







文章目录
环境准备
ELK所包含软件包下载地址:
点击下载自己所需版本
elasticsearch:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-linux-x86_64.tar.gz
kibana:
https://artifacts.elastic.co/downloads/kibana/kibana-7.17.6-linux-x86_64.tar.gz
filebeat:
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.6-linux-x86_64.tar.gz
Logstash:
https://artifacts.elastic.co/downloads/logstash/logstash-7.17.6-linux-x86_64.tar.gz
Zookeeper:
https://zookeeper.apache.org/releases.html#download
Kafka:
https://kafka.apache.org/downloads
| 节点 | IP | 应用 | |
| elk01 | 10.8.0.2 | es | |
| kibana | |||
| elk02 | 10.8.0.6 | es | |
| filebeat | |||
| elk03 | 10.8.0.9 | es | |
| kafka01 | 10.8.0.10 | zk | |
| kafka | |||
| logstash | |||
| kafka02 | 10.8.0.13 | zk | |
| kafka | |||
| logstash | |||
| kafka03 | 10.8.0.14 | zk | |
| kafka | |||
| logstash | |||
首先是需要开发人员对日志输出进行json规范化
例如下篇帖子
https://blog.csdn.net/qq_38046739/article/details/120324838
我们规范后的日志分为两类
应用日志application.log:
{"app_name":"gotone-payment-api","client_ip":"","context":"","docker_name":"","env":"dev","exception":"","extend1":"","level":"INFO","line":68,"log_message":"现代金控支付查询->调用入参[{}]","log_time":"2023-01-09 10:25:30.025","log_type":"applicationlog","log_version":"1.0.0","method_name":"com.gotone.paycenter.dao.third.impl.modernpay.ModernPayApiAbstract.getModernPayOrderInfo","parent_span_id":"","product_line":"","server_ip":"","server_name":"gotone-payment-api-bc648794d-r8h7z","snooper":"","span":0,"span_id":"","stack_message":"","threadId":104,"trace_id":"gotone-payment-apidd256466-63eb-4c3f-8e27-2c3d6f857bb2","user_log_type":""}
转为json格式:
{
"app_name":"gotone-payment-api",
"client_ip":"",
"context":"",
"docker_name":"",
"env":"dev",
"exception":"",
"extend1":"",
"level":"INFO",
"line":68,
"log_message":"现代金控支付查询->调用入参[{}]",
"log_time":"2023-01-09 10:25:30.025",
"log_type":"applicationlog",
"log_version":"1.0.0",
"method_name":"com.gotone.paycenter.dao.third.impl.modernpay.ModernPayApiAbstract.getModernPayOrderInfo",
"parent_span_id":"",
"product_line":"",
"server_ip":"",
"server_name":"gotone-payment-api-bc648794d-r8h7z",
"snooper":"",
"span":0,
"span_id":"",
"stack_message":"",
"threadId":104,
"trace_id":"gotone-payment-apidd256466-63eb-4c3f-8e27-2c3d6f857bb2",
"user_log_type":""
}
性能日志performancelog.log
{"app_name":"gotone-payment-api","business_code":"","call_chain":"","client_ip":"","docker_name":"","elapsed_time":13,"env":"dev","error_code":"","log_time":"2023-01-09 14:50:30.019","log_type":"performancelog","log_version":"1.0.0","method_name":"com.gotone.paycenter.controller.task.PayCenterJobHandler.queryWithdrawalOrderTask","parent_span_id":"","product_line":"","server_ip":"","server_name":"gotone-payment-api-bc648794d-r8h7z","snooper":"","span_id":"","trace_id":""}
转为json格式:
{
"app_name":"gotone-payment-api",
"business_code":"",
"call_chain":"",
"client_ip":"",
"docker_name":"",
"elapsed_time":13,
"env":"dev",
"error_code":"",
"log_time":"2023-01-09 14:50:30.019",
"log_type":"performancelog",
"log_version":"1.0.0",
"method_name":"com.gotone.paycenter.controller.task.PayCenterJobHandler.queryWithdrawalOrderTask",
"parent_span_id":"",
"product_line":"",
"server_ip":"",
"server_name":"gotone-payment-api-bc648794d-r8h7z",
"snooper":"",
"span_id":"",
"trace_id":""
}
接下来就是将规范后的日志(例如上面这两类日志)进行收集并展示;
一、Elasticsearch分布式集群部署
部署集群方式跟单点步骤其实差不多,只需要将其他节点的配置稍微修改下即可;
部署单点elasticsearch7.17.6
1.设置主机名以及创建elasticsearch的目录
集群内所有节点(elk01、elk02、elk03)一样操作
[root@localhost ~]# cat >> /etc/hosts << EOF
10.8.0.2 elk01
10.8.0.6 elk02
10.8.0.9 elk03
EOF
[root@localhost ~]# hostnamectl set-hostname elk01
`注:每个节点的主机名设置相应的主机名,例如elk02 elk03`
[root@localhost ~]# bash
创建存放elasticsearch数据和日志的目录
[root@elk01 ~]# mkdir -pv /hqtbj/hqtwww/data/{elasticsearch,logs}
mkdir: created directory ‘/hqtbj’
mkdir: created directory ‘/hqtbj/hqtwww’
mkdir: created directory ‘/hqtbj/hqtwww/data’
mkdir: created directory ‘/hqtbj/hqtwww/data/elasticsearch’
mkdir: created directory ‘/hqtbj/hqtwww/data/logs’
2.下载elasticsearch-7.17.6并解压到指定目录
集群内所有节点(elk01、elk02、elk03)一样操作
[root@elk01 ~]# wget -cP /hqtbj/hqtwww/ https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-linux-x86_64.tar.gz
[root@elk01 ~]# cd /hqtbj/hqtwww/
[root@elk01 hqtwww]# tar -zxf elasticsearch-7.17.6-linux-x86_64.tar.gz
[root@elk01 hqtwww]# mv elasticsearch-7.17.6 elasticsearch_workspace
3.部署Oracle JDK环境
集群内所有节点(elk01、elk02、elk03)一样操作
这里我们不使用elasticsearch自带的OpenJDK,我们手动部署Oracle JDK
软件包下载地址(需要使用oracle账号登录下载):
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
先将elasticsearch自带的jdk备份(~/elasticsearch/jdk)
