









文章目录
一、 准备工作
到这里,相信你已经学会如何将模型文件转换ONNX计算图了。在将ONNX转换为TensorRT的引擎文件时,要确保ONNX模型的版本与TensorRT兼容,首先需要确认ONNX模型的版本号和TensorRT支持的ONNX版本号是否匹配。
检查ONNX和TensorRT版本
https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html
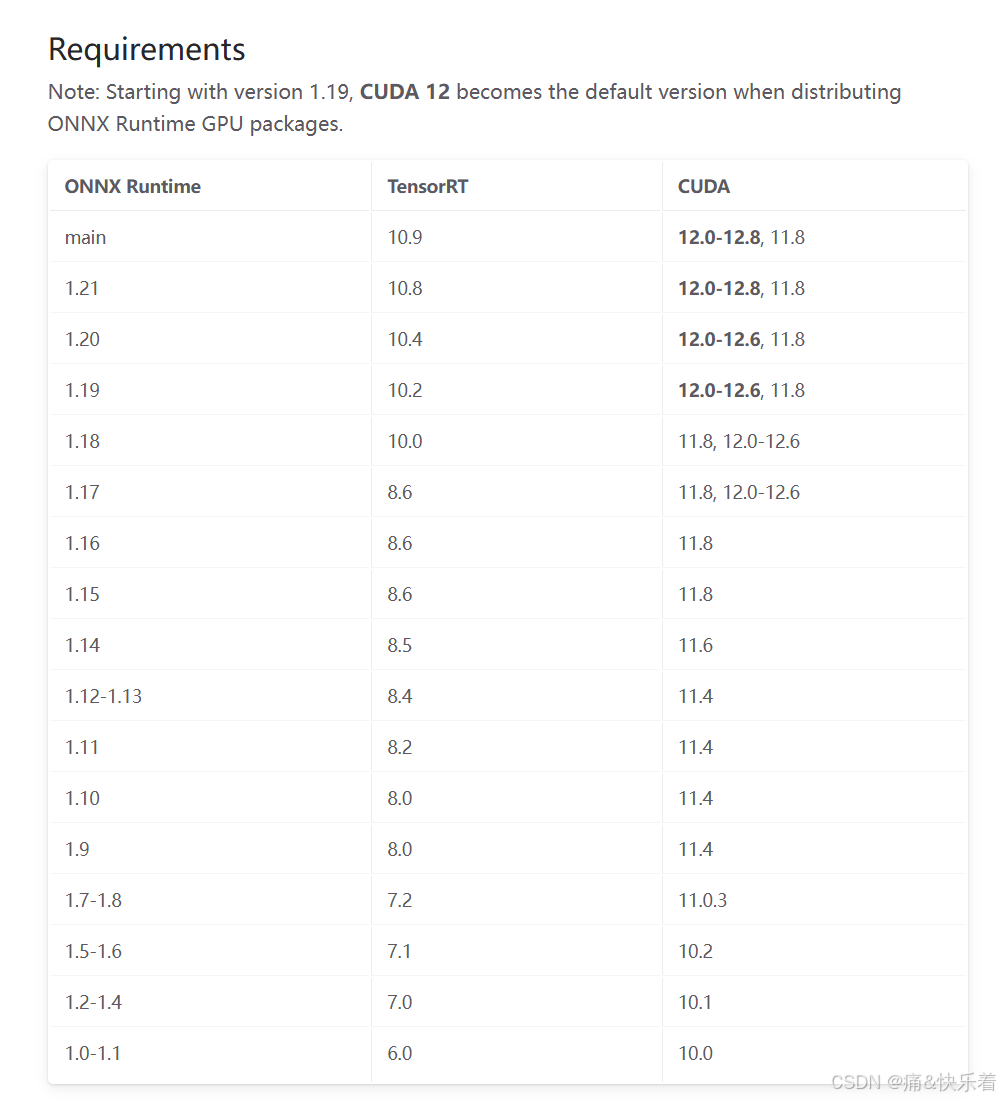
ONNX opset support
https://github.com/onnx/onnx/blob/main/docs/Versioning.md
https://onnxruntime.ai/docs/reference/compatibility.html
https://github.com/onnx/onnx-tensorrt?tab=readme-ov-file
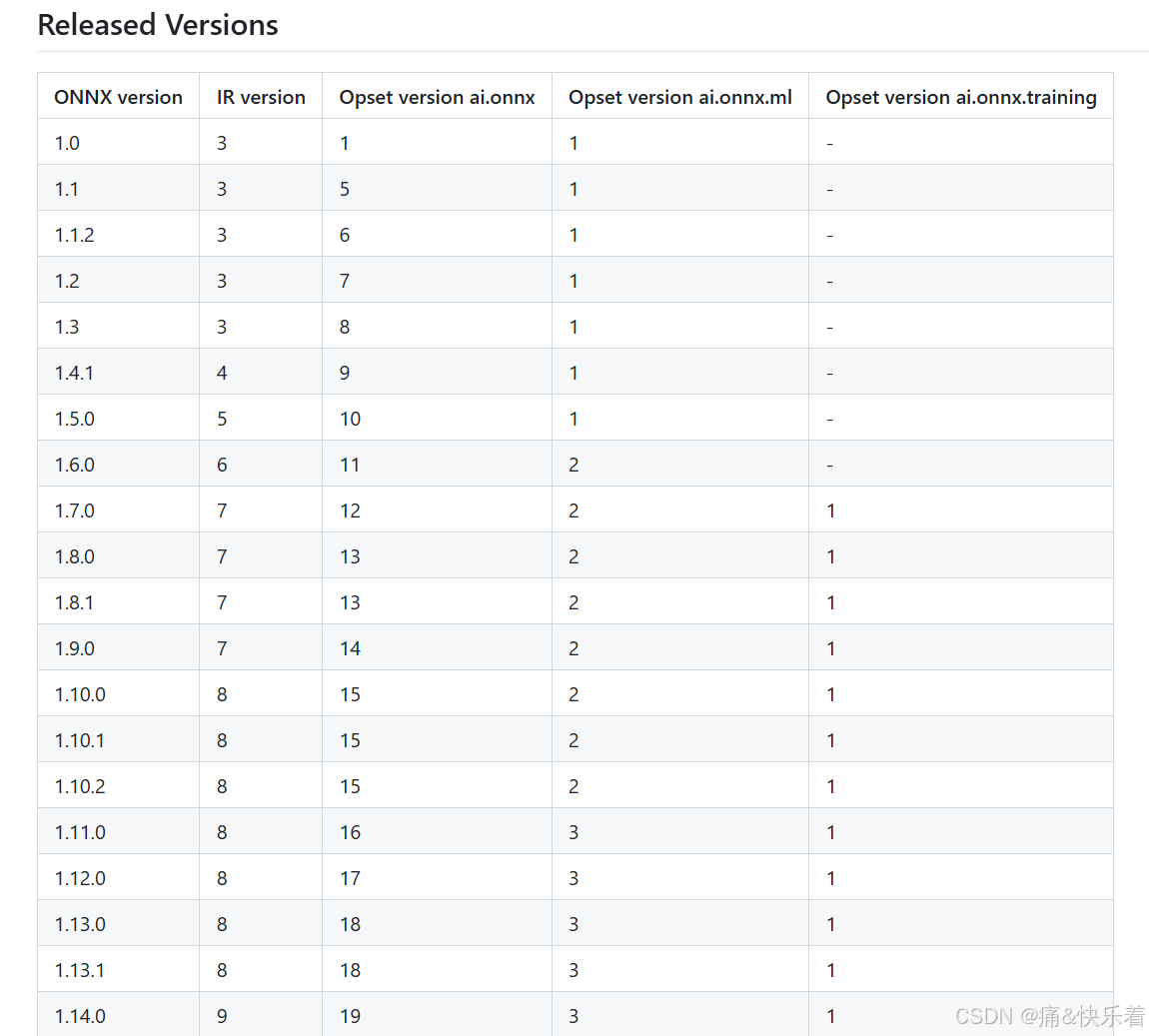
二、使用TensorRT的trtexec工具进行转换
2.1 trtexec简介
trtexec 工具是 TensorRT 的命令行工具,位于 TensorRT 的安装目录中,随 TensorRT 的安装就可以直接使用。trtexec,不仅打包了几乎所有 TensorRT 脚本可以完成的工作,并且扩展丰富的推理性能测试的功能。通常我们使用 trtexec 完成下面三个方面的工作,一是由 Onnx 模型文件生成 TensorRT 推理引擎,并且可以序列化为 .plan 文件。二是可以查看 Onnx 或者 .plan 文件的网络的逐层信息。第三是可以进行模型性能测试,也就是测试 TensorRT 引擎基于随机数输入或者是给定输入下的性能,这是其最常用的功能。
2.2 trtexec常用参数
构建阶段
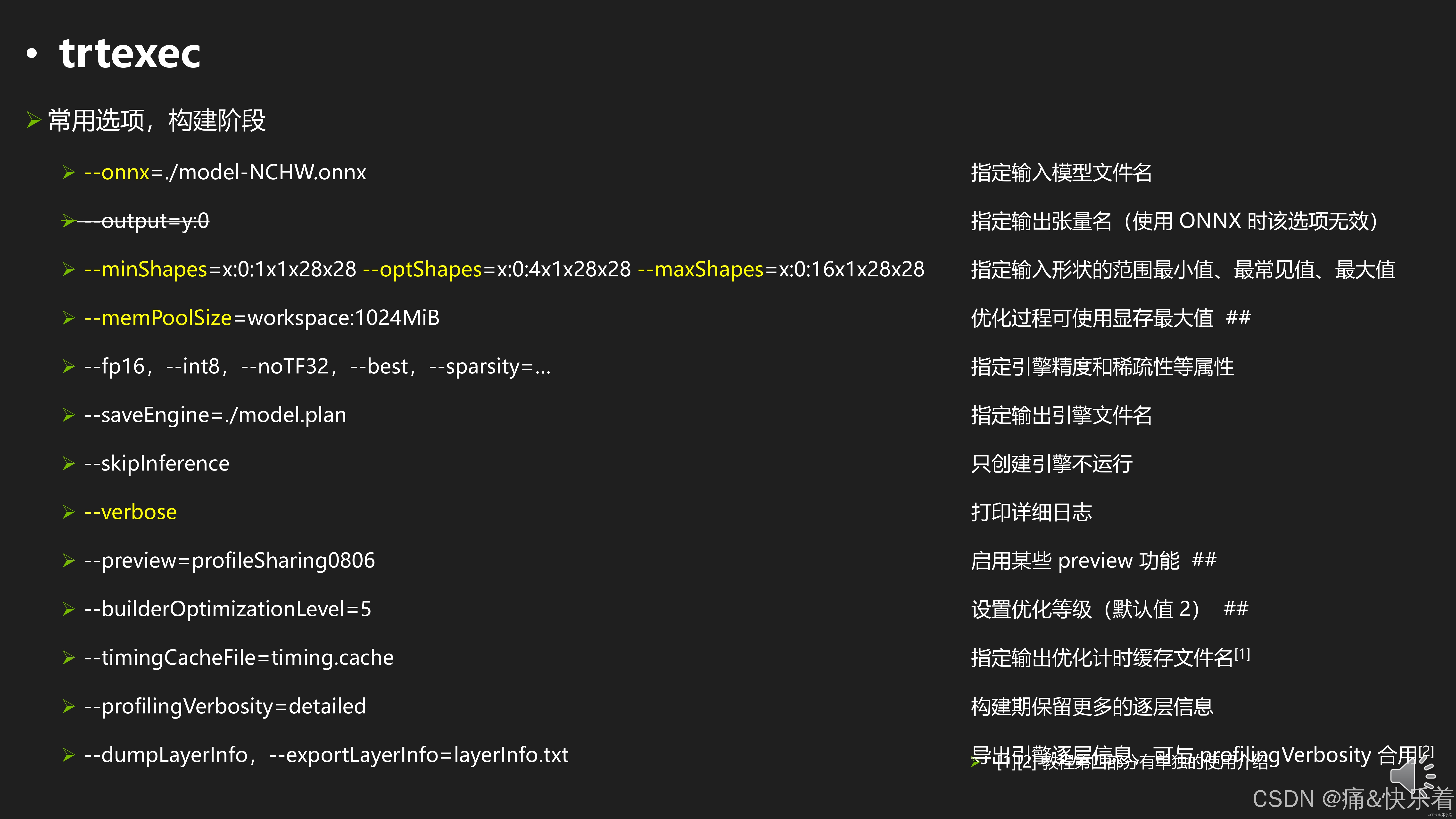
运行阶段

2.3 trtexec解析ONNX文件,使用优化选择构建TensorRT引擎并保存至.plan文件
命令行参数如下:
trtexec \
--onnx=modelA.onnx \
--saveEngine=model-02.plan \
--timingCacheFile=model-02.cache \
--minShapes=tensorX:1x1x28x28 \
--optShapes=tensorX:4x1x28x28 \
--maxShapes=tensorX:16x1x28x28 \
--fp16 \
--noTF32 \
--memPoolSize=workspace:1024MiB \
--builderOptimizationLevel=5 \
--maxAuxStreams=4 \
--skipInference \
--verbose \
> result-02.log 2>&1
