







感兴趣的话大家可以关注一下公众号 : 猿人刘先生 , 欢迎大家一起学习 , 一起进步 , 一起来交流吧!
本篇文章主要说明的是一个Bean是在Spring中如何创建的 , 也就是Bean的生命周期 , 在传统的Java应用中,bean的生命周期很简单,使用Java关键字 new 进行Bean 的实例化,然后该Bean 就能够使用了。一旦bean不再被使用,则由Java自动进行垃圾回收。
相比之下,Spring管理Bean的生命周期就复杂多了,正确理解Bean 的生命周期非常重要,因为Spring对Bean的管理可扩展性非常强 , 接下来我们慢慢的分析
流程图
我们可以先来看一下Bean生命周期的流程图 , 也就是一个Bean在创建的过程中经历了这些步骤
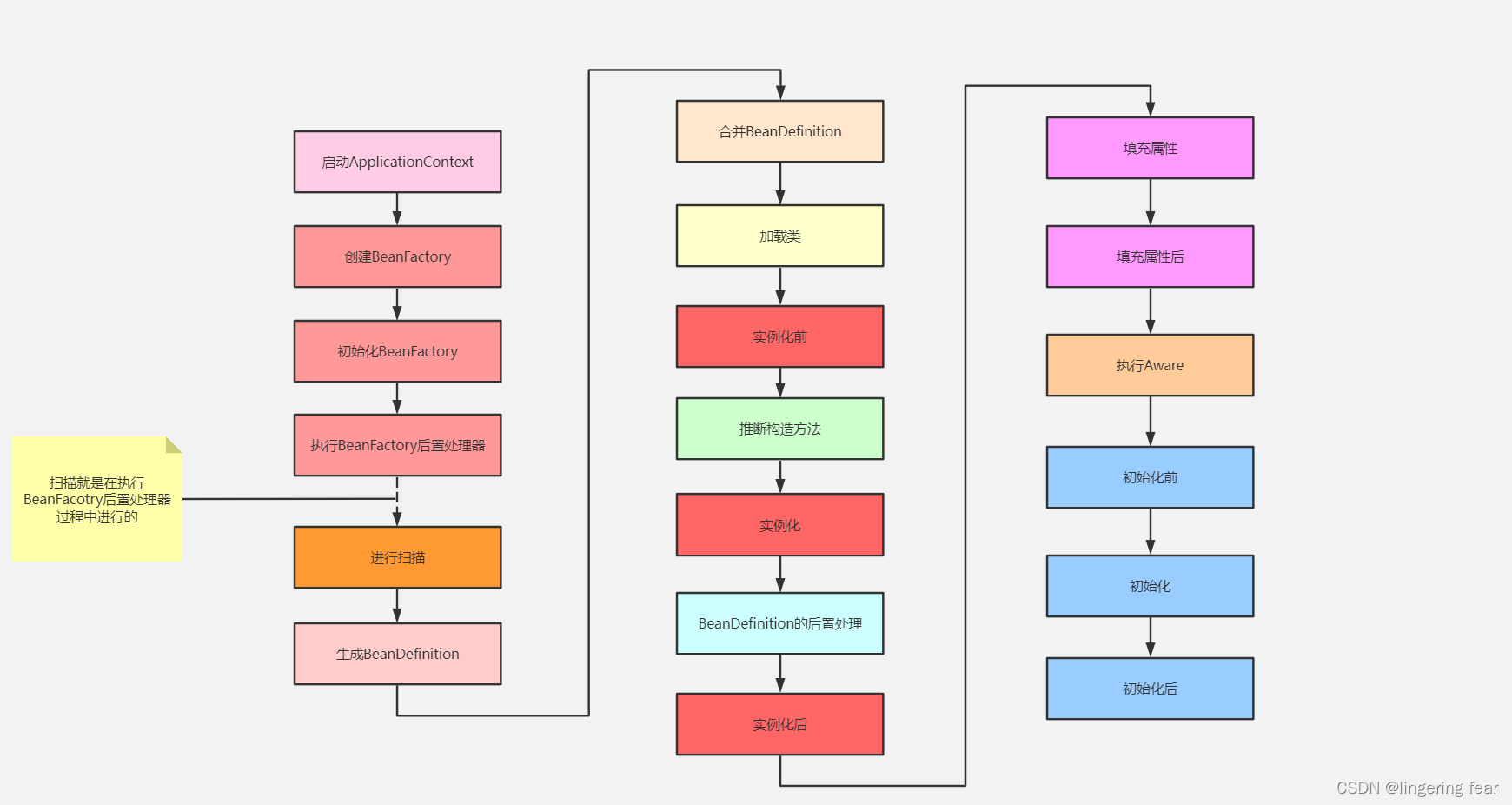
其实结合前面两篇文章的内容 , 我们也可以知道大概在Spring容器启动的时候 , 大概会做两件事情
1.扫描
2.创建非懒加载单例Bean
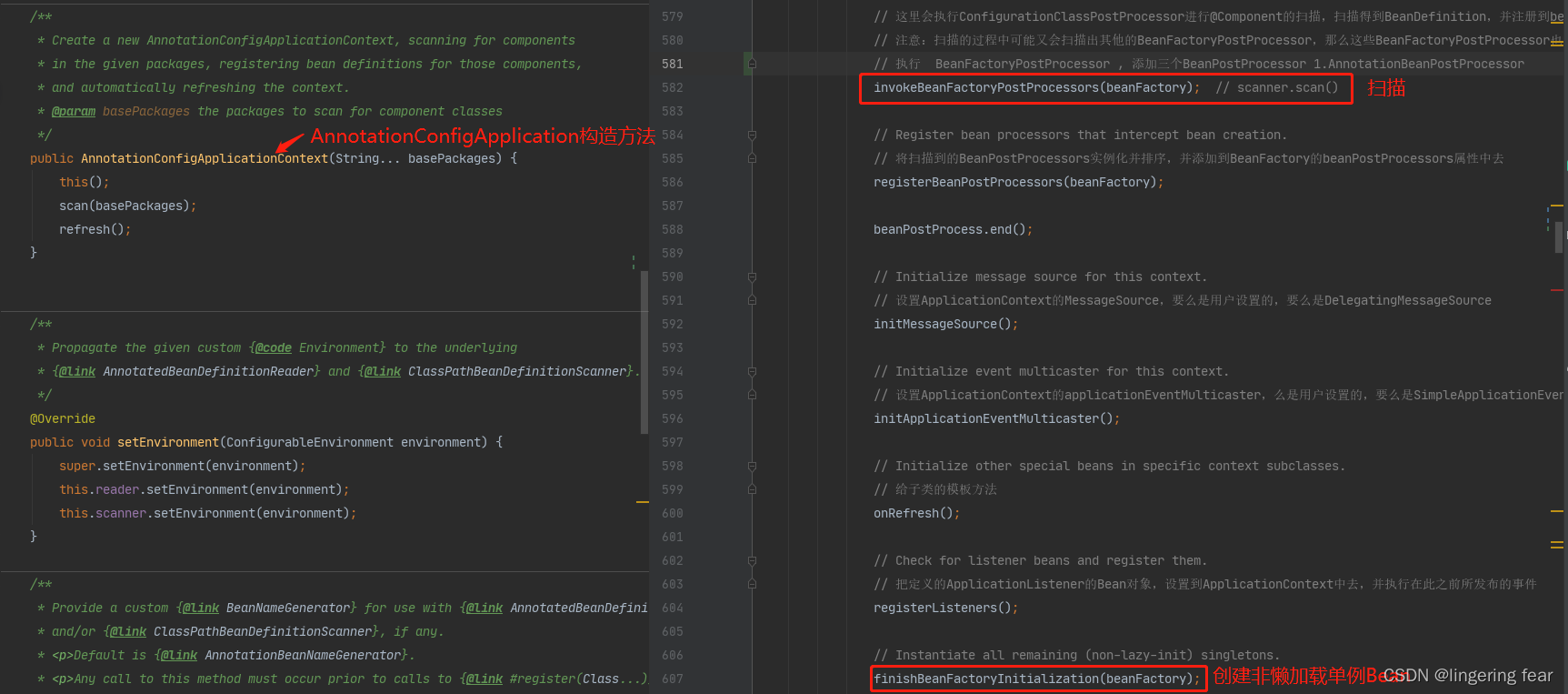
一.扫描
除了Spring启动等扫描可以说是Bean生命周期的第一步 , 扫描哪些类实现需要成为Bean的 , 我只有先扫描到哪些类是需要成为Bean的 , 我才能进行实例化 , 依赖注入 , 初始化等等步骤 , 而在构造方法的this()方法中会初始化读取器和扫描器
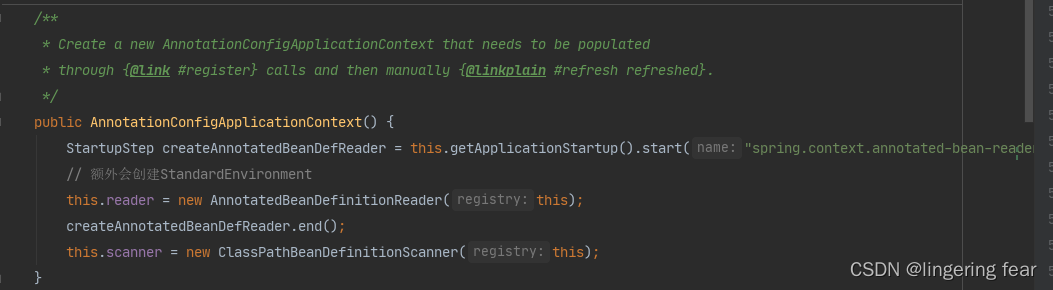 那么扫描的逻辑就是在扫描器ClassPathBeanDefinitionScanner中的scan()方法 , scan()方法会调用doScan()真正的逻辑是在doScan()中
那么扫描的逻辑就是在扫描器ClassPathBeanDefinitionScanner中的scan()方法 , scan()方法会调用doScan()真正的逻辑是在doScan()中
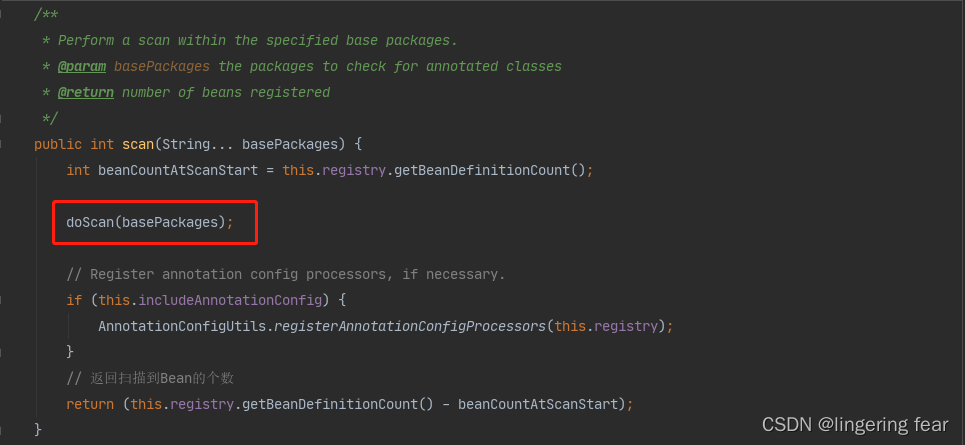
我们来看doScan()方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages)
首先doScan()方法需要一个入参 , 也就是一个包路径 , 然后Spring会调用findCandidateComponents()方法然后进行扫描 ,然后解析并得到一个BeanDefinition的集合
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
我们再来看findCandidateComponents()方法
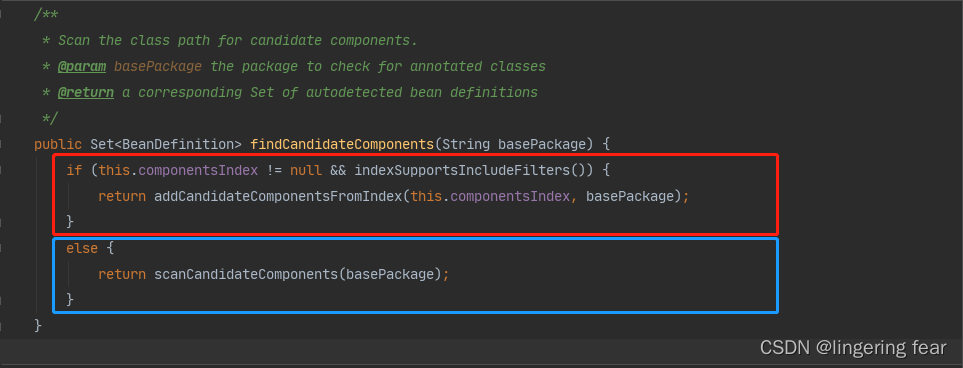
索引文件
上面的if的作用就是判断你是否定义了索引文件 , 因为这样扫描所有的class从而判断你是否能成为一个Bean的方式相对来说比较慢 , 那么Spring也提供了一种机制, 就是定义索引文件
比如这样定义一个配置文件

