






文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤: 读入文本; 分词; 建立字典;将每个词映射到一个唯一的索引(index) 将文本从词的序列转换为索引的序列,方便输入模型。
读入文本

分词

建立字典

将词转化为索引

语言模型

语言模型的计算

n元语法

时序数据采样

随机采样
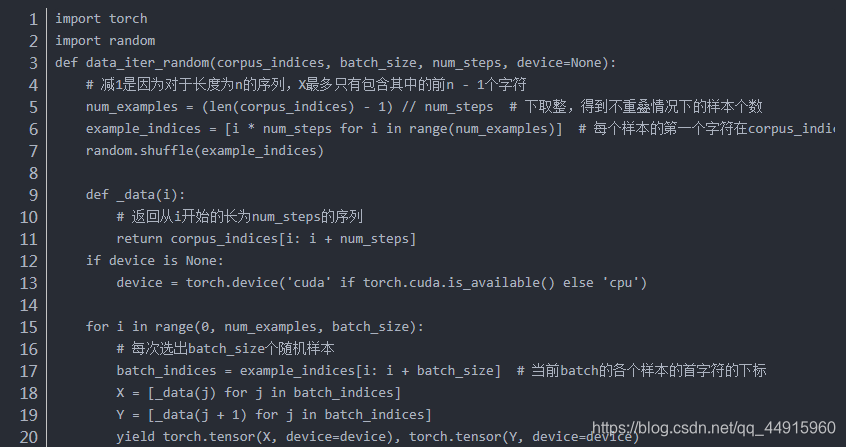
相邻采样
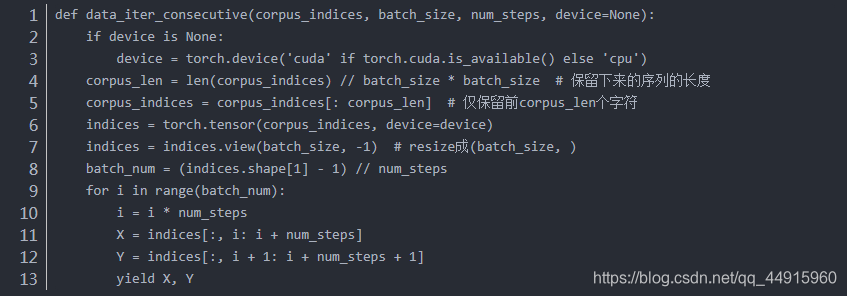
总结
N元语法是基于n − 1阶马尔可夫链的概率语法模型,其中n权衡了计算复杂度和模型准性。
循环神经网络基础RNN
网络结构
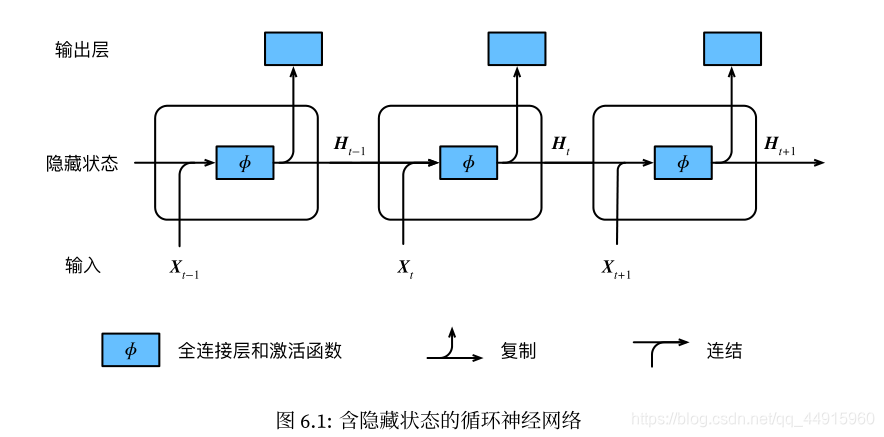
数学表达式
可以与多层感知机的表达式作比较


代码实现
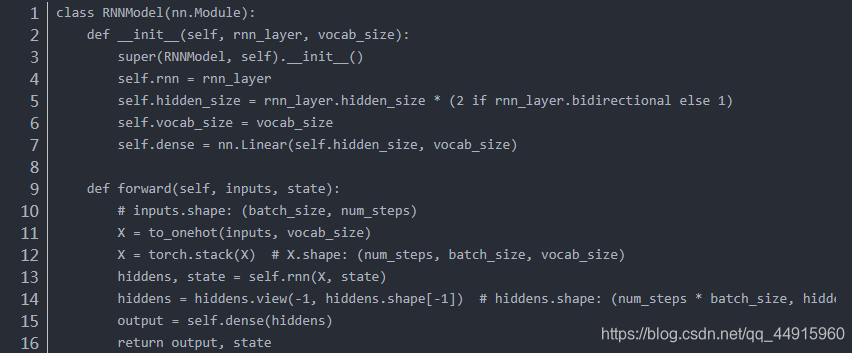
总结
使用循环计算的网络即循环神经网络,循环神经网络的隐藏状态可以捕捉截止当前时间步的序列的历史信息,循环神经网络模型参数的数量不随时间步的增加而增加。














 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









