






感兴趣的话大家可以关注一下公众号 : 猿人刘先生 , 欢迎大家一起学习 , 一起进步 , 一起来交流吧!
一.Zookeeper
1.什么是Zookeeper
ZooKeeper 是一个开源的分布式协调框架,是Apache Hadoop 的一个子项目,主要
用来解决分布式集群中应用系统的一致性问题。Zookeeper 的设计目标是将那些复杂且容
易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的
接口提供给用户使用。
官方:https://zookeeper.apache.org/
2.下载
https://zookeeper.apache.org/releases.html
3.解压
tar zxvf apache-zookeeper-3.8.0-bin.tar.gz
4.修改配置文件
cd apache-zookeeper-3.8.0-bin/conf
把示例配置文件复制出来一份
cp zoo_sample.cfg zoo1.cfg
vim zoo.cfg
#zookeeper时间配置中的基本单位
tickTime=2000
#允许followe连接到leader最大时长 , 它表示tickTime时间倍数 , 即initLimit * tickTime
initLimit=10
#允许followe与leader数据同步最大时长 , 它表示tickTime 时间倍数
syncLimit=5
#zookeeper数据存储目录以及日志保存记录(如果没有指明dataLogDir , 则日志也保存到这个文件中)
dataDir=/home/software/apache-zookeeper-3.8.0-bin/data/zookeeper
#对客户端提供的端口号
clientPort=2181
#单个客户端与zookeeper最大并发连接数
maxClientCnxns=60
#保存的数据快照量 , 之外的数据会被清楚
autopurge.snapRetainCount=3
#自动触发清除任务时间间隔 , 小时为单位 , 默认为0 , 表示不自动清楚
autopurge.purgeInterval=1
##Metrics Providers
#https://prometheus.io Metrics Exporter
#开启对prometheus监控的支持
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
#集群IP , 端口 . 1 , 2 , 3 分别表示myid文件内容
server.1=192.168.154.146:2888:3888
server.2=192.168.154.147:2888:3888
server.3=192.168.154.148:2888:3888
5.创建myid文件
在dataDir 路径下创建myid文件
cd /home/software/apache-zookeeper-3.8.0-bin/data/zookeeper
在文件中添加server对应的编号 , 注意上下左右不能有空格
echo "1" > myid
其他文件分别为 2 3
6. 启动
bin/zkServer.sh start conf/zoo.cfg
7.其他节点按照以上配置就行
8.查看状态
bin/zkServer.sh status conf/zoo.cfg
9.停止
bin/zkServer.sh stop conf/zoo.cfg
二.Kafka
1.什么是kafka
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独
特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
首先,让我们来看一下基础的消息(Message)相关术语:
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个内部消息是有序的 |
因此,从一个较高的层面上来看,producer通过网络发送消息到Kafka集群,然后consumer来进行消费,如下图:
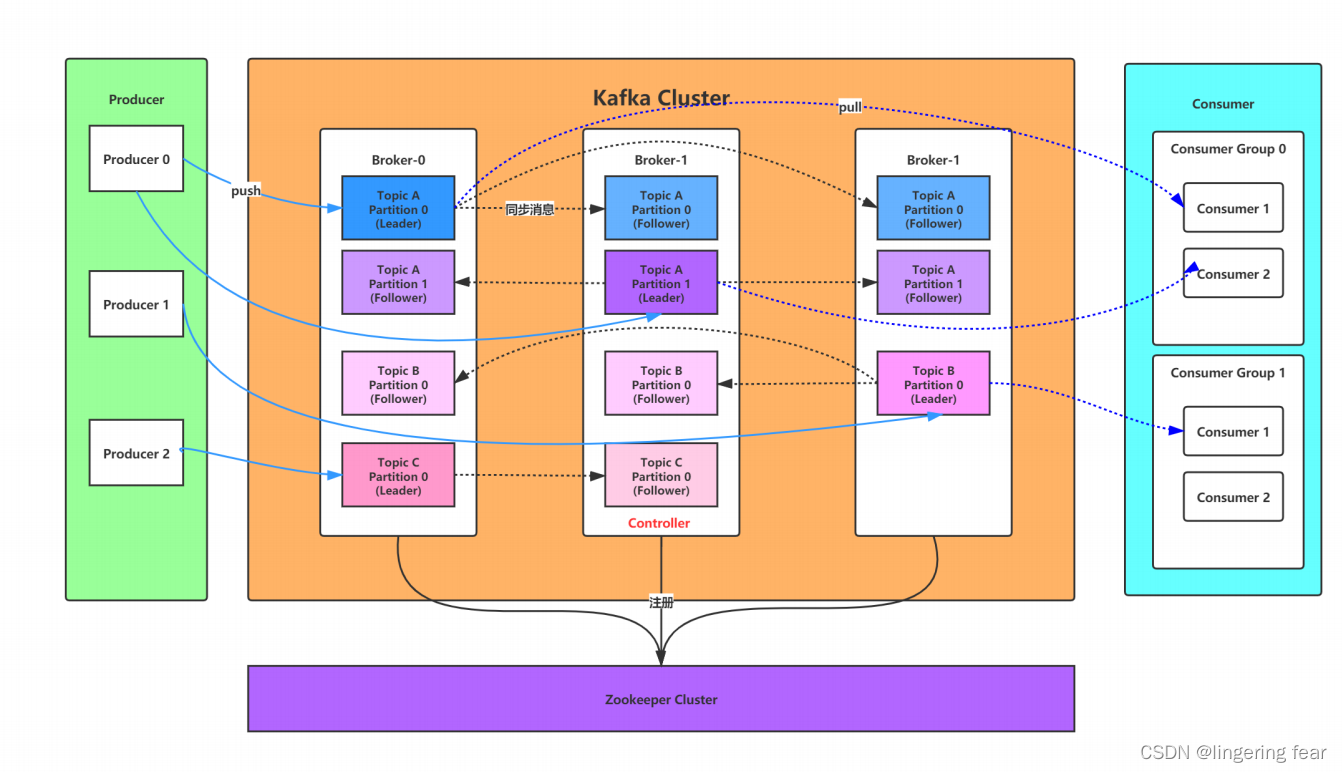
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
1.安装JDK
由于kafka是Scala语言开发的 , 运行在jvm上 , 因此在安装kafka之前要先
yum install java‐1.8.0‐openjdk* ‐y
2.kafka依赖zk , 所以需要安装zk
安装方式见上面
3.下载安装包
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11‐2.4.1.tgz # 2.11是scala的版本,2.4.1是kafka的版本
4.解压
tar ‐xzf kafka_2.11‐2.4.1.tgz
5.进入kafka的目录
cd kafka_2.11‐2.4.1
6.修改配置文件
#broker.id属性在kafka集群中必须要是唯一
broker.id=0
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.154.146:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka‐logs
#kafka连接zookeeper的地址
zookeeper.connect=192.168.154.146:2181,192.168.154.147:2181,192.168.154.148:2181
其他两台机器也按照类似的步骤安装 , 但是broker.id 以及配置文件的ip需要改变
7.启动
启动kafka,运行日志在logs目录的server.log文件里 , 后台启动,不会打印日志到控制台
bin/kafka-server-start.sh -daemon config/server.properties
或者是
bin/kafka-server-start.sh config/server.properties &
8.停止
bin/kafka-server-stop.sh
9. 查看zk数据(非必要)
进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树
bin/zkCli.sh
ls / #查看zk的根目录kafka相关节点
ls /brokers/ids #查看kafka节点















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