然后加入如下内容
com.lyh.service.UserService=org.springframework.stereotype.Component
这样的话就相当于直接定义我当前这个项目里边有哪些Bean , 就相当于直接告诉Spring , 我UserService这个类上有@Component注解 , 那么Spring会怎么做呢?
它会判断你有没有索引 , 也就是上面定义的spring.components文件 , 如果有调用addCandidateComponentsFromIndex()方法来解析 , 我们来看看这个方法
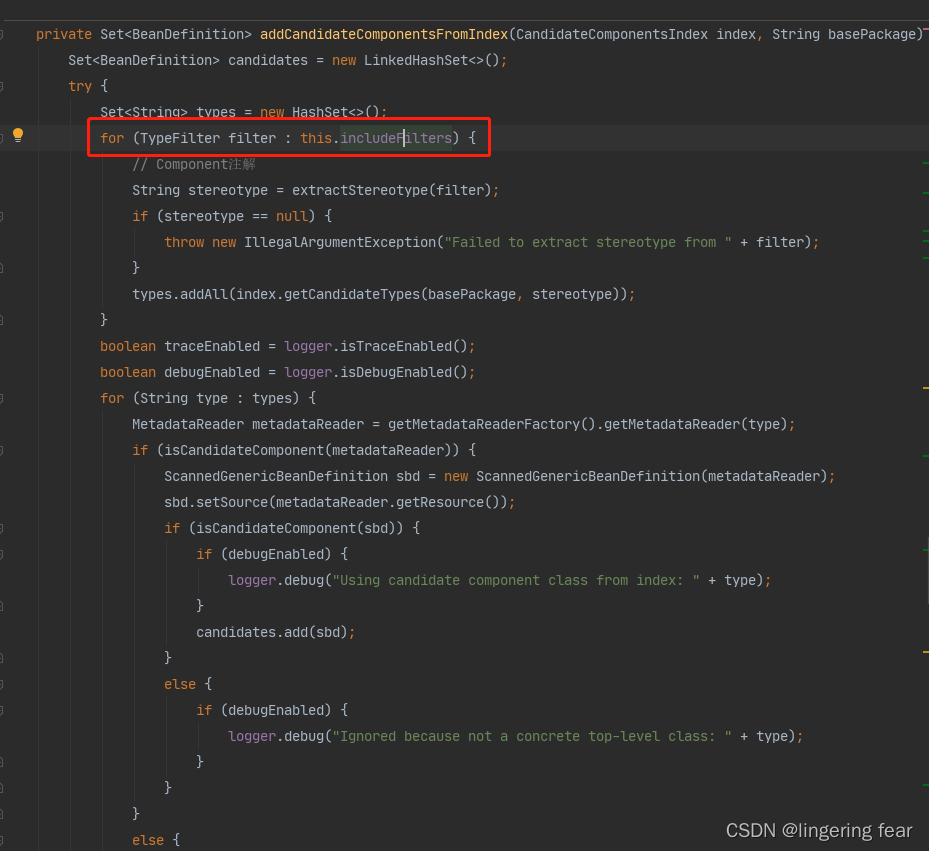
进来之后 , 我们会发现它首先循环你定义的过滤的内容 ,比如我定义的就是一个过滤component的一个过滤器
String stereotype = extractStereotype(filter);
然后它就会拿到你过滤的这个注解 , 也就是@Conponent
types.addAll(index.getCandidateTypes(basePackage, stereotype));
getCandidateTypes()方法就是获取配置文件的内容 ,然后过滤
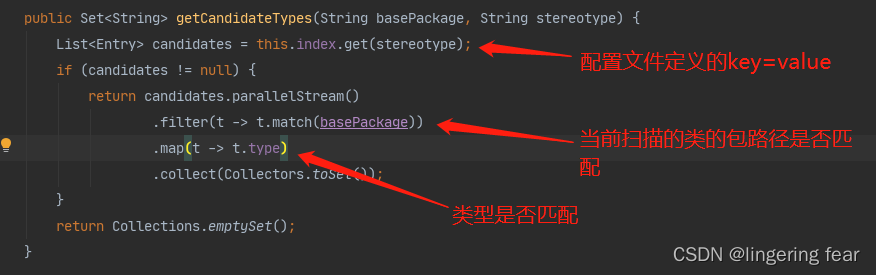
然后它会把符合的类型都放到一个集合 , 然后使用元数据读取器解析, 并使用ScannedGenericBeanDefinition封装成为BeanDefinition , 当然UserService也是要加@Component注解的
其实简单一点就是之前Spring不知道你那个类需要成为Bean , 所以对所有文件进行扫描, 现在你在配置文件直接告诉Spring , 然后Spring取到你配置文件的内容 , 然后解析封装成为BeanDefintion , 然后扫描完成了 , 不明白的话直接debug一波, 就清楚啦
默认情况下我们进的是下面的分析 , 也就是else的分支 , 我们来看scanCandidateComponents()方法:
1.构造一个LinkedHashSet , 用来存放最后扫描的结果
Set<BeanDefinition> candidates = new LinkedHashSet<>();
2.解析包路径
// 获取basePackage下所有的文件资源
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
CLASSPATH_ALL_URL_PREFIX
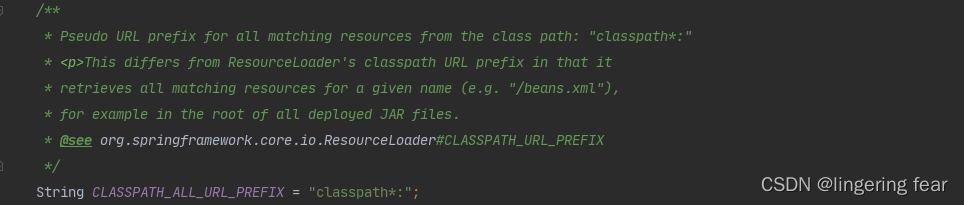
this.resourcePattern
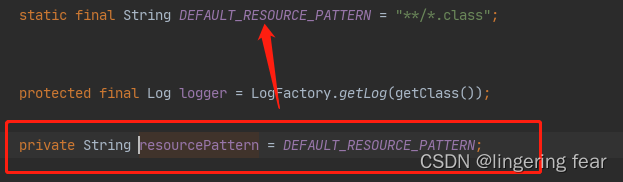
resolveBasePackage()方法的作用是将 . 替换为 /
比如说我们的包名是 : com.lyh.service
那么解析之后的包路径就是 : “classpath*:com/lyh/service/**/*.class”
然后根据解析得到的包路径并利用ResourcePatternResolver资源加载器来加载资源
加载资源的就是包路径下的class文件
得到的就是一个一个的class文件的file对象
3.将class解析为元数据读取器
第2步通过包路径然后加载class文件 , 并存放到一个数组中 , 也就是Resource[] , 然后遍历这个数组 , 如果当前资源可以读 , 那么就会把这个类解析为一个资源读取器
// 参数resource为当前正在遍历的资源
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
这样解析为一个元数据读取器之后 ,这个读取器就可以读取当前这个资源的信息 , 比如一些注解的信息 , 一些类的名称 , 是否是抽象类 , 包括这个类实现的接口等等一系列东西
它的底层使用的是ASM技术
4.过滤
这个过滤也就是过滤的我们通过以下这种方式排除或符合的Bean
@ComponentScan(value = "com.lyh",
excludeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)}.)
public class AppConfig {
}
也就是这个判断 , 我们点进去isCandidateComponent()方法看一下底层实现
@ComponentScan(value = "com.lyh",
includeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)})
public class AppConfig {
}
if (isCandidateComponent(metadataReader))
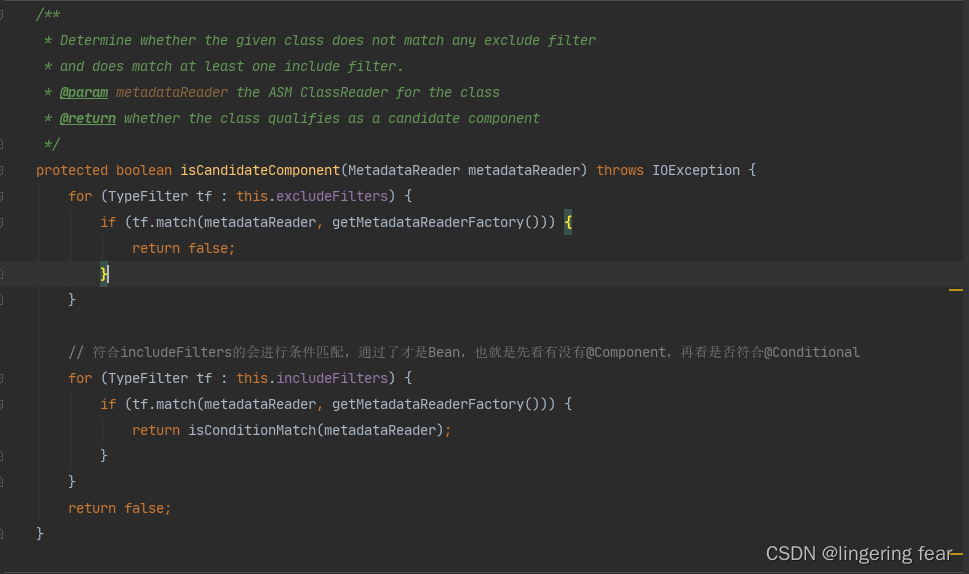
他在这里会判断如果是否需要排除或者符合条件的Bean , 只有符合条件的Bean才会真正的成为Bean , 如果有@Component注解 , 那么就会进入到isConditionMatch()方法来判断 , 然后重要的就是这个shouldSkip()方法
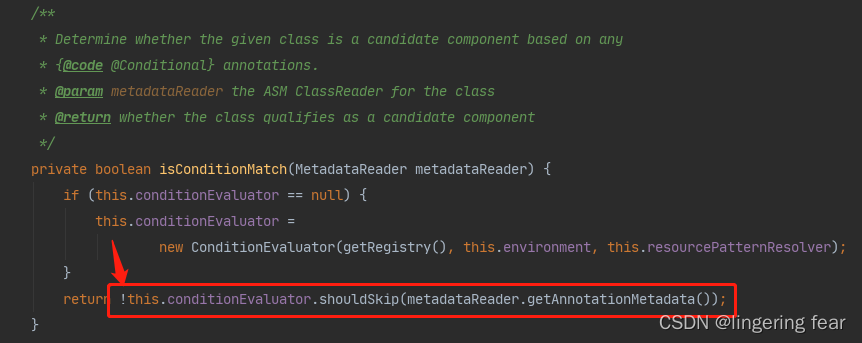
它会判断你是否有@Conditional注解 , 如果没有就跳过
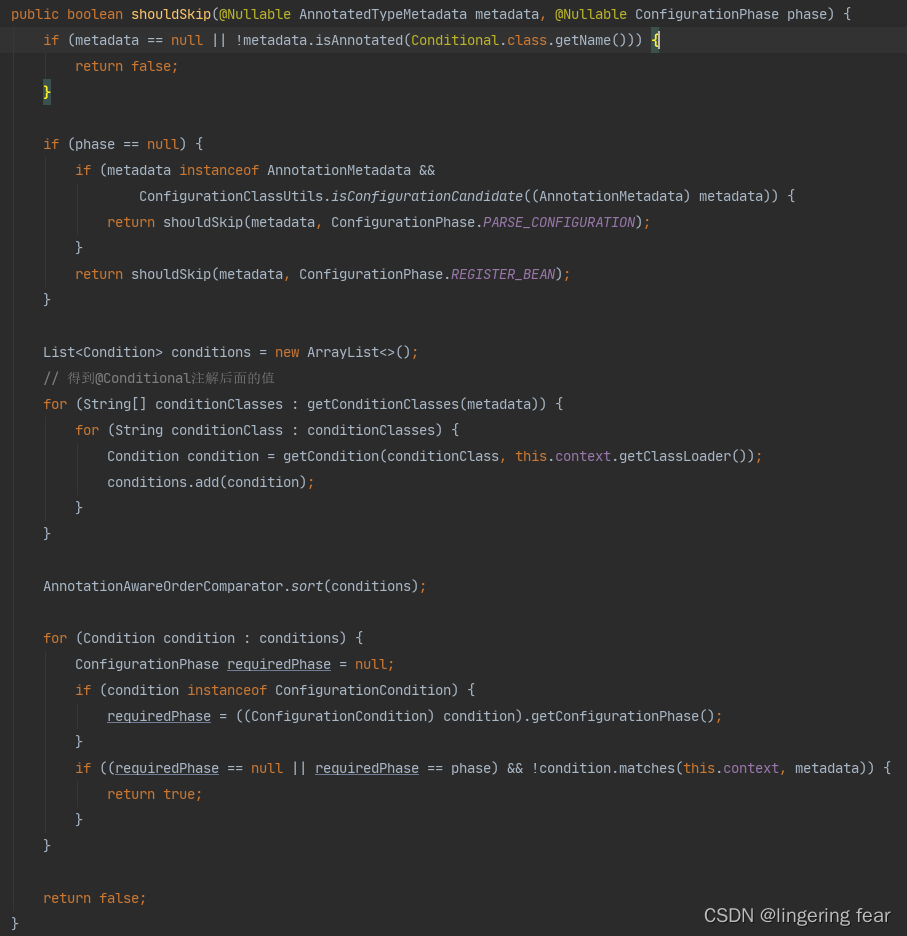
如果有@Conditional注解 , 它会解析注解的条件是否匹配 , 如果匹配 , 那么就不跳过, 如果不匹配 , 那么就跳过, 就表示不能成为一个Bean
5.判断是否是顶级类或接口等
if (isCandidateComponent(sbd))
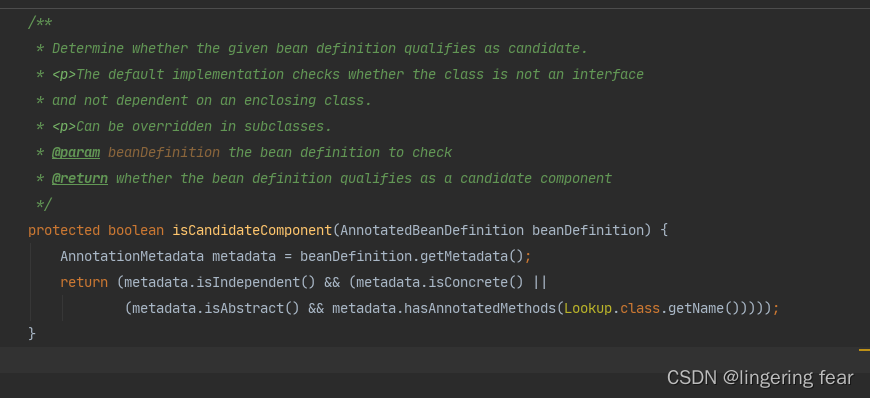
metadata.isIndependent() : 判断是否是顶级类或者是内部类
metadata.isConcrete() : 判断是否是接口或者是抽象类
metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))) : 如果是抽象类但是这个抽象类内部有随便一个方法加了@Lookup注解 , 那么它也可以成为一个Bean
@Lookup注解
我们通过一个demo来演示这个注解的作用
新建一个User类 , 并且使他的作用域为原型
@Component
@Scope(scopeName = "prototype")
public class User {
}
@Component
public class UserService {
@Resource
private User user;
public void test1(){
System.out.println("user : " + user);
}
}
然后我们这样多调用几次 , 那么每次输出user的值会一样吗?
public class TestSpring {
public static void main(String[] args){
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// 返回getObject()方法返回的Bean
UserService userService = (UserService)applicationContext.getBean("userService");
userService.test1();
userService.test1();
userService.test1();
userService.test1();
}
}
测试发现, 它们的值相同 , 为什么呢?
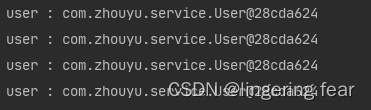
因为UserService是单例的 , 所以user也只会被赋一次值 , 那么如果想要体现出原型的效果 , 怎么做呢?
把UserService这样改造一下
@Component
public class UserService {
@Resource
private User user;
public void test1(){
System.out.println("user : " + a());
}
@Lookup("user")
public User a(){
return null;
}
定义一个方法 , 然后加上@Lookup注解
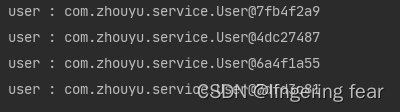
这个时候就体现除了原型的效果, 关于@Lookup注解的源码 , 我会在后续的文章来解释 , 此处只明白它的用法就行
6.添加扫描过滤结果到集合
最开始不是定义了一个BeanDefinition的集合吗, 如果第五步的判断也通过了 , 难么就添加到这个集合 , 并返回
到此为止 , 也扫描到了好多类 , 也生成了Beanfinition ,而现在的Beanfinition只有一个BeanClass属性 ,其他的属性还没有解析 , 然后我们在回到doScan()方法来看 , 刚刚我们说的是这个方法
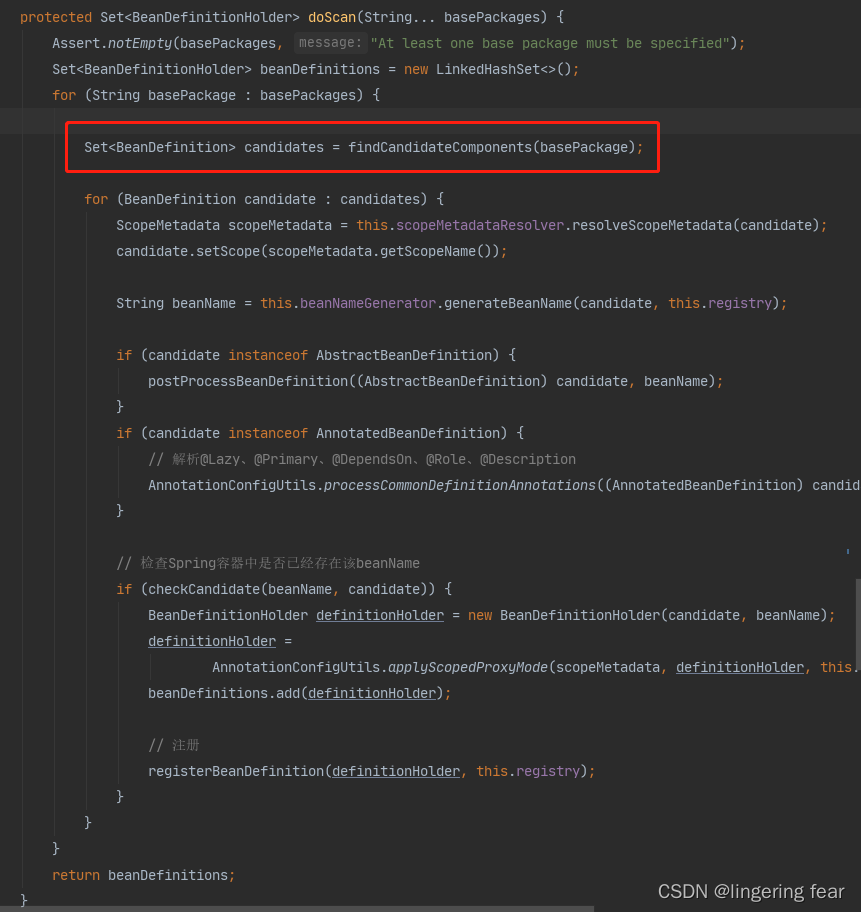
我们接着往下看
7.解析Scope属性
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
然后我们进入到这个实现类

