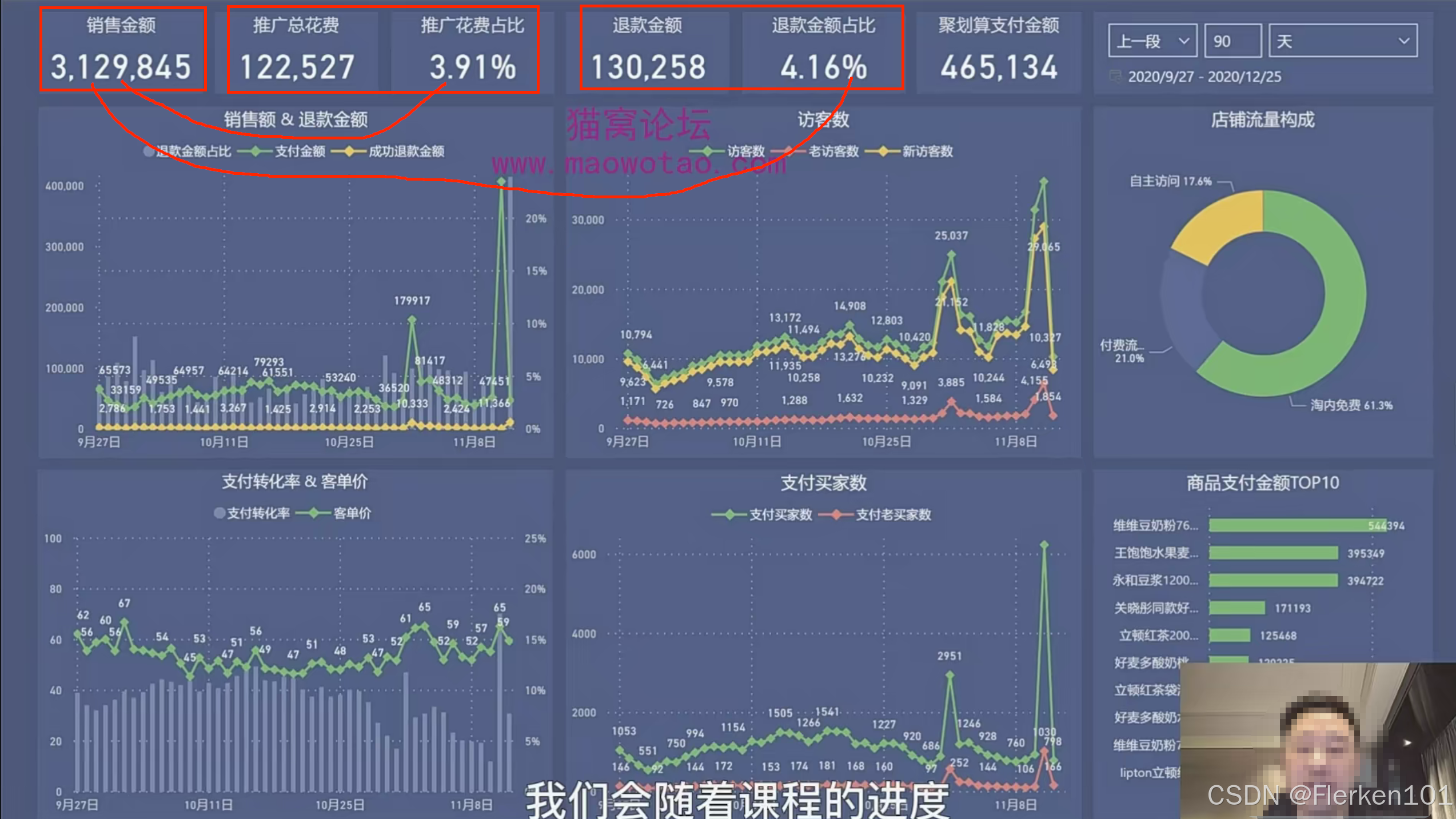
采用杜邦分析法的思想,拆解销售额后,可以制作这样一个数据运营中台/看板,将关键的指标都放在其中,可以很方便地了解每日的运营情况。
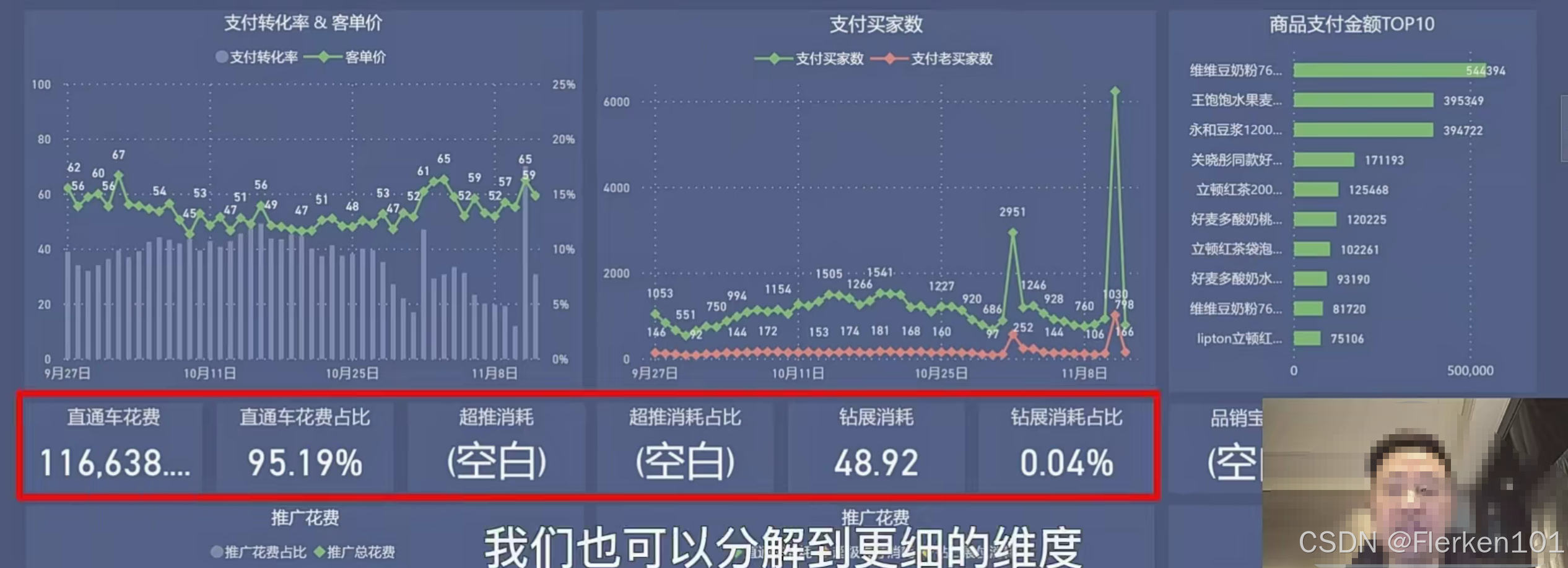
(3)拆分销售目标
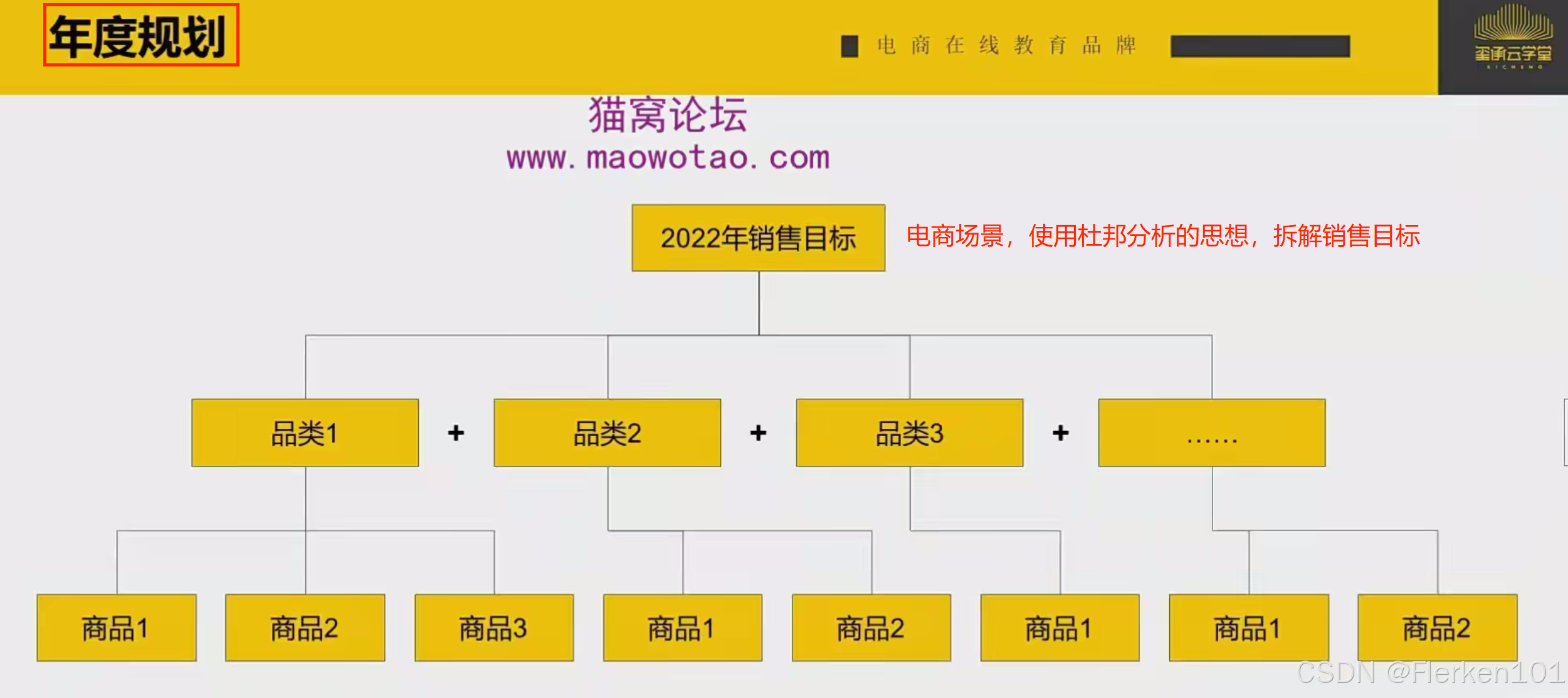
制作年度规划时,可以把年度规划的总销售目标,先分解到不同的品类,再分解到不同品类下的不同商品。
比如有些店铺经营的类目很单一,但体量很大,只要在一个类目里面经营,这个类目的体量就足以完成全年的销售额目标,那就只需要在这个类目里面去完成即可。
但如果一个品类无法完成全年的销售额目标,就需要拓品类,在更多的品类中去经营。
如果每个品类下的每种商品,完成自己销售额目标的确定性都非常高的话,那全年总销售目标完成的确定性也就非常的高。
案例:
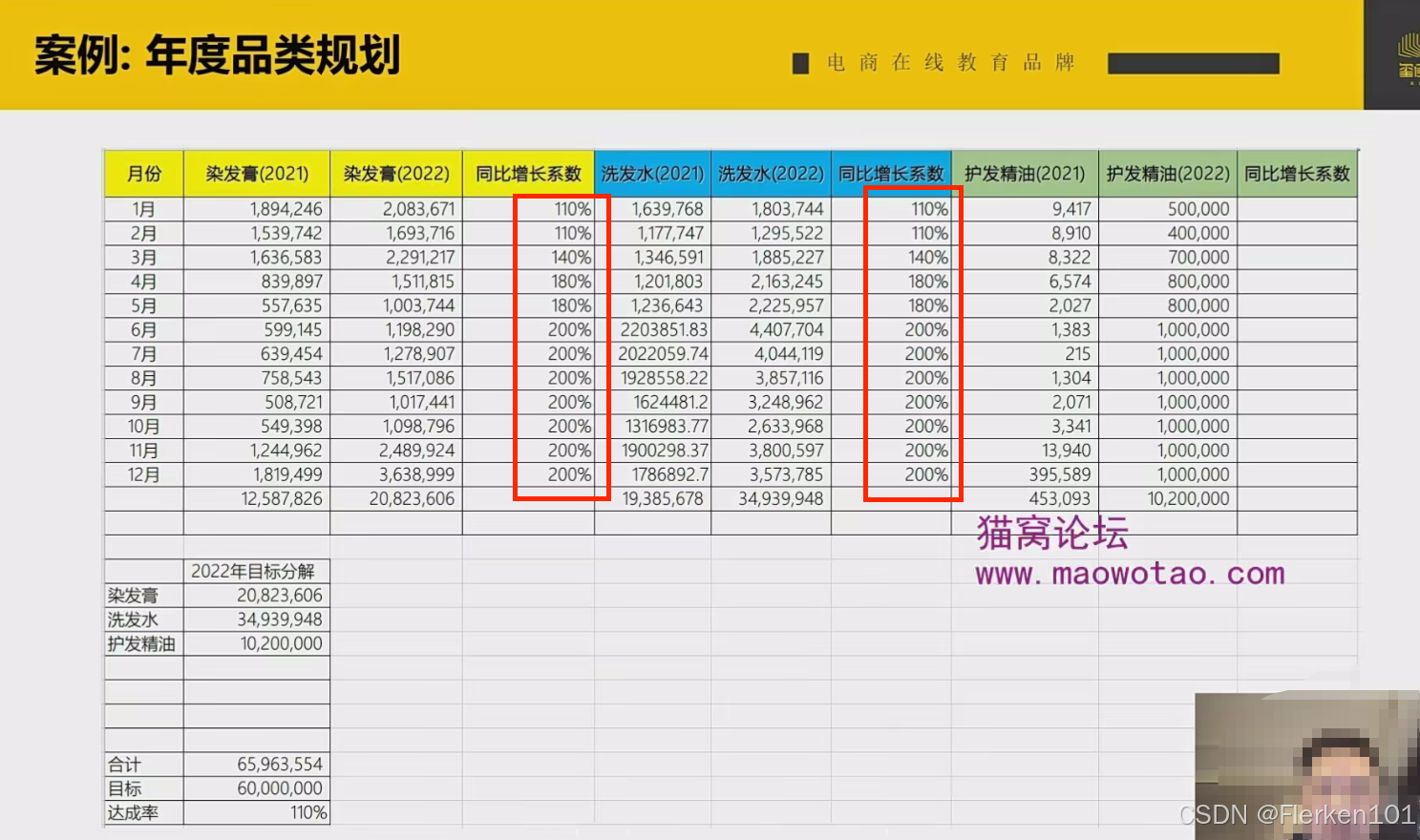
下图是一个经营美发护发类目的店铺,主要销售的是染发膏、洗发水、护发精油。
2021年完成了3000多万的销售额,2022年希望增长一倍,完成6000万的销售额。
根据2021年的销售情况以及未来产品布局,来进行2022年的规划。
首先是染发膏的品牌:
2022年第一季度(1-3月),考虑到目前品类的情况,设定的增长率并不是很高,只有百分之110到140%,但这个增长率老板和运营都是非常确定可以完成的。
2022年第二季度(4-6月),考虑到内部消费者有囤货的习惯,根据2021年的数据,以及今年618的增长情况,所以规划的增长率会比较高,从180%到200%之间。
…
通过这样的计算,认为染发膏在2022年能完成全年2000万的销售额。
采用同样的方法,在洗发水类目规划了3500万的销售额。
如果只有染发膏、洗发水,这两个类目的话,全年只能完成5500万的销售额。
但这时发现了护发精油的类目,在2021年底增长得不错。
根据老板的计划,在这个新类目里面规划了1000万的销售额。
那么通过这样的层层分解,全年应该可以完成6500万的销售额,目标达成率110%.
当然这个表格可以继续细分,把每个单品的销售额分解出来。
在2022年下半年,规划的增长率都是比较高的,这可能需要有更多的单品来进行承载,这也是老板今年需要重点关注的事情。
通过这样的规划,无论是老板还是店长,对2022年的年度销售目标都会逐步清晰。
4.6 大环境分析
4.6.1 PEST分析(行业分析)
政治(Political)、
经济(Economic)、
社会(Social)、
技术(Technological)