[root@elk01 ~]# mv /hqtbj/hqtwww/elasticsearch_workspace/jdk /hqtbj/hqtwww/elasticsearch_workspace/jdk.default
解压oracle jdk到elasticsearch目录下并命名为jdk
[root@elk01 ~]# tar -zxf jdk-8u211-linux-x64.tar.gz
[root@elk01 ~]# mv jdk1.8.0_211 /hqtbj/hqtwww/elasticsearch_workspace/jdk
---`这里解释下为什么要把oracle jdk放到elasticsearch目录下:因为后面会去
用systemd来管理elasticsearch,但是用systemd不会去用全局的系统变量,
就会依着elasticsearch去使用自带的OpenJDK,所以这一步相当于是直接把elasticsearch自带的环境变量替换成了Oracle JDK`---
配置jdk环境变量
[root@elk01 ~]# cat >> /etc/profile.d/elasticsearch.sh << EOF
JAVA_HOME=/hqtbj/hqtwww/elasticsearch_workspace/jdk
PATH=/hqtbj/hqtwww/elasticsearch_workspace/jdk/bin:/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export JAVA_HOME PATH
EOF
[root@elk01 ~]# source /etc/profile.d/elasticsearch.sh
[root@elk01 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
4.修改elasticsearch的配置文件
elasticsearch的主配置文件是~/config/elasticsearch.yml
elk01操作
备份初始配置文件
[root@elk01 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml.default
[root@elk01 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
cluster.name: HQT-ELK-PROD #集群名称-集群内所有节点保持一致
node.name: elk01 #节点名称
path.data: /hqtbj/hqtwww/data/elasticsearch #存放数据的目录
path.logs: /hqtbj/hqtwww/data/logs #存放日志的目录
network.host: 10.8.0.2 #ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
discovery.seed_hosts: ["elk01","elk02","elk03"] #服务发现的主机列表,用于发现集群内其它的节点;
cluster.initial_master_nodes: ["elk01","elk02","elk03"] #首次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定了在第一次选举中便对其票数进行计数的有资格成为集群中主节点的节点的集合(投票的目的是选出集群的主节点)。在开发模式中,集群引导步骤由节点们自动引导,但在生产环境中这种自动引导的方式不安全,cluster.initial_master_nodes参数提供一个列表,列表中是全新集群启动时,有资格成为集群主节点的节点(这些节点要被投票决定谁成为集群主节点),它在集群重启或添加新节点到集群时时不起作用的;
参数说明:
–cluster.name:集群名称,同一集群内的节点集群名称需要统一;
–node.name:当前节点名称;
–path.data:存放elasticsearch数据的目录;
–path.logs:存放elasticsearch日志的目录;
–network.host:ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
–discovery.seed_hosts:服务发现的主机列表,用于发现集群内其它的节点;
–cluster.initial_master_nodes:首次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定了在第一次选举中便对其票数进行计数的有资格成为集群中主节点的节点的集合(投票的目的是选出集群的主节点)。在开发模式中,集群引导步骤由节点们自动引导,但在生产环境中这种自动引导的方式不安全,cluster.initial_master_nodes参数提供一个列表,列表中是全新集群启动时,有资格成为集群主节点的节点(这些节点要被投票决定谁成为集群主节点),它在集群重启或添加新节点到集群时时不起作用的;
elk02操作
elk02、03只需要将elk01的elasticsearch配置文件复制过来一份修改主机名称和监听的IP地址即可;
备份原配置文件
[root@elk02 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml.default
将elk01的配置文件scp到elk02的~elasticsearch/config下
[root@elk02 ~]# scp -pr root@10.8.0.2:/hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
修改配置为文件为elk02
[root@elk02 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
cluster.name: HQT-ELK-PROD #集群名称
node.name: elk02 `需要修改为elk02的节点名称`
path.data: /hqtbj/hqtwww/data/elasticsearch #存放数据的目录
path.logs: /hqtbj/hqtwww/data/logs #存放日志的目录
network.host: 10.8.0.6 `需要修改为elk02监听的地址` #ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
discovery.seed_hosts: ["elk01","elk02","elk03"] #服务发现的主机列表,用于发现集群内其它的节点;
cluster.initial_master_nodes: ["elk01","elk02","elk03"]
elk03操作
备份原配置文件
[root@elk03 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml.default
将elk01的配置文件scp到elk03的~elasticsearch/config下
[root@elk03 ~]# scp -pr root@10.8.0.2:/hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
修改配置为文件为elk03
[root@elk03 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
cluster.name: HQT-ELK-PROD #集群名称
node.name: elk03 `需要修改为elk03的节点名称`
path.data: /hqtbj/hqtwww/data/elasticsearch #存放数据的目录
path.logs: /hqtbj/hqtwww/data/logs #存放日志的目录
network.host: 10.8.0.9 `需要修改为elk03监听的地址` #ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
discovery.seed_hosts: ["elk01","elk02","elk03"] #服务发现的主机列表,用于发现集群内其它的节点;
cluster.initial_master_nodes: ["elk01","elk02","elk03"]
5.创建ES用户(用于运行ES服务)并设置内核参数
集群内所有节点(elk01、elk02、elk03)一样操作
创建es用户并授权
[root@elk01 ~]# useradd es
[root@elk01 ~]# chown -R es:es /hqtbj/hqtwww/elasticsearch_workspace/
[root@elk01 ~]# chown -R es:es /hqtbj/hqtwww/data/
修改打开文件的数量
[root@elk01 ~]# cat > /etc/security/limits.d/elk.conf <<'EOF'
* soft nofile 65535
* hard nofile 131070
EOF
修改内核参数的内存映射信息
[root@elk01 ~]# cat > /etc/sysctl.d/elk.conf <<'EOF'
vm.max_map_count = 262144
EOF
[root@elk01 ~]# sysctl -p /etc/sysctl.d/elk.conf
vm.max_map_count = 262144
6.编写ES启动脚本 并启动
集群内所有节点(elk01、elk02、elk03)一样操作
[root@elk01 ~]# vim /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=elasticsearch-v7.17.6
After=network.target
[Service]
Restart=on-failure
ExecStart=/hqtbj/hqtwww/elasticsearch_workspace/bin/elasticsearch
User=es
Group=es
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
[root@elk01 ~]# systemctl daemon-reload
[root@elk01 ~]# systemctl start elasticsearch
