






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
前面实验三搭建了深层神经网络,我们发现并不是神经网络层越多,效果越好。在此基础上,我们运用一些小技巧,以改善我们的神经网络。本实验参考:http://t.csdn.cn/wQveQ
一、初始化参数
目前我们一共学习了三种初始化方式
- 对于逻辑回归。权重初始化可为0
- 随机初始化一个很小的随机数
- 为抑制梯度爆炸,和梯度消失的初始化
现在我们看看三种初始化方式在同一神经网络的表现:
#######初始化参数###
train_X,train_Y,test_X,test_Y=init_utils.load_dataset(is_plot=True) ###查看数据
plt.show()
#####建立一个分类器,将蓝点与红点分开
#####init_utils中已经实现了一个三层的神经网络,现在我们来调用他进行数据初始化
####目前我门学习三种初始化的方式
###1.全部参数初始化为0
###2.初始化随机数
###3.抑梯度异常初始化
def initialize_model(X,Y,learning_rate=0.01,num_iterations=20000,print_cost=True,initialization="",is_plot=True):
"""
Parameters
----------
X----输入值
Y----标签
learning_rate-----学习率
num_iterrations-----迭代次数
print_cost------是否打印成本值,每1000次打印一次
initialization-----选择初始化的方式
is_plot-----绘制梯度下降的曲线图
Returns
-------
parameters----学习后的参数
"""
grads={}
costs=[]
m=X.shape[1]
layers_dims=[X.shape[0],10,5,1]
###选择初始化参数的类型
if initialization=="zero":
parameters=initialize_parameters_zero(layers_dims)
elif initialization=="random":
parameters=initialize_parameters_random(layers_dims)
if initialization=="he":
parameters=initialize_parameters_he(layers_dims)
######开始学习######
for i in range(0,num_iterations):
#####前向传播
a3,cache=init_utils.forward_propagation(X,parameters)
####计算成本
cost=init_utils.compute_loss(a3,Y)
###后向传播
grads=init_utils.backward_propagation(X, Y, cache)
###更新参数
parameters=init_utils.update_parameters(parameters, grads, learning_rate)
####打印成本
if i%1000==0:
costs.append(cost) #append 在列表ls最后(末尾)添加一个元素object
