






fa此次内容是学习2023.1月Datawhale开源的动手学数据分析。内容为本人原创,且内容为本人打卡学习所做的笔记,仅作参考。
目录
3.3 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
第一节 数据清洗及特征处理
Task01 缺失值的处理与观察
1.1 缺失值的检查
方法一:使用info()可以查看每一列非空数据的个数以及数据类型
data.info()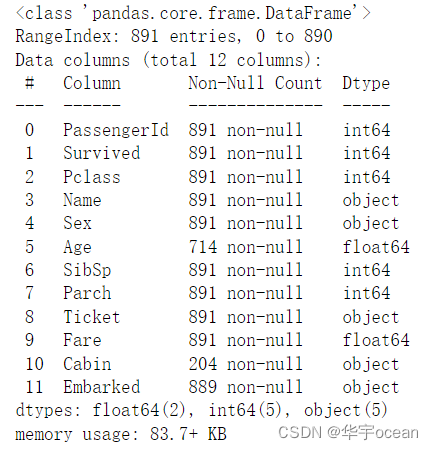
方法二:使用isnull()方法统计每一列缺失值的个数
data.isnull().sum()
1.2 缺失值的处理
以Age列为例进行说明,使用常数值填充缺失值
# 方法一
data[data['Age'].isnull()] = 5
#方法二
data[data['Age'] == np.nan] = 5
#方法三
data[data['Age'] == None] = 5【思考】检索空缺值用
np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
检查读取CSV文件之后,缺失值的类型
print("读入数据后,缺失值的类型为:",type(data["Cabin"][0]))
print("None的类型为:",type(None))
print("np.nan的类型为:",type(np.nan)) 
【思考解法】:
读取数据之后,缺失值的类型是float类型,而None是NoneType,np.nan是float类型,因此,一般比较使用np.nan更好,同时None因为类型的问题,可能会无法找到缺失值。
使用fillna()方法对整张表的缺失值进行填充