参数说明:
–onnx=modelA.onnx:这个选项指定了要解析和构建的输入ONNX文件(modelA.onnx)。
–saveEngine=model-02.plan:这个选项指定了保存生成的TensorRT引擎的文件名为model-02.plan。
–timingCacheFile=model-02.cache:这个选项指定了保存计时缓存的文件名为model-02.cache,用于在后续运行中加速引擎构建过程。
–minShapes=tensorX:1x1x28x28:这个选项指定了最小输入形状,其中tensorX是输入张量的名称,1x1x28x28是指定的形状。
–optShapes=tensorX:4x1x28x28:这个选项指定了优化输入形状,以便在引擎构建过程中进行形状优化。
–maxShapes=tensorX:16x1x28x28:这个选项指定了最大输入形状,用于支持动态形状的推理。
–fp16:这个选项启用FP16精度,以减少内存占用和提高推理性能。
–noTF32:这个选项禁用TF32精度,以确保使用FP16进行计算。
–memPoolSize=workspace:1024MiB:这个选项指定了TensorRT引擎的内存池大小为1024MiB,用于分配内存。
–builderOptimizationLevel=5:这个选项指定了引擎构建器的优化级别为5,进行更多的优化。
–maxAuxStreams=4:这个选项指定了最大的辅助流数为4,用于并行执行某些操作。
–skipInference:这个选项指示在构建引擎后跳过实际的推理过程。
–verbose:这个选项启用详细的输出信息,以便更好地了解引擎构建和优化过程。
注意:TensorRT中的workspace和memPoolSize是不同的概念。(在tensorRT10版本后workpace删除了)
在TensorRT中,workspace是指模型中每一层可以使用的内存上限,单位是字节。例如,builder.max_workspace_size = 1<<30表示1GB的内存上限。这个参数的作用是确保每一层在运行时分配的内存不会超过这个限制,但并不是每一层都会分配1GB内存,而是根据实际需要动态分配。
而memPoolSize则是指内存池的大小,用于管理内存的分配和回收。在TensorRT的命令行工具trtexec中,–memPoolSize = workspace: 1024MiB参数用于设置内存池的大小,以确保在模型推理过程中有足够的内存可用。
简而言之,workspace是每一层可以使用的内存上限,而memPoolSize是整个模型推理过程中用于管理内存分配和回收的内存池大小。两者虽然都与内存管理相关,但具体用途和设置方式有所不同。
补充:timingCacheFile的原理与作用
–timingCacheFile=model-02.cache 选项用于指定保存计时缓存的文件名。计时缓存是一个用于加速引擎构建过程的文件,它记录了在之前构建相同模型时的层级和层级间计算时间信息。