我们可以看到 , 它就会解析Scope注解 , 然后放到Meta中,
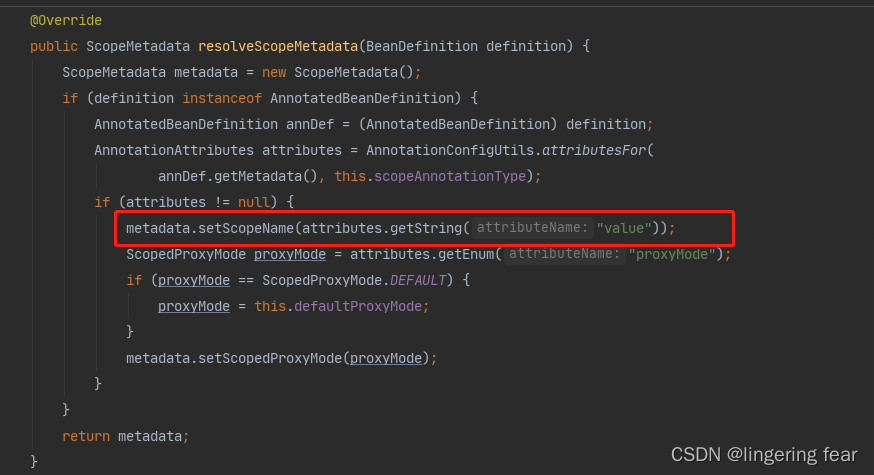
然后设置到BeanDefinition中
8.生成Bean的名字
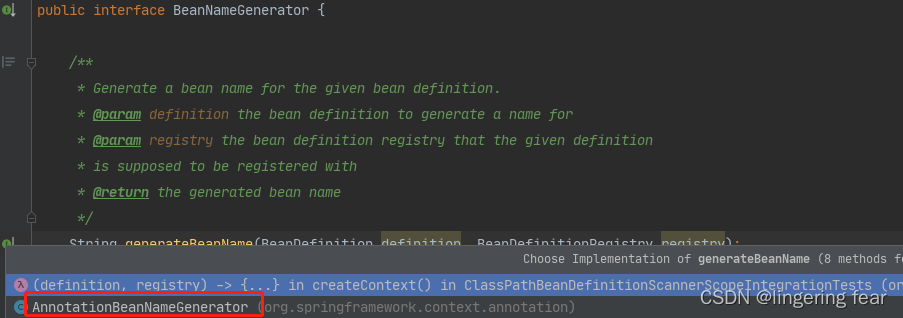
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
我们进入到generateBeanName()方法 , 点进入这个类
它会获取你注解上指定的名称 , 就比如这样定义@Component(“user”)
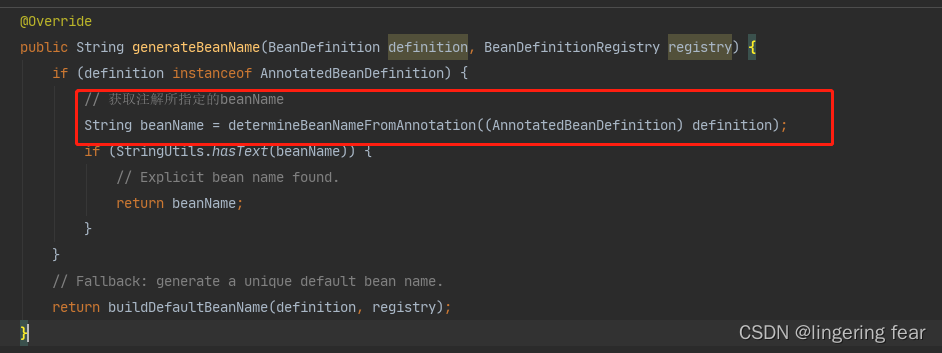
接着看isStereotypeWithNameValue()方法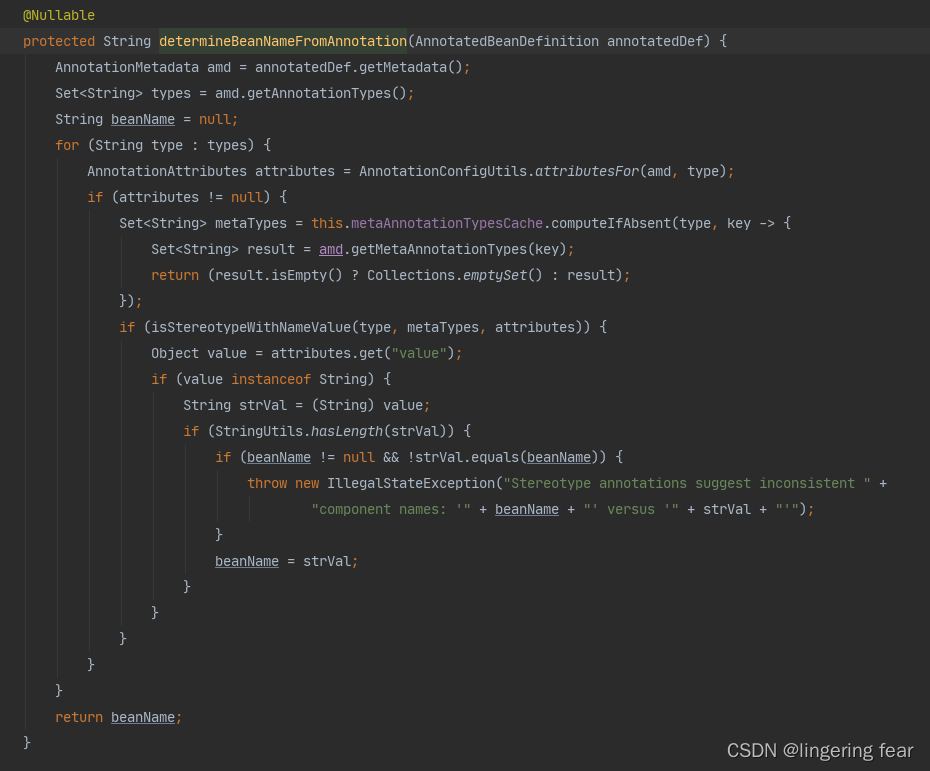
它就会判断你是否定义了这些注解
COMPONENT_ANNOTATION_CLASSNAME : org.springframework.stereotype.Component
如果有的话 , 它就会取你这个注解的值
Object value = attributes.get("value");
那么我得到的这个value就是Bean的名称 , 如果写了@Component但是没有指定值 , 那么就会返回空 , 因为beanName属性默认是空 , 如果是空 , 那么它就会默认去生成
也就是下面这一段
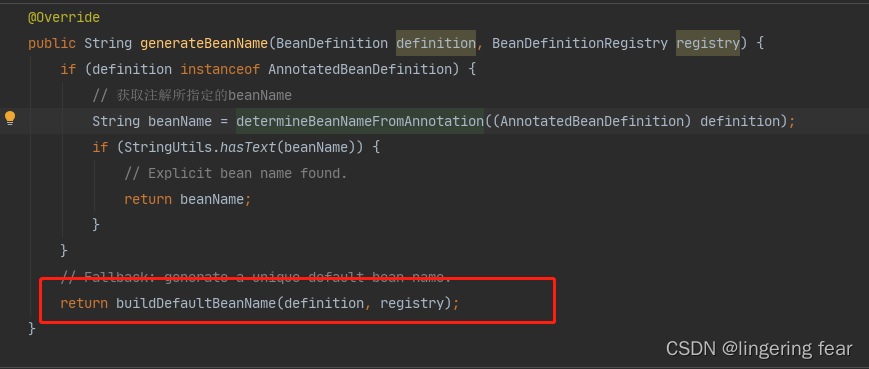
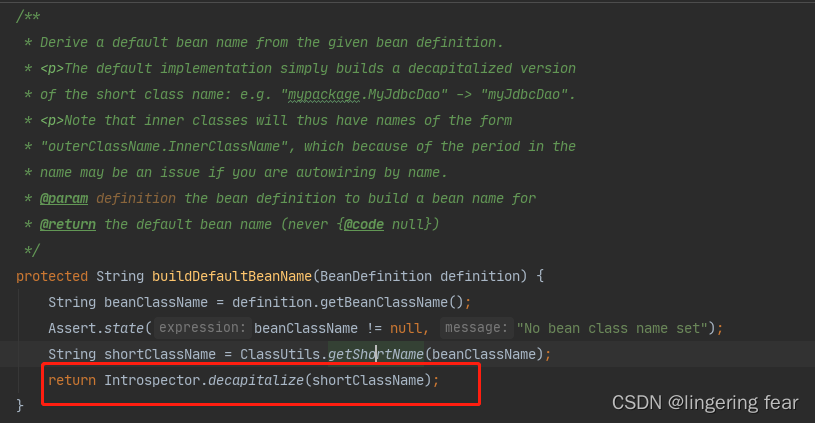
然后点进入buildDefaultBeanName()方法, 直到下面的方法 , 它就会把类的首字母小写 , 作为Bean的名称
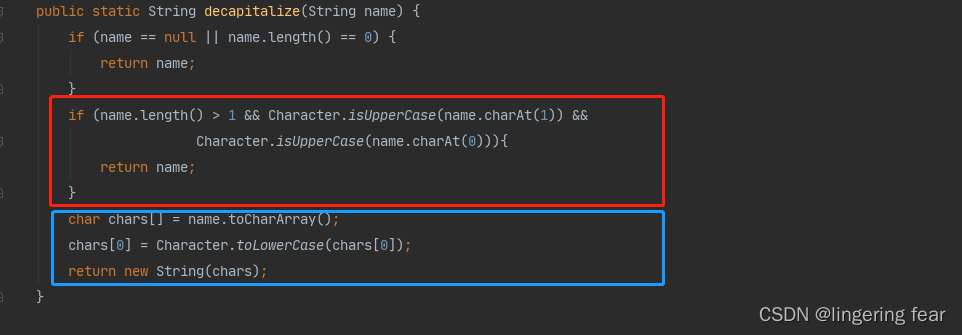
如果长度大于1 , 并且类的第一个第二字字母都是大写 , 那么就直接返回, 就是比如我们定义了一个名为这样的类 : ABtest , 那么这个类的名称就是ABtest
否则的话就将首字母小写 , 然后返回
9.是否实现了AbstractBeanDefinition接口
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
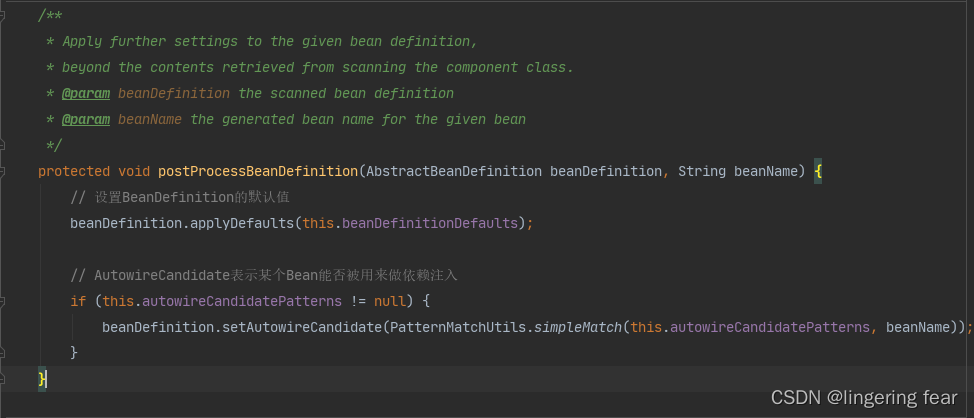
如果实现了AbstractBeanDefinition接口, 那么它会给当前BeanDefinition赋一些默认值
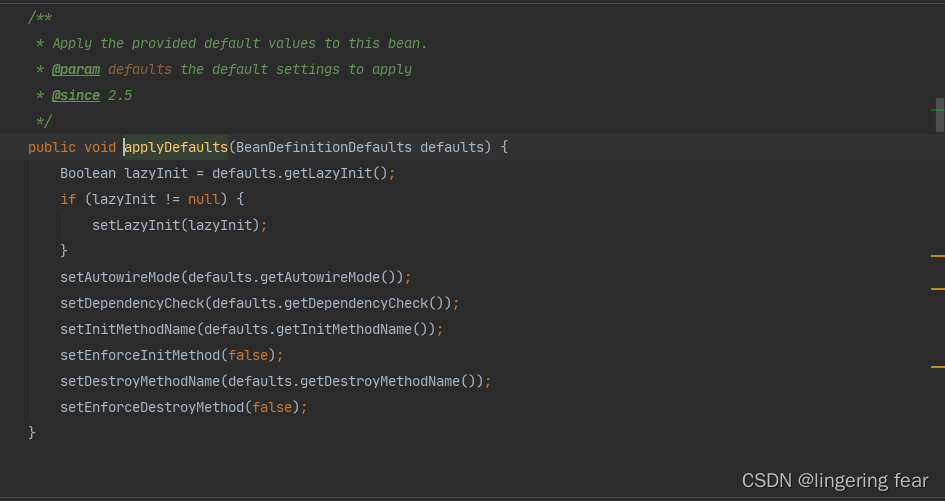
10.是否实现了AnnotatedBeanDefinition接口
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
如果实现了AnnotatedBeanDefinition , 那么它就会解析@Lazy、@Primary、@DependsOn、@Role、@Description这些注解 ,我们来看看processCommonDefinitionAnnotations()方法
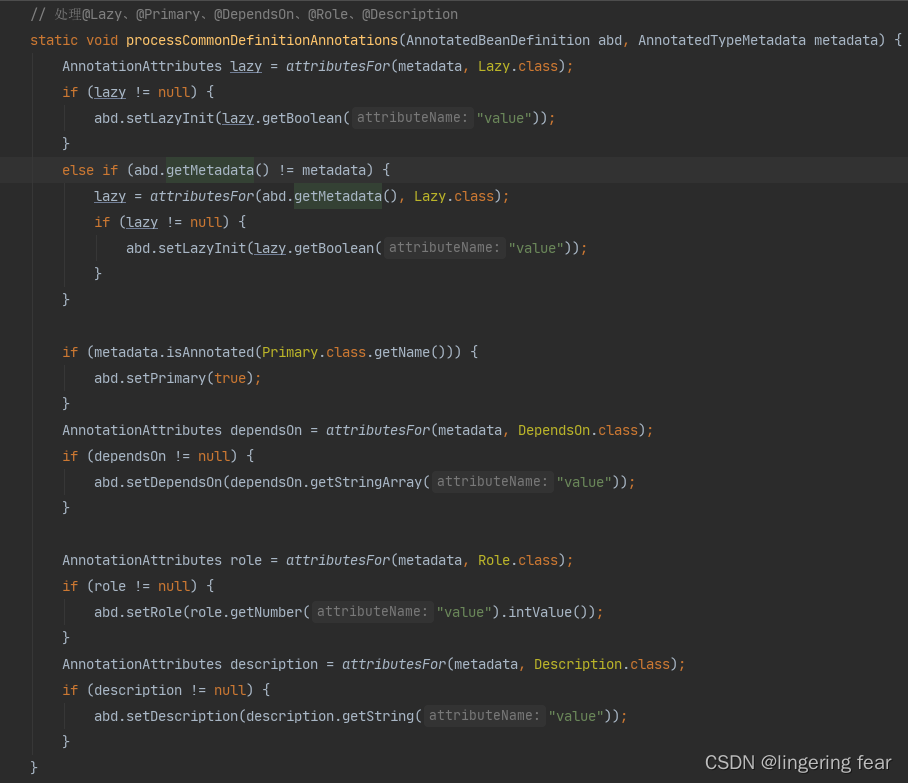
相关注解的作用我都会放在后面来说明
11.检查Spring容器中是否存在该Bean
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册
registerBeanDefinition(definitionHolder, this.registry);
}
那么注册会注册到哪呢?
我们点进来看一下registerBeanDefinition()方法 , 进入到下面这个方法
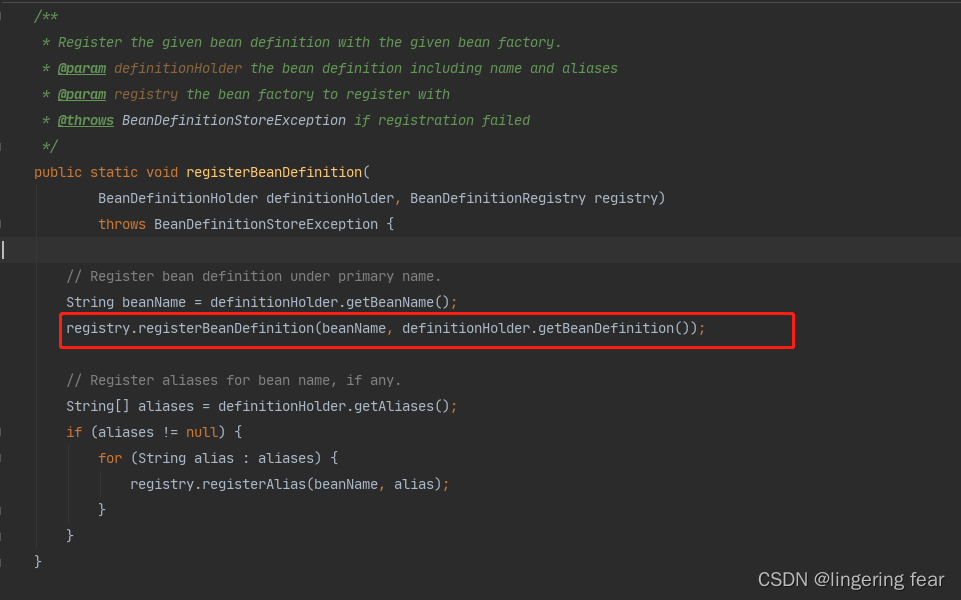

