







学完了再来回答

三种JVM

我们用的是Sun公司的HotSpot
- JVM的位置
- JVM的体系结构
- 类加载器
- 双亲委派机制
- 沙箱安全机制
- Native
- PC寄存器
- 方法区
- 栈
- 堆
- 三种JVM
- 新生区、老年区
- 永久区
- 堆内存调优
- GC
- 类加载器
- JMM
- 总结
一、 JVM的位置
操作系统之上
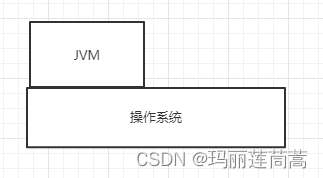
二、 JVM的体系结构
JVM主要由3部分构成:类加载器+jvm运行时数据区+执行引擎
jdk6之前:

jdk8之后:永久代没了,改成了元空间
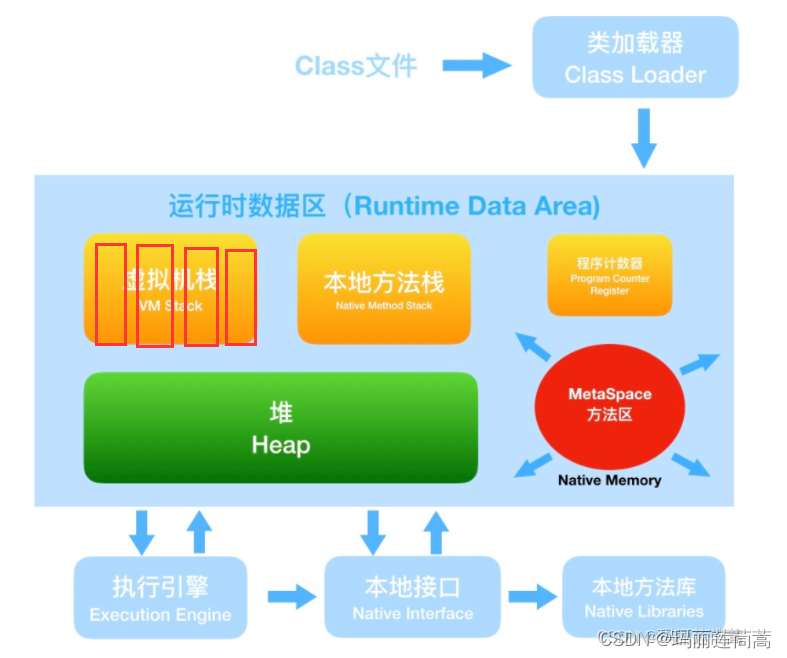
注意:方法区只是一个规范,方法区和永久代、元空间的关系可以理解为接口和实现类的关系。Hotspot在JDK6及之前对方法区的实现是永久代,JDK8改为元空间。把方法区从JVM内存空间搬到了本地内存空间,这样方法区内存大小就不受JVM的限制了,减少了溢出的可能。
JVM中哪部分肯定不存在垃圾回收?
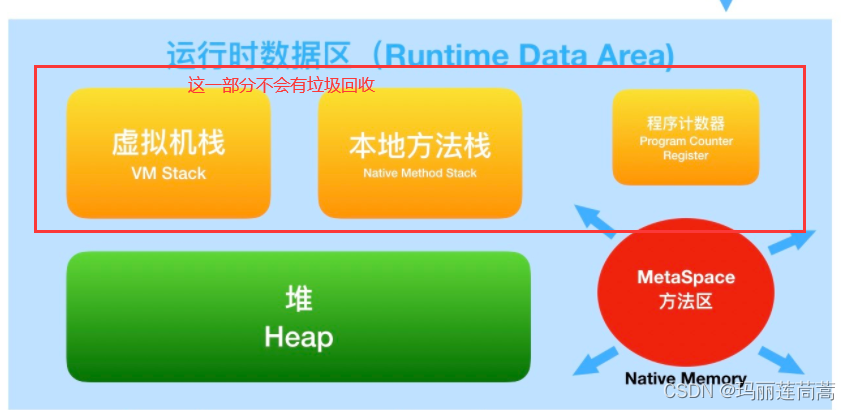
哪部分存在?堆+方法区。方法区是一个特殊的堆。绝大部分都是在堆Heap中。
JVM中哪部分占得内存最大?堆。因为JVM内存调优就是堆调优,肯定堆占了JVM大部分空间。
2.0 类加载器
Class对象new一个示例 和 实例调用getClass方法还原回Class的关系:
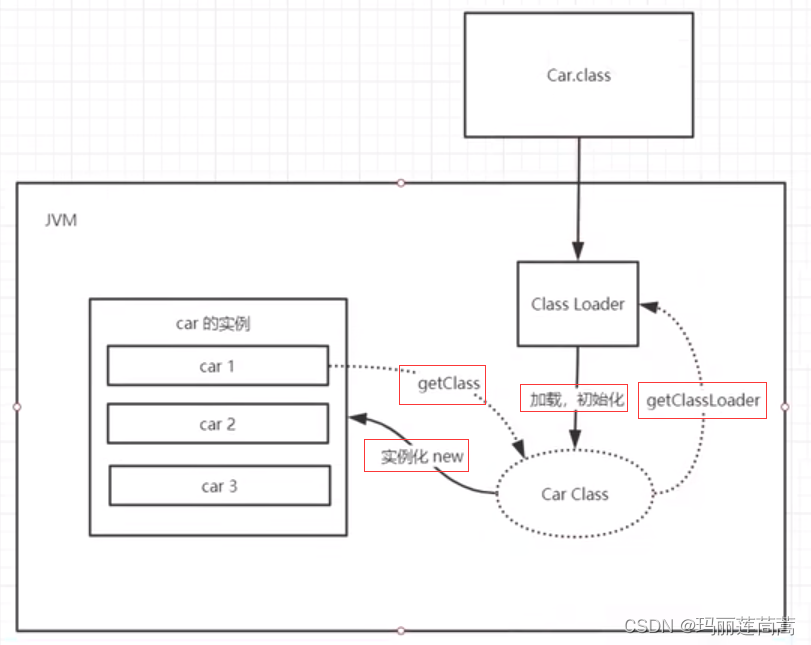
1.1 启动类/根加载器:
根加载器加载的是rt.jar包。
rt.jar包是java的核心jar包。之前学的java的基础(String包、Time包、Math包)都在这里。
路径:jre1.8.0_131\lib\rt.jar
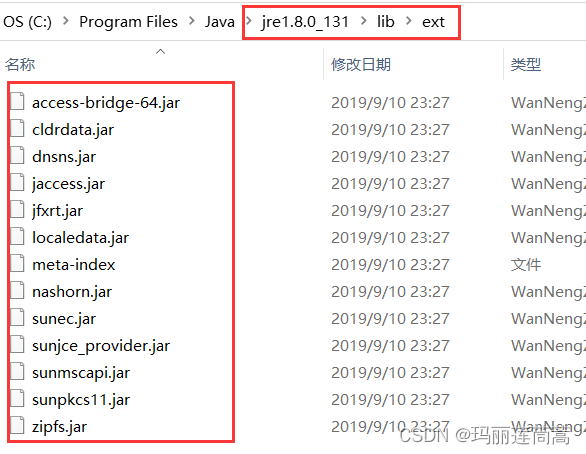
1.2 扩展类加载器
扩展类加载器加载的是jre1.8.0_131\lib\ext路径下的jar包
路径:jre1.8.0_131\lib\ext
1.3 应用程序加载器
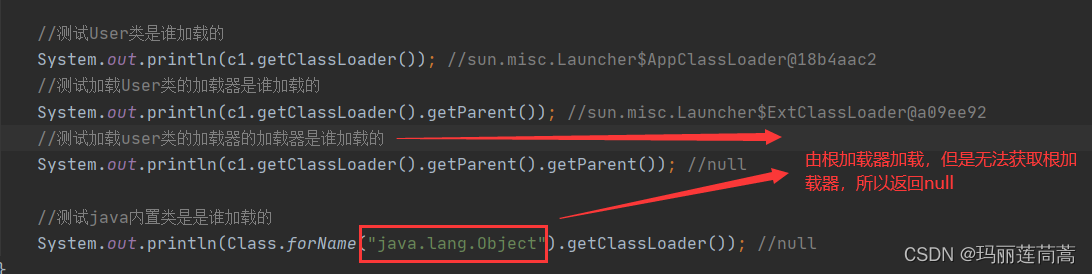
为什么根加载器获取不到?