4.6.2 波特五力(五种外界竞争力影响分析)
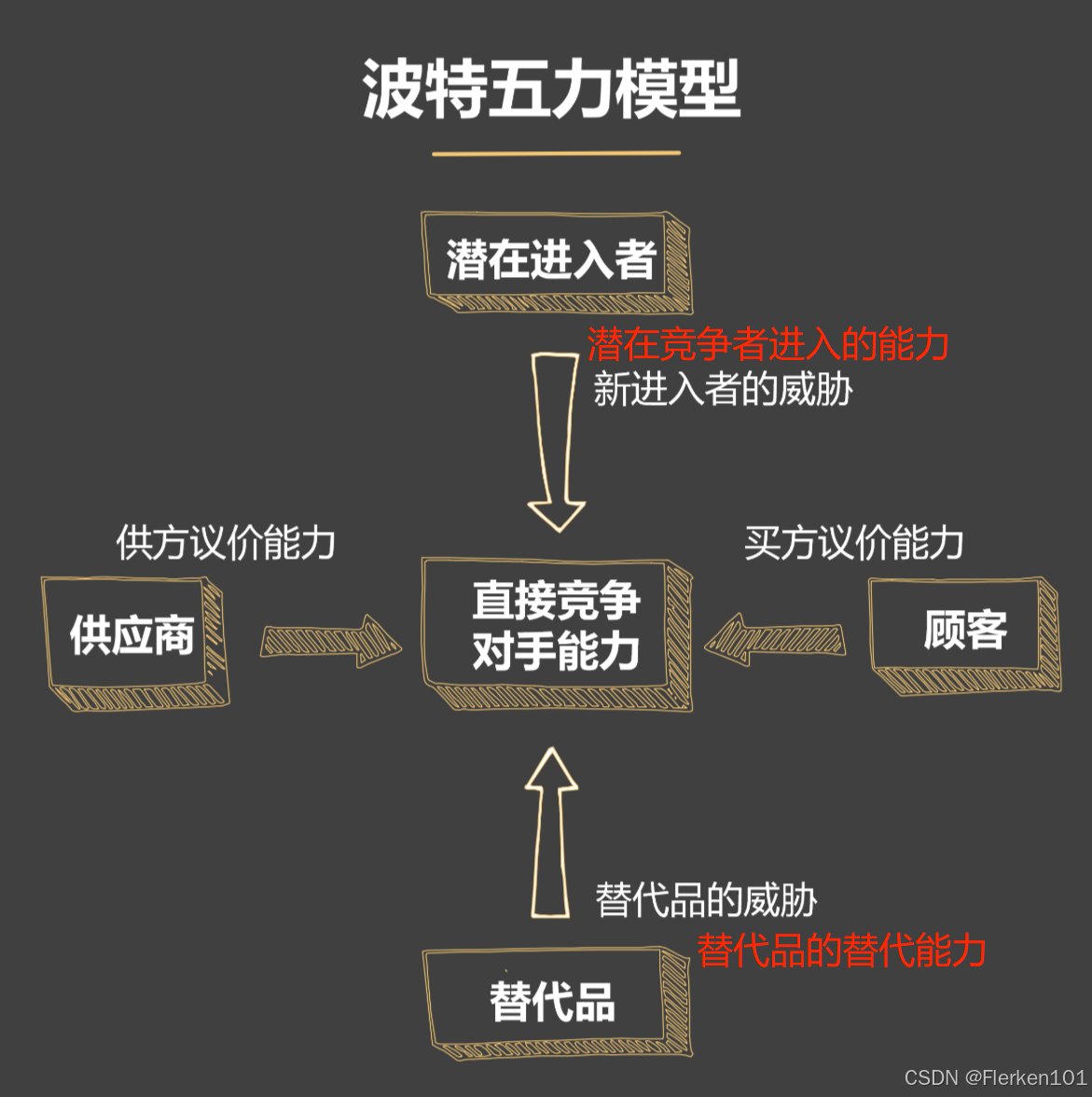
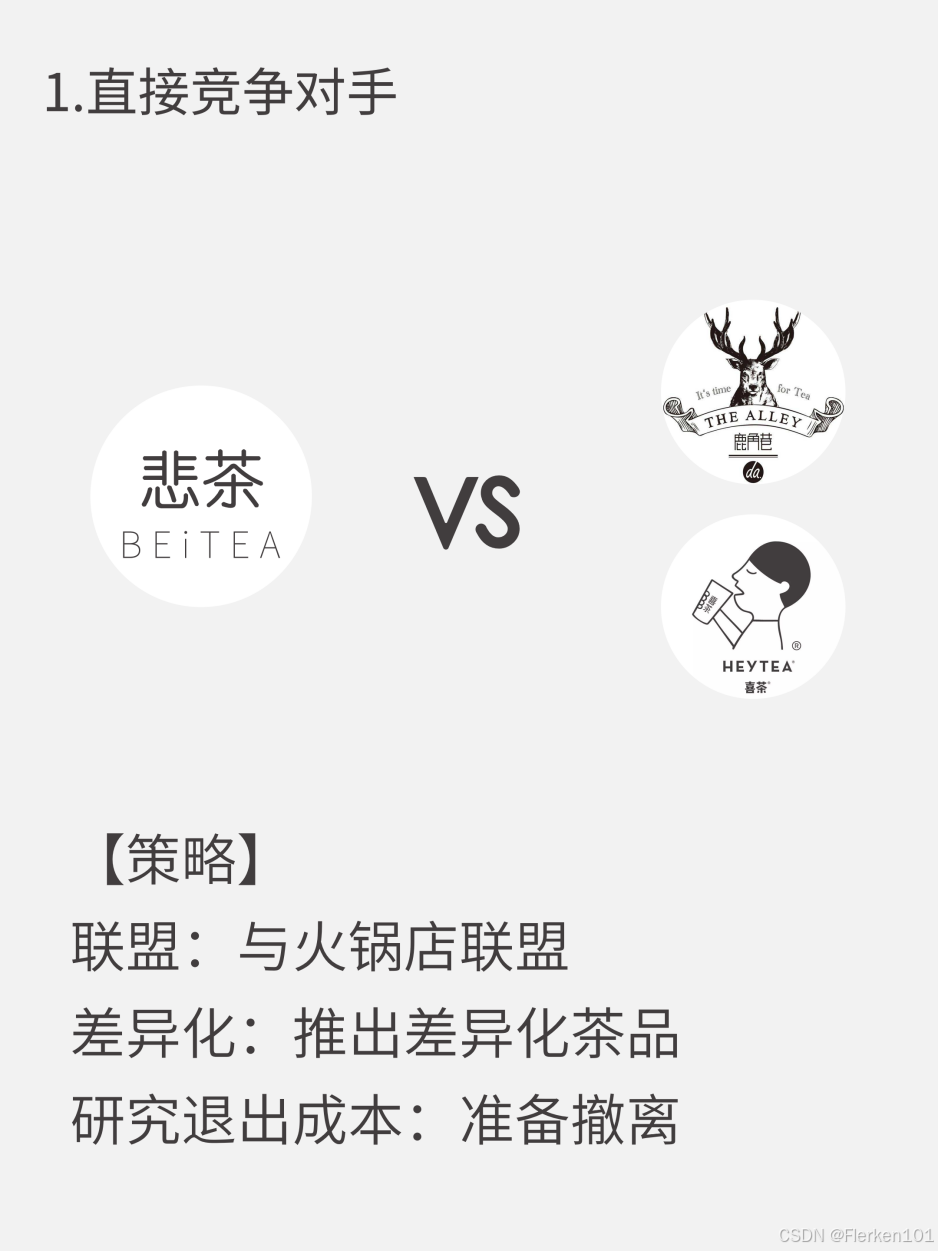


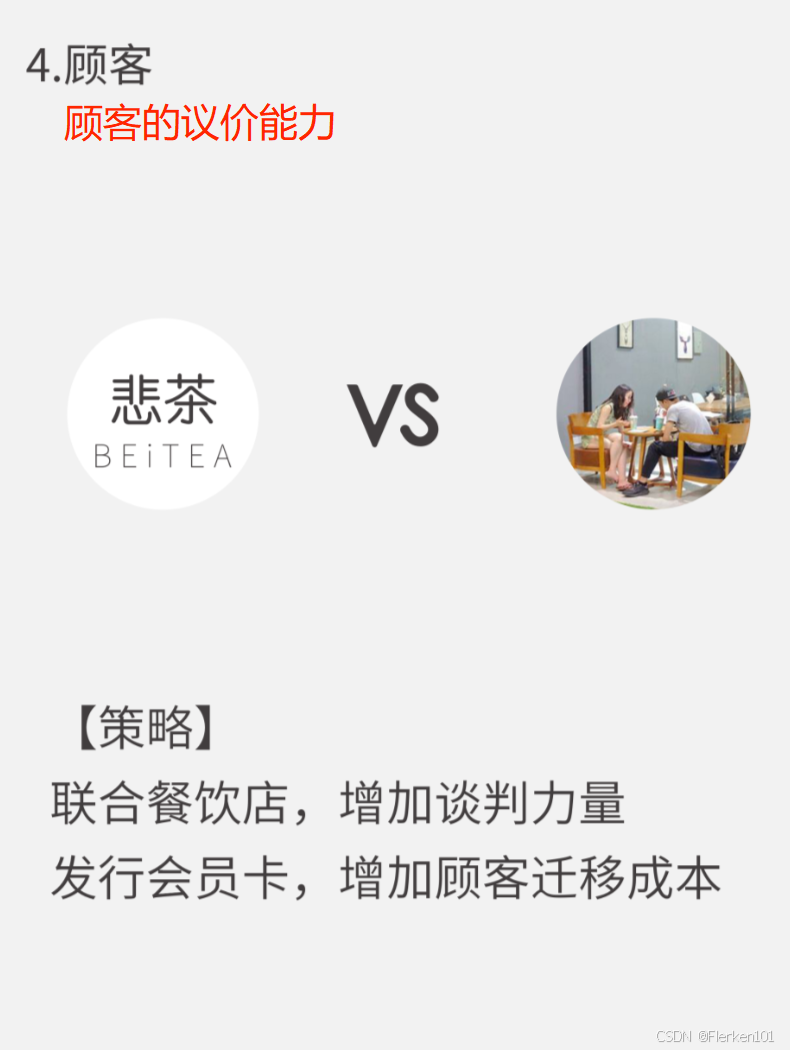

4.6.3 SWOT分析(企业 外界环境 及 内部环境 的分析)
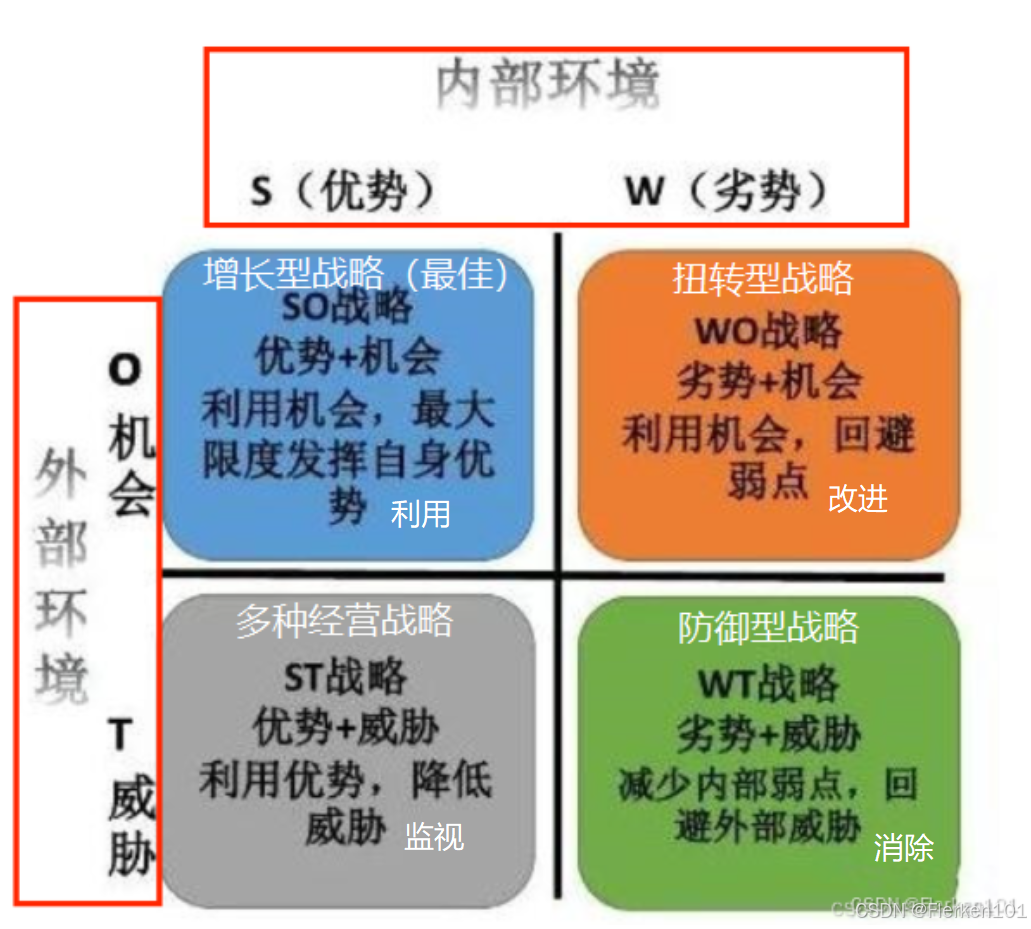
SWOT分析法的实用性解析(附SWOT分析案例)—— MeelounEssay
资源优势(Strengths)、
竞争劣势(Weaknesses)、
外部环境变化带来的机会(Opportunities)、
威胁(Threats)


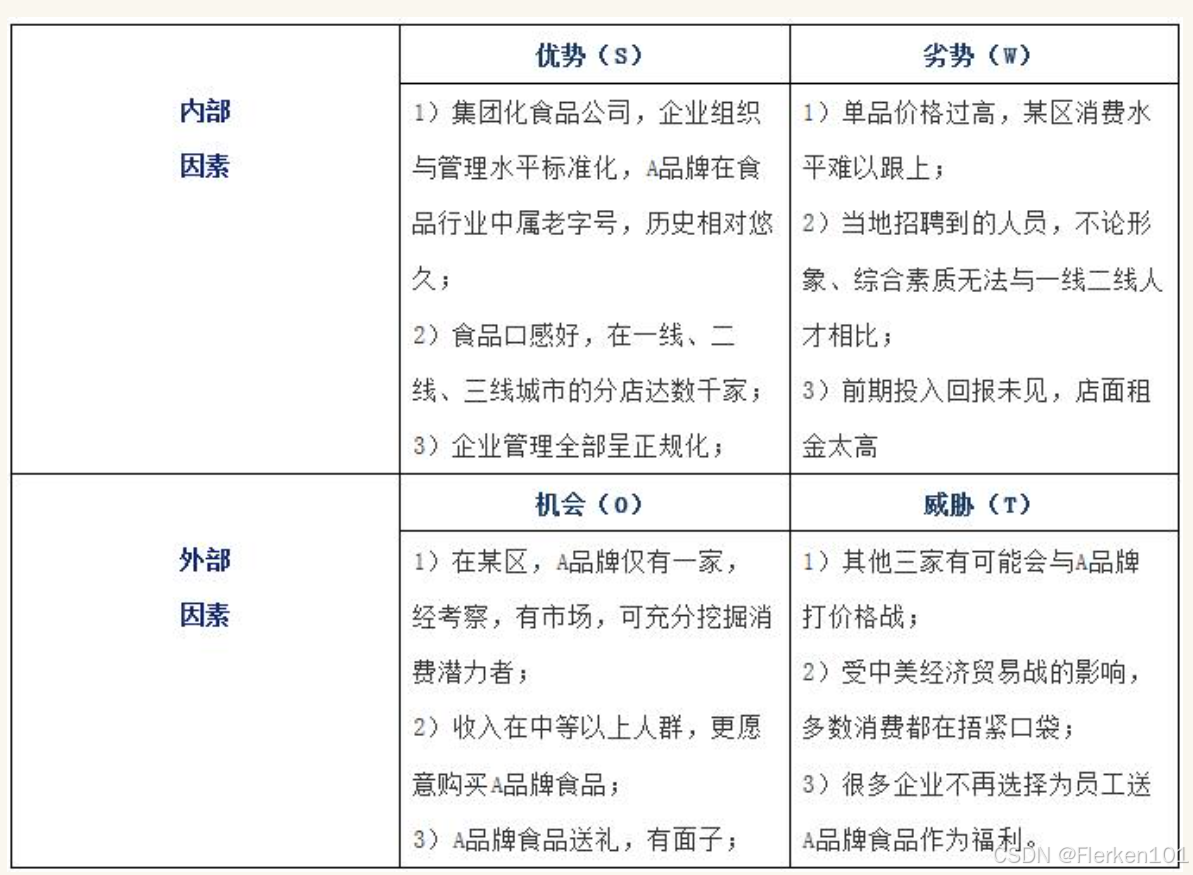
案例:

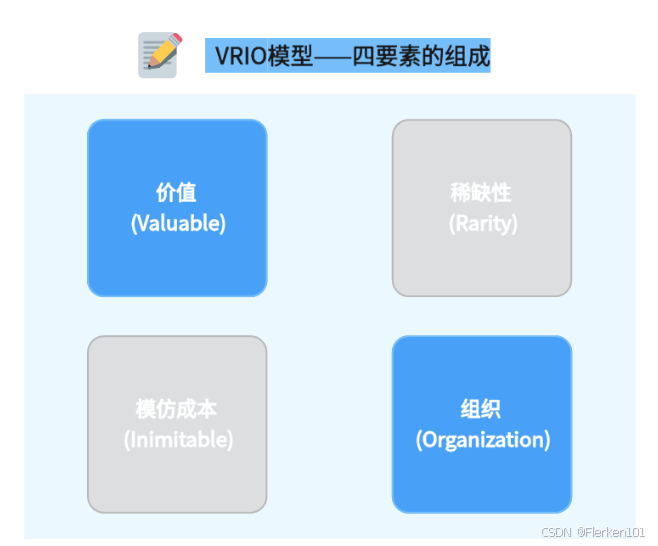
4.6.4 VRIO分析(企业内部竞争优势分析)
VRIO 模型怎么用:4个维度剖析企业竞争优势——boardmix博思在线白板
巴尼在1991年提出了VRIO模型,该模型指出了有四个因素对企业的持久竞争优势产生了影响,并且只有四个因素都满足时,企业才能够获得持久的竞争优势。
这四个因素分别代表的是:
V (Valuable):企业的资源和能力能否增加价值?
R (Rarity罕见性):有多少竞争企业获得了这些有价值的资源和能力?
I (Inimitable):资源是否容易被模仿?未获得这些资源和能力的企业会否出现劣势?
O(Organization):企业是否被组织起来,充分开发和利用它的资源和能力?
VRIO模型一个内部分析模型,与外部环境因素无关。
它是帮助企业发现内部的资源和能力、分析企业竞争优势和弱点的战略工具,以此来可视化哪个资源或者能力可以有潜力成为公司内部的可持续竞争优势,帮助企业明确了整合或者升级资源的方向,从而为企业赋予长期的核心竞争力。
该模型是一个需要按照V—R—I—O 的顺序进行逐步分析的,这样才可以知道企业内特定的一个资源和能力是否可以被认定为可持续的竞争优势。