data.fillna(axis = 1, value = 10)
使用dropna()方法对整张表的缺失值进行删除
data.dropna()
【思考1】dropna和fillna有哪些参数,分别如何使用呢?
【思考一解答】:
dropna包含参数有[axis, how, thresh, subset, inplace]
其中axis:决定当存在nan参数时,是删除所在的行还是所在的列。默认值为0,即删除行。
how:有两个参数可选择[any, all]。默认是any,即只要存在一个nan就删除,all表示该行或者该列全都是nan才删除。
thresh:数值型,表示每一行至少存在几个非nan值。
subset:列表,表示从哪几列寻找nan值。
inplace:True / False, True即更新原来的dataframe数据,默认是False。fillna包含的参数有[value, method, axis, inplace, limit, downcast]
value:类型是scalar, dict, Series, or DataFrame,用于替换缺失值nan
method:{'backfill', 'bfill', 'pad', 'ffill', None}, default None
pad / ffill: 使用上一个有效值填充当前缺失值
backfill / bfill: 使用下一个有效值填充当前值
axis:{0 or 'index', 1 or 'columns'}
分别表示按行填充或者按列填充缺失值
limit: int, default None
表示最大只填充不超过给定值的缺失值个数。即limit = 2,最大只填充两个nan值,且与method相对应,没有给定method,则沿着轴进行填充。