因为根加载器是用C/C++写的,JVM获取不到(我猜:因为C++写的编译出来的不是.class文件,所以无法在JVM里进行类的加载,所以跟加载器类就获取不到)。
双亲委派机制——保证安全性
如果我们自定义了一个java.lang.String包,可以替换java自带的吗?
不可以! 类加载器收到加载类的请求后,会层层向上委托给父类,一直达到根加载器,根加载器负责查找是否已经加载过了。首先,这个String类是我们自定义的,所以交给应用程序类加载器(先不检查),再向上交给扩展类加载器(先不检查),再向上交给根加载器(检查!),根加载器会发现已经加载过自带的java.lang.String包了,所以自己写的会失效。
如果根加载器没加载过,再交给扩展类加载器去检查,扩展类没加载过,再交给应用程序类加载器。
当然,如果你想改原始的String类也不是不可以。把rt.jar包的String类删了换成你自己的。
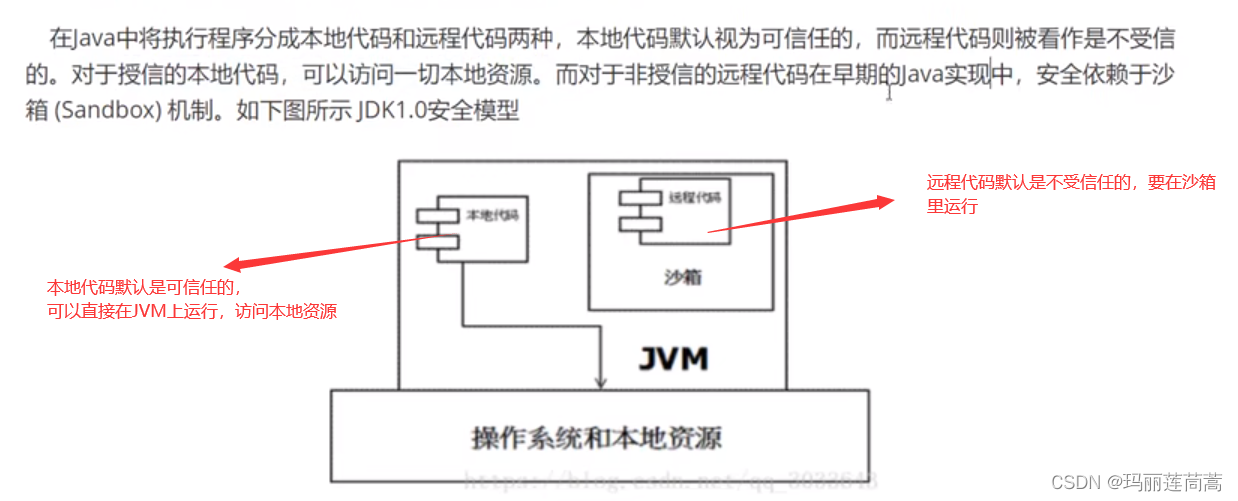
沙箱安全机制——保证安全性
很老的了,jdk1.0时候的了。了解就行
2.1 本地方法栈——native关键字
凡是带着native关键字的,表示java的作用范围达不到了,需要调用底层的C。
↓
一个方法一旦被标为native,他就被登记在本地方法栈(Native Method Stack)里
↓
当我们调用native方法时,先去JVM先去本地方法栈中查看是否登记过
↓
然后去调用相应的JNI(java native interface)
↓
JNI去调用本地方法库
JNI的作用:扩展java语言的使用,融合不同的编程语言(C/C++、Python)为java所用
2.2 PC寄存器(程序计数器)
还用说吗?
2.3 方法区
背过:静态变量(static)、常量(final)、类信息(Class模板 )、运行时的常量池存储在方法区。
一个共享,三个不变。静态变量是被所有对象共享,可以改变。剩下的常量、类模板、运行时常量只要被加载进来了就不会变了。
2.4 栈
1. 栈,又叫栈内存,主管程序的运行。
2. 栈不需要垃圾回收。
3. 栈是线程级的,有几个线程就有几个栈(栈不止一个!但堆只有一个)。栈和线程同生同死,栈和线程有相同的生命周期,当线程创建时,栈里被压入main()方法,当线程结束时,main出栈。
4. 存储的东西:方法+方法的形参+方法里的局部变量
5. 栈顶是什么?栈顶是正在运行的方法呀~
6. 栈里存放的叫栈帧
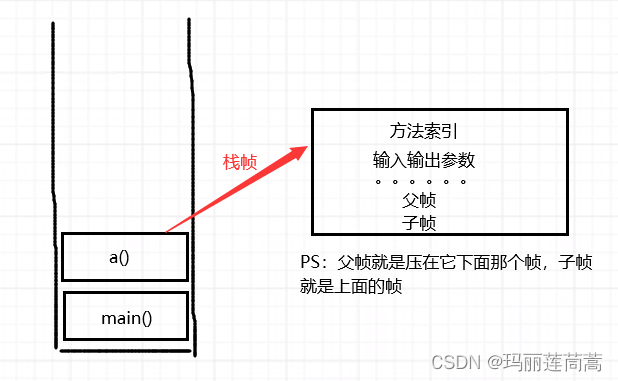
问题(一):为什么main方法最先执行,最后退出?