[root@elk01 ~]# systemctl enable elasticsearch
7.修改ES的堆(heap)内存大小
集群内所有节点(elk01、elk02、elk03)一样操作
elasticsearch的jvm配置文件是~/config/jvm.options
先查看此时的堆内存大小
[root@elk01 ~]# jmap -heap `jps | grep Elasticsearch | awk '{print $1}'`
...
MaxHeapSize = 536870912 (512.0MB)
备份并修改
[root@elk01 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options.default
[root@elk01 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options
...
-Xms1g
-Xmx1g
重启elasticsearch服务
[root@elk01 ~]# systemctl restart elasticsearch
验证堆内存大小
[root@elk01 config]# jmap -heap `jps | grep Elasticsearch | awk '{print $1}'`
...
MaxHeapSize = 1073741824 (1024.0MB)
官方建议设置es内存,大小为物理内存的一半,剩下的一半留给luence,这是因为es的内核使用的是luence,luence本身就是单独占用内存的,而且占用的还不少
请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/advanced-configuration.html#jvm-options-syntax
官方提供的查询节点状态API主要查看heap.max项
http://localhosts:9200/_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,master
8.验证
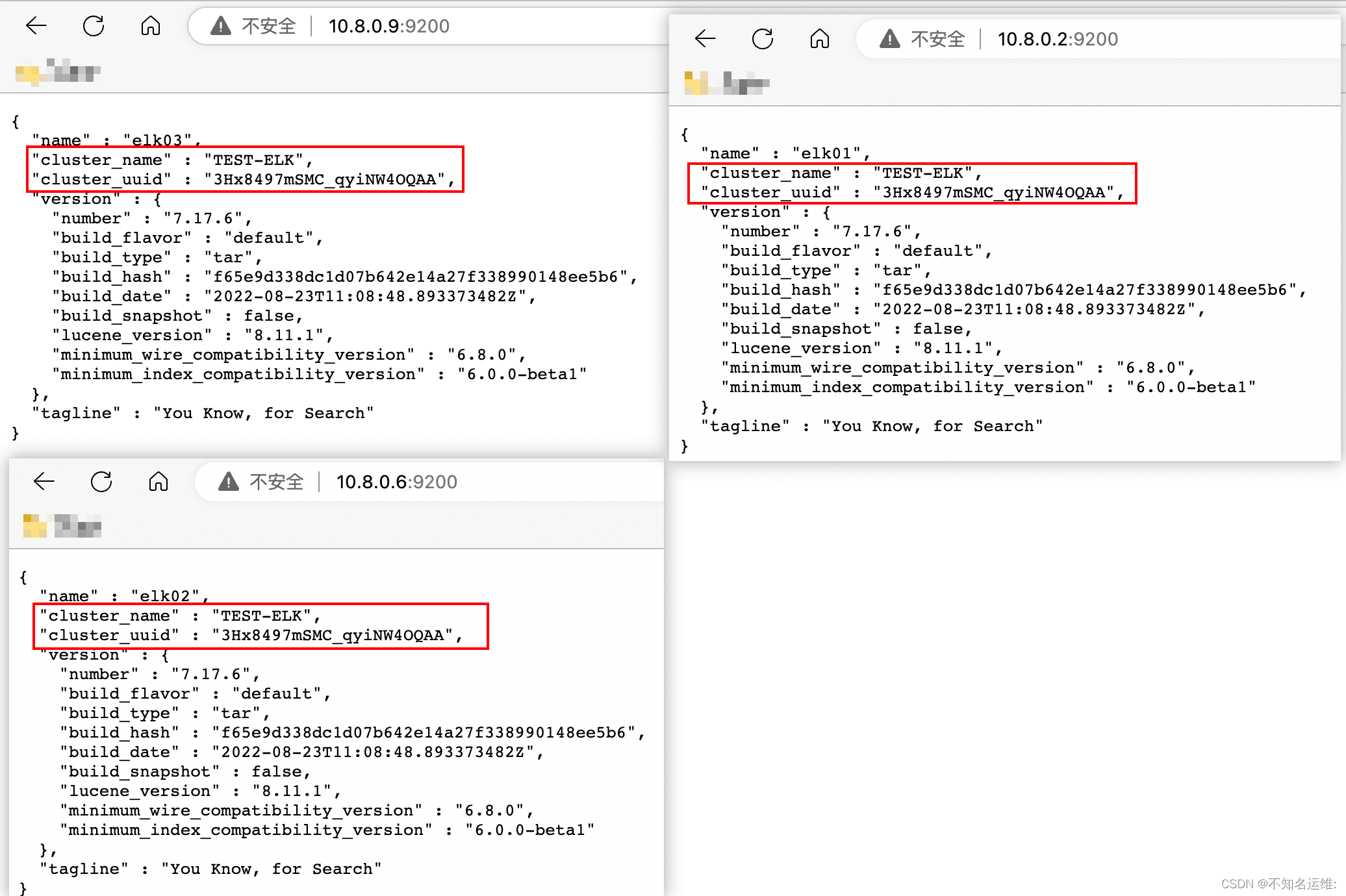
启动成功后去浏览器访问集群中任意一台节点 ip:9200/_cat/nodes 输出以下内容 Elasticsearch集群就部署成功了
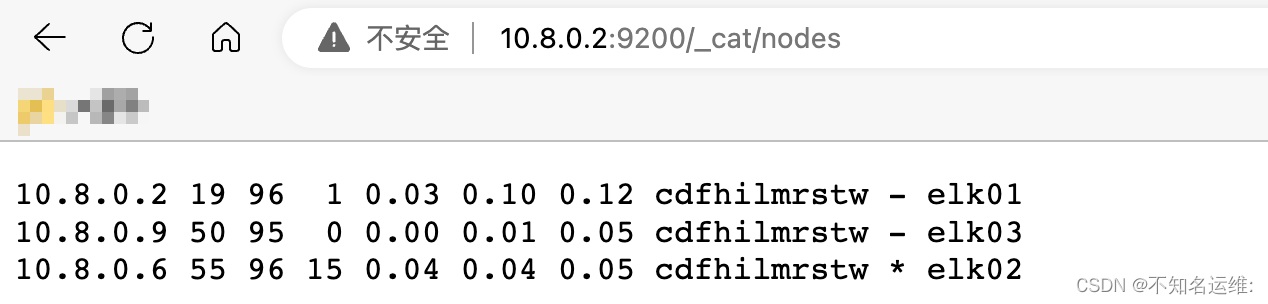
上面显示的就是集群中的节点,带“*”的是master节点;
二、Kibana部署并对接ES集群
1.下载kibana-7.17.6并解压到指定目录
[root@localhost ~]# mkdir -p /hqtbj/hqtwww/
[root@localhost ~]# wget -cP /hqtbj/hqtwww/ https://artifacts.elastic.co/downloads/kibana/kibana-7.17.6-linux-x86_64.tar.gz
[root@localhost ~]# cd /hqtbj/hqtwww/
[root@localhost hqtwww]# tar -zxf kibana-7.17.6-linux-x86_64.tar.gz
[root@localhost hqtwww]# mv kibana-7.17.6-linux-x86_64 kibana_workspace
2.修改kibana的配置文件
kibana的主配置文件是~/config/kibana.yml
[root@localhost ~]# cp -pr /hqtbj/hqtwww/kibana_workspace/config/kibana.yml /hqtbj/hqtwww/kibana_workspace/config/kibana.yml.default
[root@localhost ~]# egrep -v "^#|^$" /hqtbj/hqtwww/kibana_workspace/config/kibana.yml
server.host: "10.8.0.2" #kibana监听的IP地址
server.name: "HQT-Kibana" #kibana的实例名称
elasticsearch.hosts: ["http://10.8.0.2:9200","http://10.8.0.6:9200","http://10.8.0.9:9200"] #ES的连接地址
i18n.locale: "zh-CN" #使用中文
参数说明:
–server.host:kibana监听的IP地址;
–server.name:kibana的实例名称;
–elasticsearch.hosts:ES的连接地址,集群的话中间用,隔开;
–i18n.locale:使用中文;
3.创建kibana启动用户
创建elk用户用于启动kibana
[root@localhost ~]# useradd elk
[root@localhost ~]# chown -R elk:elk /hqtbj/hqtwww/kibana_workspace
4.编写kibana的启动脚本并启动
[root@localhost ~]# cat > /usr/lib/systemd/system/kibana.service << EOF
[Unit]
Description=kibana-v7.17.6
After=network.target
[Service]
Restart=on-failure
ExecStart=/hqtbj/hqtwww/kibana_workspace/bin/kibana
User=elk
Group=elk
[Install]
WantedBy=multi-user.target
EOF
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl start kibana.service
[root@localhost ~]# systemctl enable kibana.service
启动后浏览器访问
http://10.8.0.2:5601/
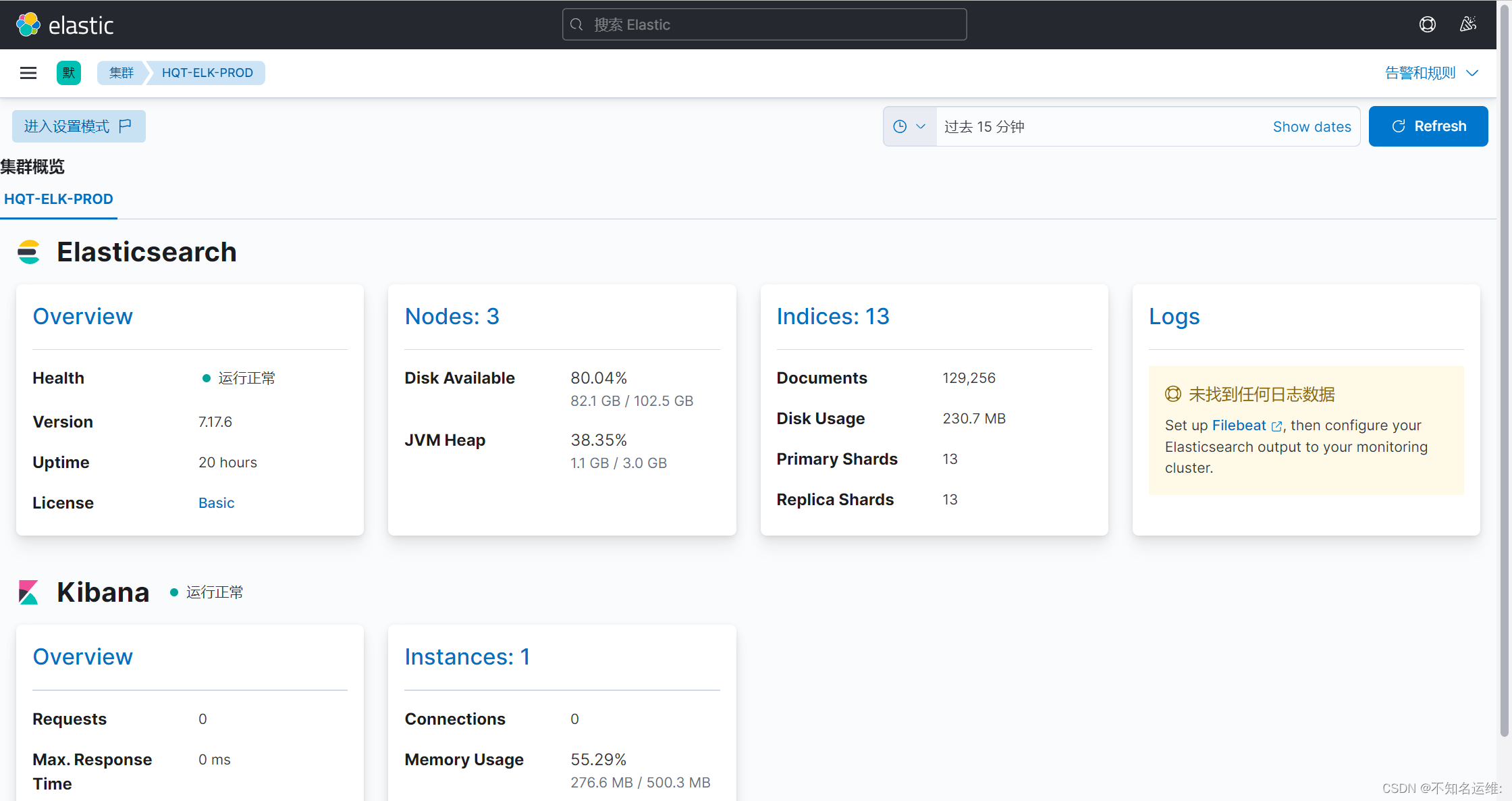
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)堆栈检测;
这样就能看elasticsearch集群的状态和kibana的状态;
创建索引模版:
生产建议10分片+2副本
三、zookeeper集群部署
1.下载zookeeper软件包并解压
三台节点同操作
#jdk环境#
[root@logstash_kafka01 ~]# tar zxf jdk-8u211-linux-x64.tar.gz
[root@logstash_kafka01 ~]# mv jdk1.8.0_211 /usr/local/java
[root@logstash_kafka01 ~]# vim /etc/profile
##jdk 8 ##
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
[root@logstash_kafka01 ~]# source /etc/profile
[root@logstash_kafka01 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
###
[root@kafka01 ~]# wget -c --no-check-certificate https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
[root@kafka01 ~]# tar -zxf apache-zookeeper-3.8.0-bin.tar.gz
[root@kafka01 ~]# mv apache-zookeeper-3.8.0-bin /hqtbj/hqtwww/zookeeper_workspace
[root@kafka01 ~]# cp -pr /hqtbj/hqtwww/zookeeper_workspace/conf/zoo_sample.cfg /hqtbj/hqtwww/zookeeper_workspace/conf/zoo.cfg
2.配置zookeeper
三台节点同操作
[root@kafka01 ~]# egrep -v "^$|^#" /hqtbj/hqtwww/zookeeper_workspace/conf/zoo.cfg
#zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳数据包,tickTime以毫秒为单位;
tickTime=2000
#集群中的follower服务器与leader服务器之间初始连接时能容忍的最多心跳数(tickTime的数量); 响应时间=initLimit * tickTime
initLimit=10
#集群中leader服务器和follower之间最大响应时间单位,在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态,如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了,就会剔除这个follower节点;
syncLimit=5
#zookeeper保存数据的目录;
dataDir=/hqtbj/hqtwww/zookeeper_workspace/data
#Zookeeper 监听的端口,用来接受客户端的访问请求;
clientPort=2181
#定义集群信息,格式如下:
server.1=10.8.0.10:2888:3888
server.2=10.8.0.13:2888:3888
server.3=10.8.0.14:2888:3888
# server.ID=A:B:C[:D]
# ID:
# zk的唯⼀编号。
# A:
# zk的主机地址。
# B:
# leader的选举端⼝,是谁leader⻆⾊,就会监听该端⼝。
# C:
# 数据通信端⼝。
# D:
# 可选配置,指定⻆⾊
节点1操作
#创建zookeeper的数据存放目录
[root@kafka01 ~]# mkdir -p /hqtbj/hqtwww/zookeeper_workspace/data
#集群节点不能myid不能相同,节点2需要echo "2",节点3需要echo "3"