downcast:dict, default is None
进行类型转换。
Task 02 重复值的观察与检查
2.1 重复值的检查
data.duplicated()使用上述代码返回一个矩阵,值为True / False。True表示重复值
data[data.duplicated()]显示重复值的数据
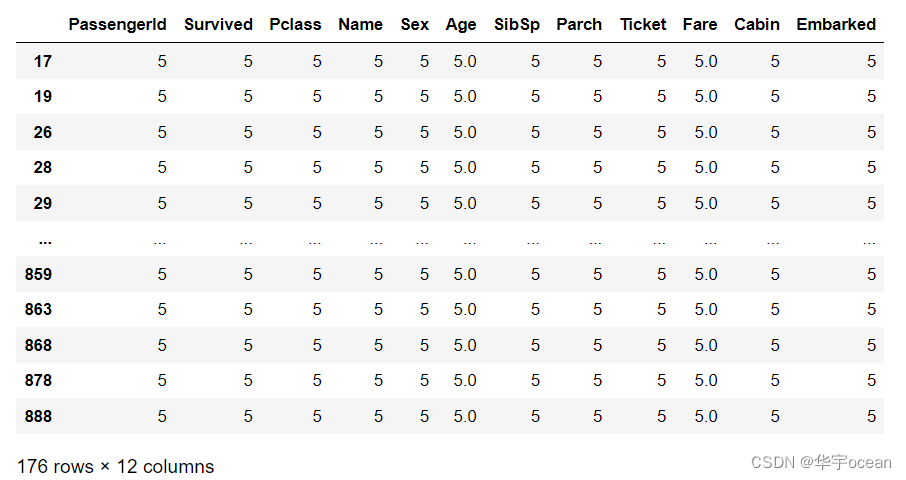
2.2 重复值的删除
data = data.drop_duplicates()
data.head(20)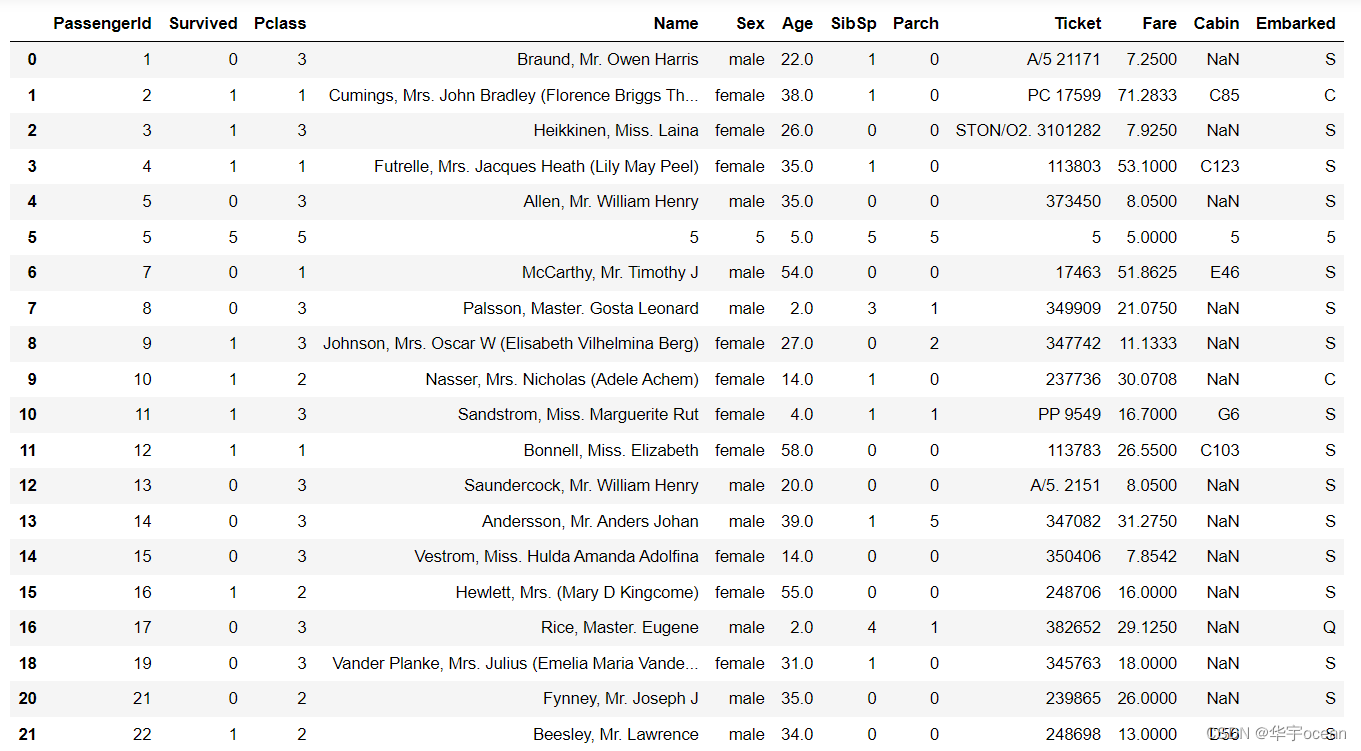
由该结果可知,重复值已经删除了。
Task 03 特征观察与处理
特征一般分为文本型特征与数值型特征,且每一类又分别包含连续性的特征与离散型的特征。在实际建模过程中,文本型特征一般需要转化为数值型特征,一般采用LabelEncode或者OneHot编码。数值型特征可以直接使用,但是有时候为了模型的鲁棒性更好,需要将数值类型的连续型特征转换为离散型特征。
3.1 对年龄进行离散化处理
1. 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
data['Age_ave'] = pd.cut(x = data["Age"], bins= 5, labels= [1, 2, 3, 4, 5])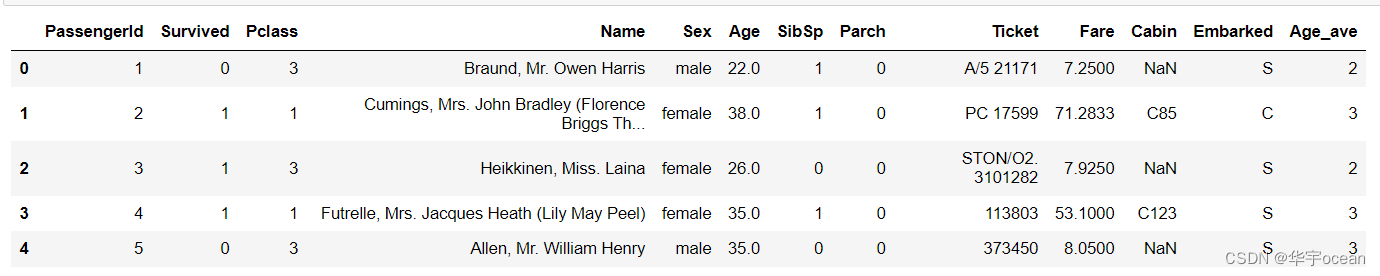
2. 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