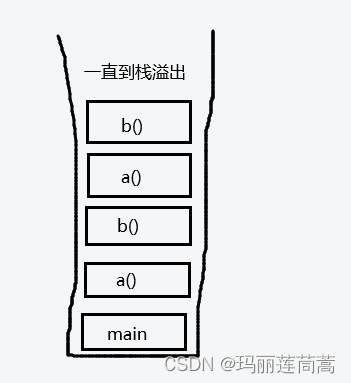
问题(二):如果方法a()调用方法b(),方法b()又调用方法a(),会报什么错误?
StackOverflow栈溢出错误
2.5 堆
1.堆,又叫堆内存
2. 堆只有一个
3. 堆内存的内存大小可以调节(内存调优)
4. 堆存储的是new出来的对象实体
2.5.1 大致划分
大致划分为3部分:
- 新生区
- 伊甸园区:对象new完以后都在伊甸园区
- 幸存区0
- 幸存区1
- 在伊甸园发生GC后,没有被回收的幸存者进入幸存区
- 为什么要有两个幸存区呢?复制算法的时候就有了答案
- 幸存区一个是from一个是to,谁空谁是to
- 养老区
- 永久存储区
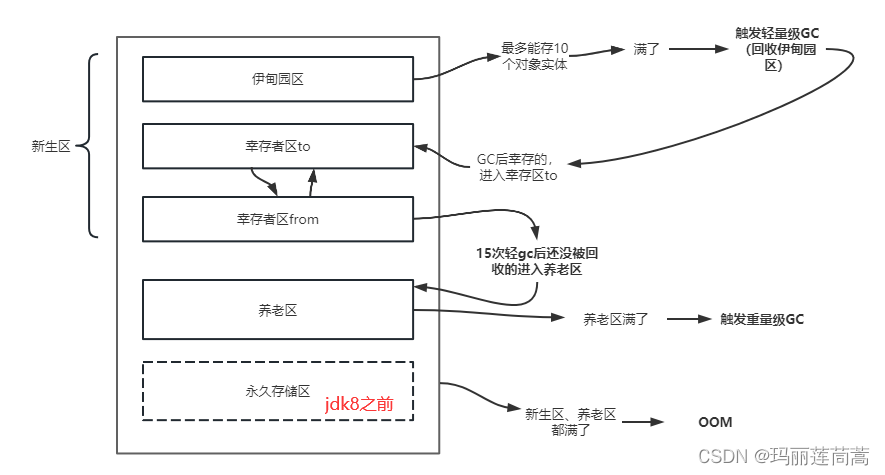
GC垃圾回收,主要发生在堆区,堆区又主要发生在伊甸园区(轻量级GC)和养老区(重量级GC)。
什么样的对象实体会被回收呢?后续不再用了的。调查发现,99%的对象实体只用了一次便不再用了。所以大部分的对象在轻量级GC时就被回收,也就是说大部分活不到养老区(得是那种为程序做了很多贡献的才能养老)
2.5.2 永久区(已无)
- 常驻内存,开启虚拟机时就有,关闭虚拟机时才释放这部分内存。
- 永久区存储的是java运行时环境(jdk自身携带的Class对象,interface元数据),不参与垃圾回收。
- 永久区什么时候会崩呢?(OOM)
- 一个启动类,加载了大量的第三方jar包
- Tomcat部署了太多的应用
- 大量动态生成的反射类不断被加载
- 永久区的变动
- jdk1.6,使用永久区,
- jdk1.7,不想用永久区了,逐渐把一些东西从永久区搬到主机内存中
- jdk1.8,取消永久区,存到元空间中,完全使用主机内存
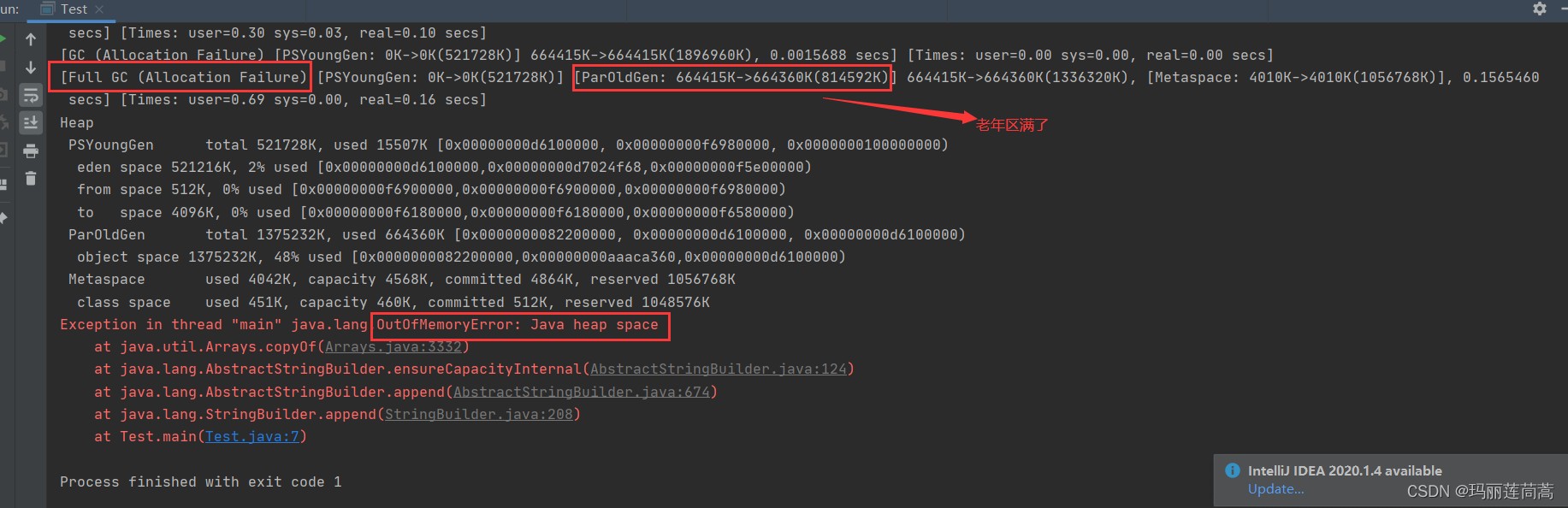
2.5.3 OOM 堆溢出错误
由于堆是由JVM自动管理的,所以一般不会溢出,如果爆出OOM错误,说明程序非常差劲,JVM也管不了了
遇到过OOM吗?发生了OOM怎么处理?
