







es字段增删改查
1.关系型数据库和es对比
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types (慢慢会被弃用) |
| 行(rows) | documents(文档) |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。
2.分词测试
ik_smart:最少切分;
ik_max_word:最细粒度划分(穷尽词库的可能);
注:可以自定义词典
GET _analyze
{
"analyzer": "ik_smart",
"text": "年轻人喜欢学习java"
}
------------------------------------------------------------
GET _analyze
{
"analyzer": "ik_max_word",
"text": "年轻人喜欢学习java"
}
3.Rest风格说明

注:_doc 默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替
测试
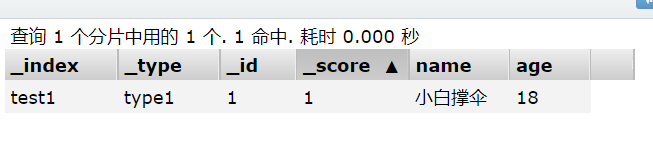
创建一个索引,添加
PUT /test1/type1/1
{
"name" : "小白撑伞",
"age" : 18
}
3.字段数据类型
字符串类型:
text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
数值型:
long、Integer、short、byte、double、float、half float、scaled float
日期类型:
date
布尔类型:
boolean
二进制类型:
binary
等等。。。
测试:
指定字段的类型(使用PUT)
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
修改(2种方案):
①旧的(使用put覆盖原来的值)
版本+1(_version);
但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失;
PUT /test3/_doc/1
{
"name" : "小白撑伞",
"age" : 18,
"birth" : "1999-10-10"
}
GET /test3/_doc/1
// 修改会有字段丢失
PUT /test3/_doc/1
{
"name" : "小白"
}
GET /test3/_doc/1
②新的(使用post的update)
version不会改变;
需要注意doc;
不会丢失字段;
POST /test3/_doc/1/_update
{
"doc":{
"name" : "post修改,version不会加一",
"age" : 2
}
}
GET /test3/_doc/1
删除:
DELETE /test1
查询(简单条件):
GET /test3/_doc/_search?q=name:小白
复杂查询:
①查询匹配
match:匹配(会使用分词器解析(先分析文档,然后进行查询))
_source:过滤字段(需要哪些字段显示)
sort:排序(asc:升序;desc:降序)
form、size 分页(查询开始页,查询页码数)
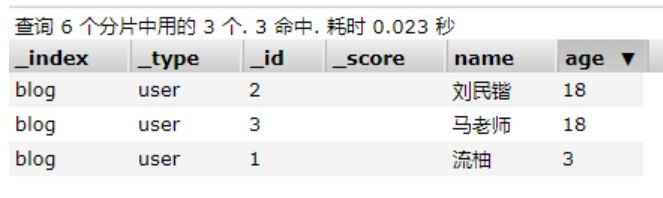
// 查询匹配(match)
GET /blog/user/_search
{
"query":{
"match":{
"name":"流"
}
}
,
"_source": ["name","desc"]
,
"sort": [
{
"age": {
"order": "asc"
}
}
]
,
"from": 0
,
"size": 1
}
②多条件查询(bool)
must 相当于 and
should 相当于 or
must_not 相当于 not (… and …)
filter 过滤
GET /blog/user/_search
{
"query":{
"bool": {
"must": [
{
"match":{
"age":3
}
},
{
"match": {
"name": "流"
}
}
],
"filter": {
"range": {
"age": {
"gte": 1,
"lte": 3
}
}
}
}
}
}
③匹配数组
貌似不能与其它字段一起使用
可以多关键字查(空格隔开)— 匹配字段也是符合的
match 会使用分词器解析(先分析文档,然后进行查询)
GET /blog/user/_search
{
"query":{
"match":{
"desc":"年龄 牛 大"
}
}
}
④精确查询
term 直接通过 倒排索引 指定词条查询
适合查询 number、date、keyword ,不适合text
GET /blog/user/_search
{
"query":{
"term":{
"desc":"年 "
}
}
}
⑤text和keyword
text:
支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
// 测试keyword和text是否支持分词
// 设置索引类型
PUT /test
{
"mappings": {
"properties": {
"text":{
"type":"text"
},
"keyword":{
"type":"keyword"
}
}
}
}
// 设置字段数据
PUT /test/_doc/1
{
"text":"测试keyword和text是否支持分词",
"keyword":"测试keyword和text是否支持分词"
}
// text 支持分词
// keyword 不支持分词
GET /test/_doc/_search
{
"query":{
"match":{
"text":"测试"
}
}
}// 查的到
GET /test/_doc/_search
{
"query":{
"match":{
"keyword":"测试"
}
}
}// 查不到,必须是 "测试keyword和text是否支持分词" 才能查到
GET _analyze
{
"analyzer": "keyword",
"text": ["测试liu"]
}// 不会分词,即 测试liu
GET _analyze
{
"analyzer": "standard",
"text": ["测试liu"]
}// 分为 测 试 liu
GET _analyze
{
"analyzer":"ik_max_word",
"text": ["测试liu"]
}// 分为 测试 liu
⑥高亮查询
会在字体中加入默认标签也可以自定义
/// 高亮查询
GET blog/user/_search
{
"query": {
"match": {
"name":"流"
}
}
,
"highlight": {
"fields": {
"name": {}
}
}
}
// 自定义前缀和后缀
GET blog/user/_search
{
"query": {
"match": {
"name":"流"
}
}
,
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