if print_cost:
print("第"+str(i)+"次迭代,成本值为:"+str(cost))
######绘制成本
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations(per thousands )')
plt.title("learning rate="+str(learning_rate))
plt.show()
return parameters1.1 初始化为0
######1.初始化为0
def initialize_parameters_zero(layers_dims):
"""
Parameters
----------
layers_dims
Returns
-------
parameters
"""
parameters={}
L=len(layers_dims)
for l in range(1,L):
parameters["W"+str(l)]=np.zeros((layers_dims[l],layers_dims[l-1]))
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1))
return parameters
######调用该初始化模型
"""
parameters=model(train_X,train_Y,initialization="zero",is_plot=True)
"""结果:
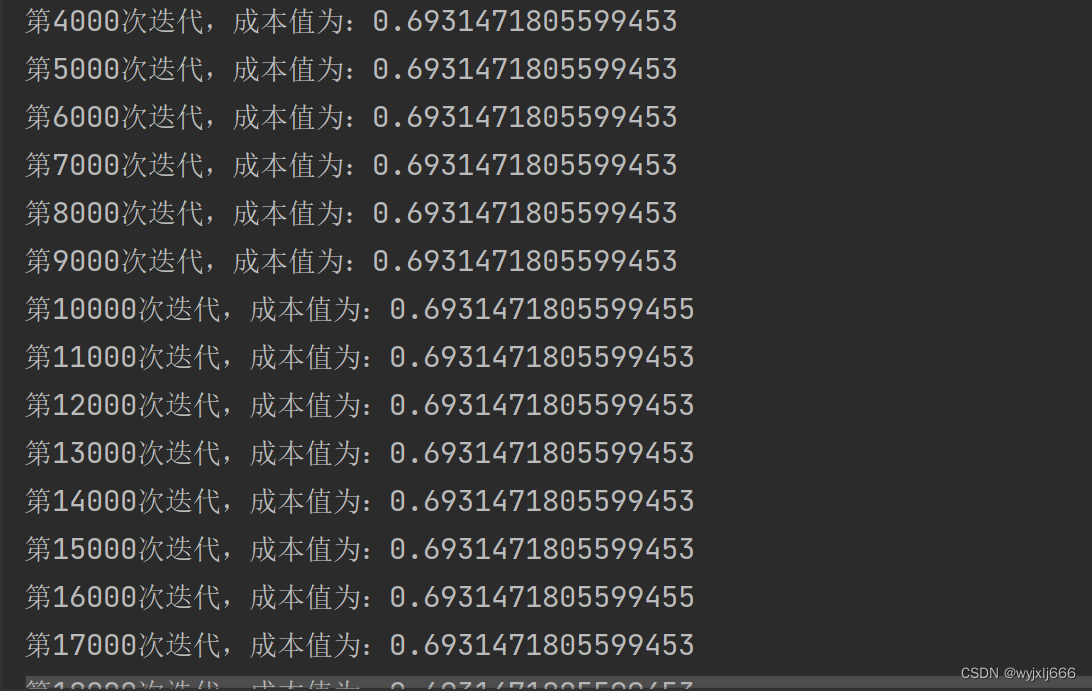
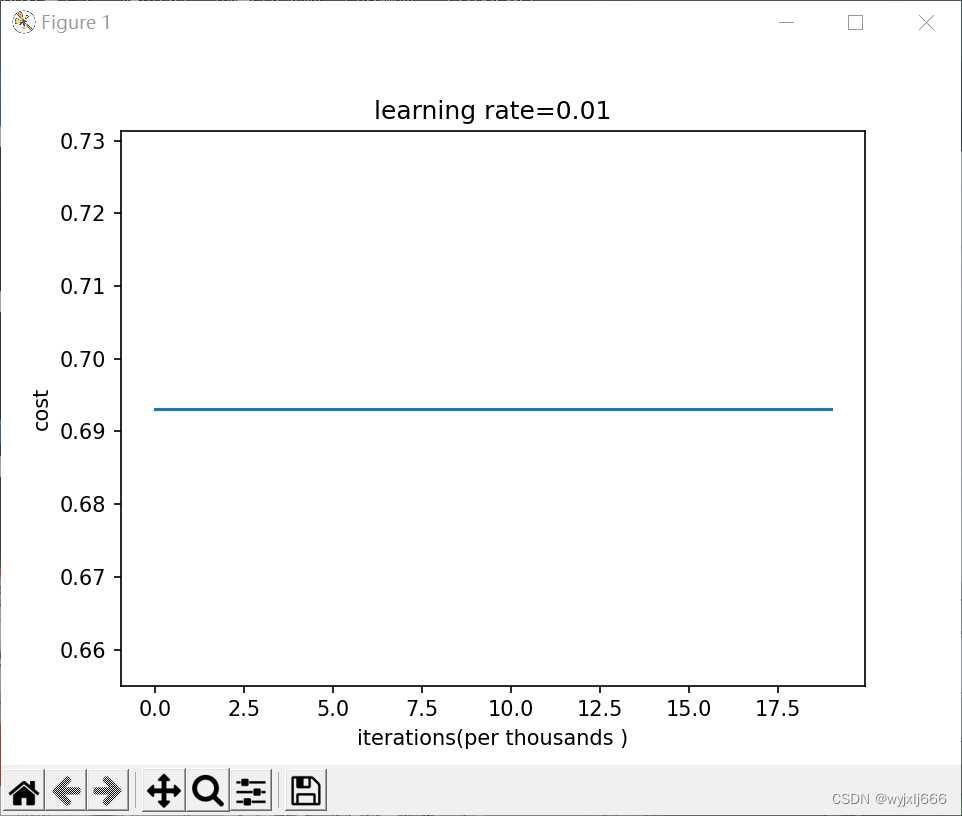
可以看到在三层神经网络中,初始化为0时根本不会迭代参数,因为零初始化会导致神经网络无法打破对称性,隐藏层不起作用,最终只会得到逻辑回归的效果
1.2 初始化为随机数
#########初始化为随机数
def initialize_parameters_random(layers_dims):
"""
Parameters
----------
layers_dims
Returns
-------
parameters
"""
np.random.seed(3) ####指定随机种子
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1])*0.1
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1)) ####b要初始化为0
assert(parameters["W"+ str(l)].shape==(layers_dims[l], layers_dims[l - 1]))
assert (parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
"""
parameters=model(train_X,train_Y,initialization="random",is_plot=True)
"""
-
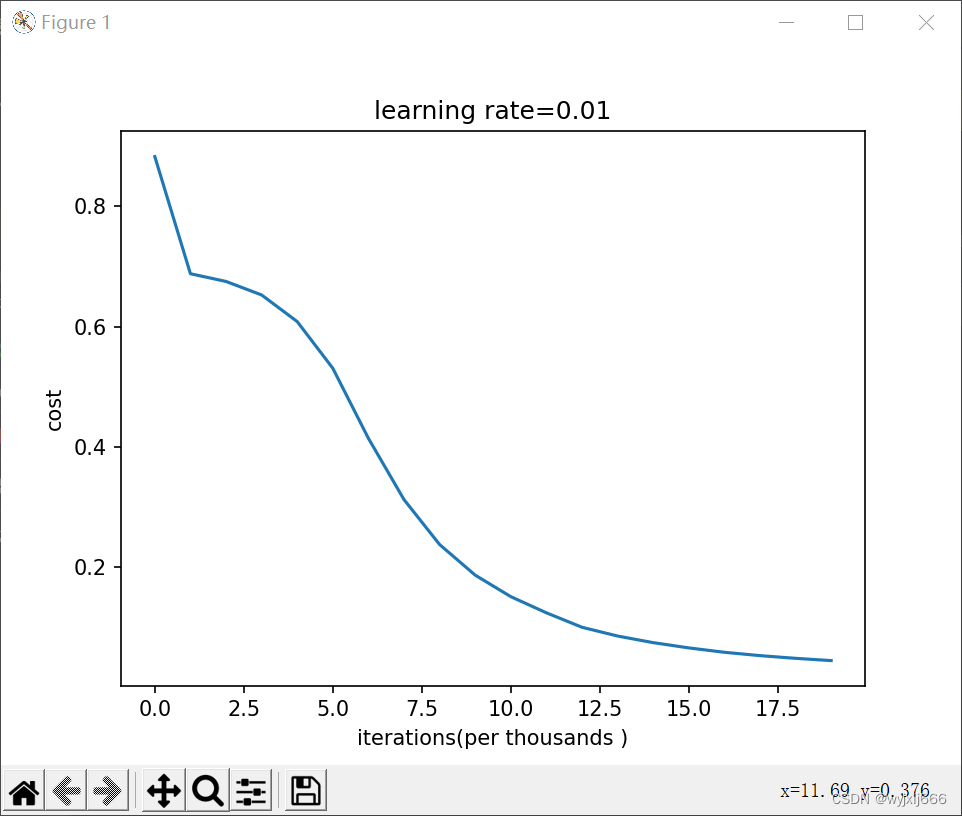
初始化为0.1,迭代20w次的结果:
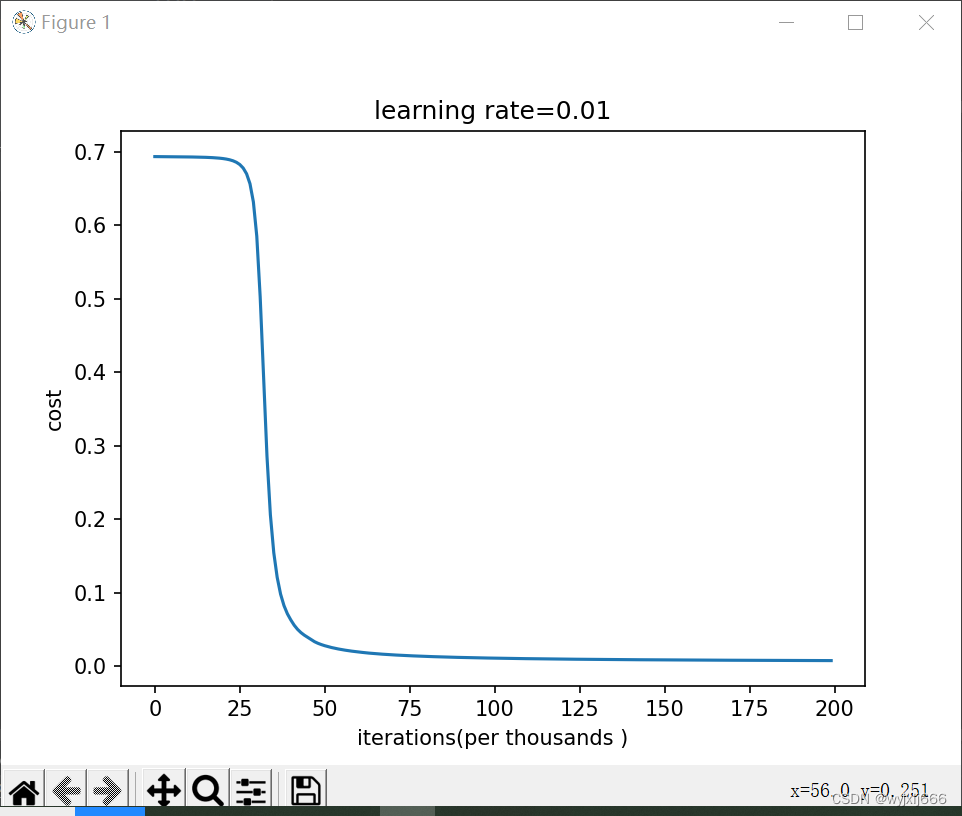
-
初始化为0.01,迭代200w次的结果:
-
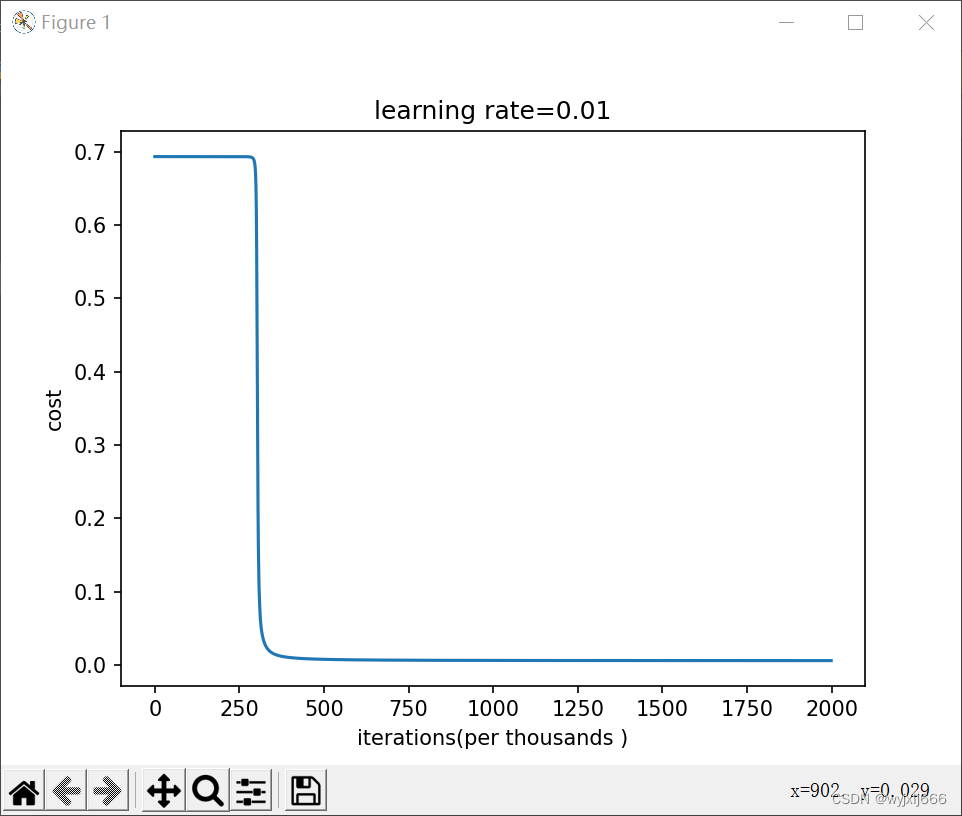
初始化*10,迭代1w5次的结果:
第0次迭代,成本值为:inf
第1000次迭代,成本值为:0.625098279396
第2000次迭代,成本值为:0.59812165967
第3000次迭代,成本值为:0.56384175723
第4000次迭代,成本值为:0.55017030492
第5000次迭代,成本值为:0.544463290966
第6000次迭代,成本值为:0.5374513807
第7000次迭代,成本值为:0.476404207407
第8000次迭代,成本值为:0.397814922951
第9000次迭代,成本值为:0.393476402877
第10000次迭代,成本值为:0.392029546188
第11000次迭代,成本值为:0.389245981351
第12000次迭代,成本值为:0.386154748571
第13000次迭代,成本值为:0.38498472891
第14000次迭代,成本值为:0.382782830835
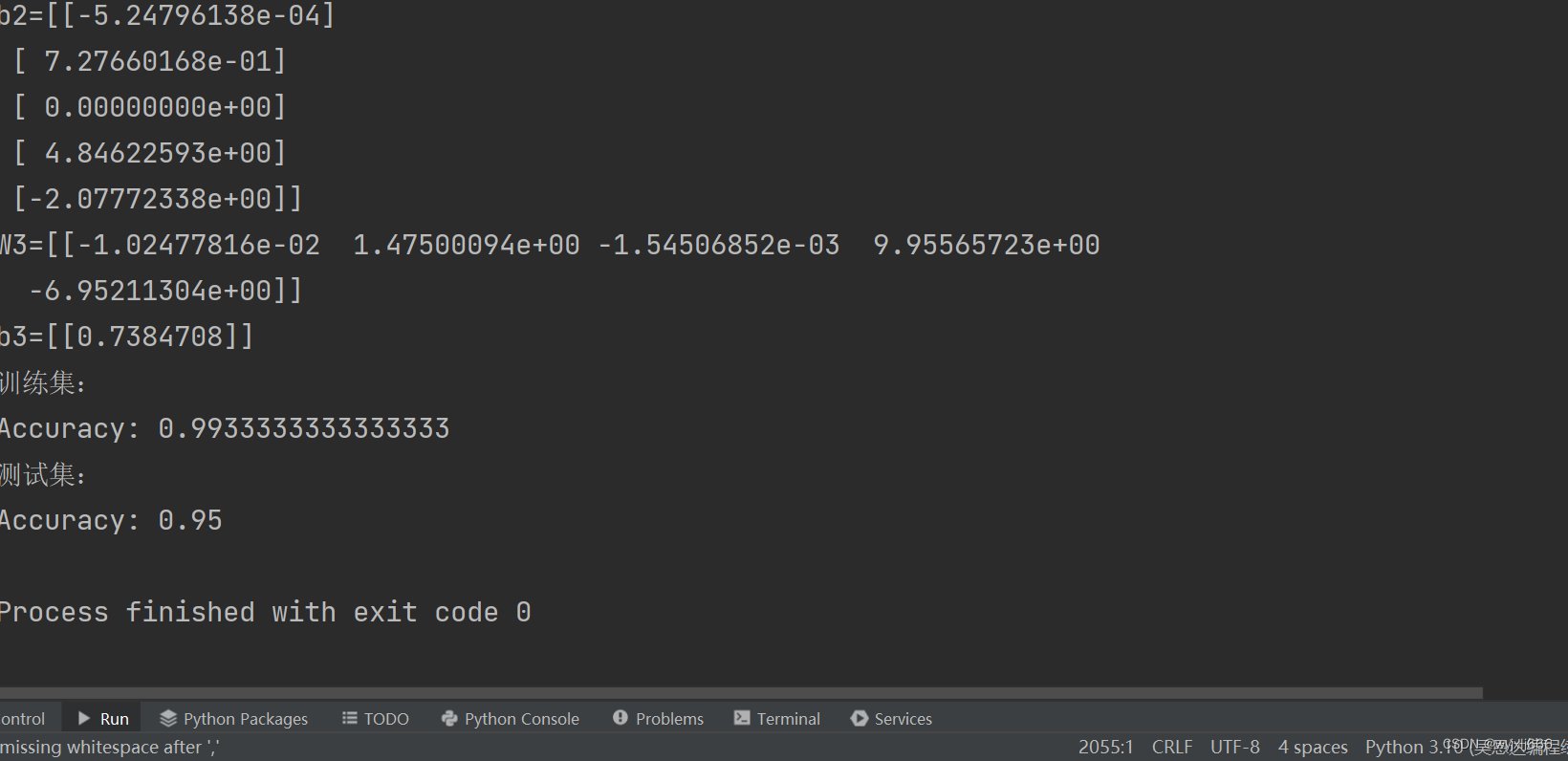
训练集:
Accuracy: 0.83
测试集:
Accuracy: 0.86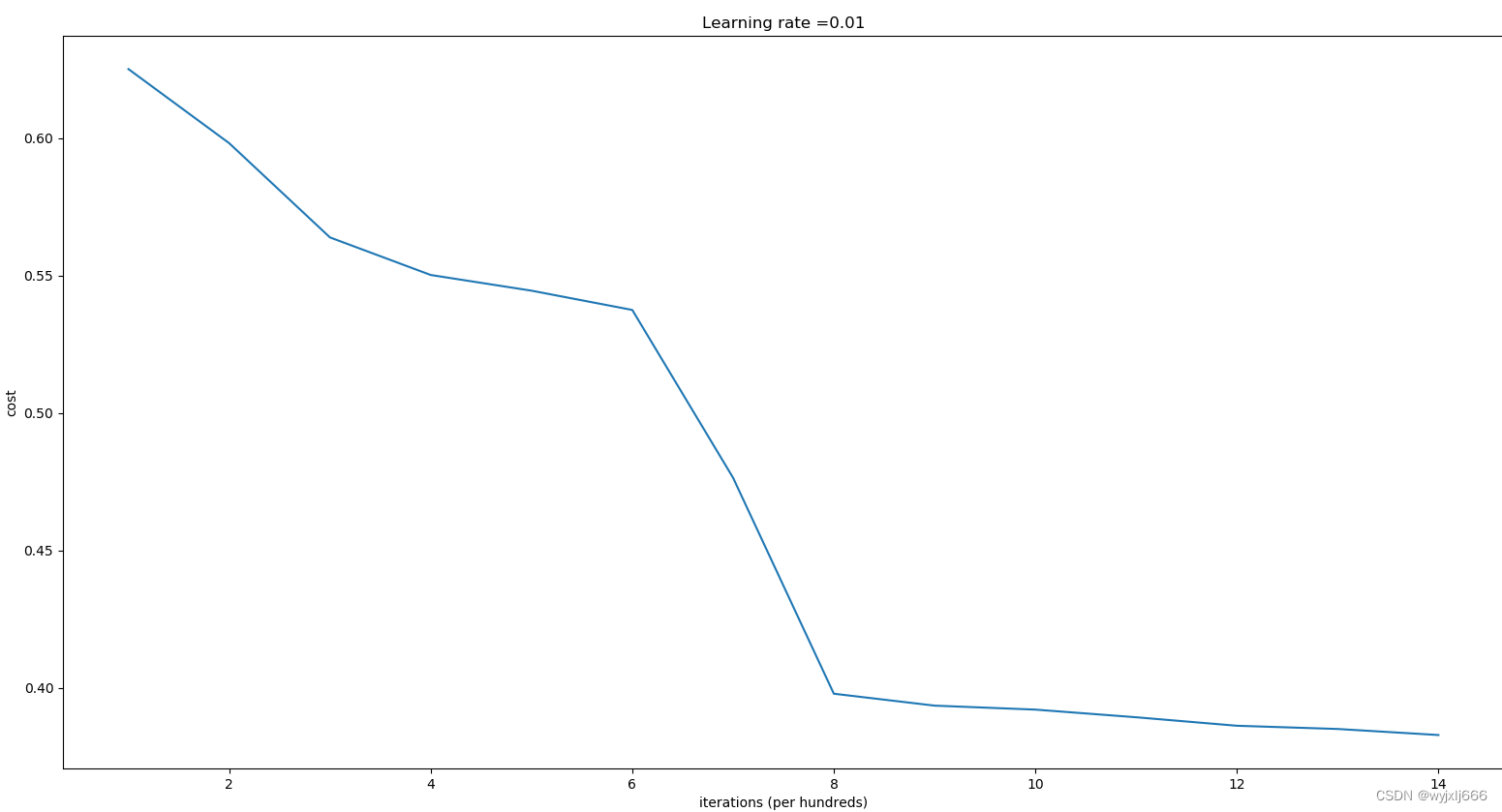
由此可见我们不好掌握该初始化怎么样的随机数,若随机数过小,那么学习次数就会变高,训练速度就会很慢。若随机数过大,就很有可能停在sigmoid/tanh平坦的部分,从而龟速学习,减慢优化的速度
1.3 抑梯度异常初始化
因此为避免梯度消失和梯度爆炸,优化学习速度,我们使用如下公式:
![]()
![]()
def initialize_parameters_he(layers_dims):
"""
Parameters
----------
layers_dims
Returns
-------
parameters
"""
np.random.seed(3)
parameters={}
L=len(layers_dims)
for l in range(1, L):
parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2/layers_dims[l-1])
#######因为激活函数是relu,因此使用np.sqrt(2/layers_dims[l-1])
######若是其他的激活函数,可使用np.sqrt(1/layers_dims[l-1])
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1)) ####b要初始化为0
assert (parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l - 1]))
assert (parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
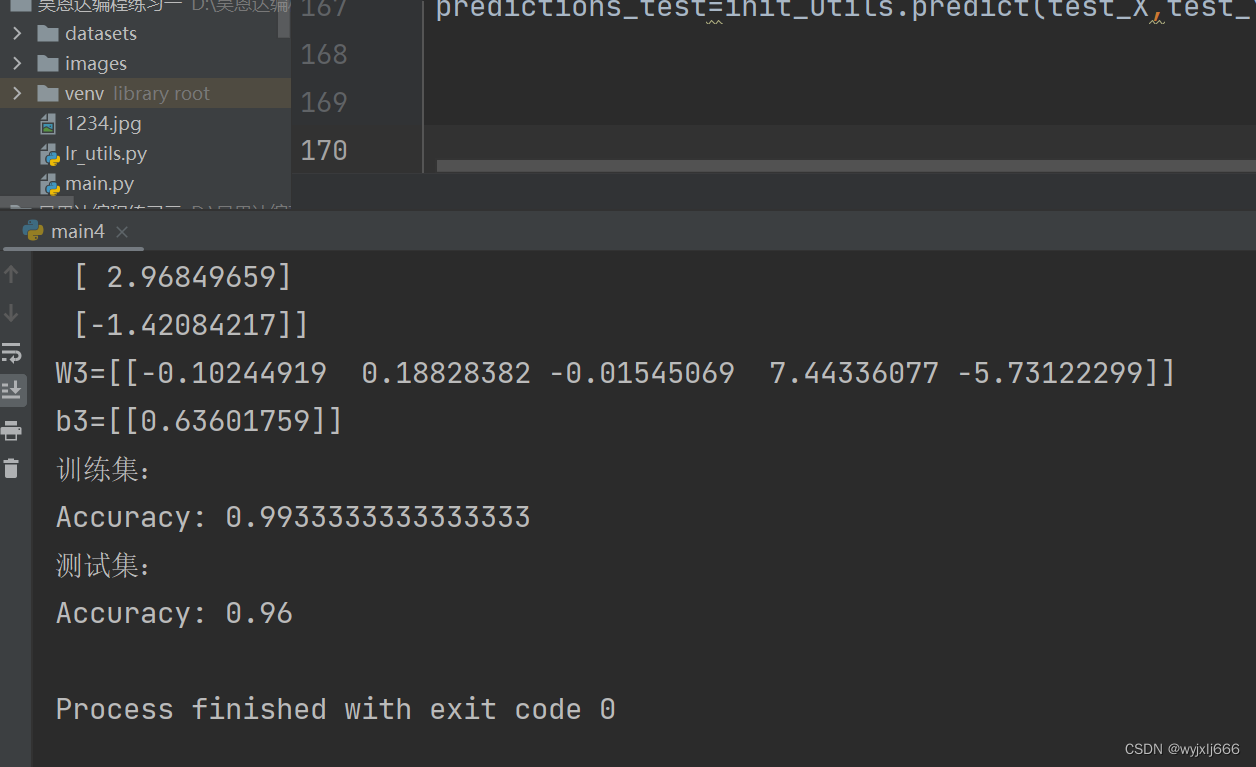
parameters=initialize_model(train_X,train_Y,initialization="he",is_plot=True)
print("W1="+str(parameters["W1"]))
print("b1="+str(parameters["b1"]))
print("W2="+str(parameters["W2"]))