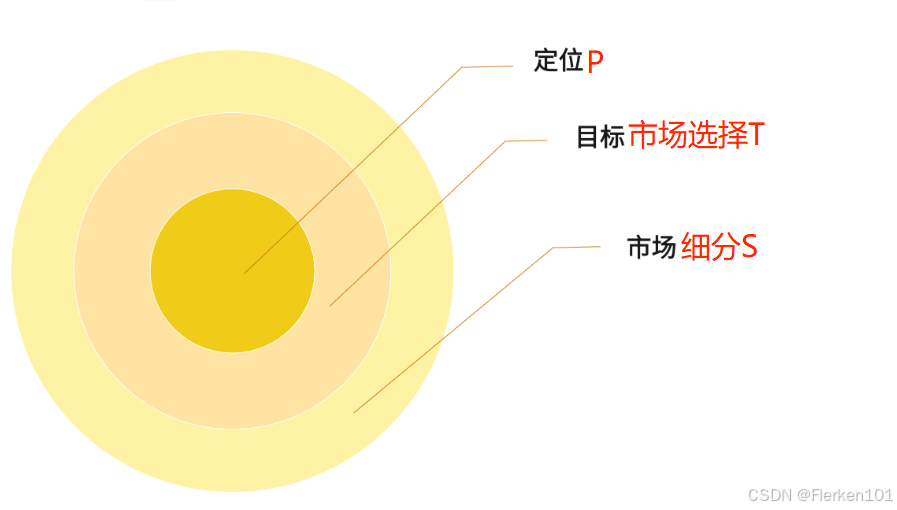
4.6.5 STP分析——进行市场细分,完成产品定位、价格定位


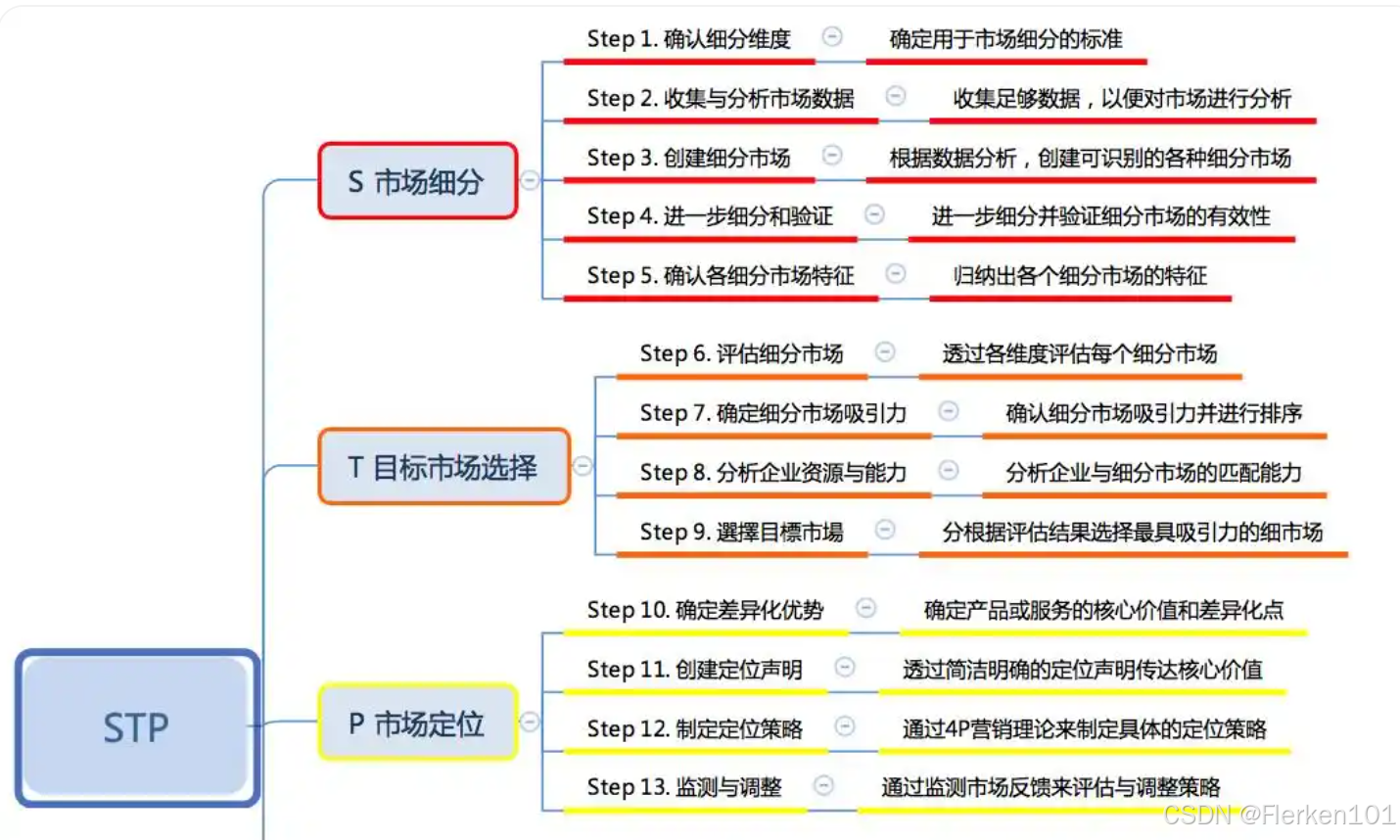
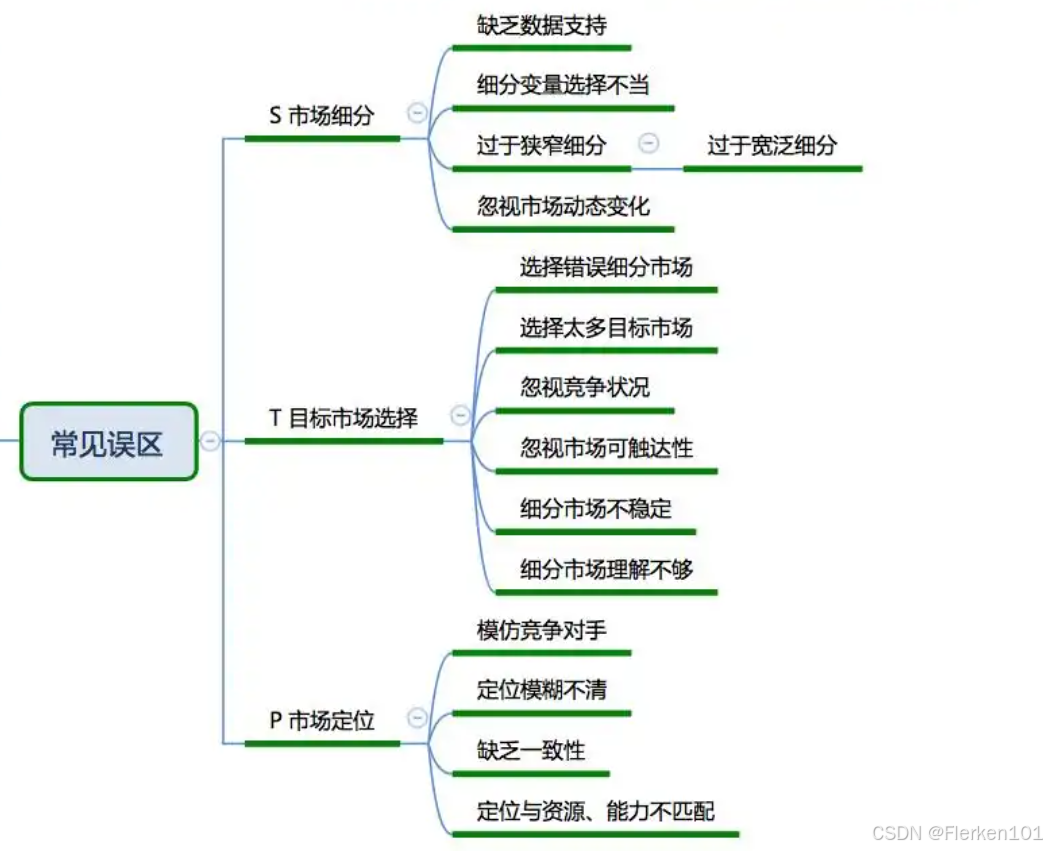


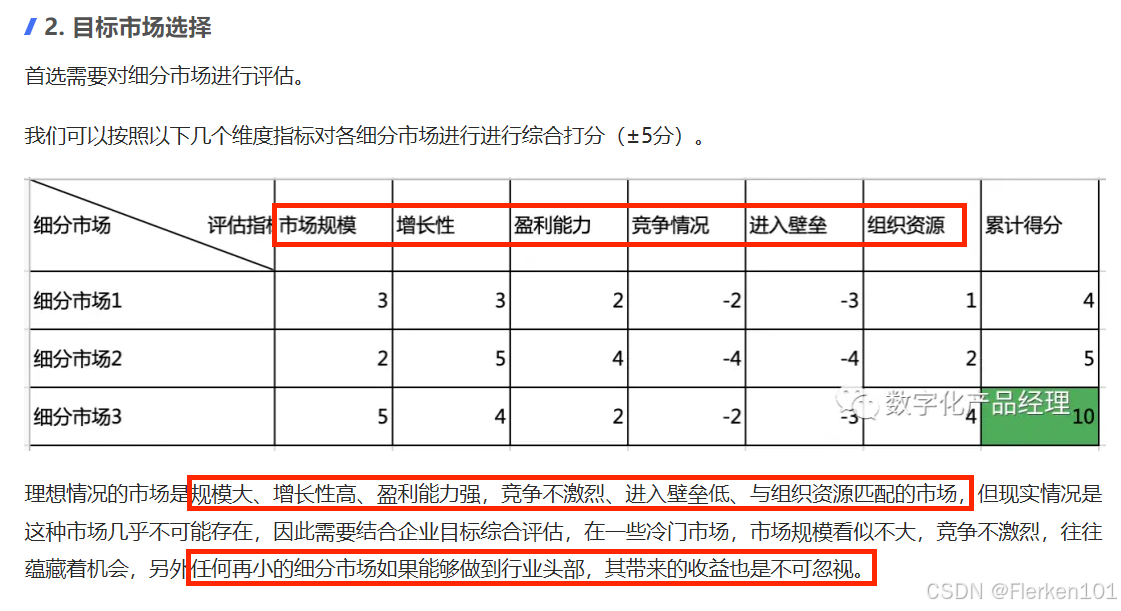
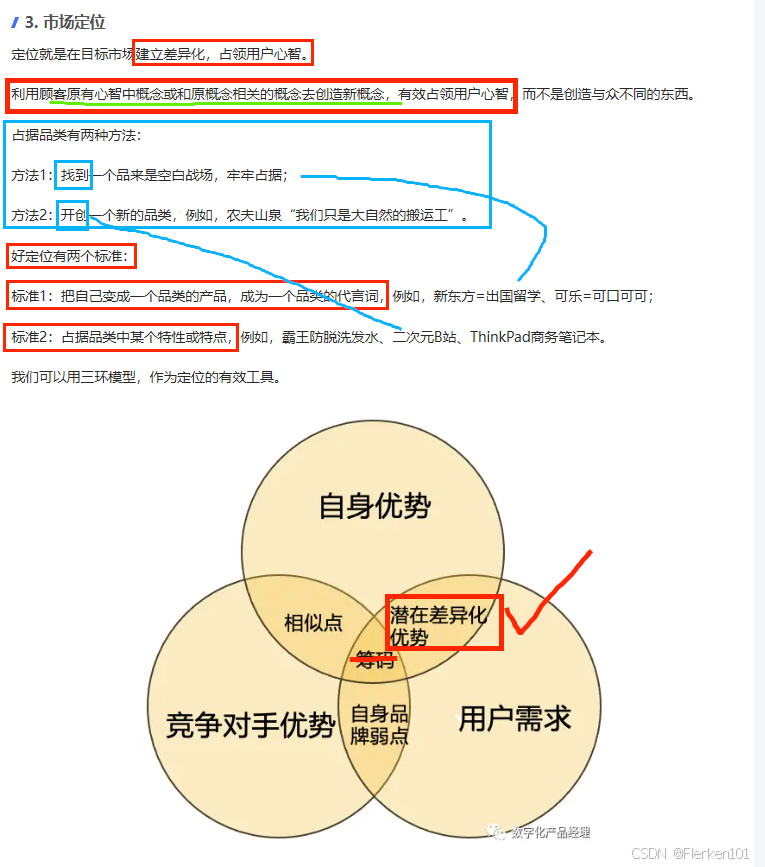
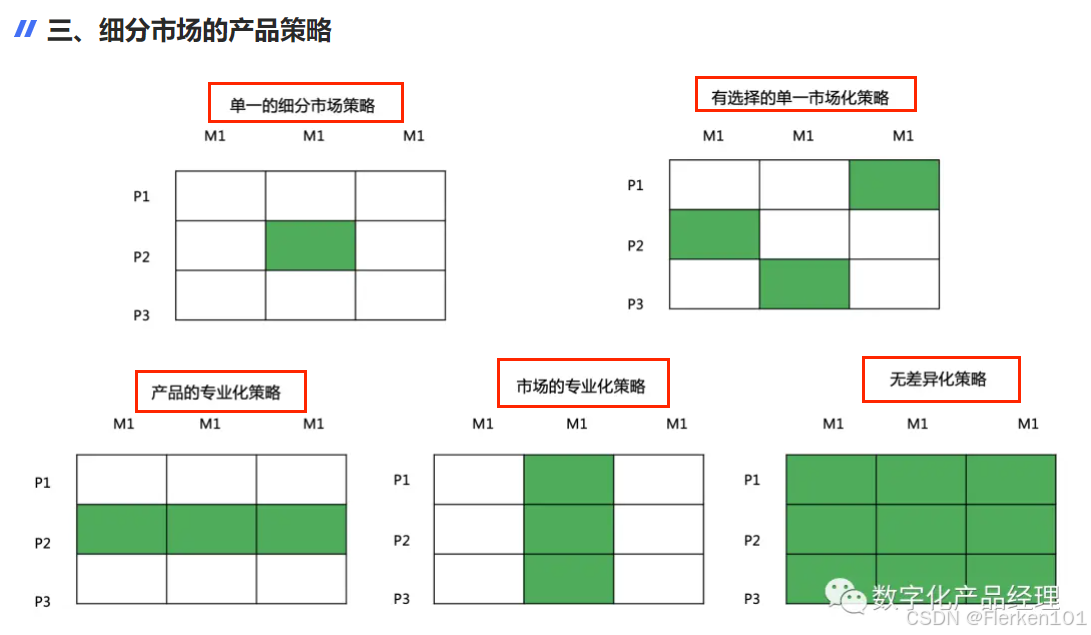

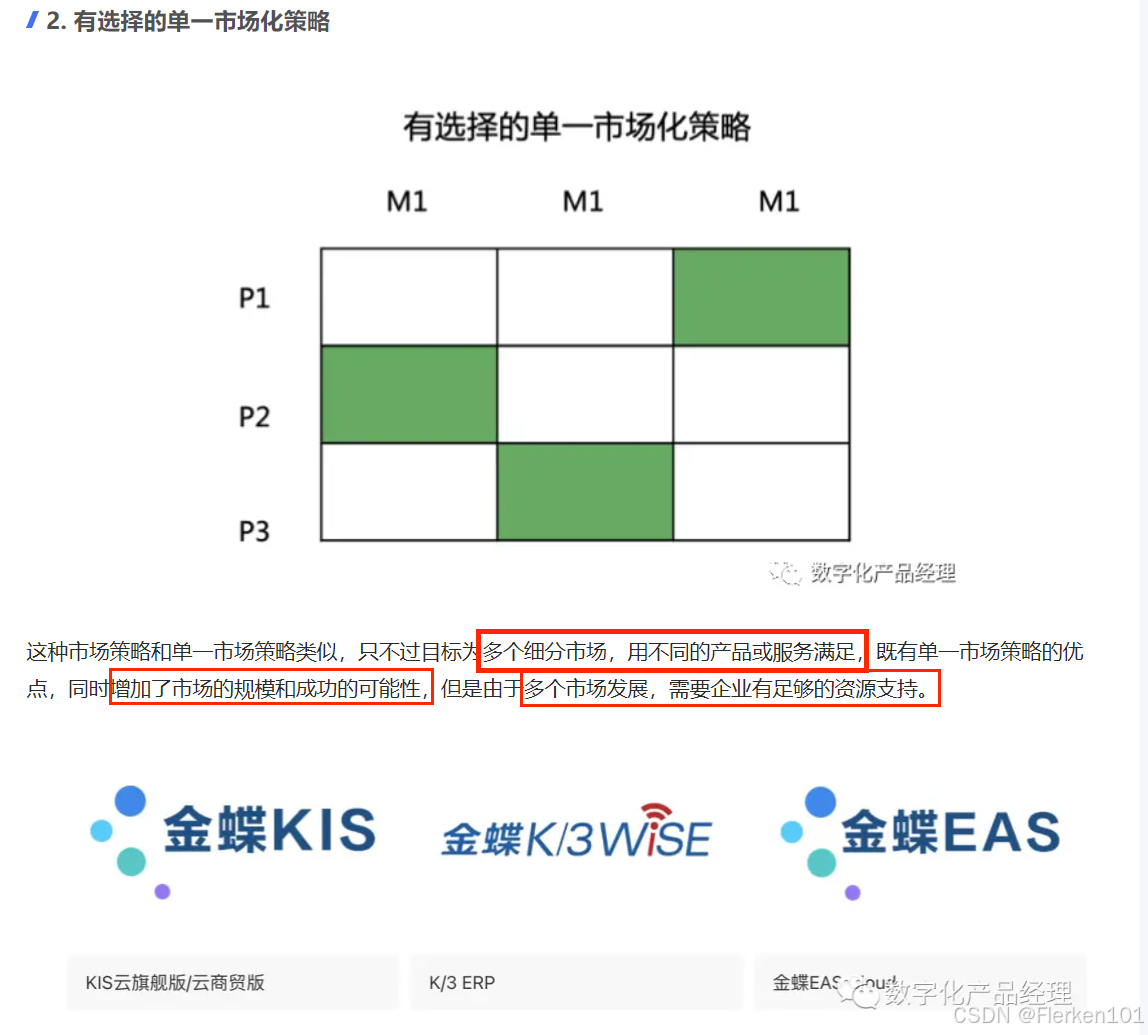
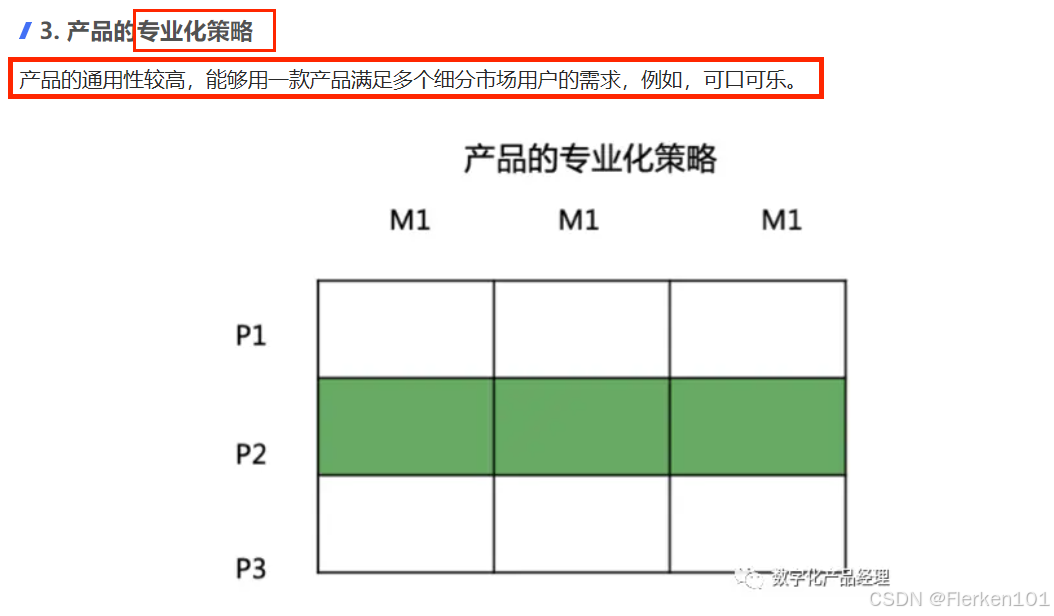
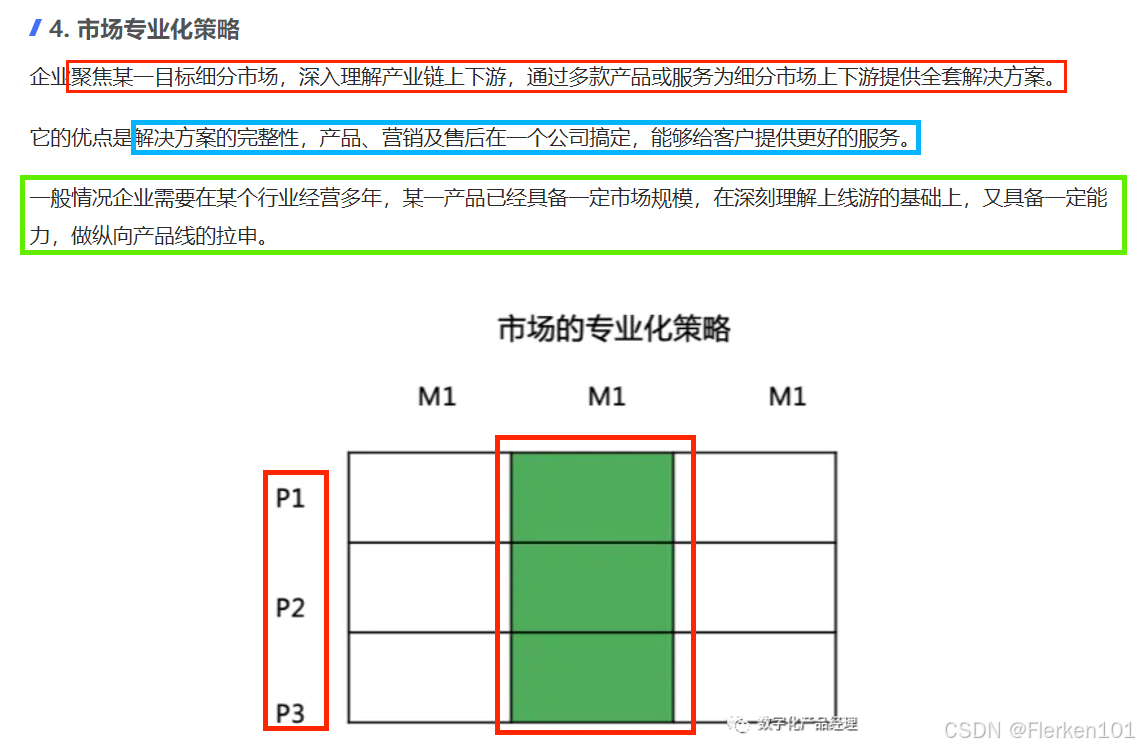