data['Age_range'] = pd.cut(x = data["Age"], bins= [0, 5, 15, 30, 50, 80], labels= [1, 2, 3, 4, 5])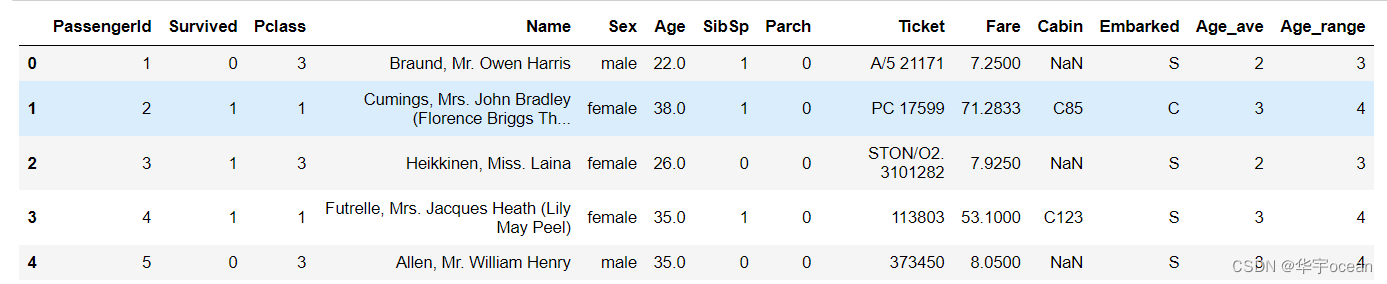
3. 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
data['Age_percentage'] = pd.qcut(x = data["Age"], q= [0, 0.1, 0.3, 0.5, 0.7, 0.9], labels= [1, 2, 3, 4, 5])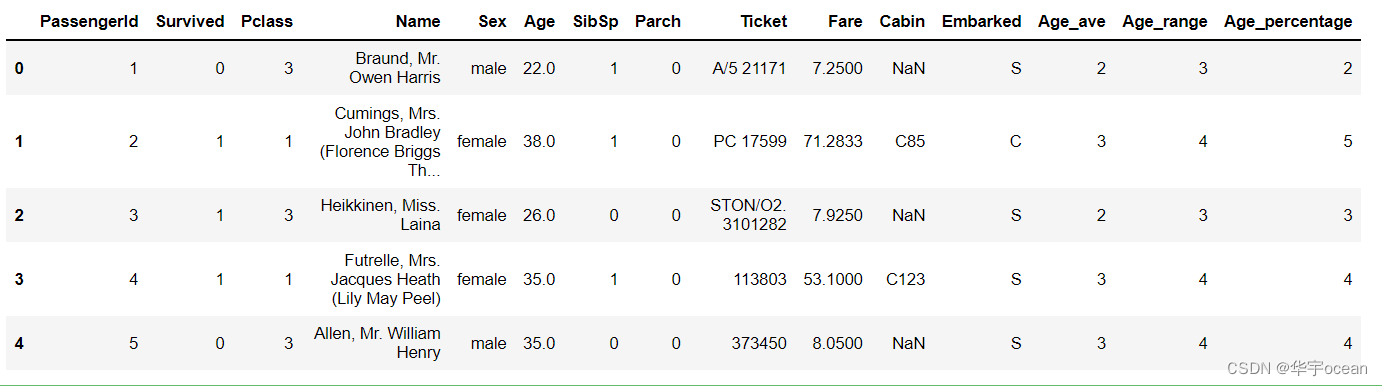
在第三个要求中,使用的是百分比,使用pd.cut()方法会报错,经过百度查询,pd.qcut()方法支持这种类型的分割
3.2 文本型特征数值化
1. 查看文本型变量名及种类
data['Sex'].value_counts() 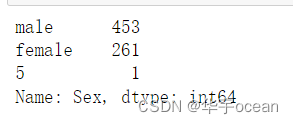
data['Sex'].unique()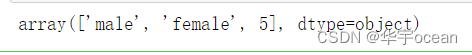
以上两种方法均可以查看一个特征包含的不同变量数,只不过第一种方法可以显示出每一种取值分别包含多少个数据。并且两种方法返回类型也不一致,分别是int64和object
2. 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
data["Sex_num"] = data["Sex"].replace(['male', 'female'], [0, 1])
使用replace方法直接将对应的文本型转化为数值型,同时还有map方法可以使用,以及sklearn中实现的LabelEncoder方法。