print("b2="+str(parameters["b2"]))
print("W3="+str(parameters["W3"]))
print("b3="+str(parameters["b3"]))
print("训练集:")
predictions_train=init_utils.predict(train_X,train_Y,parameters)
print("测试集:")
predictions_test=init_utils.predict(test_X,test_Y,parameters)
#######绘制决策边界
plt.title("抑梯度异常初始化")
axes=plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters,x.T),train_X,train_Y)
plt.show()
结果:

绘制决策边界 :
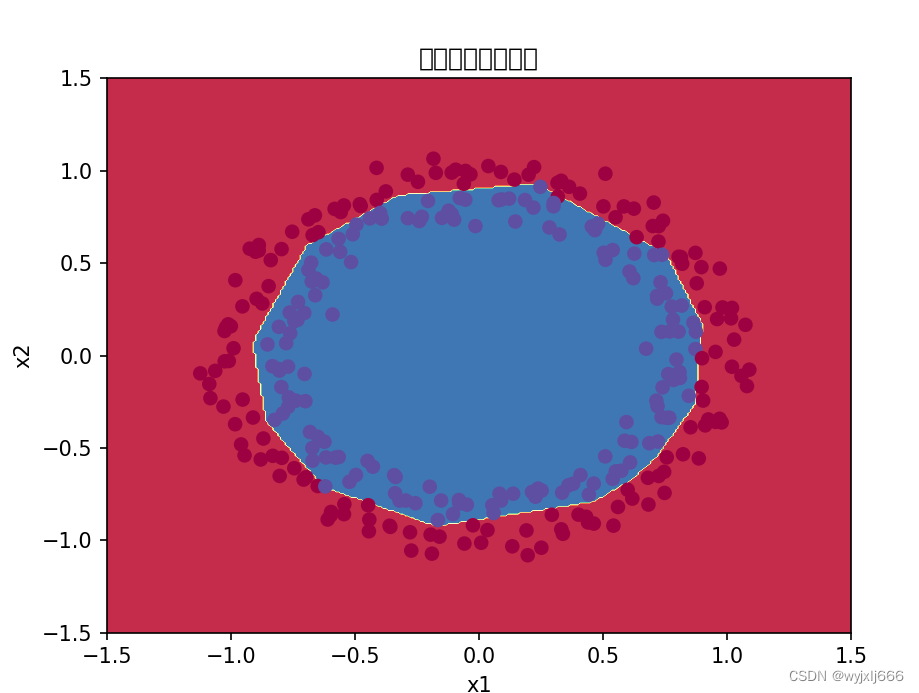
由以上可见,这种初始化方式避免了梯度消失或梯度爆炸,在保证效果的同时还优化了速度。
二、正则化
正则化的目的:收缩权重,避免验证集与训练集的结果方差多大,避免过拟合
建立模型:
def model(X,Y,learning_rate=0.3,num_iterations=30000,print_cost=True,is_plot=True,lambd=0,keep_prob=1):
"""
Parameters
----------
X
Y
learning_rate
num_iterations
print_cost
is_plot
lambd--------L2正则化的超参数,实数
keep_prob-------随机删除节点的概率
Returns
-------
parameters------学习后的参数
"""
grads={}
parameters={}
costs=[]
m=X.shape[1]
layers_dims=[X.shape[0],20,3,1]
###初始化参数
parameters=reg_utils.initialize_parameters(layers_dims)
######开始学习
for i in range(0,num_iterations):
####前向传播
if keep_prob==1:
#不随机删除节点,使用L2正则化
a3,cache=reg_utils.forward_propagation(X,parameters)
elif keep_prob<1:
#随机删除节点,使用dropout正则化
a3,cache=forward_propagation_with_dropout(X,parameters,keep_prob)
else:
print("keep_prob参数错误!程序退出")
exit
####计算成本
#######是否使用二范数
if lambd==0:
####不适用L2正则化
cost=reg_utils.compute_cost(a3,Y)
else:
####使用L2正则化
cost=compute_cost_with_regularization(a3,Y,parameters,lambd)
####后向传播
#####可以同时使用L2正则化和dropout,但是本实验不使用
assert(lambd==0 or keep_prob==1)
#####两个参数的使用情况
if (lambd==0 and keep_prob==1):