1. 首先先扩大堆内存,看能否消除这个错误
2. 不能的话那就是程序的问题。用内存分析工具看一下哪里出了问题。
如何进行内存调优?
获取一下JVM的最大内存和初始内存:
-Xms2048m -Xms2048m -XX:+PrintGCDetails
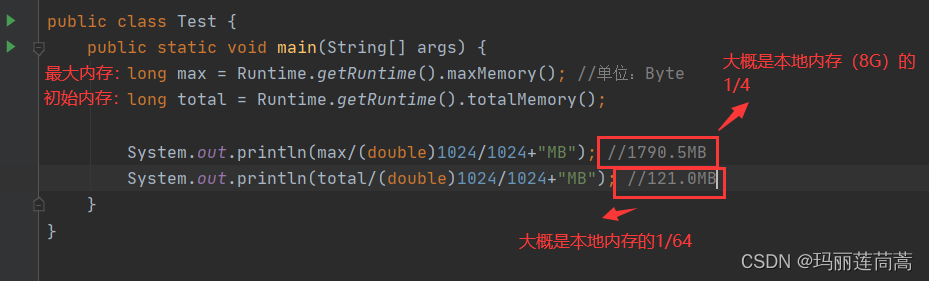
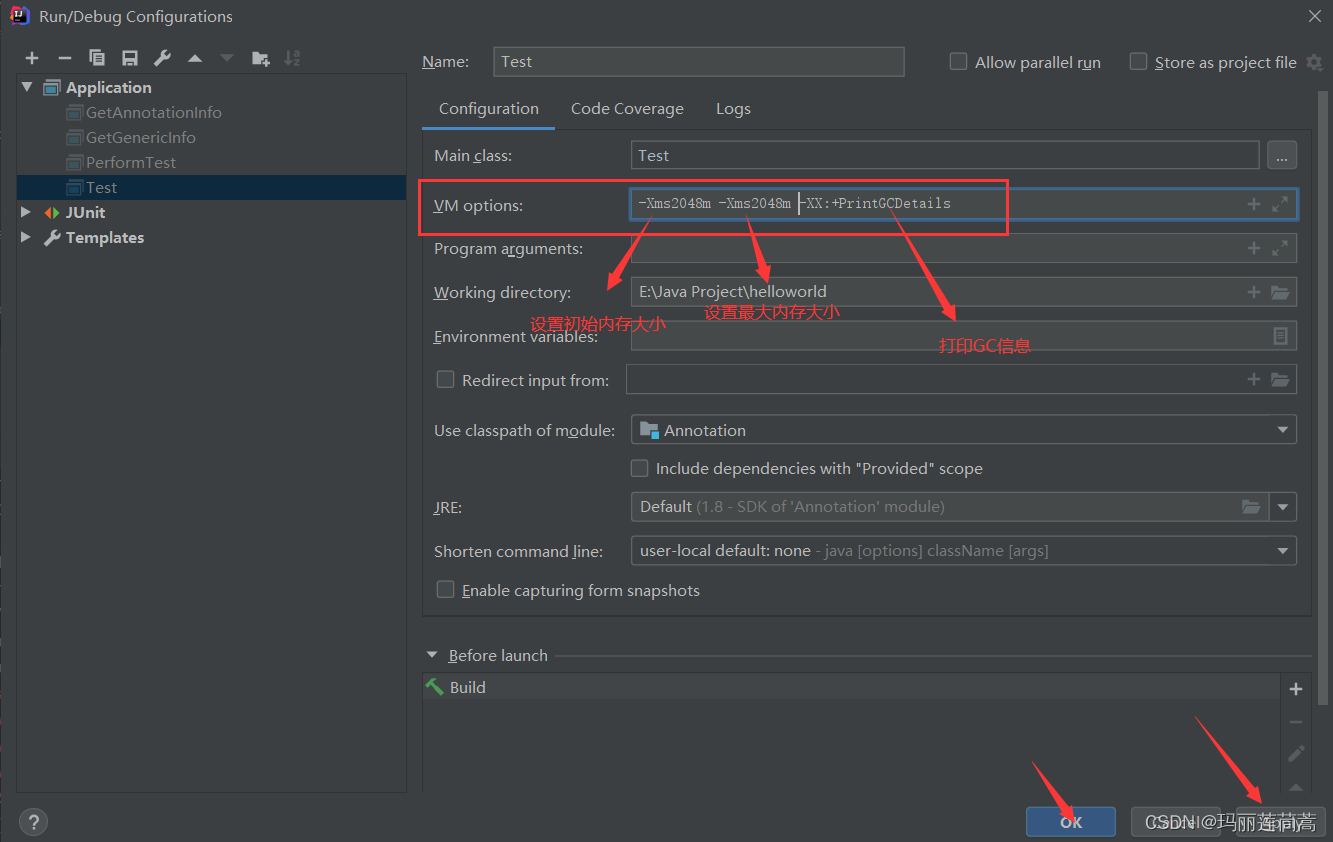
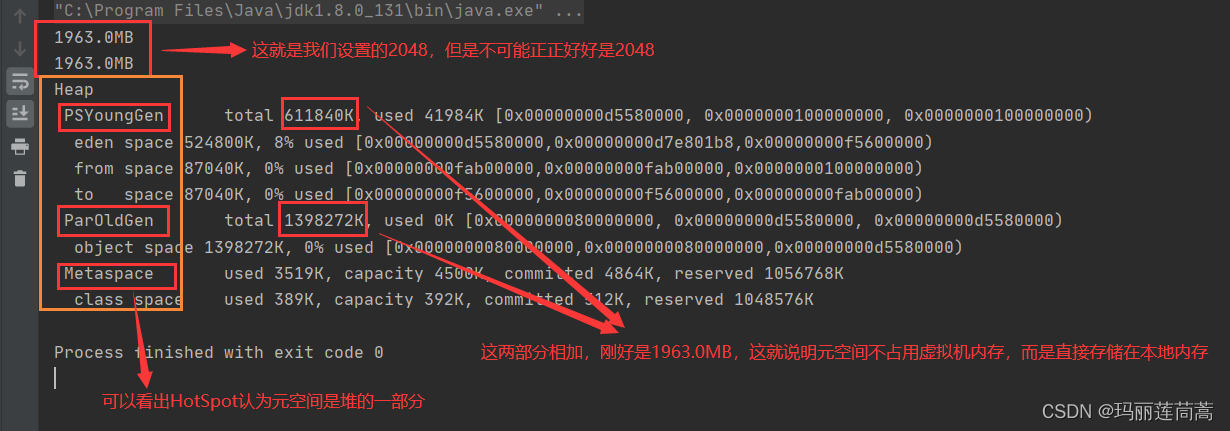
我们先不用内存分析工具,只是通过运行参数“-XX:+PrintGCDetails”观察一下OOM错误
但是我们无从知晓为何出现OOM,所以就要用内存分析工具
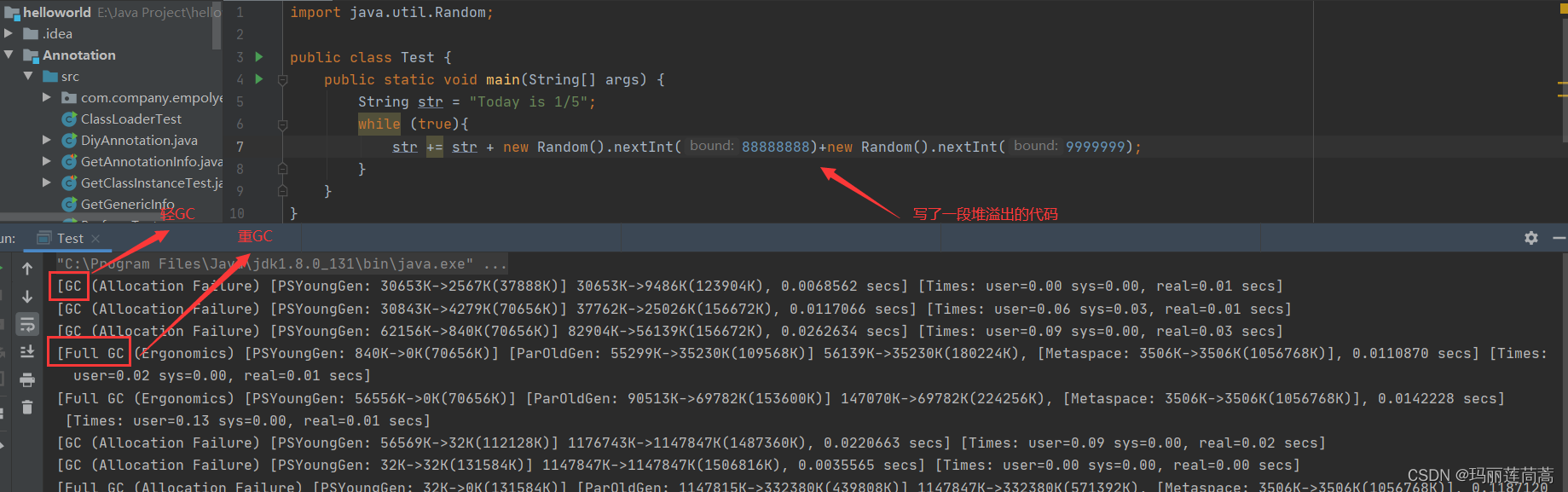
2.5.4 内存分析工具
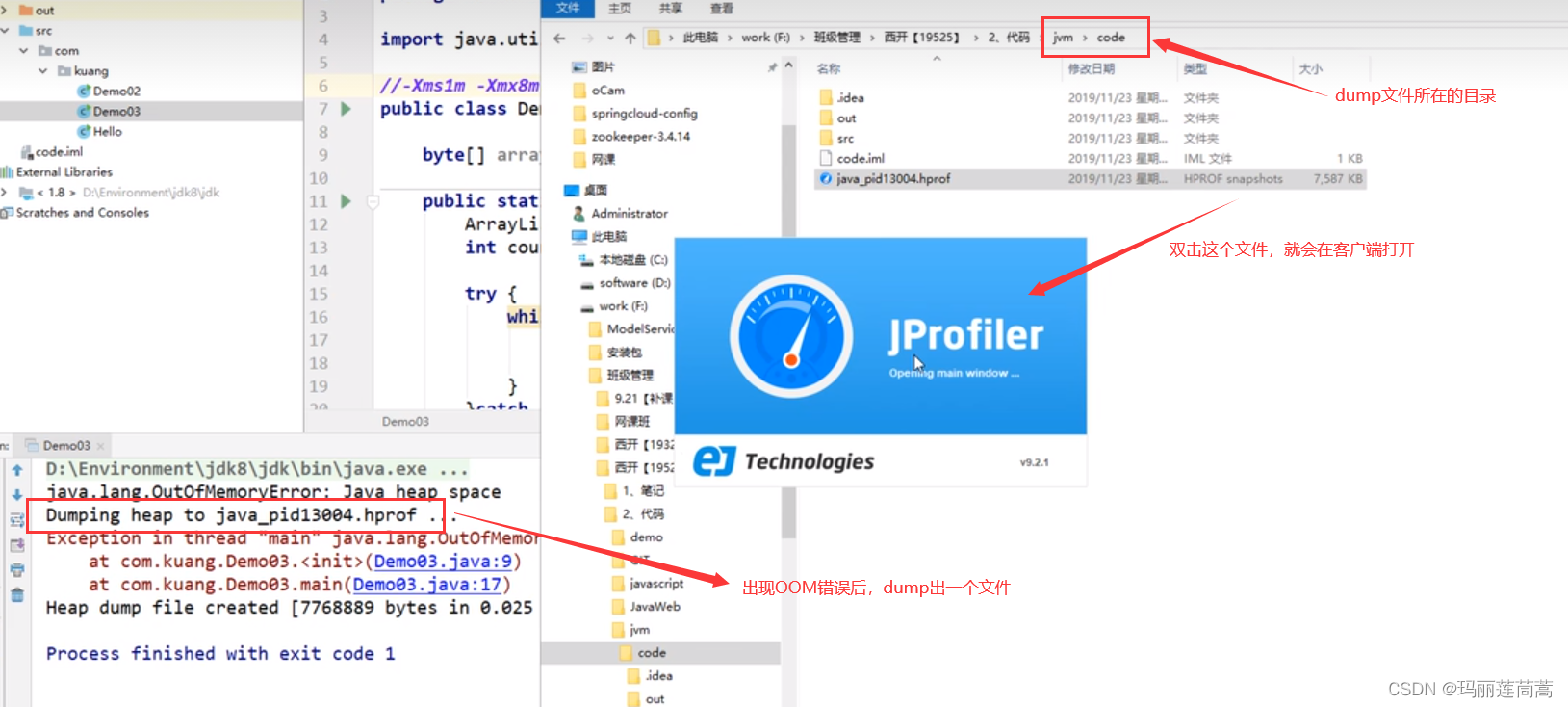
先下一个Windows的客户端,然后再IDEA中下一个它的插件
给程序加一段如下命令

当这个程序出现OOM错误的时候,就会dump出一个文件(内存快照!!)。然后我们在JProfile客户端打开这个文件就能查看程序哪里出现错误了。
调优参数:-XX:+HeapDumpOn+错误名
这个调优参数是用来保存内存快照的,当发生参数指定的错误时,就会Dump下一个文件,保存此刻的内存快照。
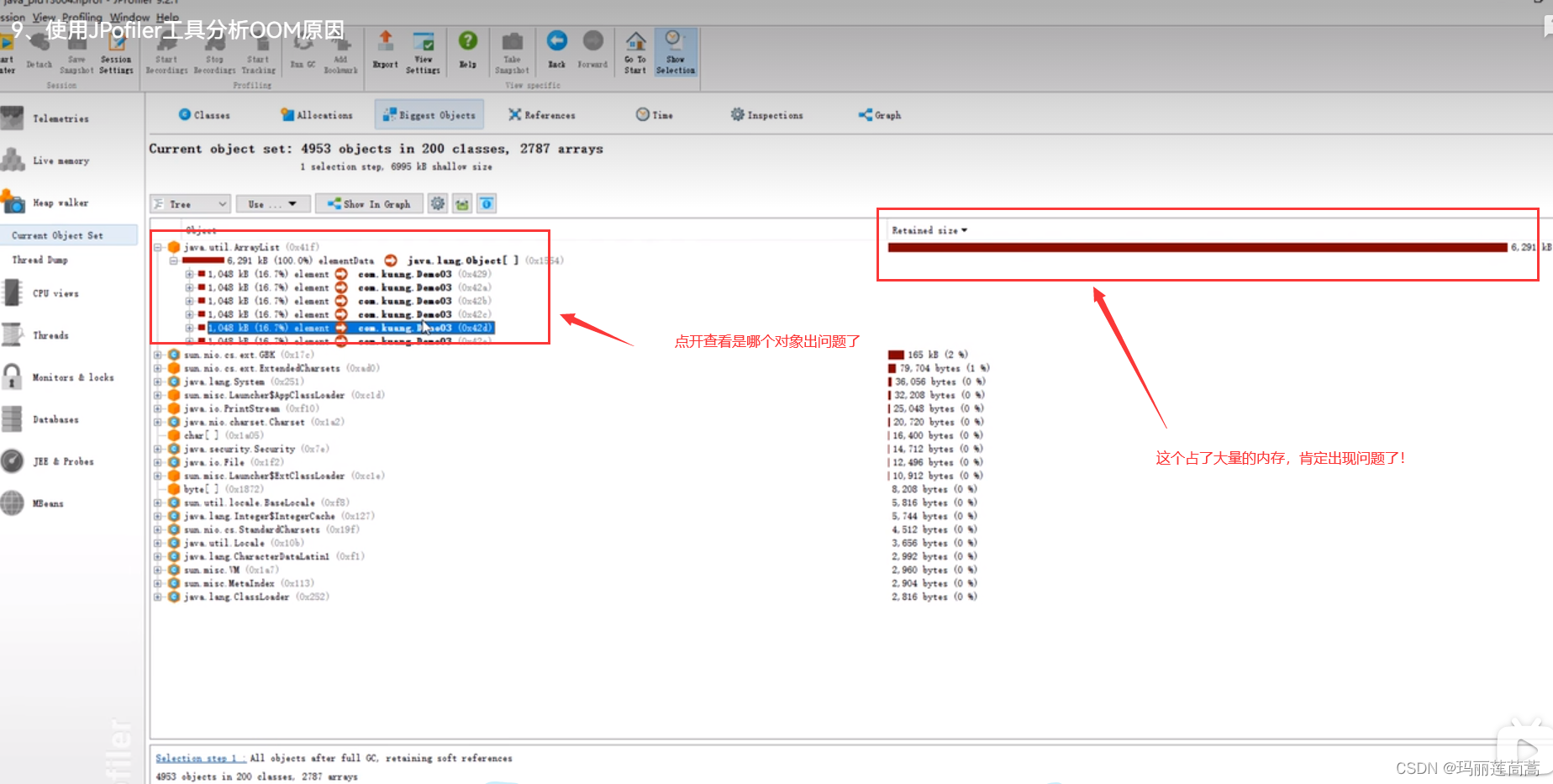