[root@kafka01 ~]# echo "1" > /hqtbj/hqtwww/zookeeper_workspace/data/myid
节点2操作
#创建zookeeper的数据存放目录
[root@kafka02 ~]# mkdir -p /hqtbj/hqtwww/zookeeper_workspace/data
#集群节点不能myid不能相同,节点2需要echo "2",节点3需要echo "3"
[root@kafka02 ~]# echo "2" > /hqtbj/hqtwww/zookeeper_workspace/data/myid
节点3操作
#创建zookeeper的数据存放目录
[root@kafka03 ~]# mkdir -p /hqtbj/hqtwww/zookeeper_workspace/data
#集群节点不能myid不能相同,节点2需要echo "2",节点3需要echo "3"
[root@kafka03 ~]# echo "3" > /hqtbj/hqtwww/zookeeper_workspace/data/myid
3.启动zookeeper
[root@kafka01 ~]# /hqtbj/hqtwww/zookeeper_workspace/bin/zkServer.sh start
[root@kafka01 ~]# /hqtbj/hqtwww/zookeeper_workspace/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /hqtbj/hqtwww/zookeeper_workspace/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@kafka01 ~]# /hqtbj/hqtwww/zookeeper_workspace/bin/zkCli.sh -server 10.8.0.10:2181,10.8.0.13:2181,10.8.0.14:2181
...
[zk: 10.8.0.10:2181,10.8.0.13:2181,10.8.0.14:2181(CONNECTED) 1] ls /
[zookeeper]
也可以设置zk的环境变量然后再启动
[root@logstash_kafka01 ~]# cat > /etc/profile.d/zk.sh << EOF
#!/bin/bash
export ZK_HOME=/hqtbj/hqtwww/zookeeper_workspace
export PATH=$PATH:$ZK_HOME/bin
EOF
[root@logstash_kafka01 ~]# source /etc/profile.d/kafka.sh
[root@logstash_kafka01 ~]# zkServer.sh start
四、kafka集群部署
1.下载kafka软件包并解压
三台节点同操作
[root@kafka01 ~]# wget -c https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
[root@kafka01 ~]# tar -zxf kafka_2.13-3.2.0.tgz
[root@kafka01 ~]# mv kafka_2.13-3.2.0 /hqtbj/hqtwww/kafka_workspace
[root@kafka01 ~]# cp /hqtbj/hqtwww/kafka_workspace/config/server.properties /hqtbj/hqtwww/kafka_workspace/config/server.properties.default
2.配置kafka
节点1操作
[root@kafka01 ~]#vim /hqtbj/hqtwww/kafka_workspace/config/server.properties
#当前机器在集群中的唯一标识,和zookeeper的myid性质一样,必须是正数,当该服务器的IP地址发生改变时,只要broker.id没有变,则不会影响consumers的消费情况;
broker.id=1
#kafka监听的地址,如果只是公司内网服务使用的话使用listeners就可以,如果外网服务需要连接kafka的话,则需要另配置advertised.listeners,如下;
listeners=PLAINTEXT://10.8.0.10:9092
#advertised.listeners=PLAINTEXT://公网IP:9092
#处理网络请求的最大线程数
num.network.threads=3
#处理磁盘I/O的线程数
num.io.threads=8
#发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能;(发送缓冲区)
socket.send.buffer.bytes=5242880
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘;(接受缓冲区)
socket.receive.buffer.bytes=5242880
#套接字服务器将接受的请求的最⼤⼤⼩,这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小 104857600B = 100M (防止oom);
socket.request.max.bytes=104857600
#在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数,适量增大queued.max.requests能够缓存更多的请求,以撑过业务峰值。如果过大,会造成内存的浪费;
queued.max.requests=1000
#日志的存放目录;
log.dirs=/hqtbj/hqtwww/kafka_workspace/logs
#默认topic的分区数,一个topic默认1个分区数,这里设置8个分区,是为了后面logstash更好的消费;因为同一消费者组内的多个logstash可以同时消费kafka内topic的数据,从而提高logstash的处理能力,但需要注意的是消费kafka数据时,每个consumer最多只能使用一个partition,当一个Group内consumer的数量大于partition的数量时,只有等于partition个数的consumer能同时消费,其他的consumer处于等待状态。例如一个topic下有3个partition,那么在一个有5个consumer的group中只有3个consumer在同时消费topic的数据,而另外两个consumer处于等待状态,所以想要增加logstash的消费性能,可以适当的增加topic的partition数量,但kafka中partition数量过多也会导致kafka集群故障恢复时间过长,消耗更多的文件句柄与客户端内存等问题,也并不是partition配置越多越好,需要在使用中找到一个平衡。
num.partitions=40
#默认副本数,默认分区副本数不得超过kafka节点数,生产环境一般配置2个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率;
default.replication.factor=3
#在启动时用于日志恢复和在关闭时刷新的每个数据目录的线程数,对于数据目录位于RAID阵列中的安装,建议增加此值;
num.recovery.threads.per.data.dir=1
#新版本kafka的各个consumer的offset位置默认是在某一个broker当中的topic中保存的:"__consumer_offsets",(为防止该broker宕掉无法获取offset信息,可以配置在每个broker中都进行保存,配置文件中配置),单节点应为1;
offsets.topic.replication.factor=3
#事务topic的复制因子(设置较高来确保可用性)。内部topic创建将失败,直到集群规模满足该复制因子要求,建议值跟brocker数量一致;
transaction.state.log.replication.factor=3
#覆盖事务topic的min.insync.replicas配置。常见的场景是创建一个三副本(即replication.factor=3)的topic,最少同步副本数设为2(即min.insync.replicas=2),acks设为all,以保证最高的消息持久性。
transaction.state.log.min.isr=2
#服务器接受单个消息的最⼤⼤⼩,即消息体的最⼤⼤⼩,单位是字节,下⾯是100MB;
message.max.bytes=104857600
#实现topic Leader的自动负载均衡,在创建一个topic时,kafka尽量将partition均分在所有的brokers上,并且将replicas也均分在不同的broker上,每个partitiion的所有replicas叫做"assigned replicas","assigned replicas"中的第一个replicas叫"preferred replica",刚创建的topic一般"preferred replica"是leader。leader replica负责所有的读写。但随着时间推移,broker可能会停机,会导致leader迁移,导致机群的负载不均衡。我们期望对topic的leader进行重新负载均衡,让partition选择"preferred replica"做为leader。
auto.leader.rebalance.enable=true
#日志保存的时间 (hours|minutes),默认为7天(168⼩时);
log.retention.hours=168
#单个日志文件的最大大小,如果超过次大小,将创建新的日志文件;
log.segment.bytes=536870912
#⽇志⽚段⽂件的检查周期,查看它们是否达到了删除策略的设(log.retention.hours或log.retention.bytes);
log.retention.check.interval.ms=300000
#zookeeper集群的地址,可以是多个,多个之间⽤逗号分割;
zookeeper.connect=10.8.0.10:2181,10.8.0.13:2181,10.8.0.14:2181
#连接zookeeper的最大等待时间;