######不使用L2正则化和不适用随机删除节点
grads=reg_utils.backward_propagation(X,Y,cache)
elif lambd != 0:
#####使用L2正则化,不适用随机删除节点
grads=backward_propagation_with_regularization(X,Y,cache,lambd)
elif keep_prob<1:
#####不使用L2正则化,使用随机删除节点
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
#####更新参数
parameters=reg_utils.update_parameters(parameters,grads,learning_rate)
######打印成本
if i%1000==0:
#####记录成本
costs.append(cost)
if(print_cost):
print("第"+str(i)+"次迭代,成本值为:"+str(cost))
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations')
plt.title("learning rate="+str(learning_rate))
plt.show()
return parameters正则化实验数据集: (就是要建立一个分类器)
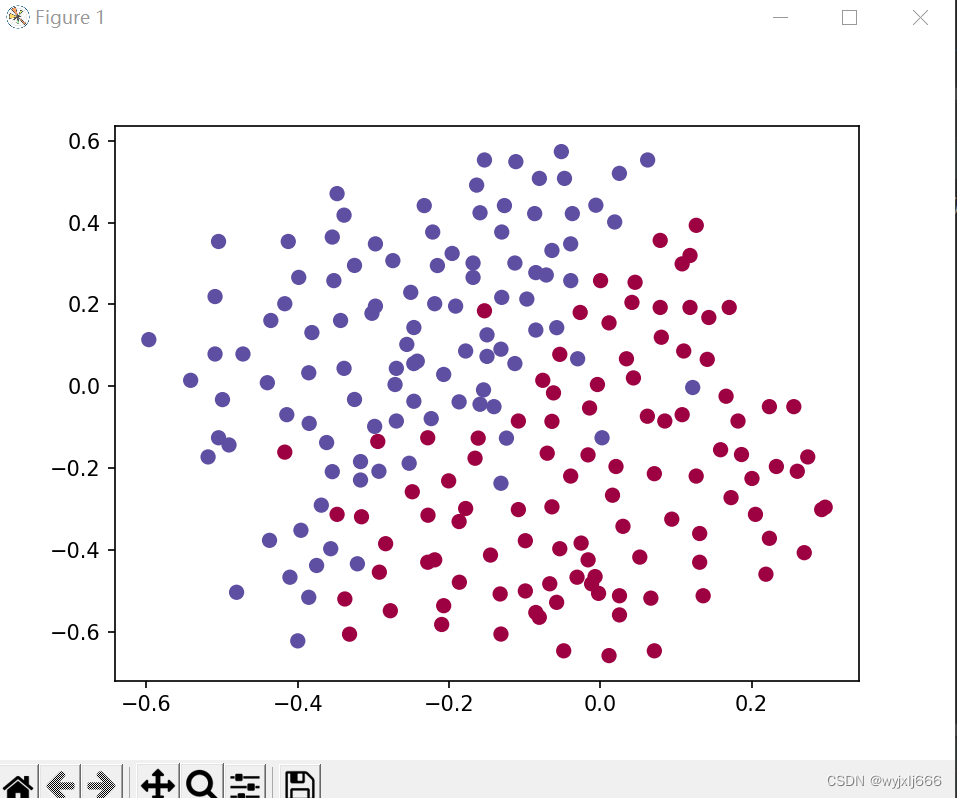
2.1 不使用正则化
#########不使用正则化
parameters=model(train_X,train_Y,is_plot=True,lambd=0,keep_prob=1)
print("训练集:")
predictions_train=reg_utils.predict(train_X,train_Y,parameters)
print("测试集:")
predictions_test=reg_utils.predict(test_X,test_Y,parameters)
#####绘制决策边界
plt.title("model without regularization")
axes=plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters,x.T),train_X,train_Y)
plt.show()结果:
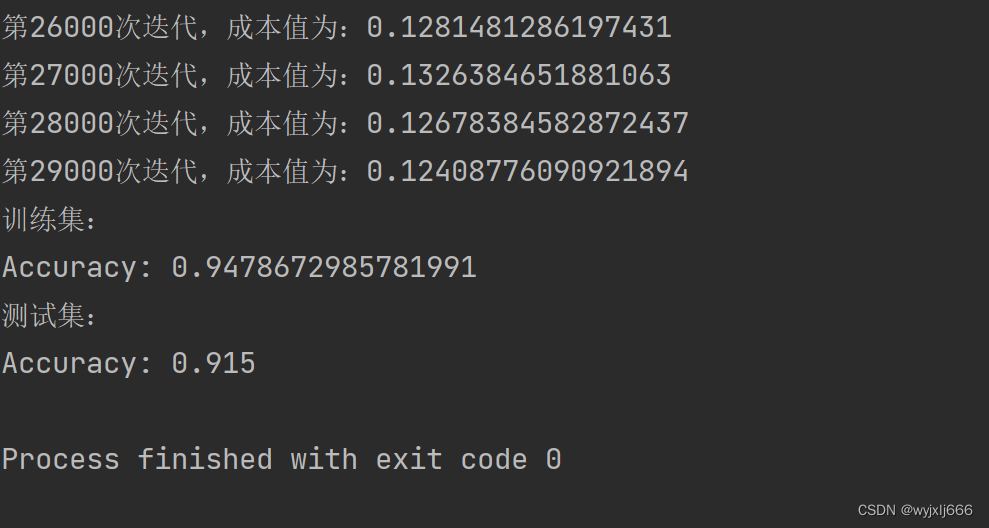
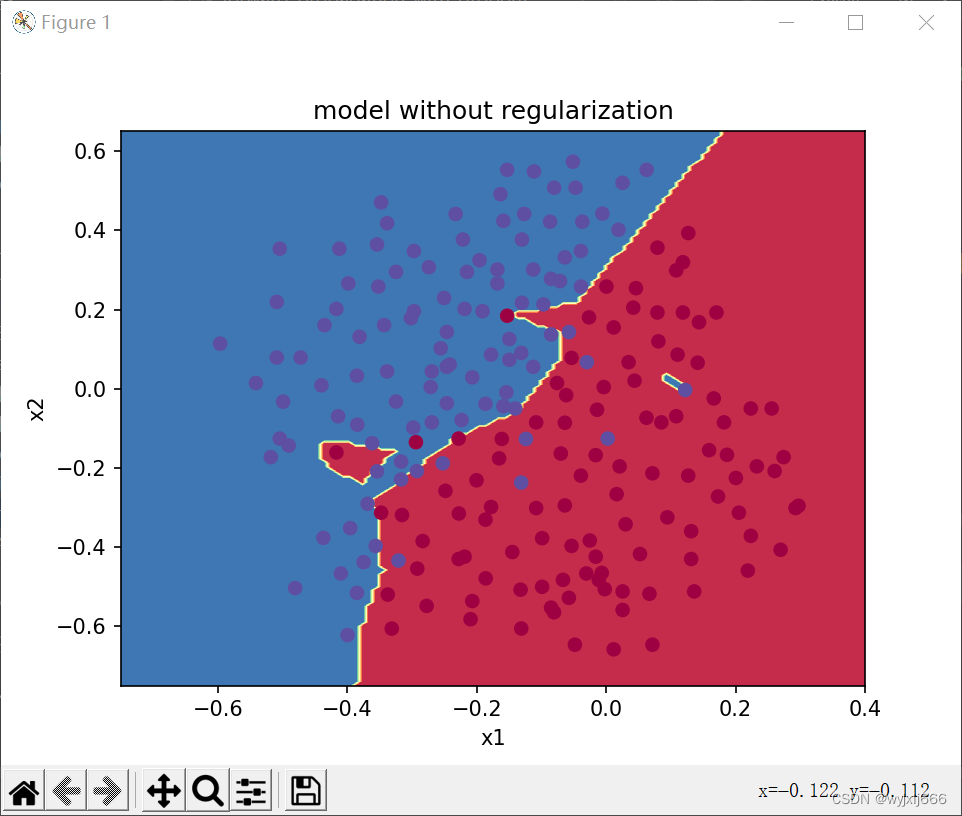
明显的过拟合,训练集与验证集有高方差
2.2 L2正则化
L2正则化通过修改成本函数,加入正则项:


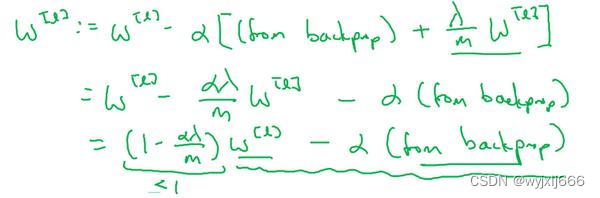
在反向传播过程中,由于增加了正则化项,w权重衰减
############使用L2正则化
def compute_cost_with_regularization(A3,Y,parameters,lambd):
"""
Parameters
----------
A3-------正向传播的输出结果,维度为(输出节点的数量,训练/测试的数量)
Y----标签数量,维度为(输出节点数量,训练/测试的数量)
parameters-----包含模型学习后的参数
lambd-----正则化参数
Returns
-------