计时缓存的作用是避免重复计算相同层级和层级间的时间。在构建引擎时,TensorRT会评估和记录每个层级的计算时间,然后将这些信息保存到计时缓存中。当再次构建相同模型时,TensorRT可以利用缓存中的计时信息,避免重新评估层级的计算时间,从而加速引擎构建过程。
计时缓存的原理是根据层级和层级间的计算时间,建立一个映射关系。当构建引擎时,TensorRT会检查缓存文件中是否存在相应的计时信息。如果存在,TensorRT将直接使用缓存中的时间信息,避免重新评估。如果缓存文件不存在或不匹配,TensorRT将重新评估计算时间并更新缓存。
通过使用计时缓存,可以显著减少引擎构建的时间,特别是对于大型模型和复杂计算图的情况。计时缓存文件可以在之后的引擎构建过程中重复使用,以提高构建的效率。
需要注意的是,计时缓存文件是特定于模型和硬件的。如果模型结构或硬件配置发生变化,计时缓存文件可能会失效,需要重新构建。因此,在使用计时缓存时,确保模型和硬件配置保持一致才能获得最佳的性能加速效果。
2.4 加载engine并做推理
trtexec工具除了能够将模型转换为trt引擎文件外,还能够加载引擎文件进行推理计时评估。
trtexec \
--loadEngine=model-02.plan \
--shapes=tensorX:4x1x28x28 \
--noDataTransfers \
--useSpinWait \
--useCudaGraph \
--verbose \
> result-03.log 2>&1
参数说明:
–loadEngine=model-02.plan:这个选项指定了要加载的TensorRT引擎文件(model-02.plan)。
–shapes=tensorX:4x1x28x28:这个选项指定了输入形状,其中tensorX是输入张量的名称,4x1x28x28是指定的形状。
–noDataTransfers:这个选项禁用数据传输。在推理过程中,TensorRT默认会将输入和输出数据从主机内存传输到GPU内存,然后再传输回主机内存。使用–noDataTransfers选项可以避免这些数据传输,从而提高推理的效率。
–useSpinWait:这个选项启用自旋等待。在GPU计算完成后,TensorRT默认会使用阻塞方式等待结果,即线程会被挂起。使用–useSpinWait选项可以改为使用自旋等待,即线程会循环检查计算是否完成,避免线程挂起和恢复的开销,提高推理效率。
–useCudaGraph:这个选项启用CUDAGraph。TensorRT可以将推理计算图编译为CUDAGraph以提高推理性能。
2.5 输出engine信息