zookeeper.connection.timeout.ms=18000
#当新的消费者加入消费者组时,或当一个topic的分区数量增大时,消费者组的各个消费者将重新分配,触发rebalance,即重新分配待消费分区的所属权;此配置的意思是分组协调器在执行第一次重新平衡之前,等待更多消费者加入新组的时间(默认3s);
group.initial.rebalance.delay.ms=3000
[root@kafka01 ~]# mkdir -pv /hqtbj/hqtwww/kafka_workspace/logs
节点2操作
[root@kafka02 ~]# egrep -v "^#|^$" /hqtbj/hqtwww/kafka_workspace/config/server.properties
broker.id=2
listeners=PLAINTEXT://10.8.0.13:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=5242880
socket.receive.buffer.bytes=5242880
socket.request.max.bytes=104857600
queued.max.requests=1000
log.dirs=/hqtbj/hqtwww/kafka_workspace/logs
num.partitions=3
default.replication.factor=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
message.max.bytes=104857600
auto.leader.rebalance.enable=true
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.8.0.10:2181,10.8.0.13:2181,10.8.0.14:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=3
[root@kafka02 ~]# mkdir -pv /hqtbj/hqtwww/kafka_workspace/logs
节点3操作
[root@kafka03 ~]# egrep -v "^#|^$" /hqtbj/hqtwww/kafka_workspace/config/server.properties
broker.id=3
listeners=PLAINTEXT://10.8.0.14:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=5242880
socket.receive.buffer.bytes=5242880
socket.request.max.bytes=104857600
queued.max.requests=1000
log.dirs=/hqtbj/hqtwww/kafka_workspace/logs
num.partitions=3
default.replication.factor=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
message.max.bytes=104857600
auto.leader.rebalance.enable=true
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.8.0.10:2181,10.8.0.13:2181,10.8.0.14:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=3
[root@kafka03 ~]# mkdir -pv /hqtbj/hqtwww/kafka_workspace/logs
3.启动kafka
[root@kafka01 ~]# /hqtbj/hqtwww/kafka_workspace/bin/kafka-server-start.sh -daemon /hqtbj/hqtwww/kafka_workspace/config/server.properties
[root@kafka01 ~]# ss -unptl| grep 9092
tcp LISTEN 0 50 [::ffff:10.8.0.10]:9092 [::]:* users:(("java",pid=27394,fd=133))
[root@kafka01 ~]# cat /hqtbj/hqtwww/kafka_workspace/logs/meta.properties
#
#Sun Jan 08 16:47:34 CST 2023
cluster.id=gzCyEWf5TWSWOlkIfBUvHQ
version=0
broker.id=1
#去zookeeper下验证kafka集群是否都注册上了
[root@kafka01 ~]# /hqtbj/hqtwww/zookeeper_workspace/bin/zkCli.sh ls /brokers/ids | grep "^\["
[1, 2, 3] #broker.id 三台都已注册;
也可以设置kafka的环境变量然后再启动
[root@logstash_kafka01 ~]# cat > /etc/profile.d/kafka.sh << EOF
#!/bin/bash
export KAFKA_HOME=/hqtbj/hqtwww/kafka_workspace
export PATH=$PATH:$KAFKA_HOME/bin
EOF
[root@logstash_kafka01 ~]# source /etc/profile.d/kafka.sh
[root@logstash_kafka01 ~]# kafka-server-start.sh -daemon /hqtbj/hqtwww/kafka_workspace/config/server.properties
4.创建生产者与消费者验证
生产者
在kafka01节点上创建生产者,并发送任意消息;
[root@kafka01 ~]# /hqtbj/hqtwww/kafka_workspace/bin/kafka-console-producer.sh --topic test-2022-0108-elk --bootstrap-server 10.8.0.10:9092
>1111
>2222
>abcd
消费者
在kafka02或者03节点上创建消费者,消息会同步生产者,即消费成功;
[root@kafka02 ~]# /hqtbj/hqtwww/kafka_workspace/bin/kafka-console-consumer.sh --topic test-2022-0108-elk --bootstrap-server 10.8.0.13:9092 --from-beginning
1111
2222
abcd
五、Filebeat部署
1.下载filebeat软件包并解压
[root@elk02 ~]# mkdir -p /hqtbj/hqtwww/
[root@elk02 ~]# wget -cP /hqtbj/hqtwww/ https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.6-linux-x86_64.tar.gz
[root@elk02 ~]# cd /hqtbj/hqtwww/
[root@elk02 hqtwww]# tar -zxf filebeat-7.17.6-linux-x86_64.tar.gz
[root@elk02 hqtwww]# mv filebeat-7.17.6-linux-x86_64 filebeat_workspace
2.配置filebeat
[root@elk02 hqtwww]# mkdir filebeat_workspace/config
[root@elk02 hqtwww]# vim filebeat_workspace/config/gotone-applogs-kafka.yml
filebeat.inputs:
- type: log
enabled: true
#指定要收集的日志路径;
paths:
- /tmp/*/application/application.log
#自定义添加两个字段,含义如下;
fields:
#kafka创建的topic名称;
log_topic: gotone-pro-log
#表明收集的是什么日志(用于后面根据不同的日志写入不同的es索引);
log_type: application_log
- type: log
enabled: true
#指定要收集的日志路径;
paths:
- /tmp/*/performancelog/performancelog.log
#自定义添加两个字段,含义如下;
fields:
#kafka创建的topic名称;
log_topic: gotone-pro-log
#表明收集的是什么日志(用于后面根据不同的日志写入不同的es索引);
log_type: performance_log
#输出到kafka
output.kafka:
#kafka集群的地址
hosts: ["10.8.0.10:9092","10.8.0.13:9092","10.8.0.14:9092"]
#输出到kafka的哪个topic,这里就用到了我们上面声明的"log_topic"
topic: '%{[fields.log_topic]}'
3.启动filebeat
[root@elk02 hqtwww]# vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=filebeat-v7.17.6
After=network.target
[Service]
Restart=always
Environment="BEAT_CONFIG_OPTS=-e -c /hqtbj/hqtwww/filebeat_workspace/config/gotone-applogs-kafka.yml"
ExecStart=/hqtbj/hqtwww/filebeat_workspace/filebeat $BEAT_CONFIG_OPTS
User=root
Group=root
EOF
[root@elk02 hqtwww]# systemctl daemon-reload
[root@elk02 hqtwww]# systemctl start filebeat.service
