






 该博客讲述了如何处理气象塔观测数据,包括从txt文件中提取数值,转换为浮点数,存储到csv文件,然后使用pandas读取csv文件。进一步,创建时间序列并将其添加到数据中,最后进行异常值处理和缺失数据填补。
该博客讲述了如何处理气象塔观测数据,包括从txt文件中提取数值,转换为浮点数,存储到csv文件,然后使用pandas读取csv文件。进一步,创建时间序列并将其添加到数据中,最后进行异常值处理和缺失数据填补。
气象塔观测数据通常有15层:8,15,32,47,65,80,100,120,140,160,180,200,240,280,320m,并每隔5分钟输出一次平均值,数据记录方式通常为:

每一时间段之间有-----------------------------------------分割,该种方式对数据处理造成巨大麻烦。
通过观察我们不难发现,在每一组--------分割线之间包含15组观测数据,以及两行时间记录data=090101(09年1月1日);hour=0:05-0:10(小时:分钟)
那么我们不妨先逐行读取一下该txt文本
f = open(r'D:\2009-5min 325m tower meteorological data\month1/0101-5.txt')
for i in f.readlines():
print(i)
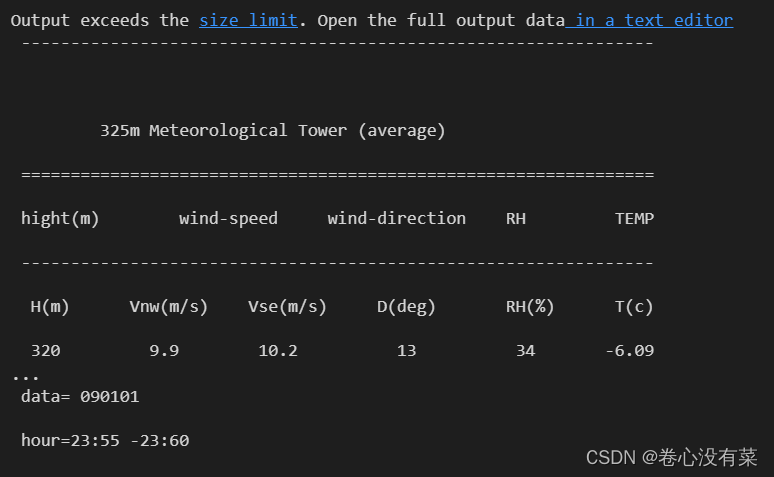
看到这里有没有灵光一现? 如果我们对每一行字符串进行分割生成一个列表,然后判断列表中每一个元素是否可以被转化为int类型岂不是就可以完美提取出我们所需要的数字了?
经过上述优化后的代码如下:
f = open(r'D:\2009-5min 325m tower meteorological data\month1/0101-5.txt')
for i in f.readlines():
row = i.split()
try:
for j in range(len(row)):
if row[j] !='':
row[j] = float(row[j])
print(row)
except TypeError:
pass
except ValueError:
pass

美滋滋!!
第一步数据提取我们已经差不多完成,但是这其中还有一个重要的问题我们如何才能把对应的时间增加上去呢?
通过观察数据集合我们可以发现每组数据15条,每两条之间间隔5min那么我们是否可以通过手动创建一组时间序列并反向添加回去呢!