我们会看到这样一行代码
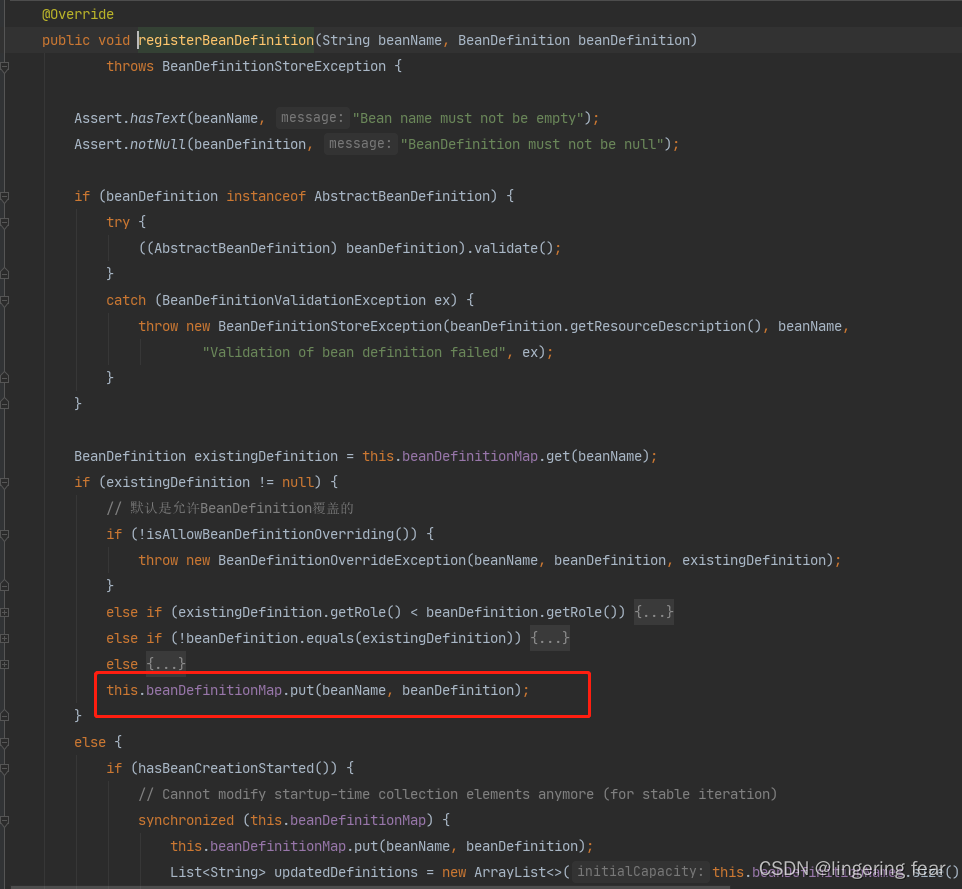
也就是说注册到了Map中 , 这个Map之前的文章中有提到过 , 可以把这个Map理解为Spring容器 , 也可以把单例池理解为Spring容器
this.beanDefinitionMap.put(beanName, beanDefinition);
所以它检查的时候就会判断根据beanName去beanDefinitionMap中判断
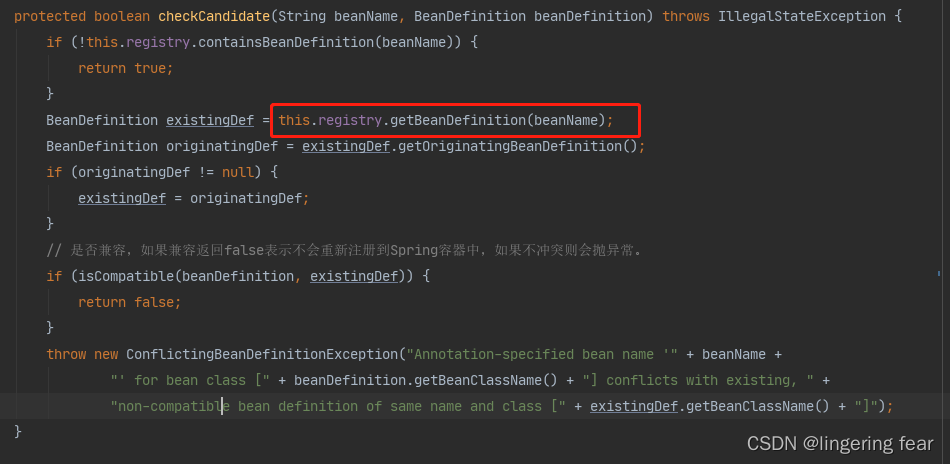
可以看到, 如果存在的话就抛了异常 , 也就是Bean的名称重复了
那isCompatible()方法又是什么意思呢?
我们把AppConfig复制一份 , 不需要改变任何内容
然后我们这样来测试
public class TestSpring {
public static void main(String[] args){
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
applicationContext.register(AppConfig.class);
applicationContext.register(AppConfig1.class);
applicationContext.refresh();
}
}
它这里会扫描两次, 因为AppConfig和AppConfig1的内容是相同的, 那么扫描两次 , 按照上面的逻辑 , beanName冲突不是会报错吗 , 这里测试发现是不会报错的 , 那么为什么呢?就是因为isCompatible()方法它会判断这两个Bean的source是不是相同 , 如果相同 , 那么就不会注册第二次了, 所以就没有问题
到此为止 , 扫描的主要逻辑就讲完了 , 上面我们还遗留了一点小问题
二.实例化非懒加载单例Bean
我们直接来看refresh()的finishBeanFactoryInitialization()方法的beanFactory.preInstantiateSingletons();这个方法
1.合并BeanDefinition
在哪里体现是非懒加单例Bean呢?
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit())
它就会判断是不是单例, 是不是懒加载, 如果不是 , 就不会做任何操作
而 !bd.isAbstract() 这个并不是判断是否是抽象类 , 而是判断是否是抽象的BeanDefinition , 那么抽象的BeanDefinition一般是通过xml的方式来定义的 , 比如这样定义
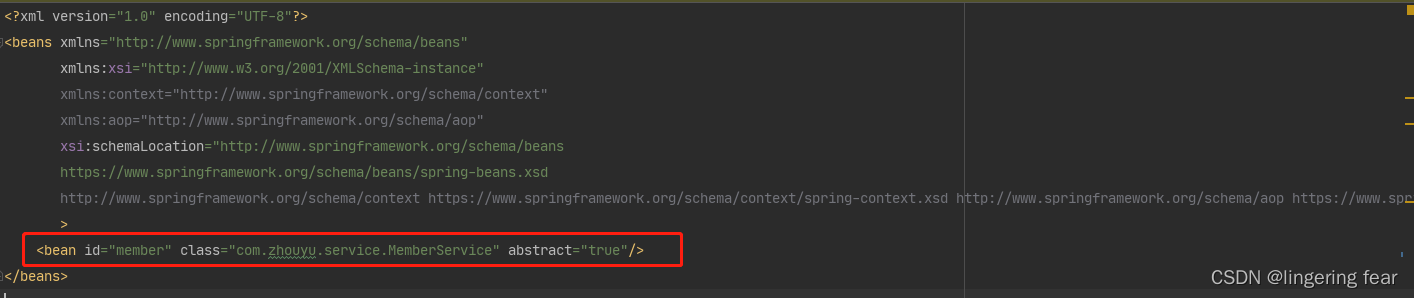
也就是说抽象的BeanDefinition是不会创建Bean的
那么抽象的BeanDefinition有什么作用呢?比如我们在xml是这样定义的
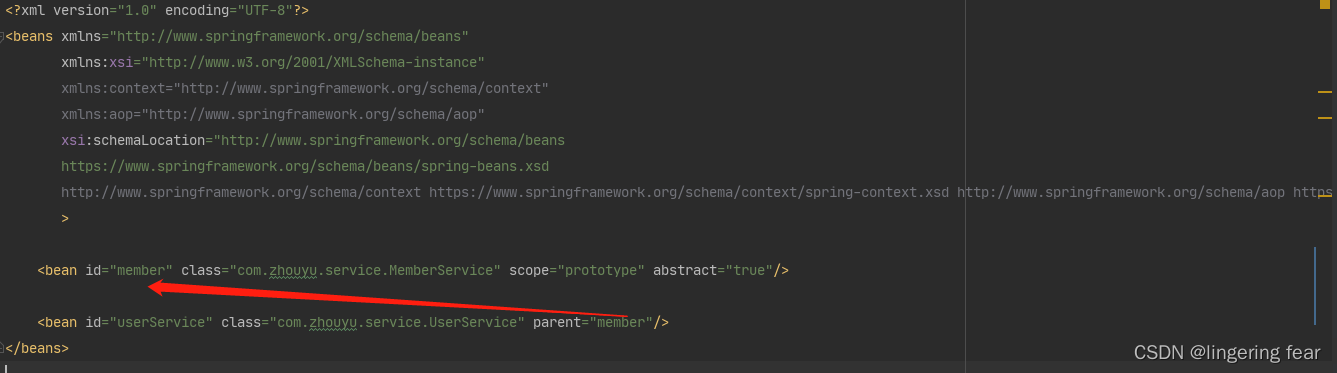
这个时候虽然userService是单例的 , 但是由于它继承了id为member的 BeanDefinition(注意这里是继承BeanDefinition , 并不是继承类) , 所以userService也就成为了原型 , 虽然抽象BeanDefinition不能生成Bean , 但是继承它的BeanDefinition可以成为 Bean , 这就是它的作用 , 而这个userService成为原型的过程被称为合并BeanDefinition , 也就是这行代码
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
它会合并父子BeanDefinition , 如果子类自己没有定义 , 那么就会用父类的 , 如果子类定义了 , 那么就用自己的 , 而合并BeanDefinition 会产生第三个BeanDefinition , 而 并非改之前的BeanDefinition , 因为可能一个父BeanDefinition被好多个类继承 , 如果改了父BeanDefinition , 那么其他子类也就一块跟着改了 , 所以合并不会 修改原来的BeanDefinition , 只会产生新的 , 而新的BeanDefinition就称为RootBeanDefinition
2.创建非懒加载单例Bean
如果通过非懒加载的条件之后 ,它他会判断当前bean是否是一个FactoryBean , 如果不是一个FactoryBean , 那么就会调用getBean()创建非懒加载单例Bean
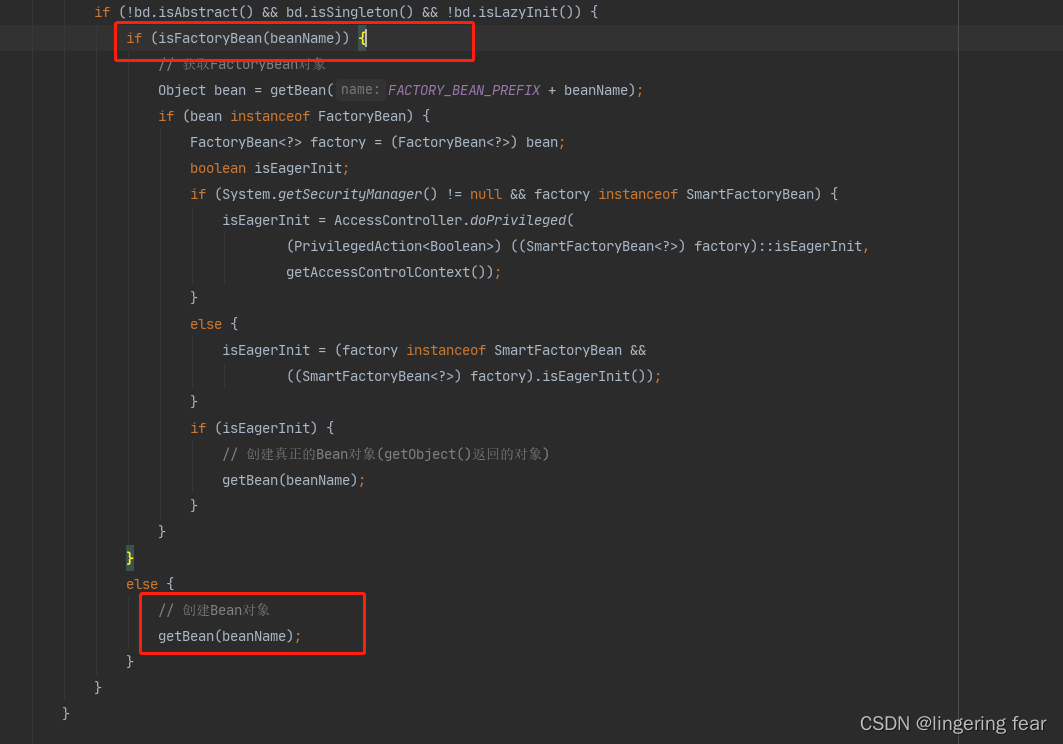
那么他它是怎么判断是否是一个FactoryBean的呢?
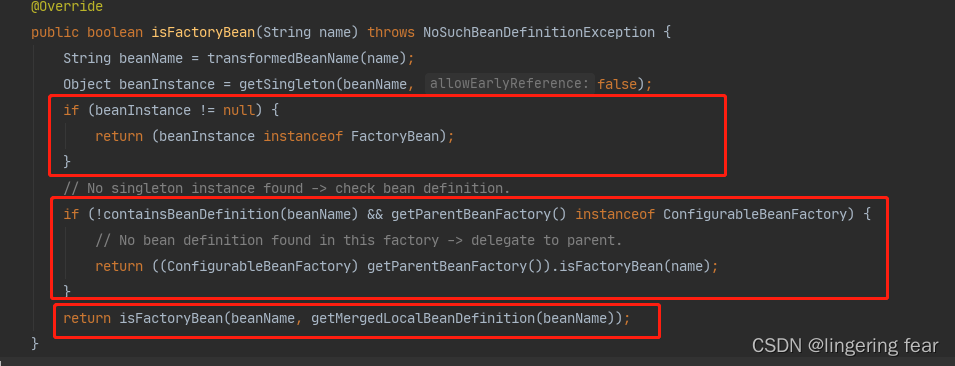
首先它会转换名字 , 就是截取&符号
逻辑大概分为三段
1.从单例池获取Bean的实例 , 如果实现了FactoryBean接口接口 , 那么就是一个FactoryBean
2.如果从单例池获取不到 , 就会判断父Bean工厂有没有
3.如果单例池没有 , 那么就根据BeanDefinition的类型去判断(获取BeanDefinition的beanClass属性) , 代码如下
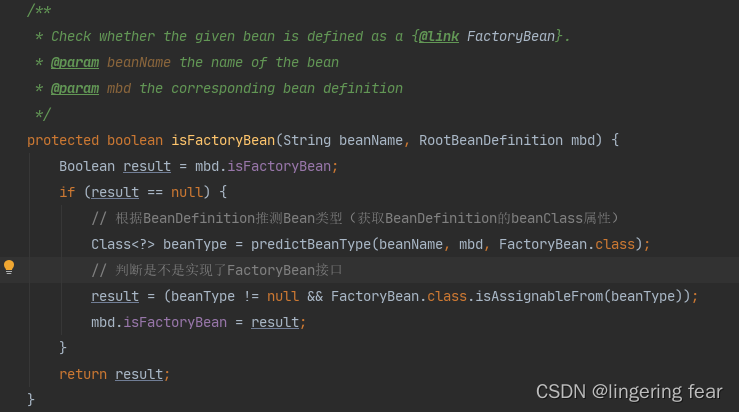
然后缓存一下这个属性
mbd.isFactoryBean = result;
下一次再来判断的时候就会
Boolean result = mbd.isFactoryBean;
直接获取
如果是一个FactoryBean , 那么就会去创建一个Bean , 这个对象就是实现了FactoryBean的这个Bean
// FACTORY_BEAN_PREFIX : &
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
比如上篇文章我们讲的FactoryBean会创建两个对象
// 创建两个对象 , 一个是LyhFactoryBean , 一个是getObject()方法返回的
public class LyhFactoryBean implements FactoryBean {
比如这里Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);创建的就是LyhFactoryBean ,并把这个创建好的Bean强转为FactoryBean
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
如果实现了SmartFactoryBean , 并且isEagerInit()返回true , 才会调用getBean()去创建getObject()返回的Bean
@Component
public class LyhFactoryBean implements SmartFactoryBean {
@Override
public boolean isEagerInit() {
return true;
}
@Override
public Object getObject() throws Exception {
return new UserService();
}
@Override
public Class<?> getObjectType() {
return UserService.class;
}
}
说白了就是如果实现了SmartFactoryBean并且isEagerInit()返回true , 那么它才会调用getBean()去创建 getObject()对象
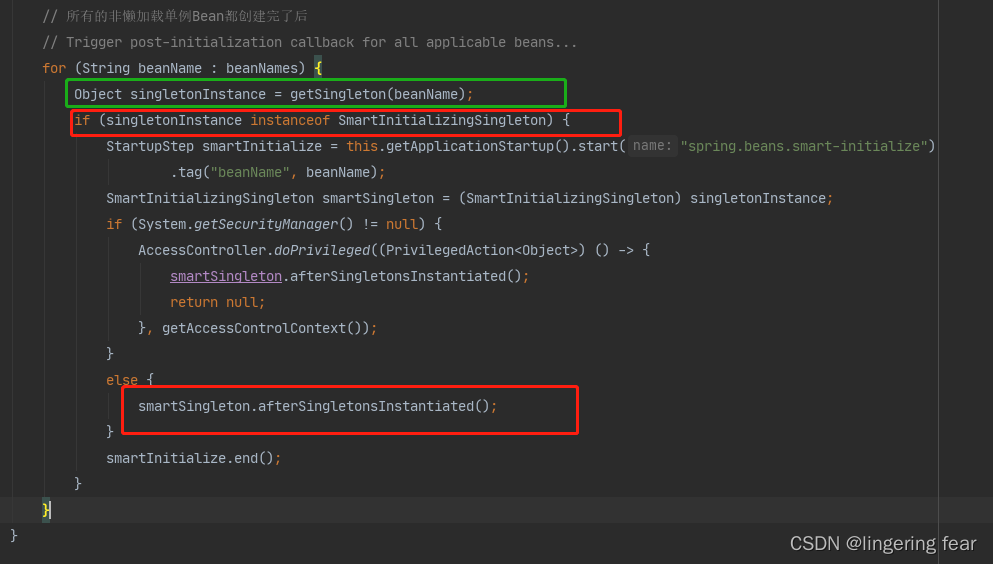
3.执行SmartInitializingSingleton
所有非懒加载单例Bean创建完毕之后 , 它会根据Bean名称获取到单例Bean的实例,
Object singletonInstance = getSingleton(beanName);
然后判断是否实现了SmartInitializingSingleton , 如果实现了 , 那么就执行afterSingletonsInstantiated()方法
三.获取或创建Bean
上面说了扫描和解析以及实例化非懒加载单例Bean , 下面我们说一下Bean的获取以及获取不到时的创建
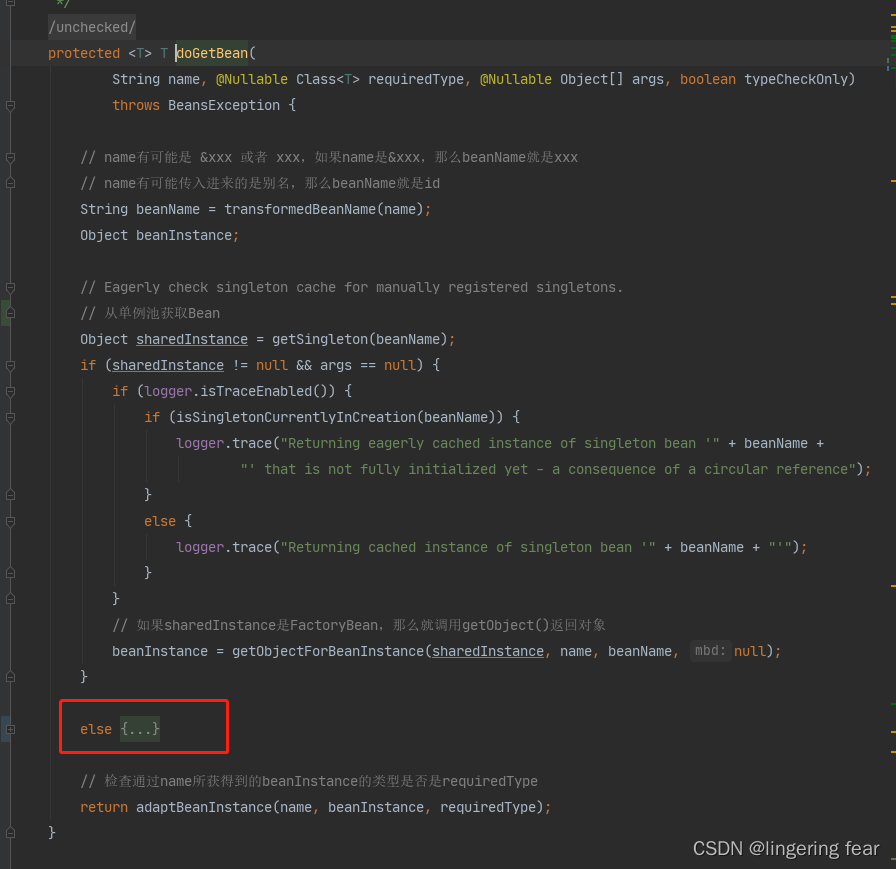
首先就是转换BeanName , 然后从单例池获取 ,能获取到就返回 , 获取不到呢? 也就是这段else的逻辑
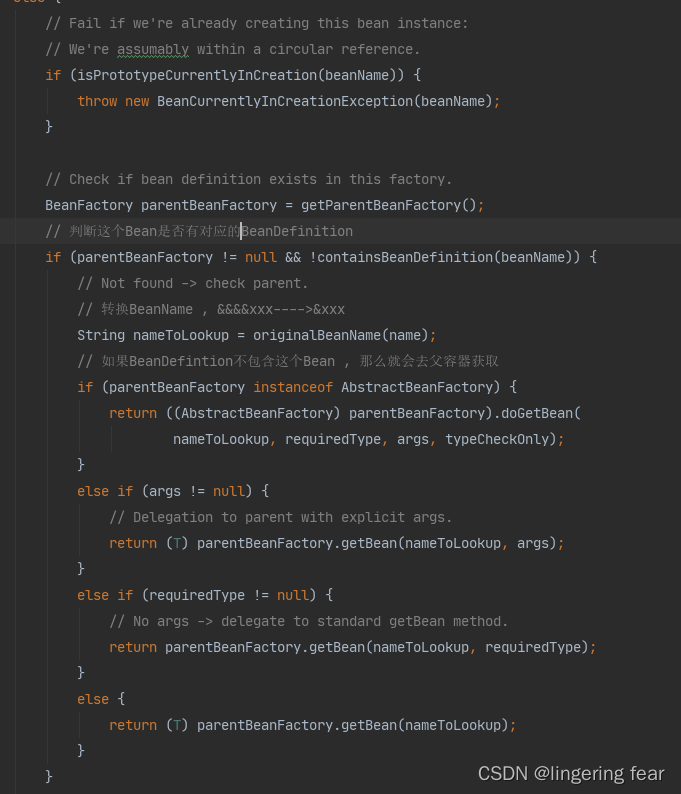
它判断这个Bean是否有对应的BeanDefinition , 如果没有的话 , 就转换一下BeanName然后去父Bean工厂找
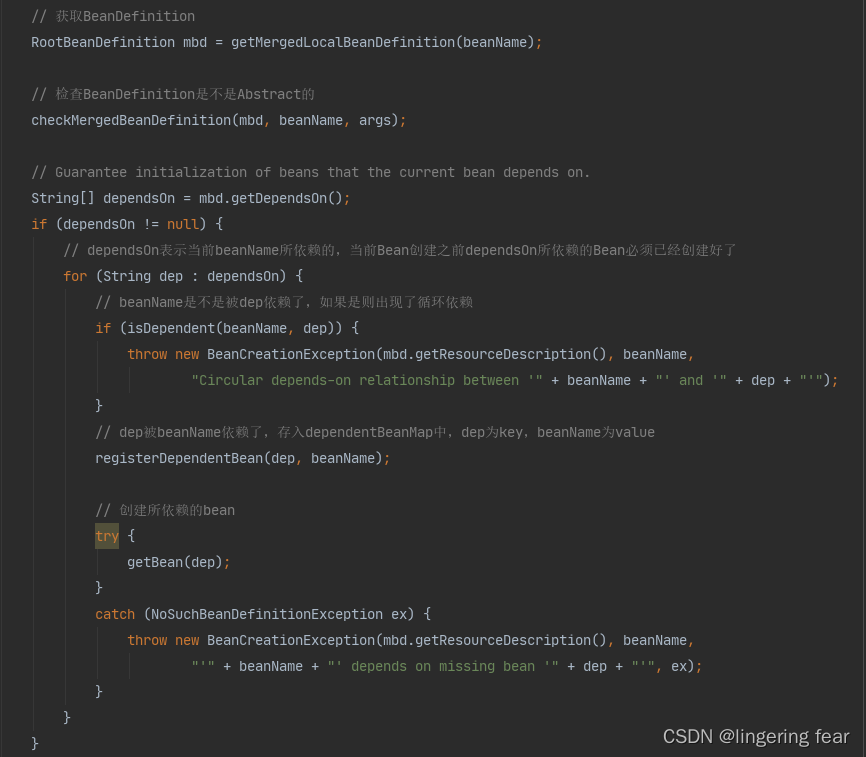
紧接它会获取合并之后的BeanDefinition , 然后检查这个BeanDefinition是不是抽象的 , 如果是的话是创建不了Bean的 , 然后就会通过getDependsOn()获取它所依赖的Bean
@DependsOn