那可不可以像编译器一样直接定位到哪一行出现问题呢(这是我们程序员最想知道的)?
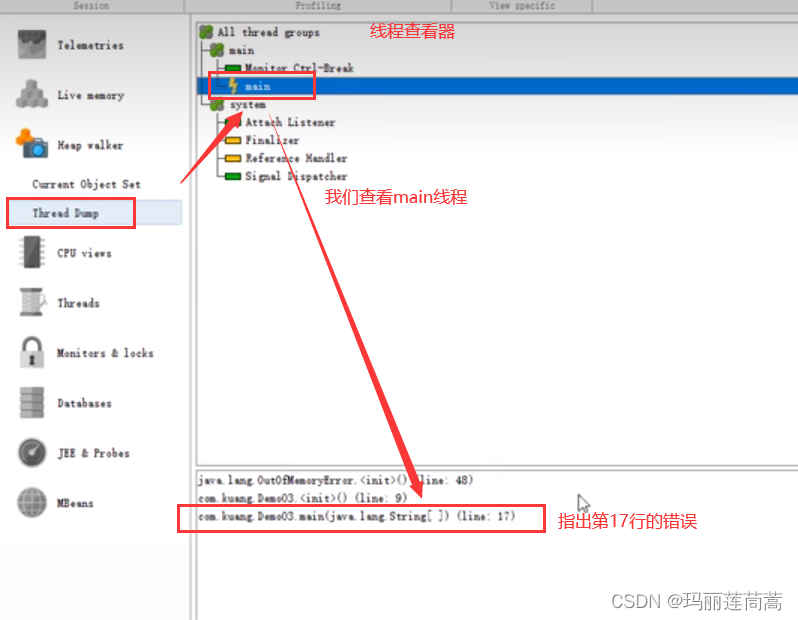

2.5.5 GC算法
面试问题:如何判断一个对象是否应该被回收?两个方法
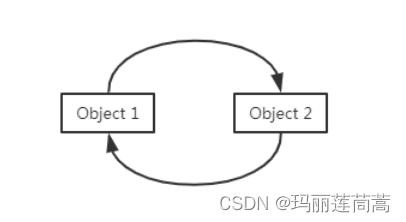
(1)引用计数法。给每个对象一个计数器,当引用次数为0时,就可以被回收了。但是这种方法存在两个问题,一个是一个对象一个计数器资源代价太大了,另一个是当发生循环引用时会失效,虽然Object1和Object2在程序里用不到了,但是因为他俩存在互相引用,那么引用次数永远不可能为0,也就无法被回收,所以jvm不采用引用计数法。
(2)可达性分析法。jvm维护了这样一个集合“GC root Set”。引用计数法就是遍历所有的GC root节点,根据引用关系顺着引用链去遍历。那些没有被便利到的就可以被淘汰了。
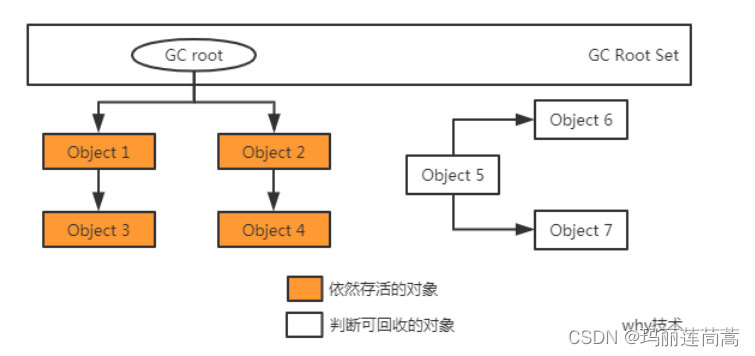
1. 引用计数法(已淘汰)
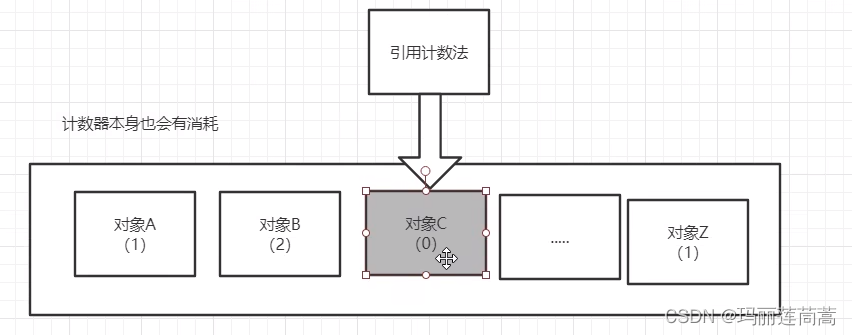
描述:给每个分配一个计数器,记录着被引用的次数,GC去回收那些次数为0的。
缺点:java一个大项目里有好多好多对象,每个对象一个计数器,代价太大了!
2. 复制算法(用于新生区,所以这就是轻GC)
(1)为什么要有两个幸存区?
主要为了消除内存碎片,有了两个就可以来回倒腾(拷贝),消除内存碎片