说干就干
第一步,我们需要把上面的数据先保存成csv文件,全部保存出来之后再使用pandas读取该csv文件
import csv
f = open(r'D:\2009-5min 325m tower meteorological data\month1/0101-5.txt')
g = open(r'D:/数据.csv','w+',newline='',encoding='gbk')
head = ['H(m)', 'Vnw(m/s)', 'Vse(m/s)', 'D(deg)', 'RH(%)', 'T(c)']
csv_wrirt = csv.writer(g)
csv_wrirt.writerow(head)
for i in f.readlines():
row = i.split()
try:
for j in range(len(row)):
if row[j] !='':
row[j] = float(row[j])
print(row)
csv_wrirt.writerow(row)
except TypeError:
pass
except ValueError:
pass
紧接着我们需要重新将保存出的csv文件读取回来
import pandas as pd
df = pd.read_csv(r'D:/数据.csv')
print(df)
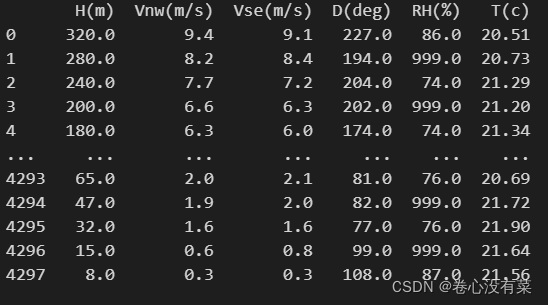
根据该数据集本身特性:一个txt文件中是一天的数据且每隔5分钟记录一次平均值,那么就一共有2460/515行数据。
根据这种思路我们来创建时间序列
from datetime import datetime as d1
import datetime
mon = '01' #输入起始月份
day = '01' #输入起始日
s1_start = '2009-{}-{} '.format(mon,day) + '00:00:00'
s1_end = '2009-{}-{} '.format(mon,day) + '23:55:00'
time = d1.strptime(s1_start, '%Y-%m-%d %H:%M:%S') #将开始时间字符串转为时间格式
s1_start_endnow = d1.strptime(s1_end, '%Y-%m-%d %H:%M:%S') #将结束时间字符串转为时间格式
delta = datetime.timedelta(minutes=5) #设置间隔时间(5min)
time_ = [] #创建空列表,用于接收时间
s = [str(time.strftime('%Y-%m-%d %H:%M:%S'))] * 15 #每个时间段有15条数据
time_ = time_ + s
while str(time.strftime('%Y-%m-%d %H:%M:%S')) != str(s1_start_endnow.strftime('%Y-%m-%d %H:%M:%S')):
time += delta
s = [str(time.strftime('%Y-%m-%d %H:%M:%S'))] * 15
time_ = time_ + s
print(time_)
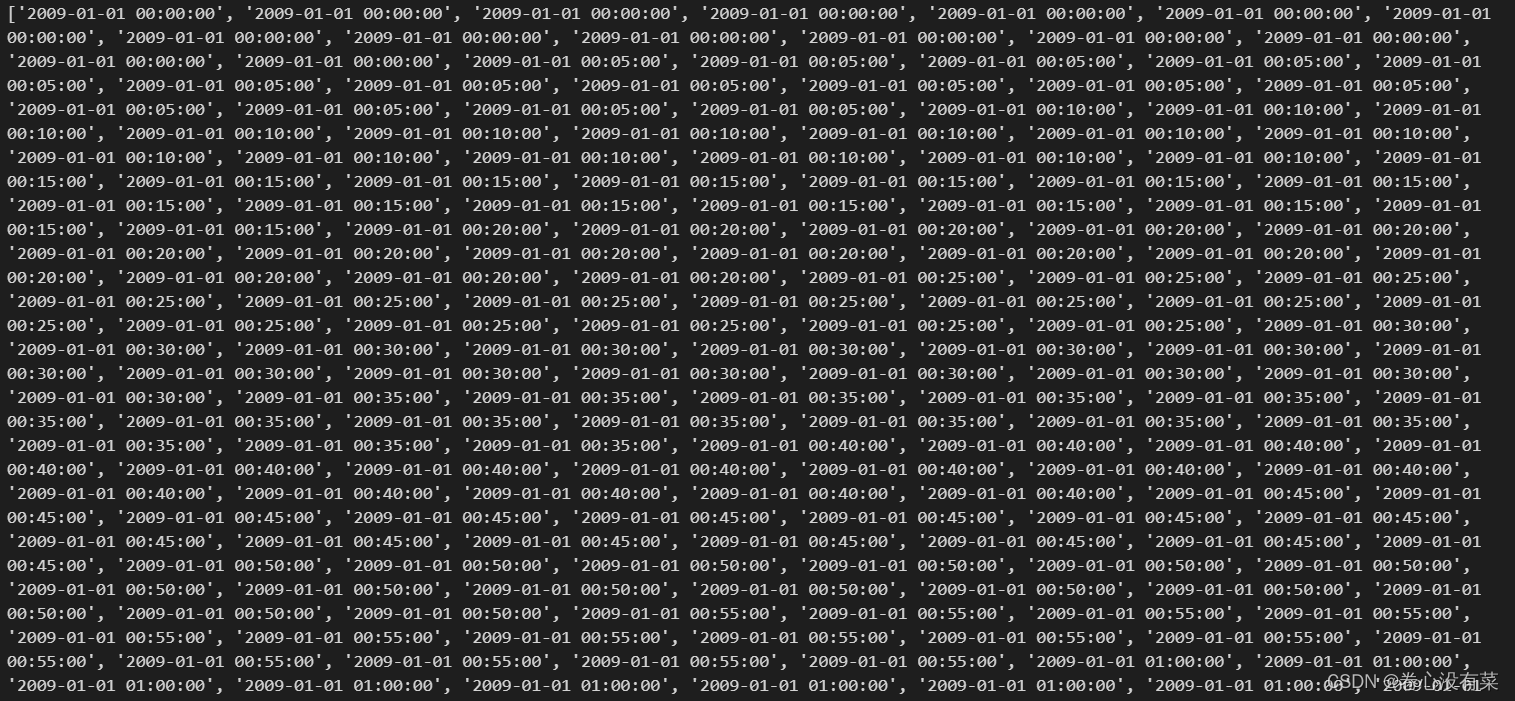
紧接着我们便可以将创建好的时间序列重新添加回pandas中
df['time'] = time_
完整代码奉上
import pandas as pd
from datetime import datetime as d1
import datetime
import os
import numpy as np
import csv
np.set_printoptions(suppress=True)
path = r'D:\2009-5min 325m tower meteorological data\month12'
file_list = os.listdir(path)
for file in file_list:
mon = file[0:2]
day = file[2:4]
s1_start = '2009-{}-{} '.format(mon,day) + '00:00:00'
