







python—第13天—高阶函数
函数参数
在设计函数的时候,函数的参数个数是暂时无法确定的
arguments —> args —> 参数
位置参数 —> position arguments
关键字参数 —> keyword arguments
*args —> 可变参数 —> 可以接收零个或任意多个位置参数 —> 将所有的位置参数打包成一个元组
**kwargs —> 可以接受零个或任意多个关键字参数 —> 将所有关键字参数打包成一个字典
def add(*args, **kwargs):
"""相加"""
total = 0
for arg in args:
if type(arg) in (int, float):
total += arg
for value in kwargs.values():
if type(value) in (int, float):
total += value
return total
def mul(*args, **kwargs):
"""相乘"""
total = 1
for arg in args:
if type(arg) in (int, float):
total *= arg
for value in kwargs.values():
if type(value) in (int, float):
total *= value
return total
print(add(1, 2, 3, 4))
print(mul(1, 2, 3, 4))
高阶函数
Python中的函数是一等函数(一等公民)
- 函数可以作为函数的参数
- 函数可以作为函数的返回值
- 函数可以赋值给变量
如果把函数作为函数的参数或者返回值,这种玩法通常称之为高阶函数。
通常使用高阶函数可以实现对原有函数的解耦合操作。
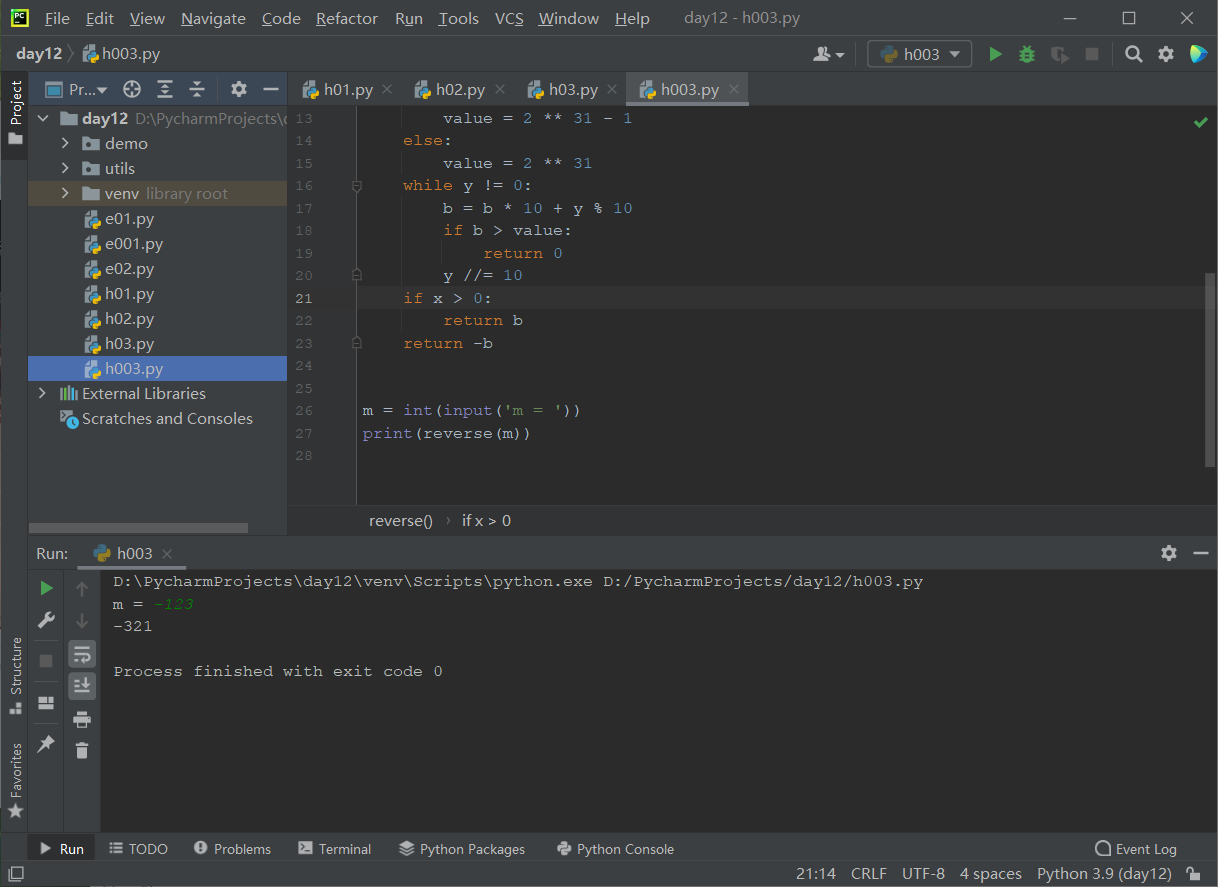
# fn ---> 一个实现二元运算的函数(可以做任意的二元运算)
def calc(*args, op, init_value=0, **kwargs):