这个注解表示依赖的意思 , 就比如MemberService加上@DependsOn注解之后 , 就表示在创建MemberService之前 , 要先把依赖的Bean创建好 , MemberService的这种写法是集合的形式, 而UserService的写法是单个的形式
拿到锁依赖的Bean之后就会把依赖的Bean注册到Map中
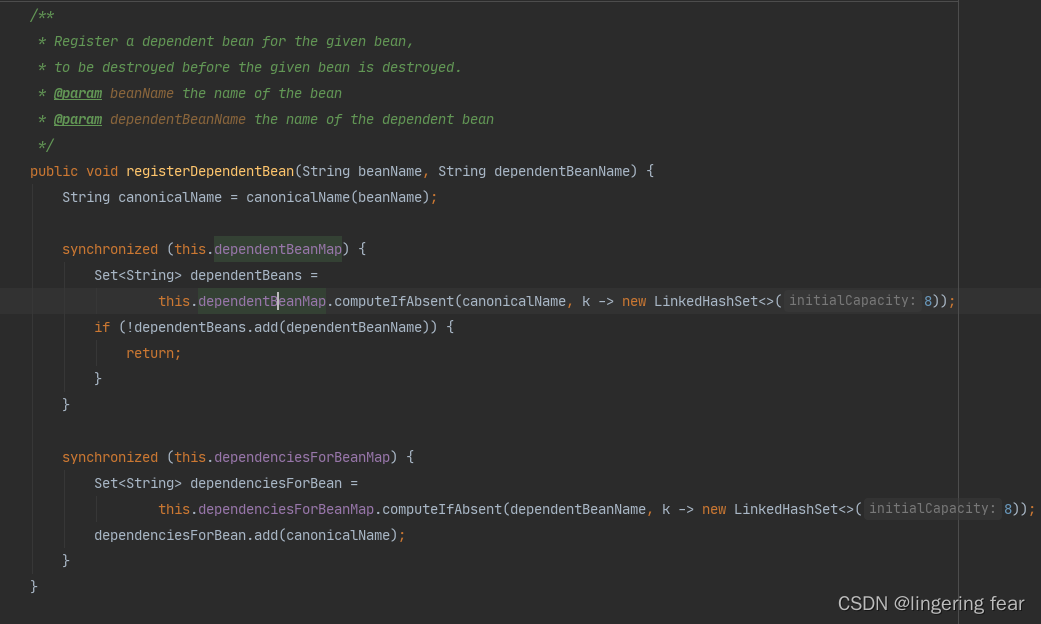
对应的就是这两个Map