4.6.6 4P’s 营销理论(The Marketing Theory of 4Ps)
产品(Product)、
价格(Price)、
渠道(Place)、
宣传推广/促销(Promotion)
由于这四个词的英文字头都是P,再加上策略(Strategy),所以简称为“4P’s”。






4.7 需求分析
4.7.1 传统KANO模型(传统卡诺模型)
最全面的Kano模型详解,及Kano模型为何是5种需求?——惹不起的程咬金

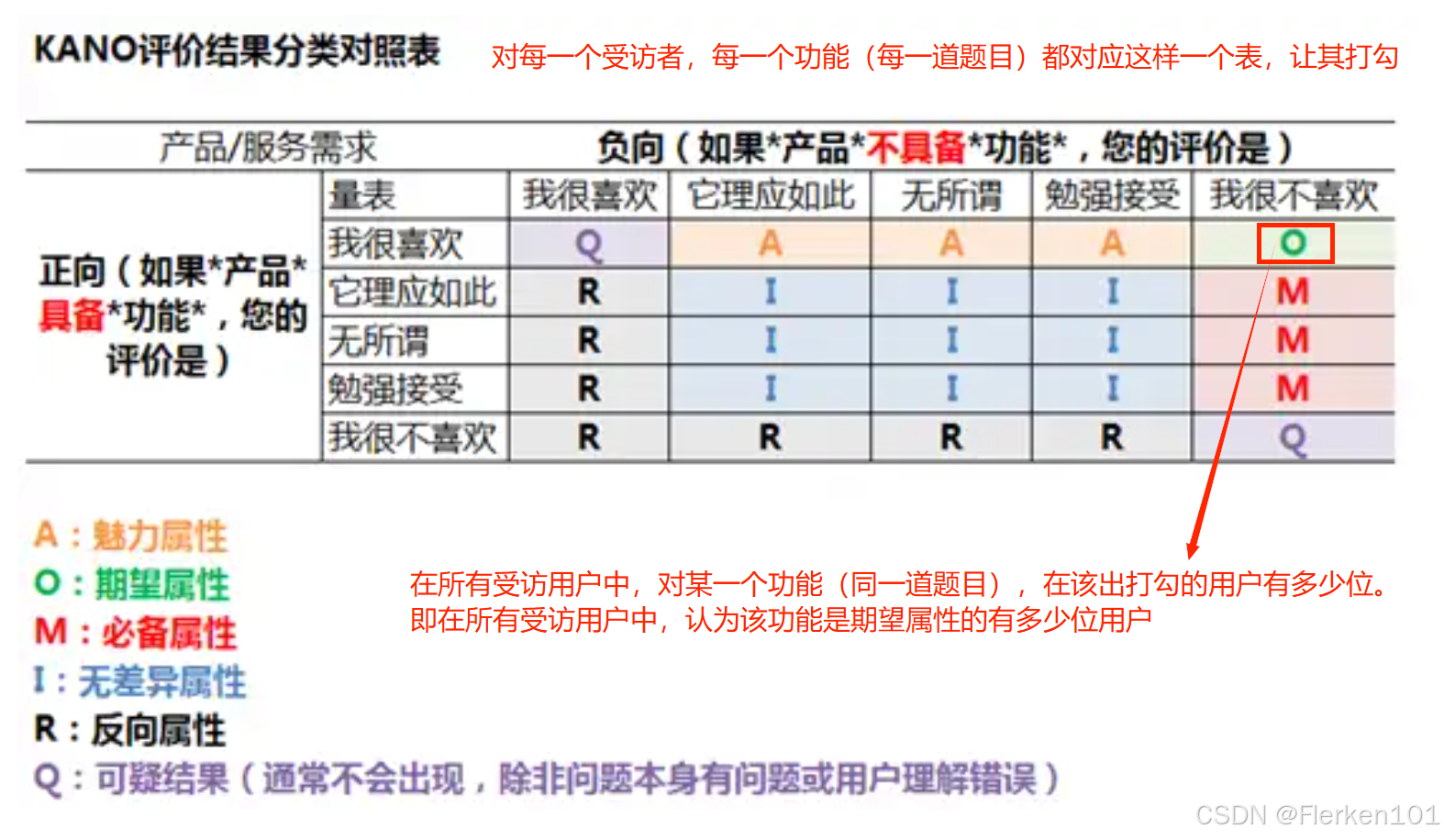
两个系数中,都没有考虑某一个功能,受访者认为其为 反向属性R类 和 可疑属性Q类 的情况。

在产品开发时(此时不考虑四分位图中的象限),功能优先级的排序一般是:必备属性>期望属性>魅力属性>无差异属性。
对应下面四分位图,在产品开发时,对各种类型功能的考虑优先级顺序为:
第四象限的功能 > 第一象限的功能 > 第二象限的功能 > 第三象限的功能
必备属性的功能 > 期望属性的功能 > 魅力属性的功能 > 无差异属性的功能
根据 better 和 worse 系数的含义,都应当是优先实施 对系数绝对值较大的 功能/服务需求。
又因为 worse 系数 为一般负值,所以应该优先考虑 better系数值较大,worse系数值较小的。虽然对某一个功能,better 和 worse两个系数都是绝对值越大越好。
但同类型的多个功能之间(落在同一象限的散点),建议优先考虑better系数值较高,然后再考虑worse系数值较低的(绝对值较大的)。即对于落在第四象限(必备功能)的两个散点,虑优先级顺序为:
功能5 > 功能4
因此,为提高用户的满意度,在下面整个四分位图中,所有功能的考虑优先级顺序为:
功能5 > 功能4 > 功能2 > 功能1 > 功能3
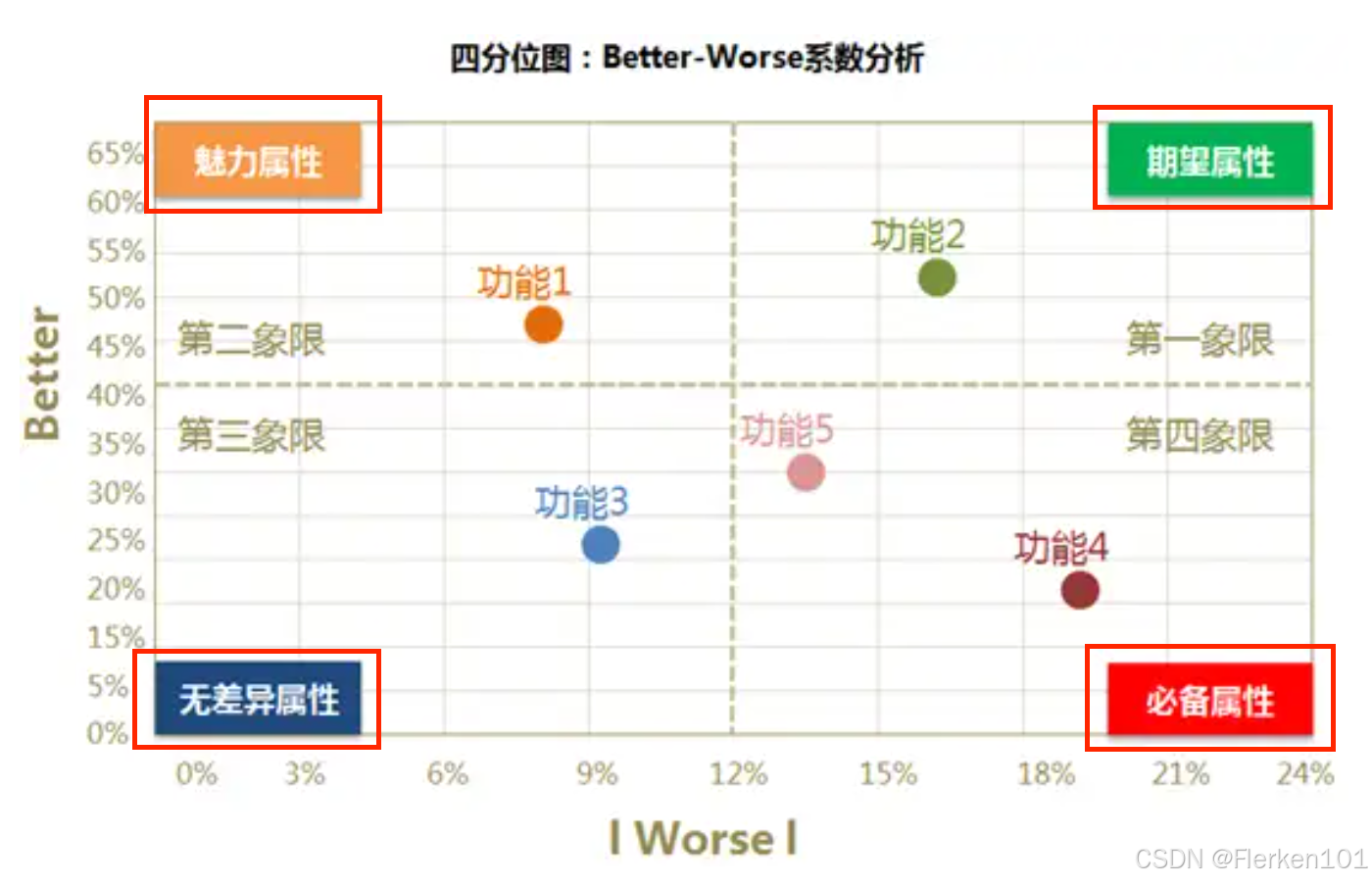
实际需要考虑产品的市场策略时,期望属性和魅力属性是可以击中用户的爽点或痒点的。
具体应用:
在争取市场份额上,期望属性和魅力属性更为重要,且可以考虑作为产品卖点进行包装营销。

4.7.2 模糊KANO模型(模糊卡诺模型)
哪个能跑通看哪个。
基于模糊 KANO-SEM 模型的用户需求识别方法研究——李树,蒋鹏
模糊 KANO 模型相对于传统 KANO 模型最大的不同在于模糊 KANO 模型问卷允许被试者根据自己的心理感受对每项需求在[0,1]之间任意赋值,最终和为 1。
需求的隶属度向量 T 的计算方式是?
不存在一行五列的矩阵 X满足:X * A = T.
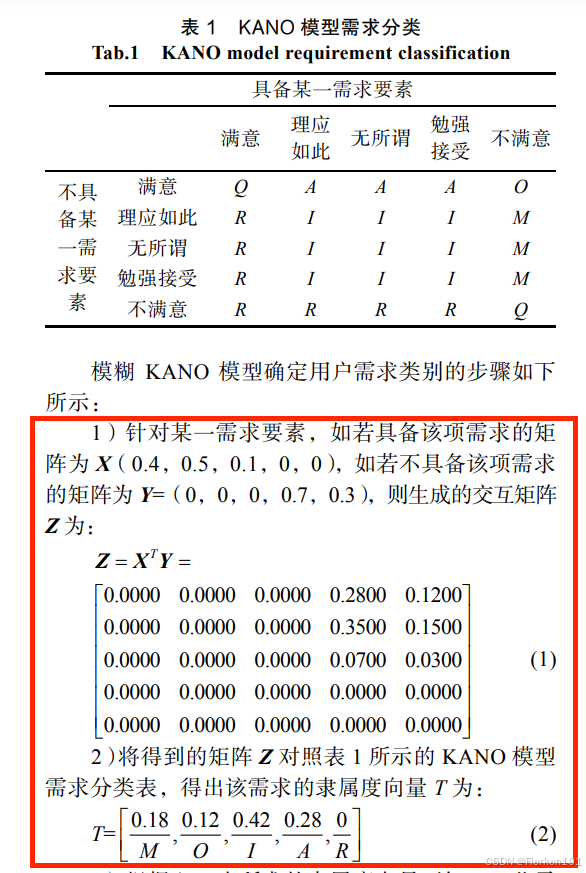
??
模糊 KANO 模型相对于传统 KANO 模型最大的不同在于模糊 KANO 模型问卷允许被试者根据自己的心理感受对每项功能在 [0,1] 之间任意赋值,最终该功能在各种属性中的隶属度和为 1。
就是计算每个功能,每种属性的的系数,不只是计算better 和 worse 系数:
A /(A + O + M + I + R)
O /(A + O + M + I + R)
M /(A + O + M + I + R)
I /(A + O + M + I + R)
R /(A + O + M + I + R)
五和数值,加起来和为1.
以智能手机的 “快充”功能需求分析为例:
(1)传统 KANO 模型:对于 “手机快充功能”,若通过问卷调查,多数用户表示有快充功能会满意,没有也不会太不满,就会将其归为魅力型需求。
(2)模糊 KANO 模型:同样针对 “手机快充功能”,通过模糊 KANO 模型分析,可能得出该功能属于魅力型需求的隶属度为 0.6,属于期望型需求的隶属度为 0.3,属于必备型需求的隶属度为 0.1。
这不仅能说明快充功能主要是魅力型需求,还能体现出它在一定程度上也有期望型需求的特征,即部分用户还是比较希望手机具备快充功能的,比传统 KANO 模型的分析更细致深入。
4.8 异动归因分析——贡献度计算
⭐『指标异动』贡献度定量归因之法,带你知因又知果! —— 六哥1