total = init_value
for arg in args:
if type(arg) in (int, float):
total = op(total, arg)
for value in kwargs.values():
if type(value) in (int, float):
total = op(total, value)
return total
# 加法运算
print(calc(11, 22, 33, 44, op=lambda x, y: x + y))
# 乘法运算
print(calc(11, 22, 33, 44, init_value=1, op=lambda x, y: x * y))
# 减法运算
print(calc(11, 22, 33, 44, init_value=100, op=lambda x, y: x - y))
运算 - operator - op
Lambda函数 — 没有名字而且一句话就能写完
这里我们也可以使用
operator函数,里面就有各类运算
练习1:
编写实现对列表元素进行冒泡排序的函数
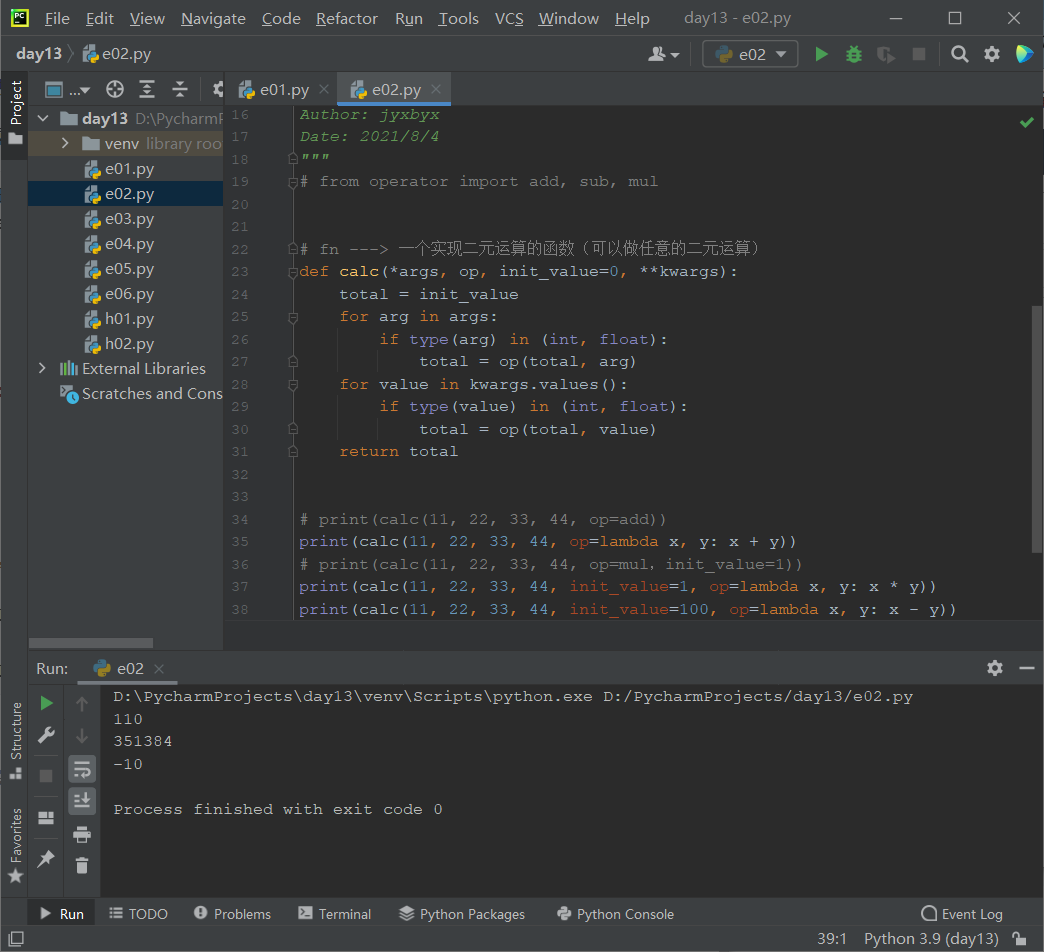
def bubble_sort(items, asending=True, gt=lambda x, y: x > y):
"""冒泡排序
:param items: 待排序列表
:param asending: 是否升序
:param gt: 比较两个元素大小的函数
:return: 排序后的列表
"""
# 保证原有列表不改变
items = items[:]
for i in range(1, len(items)):
swapped = False
for j in range(i, len(items) - i):
if gt(items[j], items[j + 1]):
items[j], items[j + 1] = items[j + 1], items[j]
swapped = True
if not swapped:
break