# 04-Print information of the TensorRT engine (TensorRT>=8.4)
# Notice
# + Start from ONNX file because option "--profilingVerbosity=detailed" should be added during buildtime
# + output of "--dumpLayerInfo" locates in result*.log file, output of "--exportLayerInfo" locates in specified file
trtexec \
--onnx=modelA.onnx \
--skipInference \
--profilingVerbosity=detailed \
--dumpLayerInfo \
--exportLayerInfo="./model-04-exportLayerInfo.log" \
> result-04.log 2>&1
注意:
1、输入为onnx模型;
2、–dumpLayerInfo 输出的信息在result-04.log;
3、–exportLayerInfo 输出的信息在model-04-exportLayerInfo.log;
如下图所示为model-04-exportLayerInfo.log保存的内容,其中可以看到每个层信息。

2.6 输出分析信息
# Notice
# + output of "--dumpProfile" locates in result*.log file, output of "--exportProfile" locates in specified file
trtexec \
--loadEngine=./model-02.plan \
--dumpProfile \
--exportTimes="./model-02-exportTimes.json" \
--exportProfile="./model-02-exportProfile.json" \
> result-05.log 2>&1
不常用,NVIDIA的Nsight system可以代替实现。
2.7 指定输入进行测试
# 07-Run TensorRT engine with loading input data
trtexec \
--loadEngine=./model-02.plan \
--loadInputs=tensorX:tensorX.input.1.1.28.28.Float.raw \
--dumpOutput \
> result-07.log 2>&1
三、使用C++API进行转换
#include <iostream>
#include <fstream>
#include "NvInfer.h"
#include "NvOnnxParser.h"
// 实例化记录器界面。捕获所有警告消息,但忽略信息性消息
class Logger : public nvinfer1::ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
void ONNX2TensorRT(const char* ONNX_file, std::string save_ngine)