s1_end = '2009-{}-{} '.format(mon,day) + '23:55:00'
time = d1.strptime(s1_start, '%Y-%m-%d %H:%M:%S')
head = ['H(m)', 'Vnw(m/s)', 'Vse(m/s)', 'D(deg)', 'RH(%)', 'T(c)']
s1_start_endnow = d1.strptime(s1_end, '%Y-%m-%d %H:%M:%S')
delta = datetime.timedelta(minutes=5)
time_ = []
s = [str(time.strftime('%Y-%m-%d %H:%M:%S'))] * 15
time_ = time_ + s
while str(time.strftime('%Y-%m-%d %H:%M:%S')) != str(s1_start_endnow.strftime('%Y-%m-%d %H:%M:%S')):
time += delta
s = [str(time.strftime('%Y-%m-%d %H:%M:%S'))] * 15
time_ = time_ + s
# print(str(time.strftime('%Y-%m-%d %H:%M:%S')))
f = open(r'{}/{}'.format(path,file))
g = open(r'D:\2009-5min 325m tower meteorological data/{}'.format(file.split('.')[0]+'.csv'),'w+',newline='',encoding='gbk')
csv_wrirt = csv.writer(g)
csv_wrirt.writerow(head)
data_array = np.zeros((6))
for i in f.readlines():
row = i.split()
try:
for j in range(len(row)):
if row[j] !='':
row[j] = float(row[j])
# print(row)
csv_wrirt.writerow(row)
except TypeError:
pass
except ValueError:
pass
f.close()
g.close()
df = pd.read_csv(r'D:\2009-5min 325m tower meteorological data/{}'.format(file.split('.')[0]+'.csv'))
df['time'] = time_
'''
head = ['H(m)', 'Vnw(m/s)', 'Vse(m/s)', 'D(deg)', 'RH(%)', 'T(c)']
异常值处理,缺测数据补全
'''
df['Vnw(m/s)']=df['Vnw(m/s)'].replace(999,np.nan)
df['Vse(m/s)']=df['Vse(m/s)'].replace(999,np.nan)
df['RH(%)']=df['RH(%)'].replace(999,np.nan)
df['T(c)']=df['T(c)'].replace(999,np.nan)
df['Vnw(m/s)']=df['Vnw(m/s)'].interpolate()
df['Vse(m/s)']=df['Vse(m/s)'].interpolate()
df['RH(%)']=df['RH(%)'].interpolate()
df['T(c)']=df['T(c)'].interpolate()
df.to_csv(r'D:\2009-5min 325m tower meteorological data/{}'.format(file.split('.')[0]+'.csv'),index=False)
print(df)


















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