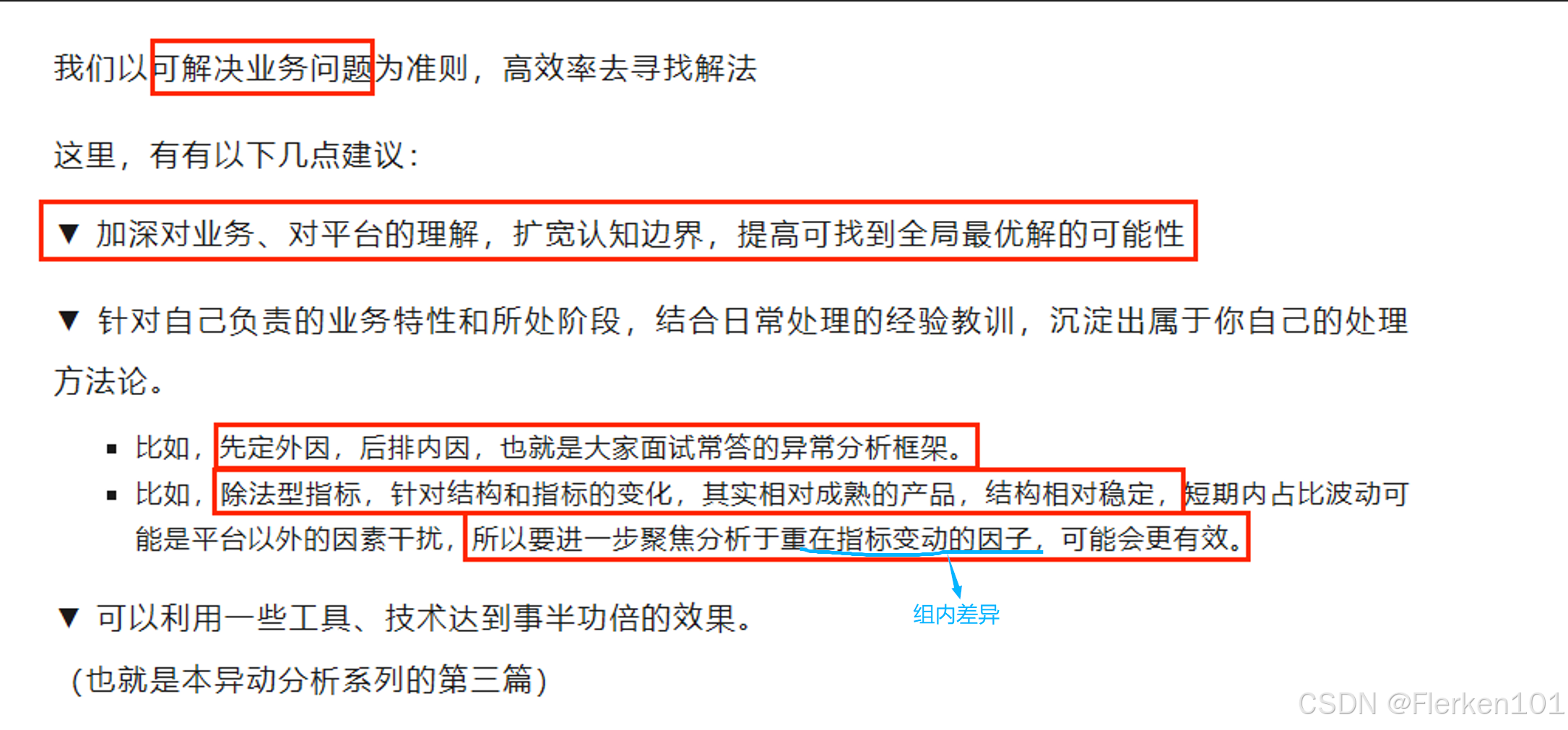
在异动分析中,一般采用 “先定外因,后排内因” 的异动分析框架。
先快速识别和排除外部因素影响(周期性、竞争对手、合作伙伴等),再深入企业内部,从产品、运营、人员等方面查找根源,制定针对性解决方案。



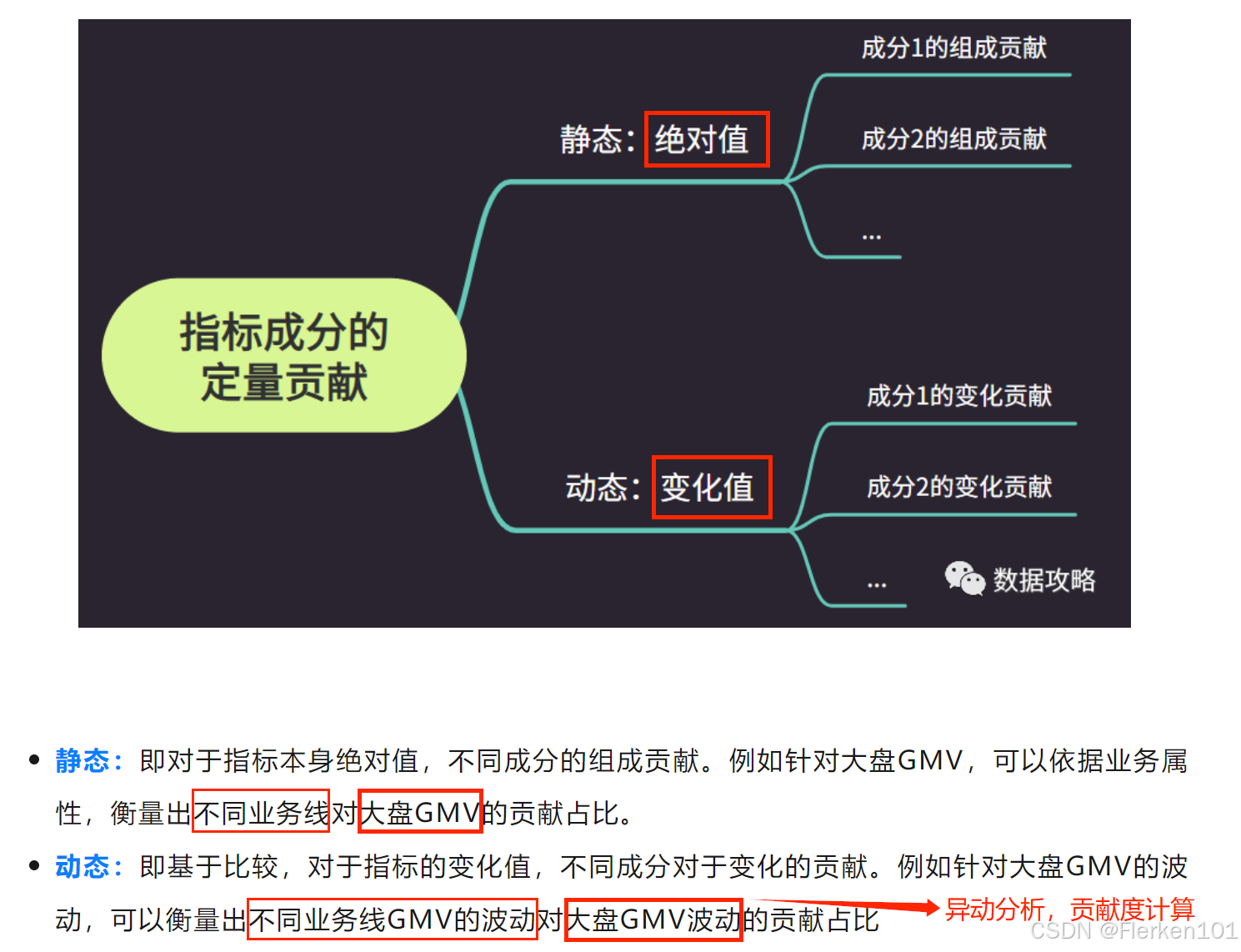


4.8.1 加法型指标拆解


实例:
业务背景:大盘DAU = 自然流量DAU + 分享渠道DAU + 其它渠道DAU
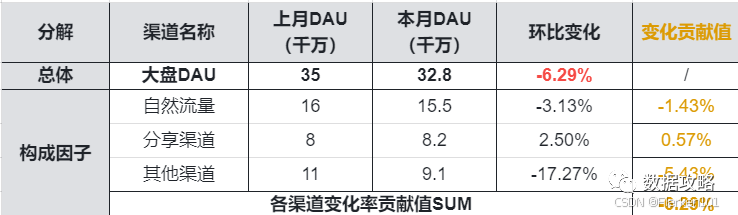
(1)本月大盘DAU环比变化 计算方式一:
本月大盘DAU环比变化 = (本月大盘DAU - 上月大盘DAU)/ 上月大盘DAU
本月大盘DAU环比变化 = (32.8 - 35)/ 35 = -6.29%
(2)本月大盘DAU环比变化 计算方式二:
本月大盘DAU环比变化
= (本月自然流量DAU + 本月分享渠道DAU + 本月其它渠道DAU - 上月自然流量DAU - 上月分享渠道DAU - 上月其它渠道DAU )/ 上月自然流量DAU + 上月分享渠道DAU + 上月其它渠道DAU
= (本月自然流量DAU + 本月分享渠道DAU + 本月其它渠道DAU - 上月自然流量DAU - 上月分享渠道DAU - 上月其它渠道DAU )/ 上月大盘DAU
本月大盘DAU环比变化 = (15.5+8.2+9.1 - 16-8-11)/ (16+8+11) = -6.29%
(3)各渠道本月DAU变化,对本月大盘DAU环比变化贡献度的计算:
本月大盘DAU环比变化 自然流量贡献度 =(15.5-16)/ (16+8+11) = (15.5-16)/ 35 ≈ -1.43%
本月大盘DAU环比变化 分享渠道贡献度 =(8.2-8)/ (16+8+11) = (8.2-8)/ 35 ≈ 0.57%
本月大盘DAU环比变化 其它渠道贡献度 =(9.1-11)/ (16+8+11) = (9.1-11)/ 35 ≈ -5.43%
(4)本月大盘DAU环比变化 与 各渠道本月DAU变化,对本月大盘DAU环比变化贡献度 之间的关系:
-6.29% = -1.43% + 0.57% -5.43%
本月大盘DAU环比变化 = 本月大盘DAU环比变化自然流量贡献度 + 本月大盘DAU环比变化分享渠道贡献度 + 本月大盘DAU环比变化其它渠道贡献度
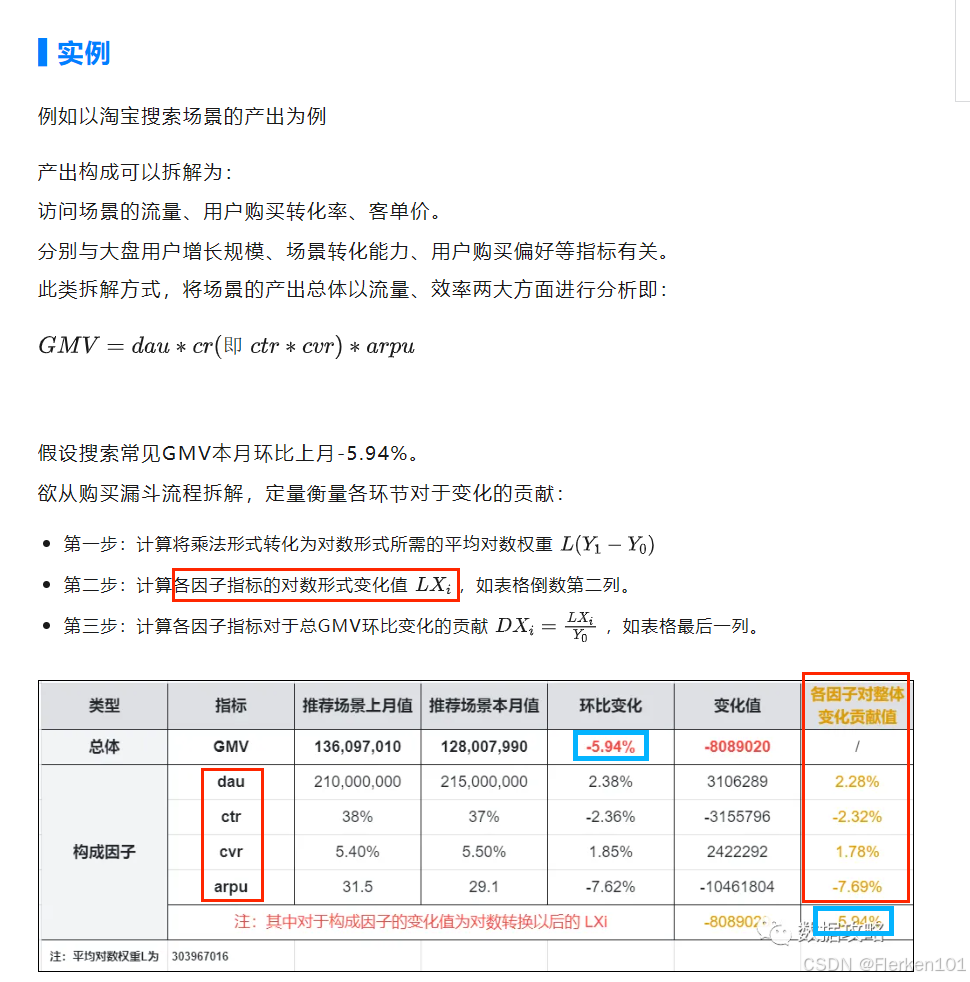
4.8.2 乘法型指标拆解




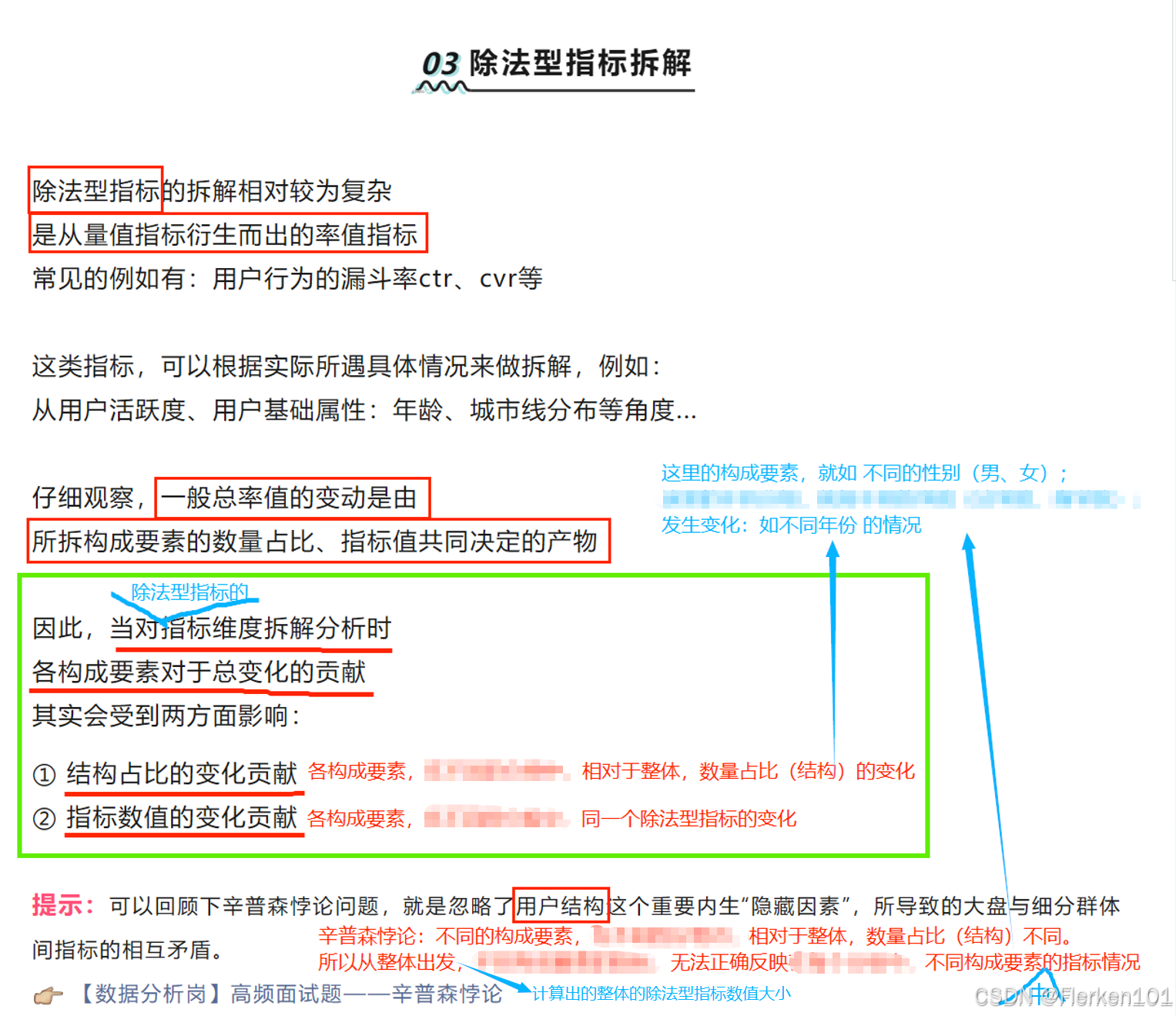
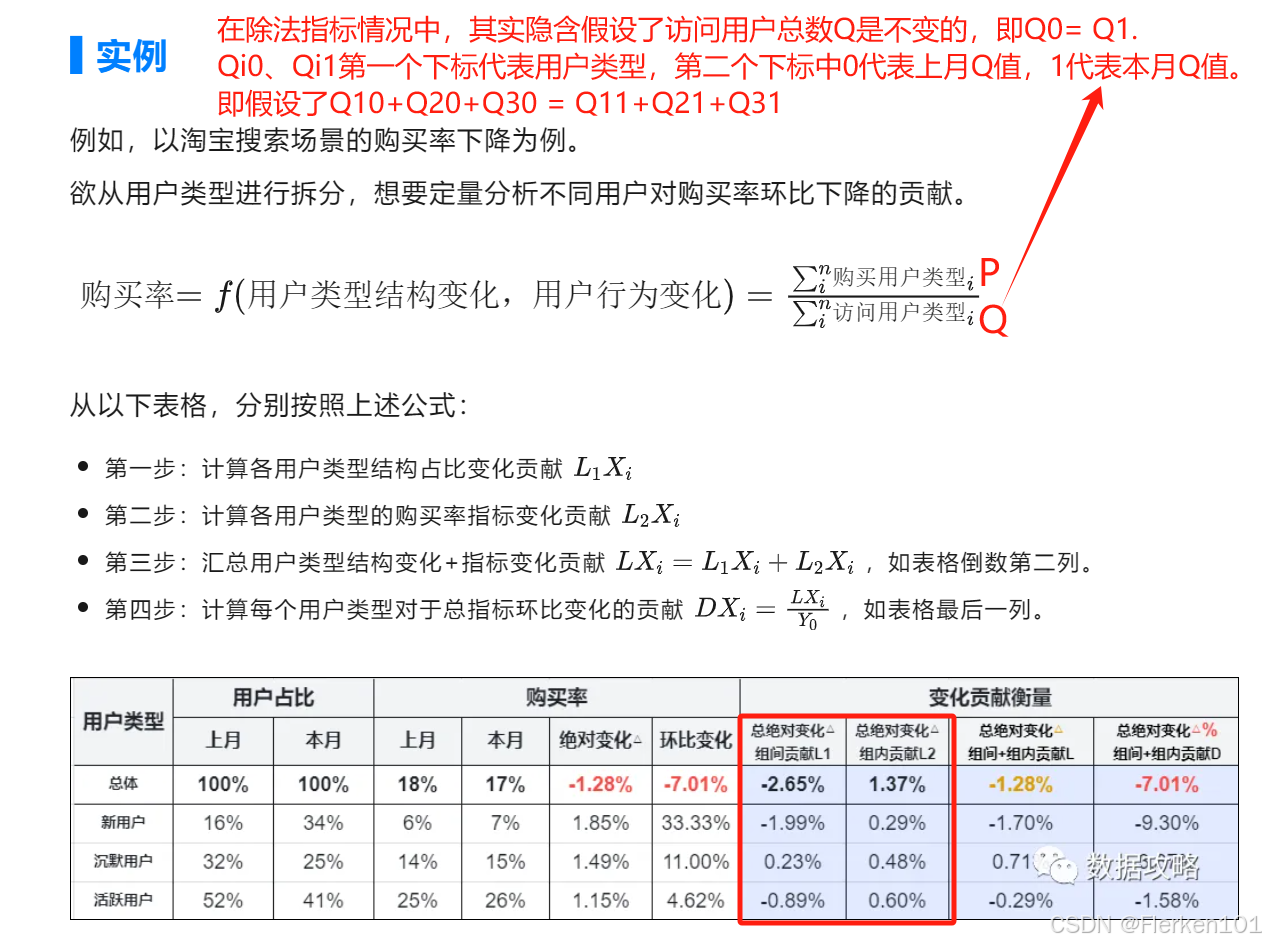
4.8.3 除法型指标拆解
最后看:『指标异动』贡献度实操计算中,5个常见QA!——六哥