# 控制排序是升序还是降序,默认升序
if not asending:
items = items[::-1]
return items
if __name__ == '__main__':
nums = [2, 6, 5, 1, 3, 4]
print(bubble_sort(nums, ))
print(bubble_sort(nums, False))
# 使用lambda函数,实现对字符串长度进行比较
words = ['apple', 'watermelon', 'zoo', 'banana']
print(bubble_sort(words, gt=lambda x, y: len(x) > len(y)))
练习2:
-
编写实现查找列表元素的函数
-
列表元素无序 —> 顺序查找
-
列表元素有序 —> 二分查找(折半查找)
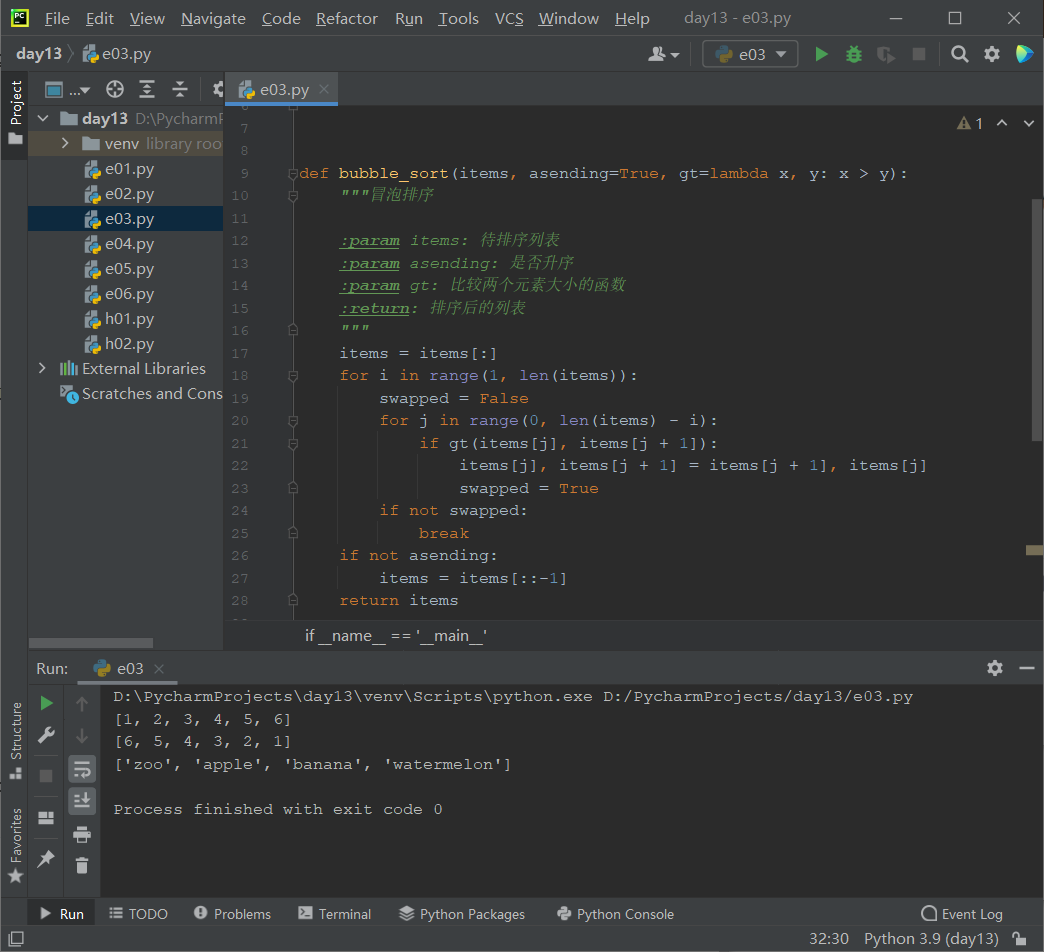
def seq_search(items, key):
"""顺序查找"""
for index, item in enumerate(items):
if item == key:
return index
return -1
def bin_search(items, key, *, cmp=lambda x, y: x - y):
"""二分查找"""
start, end = 0, len(items) - 1
while start <= end:
mid = (start + end) // 2
if cmp(key, items[mid]) > 0:
start = mid + 1
elif cmp(key, items[mid]) < 0:
end = mid + 1
else:
return mid
return -1
if __name__ == '__main__':
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(bin_search(nums, 8))
print(seq_search(nums, 2))
函数可以自己调用自己吗???