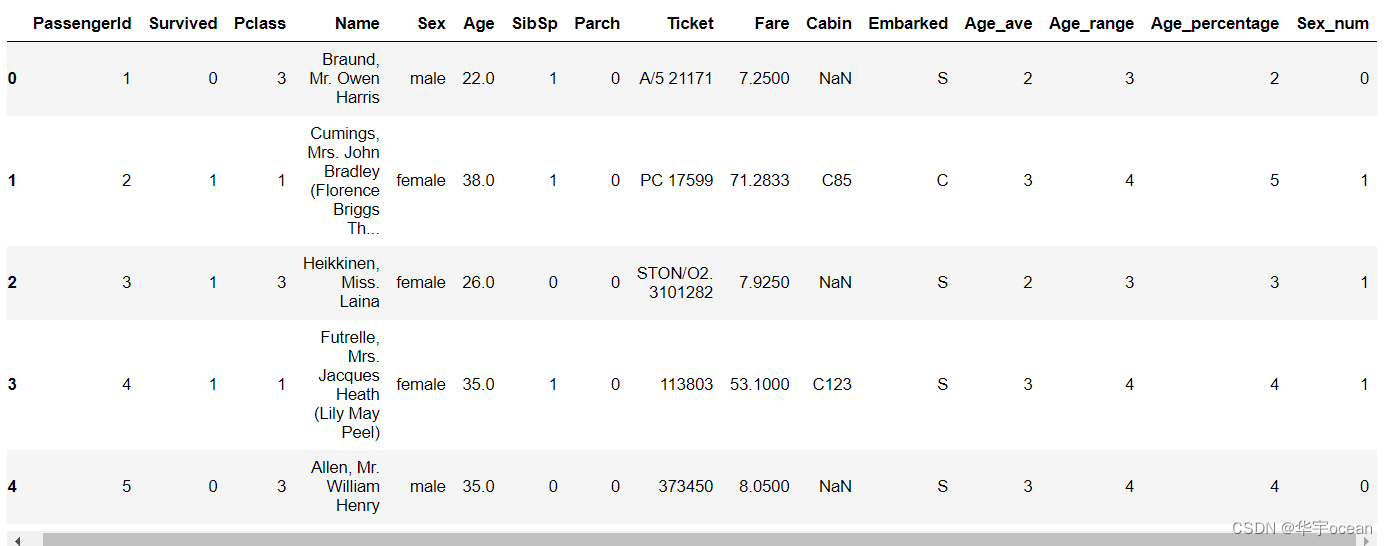
对于另外两个变量采用LabelEncoder的方法
from sklearn.preprocessing import LabelEncoder
for feature in ['Cabin', 'Embarked']:
le = LabelEncoder()
data[feature + "_Encode"] = le.fit_transform(data[feature].astype(str))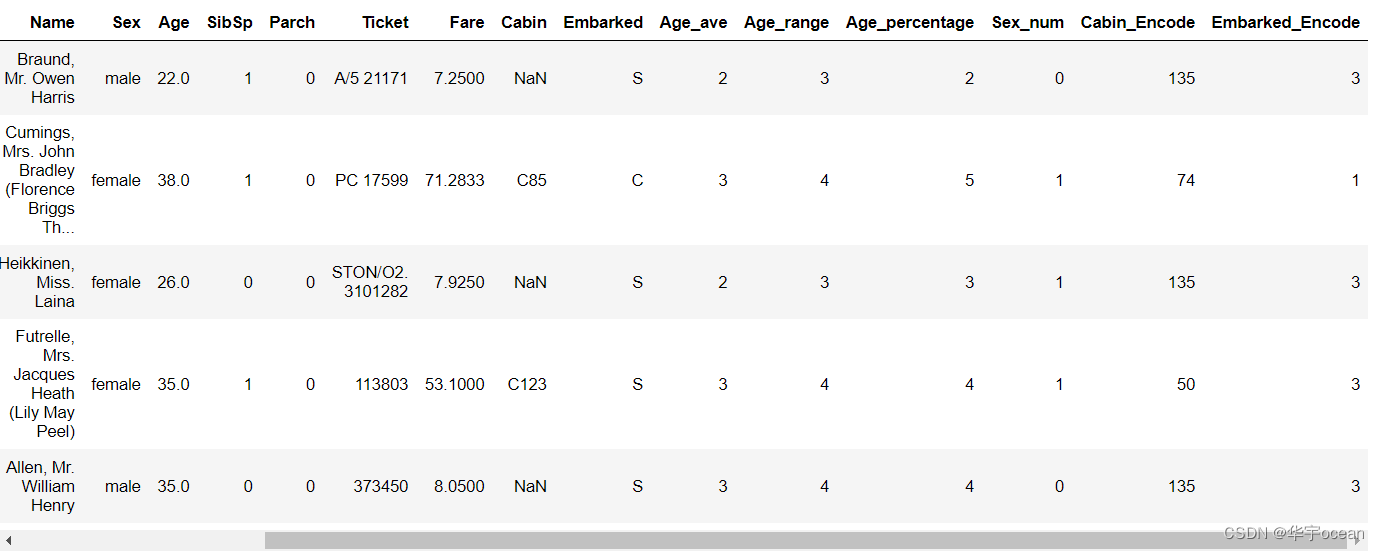
使用map方法进行转换
for feature in ['Cabin', 'Embarked']:
label_encode_dict = dict(zip(data[feature].unique(),
range(data[feature].nunique())))
data[feature + "_Encode"] = data[feature].map(label_encode_dict)使用map方法与LabelEncode方法的结果有些差别,他们使用的顺序不一致,比如LabeEncode这里他把Embarked的S用3表示,而在map方法中他为0,这与自己实现的方法有所相关。
这里使用map方法的结果没有保存,有兴趣的小伙伴可以自己实现一下。
3. 将文本变量Sex, Cabin, Embarked用one-hot编码表示
实现one-hot编码有sklearn中的OneHotEncoder和pandas自己的pd.get_dummies方法
ohe = OneHotEncoder(sparse= False)
