






梦开始的地方,从最小二乘法开始学机器学习
从这篇博客开始,我们将逐步实现不同的机器学习代码,以此来深入学习了解不同的机器学习背后的原理~
00. 参考资料
我们的参考书有如下:
- [周志华老师的《机器学习》](机器学习 (豆瓣) (douban.com))
- [《南瓜书》](南瓜书PumpkinBook (datawhalechina.github.io))
- [李航老师的《统计学习方法》](统计学习方法(第2版) (豆瓣) (douban.com))
01. 从线性回归问题开始
西瓜书正式开始讲机器学习算法便是从这里入手的,所以这里也就是我们启航的地方。
线性模型几乎是大部分人接触的第一个机器学习模型,它形式非常的简单,所以这也是我们的第一站。那么首先我们需要明白,线性回归问题是一个回归问题, 回归问题多是处理连续值的,又或者可以理解为:尽量的画出一条线,让结果都尽量的离这条线越近越好。
与此相反的,分类问题就是来处理离散值的,也就是去将结果尽量地通过我们画的线区分开来。
所以该怎么去区分回归还是分类?当然是通过我们的需求了。
02. 线性回归的问题提出
一句话来总结,线性回归就是想办法让所有点到线的距离之和最小化。
所以我们该如何去解决这个问题?这就是最小二乘法的作用了。
我们通常见到的一个数学公式来描述一条直线的,通常会是这样:
f
(
x
)
=
w
x
+
b
f(x)=wx+b
f(x)=wx+b
其中w代表我们变量前的系数,b代表截距,又或者我们在这里称它为偏执。
我们将以下的点代入进去:
x = [1, 3, 5, 8, 11, 15]
y = [1, 7, 12, 20, 26, 36]
绘图看一下结果:

如果是我们来画一条线的画,我们可以非常轻松的画出一个大致差不多的答案:

但是当数据量多了起来,当数据维度多了起来,我们又该怎么办了呢?
就如同周志华老师书中的那个公式一样:
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
…
+
w
d
x
d
+
b
f(x)=w_{1}x_{1}+w_{2}x_{2}+ \ldots +w_{d}x_{d}+b
f(x)=w1x1+w2x2+…+wdxd+b
通过向量的方式,我们可以将公式转换成如下:
f
(
x
)
=
w
T
x
+
b
f(x)=w^{T}x+b
f(x)=wTx+b
怎么样通过计算机,来找出这样一条线,就是我们今天所需要去做的。
03. 线性回归问题的数学理论推导
我们之前说过,线性回归就是为了所有点到线的距离之和最小化。所以我们以最基础的 f ( x ) = w x + b f(x)=wx+b f(x)=wx+b来展开推导:
所以我们需要得到的结果就是让得到一个让每个点竖直到直线的值最小。即我们将每个点到直线的公式可以写成这样:
d
i
s
t
a
n
t
=
∣
f
(
x
)
−
y
∣
distant = |f(x)-y|
distant=∣f(x)−y∣
其中f(x)是我们预测的线上的点,而y是离散的点的y坐标,也就是实际结果。
随后我们需要将所有点的distant之和最小:
d
i
s
t
a
n
t
_
s
u
m
=
a
r
g
min
∑
i
=
1
m
∣
f
(
x
i
)
−
y
i
∣
distant\_sum = arg\min \sum _{i=1}^{m}|f(x_{i})-y_{i}|
distant_sum=argmini=1∑m∣f(xi)−yi∣
但是在这里,我们如果通过绝对值的方式就很难再继续展开求解,因为我们没有办法去求导了。于是有什么办法在不改变数值特性的情况下,又方便求导呢?我们将绝对值替换成了平方的方式,完美的解决了这个问题~
d
i
s
t
a
n
t
_
s
u
m
2
=
a
r
g
min
∑
i
m
(
f
(
x
i
)
−
y
i
)
2
distant\_sum^2 = arg \min \sum _{i}^{m}(f(x_{i})-y_{i})^{2}
distant_sum2=argmini∑m(f(xi)−yi)2
接下来我们将
f
(
x
)
f(x)
f(x)展开看看吧:
d
i
s
t
a
n
t
_
s
u
m
2
=
a
r
g
m
i
n
∑
i
=
1
m
(
y
i
−
ω
x
i
−
b
)
2
distant\_sum^2 = arg min\sum _{i=1}^{m}(y_{i}- \omega x_{i}-b)^{2}
distant_sum2=argmini=1∑m(yi−ωxi−b)2
接下来我们我们就要开始秀了!
不知道大家是否还记得偏导呢?在百度百科中,它的定义如下:
在数学中,一个多变量的函数的偏导数,就是它关于其中一个变量的导数而保持其他变量恒定(相对于全导数,在其中所有变量都允许变化)。如果大家忘记怎么算了,可以先去回顾一下,这里不做详细介绍了。
于是我们将偏导运用进来,就可以求出不同变量的最小值点了!于是我赶快写下了求导公式:
∂
E
(
w
,
b
)
∂
w
=
2
(
w
∑
i
=
1
m
x
i
2
−
∑
i
=
1
m
(
y
i
−
b
)
x
i
)
∂
E
(
w
,
b
)
∂
b
=
2
(
m
b
−
∑
i
=
1
m
(
y
i
−
w
x
i
)
)
\frac{ \partial E_{(w,b)}}{ \partial w}=2(w \sum _{i=1}^{m}x_{i}^{2}- \sum _{i=1}^{m}(y_{i}-b)x_{i})\\\frac{ \partial E_{(w,b)}}{ \partial b}=2(mb- \sum _{i=1}^{m}(y_{i}-wx_{i}))
∂w∂E(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi)∂b∂E(w,b)=2(mb−i=1∑m(yi−wxi))
公式推导详见南瓜书~建议先自己手推一下,这个难度不高。
随后我们再看,我们现在希望让偏导的结果都为0,于是我们把等号左边置零。这个时候上面的那个公式存在着w和b两个未知数,一看就不是现在可以解的,于是我们可以先求解对b求偏导的结果。
于是我们得到了这样的公式:
b
=
1
m
∑
i
=
1
m
(
y
i
−
ω
x
i
)
b= \frac{1}{m} \sum _{i=1}^{m}(y_{i}- \omega x_i)
b=m1i=1∑m(yi−ωxi)
将b的结果作为已知值代入w中计算,于是也可以求解出公式如下:
w
=
∑
i
=
1
n
y
i
(
x
i
−
x
‾
)
∑
i
=
1
m
x
i
2
−
1
m
(
∑
i
=
1
m
x
i
)
2
w= \frac{ \sum _{i=1}^{n}y_{i}(x_{i}- \overline{x})}{ \sum _{i=1}^{m}x_{i}^{2}- \frac{1}{m}( \sum _{i=1}^{m}x_{i})^{2}}
w=∑i=1mxi2−m1(∑i=1mxi)2∑i=1nyi(xi−x)
看着这个离谱的公式,我陷入了沉思…
这还玩不玩了?我敲这代码岂不是会把自己绕死?
这里南瓜书给了我一个解决方法:
如果我们按照向量的方式去展开…我们就可以吧其中的部分公式做亿点点改动~