函数如果直接或间接的调用自身,这种调用为递归调用
不管函数是调用别的函数,还是调用自身,一定要做到快速收敛。
再比较有限的调用次数内能够结束,而不是无限制的调用函数。
如果一个函数(通常之递归调用的函数)不能够快速收敛,那么就很有可能产生下面错误
RecursionError: maximum recursion depth exceeded 最终导致程序的崩溃
递归函数的两个要点:
1.递归公式(第n次跟第n-1次的关系)
2.收敛条件(什么时候停止递归调用)
def fac(num):
"""求阶乘(递归调用写法)"""
if num == 0:
return 1
return num * fac(num - 1)
if __name__ == '__main__':
print(fac(5))
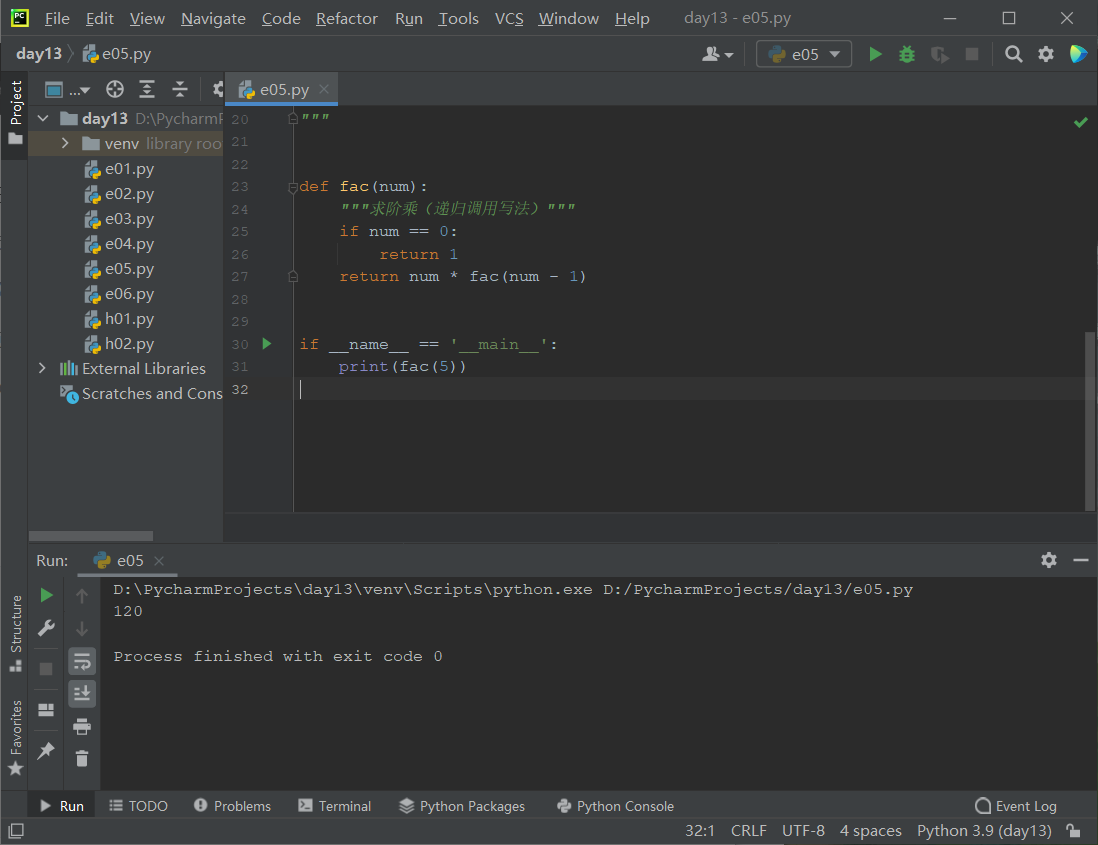
练习:斐波拉契数
1, 1, 2, 3, 5, 8, 13, 21
f(n) = f(n - 1) + f(n - 2)
def fib(n):
if n in (1, 2):
return 1
return fib(n - 1) + fib(n - 2)
从第35个斐波拉契数开始,速度就变慢了,我们可以创建一个字典来储存前面的值,这样就能大大提高效率
优化后:
def fib(n, temp={}):
if n in (1, 2):
return 1
if n not in temp:
temp[n] = fib(n - 1) + fib(n - 2)
return temp[n]
if __name__ == '__main__':
for i in range(1, 121):
print(i, fib(i))
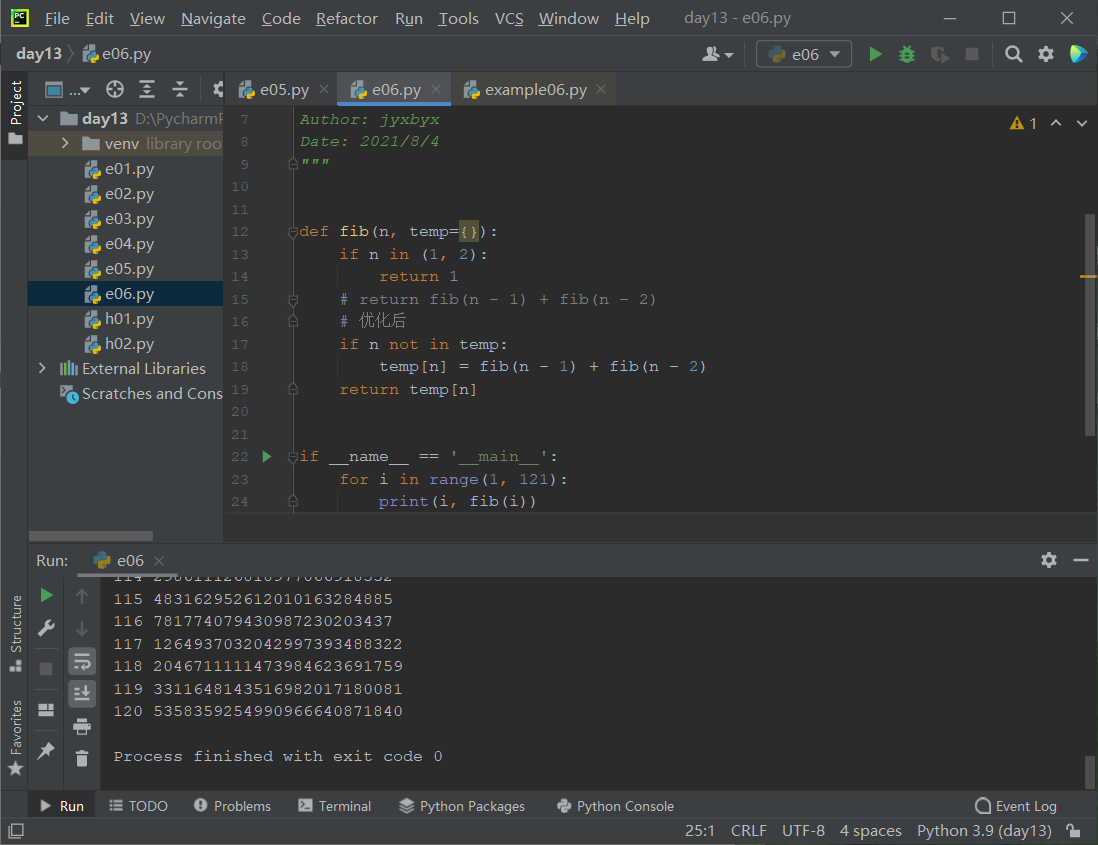
练习:汉诺塔(梵塔)问题的求解
算法:假设有 A、B、C三个塔,A 塔有 N 块盘, 目标是把这些盘全部移到 C 塔。那么先把 A 塔顶部的 N - 1 块盘移动到 B 塔, 再把 A 塔剩下的大盘移到 C, 最后把 B 塔的 N - 1 块盘移到 C。
def toh(n, a, b, c):
if n == 1:
print(a, '--->', c)
else:
toh(n - 1, a, c, b)
toh(1, a, b, c)
toh(n - 1, b, a, c)
if __name__ == '__main__':
toh(3, 'A', 'B', 'C')















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