x = ohe.fit_transform(data['Sex'].astype(str).values.reshape(-1, 1))

x = pd.get_dummies(data['Sex'], prefix='Sex')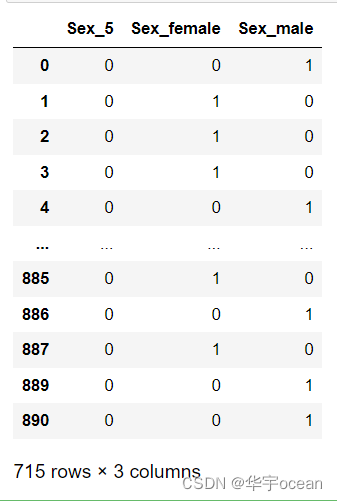
以上两种中,sklearn的方法返回的数组,pandas返回的是dataframe类型的数据,为了更好的拼接,这里我是用了pandas提供的方法
for feature in ['Sex', 'Cabin', 'Embarked']:
x = pd.get_dummies(data[feature], prefix=feature)
data = pd.concat([data, x], axis=1)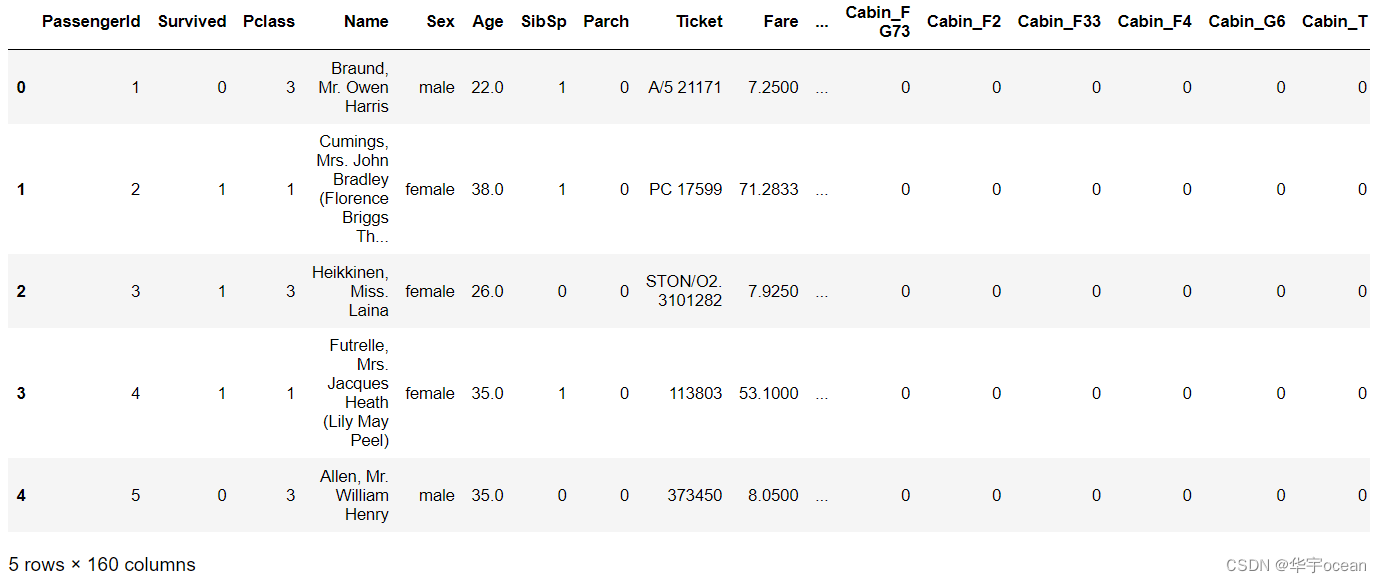
由上图可知,经过了one-hot编码,特征个数增加为至160个
3.3 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
data['Titles'] = data.Name.str.extract('([A-Za-z]+)\.')
这里使用了正则表达式的用法
总结
在本次学习中,学习到了pd.cut的方法,这可以将连续型的数值型特征转换为离散型的数值型特征,同时,掌握了sklearn中和pandas中one-hot编码的使用。在最后一个任务中,使用到了正则表达式。以下有对其的补充。
补充

















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









