







文章目录
piecewise_linear_model
make_segmentation_par
make_segmentation_par 函数是使用 OpenMP 并行化 make_segmentation 函数的版本。它接受四个参数:
n:输入数组的大小。
epsilon:用于控制分段精度的参数。
in:一个接受索引并返回一对值(X,Y)的函数。此函数用于访问输入数组的元素。
out:一个接受“规范段”并对其进行操作的函数。
该函数首先使用与之前相同的方法设置并行化(即确定线程数和每个块的大小)。如果 parallelism 为 1 或 n 小于 32768,则调用单线程版本的函数。
否则,该函数设置了一个用于保存每个线程结果的向量。然后,它使用 OpenMP 的 parallel for 循环将输入数组分成块,并在每个块上调用单线程版本的函数。结果存储在向量中,然后传递给 out 函数。最后,函数返回找到的总段数。
make_segmentation
make_segmentation 函数似乎是在实现从(X,Y)数据点集创建分段线性模型的算法。它接受四个参数:
n:输入数组的大小。
epsilon:用于控制分段精度的参数。
in:一个接受索引并返回一对值(X,Y)的函数。此函数用于访问输入数组的元素。
out:一个接受“规范段”并对其进行操作的函数。
函数首先检查输入数组是否为空,如果是,则返回 0。然后,它创建了一个 OptimalPiecewiseLinearModel 类的对象 opt,该类用于创建分段线性模型。该对象使用 epsilon 的值进行初始化。
然后,函数使用 opt 对象的 add_point 方法将输入数组的第一个点添加到模型中。然后,它迭代输入数组的其余点,并使用 add_point 方法一次添加一个点。如果 add_point 方法返回 false,则意味着应创建新段,并使用 opt 对象的 get_segment 方法将当前段传递给 out 函数。然后,函数再次将当前点添加到模型中,并将段计数器加 1。
最后,将最后一段传递给 out 函数。
在函数中,首先调用 in 函数获取第一个输入点,并创建一个新的线性模型 opt。然后,循环处理剩余的点。对于每个点,如果可以在不违反最大误差限制的情况下将其添加到线性模型中,就将其添加到模型中;如果不能,就将当前模型输出到 out 函数,并创建一个新的模型继续处理剩余的点。最后,将最后一个模型输出到 out 函数,并返回模型的数量。
这段代码实现了一个将输入序列分割为最优的线段的函数。它使用OptimalPiecewiseLinearModel<X, Y>类的对象opt来执行此操作。OptimalPiecewiseLinearModel类的构造函数接受一个epsilon参数,该参数在添加点时用于在线段的端点上略微延伸。
函数从输入序列的第一个点开始遍历。它将第一个点添加到opt对象中,然后从第二个点开始遍历剩余的点。对于每个点,函数读取该点,然后检查其x值是否与上一个点的x值相同。如果是,则函数跳过该点。
否则,函数使用opt对象的add_point()函数尝试将该点添加到凸包中。如果add_point()函数返回false,则函数使用opt对象的get_segment()函数获取当前段,并将其输出。然后,函数使用add_point()函数再次尝试将该点添加到凸包中。每次成功输出段时,函数增加计数器c。
最后,函数使用get_segment()函数获取最后一个段,并将其输出。函数返回c加1的值,以表示已成功输出的线段的数量。
此处输出的意思是将本段的信息传入负责输出的函数,事实上,输出函数将本段push_back进了存储段信息的一个vector里面(segments)
OptimalPiecewiseLinearModel
OptimalPiecewiseLinearModel 类似乎是用于从(X,Y)数据点集创建分段线性模型的类。它有一个构造函数,该构造函数接受一个名为 epsilon 的参数,用于控制模型的精度。
类具有一个名为 add_point 的方法,该方法接受一个 X 值和一个 Y 值,并将它们添加到模型中。它返回一个布尔值,指示点是否已成功添加。
类还具有一个名为 get_segment 的方法,该方法返回模型的“规范段”,这是模型的特定形式的段的表示。
从提供的代码中无法清楚地了解分段线性模型是如何构建的或“规范段”是如何计算的。需要更多的上下文来提供更详细的解释。
using X = typename std::invoke_result_t<Fin, size_t>::first_type;
你提供的代码使用了 C++ 标准模板库(STL)的一些特性。
std::invoke_result_t 别名模板是一个类型特征,允许您确定调用函数对象的结果类型。它在 type_traits 头文件中定义。
Fin 和 size_t 类型作为模板参数传递给 std::invoke_result_t。假设 Fin 类型是函数类型,并将 size_t 类型作为此函数的参数传递。然后,std::invoke_result_t 返回函数调用时传递 size_t 值作为参数的结果类型。
然后使用 std::invoke_result_t 的结果类型的 first_type 和 second_type 成员类型来定义两种类型 X 和 Y。当调用 Fin 函数时,这些类型是返回对的第一个和第二个元素的类型。
因此,简而言之,代码定义了两种类型 X 和 Y,它们是调用 Fin 函数时返回的对的第一个和第二个元素的类型。
pgm_index.hpp
build
这段代码中的变量和函数意义如下:
in_fun 是一个函数对象(lambda函数),用于对输入数据进行处理。它接受一个数值型参数 i,并返回一个 std::pair 类型的值。
out_fun 是另一个函数对象,用于对处理后的数据进行存储。它接受一个值类型为 T 的参数 cs。
first 是输入迭代器,表示输入数据的起点。
n 是输入数据的元素个数。