cost------使用正则化计算出来的正则化损失值
"""
m=Y.shape[1] ######要与原成本函数的y^的数量保持一致
W1=parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost=reg_utils.compute_cost(A3,Y)
L2_regularization_cost=lambd*(np.sum(np.square(W1))+np.sum(np.square(W2))+np.sum(np.square(W3)))/(2*m)
cost=cross_entropy_cost+L2_regularization_cost
return cost
########成本函数都改变了,我们必须改变后向传播的函数了,,,所有梯度都必须根据这个新的成本函数计算
def backward_propagation_with_regularization(X,Y,cache,lambd):
"""
Parameters
----------
X
Y
cache
lambd
Returns
-------
grads------一个包含每个参数,激活值,和预激活值变量的梯度的字典
"""
m=X.shape[1]
(Z1,A1,W1,b1,Z2,A2,W2,b2,Z3,A3,W3,b3)=cache
dZ3=A3-Y
dW3=(1/m)*np.dot(dZ3,A2.T)+((lambd*W3)/m)
db3=(1/m)*np.sum(dZ3,axis=1,keepdims=True)
dA2=np.dot(W3.T,dZ3)
dZ2=np.multiply(dA2,np.int64(A2>0))
dW2=(1/m)*np.dot(dZ2,A1.T)+((lambd*W2)/m)
db2=(1/m)*np.sum(dZ2,axis=1,keepdims=True)
dA1=np.dot(W2.T,dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T) + ((lambd * W1) / m)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradins={"dZ3":dZ3,"dW3":dW3,"db3":db3,"dA2":dA2,
"dZ2":dZ2,"dW2":dW2,"db2":db2,"dA1":dA1,
"dZ1":dZ1,"dW1":dW1,"db1":db1,}
return gradins
#########使用L2正则化
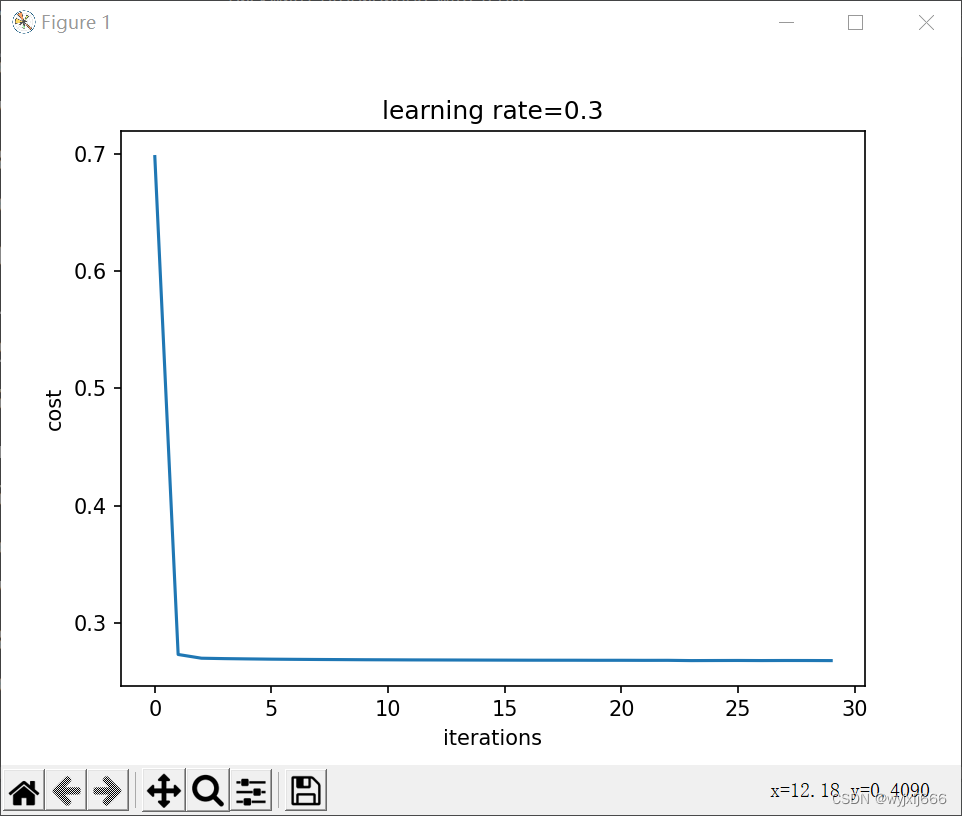
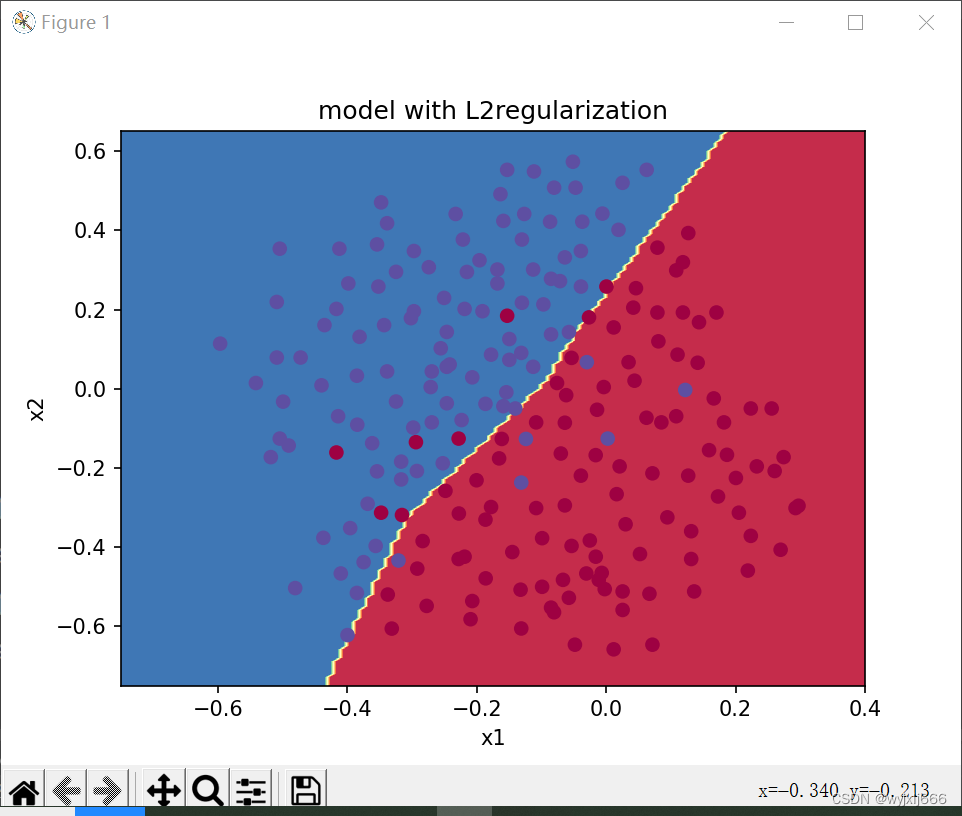
parameters=model(train_X,train_Y,lambd=0.7,is_plot=True)
print("L2正则化后训练集:")
predictions_train=reg_utils.predict(train_X,train_Y,parameters)
print("L2正则化后测试集:")
predictions_test=reg_utils.predict(test_X,test_Y,parameters)
#####绘制决策边界
plt.title("model with L2regularization")