😮妙哉!于是我们通过这个方式,这个公式都可以通过numpy来解决了。
到这里,最小二乘法的基础形式我们就退到完毕了,但这样也只能去解决数据多的情况,也无法解决高维数据呀?所以接下来我们开始高维数据的解~
对于多维的数据,还是那个需求:所有点到线的距离之和最小化。
我们将偏执b并入权重w中得到
w
^
\widehat{w}
w
,而相对应的,我们再输入的数据中,也需要将变量X后面追加一个1作为偏执b的乘积项。于是X就成了如下的样子:
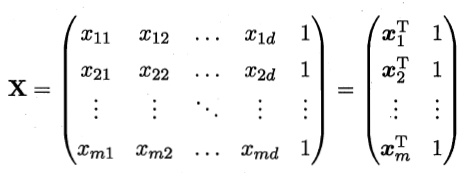
相对应的, y = ( y 1 ; y 2 ; … ; y m ) y=(y_{1};y_{2}; \ldots ;y_{m} ) y=(y1;y2;…;ym)
于是我们可以列出distant:
d
i
s
t
a
n
t
=
a
r
g
m
i
n
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
distant = argmin(\mathbf y-\mathbf X \widehat{w})^{T}(\mathbf y-\mathbf X \widehat{w})
distant=argmin(y−Xw
)T(y−Xw
)
仍旧是对不同的偏执去求导:
∂
E
ω
^
∂
ω
^
=
2
X
T
(
X
ω
^
−
y
)
\frac{ \partial E \widehat{ \omega }}{ \partial \widehat{ \omega }}=2X^{T}(X \widehat{ \omega }-y)
∂ω
∂Eω
=2XT(Xω
−y)
继续将等式左边置零,参考之前南瓜书中的求解方案,得到了最后的偏执的结果:
w
^
∗
=
(
X
T
x
)
−
1
X
T
y
\widehat{w}^{*}=(X^{T}x)^{-1}X^{T}y
w
∗=(XTx)−1XTy
实话实说,刚开始看的时候非常绝望,但多读几篇,就越觉得这些推到的精彩。
04. python代码实现
公式的推导就是为了降低计算机的时间以及空间复杂度的,将公式推导这个地步,我们可以通过短短几行就能解决这个问题了,代码如下:
"""
作为解决回归问题的函数库
需要预先安装numpy
"""
import numpy as np
class LSM:
"""
最小二乘法算法 数学公式推导见西瓜书\n
"""
def __init__(self, w=None):
self.w = w
def train(self, data, answer):
"""
训练拟合算法\n
:param data: numpy的二维数组,作为训练集的数据
:param answer: numpy的一维数组,作为训练集的答案
:return: 返回拟合后的系数
"""
data = np.mat(np.hstack((data, np.ones((len(data), 1)))))
self.w = np.array((data.T * data).I * data.T * answer.reshape(len(answer), 1)).T
return self.w
def detection(self, data):
"""
检测数据\n
:param data: 检测的数据集,依旧是二位数组
:return: 返回一个一维数组,是拟合答案
"""
data = np.hstack((data, np.ones((len(data), 1))))
return np.sum(self.w * data, axis=1)
def avg_loss(self, data, answer):
"""
检测得分\n
:param data: 待检测的数据集,二维数组
:param answer: 待核验的答案,一维数组
:return: 平均损失
"""
avg_loss = np.average((self.detection(data) - answer)**2)
return avg_loss
其中拟合过程就是代码的23,24行。【是不是第一次见这么简洁的代码】
这个是我自己做的myML中的一部分代码~目前还在完善中。
接下来我们把之前的输入输入,看看结果:
import numpy as np
import matplotlib.pyplot as plt
import regression # 自己之前写的那个库的名称
# LSM例程
data = np.array([1, 3, 6, 8, 11, 13, 18])
data = data.reshape(len(data), 1)
answer = np.array([1, 5, 13, 20, 22, 30, 35])
model = regression.LSM()
print('w:', model.train(data, answer))
predict = model.detection(data)
plt.scatter(data, answer, c='red')
plt.plot(data, predict, c='green')
plt.show()
print('loss:', model.avg_loss(data, answer))
运行结果如下:
![[外链图片转存中...(img-b9EuiX9I-1629530605582)]](https://img-blog.csdnimg.cn/8799d48a338f405d88cad03b01ffd7cf.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTYxMDI4,size_16,color_FFFFFF,t_70)
![[外链图片转存中...(img-VhchIjBe-1629530605585)]](https://img-blog.csdnimg.cn/e533b218598e45a5acc11f5d3229db0d.png)














 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