但是有一种情况会抛异常的
如果是这样声明的话就会产生循环依赖 , 通过@DependsOn注解产生的循环依赖是无法解决的
我们接着来看的getBean()源码然后紧接着会调用getBean()创建所依赖的Bean , 然后创建锁依赖的Bean之后 , 才去真正的创建这个当前需要创建的Bean
简单回想一下Bean的生命周期 , 扫描, 接下来就要去创建实例化 , 属性注入…等等操作
, 它就会先判断当前需要创建的Bean的作用域是原型还是单例还是其他的作用域 ,
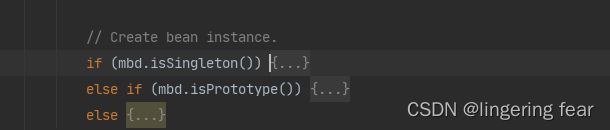
我们先来看一下原型的逻辑
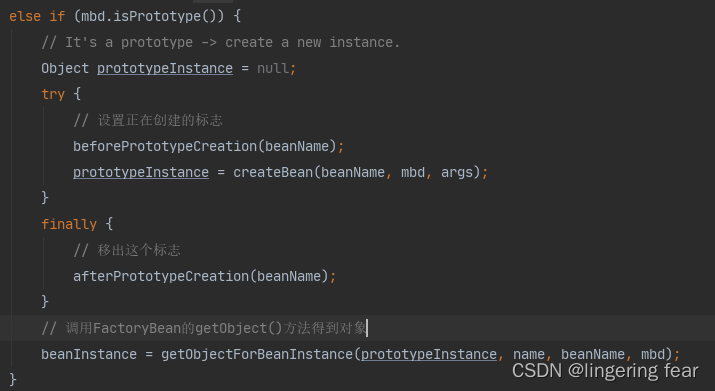
原型的话就是直接调用createBean()方法创建 , 也没有放到单例池等操作
再来看单例Bean
这一块其实是一个lambda表达式 , 然后lambda执行的时候就会调用createBean()去创建Bean
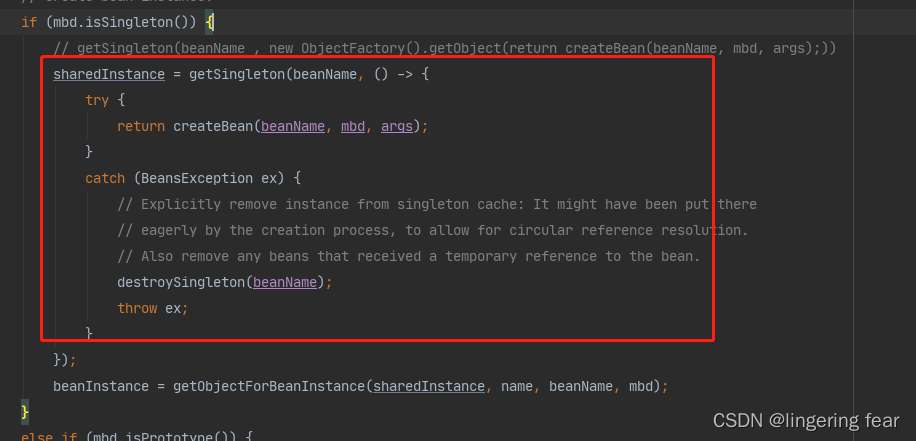
我们接着来看getSingleton()方法
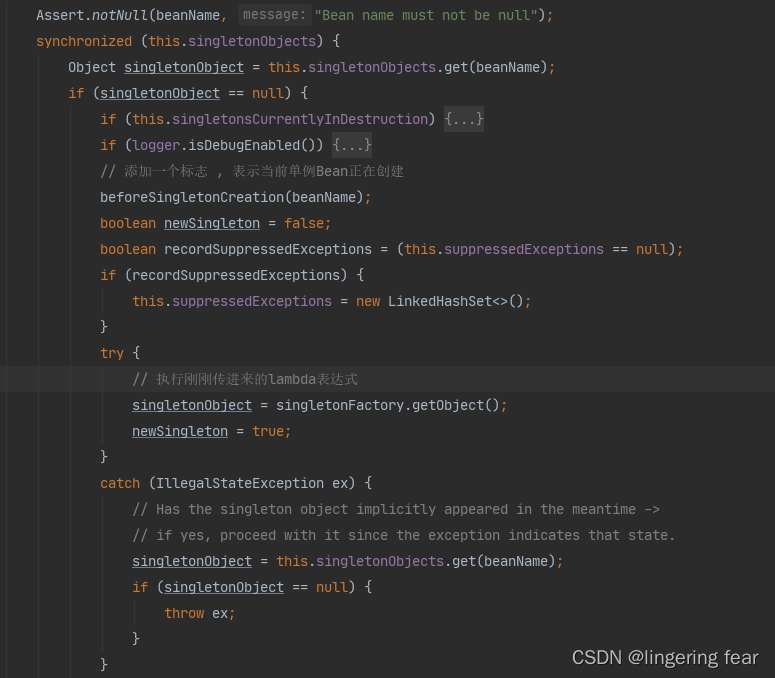
先从单例池获取 , 如果获取不到 , 那么就会执行刚刚的lanbda表达式 , 就会调用createBean()方法去创建一个对象
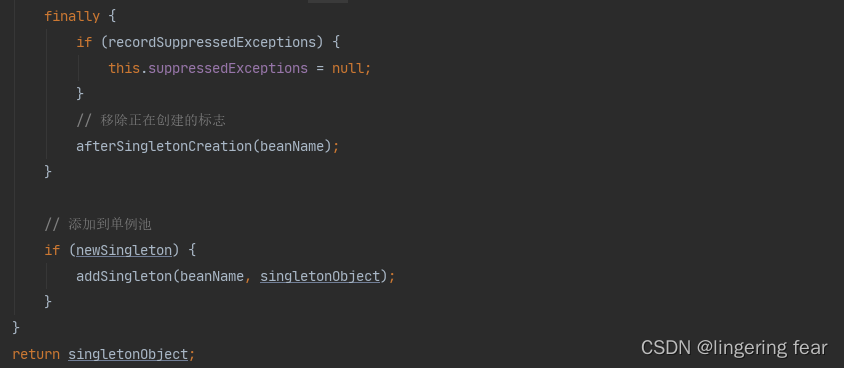
然后会移除这个正在创建的标志并添加到单例池
原型和单例大概都讲完了 , createBean()的逻辑我们之后再看 , 再来看看第三种情况 , Bean的作用域除去原型和单例的话 , 如果考虑SpringMVC的话 , 还有一些其他的作用域 ,如request , application , session , 也就是说一次请求 , 拿到的Bean肯定是同一个Bean ,那么要怎样保证呢?其实实现原理和创建单例对象时候的逻辑差不多
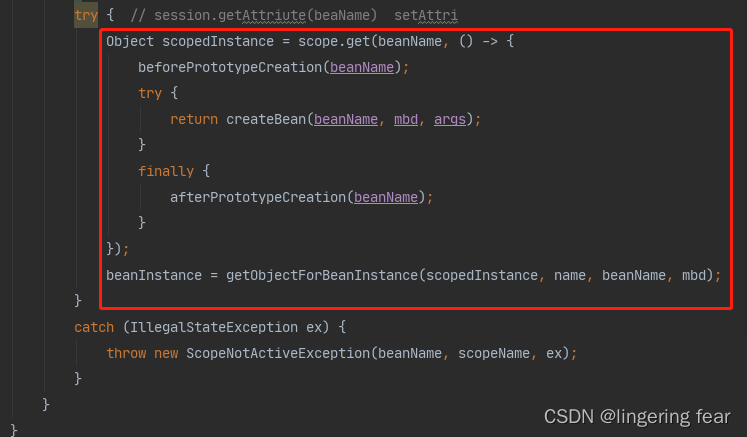
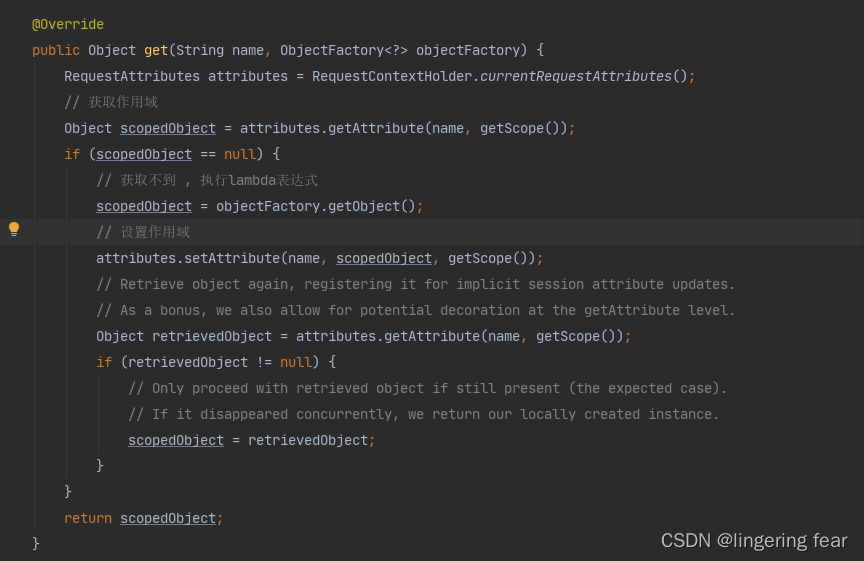
这里会传一个lambda表达式 , 如果可以getAttribute()获取不为空 , 那么就返回 , 否则就创建
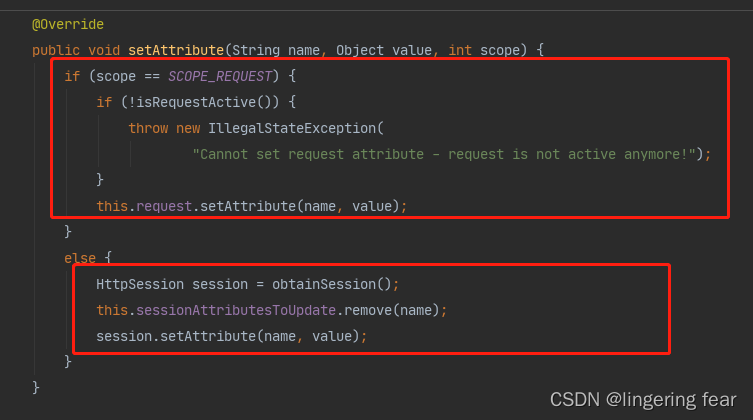
在set设置的时候就会有区分
不管Bean的作用域是什么总归还是要去创建的 , 所以接下来我们就看看createBean()方法
四.加载类
再创建Bean的时候肯定是要加载类的 , 所以createBean()方法第一步就是加载类
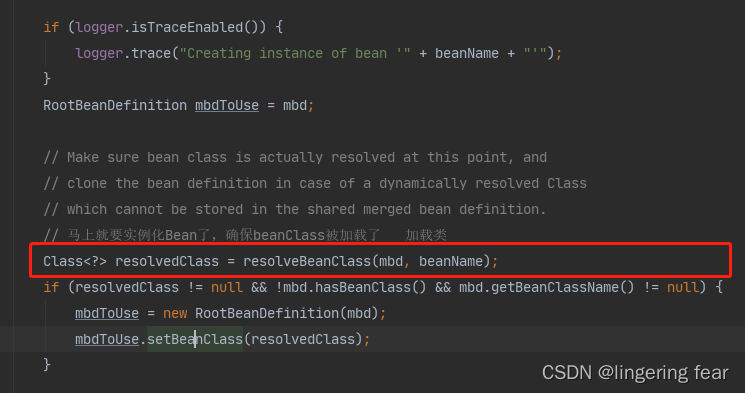
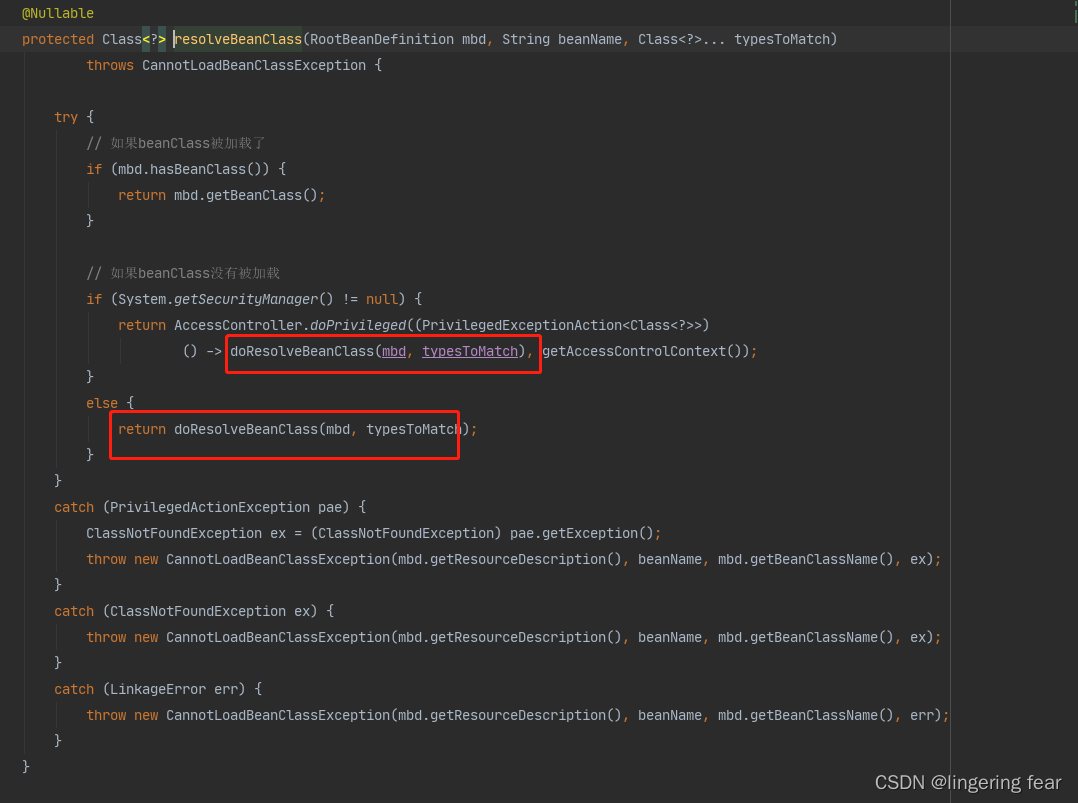
如果加载过的话就直接返回 , 否则的话就加载类 , 就会先去获取类加载器


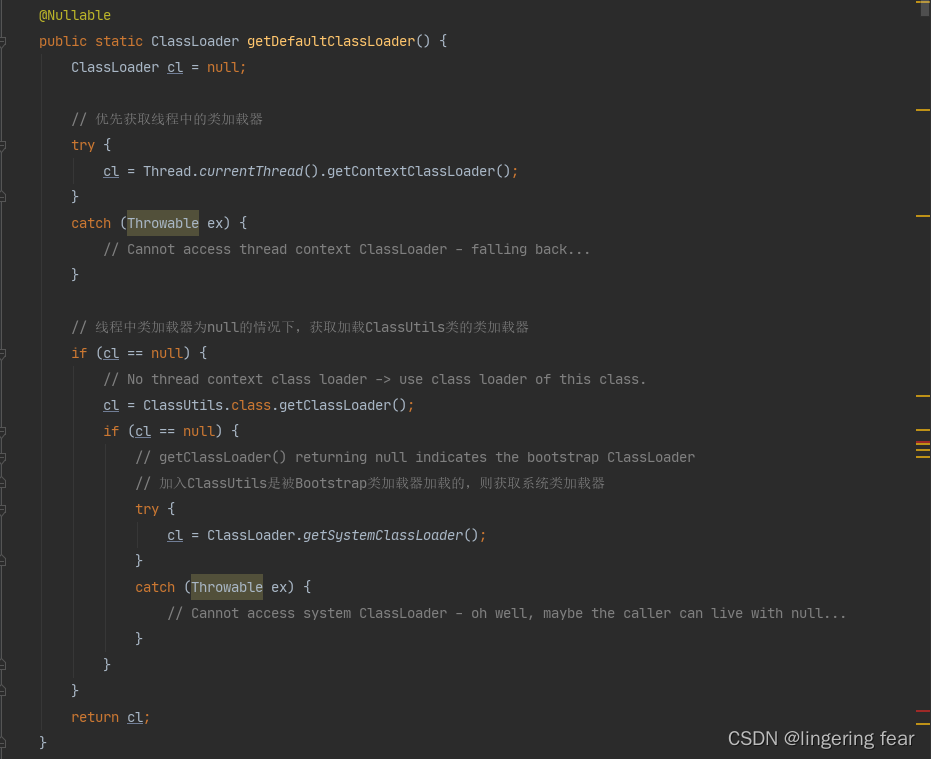
当然 ,我们也可以这样自定义

然后就会获取类的名称 , 然后如果有Spring表达式 , 那么就解析
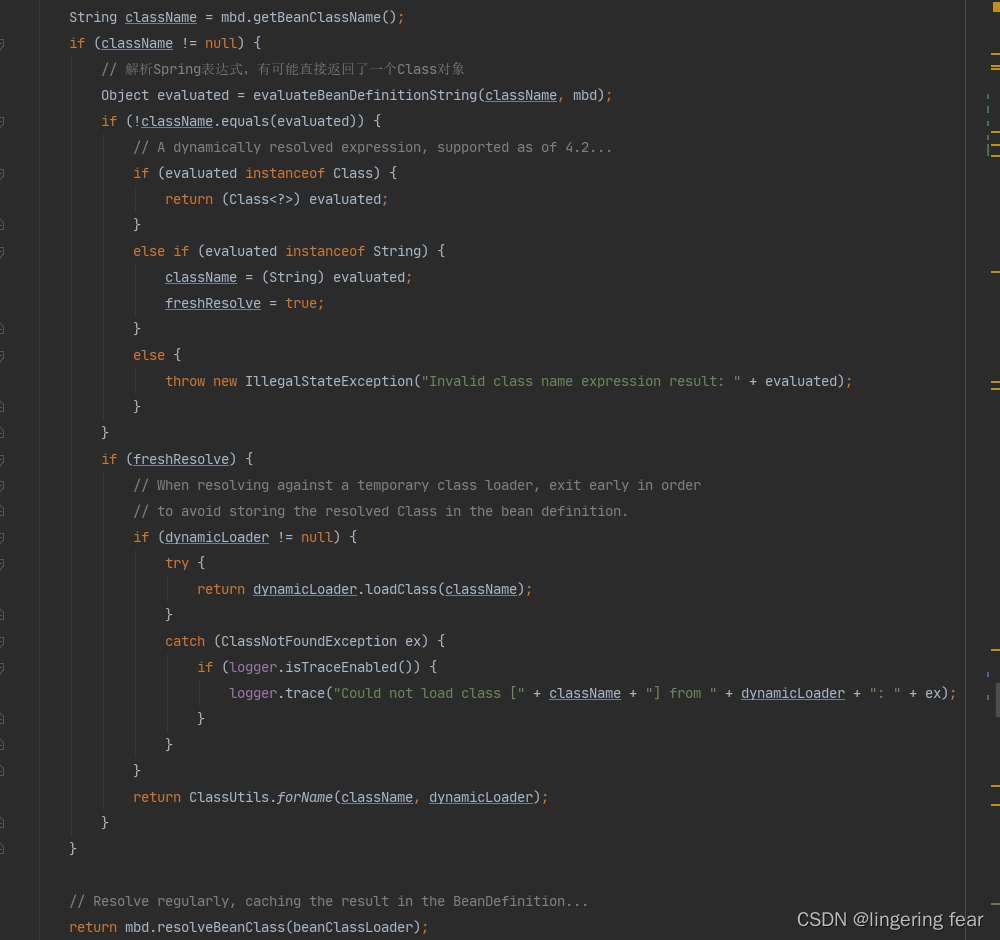
这种使用方法的Spring表达式时很少使用的 , 比如是这样定义的(语法错误 , 为了演示)