[root@elk02 hqtwww]# systemctl enable filebeat.service
#日志可以去filebeat家目录下面的logs/里查看
#或通过"journalctl -f -u filebeat.service"命令查看
或nohup后台启动
[root@elk02 hqtwww]# cd/hqtbj/hqtwww/filebeat_workspace/logs
[root@elk02 logs]# nohup /hqtbj/hqtwww/filebeat_workspace/filebeat -e -c /hqtbj/hqtwww/filebeat_workspace/config/gotone-applogs-kafka.yml > nohup.filebeat 2<&1 &
六、logstash高可用部署 (单通道多节点模式)
1.下载logstash软件包并解压
需要jdk环境
[root@kafka01 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
(1)下载解压lostash
[root@kafka01 ~]# mkdir -p /hqtbj/hqtwww/
[root@kafka01 ~]# wget -cP /hqtbj/hqtwww/ https://artifacts.elastic.co/downloads/logstash/logstash-7.17.6-linux-x86_64.tar.gz
[root@kafka01 ~]# cd /hqtbj/hqtwww/
[root@kafka01 hqtwww]# tar -zxf logstash-7.17.6-linux-x86_64.tar.gz
[root@kafka01 hqtwww]# mv logstash-7.17.6 logstash_workspace
2.配置logstash
节点1操作
(2)修改配置文件编写测试案例
[root@kafka01 ~]# mkdir /hqtbj/hqtwww/logstash_workspace/conf.d
[root@kafka01 ~]# vim /hqtbj/hqtwww/logstash_workspace/conf.d/gotone-kafka-to-es.conf
input {
kafka {
#kafka集群地址
bootstrap_servers => "10.8.0.10:9092,10.8.0.13:9092,10.8.0.14:9092"
#唯一标识一个group,具有相同group_id的消费者(consumer)构成了一个消费者组(consumer group),这样启动多个logstash实例,只需要保证group_id一致就能达到logstash高可用的目的,一个logstash挂掉同一Group内的logstash可以继续消费;
group_id => "gotone-pro-log"
#多台logstash实例(客户端)同时消费一个topics时,client_id需要指定不同的名字
client_id => "logstash01"
#指定消费的topic,也就是filebeat输出到的topic;
topics => ["gotone-pro-log"]
#Kafka中如果没有初始偏移量或偏移量超出范围时自动将偏移量重置为最新偏移量;
auto_offset_reset => "latest"
#Logstash开启多线程并行消费kafka数据;
consumer_threads => 8
#logstash消费者 请求kafka(例如,获取消息、提交偏移量等)的超时时间 默认为30,000 毫秒(30 秒);
request_timeout_ms => "305000"
#可向事件添加Kafka元数据,比如主题、消息大小、消息偏移量的选项,这将向logstash事件中添加一个名为kafka的字段,经过配置可以在一定程度上实现避免重复数据;
decorate_events => true
#设置数据格式,es是按照json格式存储数据的,上面的例子中,我们输入到kafka的数据是json格式的,但是经Logstash写入到es之后,整条数据变成一个字符串存储到message字段里面了;如果我们想要保持原来的json格式写入到es,就得配置这个格式化;
codec => json
}
}
filter {
if [fields][log_type] in [ "application_log","performance_log" ] {
json {
source => "message"
}
date {
match => [ "log_time", "yyyy-MM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
}
output {
stdout {}
if [fields][log_type] in [ "application_log","performance_log" ] {
elasticsearch {
hosts => ["10.8.0.2:9200","10.8.0.6:9200","10.8.0.9:9200"]
index => "hqt-gotone-pro-%{+YYYY.MM.dd}"
}
}
}
节点2操作
[root@kafka02 ~]# vim /hqtbj/hqtwww/logstash_workspace/conf.d/gotone-kafka-to-es.conf
input {
kafka {
bootstrap_servers => "10.8.0.10:9092,10.8.0.13:9092,10.8.0.14:9092"
group_id => "gotone-pro-log"
client_id => "logstash02"
topics => ["gotone-pro-log"]
auto_offset_reset => "latest"
consumer_threads => 8
request_timeout_ms => "305000"
decorate_events => true
codec => json
}
}
filter {
if [fields][log_type] in [ "application_log","performance_log" ] {
json {
source => "message"
}
date {
match => [ "log_time", "yyyy-MM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
}
output {
stdout {}
if [fields][log_type] in [ "application_log","performance_log" ] {
elasticsearch {
hosts => ["10.8.0.2:9200","10.8.0.6:9200","10.8.0.9:9200"]
index => "hqt-gotone-pro-%{+YYYY.MM.dd}"
}
}
}
节点3操作
[root@kafka03 ~]# vim /hqtbj/hqtwww/logstash_workspace/conf.d/gotone-kafka-to-es.conf
input {
kafka {
bootstrap_servers => "10.8.0.10:9092,10.8.0.13:9092,10.8.0.14:9092"
group_id => "gotone-pro-log"
client_id => "logstash03"
topics => ["gotone-pro-log"]
auto_offset_reset => "latest"
consumer_threads => 8
request_timeout_ms => "305000"
decorate_events => true
codec => json
}
}
filter {
if [fields][log_type] in [ "application_log","performance_log" ] {
json {
source => "message"
}
date {
match => [ "log_time", "yyyy-MM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
}
output {
stdout {}
if [fields][log_type] in [ "application_log","performance_log" ] {
elasticsearch {
hosts => ["10.8.0.2:9200","10.8.0.6:9200","10.8.0.9:9200"]
index => "hqt-gotone-pro-%{+YYYY.MM.dd}"
}
}
}
logstash04\05\跟01\02\03配置一样,只是需要修改client_id
重要配置说明:
group_id => “gotone-pro-log”:
#唯一标识一个group,具有相同group_id的消费者(consumer)构成了一个消费者组(consumer group),这样启动多个logstash实例,只需要保证group_id一致就能达到logstash高可用的目的,一个logstash挂掉同一个消费者组(consumer group)内的logstash可以继续消费;
auto_offset_reset => “latest”:
#Kafka中如果没有初始偏移量或偏移量超出范围时自动将偏移量重置为最新偏移量;
举个例子:2023.01.09当天下午13:00有一个名为test-2023.01.09的索引由于磁盘问题空间问题导致es无法正常写入数据;
当我们删除此索引(用于清理磁盘空间)后 发现这个索引又会重新生成并从2023.01.09凌晨00:00点开始写当天的数据,当写到下午13点时磁盘就又会满;这样就会始终无法获取最新的日志数据;
此时,我们只需要将kafka的test-2023.01.09这个索引所在的topic删除(此时时间是下午15:00),topic在重建后就会找不到之前的偏移量,就会从最新的日志开始输出;这样我们看到的日志就会从最新(下午15:00)的开始;注:此操作可以在测试环境自己理解意思,在生产环节千万要注意不要乱搞!!!!!
