







 本文详细介绍了机器学习过程中的关键步骤,包括数据清洗以处理错误和缺失值,探索性数据分析用于理解数据特性,特征工程涉及特征提取和转换,特征选择以优化模型性能,以及数据建模中模型选择、调整和评估。
本文详细介绍了机器学习过程中的关键步骤,包括数据清洗以处理错误和缺失值,探索性数据分析用于理解数据特性,特征工程涉及特征提取和转换,特征选择以优化模型性能,以及数据建模中模型选择、调整和评估。
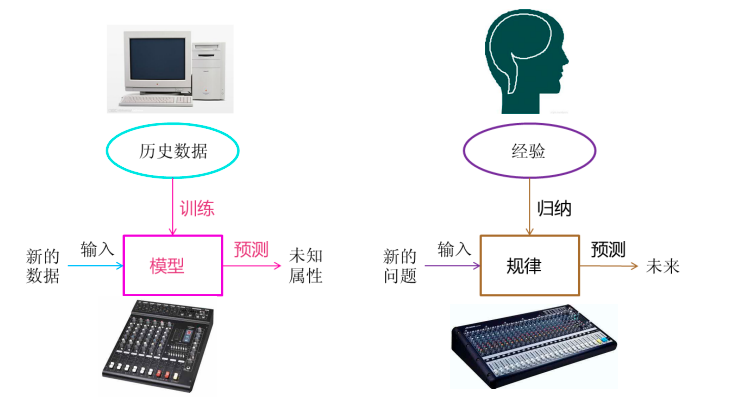
机器学习的一般步骤

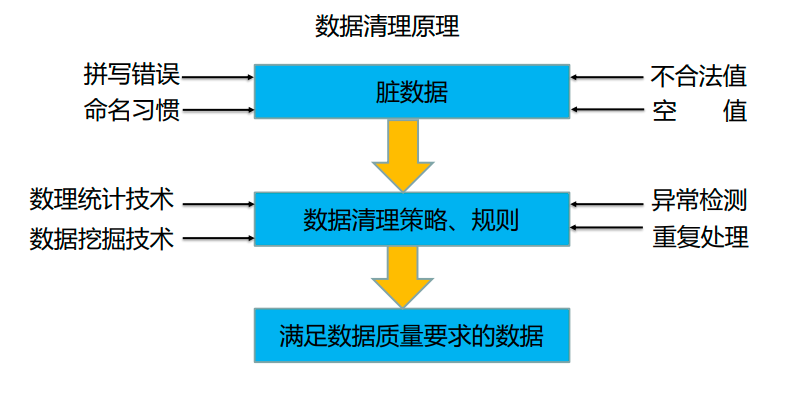
数据清洗
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
探索性数据分析(EDA
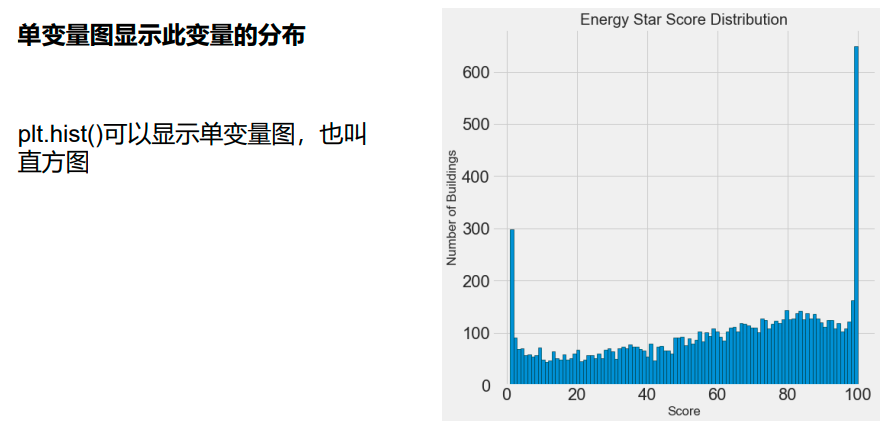
探索性数据分析(EDA)是一个开放式流程,我们制作绘图并计算统计数据,以便探索我们的数据。目的是找到异常,模式,趋势或关系。 这些可能是有趣的(例如,找到两个变量之间的相关性),或者它们可用于建模决策,例如使用哪些特征。简而言之,EDA的目标是确定我们的数据可以告诉我们什么!
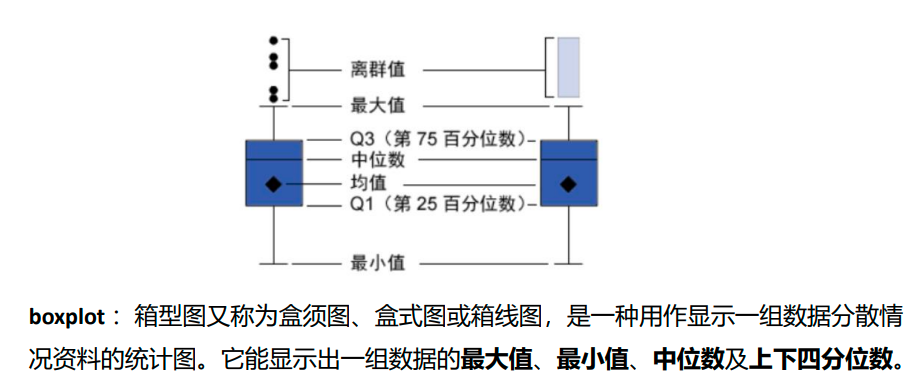
IQR = Q3-Q1,即上四分位数与下四分位数之间的差,也就是盒子的长度。
最小观测值为min = Q1 - 1.5IQR,如果存在离群点小于最小观测值,则下限为最小观测值,离群点单独以点汇出。
最大观测值为max = Q3 +1.5IQR,如果存在离群点大于最大观测值,则上限为最大观测值,离群点单独以点汇出。如果没有比最大观测值大的数,则上限为最大值。
- 寻找关系
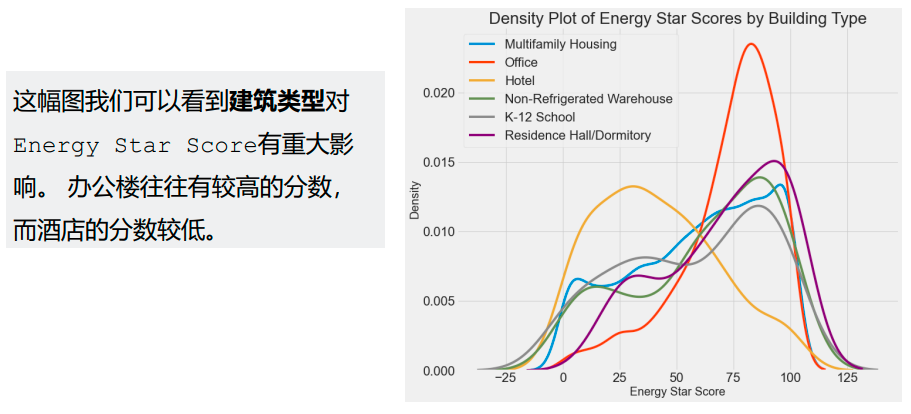
为了查看分类变量 - categorical variables对分数的影响,我们可以通过分类变量的值来绘制密度图。 密度图还显示单个变量的分布,可以认为是平滑的直方图。 如果我们通过为分类变量密度曲线着色,这将向我们展示分布如何基于类别变化的。
现在我们有了正确的列数据类型,我们可以通过查看每列中缺失值的百分比来开始分析。 当我们进行探索性数据分析时,缺失的值很好,但是必须使用机器学习方法进行填写。Pairs Plot是一次检查多个变量的好方法,因为它显示了对角线上的变量对和单个变量直方图之间的散点图。