segments 是一个数组,用于存储分层算法中的线段。
in_fun 函数的作用是:
计算输入数据中第 i 个元素的值 x。
对于输入数据中出现的重复键值,进行调整。具体来说,当满足以下所有条件时:
i 不是数组的第一个元素。
i+1 不是数组的最后一个元素。
x=first[i] 的值与前一个元素相同。
x 的值与下一个元素不相同。
x+1 的值与下一个元素不相同。
在这种情况下,将 x 调整为 x+1。
返回一个 std::pair 类型的值,其中包含调整后的键值 x 和元素编号 i。
out_fun 函数的作用是:
将处理后的数据 cs 添加到 segments 数组中。
这两个函数对象是用于分层算法中的分治算法(divide-and-conquer algorithm)的。分治算法是一种常见的算法设计技巧,它的基本思想是将一个大问题分成若干个规模较小的子问题,再对子问题求解。分治算法通常使用递归的方式实现,可以在保证时间复杂度的前提下提高空间效率。
分层算法通常使用分治算法来进行排序。在分治算法中,通常会有两个函数:
in_fun 函数,用于将输入数据转化为内部数据结构,方便进行处理。
out_fun 函数,用于将处理后的内部数据结构转化为输出数据,并存储。
在分层算法中,in_fun 函数通常会将输入数据按照键值排序,然后将每个元素的键值和元素编号打包成一个 std::pair 类型的值,便于后续处理。out_fun 函数则会将这些数据进一步处理,比如进行分层、合并等操作。
这两个函数对象的具体实现方式可以根据具
in_fun
这段代码中的lambda表达式是一个匿名函数,它的参数是一个模板参数,类型由调用时推断得到。这个匿名函数的目的是生成一个pair,其中pair的第一个元素是一个给定的数字(第一个元素是变量x,该变量的值等于first[i]),第二个元素是变量i的值。
如果当前索引i满足以下任一条件,则这个匿名函数会对第一个元素加1:
- i > 0 && i + 1u < n:这表示索引i不是数组first的第一个元素,且i+1也不是最后一个元素
- x == first[i - 1] && x != first[i + 1] && x + 1 != first[i + 1]:这行条件中的所有条件都必须为真,才能使第一个元素加1。第一个条件表示first[i]和first[i-1]相等;第二个条件表示first[i]和first[i+1]不相等;第三个条件表示first[i]+1和first[i+1]不相等。
最终,这个匿名函数会返回一个pair,其中第一个元素的值是first[i] + flag(flag的值为1或0,如果条件满足则为1,否则为0),第二个元素的值是i。
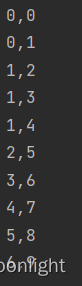
下面展示in_fun的效果
vector<int> data={0,0,1,1,1,2,3,4,5,6};
将上面数组输入in_fun,输出如下:
segment_for_key
在这段代码中,有一个函数 segment_for_key ,它接受一个泛型参数 K 并返回一个迭代器。这个函数的作用是在数据结构中查找存储给定键值 key 的段。
首先,它会检查常量表达式 EpsilonRecursive 是否等于零。如果是,则会使用 std::upper_bound 函数找到第一个大于给定键值的段,并使用 std::prev 函数返回该段的前一个段。
否则,它会获取最后一层级的第一个段的迭代器,并从最后一层级循环到第一层级。在每一层级中,它会计算当前层级的起始迭代器、使用当前层级的段的函数获取近似位置、使用宏 PGM_SUB_EPS 获取下界、使用宏 PGM_ADD_EPS 获取上界。
然后,它会检查常量表达式 EpsilonRecursive 是否小于等于常量 linear_search_threshold 。如果是,则会使用一个循环找到第一个大于给定键值的段,并将该段的迭代器赋值给 it 。
否则,它会使用 std::upper_bound 函数在当前层级中找到第一个大于给定键值的段,并使用 std::prev 函数返回该段的前一个段的迭代器。最后,它会返回找到的段的迭代器。
这段代码的意思是:在数据结构中查找存储给定键值的段。首先,它会检查常量表达式 EpsilonRecursive 的值是否为零。如果是,则会使用二分查找在数据结构中查找存储给定键值的段。否则,它会从最后一层级循环到第一层级,并在每一层级中使用二分查找或线性查找来查找存储给定键值的段。
search
在这段代码中,有一个函数 search ,它接受一个泛型参数 K 并返回一个结构体 ApproxPos 。这个函数的作用是在一个数据结构中查找给定的键值 key 。
首先,它会用 std::max 函数获取 first_key 和 key 中的最大值,并将其存储在变量 k 中。然后,它会调用函数 segment_for_key ,并将 k 作为参数传递给它。该函数返回一个迭代器,指向数据结构中存储键值 k 的特定段。
接下来,它会调用迭代器所指向的段的函数,并将 k 作为参数传递给它。这个函数返回在这个段中查找 k 的近似位置。
然后,它会使用 std::min 函数,将查找的近似位置与下一个段的截距中的最小值进行比较,并将最小值存储在变量 pos 中。
最后,它会使用宏 PGM_SUB_EPS 和 PGM_ADD_EPS 计算位置的下界和上界。最终,它会返回一个结构体 ApproxPos ,其中包含近似位置、下界和上界。
运行过程
std::vector<int> data={0,0,1,1,1,2,3,4,7,9};
 auto n_segments = internal::make_segmentation_par
auto n_segments = internal::make_segmentation_par
n_segments = 2
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