consumer_threads => 2
#Logstash的input读取数的时候可以多线程并行读取,logstash-input-kafka插件中对应的配置项是consumer_threads,默认值为1。一般这个默认值不是最佳选择,那这个值该配置多少呢?这个需要对kafka的模型有一定了解:
- kafka的topic是分区的,数据存储在每个分区内;
- kafka的
consumer(消费者)是分组的,任何一个consumer(消费者)属于某一个consumer group(消费者组),一个consumer group(消费者组)可以包含多个consumer,同一消费者组内的消费者不能同时消费一个分区(partition)的数据;
例如一个topic下有1个分区(partition),那么在一个有3个消费者consumer的消费者组(consumer group)中只有1个消费者(consumer)在消费topic的数据,而另外两个消费者(consumer)则处于等待状态;这样肯定是达不到充分的高可用;
所以,对于kafka的消费者(consumer),一般最佳配置是同一个consumer group(消费者组)内消费者(consumer)个数(或线程数)等于topic的分区(partition)数,这样consumer就会均分topic的分区,达到比较好的均衡效果。
举个例子,比如一个topic有n个分区(partition),消费者(consumer)有m个线程。那最佳场景就是n=m,此时一个线程消费一个分区。如果n小于m,即线程数多于分区(partition)数,那多出来的线程就会空闲。
如果n大于m,那就会存在一些线程同时消费多个分区(partition)的数据,造成线程间负载不均衡。
所以,一般consumer_threads配置为你消费的topic的所包含的分区(partition)个数即可。如果有多个Logstash实例,那就让logstash实例个数 * consumer_threads等于分区(partition)数即可。
综上所述:我们的topic设置的是6个分区,logstash的节点为三个,所以想要logstash实现更好的消费,那么每个logstash的消费者(consumer)线程应为2个,3(logstash节点数)*2(消费者线程数)=6(topic分区数量),也就是我们上面配置的"consumer_threads => 2"
没有配置consumer_threads,使用默认值1,可以在Logstash中看到如下日志:
[2023-01-10T10:07:17,331][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][c3e19c39a2cd2881fd137177719b505215f6c6e467c3b096e6badaf2df25961e] [Consumer clientId=logstash01-0, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-5, gotone-pro-log-4, gotone-pro-log-3, gotone-pro-log-2, gotone-pro-log-1, gotone-pro-log-0
因为只有一个consumer,所以6个分区都分给了它;
这次我们将consumer_threads设置成了6,看下效果:
[2023-01-10T10:10:02,549][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-5, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-5
[2023-01-10T10:10:02,549][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-2, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-2
[2023-01-10T10:10:02,551][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-1, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-1
[2023-01-10T10:10:02,551][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-4, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-4
[2023-01-10T10:10:02,550][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-0, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-0
[2023-01-10T10:10:02,550][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][e98b66199ec64f60c1f0f9b5f59268325c152d5cb584c7ab3f11ef2508e2e792] [Consumer clientId=logstash01-3, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-3
可以看到有6个线程,即6个consumer,所以各分到一个partition;
如下是三个logstash实例都将consumer_threads设置成2(启动logstash后的日志效果:
#logstash节点1
[2023-01-10T09:47:12,483][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][6517b79bb9ec7e8d23ca4334f107b081c1ea5074897901ec10c89c30f2b93126] [Consumer clientId=logstash01-1, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-1
[2023-01-10T09:47:12,484][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][6517b79bb9ec7e8d23ca4334f107b081c1ea5074897901ec10c89c30f2b93126] [Consumer clientId=logstash01-0, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-0
#logstash节点2
[2023-01-10T09:47:12,528][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][5f1de94b693d063898bd11550fa57003d39682c72054fd1a67473e021a279c3a] [Consumer clientId=logstash02-1, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-3