{
// 1.创建构建器的实例
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
// 2.创建网络定义
uint32_t flag = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(flag);
// 3.创建一个 ONNX 解析器来填充网络
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);
// 4.读取模型文件并处理任何错误
parser->parseFromFile(ONNX_file, static_cast<int32_t>(nvinfer1::ILogger::Severity::kWARNING));
for (int32_t i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
// 5.创建一个构建配置,指定 TensorRT 应该如何优化模型
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 6.设置属性来控制 TensorRT 如何优化网络
// 设置内存池的空间
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 16 * (1 << 20));
// 设置低精度 注释掉为FP32
if (builder->platformHasFastFp16())
{
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
// 7.指定配置后,构建引擎
nvinfer1::IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
// 8.保存TensorRT模型
std::ofstream p(save_ngine, std::ios::binary);
p.write(reinterpret_cast<const char*>(serializedModel->data()), serializedModel->size());
// 9.序列化引擎包含权重的必要副本,因此不再需要解析器、网络定义、构建器配置和构建器,可以安全地删除
delete parser;
delete network;
delete config;
delete builder;
// 10.将引擎保存到磁盘,并且可以删除它被序列化到的缓冲区
delete serializedModel;
}
void exportONNX(const char* ONNX_file, std::string save_ngine)
{
std::ifstream file(ONNX_file, std::ios::binary);
if (!file.good())
{