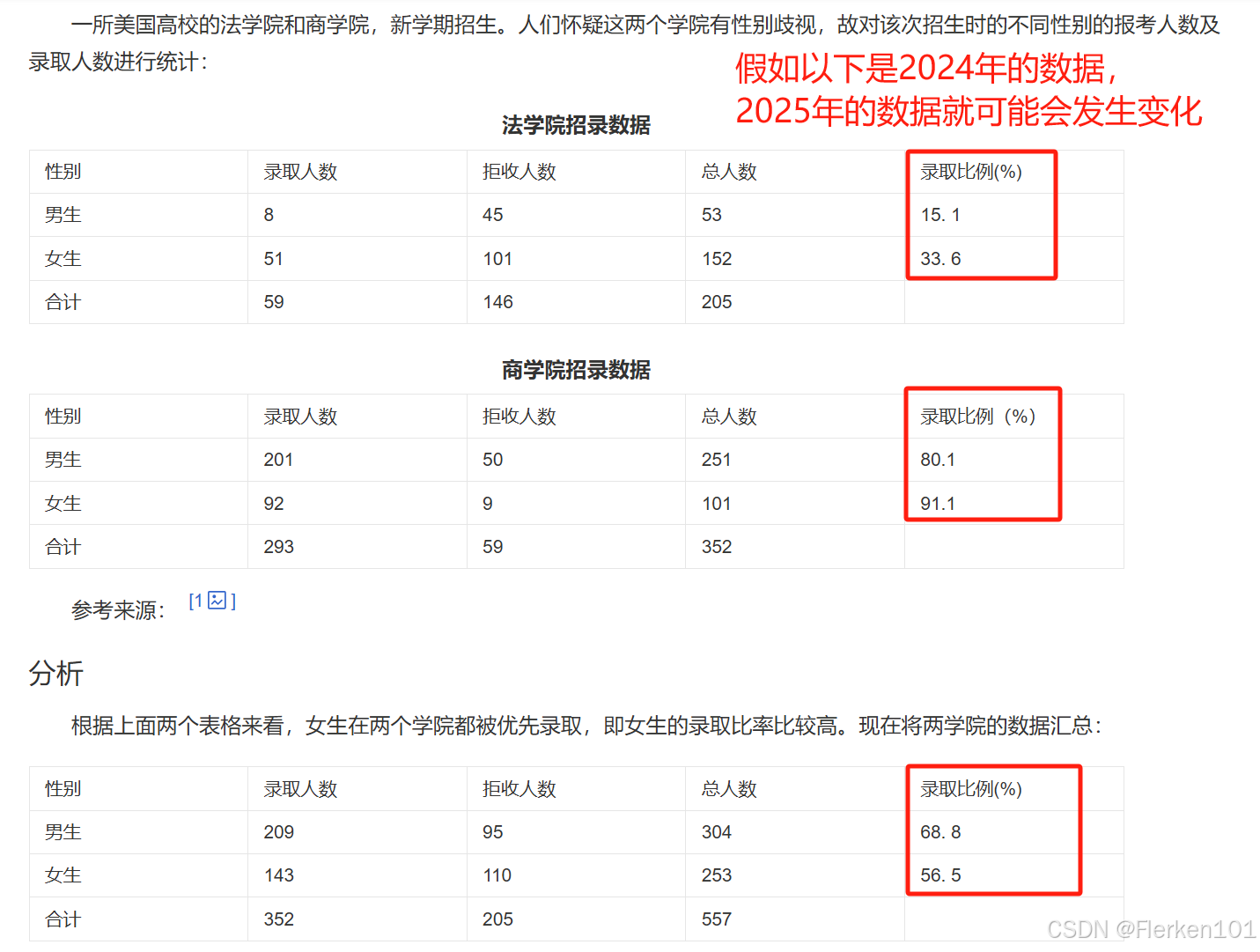
辛普森悖论说明:简单地将分组数据相加汇总,是不能反映真实情况的。
无论什么年份的数据,都要避免辛普森悖论。
即都不能将第三张表中,相加汇总后,男生和女生录取比例的大小对比情况,等价于上面两张不同学院的表中,男生和女生录取比例的大小对比情况。
(1)这里的除法型指标拆解,与上面的辛普森悖论问题的相同之处:
①计算某个除法型指标(录取比例)时,都要先考虑 某个维度下(性别),不同维度值(男性和女性)中数量占比大小(男性数量占比 和 女性数量占比);
②再计算在该维度下(性别),不同维度值里(男性和女性)该除法型指标的大小(男性录取比例 和 女性录取比例)。
除法型指标拆解的案例中,由于不同用户类型下的用户数量占比不同,为了避免辛普森悖论,也 没有/不能 将三种不同用户类型下,相加汇总后求出来的购买率,直接等价于 不同用户类型下的购买率。
(2)这里的除法型指标拆解,与上面的辛普森悖论问题的不同之处:
①上面的辛普森悖论,实际上将 除法型指标(录取比例),拆解到了两个维度,性别和学院。
所以不仅仅是 男性录取比例 和 女性录取比例,还是 法学院的男性录取比例 和 法学院的女性录取比例,商学院的男性录取比例 和 商学院的女性录取比例。
②而这里的除法型指标拆解,只会将除法型指标,进行一种维度下的拆解,并不会拆解到多个维度下。
即:如果还是计算录取比例,那么只会计算 男性录取比例 和 女性录取比例(拆解到性别维度下的不同维度值里),或者计算 法学院的录取比例 和 商学院的录取比例(拆解到学院维度下的不同维度值里)。
案例中,计算的是购买率,并且将购买率拆解到了用户类型维度下的不同维度值中,计算了新用户购买率、沉默用户购买率、活跃用户购买率。
【其将拆解到的用户类型维度下的,不同维度值,成为各构成要素。】




4.8.4 一些建议


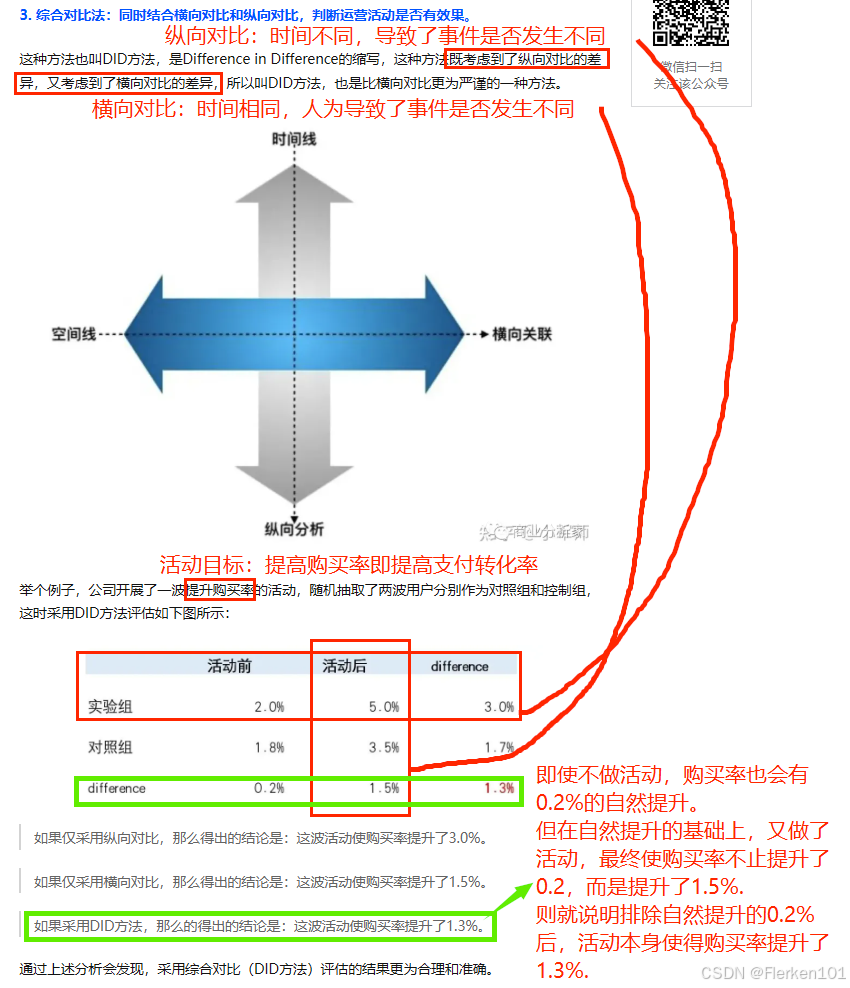
4.9 效果评估——评估运营活动的效果


4.9.1 六大基础评估法

2.与横向对比法,以及3.综合对比法 相类似的,可以消除周末或节假日的时间影响,更准确地进行活动前后的对比的方法,是 4.9.2 单位权重曲线法。

4.9.2 单位权重曲线法(消除其它因素影响,量化差异)
公式不对:如何评估运营活动的效果?系列二:单位权重曲线法——小军师


除了单位权重曲线法,4.9.1的2.横向对比法和3.综合对比法,也可以消除周末或节假日的时间影响,更准确地进行活动前后的对比。


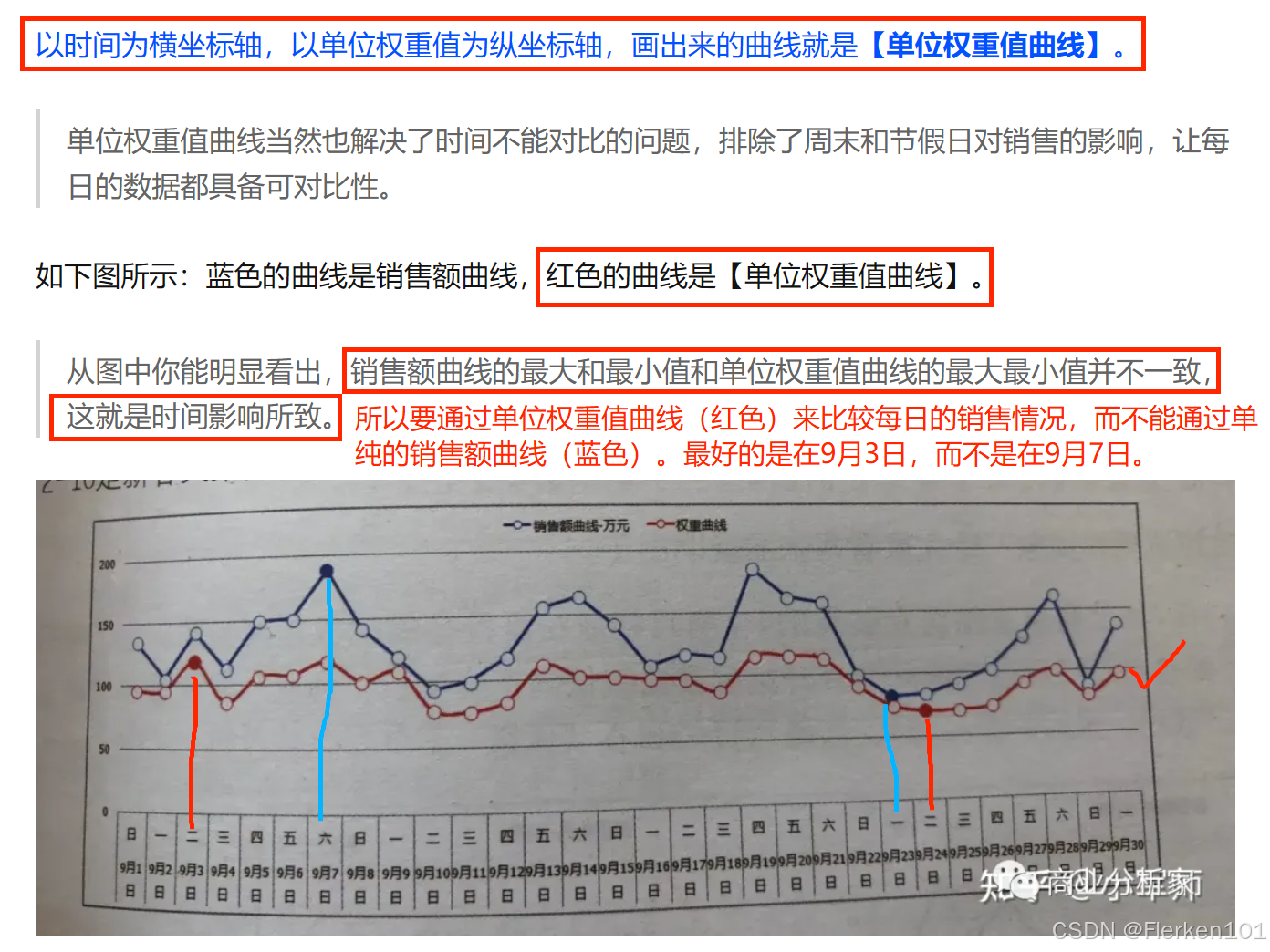
销售额曲线可以是一条波动幅度比较大的曲线,而权重曲线则显得相对平稳。
如果一个零售店铺的每日销售额是绝对服从周权重指数的规律,那对应的权重曲线则将是一条绝对的水平直线,而这种情况是根本不可能出现的。
正常的权重曲线是一条围绕某个值变化的曲线,正是这种变化给我们提供了去洞察某些营运现象的可能。
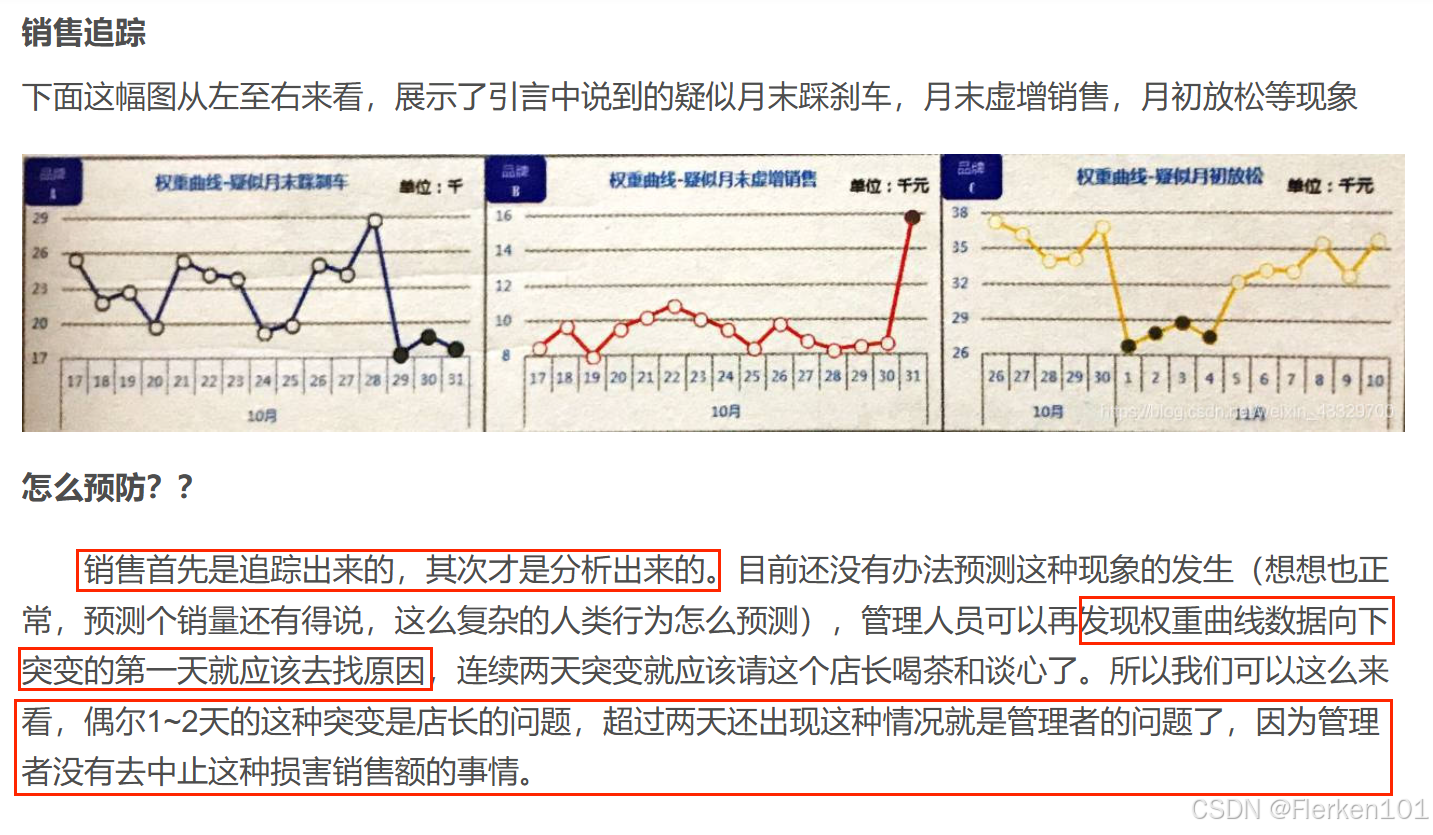