(2)复制算法倒腾的过程
每一次倒腾完,都要保证to区是空的。
每经过一次复制算法,from和to就交换一次位置
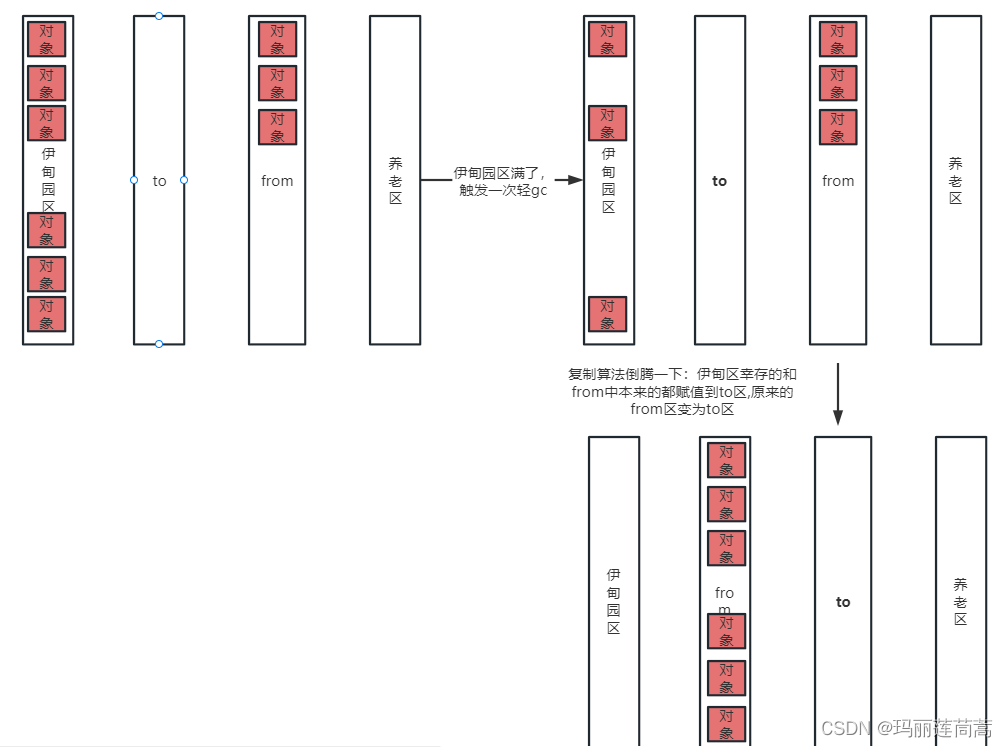
所以每一次GC清理完成后,伊甸园区是空的,to区也是空的,只有from里有对象的实体。
当一个对象经历了15次轻GC还没有被回收,就(才有资格)进入养老区。这个15次是默认的,通过如下运行参数可以调整
-XX:MaxTenuringThreshold=5
// 非常形象,Tenuring有任期的意思,任期满了就可以退休了哈哈
弊端:需要两个幸存区,且有一个一直是空的,所以这块内存是浪费的。
优点:解决内存碎片
想象一个场景,每个对象都100%存活,gc一个也回收不了。那么所有的对象就在from和to之间拷贝过来拷贝过去。所以复制算法最佳使用场景:当对象的存活率较低的地方,也就是我们的新生区。
3. 标记-清除-压缩算法(用于老年代,所以这就是重GC)
(1)先看一下标记-清除算法
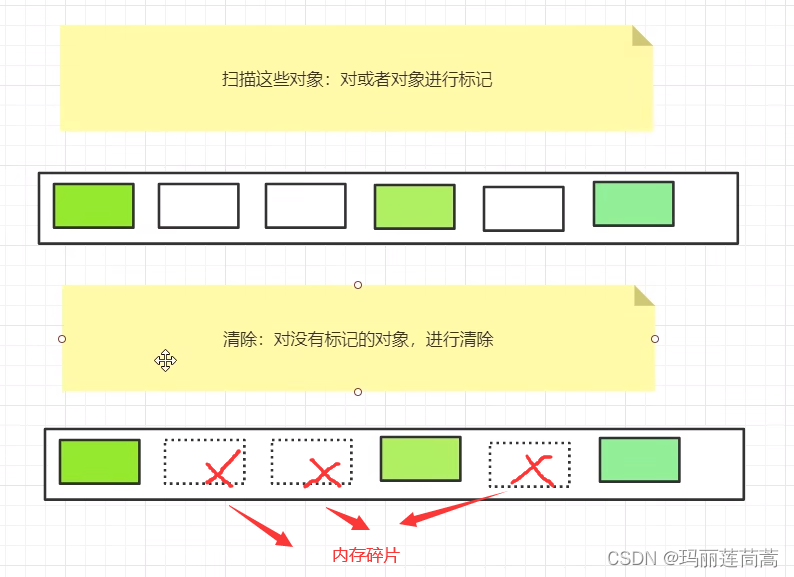
缺点:产生内存碎片
(2)优化——压缩
为了清除内存碎片,再扫描一遍。
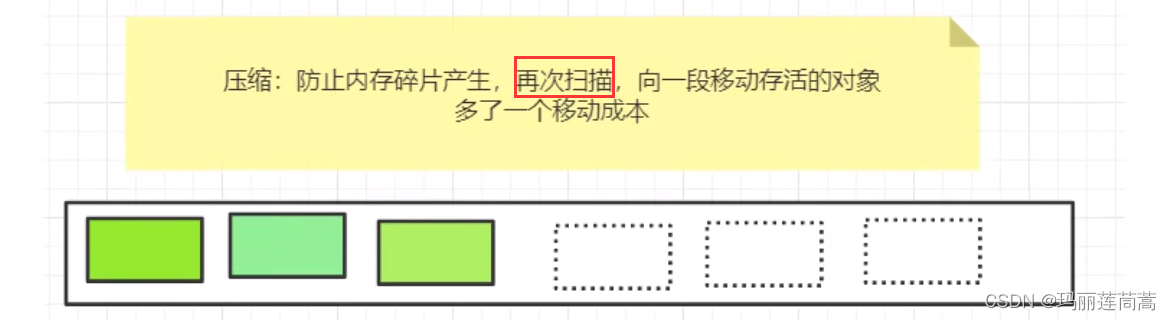
(3)优化——多次标记-清除,一次压缩
优点:不用开辟两个幸存区。和复制算法相比省空间
缺点:标记-清除-压缩经历了3次扫描,浪费时间。适合不怎么需要垃圾回收的地方,也就是老年区,当老年区满了才调用一次重GC。