std::cout << "Load ONNX file failed! No file found from:" << ONNX_file << std::endl;
return ;
}
std::cout << "Load ONNX file from: " << ONNX_file << std::endl;
std::cout << "Starting export ..." << std::endl;
ONNX2TensorRT(ONNX_file, save_ngine);
std::cout << "Export success, saved as: " << save_ngine << std::endl;
}
int main(int argc, char** argv)
{
// 输入信息
const char* ONNX_file = "../weights/test.onnx";
std::string save_ngine = "../weights/test.engine";
exportONNX(ONNX_file, save_ngine);
return 0;
}
注意:动态尺寸时,上面的程序会出现以下错误:
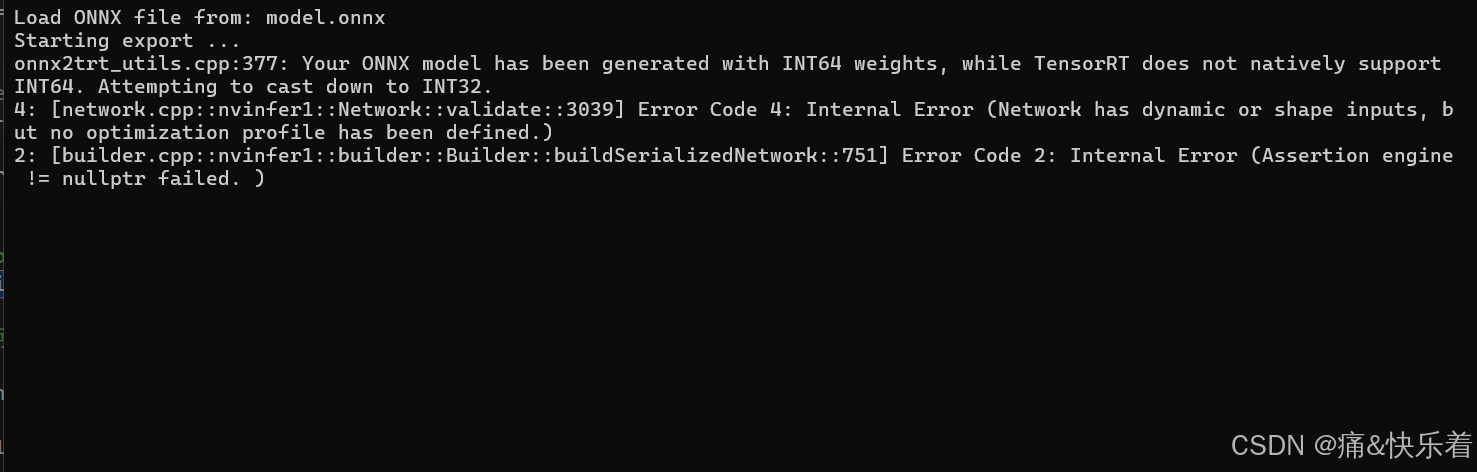
这时第5步的设置更改如下,添加以下动态尺寸。
// 5.创建一个构建配置,指定 TensorRT 应该如何优化模型
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
int minInputSize[4] = { 1, 1, 64, 64 };
int optInputSize[4] = { 1, 1, 256, 256 };
int maxInputSize[4] = { 1, 1, 512, 512 };
auto profile = builder->createOptimizationProfile();
auto input_tensor = network->getInput(0);
auto input_dims = input_tensor->getDimensions();
if (input_dims.d[2] < 0 || input_dims.d[3] < 0)
{
//配置最小允许batch
input_dims.d[0] = minInputSize[0];
input_dims.d[1] = minInputSize[1];
input_dims.d[2] = minInputSize[2];
input_dims.d[3] = minInputSize[3];
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);
//配置最优允许batch
input_dims.d[0] = optInputSize[0];
input_dims.d[1] = optInputSize[1];