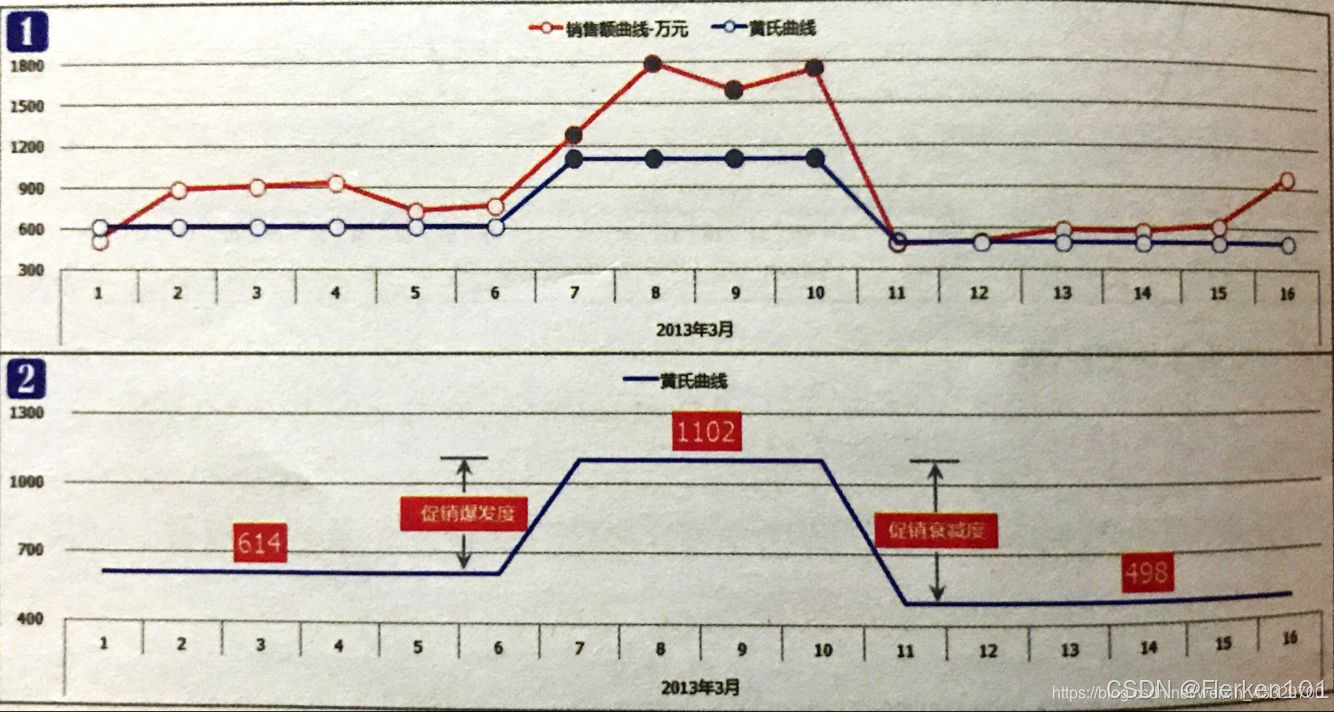
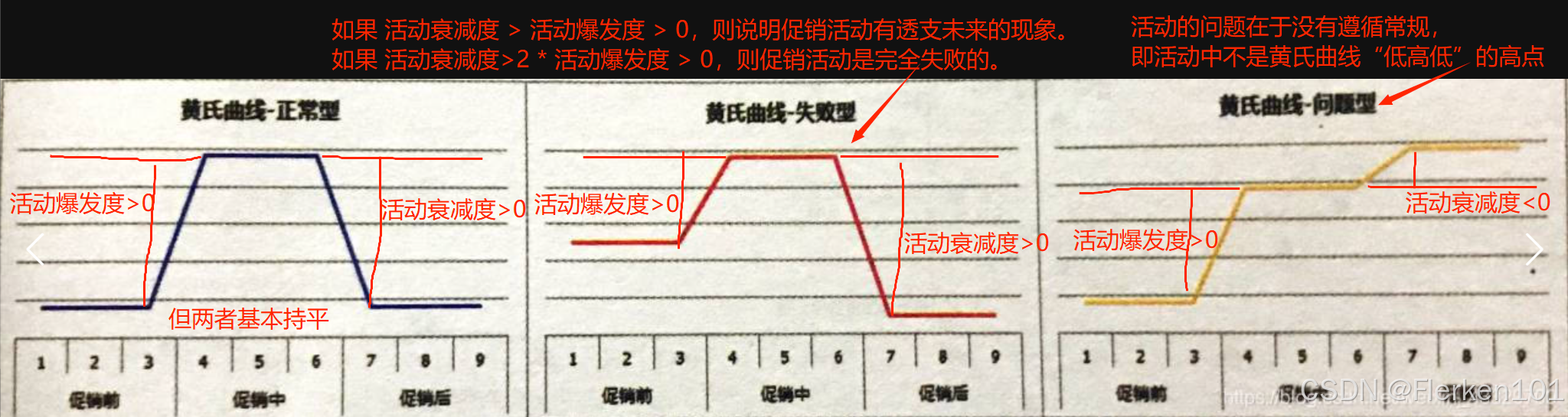
下图是某店铺三八妇女节促销活动的销售额曲线情况(整半个多月),把权重曲线换一种表达方式——黄氏曲线。
黄氏曲线为权重曲线中,同时间段内,单位权重值的平均值。
促销前、促销后的周期一般取7天,特殊情况例外。黄氏曲线只是和相邻的时期对比,所以时效性和可对比性都很强。
使用黄氏曲线时一定要注意是“突发”状态,要有非常清晰的时间节点、非常明确的时间信息状态才可以使用。
即某个时间段的前、中、后三个阶段,每个阶段单位权重值的平均值要有非常显著的差异。
建议同时画出权重曲线(即单位权重值曲线)和黄氏曲线。
另外,有可能在活动促销的同时,还有诸如新品上市等其他因素的作用,也增加了一部分活动销售额。
最终导致每日销售额单位权重值的权重曲线中,包含了不只有活动这一影响因素。虽然黄氏曲线的处理方法已经尽量降低了其他因素的影响度(如节假日),但还是需要综合分析。
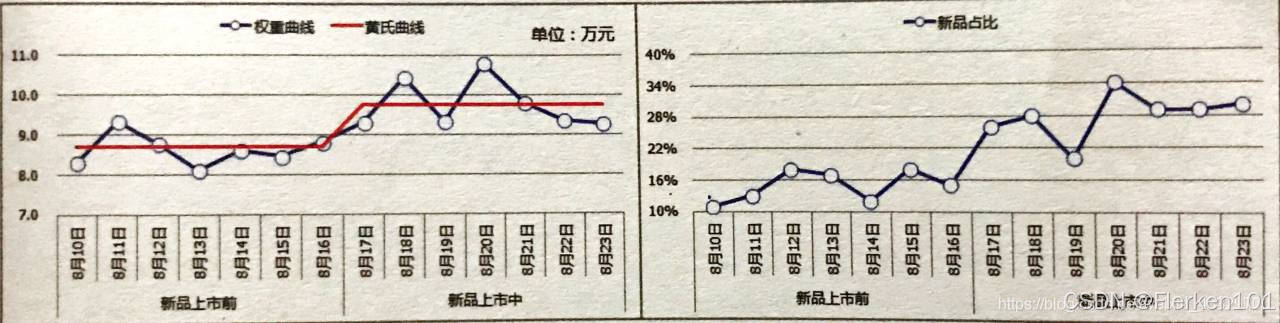

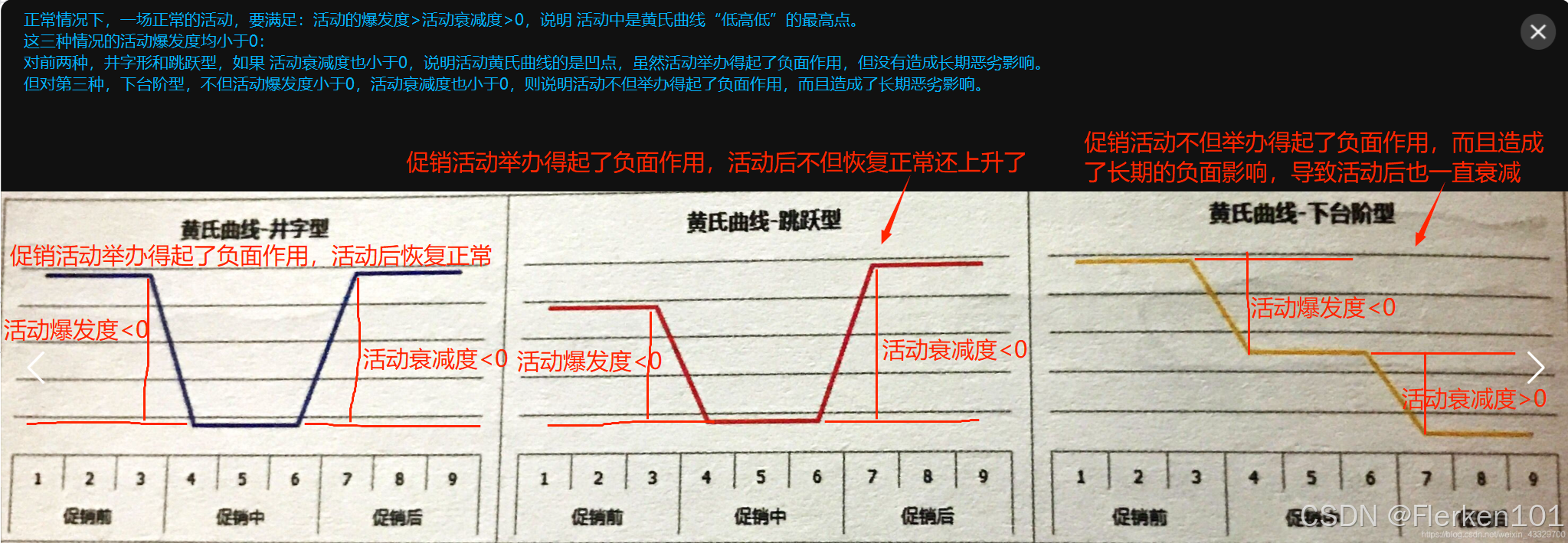
第二种失败型,就像一些软文促销、9.9 训练营、标题党等,短时间内吸引了大量用户购买(活动爆发度>0);
促销期结束后因为质量原因导致口碑下降,一下子把品牌搞坏了(活动衰减度>0),呈现比促销前还差劲的销量(活动衰减度>活动爆发度>0)也就不足为奇了,相当于进行了透支后期销售的促销活动。
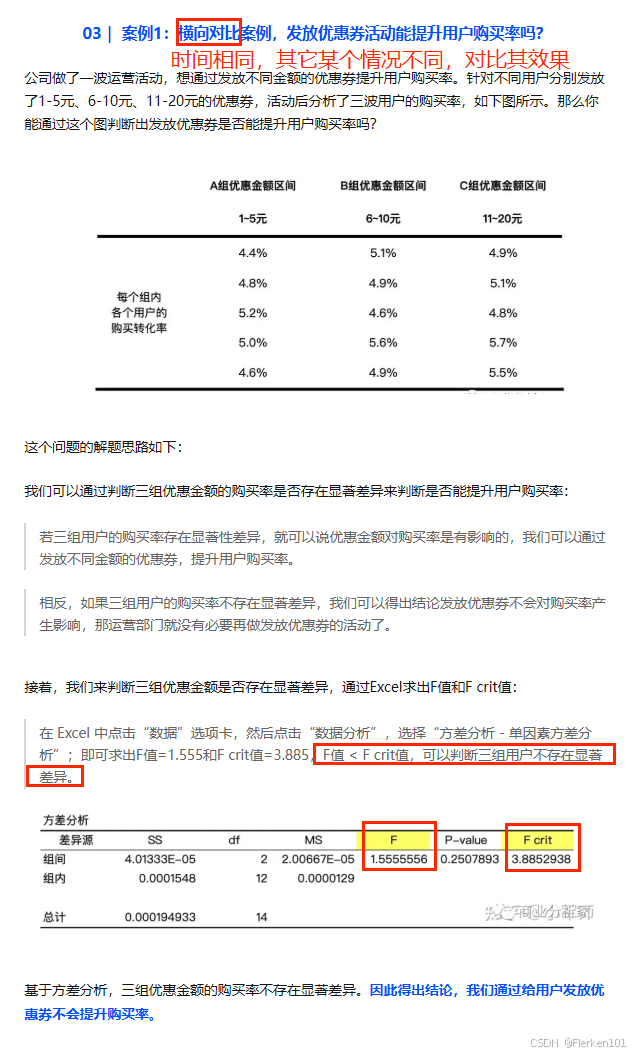
4.9.3 方差分析法(检验差异是否显著)

一般情况下:
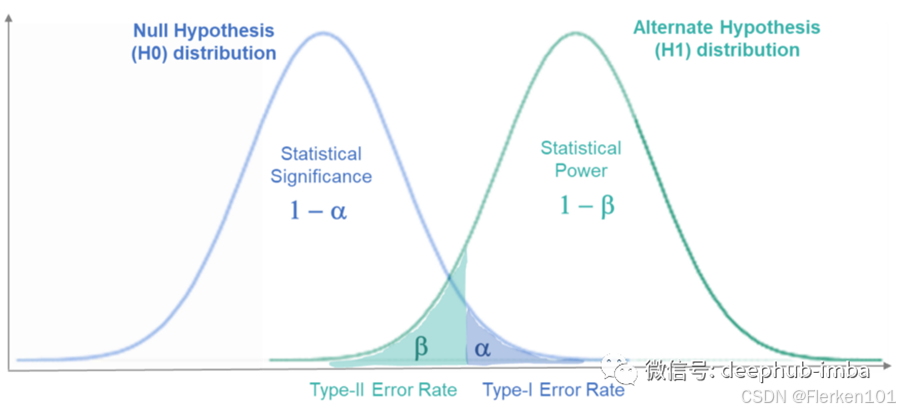
原假设H0是两个均值之间没有显著差异(是原先的大家持有、公认观点,也是现在被挑战但同时也被保护起来的观点);
备择假设Ha是两个均值之间差异显著(新的观点,要去挑战原假设的观点)。
在犯拒真错误的概率为5%的情况下,如果p值小于0.05,代表在原来的观点下,本来基本不会发生的事件(发生可能性为p值的事件),而现在已经发生了(用来进行第一类假设检验的,新事件的数据一般都是支持备择假设的,去看这样的新事件是否能通过统计学的检验,具备统计学的意义)。所以应该拒绝原假设,即代表接受备择假设,说明两个均值之间存在显著差异。
如果F值 > 临界值F cirt(临界值是根据P值计算的,F值大于 临界值F cirt,也就代表了p值小于0.05),说明F值落在了原假设中等号成立情况下的拒绝域中,同样也说明,对现在的数据(支持备择假设Ha),按原来的观点,基本不会发生的事件已经100%发生了,那么就可以拒绝原假设,接受备择假设,即认为差异是显著的。

而如果在犯拒真错误的概率为5%的情况下,不能拒绝原假设,即是上面“拒绝了H0”的反面事件,其代表的概率密度曲线下的面积很大1-α,本身就很可能发生。不能就此说明“H0到底是假的还是真的”,对应地,不能就此说明“Ha/H1到底是假的还是真的”。
所以,不能拒绝原假设H0:下面①②同时成立
①代表推翻原假设H0的证据暂时不足,同时也不能说明“H0到底是假的还是真的”, 以及到底是否要接受原假设H0。
第一类假设检验,不能拒绝原假设H0时,仅能知道由于证据不足,原假设H0暂时还不会被推翻。
对于到底是否要接受原假设H0,应该再进行第二类假设检验(即只控制发生第二类取伪错误概率大小 的假设检验)。
即在第二类假设检验中,要考虑到可能会发生第二类取伪错误,因此也还要先降低取伪错误发生的概率β,再进行检验和判断。②但并不代表备择假设Ha一定是错的,即也不能就此说明“Ha到底是假的还是真的”
即也并不能得出两个均值之间的差异不显著的结论。
(此时,对于备择假设Ha,是不完全支持、不完全推翻的态度,而之所以有这种不确定的态度,也是因为证据不足。)


4.10 费米测算
逻辑推理篇:数据分析最爱用的估算法:费米估计——Soyoger

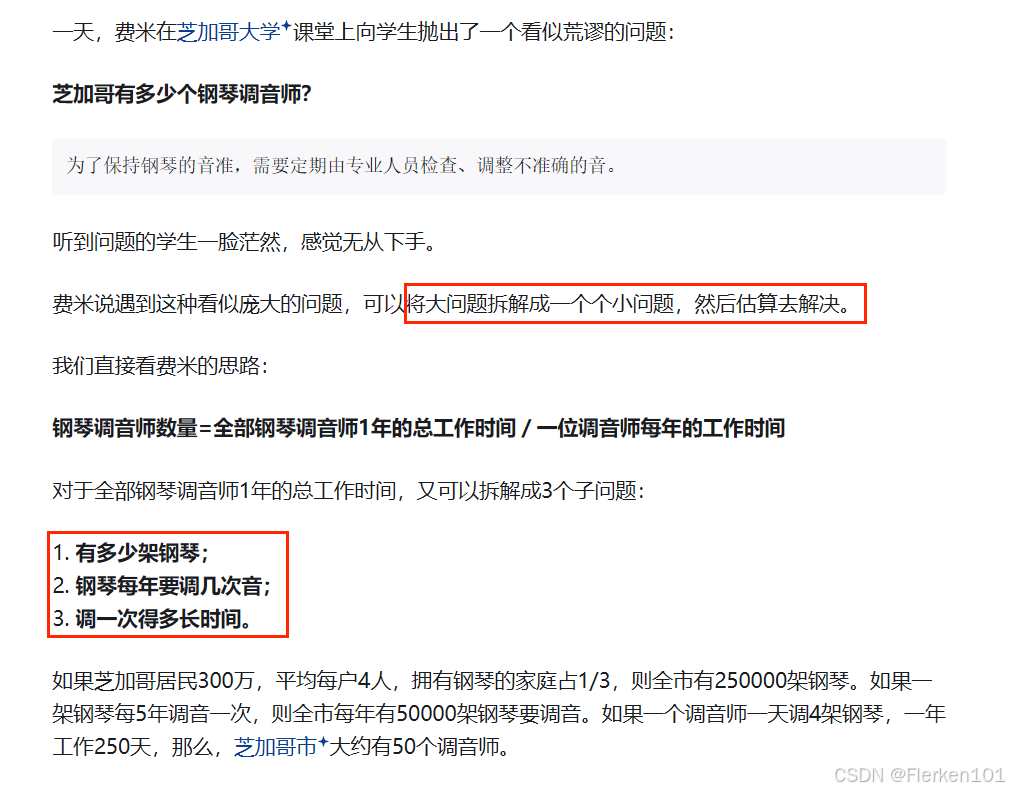
明确需求:全市有250000架钢琴。如果一架钢琴每5年调音一次,则全市每年有50000架钢琴要调音。
- 首先明确计算每年调音钢琴数量的原理:
- 已知钢琴的总数以及每架钢琴调音的周期,要求每年需要调音的钢琴数量。可以把钢琴总数按照调音周期进行平均分配到每一年。
- 这里钢琴总数是250000架,每架钢琴每5年调音一次。
- 然后进行计算:
- 每年需要调音的钢琴数量 = 钢琴总数÷调音周期。
- 已知钢琴总数为250000架,调音周期是5年,那么每年需要调音的钢琴数量为250000/5 = 50000(架)。