4. 分代收集算法
- 内存效率(时间复杂度):复制算法 >优于)标记清除算法 > 标记清除压缩算法
- 解释:复制需要扫描一趟,标记清除两趟,标记清除压缩三趟
- 内存整齐度: 复制算法 = 标记清除压缩 > 标记清除
- 内存利用率: 标记清除= 标记清除压缩 > 复制算法
各有优劣,所以只能因地制宜——>分代收集算法
上面说过,新生代存活率低,所以适合复制算法。老年代存活率高,产生的内存碎片少,适合标记-清除-压缩算法。
2.5.6 总结一下内存调优用到的参数
-
-Xms8m -Xms2048m (初始内存 最大内存)
- -XX:+PrintGCDetails
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:MaxTenuringThreshold=5
2.5.7 JVM其他调优
jstack工具:是jvm自带的拍片子工具。主要有两个功能
1)查看每个线程堆栈的使用情况,看哪个线程用的堆内存、栈内存最多
2)查看每个线程使用CPU的情况,分析CPU过高的原因(阿里云面试题)
小林coding给出的官方解答:

查看每个线程使用CPU的情况,分析CPU过高的原因主要分以下5步
- top 查看哪个进程使用CPU最多,记录pid
- top -Hp pid 用pid指定进程,查看这个进程中的哪个线程使用CPU最多
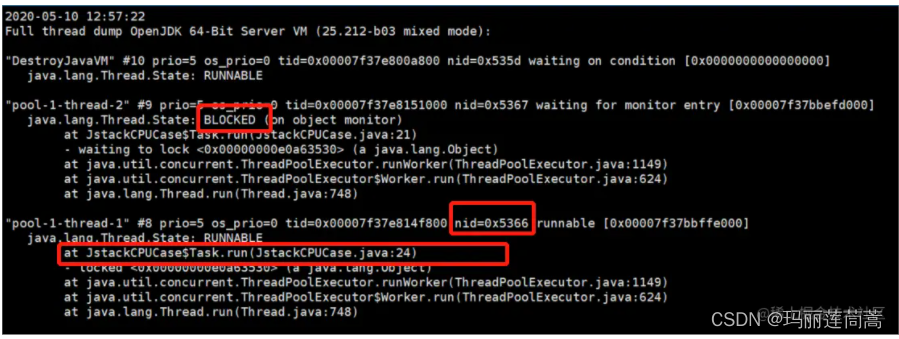