input_dims.d[2] = optInputSize[2];
input_dims.d[3] = optInputSize[3];
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);
//配置最大允许batch
input_dims.d[0] = maxInputSize[0];
input_dims.d[1] = maxInputSize[1];
input_dims.d[2] = maxInputSize[2];
input_dims.d[3] = maxInputSize[3];
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
config->addOptimizationProfile(profile);
}
四、导出失败问题排查
查看TensorRT支持的ONNX版本:
TensorRT的文档通常会列出它支持的ONNX版本范围。你可以访问TensorRT的官方文档或GitHub仓库(如https://github.com/onnx/onnx-tensorrt),查找与你安装的TensorRT版本相对应的支持矩阵或版本信息1。
如果TensorRT 8.6.1支持的ONNX版本不包括1.12.0,那么你需要将ONNX模型导出为一个兼容的版本,或者升级/降级你的TensorRT安装。
核对算子支持情况:
即使ONNX版本和TensorRT版本在整体上兼容,也可能存在某些特定算子不被支持的情况。你可以查看TensorRT的文档或GitHub仓库中的算子支持列表,确认你模型中使用的算子是否被支持12。
考虑模型结构和依赖库:
TensorRT对某些特定的模型结构可能不支持,例如包含动态形状或特定操作的模型。此外,确保安装了所有必要的依赖库,并且版本与TensorRT兼容。
测试和验证:
在部署模型之前,确保在目标平台上进行充分的测试和验证。这包括验证模型是否能够正确地加载和执行,以及是否能够达到预期的推理性能。
处理不兼容的情况:
如果确认ONNX模型和TensorRT版本不兼容,你可以考虑以下几种解决方案:修改模型以移除或替换不支持的算子;使用转换工具将模型转换成其他格式(如TensorFlow或PyTorch)再进行部署;或者升级/降级TensorRT或ONNX到兼容的版本23。
重要的是要认识到,不同版本的TensorRT和ONNX之间可能存在兼容性问题。因此,在部署模型之前,务必进行充分的测试和验证,以确保模型在目标平台上能够正确地运行。如果遇到兼容性问题,通过上述步骤进行排查和解决。
参考文献
[1] tensorRT部署之 代码实现 onnx转engine/trt模型
[2] TensorRT入门:trtexec开发辅助工具的使用

















 2354
2354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