4.10.1 一个正常成年人有多少根头发?
-
查找资料数据:一般来说,每平方厘米头皮上约有 100 - 150 根头发,成年人头皮面积大约在 500 - 600 平方厘米。
-
分析过程:我们取中间值,每平方厘米 125 根头发,头皮面积 550 平方厘米。
则头发数量 = 每平方厘米头发数×头皮面积,即 (125×550 = 68750) 根。 -
结果:一个正常成年人大约有 68750 根头发。
4.10.2 在没有其他公开资料,你所在城市有多少个加油站?
-
假设资料数据:假设所在城市人口 500 万,平均每 10 人拥有 1 辆车,一辆车平均 10 天加一次油,一个加油站平均每天能为 500 辆车服务。
-
分析过程:
- 城市车辆数 = 城市人口÷每 10 人拥有车辆数,即 (5000000÷10 = 500000) 辆。
- 每天需要加油的车辆数 = 城市车辆数÷加油周期(天),即 (500000÷10 = 50000) 辆。
- 加油站数量 = 每天需要加油的车辆数÷一个加油站每天服务车辆数,即 (50000÷500 = 100) 个。
-
结果:所在城市大约有 100 个加油站。
4.10.3 地铁口的煎饼摊子一年能卖出多少个煎饼?
(1)算法一
-
查找资料数据:假设地铁口每天人流量 3000 人,购买煎饼的比例为 5%,煎饼摊一年营业 300 天。
-
分析过程:
- 每天卖出煎饼数 = 每天人流量×购买煎饼比例,即 (3000×5%= 150) 个。
- 一年卖出煎饼数 = 每天卖出煎饼数×一年营业天数,即 (150×300 = 45000) 个。
-
结果:地铁口的煎饼摊子一年大约能卖出 45000 个煎饼。
以下是使用费米估算法估算北京地铁口煎饼摊子一年卖出煎饼数量的过程:
(2)算法二
① 确定基本假设
- 营业时间:假设地铁口的煎饼摊子每天营业10小时,一般早高峰和晚高峰是销售高峰期,其他时间段客流量相对较少。
- 销售速度
- 高峰时段:早高峰(7-9点)和晚高峰(17-19点)这4个小时内,平均每3分钟能卖出1个煎饼,那么高峰时段每小时能卖出20个煎饼,4个小时共卖出80个煎饼。
- 非高峰时段:其余6个小时,平均每6分钟卖出1个煎饼,每小时能卖出10个煎饼,6个小时共卖出60个煎饼。
- 全年营业天数:假设一年365天,除去春节等法定节假日以及恶劣天气等因素休息15天,实际营业天数为350天。
②计算过程
- 每天卖出的煎饼数量 = 高峰时段卖出的数量 + 非高峰时段卖出的数量,即80 + 60 = 140个。
- 一年卖出的煎饼数量 = 每天卖出的煎饼数量×全年营业天数,即140×350 = 49000个。
所以,在北京,一个地铁口的煎饼摊子一年大约能卖出49000个煎饼。
当然,这只是一个大致的估算,实际数量可能会因地铁口的人流量、周边竞争情况、煎饼的口味和价格等因素而有所不同。
4.10.4 一辆公交车里能装下多少个乒乓球?
-
查找资料数据:假设公交车内部空间长 10 米、宽 2.5 米、高 2 米,乒乓球直径 4 厘米(0.04 米)。
-
分析过程:
- 公交车内部体积 = 长×宽×高,即 10×2.5×2 = 50 立方米。
- 一个乒乓球体积 = 4/3 * Π * r^3 = 3.35×10^(-5)立方米。
- 能装乒乓球数量 = 公交车内部体积 ÷ 一个乒乓球体积,即 50 ÷ (3.35×10^(-5)) = 1.5×10^6个。
- (这里忽略了乒乓球之间的空隙等因素)。
-
结果:一辆公交车里大约能装下 1.5×10^6 个乒乓球。
4.10.5 一个人一生会长出多长的手指甲?
-
查找资料数据:手指甲每个月大约生长 0.3 厘米,假设一个人寿命 80 年。
-
分析过程:
- 一年有 12 个月,80 年的月数 = 80×12 = 960 个月。
- 一个人一生手指甲生长长度 = 每个月生长长度×总月数,即 (0.3×960 = 288) 厘米。
-
结果:一个人一生会长出大约 288 厘米长的手指甲。
4.10.6 估算你所在城市有多少家奶茶店?
-
查找资料数据:北京常住人口约2100万。假设每天有5%的人有购买奶茶需求。一家普通奶茶店平均每天能卖出200杯奶茶(综合考虑不同规模、地段店铺经营情况给出的大致数值)。
-
分析过程:
- 每天喝奶茶的人数 = 城市人口×每天喝奶茶比例,即 21000000×5% = 1050000 人。
- 奶茶店数量 = 每天喝奶茶的人数 ÷ 一家奶茶店每天卖出奶茶杯数,即 1050000÷200 = 5250家。
-
结果:所在城市大约有 5250 家奶茶店。
不过这只是基于假设和估算的结果,实际情况中,受人口流动、店铺淡旺季、不同区域消费能力差异等因素影响,会与该估算值有所不同。
4.11 使用方法
有一些可以直接用,但多数太宽泛,实际中大多数情况下,要下钻分析到很细小的方面。
比如①商品的SKU,SKU里的颜色
②直播的时间——直播的预告时间、开始日期、时间,结束时间、推流的时间等等
③直播的话术——直播的开场话术、促单话术等等。
所以实际应用中,如果在细化问题上使用,要先深入的总结和变形。

05、常用的数据分析工具

06、淘系电商常用平台
生意参谋:生意参谋
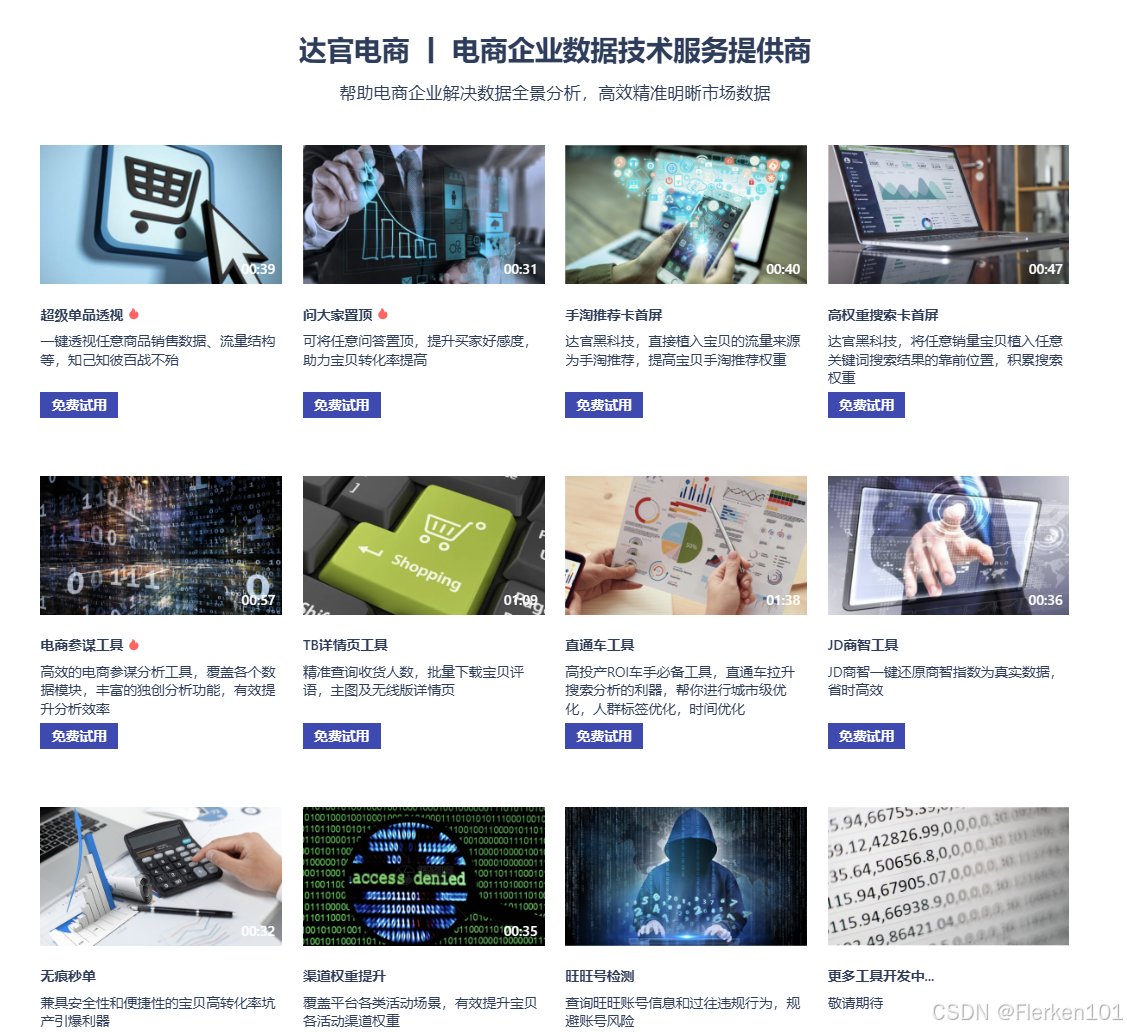
达官电商(七天试用期):达官电商
下载生意参谋上不直接提供的数据。
达摩盘:达摩盘
阿里妈妈-万相台无界版:阿里妈妈-万相台无界版
品牌数据银行:品牌数据银行——官网——核心功能
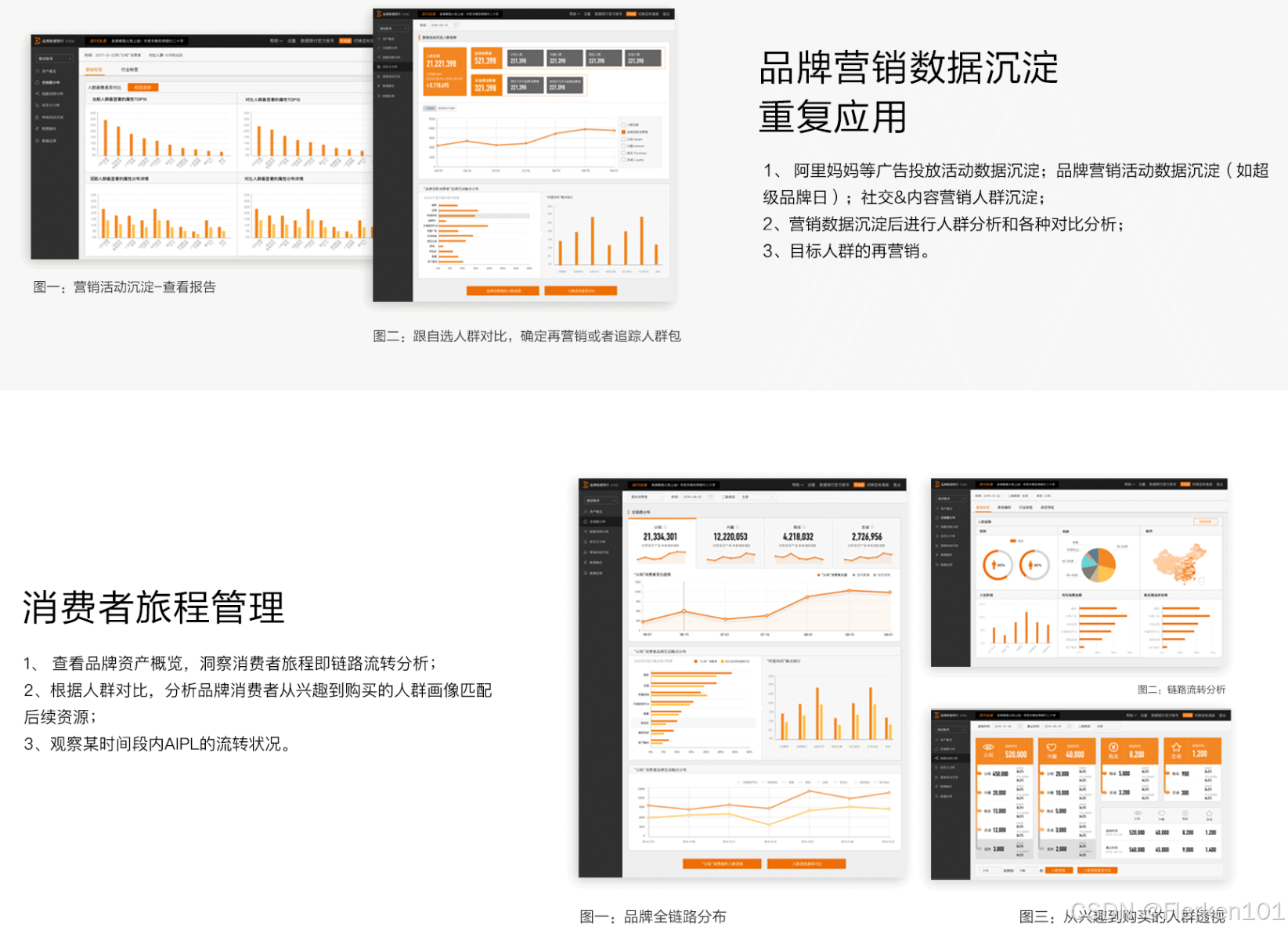
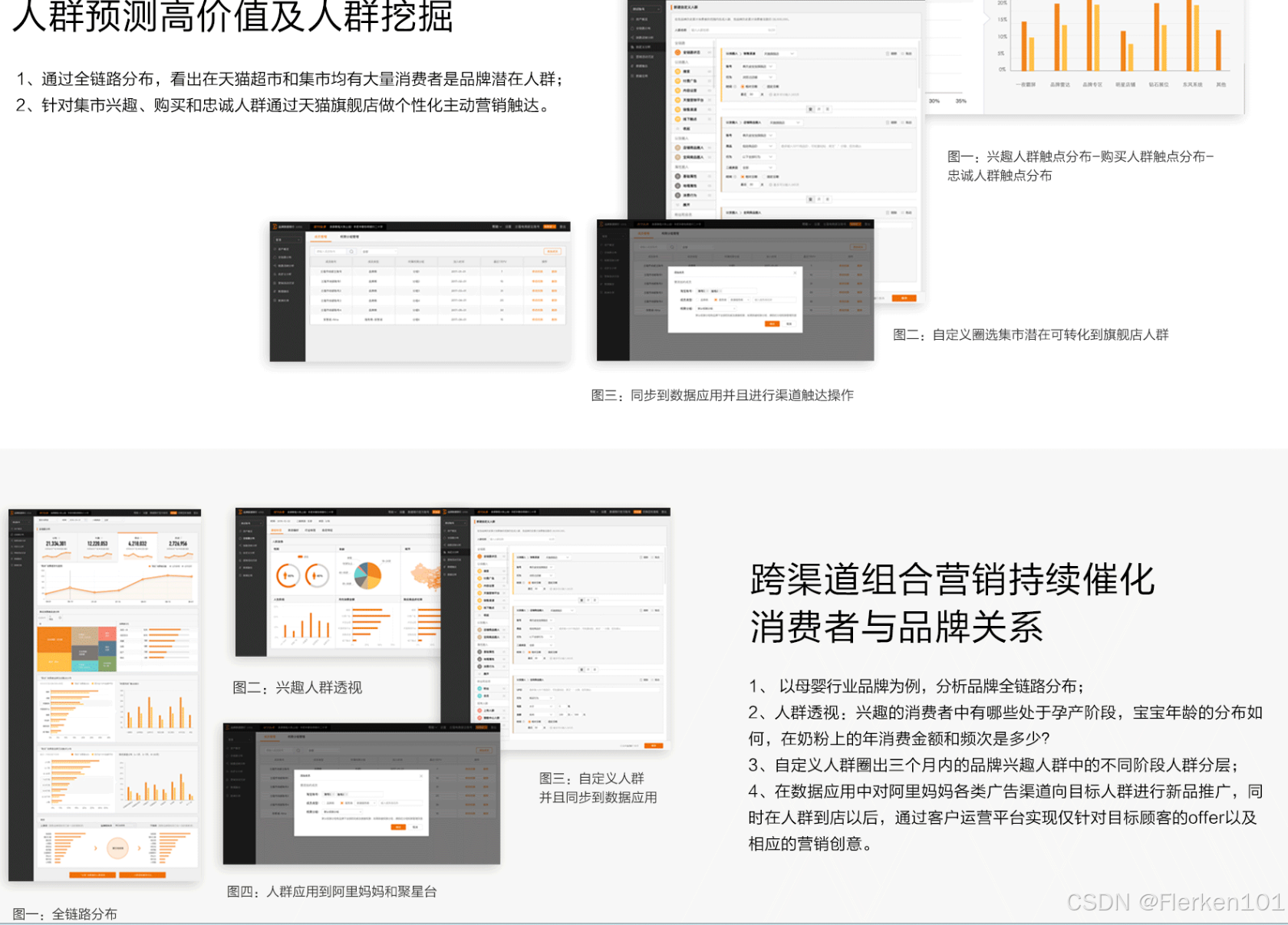
品牌数据引擎,是淘系专门进行消费者全生命周期运营(AIPL)的平台。
品牌数据引擎——入口

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