axes=plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters,x.T),train_X,train_Y)
plt.show()
2.3 dropout正则化
dropout 会遍历网络的每一层,随机按概率(1-keep_prob)消除每一层的节点的个数,从而精简神经网络,消除过拟合。
加入dropout之后,输入的特征有可能被随机清除,因而不能特别依赖于任何一个输入的特征,不会给设置大权重,通过传播,dropout和前述正则化一样,产生了权重收缩的效果。
使用上,在神经元少时,减少使用dropout, keep_prob=1, 神经元多时,减小keep_prob。但其使得 J 无法明确定义,难以绘图,因而一般先关闭dropout,确保收敛下降,再打开。
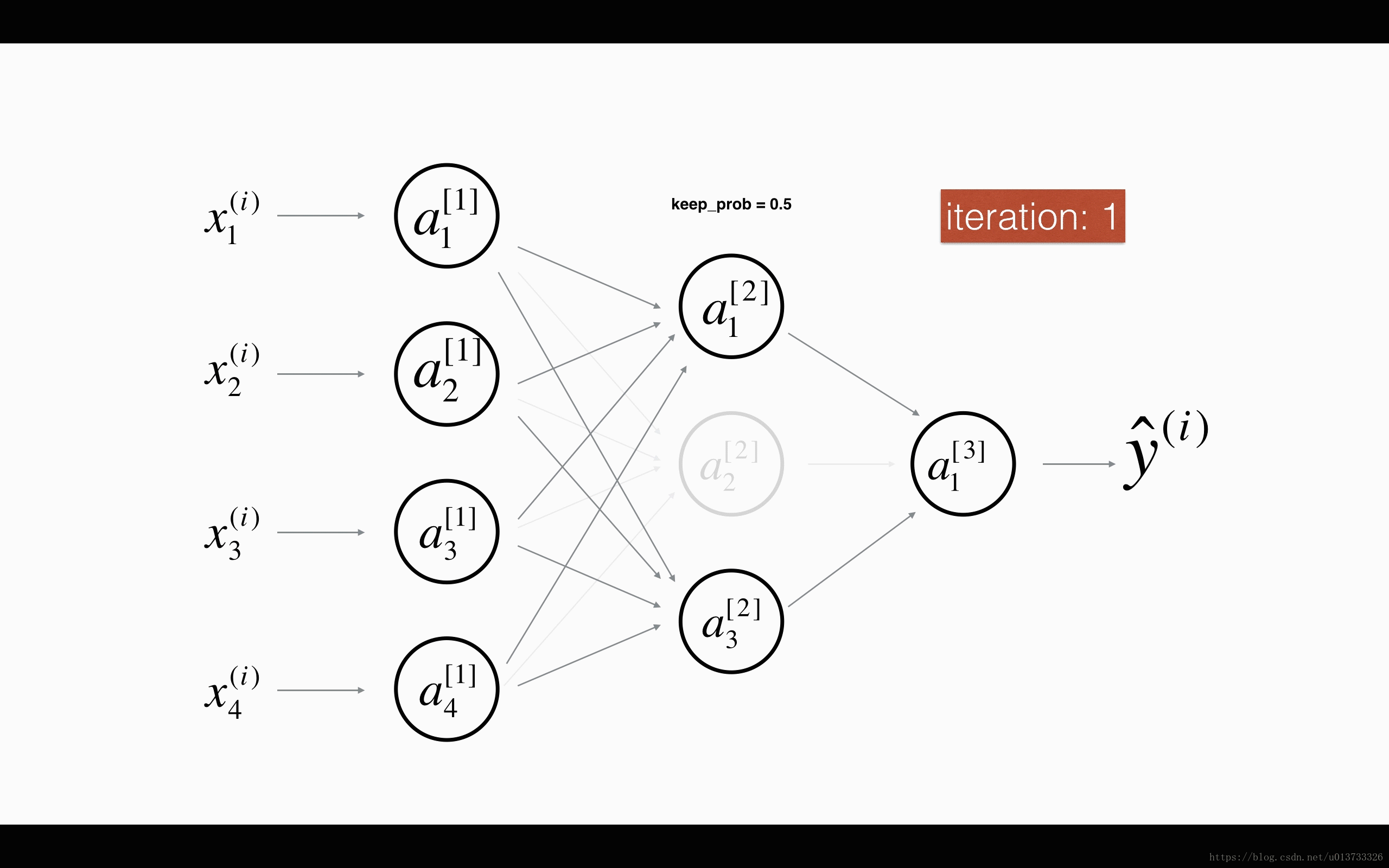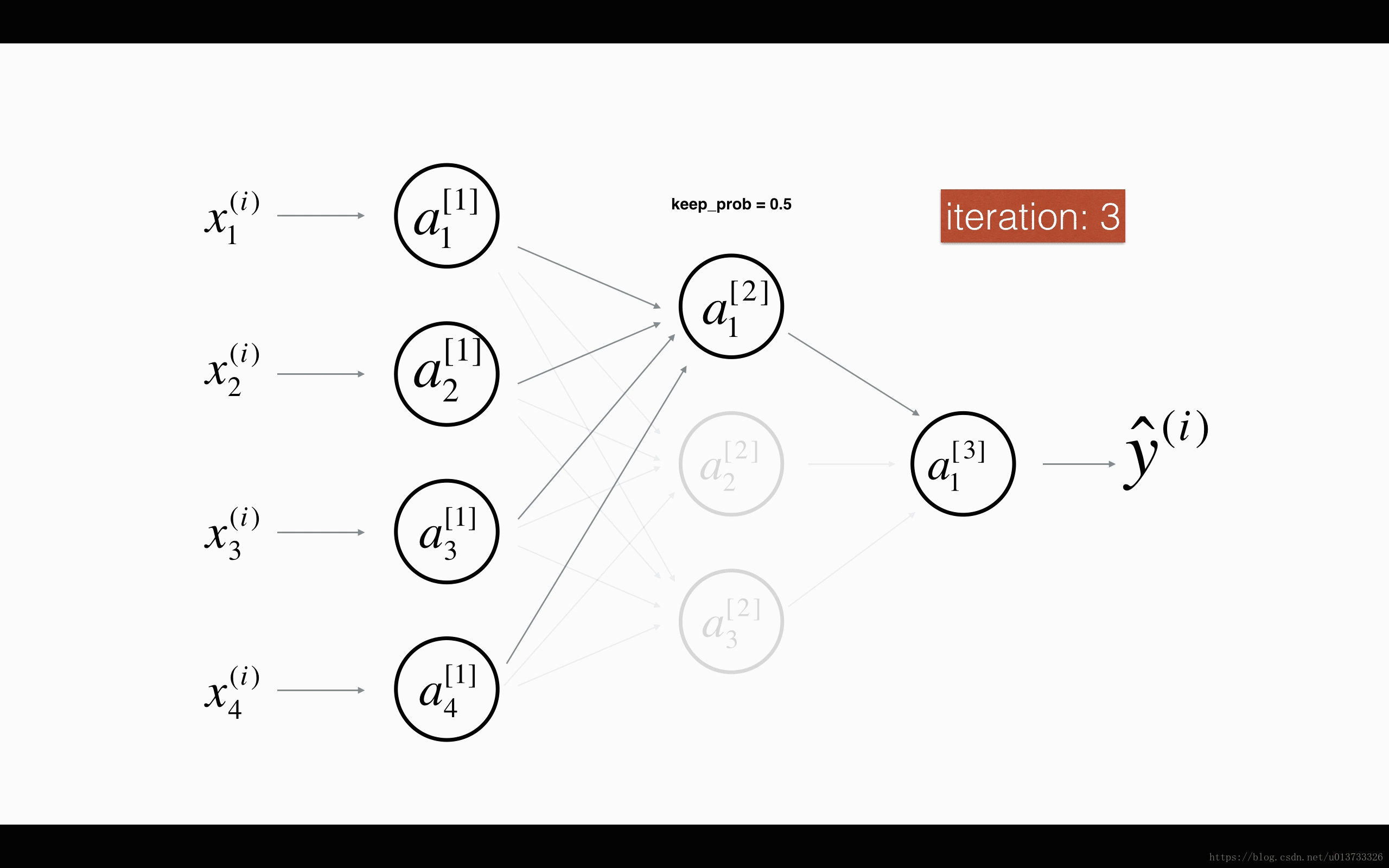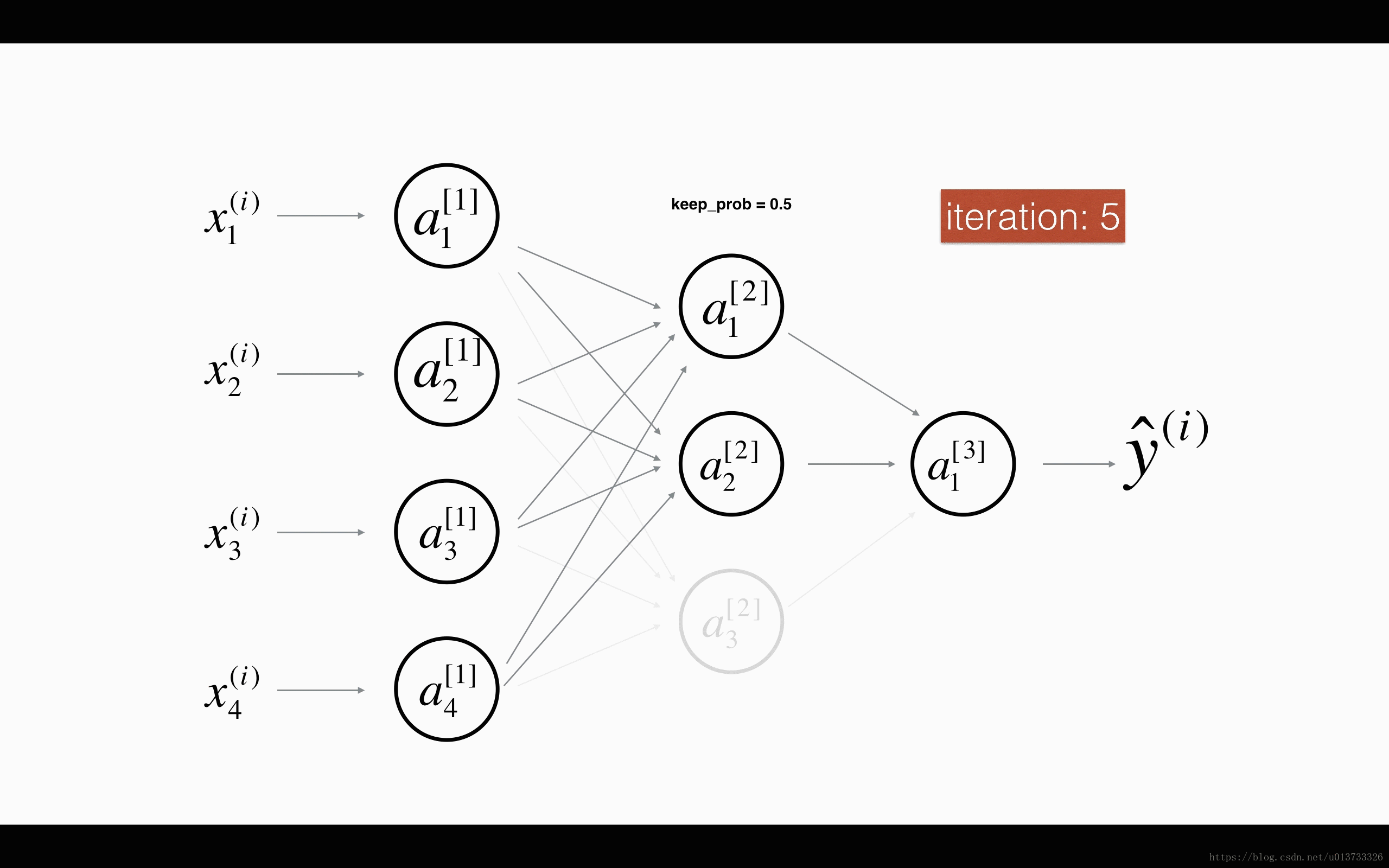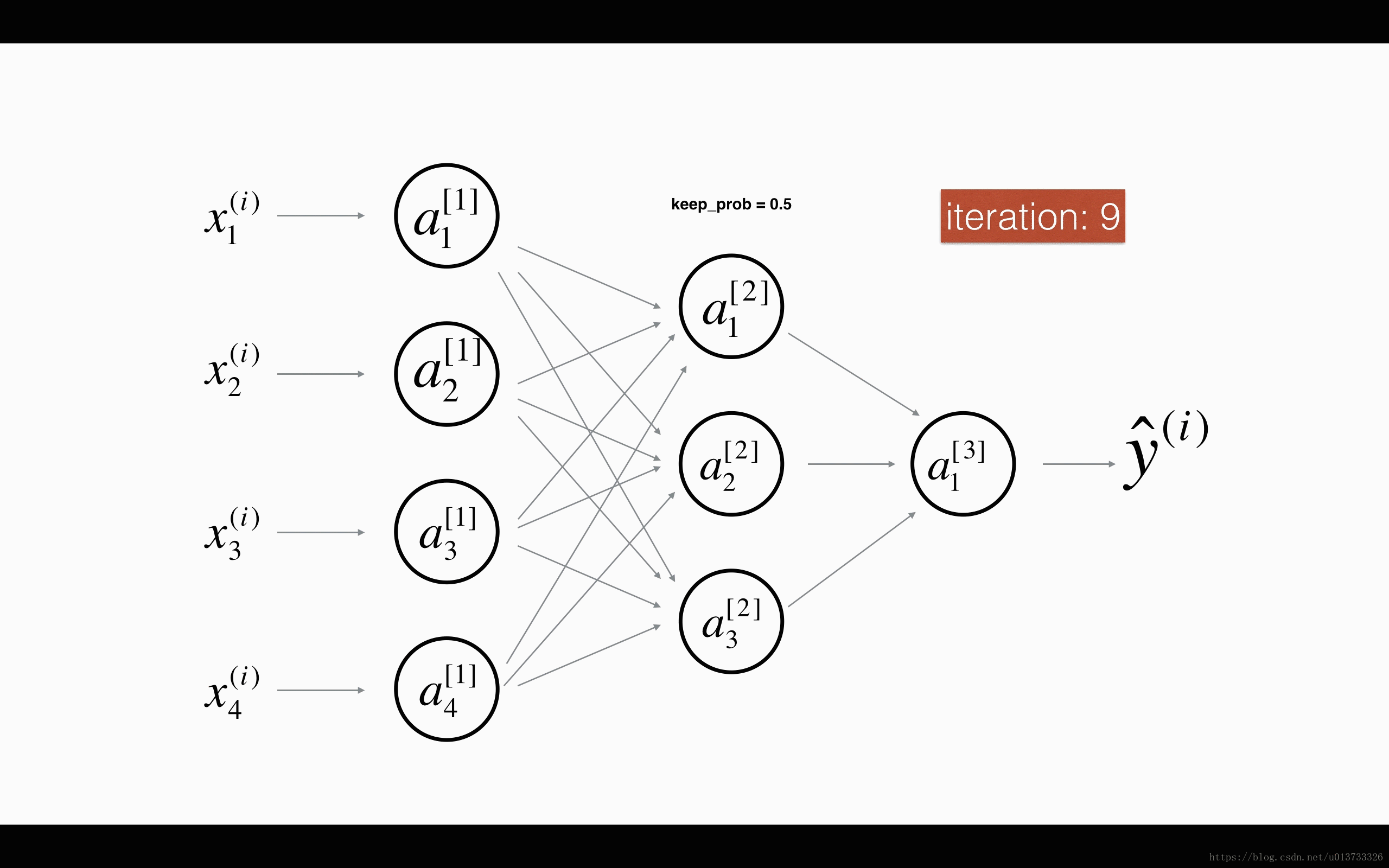
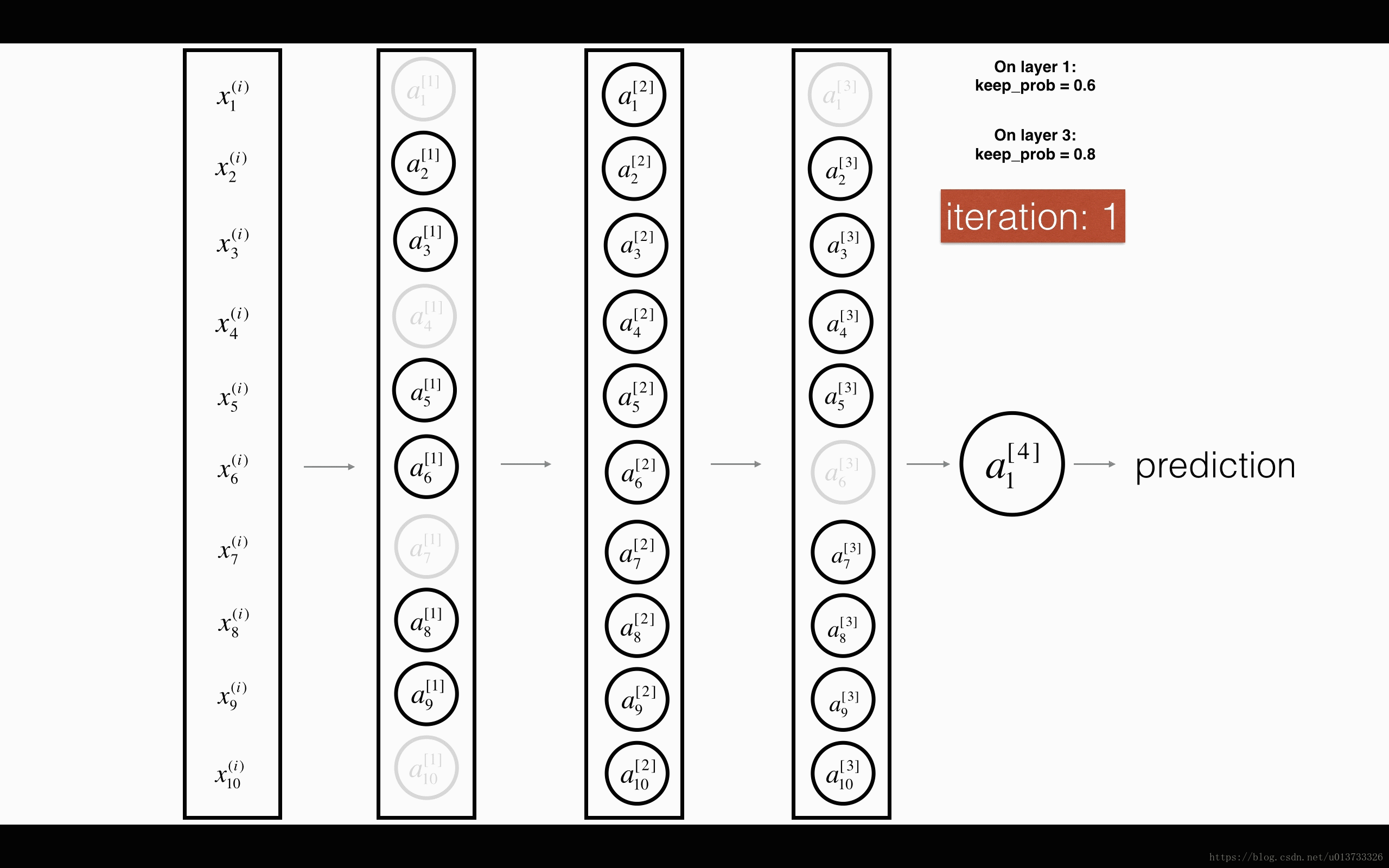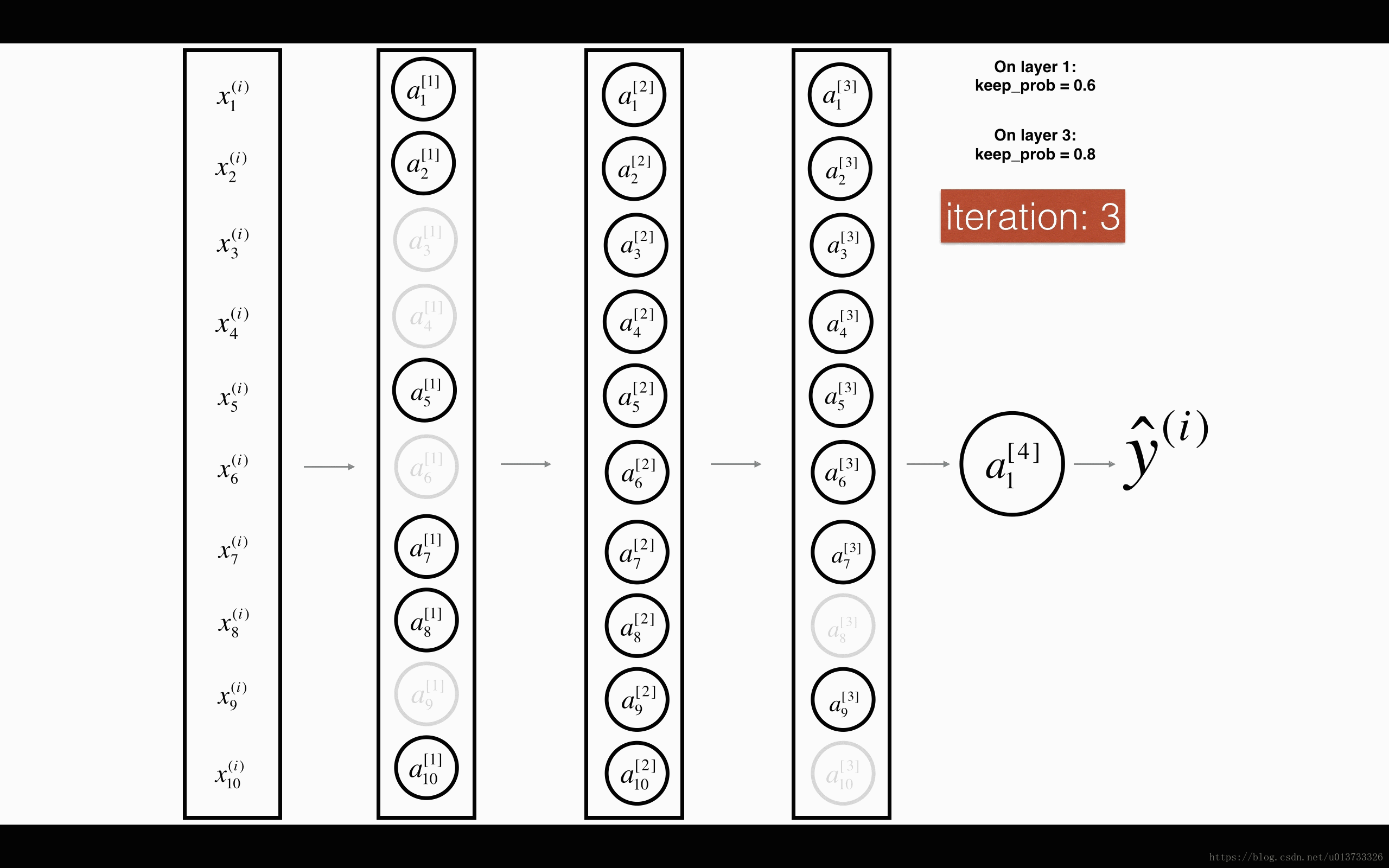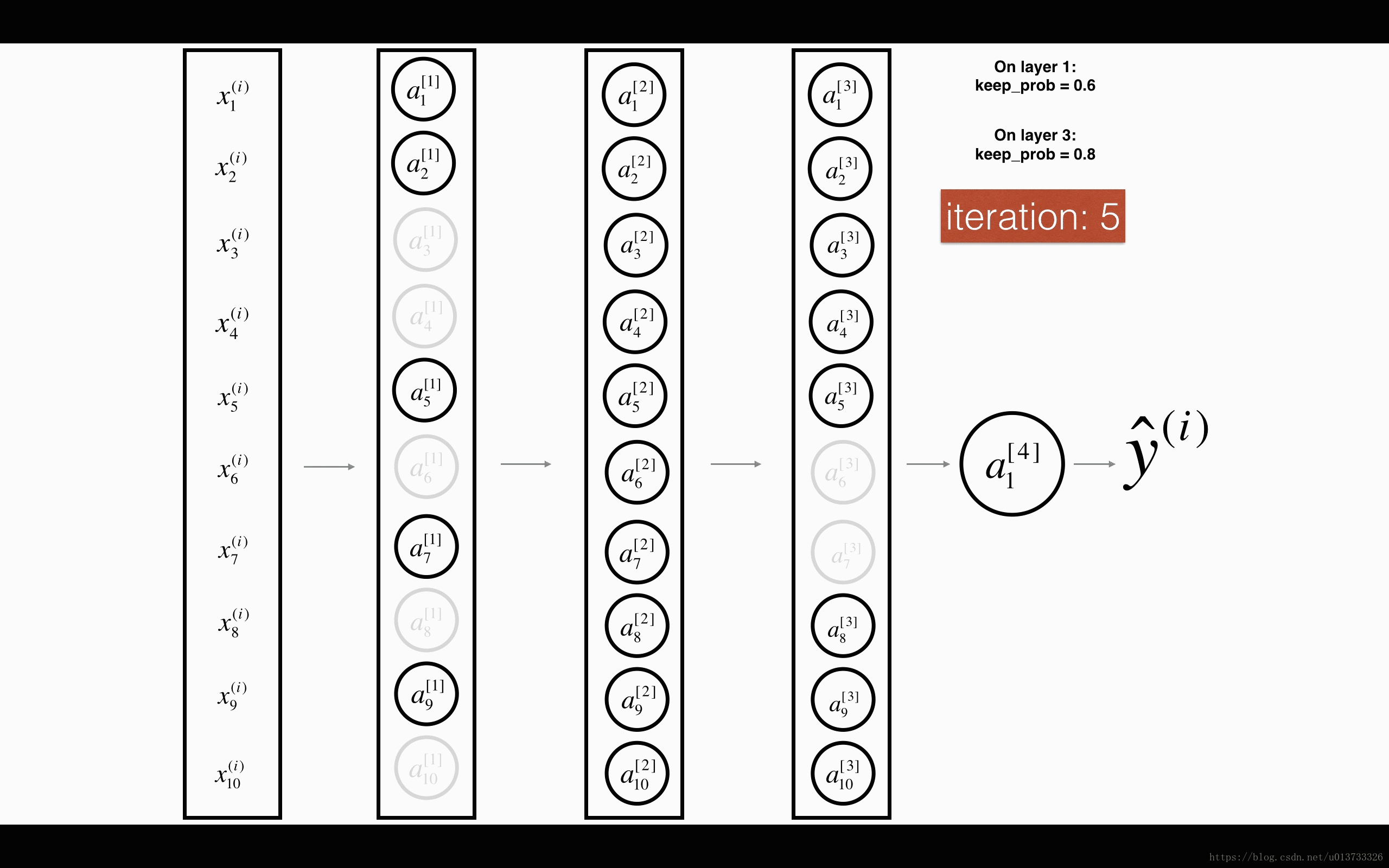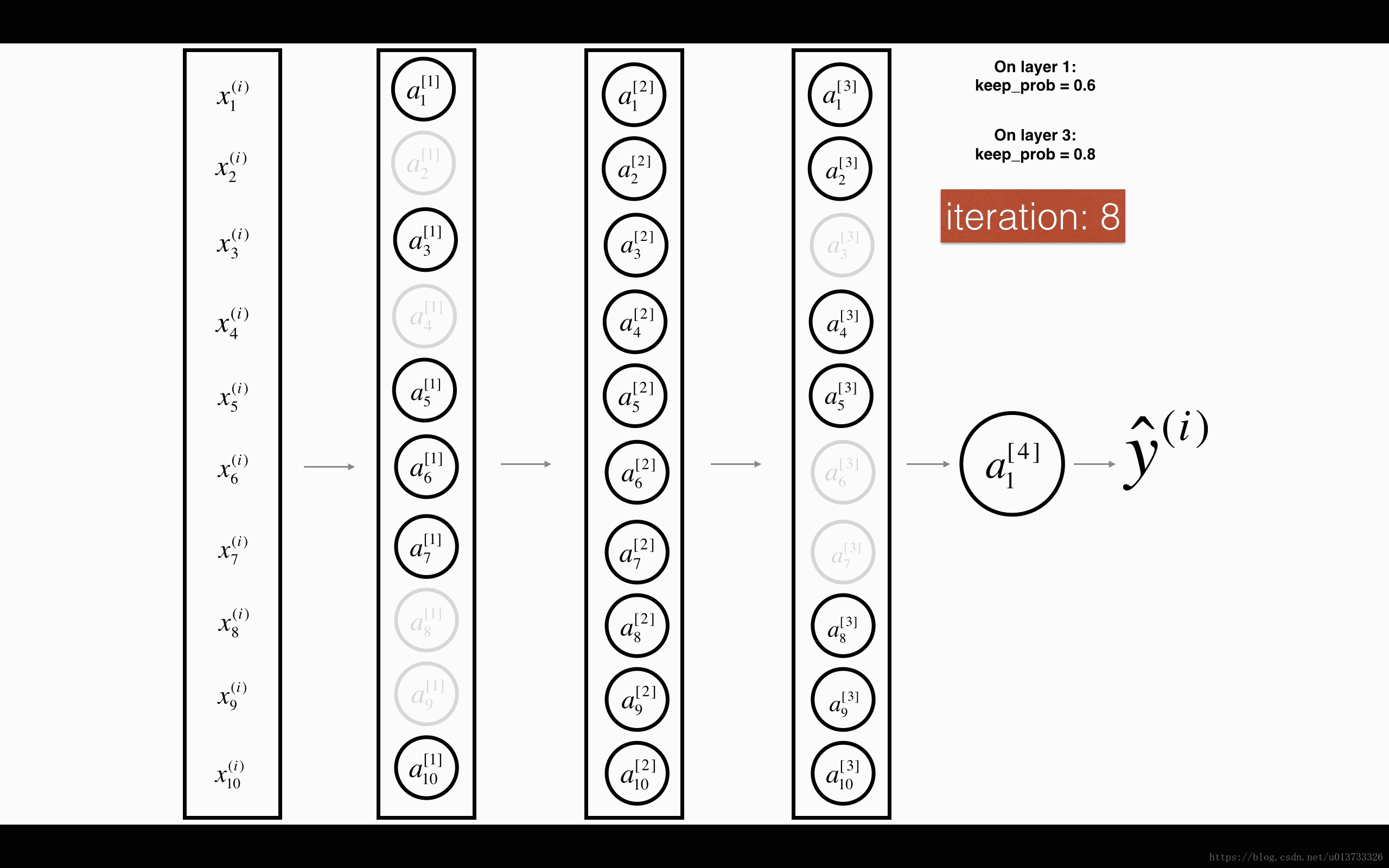
以上的两个图片来自何宽 http://t.csdn.cn/pDDFz 博文,我觉得很生动形象
执行步骤:
- 随机初始化一个与A[l]向量结构相同的矩阵D[l]
- 将D[l]值转化为0或1
- 舍弃A[i]的一些节点
- 为了不影响下一层的值,缩放未舍弃的节点
#######dropout正则化#######
def forward_propagation_with_dropout(X,parameters,keep_prob=0.5):
"""
实现具有随机舍弃节点的前向传播
Parameters
----------
X------输入数据集
parameters------
W1-------权重矩阵,维度为(20,2)
b1-------偏向量,维度为(20,1)
W2-------权重矩阵,维度为(3,20)
b2-------偏向量,维度为(3,1)
W3-------权重矩阵,维度为(1,3)
b3-------权重矩阵,维度为(1,1)
keep_prob------随机删除的概率
Returns
-------
A3-----最后的激活值,维度为(1,1),正向传播的输出
cache----存储反向传播参数的元组
"""
np.random.seed(1)
W1=parameters["W1"]
b1 = parameters["b1"]
W2=parameters["W2"]
b2 = parameters["b2"]
W3=parameters["W3"]
b3 = parameters["b3"]
Z1=np.dot(W1,X)+b1
A1=reg_utils.relu(Z1)
D1=np.random.rand(A1.shape[0],A1.shape[1])########初始化矩阵D1
D1 = D1 < keep_prob ######将D1的值转化为0或1,python中的False和True等于0和1.