- jstack pid 线程ID还是进程ID?
- jstack -l [PID] >/tmp/log.txt
- 分析堆栈信息,堆栈信息里会给出多少行出现错误,然后我们去看源码就行
1.在服务器上,我们可以通过top命令查看各个进程的cpu使用情况,它默认是按cpu使用率由高到低排序的
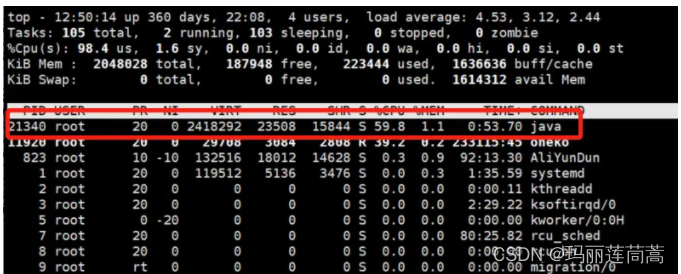
由上图中,我们可以找出pid为21340的java进程,它占用了最高的cpu资源,凶手就是它,哈哈!
2.通过top -Hp 21340可以查看该进程下,各个线程的cpu使用情况,如下:
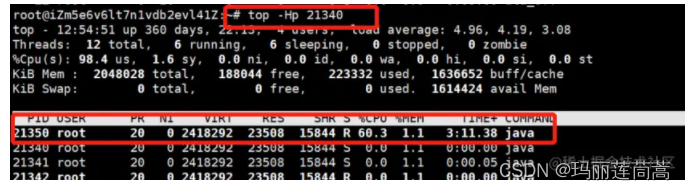
可以发现pid为21350的线程,CPU资源占用最高~,嘻嘻,小本本把它记下来,接下来拿jstack给它拍片子~但是之前呢我们需要得到这个线程PID的十六进制表示,用
printf "%x\n" 21350
命令得到21350的十六进制表示0x5366
3. jstack 21350 | grep 5366 或者直接输入jstack 21350命令(这里应该用线程号还是进程号?不确定哈),然后肉眼去找0x5366这一行,发现21350占用CPU最高的原因在24行!定位成功!















 83
83











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