特征工程
特征工程:
获取原始数据并提取或创建新特征的过程。这可能意味着需要对变量进行变换,例如自然对数和平方根,或者对分类变量进行one-hot编码,以便它们可以在模型中使用。 一般来说,我认为特征工程是从原始数据创建附加特征。
特征工程在数据挖掘中有举足轻重的位置数据领域一致认为:数据和特征决定了机器学习的上限,而模型和算法只能逼近这个上限而已。
- 特征工程重要性:
特征越好,灵活性越强; 特征越好,模型越简单;特征越好,性能越出色;好特征即使使用一般的模型,也能得到很好的效果! - 主要方法
离散型变量处理
分箱/分区
交叉特征
特征缩放
特征提取
特征选择
选择数据中最相关的特征的过程。在特征选择中,我们删除特征以帮助模型更好地总结新数据并创建更具可解释性的模型。一般来说,特征选择是减去特征,所以我们只留下那些最重要的特征。
- 特征选择主要有两个功能:
1.减少特征数量、降维,使模型泛化能力更强,减少过拟合
2.增强对特征和特征值之间的理解 - 主要方法
去除变化小的特征
去除共线特征
去除重复特征
主成分分析(PCA)

数据建模
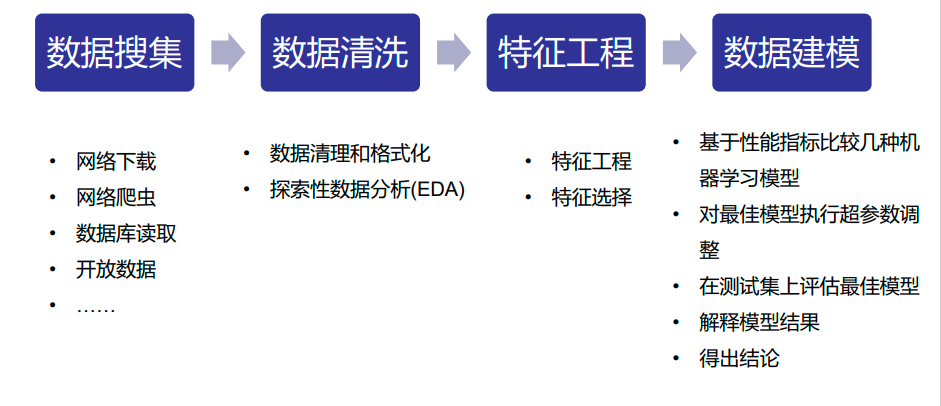
• 基于性能指标比较几种机器学习模型
• 对最佳模型执行超参数调整
• 在测试集上评估最佳模型
• 解释模型结果
• 得出结论



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