[2023-01-10T09:47:12,528][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][5f1de94b693d063898bd11550fa57003d39682c72054fd1a67473e021a279c3a] [Consumer clientId=logstash02-0, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-2
#logstash节点3
[2023-01-10T09:47:12,541][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][26df688be6374469bef66b7f8cb83a47372aad91824fb1dab8a4a1177ee22fe2] [Consumer clientId=logstash03-0, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-4
[2023-01-10T09:47:12,541][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator][main][26df688be6374469bef66b7f8cb83a47372aad91824fb1dab8a4a1177ee22fe2] [Consumer clientId=logstash03-1, groupId=gotone-pro-log] Adding newly assigned partitions: gotone-pro-log-5
可以看到3个实例各有2个线程,即6个线程=6个consumer,所以每个实例各分到2个partition;
3.启动logstash
[root@localhost kafka01]# vim /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash-v7.17.6
After=network.target
[Service]
Restart=always
Environment="BEAT_CONFIG_OPTS=-f /hqtbj/hqtwww/logstash_workspace/conf.d"
ExecStart=/hqtbj/hqtwww/logstash_workspace/bin/logstash $BEAT_CONFIG_OPTS
User=root
Group=root
[Install]
WantedBy=multi-user.target
[root@kafka01 hqtwww]# systemctl daemon-reload
[root@kafka01 hqtwww]# systemctl start logstash.service
[root@kafka01 hqtwww]# systemctl enable logstash.service
或使用nohup后台启动
[root@kafka01 hqtwww]# cd /hqtbj/hqtwww/logstash_workspace/logs
[root@kafka01 logs]# nohup /hqtbj/hqtwww/logstash_workspace/bin/logstash -f /hqtbj/hqtwww/logstash_workspace/conf.d/*.conf > nohup.logstash 2<&1 &
七、模拟运行
1.写入日志
所有组件启动成功后,往filebeat所收集的日志文件里添加日志;
[root@elk02 ~]# echo "{"app_name":"gotone-payment-api","client_ip":"","context":"","docker_name":"","env":"dev","exception":"","extend1":"","level":"INFO","line":68,"log_message":"现代金控支付查询->调用入参[{}]","log_time":"2023-01-09 10:25:30.025","log_type":"applicationlog","log_version":"1.0.0","method_name":"com.gotone.paycenter.dao.third.impl.modernpay.ModernPayApiAbstract.getModernPayOrderInfo","parent_span_id":"","product_line":"","server_ip":"","server_name":"gotone-payment-api-bc648794d-r8h7z","snooper":"","span":0,"span_id":"","stack_message":"","threadId":104,"trace_id":"gotone-payment-apidd256466-63eb-4c3f-8e27-2c3d6f857bb2","user_log_type":""}" >> /tmp/test/application/application.log
此时这条日志会先由filebeat收集并发送到kafka的“gotone-pro-log”topic上,然后logstash会去“gotone-pro-log”topic上获取数据,经过处理后再发送到es上供kibana展示;
/tmp/test/application/application.log <-- filebeat --> kafka <-- logstash --> es -->kibana
2.去kibana上查看日志
查看索引
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)StackManagement;
(3)数据;
(4)索引管理;
可以看到数据已经推过来了,并且创建的索引也是我们logstash上定义的索引名称

添加索引模式
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)StackManagement;
(3)Kibana;
(4)索引模式;
(5)创建索引模式匹配索引;
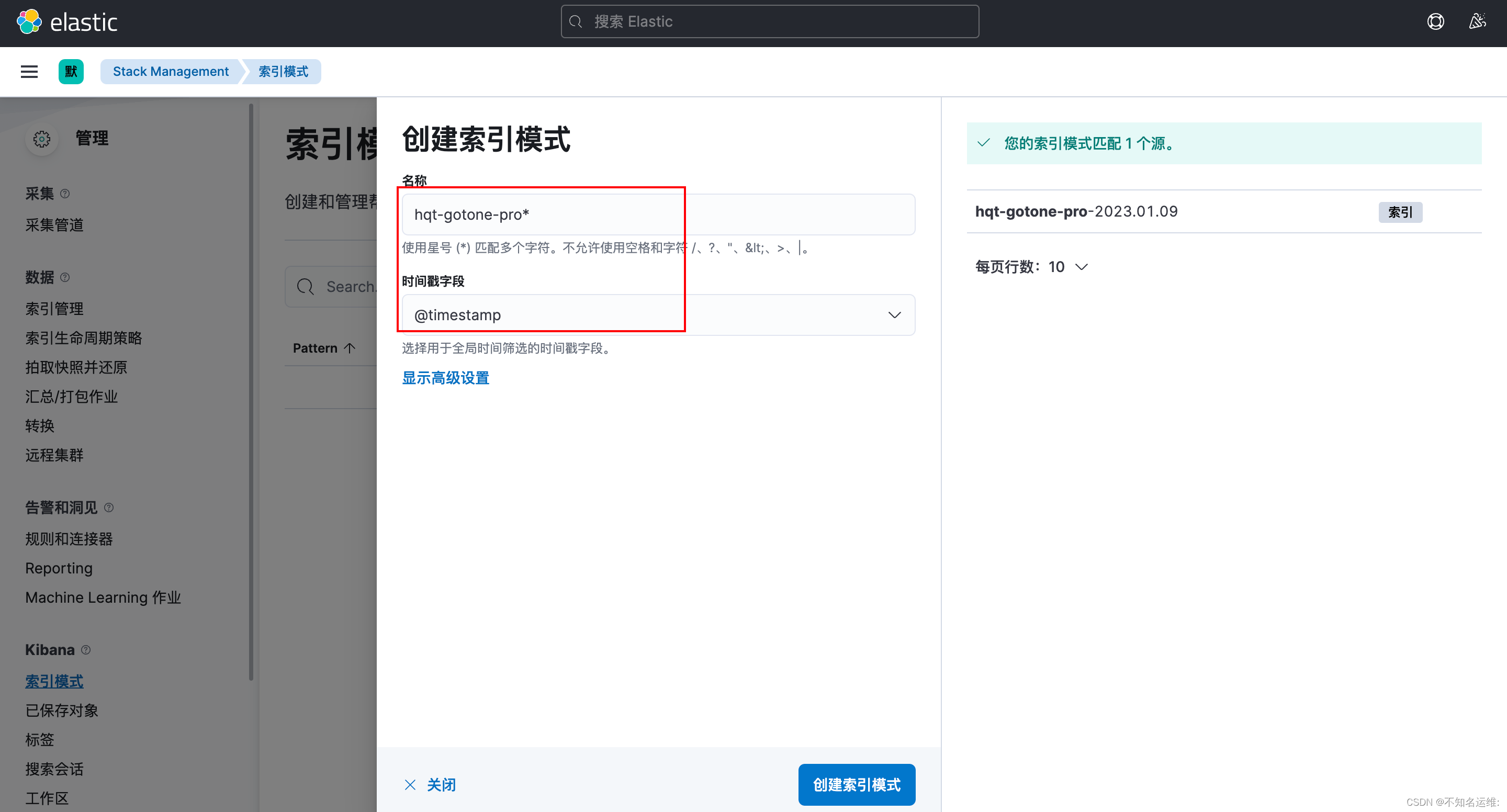
查看日志
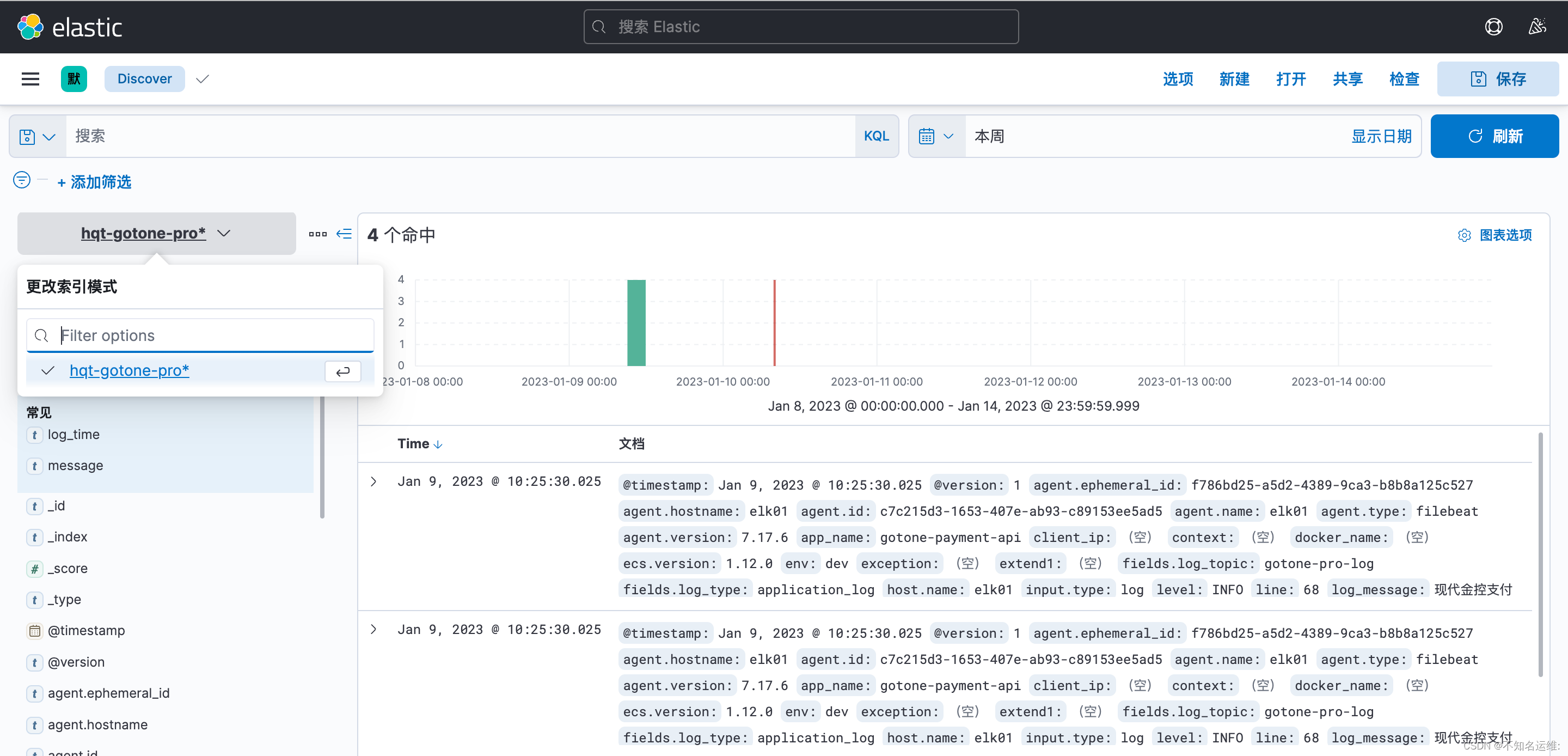
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Discover;
(3)选择刚创建的索引模式即可看见数据,也可以根据想要的字段过滤;
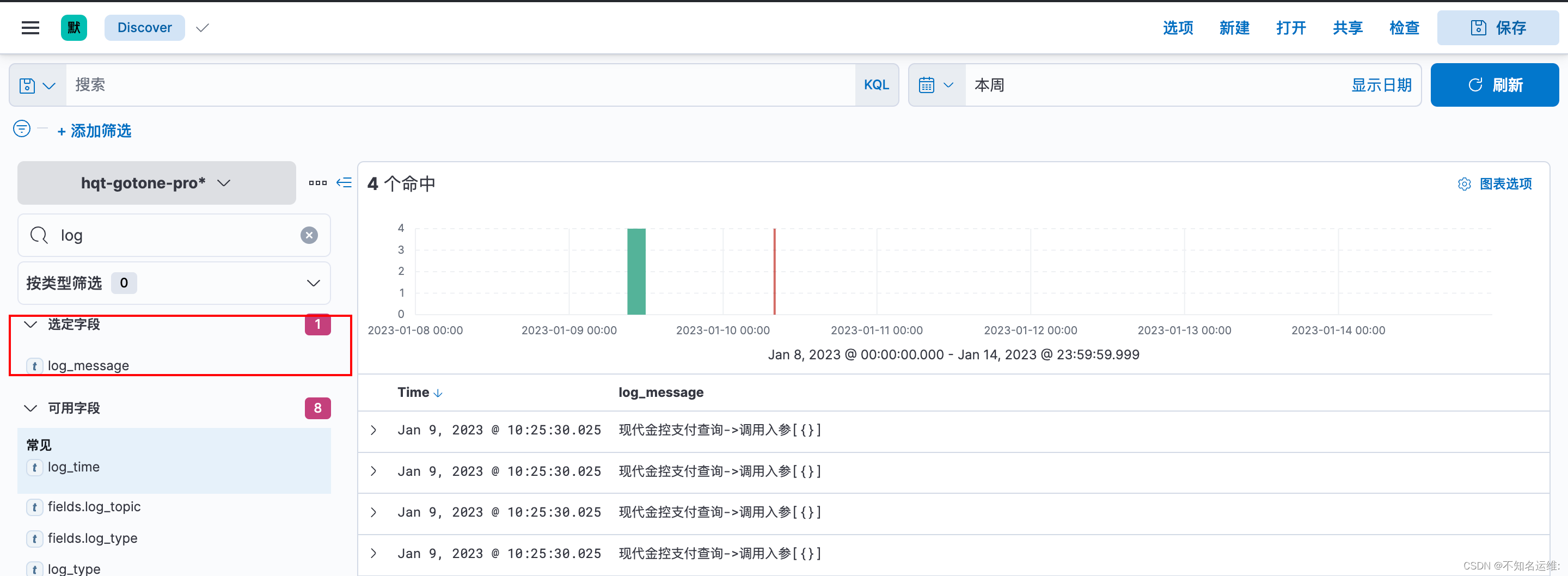
例如只查看log_message关键字段
总结
以上就是ELFK 7.17.6集群部署并收集java微服务日志过程的记录,后续会接着学习记录filebeat和logstash组件的用法以及案例;
















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











