







前言
本人遥感小白,记录一下上周裁剪踩过的坑吧。
裁剪原理
裁剪原理,个人理解是根据矢量文件,获取矢量文件的范围,根据这个范围创建一个与矢量文件尺寸一致的掩膜文件,从这个思路出发,我粗略的对某个地区进行了矢量裁剪。当然也可以调用gdal.Warp进行裁剪,更简单,代码跟少,但也会有问题(可能我对这块理解有点问题),具体问题下面会说到。
代码
下面开始紧张的代码环节: 
代码
首先展示一下GDAL裁剪的代码
#author CUIT_RS191_TCY
from osgeo import gdal
input_file = 'G:/Test/'
output_file = 'G:/Test/Clip/'
input_shape = 'G:/Test/Test.shp'
prefix = '.tif'
if not os.path.exists(output_file):
os.mkdir(output_file)
file_all = os.listdir(input_file)
for file_i in file_all:
if file_i.endswith(prefix):
file_name = input_file + file_i
data = gdal.Open(file_name)
ds = gdal.Warp(output_file + os.path.splitext(file_i)[0] + '_Clip.tif',
data,
format = 'GTiff',
cutlineDSName = input_shape,
cutlineWhere="FIELD = 'whatever'",
dstNodata = 0)
到这里调用gdal进行裁剪的代码完成!改一下输入路径和输出路径即可使用,输出结果如下:
这是输出的图像

你以为这就是全部吗?不不不,真实的范围是这个样子!

他把整幅图像掩膜了,而不是矢量文件那部分

一张图33.3M,我要出上千张,这谁顶得住啊。果断换掉!(当然我对gdal了解也不是很多,有大佬能解决这个问题,欢迎联系我)

代码二
接下来上自己的理解,虽然裁剪有些小问题,但总归是能接受
#author CUIT_RS191_TCY
from osgeo import gdal,gdal_array
import os
import numpy as np
import shapefile
from PIL import Image,ImageDraw
def write_tif(img_data,output_name,proj,geoinfo):
driver = gdal.GetDriverByName('GTiff')
cols = img_data.shape[1]
rows = img_data.shape[0]
out_file = driver.Create(output_name,cols,rows,1,6)
out_file.SetGeoTransform(geoinfo)
out_file.SetProjection(proj)
out_file.GetRasterBand(1).WriteArray(img_data)
del out_file
def get_clip_extent(geoinfo,shp_x,shp_y):
ul_x = geoinfo[0]
ul_y = geoinfo[3]
x_res = geoinfo[1]
y_res = geoinfo[5]
geo_x_pos = int((shp_x - ul_x)/x_res)
geo_y_pos = int((ul_y - shp_y)/abs(y_res))
return (geo_x_pos,geo_y_pos)
def img2array(img):
data = gdal_array.numpy.frombuffer(img.tobytes(),'b')
data.shape = img.im.size[1],img.im.size[0]
return data
input_file = 'G:/Test/'
output_file = 'G:/Test/Clip/'
shp_file = 'G:/Test/Test.shp'
prefix = '.tiff'
if not os.path.exists(output_file):
os.mkdir(output_file)
file_all = os.listdir(input_file)
for file_i in file_all:
if file_i.endswith(prefix):
file_name = input_file + file_i
output_name = output_file + os.path.splitext(file_i)[0] + '_Clip.tiff'
data = gdal.Open(file_name)
data_Array = gdal_array.LoadFile(file_name)
proj = data.GetProjection()
geoTrans = data.GetGeoTransform()
shp_data = shapefile.Reader(shp_file)
minX,minY,maxX,maxY = shp_data.bbox
start_pos_x,start_pos_y = get_clip_extent(geoTrans,minX,maxY)
end_pos_x,end_pos_y = get_clip_extent(geoTrans,maxX,minY)
clip = data_Array[start_pos_y:end_pos_y,start_pos_x:end_pos_x]
clip_width = end_pos_x - start_pos_x
clip_height = end_pos_y - start_pos_y
geoinfo_new = list(geoTrans)
geoinfo_new[0] = minX
geoinfo_new[3] = maxY
pixels = []
for pixel in shp_data.shape(0).points:
pixels.append(get_clip_extent(geoinfo_new,pixel[0],pixel[1]))
rastershp = Image.new('L',(clip_width,clip_height),1)
rasterize = ImageDraw.Draw(rastershp)
rasterize.polygon(pixels,0)
mask = img2array(rastershp)
clip = gdal_array.numpy.choose(mask,(clip,0.0)).astype(gdal_array.numpy.float32)
write_tif(clip,output_name,proj,geoinfo_new)
结果图如下:

这才是好的范围嘛,这才是正常的文件大小嘛。当然也出现了一些小问题,但总体问题不大。

裁剪的文件有点小偏移,少于一个像元,对裁剪范围内数据进行定量分析问题不大。如果介意的话可以修改一下角点坐标,或者直接把get_clip_extent函数修改一下。
代码三(最为准确)
既然上面两种方法,都不能获得位置完全精确的裁剪文件,那么必然会有一些较真的小伙伴们会问有没有一种方法能获得准确的结果,这时候我们就有必要引入一个大部分地学人都用到过的方法,那就是arcmap中的ExtracByMask。

代码如下:
#author CUIT_RS191_TCY
import arcpy
import os
import glob
arcpy.CheckOutExtension('Spatial')
arcpy.gp.overwriteOutput = 1
#arcpy.env.workspace = 'G:/Ice_phenology/2002_LST/test/'
input_file = 'G:/Test/'
output_file = 'G:/Test/Clip/'
shp_file = 'G:/Test/Test.shp'
prefix = '.tif'
tail = os.path.splitext(shp_file)[0][36:]#这里可自行修改
if not os.path.exists(output_file):
os.mkdir(output_file)
#rasters = arcpy.ListRasters('*',".tiff")
file_all = os.listdir(input_file)
for file_i in file_all:
if file_i.endswith(prefix):
file_name = input_file + file_i
output_name = output_file + os.path.splitext(file_i)[0] + tail + '_Clip.tif'
arcpy.gp.ExtractByMask_sa(file_name,shp_file,output_name)
print('The clip of {} has completed!'.format(file_i))
print('The project has completed! Congratulation!!!')
for file_i in glob.glob(os.path.join(output_file,'*.xml')):
os.remove(file_i)
for file_i in glob.glob(os.path.join(output_file,'*.tfw')):
os.remove(file_i)
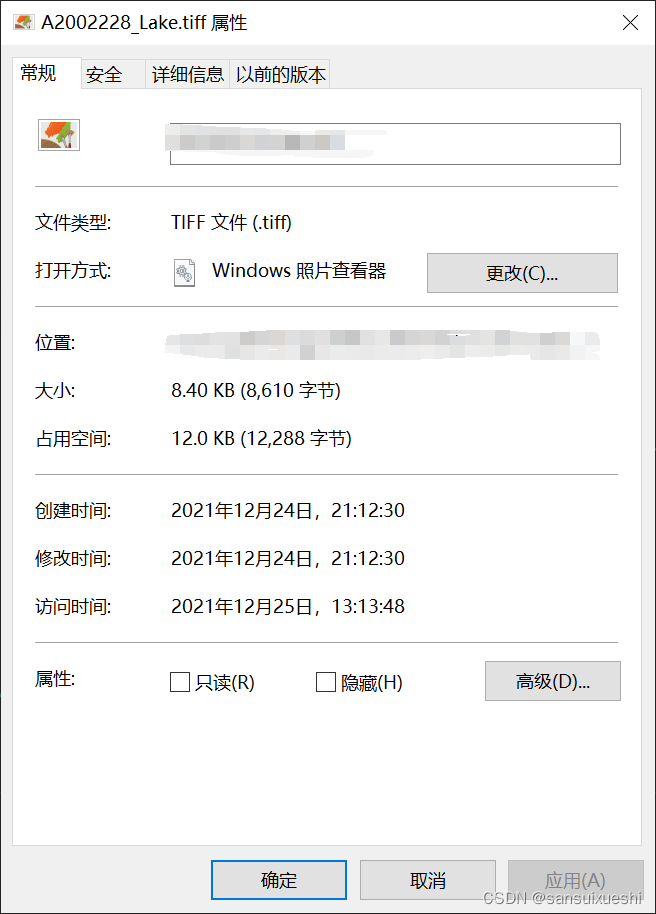
这里的结果也是最好的,如下

既然都看了,客官不点个关注吗?嘿嘿嘿

小结
以上三种方法,可自行选用,由于我也才入行不久,大佬勿喷。














 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