然后就会加载类并返回
return dynamicLoader.loadClass(className);
接下来就是这个功能
这个功能会和@Lookup注解有关系 , 放到后面来说
五.实例化前
加载完类之后紧接着就是实例化之前需要做的一些操作
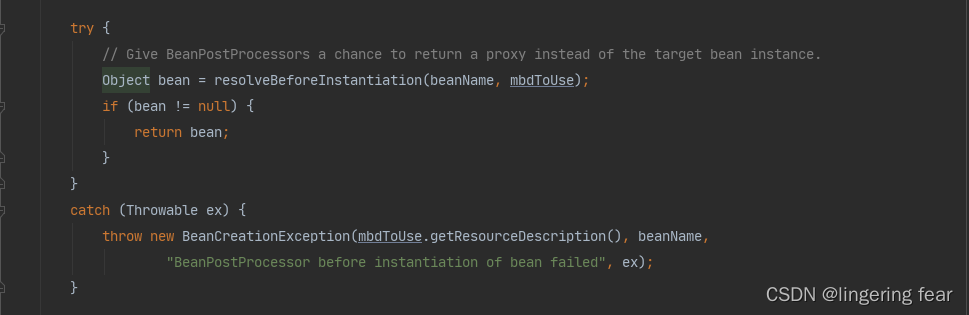
之前的文章我们提到过实现BeanPostProcessors接口可以在Bean初始化前后去对Bean进行一些额外的处理 , 那么在初始化前也提供了这个功能 , 就是InstantiationAwareBeanPostProcessor这个接口
@Component
public class TestInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
// 实例化前
return null;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
// 实例化后
return null;
}
}
而初始化前就是做这一步操作的
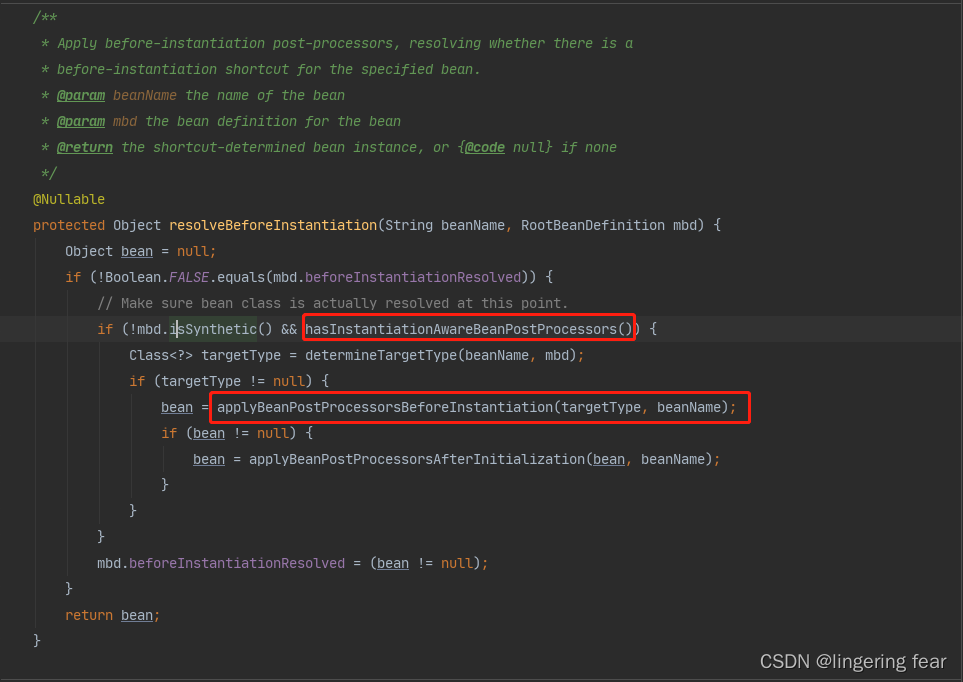
它会先从缓存判断你是否有实现了InstantiationAwareBeanPostProcessor接口的类 , 如果有 , 那么就执行对应的postProcessBeforeInstantiation()方法
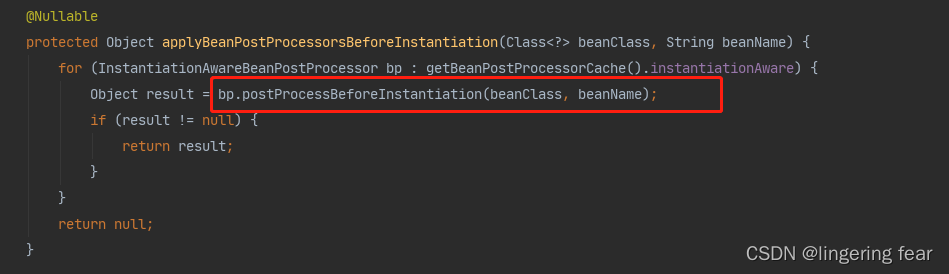
比如我们可以这样写
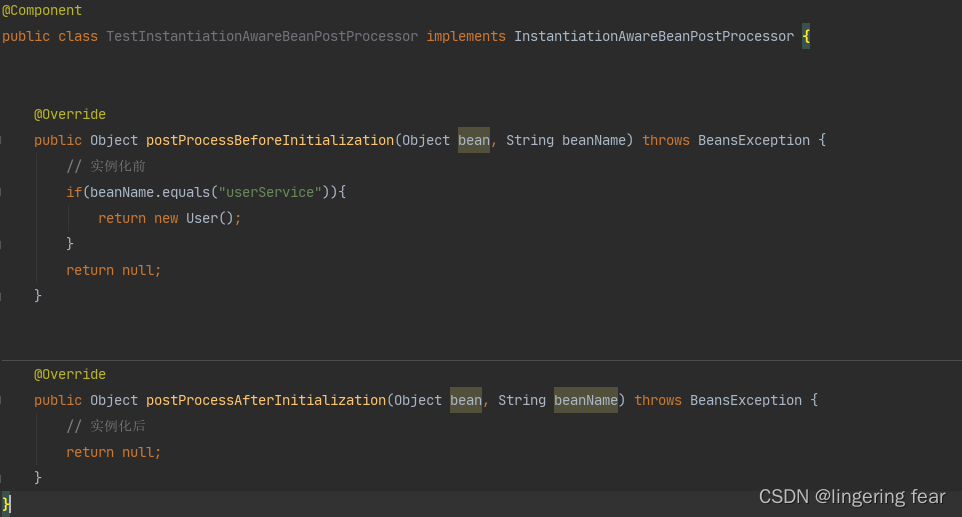
按理说得到的应该是userService这个Bean , 但是由于我们实现了接口 , 那么它就会在实例化前执行 , 然后返回你自己所定义的结果

不等于空就直接返回了
六.推断构造方法
推断构造方法的过程在后面有单独的文章说明
七.实例化
如果在实例化前没有做什么事情 , 那么正常进行实例化
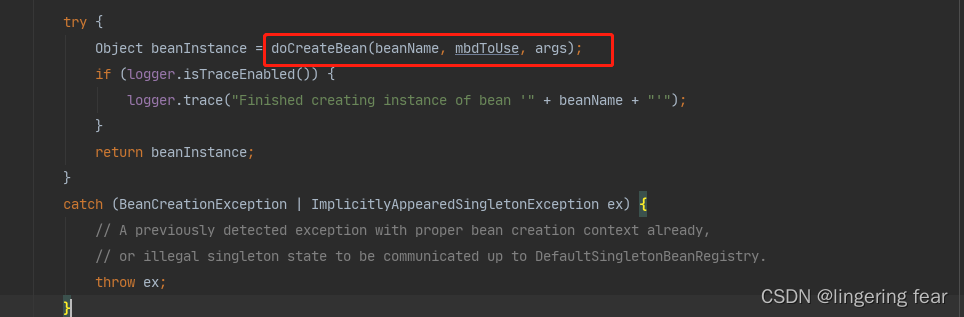
八.BeanDefinition后置处理器
那么实例化之后就会专门的处理合并之后的BeanDefinition
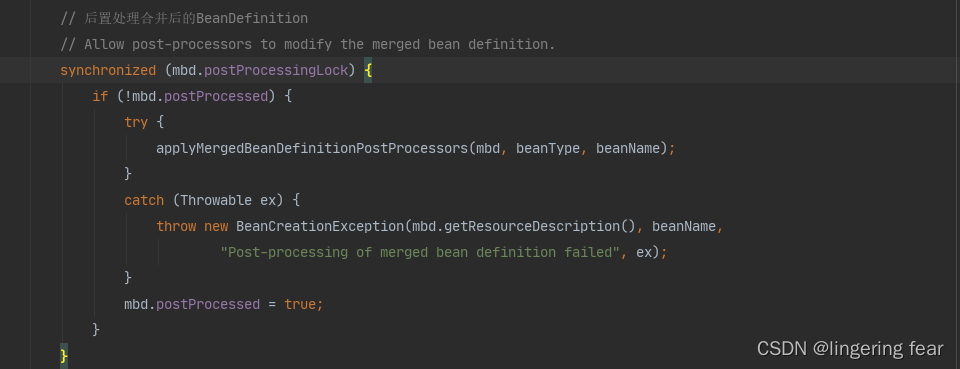
也就是这个接口
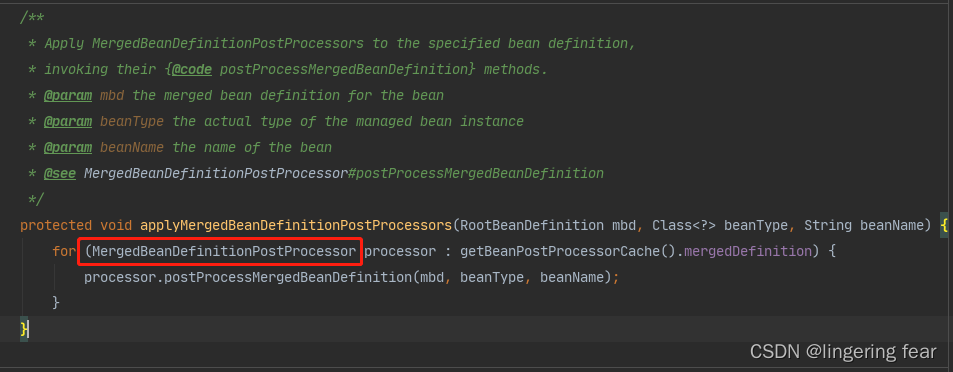
实现这个接口 , 我们就可以在实例化之后设置BeanDefinition的一些属性 , 但是有一部分是设置不了的
九.实例化后
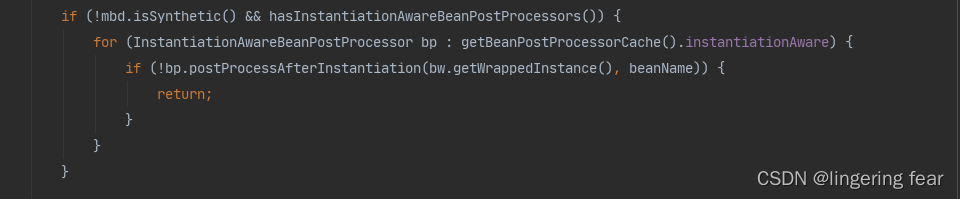
实例化后在populateBean()这个方法中 , 在属性赋值之前 , 其实和实例化之前差不多 .InstantiationAwareBeanPostProcessor接口实现之后可以重写postProcessBeforeInitialization()和postProcessAfterInitialization()方法, 而实例化前后就是找出实现了InstantiationAwareBeanPostProcessor接口的类分表调用这两个方法
十.属性填充
再往下看
这个其实为了支持Spring的自带的依赖注入功能 , 但是已经过时了 , 不怎么用 , 但是如果使用的话必须添加一个set方法
public class OrderService {
private MemberService memberService;
public void setMemberService(MemberService memberService) {
this.memberService = memberService;
}
public void test(){
System.out.println(this.memberService);
}
}
然后在AppConfig添加如下配置
@Bean(autowire = Autowire.BY_TYPE)
public MemberService memberService(){
return new MemberService();
}
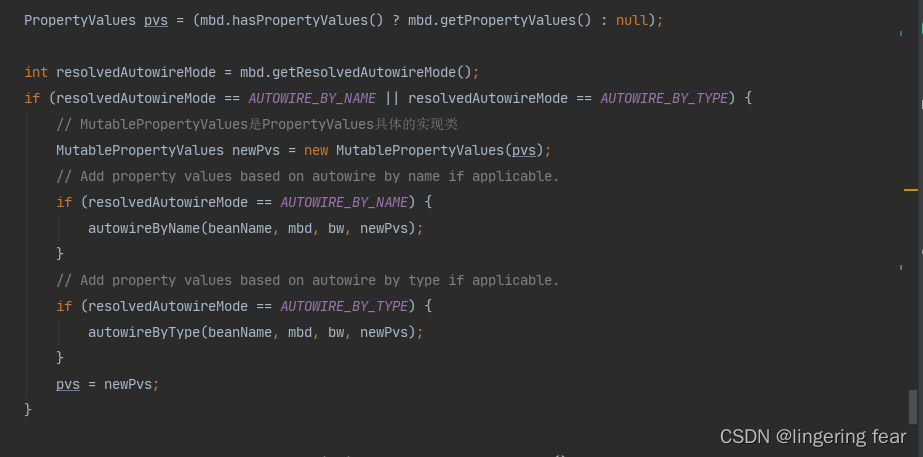
这个时候OrderService中的MemberService就是有值的 , 如果配置的是 Autowire.BY_TYPE , 那么它会根据set方法入参的类型去寻找Bean

如果是 Autowire.BY_NAME , 那么就是截取set方法名 , 去掉set然后首字母小写

十一.属性填充后
然后Spring自带的注入完毕之后 , 又会去调用InstantiationAwareBeanPostProcessor的postProcessProperties()方法 , 这个方法可以去处理自己的注解 , 比如AutowiredAnnotationBeanPostProcessor就会去处理@Autowired注解
这里还有个pvs , 这个pvs就是通过自定义的方式来给属性赋值 , 比如这样
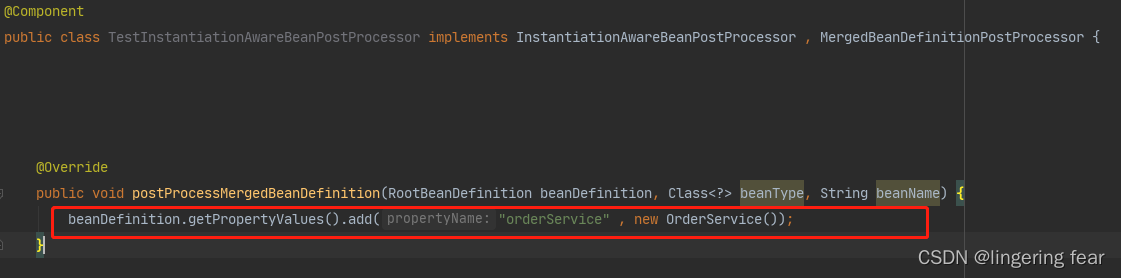
也就是说在属性填充之前 , 它会去检查你有没有通过这种方式自定义给属性赋值 , 如果赋值了 , 那么@Autowired是不生效的
十二.初始化前
紧接着就是到了初始化这一步 , 我们接着分析源码
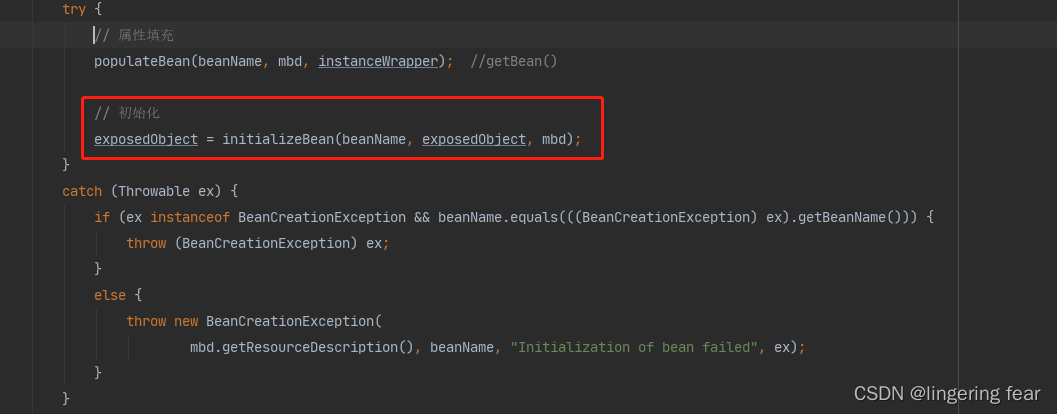
那么首先会初始化各种Aware回调
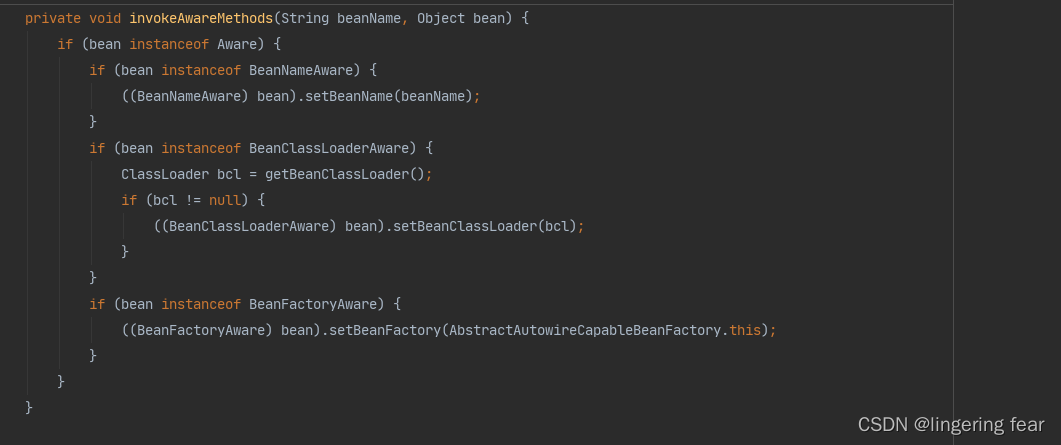
接下来就是初始化前的操作了