#######即D1=0的概率为1-keep_prob
A1=A1*D1 #######舍弃A1的一些节点
A1=A1/keep_prob######缩放未舍弃的节点的值,为了不影响Z2
Z2=np.dot(W2,A1)+b2
A2=reg_utils.relu(Z2)
D2=np.random.rand(A2.shape[0],A2.shape[1])
D2=D2<keep_prob
#######即D1=0的概率为1-keep_prob
A2=A2*D2 #######舍弃A1的一些节点
A2=A2/keep_prob######缩放未舍弃的节点的值,为了不影响Z2
Z3 = np.dot(W3, A2) + b3
A3 = reg_utils.sigmoid(Z3)
cache=(Z1,D1,A1,W1,b1,Z2,D2,A2,W2,b2,Z3,A3,W3,b3)
return A3,cache前向传播改变了,后向传播也得变了:
########改变了前向传播的算法,我们也需要改变后向传播的算法
def backward_propagation_with_dropout(X,Y,cache,keep_prob):
"""
实现我们随机删除的模型的后向传播
Parameters
----------
X----------维度为(2,示例数)
Y---------维度为(输出节点数量,示例数量)
cache------来自forward_propagation_with_dropout()的cache
keep_prob-----随机删除的概率
Returns
-------
gradients------关于每一个参数,激活值和预激活变量的梯度值的字典
"""
m=X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)=cache
dZ3=A3-Y
dW3=(1/m)*np.dot(dZ3,A2.T)
db3=(1/m)*np.sum(dZ3,axis=1,keepdims=True)
dA2=np.dot(W3.T,dZ3)
dA2=dA2*D2 ######使用正向传播期间相同的节点,舍弃那些关闭的节点
dA2=dA2/keep_prob ####缩放未舍弃的节点值
dZ2=np.multiply(dA2,np.int64(A2>0))
dW2=(1/m)*np.dot(dZ2,A1.T)
db2=(1/m)*np.sum(dZ2,axis=1,keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dA1 = dA1 * D1 ######使用正向传播期间相同的节点,舍弃那些关闭的节点
dA1 = dA1 / keep_prob ####缩放未舍弃的节点值
dZ1=np.multiply(dA1,np.int64(A1>0))
dW1=(1/m)*np.dot(dZ1,X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradients={"dZ3":dZ3,"dW3":dW3,"db3":db3,"dA2":dA2,
"dZ2":dZ2,"dW2":dW2,"db2":db2,"dA1":dA1,
"dZ1":dZ1,"dW1":dW1,"db1":db1}
return gradients#########使用dropout正则化
parameters=model(train_X,train_Y,keep_prob=0.86,lambd=0,is_plot=True,learning_rate=0.3)
print("dropout正则化后训练集:")
predictions_train=reg_utils.predict(train_X,train_Y,parameters)
print("dropout正则化后测试集:")
predictions_test=reg_utils.predict(test_X,test_Y,parameters)
#####绘制决策边界
plt.title("model with dropoutregularization")
axes=plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters,x.T),train_X,train_Y)
plt.show()
dropout结果:
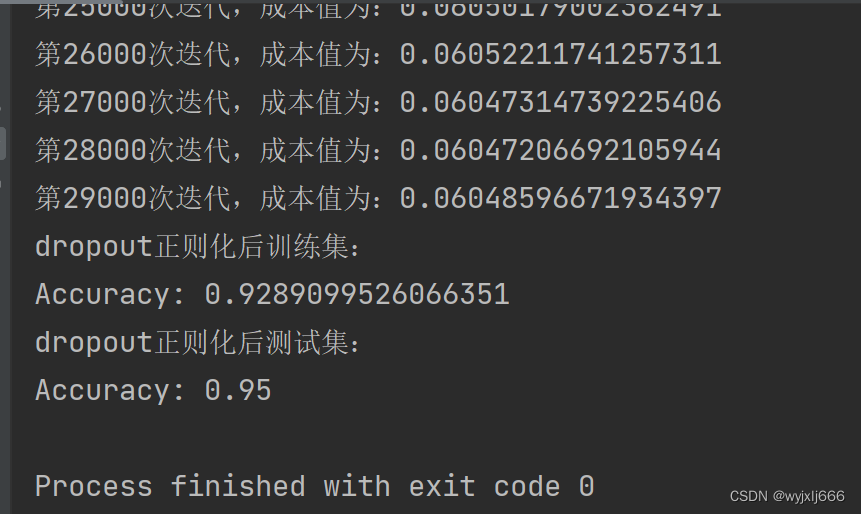
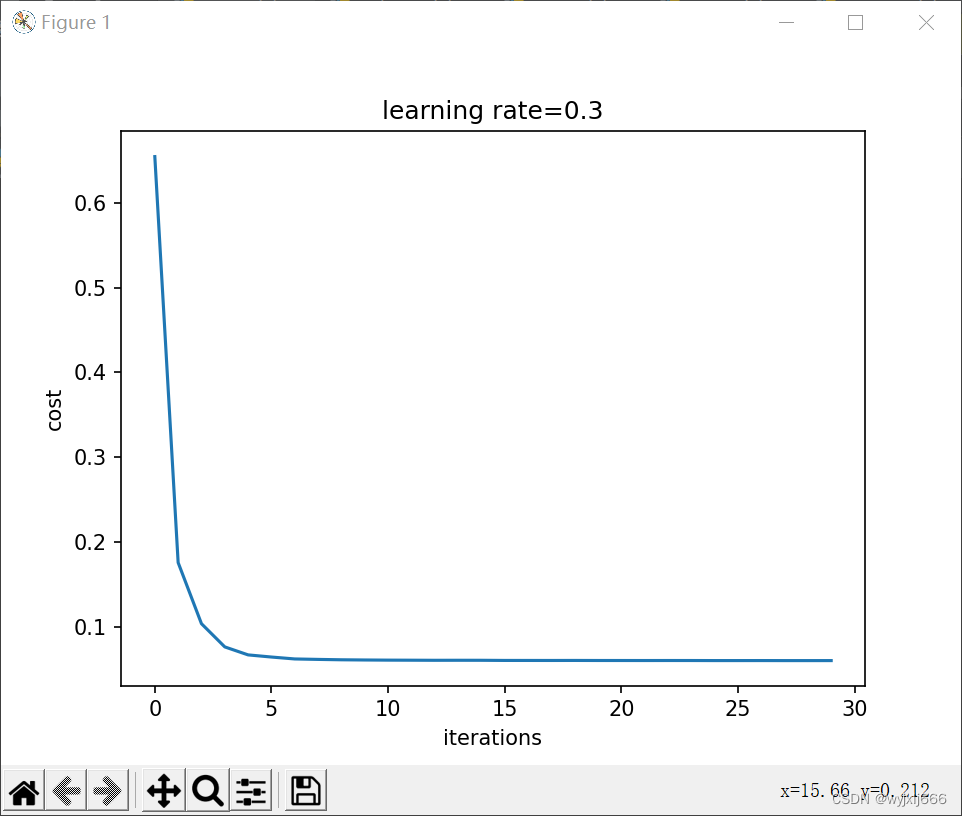
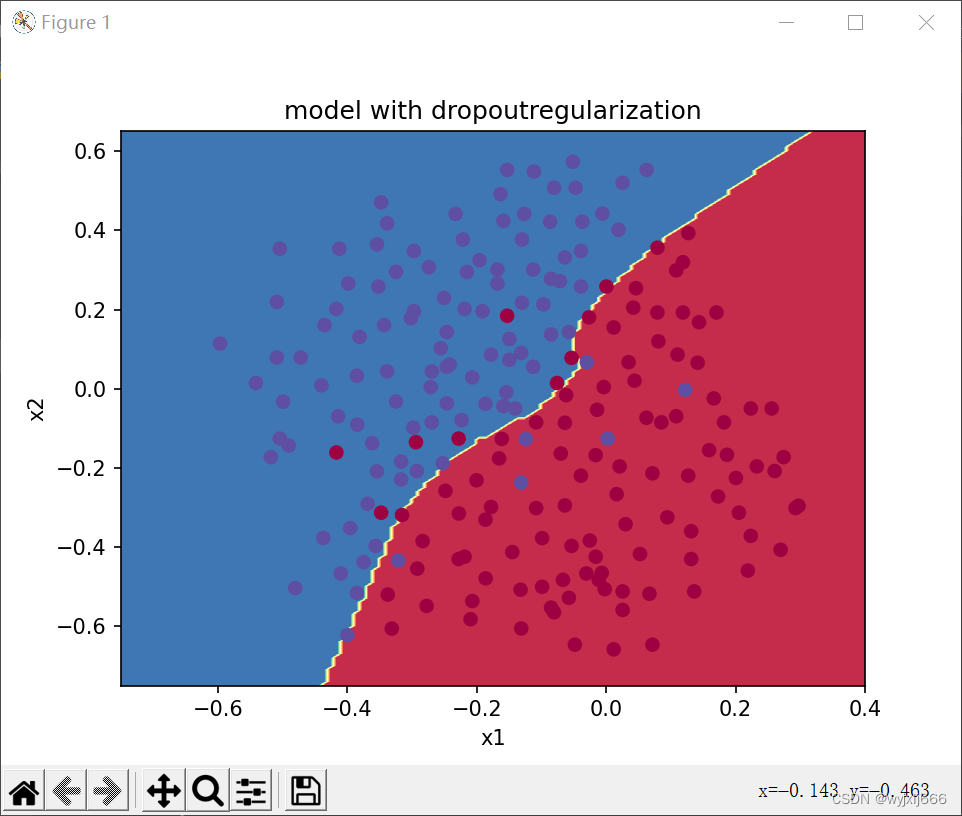
我们可以看到,dropout把训练集的准确度降低了,但是测试集的准确度提高了
2.4 其他正则化
除了以上的L2正则化,和dropout,还有以下两种
2.4.1 正则化数据集

2.4.1 early stopping


三、梯度检验
以检验反向传播是否得以正确的实施。

#########梯度检验######
######为了验证反向传播函数是否正确,以及梯度是否下降,进行的梯度检验
######高维梯度检验######
def forward_propagation_n(X,Y,parameters):
"""
实现途中的前向传播(并计算成本)
Parameters
----------
X------训练集为m个例子
Y------m个示例的标签
parameters - 包含参数“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典:
W1 - 权重矩阵,维度为(5,4)
b1 - 偏向量,维度为(5,1)
W2 - 权重矩阵,维度为(3,5)
b2 - 偏向量,维度为(3,1)
W3 - 权重矩阵,维度为(1,3)
b3 - 偏向量,维度为(1,1)
Returns
-------
cost-----成本函数(logistic)
"""
m=X.shape[1]
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
####linear->relu->linear->relu->linear->sigmoid
Z1=np.dot(W1,X)+b1
A1=gc_utils.relu(Z1)
Z2=np.dot(W2,A1)+b2
A2=gc_utils.relu(Z2)
Z3=np.dot(W3,A2)+b3
A3=gc_utils.sigmoid(Z3)
######计算成本
logprobs=np.multiply(-np.log(A3),Y)+np.multiply(-np.log(1-A3),1-Y)
cost=(1/m)*np.sum(logprobs)
cache=(Z1,A1,W1,b1,Z2,A2,W2,b2,Z3,A3,W3,b3)
return cost,cache
######实现反向传播####
def backward_propagation_n(X,Y,cache):
"""
Parameters
----------
X------输入节点数量
Y-----标签
cache
Returns
-------
gradients
"""
m=X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3=A3-Y
dW3=(1/m)*np.dot(dZ3,A2.T)
db3=(1/m)*np.sum(dZ3,axis=1,keepdims=True)
dA2=np.dot(W3.T,dZ3)
dZ2=np.multiply(dA2,np.int64(A2>0))
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dA1=np.dot(W2.T,dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients######梯度检验#####
def gradient_check_n(parameters,gradients,X,Y,epsilon=1e-7):
"""
检查backward_propogation_n是否正确计算forward_propagation_n输出的成本梯度
Parameters
----------
parameters
gradients
X
Y
epsilon-----------计算输入的微笑漂移以近似梯度
Returns
-------
difference--------近似梯度和后向传播之间的差异
"""
#######初始化参数
parameters_values,keys=gc_utils.dictionary_to_vector(parameters)
grad=gc_utils.gradients_to_vector(gradients)
num_parameters=parameters_values.shape[0]
J_plus=np.zeros((num_parameters,1))
J_minus=np.zeros((num_parameters,1))
gradapprox=np.zeros((num_parameters,1))
####计算gradapprox
for i in range(num_parameters):
thetaplus=np.copy(parameters_values)
thetaplus[i][0]=thetaplus[i][0]+epsilon
J_plus[i],cache=forward_propagation_n(X,Y,gc_utils.vector_to_dictionary(thetaplus))
thetaminus=np.copy(parameters_values)
thetaminus[i][0]=thetaplus[i][0]-epsilon
J_minus[i],cache=forward_propagation_n(X,Y,gc_utils.vector_to_dictionary(thetaminus))
####计算 gradapprox[i]
gradapprox[i]=(J_plus[i]-J_minus[i])/(2*epsilon)
######通过计算差异比较gradapprox和后向传播梯度
numerator=np.linalg.norm(grad-gradapprox)
denominator=np.linalg.norm(grad)+np.linalg.norm(gradapprox)
difference=numerator/denominator
if difference<1e-7:
print("梯度检查:梯度正常")
else:
print("梯度检查:梯度超出阈值")
return difference
######测试梯度检验
print("--------测试gradient_check----------")
x,y,parameters = testCase.gradient_check_n_test_case()
cost,cache=forward_propagation_n(x,y,parameters)
gradients=backward_propagation_n(x,y,cache)
difference=gradient_check_n(parameters,gradients,x,y,epsilon=1e-7)
print("difference="+str(difference))结果:
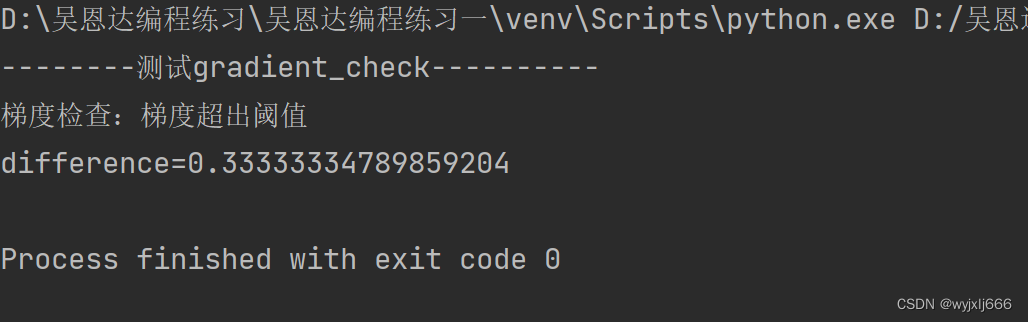
emmmmm,梯度检查正常的误差不能超过1e-7,不知道那一步出了错。
梯度检验注意事项:
- 不要在训练时使用梯度检验,因为它太慢了
- 注意正则项,如果有L2正则项,梯度检验也要带上该正则项
- 梯度检验不能与dropout同时使用
总结
以上就是优化深层神经网络的一些方法,总体上收获了很多。但也有不足之处,比如我不知道梯度检验失败后,该如何检查。希望下次的学习,能在此基础上有所改进。加油!!!共勉!















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