找出实现了BeanPostProcessor接口的类 , 然后执行postProcessBeforeInitialization()方法
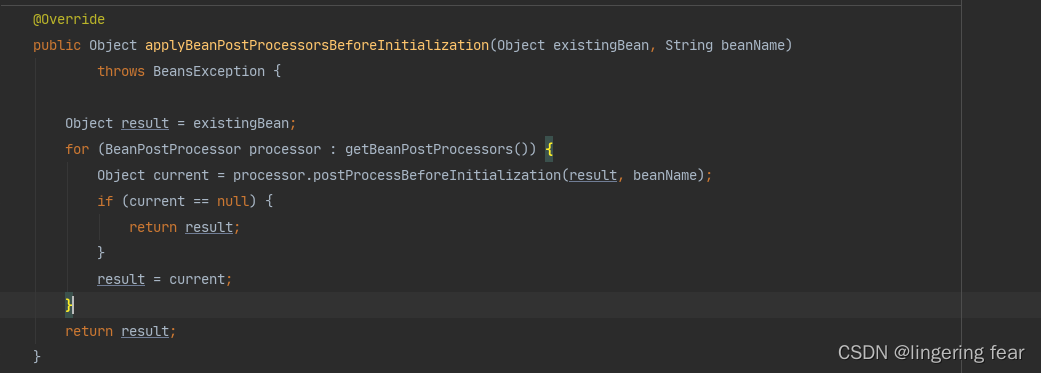
十三.初始化
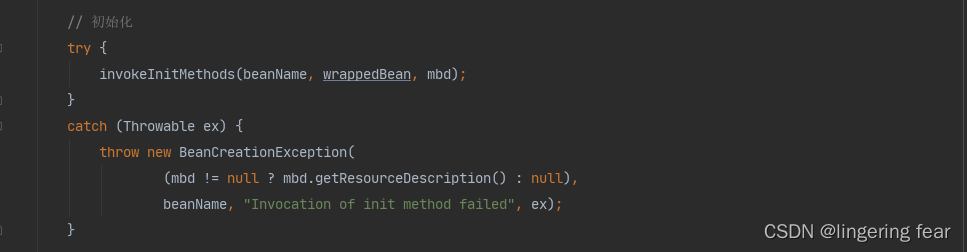
判断是否实现了InitializingBean接口 , 实现了就调用afterPropertiesSet()方法 , 或者说指定了初始化方法 , 那么就去执行这个方法
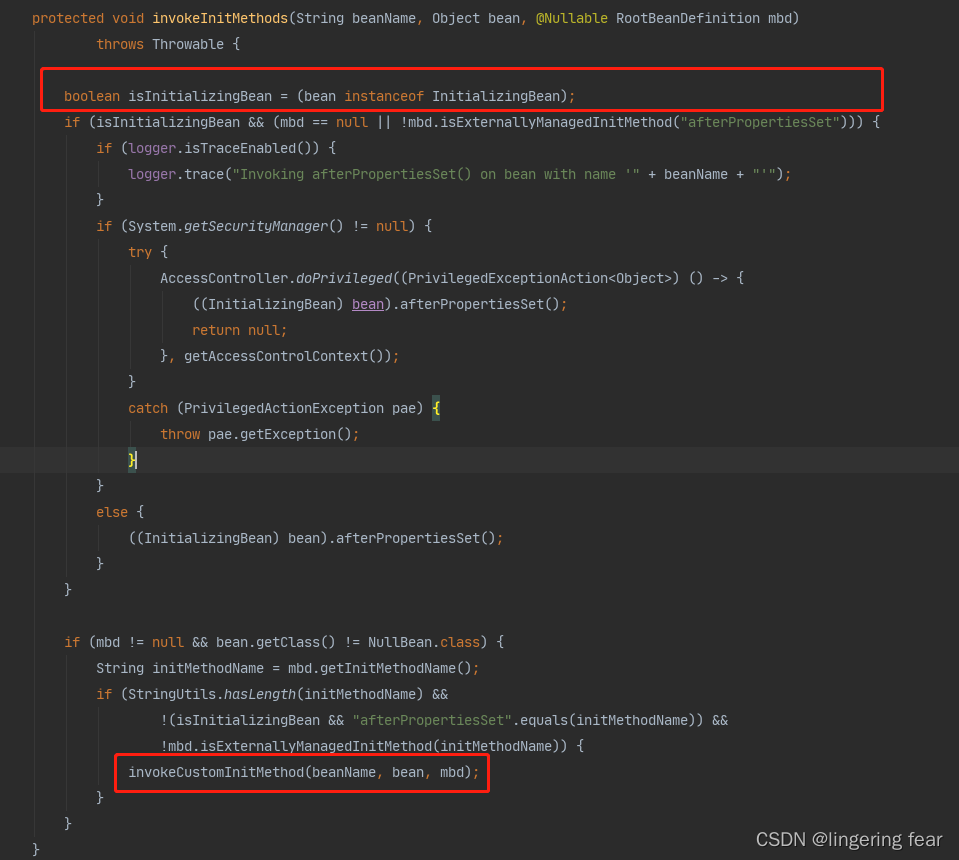
十四.初始化后

初始化后和初始化前是差不多的 , 只不过是执行的方法不同 , 初始化后执行的是postProcessAfterInitialization
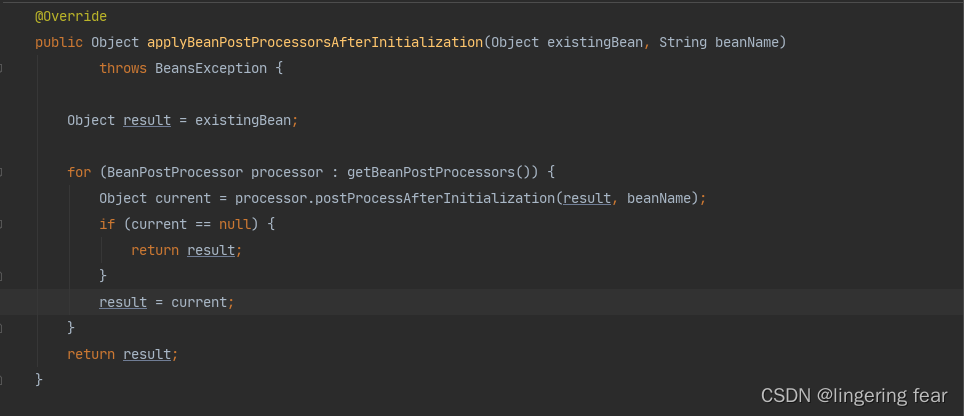
初始化完成之后 , 就算真正的创建出了一个Bean对象 , 随后就会有循环依赖相关的处理逻辑 , 循环依赖可以看我之前的文章
十五.Bean销毁
最后就是去判断你有没有定义一些Bean销毁的逻辑
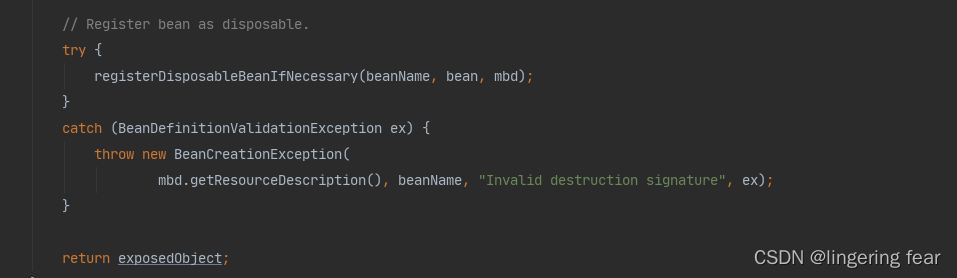
我们可以通过实现一个接口来定义Bean销毁的逻辑
public class OrderService implements DisposableBean {
@Override
public void destroy() throws Exception {
System.out.println("销毁");
}
}
而这个销毁逻辑方法被调用是当我们Spring容器关闭的时候被触发
关闭的方式有两种
1.向JVM注册一个关闭的钩子 , 当进程结束 , 容器关闭
applicationContext.registerShutdownHook();
2. 手动调用close()方法关闭
applicationContext.close();
但是这两种方法最后都调用的是doClose()方法
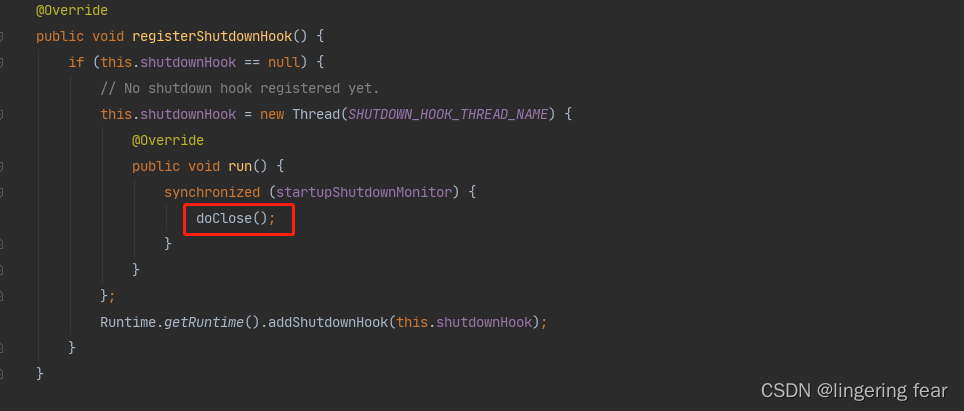
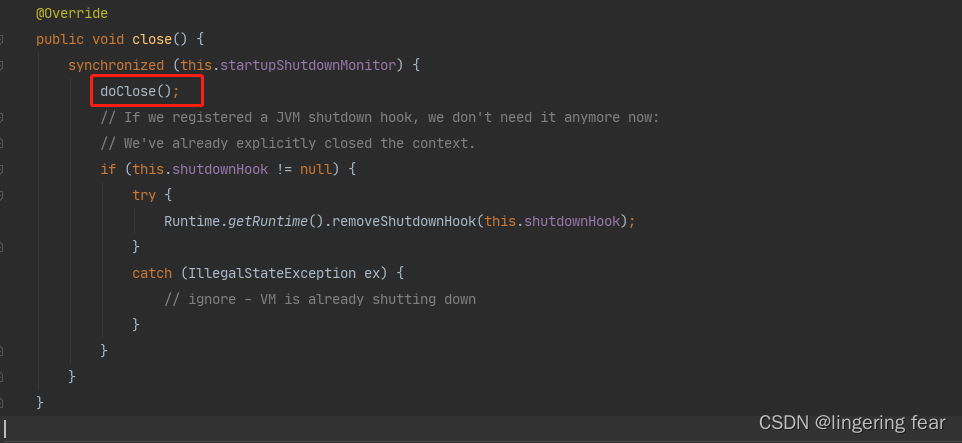
也就是这段源代码
/**
* Actually performs context closing: publishes a ContextClosedEvent and
* destroys the singletons in the bean factory of this application context.
* <p>Called by both {@code close()} and a JVM shutdown hook, if any.
* @see org.springframework.context.event.ContextClosedEvent
* @see #destroyBeans()
* @see #close()
* @see #registerShutdownHook()
*/
@SuppressWarnings("deprecation")
protected void doClose() {
// Check whether an actual close attempt is necessary...
// 检查上下文是否属于激活状态
if (this.active.get() && this.closed.compareAndSet(false, true)) {
if (logger.isDebugEnabled()) {
logger.debug("Closing " + this);
}
if (!NativeDetector.inNativeImage()) {
// 移除应用上下文的注册
LiveBeansView.unregisterApplicationContext(this);
}
try {
// Publish shutdown event.
// 发布上下文已关闭事件 ContextClosedEvent
publishEvent(new ContextClosedEvent(this));
}
catch (Throwable ex) {
logger.warn("Exception thrown from ApplicationListener handling ContextClosedEvent", ex);
}
// Stop all Lifecycle beans, to avoid delays during individual destruction.
if (this.lifecycleProcessor != null) {
try {
// 调用生命周期管理器的 onClose() 方法,终止对容器中各个bean的生命周期管理
this.lifecycleProcessor.onClose();
}
catch (Throwable ex) {
logger.warn("Exception thrown from LifecycleProcessor on context close", ex);
}
}
// Destroy all cached singletons in the context's BeanFactory.
//销毁容器中所有的(单例)bean
//这里的容器指的是高级容器内嵌的低级容器 beanFactory,bean都是放在内置的beanFactory中的
destroyBeans();
// Close the state of this context itself.
//关闭内置的beanFactory
closeBeanFactory();
// Let subclasses do some final clean-up if they wish...
//预留的扩展点,在关闭beanFactory后做一些额外操作
onClose();
// Reset local application listeners to pre-refresh state.
//重置存储监听器的2个成员变量
if (this.earlyApplicationListeners != null) {
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
//设置上下文的激活状态为false
// Switch to inactive.
this.active.set(false);
}
}
/**
* Template method for destroying all beans that this context manages.
* The default implementation destroy all cached singletons in this context,
* invoking {@code DisposableBean.destroy()} and/or the specified
* "destroy-method".
* <p>Can be overridden to add context-specific bean destruction steps
* right before or right after standard singleton destruction,
* while the context's BeanFactory is still active.
* @see #getBeanFactory()
* @see org.springframework.beans.factory.config.ConfigurableBeanFactory#destroySingletons()
*
* 销毁容器中所有的(单例)bean。
* 如果bean实现了 DisposableBean 接口,或使用 destroy-method 属性指定了销毁方法,会调用对应的销毁方法
*/
protected void destroyBeans() {
getBeanFactory().destroySingletons();
}
/**
* Template method which can be overridden to add context-specific shutdown work.
* The default implementation is empty.
* <p>Called at the end of {@link #doClose}'s shutdown procedure, after
* this context's BeanFactory has been closed. If custom shutdown logic
* needs to execute while the BeanFactory is still active, override
* the {@link #destroyBeans()} method instead.
*
* 预留给子类的扩展点,可以在内置的beanFactory关闭后做一些自定义处理
*
*/
protected void onClose() {
// For subclasses: do nothing by default.
}
到此为止 , Spring框架的生命周期完成 , 对于比较具体的细节还需要仔细的琢磨 , 谢谢大家的阅读 , 感觉文章不错的话来个一键三连吧
















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











